Keywords
breast cancer, biomarker expression, Estrogen receptor, Progesterone receptor, algorithm, manual
This article is included in the Manipal Academy of Higher Education gateway.
breast cancer, biomarker expression, Estrogen receptor, Progesterone receptor, algorithm, manual
The presence and degree of Estrogen receptor (ER) and Progesterone receptor (PR) expression hold significant importance in both prognostic evaluation and selection of the most suitable treatment strategy in patients with breast cancer.1 Studies highlight that positive receptor status often correlates with better outcomes and responsiveness to hormone therapy, improving survival rates.2
Interpreting ER and PR expression in breast cancer poses challenges owing to its subjective nature, which is influenced by factors such as pathologist experience, training, and workload fatigue.3–5 Recent advancements suggest that Artificial Intelligence (AI) can enhance the accuracy and reproducibility of these assessments.5,6 Studies show AI’s potential in standardizing receptor quantification and improving diagnostic precision.7
While there have been several studies reporting on the development of individual AI models for the assessment of Her2, ER/PR in breast cancer, which have demonstrated good accuracy and reliability, their adoption has been limited because of several factors such as cost, lack of validation, and integration into routine pathology workflows.8,9
In this study, we conducted a comparative analysis of scores between the algorithm, junior, and senior pathologists in assessing the scores of ER and PR expressions in breast carcinoma to validate the performance of our in-house built algorithm (Mimansa) and its potential for incorporation into the workflow to improve diagnostic accuracy.
We conducted a comprehensive search of our pathology database to retrieve 300 surgical pathology cases to include all cases of invasive breast carcinoma of all types diagnosed from March 2020–March 2021, and study period started from June 2021 after obtaining Institutional ethics committee approval. The study incorporated a mix of slides from trucut biopsy and resection specimens to validate the algorithm across different sample types.
In our study, we obtained hematoxylin and eosin (H&E)-stained slides and immunohistochemically (IHC) stained slides for ER and PR. We excluded slides of poor quality, those with bubbles, and those that faded. Ultimately, we included 297 ER IHC slides and 293 PR IHC slides, along with their corresponding H&E slides, to ensure correlation and validation of the algorithm’s performance.
ER expression was assessed using formalin-fixed paraffin embedded (FFPE) tissue sections (ischemic time < 1 h and fixation time between 3 and 36 h) by immunohistochemistry (IHC) using an anti-ER antibody (clone EP1 mouse monoclonal antibody; Dako) and anti-PR (Clone PgR636 mouse monoclonal antibody; Dako), and staining was performed using an automated IHC stainer (Ventana Benchmark XT, Ventana Medical Systems Inc., Tucson, AZ, USA). ER and PR expression was scored using the Allred scoring system as shown in Table 1.
Algorithm development
Methodology
In this paper, we present a fully automatic multi-class tissue segmentation in-house built algorithm (Mimansa) that classifies tumors as well as other tissue regions, such as acini, ducts, and DCIS, into fine-grained segmentation maps of histopathology images. The proposed model works with multiple stains of breast IHC, including and not limited to nuclear (ER, PR) stains. The model was built using 10 million patches extracted from 513 WSI from multiple data sources and multiple scanners to account for strain and scanner illumination variations.
For the ground truth, because complete slide annotation is very difficult and time-consuming, a selective region-wise annotation technique was utilized. The pathologists selected 2–3 mutually exclusive non-similar small regions and annotated them completely with multiple labels, including tumor, normal, stroma, acini, duct, blood vessels, and DCIS. Annotations for bad regions such as Folds, Artifacts, bubbles, and out-of-focus areas were also performed, and the patches were extracted from the annotated regions.
Class imbalance
In clinical samples of WSI, tumor regions are far fewer than normal tissue regions and the background. Using filtration techniques, the non-tissue area and background were ignored. Because the majority of the annotated tissue regions were either Tumor or Normal/Stroma tissues, all additional regions (blood vessels, DCIS, acini, ducts, folds, skin, and Unknowns) were classified into a section called others. A data generator pipeline was introduced to ensure that all batches had a similar class distribution of 2:1:1 (tumor: normal: others). The algorithm also accounts for pixel-level imbalances of the dataset using a set of normalized dynamic weights.
Data augmentation and final model
The images were adjusted for visual (brightness and contrast), color, and texture differences. Augmentation techniques were used to enhance the dataset.
To compensate for the manually annotated dataset, the Phase-1 model learns basic nuances such as cell structures, background, regions to ignore, different tissue types, and staining colors. However, this model cannot be scaled to different data sources, scanner variations, and similar looking tissues such as DCIS and ACINIs, which look like tumors and have smaller FOV. In Phase-2, works on increasing augmentations and predictions. This allows for a tighter thresholding, thereby increasing the accuracy of the model.
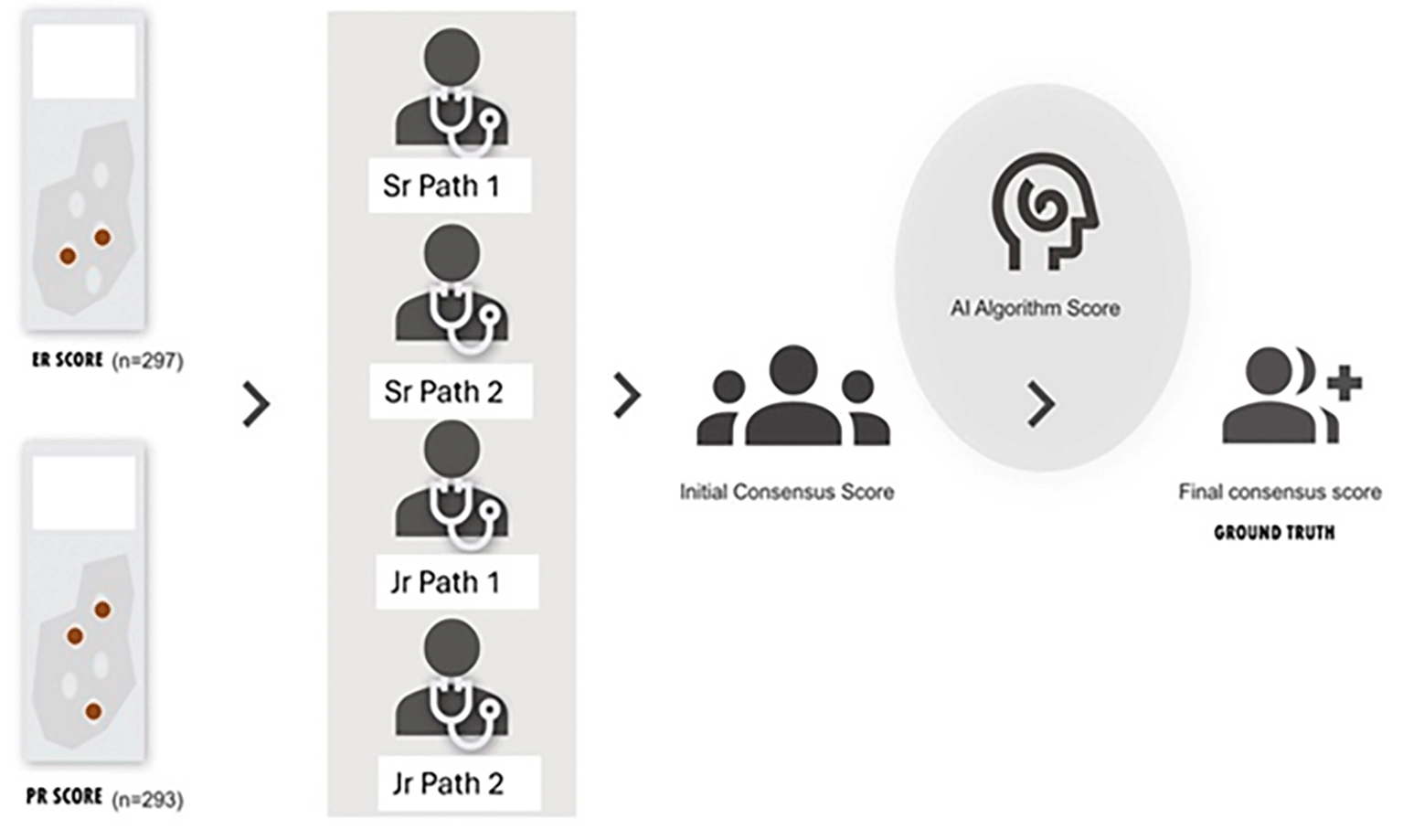
The slides were scanned using Morpholens 6 T at 40X magnification and uploaded to a cloud-based platform. The in-house built-in algorithm (Mimansa) was run to score each case, providing the proportion of positively stained tumour cells for ER and PR and the intensity of positive cells to generate a total score according to the Allred scoring system (Figures 1 and 2). Manual scoring of ER and PR IHC of the above slides was independently performed by four pathologists: two senior pathologists with over 15 years of experience in breast pathology (Sr Path 1, Sr Path 2) and two with less than three years of experience (Jr Path 1, Jr Path 2). The ER and PR scores were dichotomized, with ER/PR positivity recognized at an Allred Score cut-off of 3. Using this cut-off, scores of 0 to 2 were considered negative for ER/PR and not actionable, while scores of 3 to 8 were regarded as positive and suitable for hormonal therapy according to the American Society of Clinical Oncology/College of American Pathologists guidelines. Any discrepancy between the scores of pathologists resulting in an actionable outcome (cut-off score of 3) that would affect therapeutic decision was reviewed to obtain an initial consensus score. The algorithm was run on the digitized slides to obtain Allred scores for ER and PR similar to that of the pathologist’s score. The algorithm score was compared with the initial (pathologist) consensus score, and any discordance was reviewed to obtain a final consensus score (ground truth). The study design is depicted in Figure 3. ER and PR scores were further classified into three groups: 0–2 as negative, 3–5 as low positive and 6–8 as strong positive. The agreement and reliability between the raters and the AI-based algorithm were statistically analyzed.
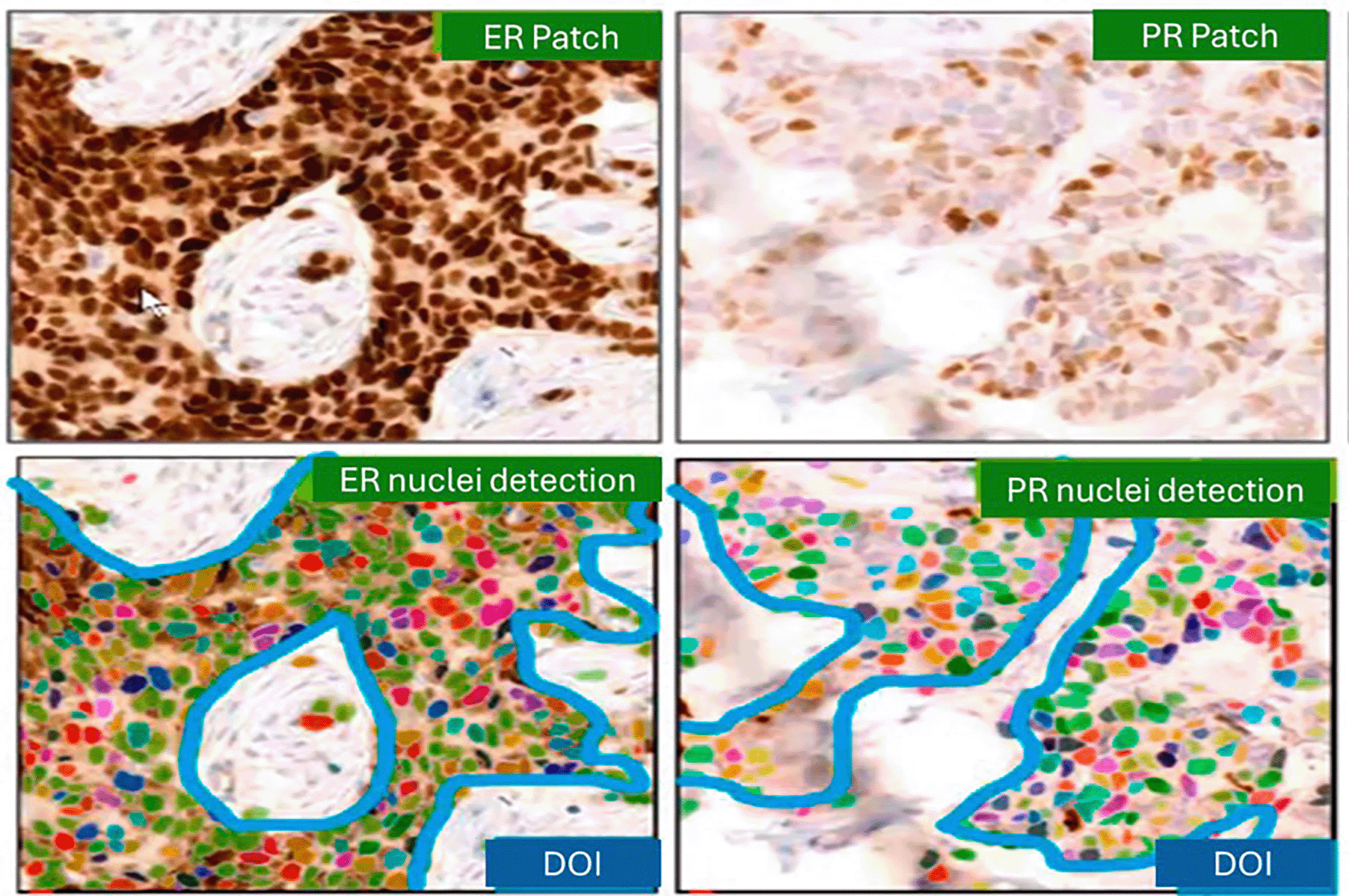
This image is output generated by the algorithm, which was developed by training AI tool (Mimansa) by pathologists and software engineers who are listed as authors to detect and represent hormone receptor staining patterns.
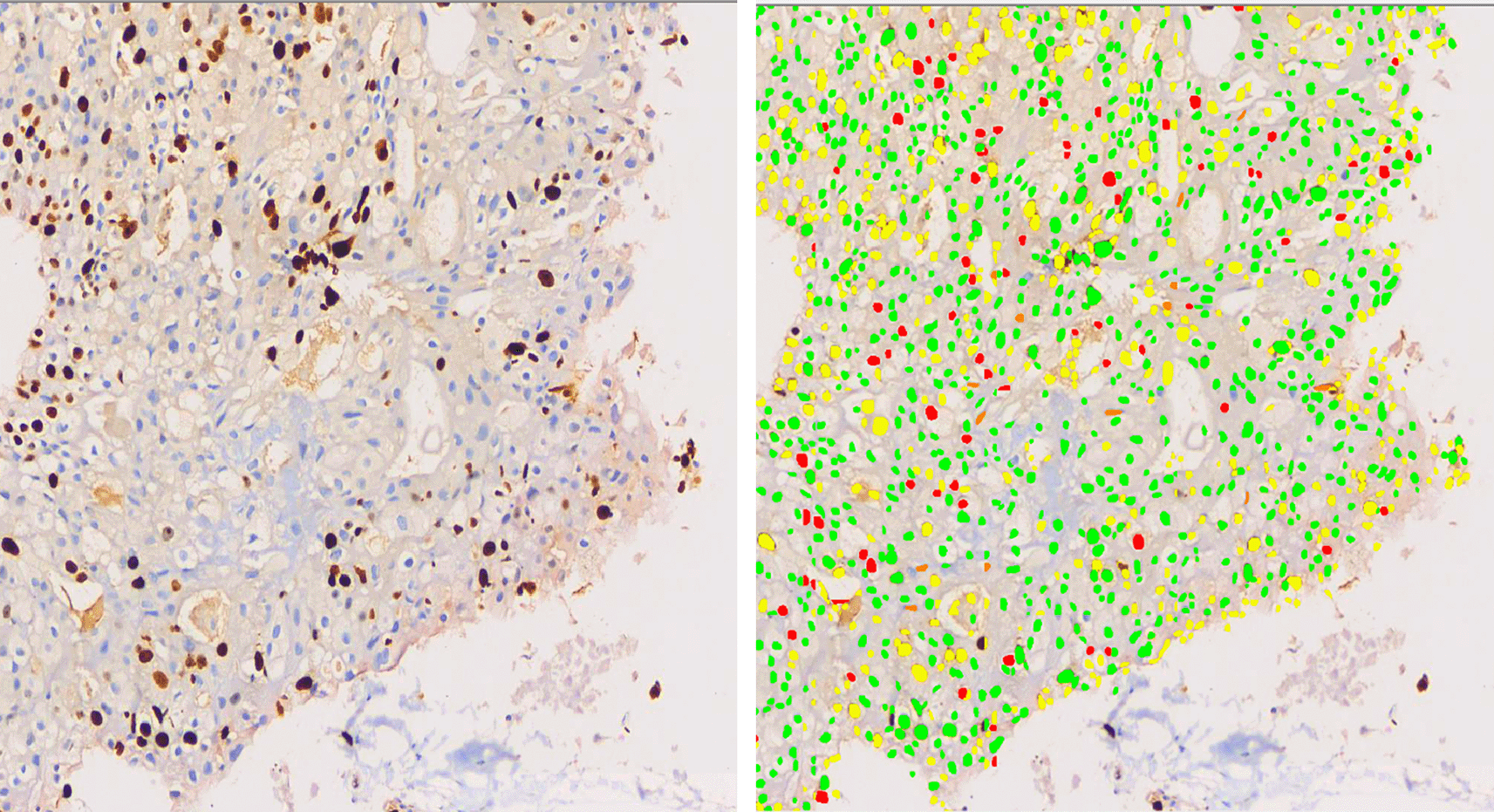
This image is output generated by the algorithm, which was developed by training AI tool (Mimansa) by pathologists and software engineers who are listed as authors to detect and represent hormone receptor staining patterns.
The Google material design icons were used for the figures.
Data were analyzed using IBM-SPSS Statistics for Windows version 23.0 (Armonk, NY, IBM Corp). Categorical data were expressed in terms of proportions and percentages. Inter-rater reliability analysis was performed using Cohen’s Kappa with significance testing and confidence intervals to see the agreement of the algorithm with ground truth for ER/PR scores across different score ranges as well as three groups: negative, low positive, and strong positive scores. Pearson’s correlation coefficient was used to evaluate the agreement of scores generated by the algorithm and other raters, which included senior pathologists and junior pathologists with the ground truth (final consensus scores).
The age of the patients ranged from 18 to 79 years. Trucut biopsies formed majority of cases (60.60%).
The most common histopathological diagnosis was Invasive ductal carcinoma of no special type. Luminal type showing either ER and/or PR positivity accounted tor 82.15% of the cases. Table 2 shows the pathological features of the 297 cases of breast carcinoma analysed in this study.
Table 3 reveals the performance of algorithm for ER and PR expression.and the reasons for mis-interpretation. There was concordance of 93.93% with ER expression, while slightly lower at 87.37% for PR expression scoring by algorithm when compared with ground truth. The reasons for misinterpretation are listed in Table 3 and in Figure 4.
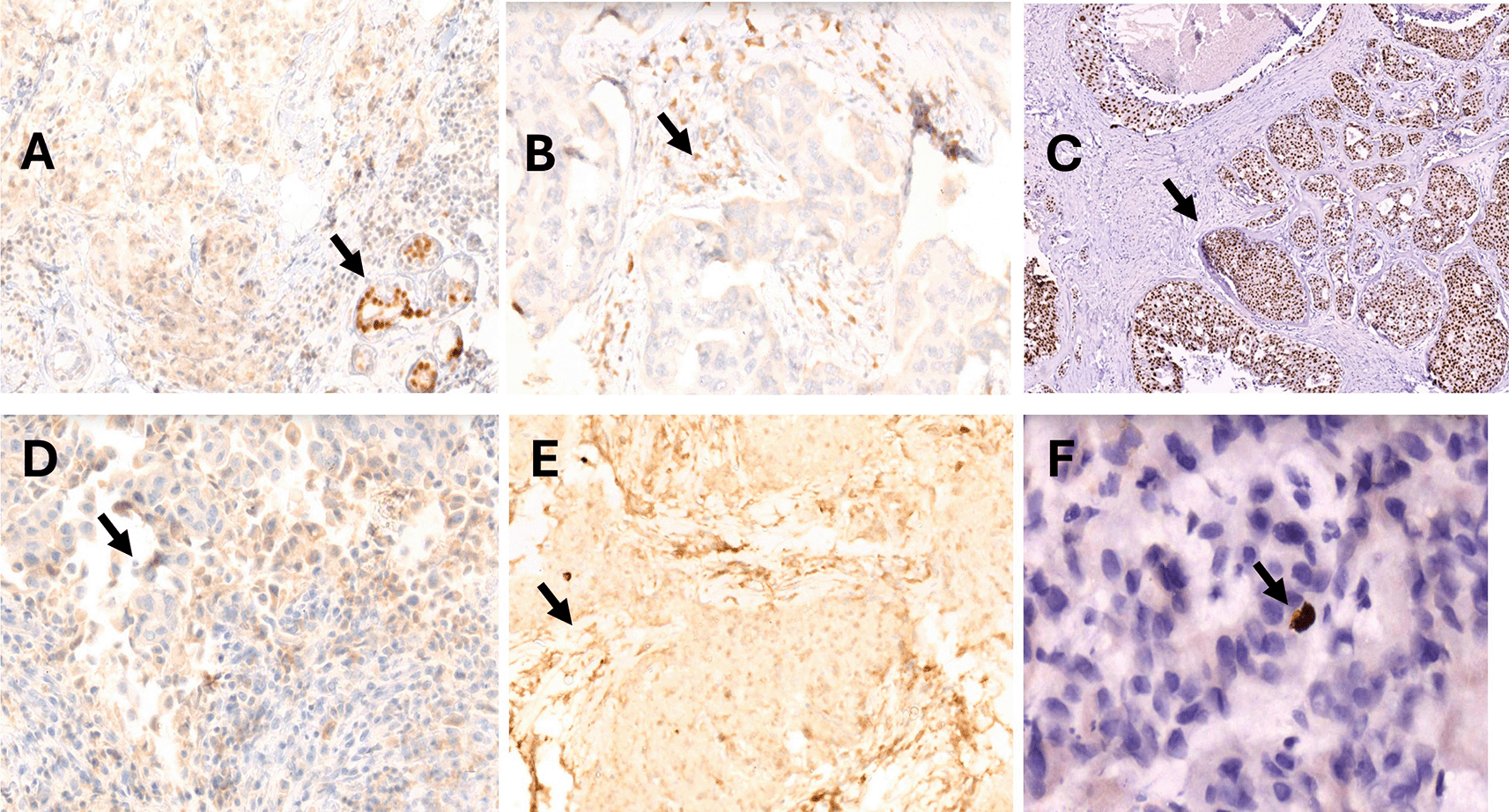
There were no statistically significant differences in ER and PR scores between the trucut biopsy and resection specimens.
Tables 4–6 reveal Algorithm performance for different scores, low positive and strong positive scores as well as comparison with senior and junior pathologists for ER expression.
For ER expression, the ground truth (GT) revealed 169 strong positive, 31 low positive, and 98 negative cases. Concordance with GT was highest among senior pathologists (99% and 98%), followed by the AI algorithm (97%), and slightly lower for junior pathologists (95% and 93%). The algorithm was particularly accurate in correctly classifying all strong positive cases; however, discordance was observed in 16 low-score cases, including four false negatives and ten false positives. Importantly, the algorithm correctly identified two true positive cases that were missed by all pathologists.
Tables 7–9 reveal Algorithm performance for different scores, low positive and strong positive scores as well as comparison with senior and junior pathologists for PR expression.
The above results for PR immunohistochemistry reveals 98% and 97% agreement for senior pathologists, 92% for the algorithm, and 93% and 91% for junior pathologists with ground truth. The algorithm for PR expression also achieved perfect concordance in strong positive cases but showed reduced performance in low-score cases, resulting in 16 false negatives and eight false positives. Cohen’s kappa coefficients demonstrated excellent agreement for ER (κ = 0.91) and strong agreement for PR (κ = 0.84).
Assessing estrogen receptor (ER) and progesterone receptor (PR) status by immunohistochemistry in breast cancer is essential, as it guides treatment decisions and predicts therapeutic responses.10–12 However, the reliability of assay results depends on both the consistency of assay performance and the accuracy of its interpretation.13 Automated immune-stainers with high reproducibility, combined with whole slide digitalization and dedicated software helps in objective image quantification through color and intensity segmentation, allowing for unbiased scoring.5,14
Several studies have validated the performance of automated scoring methods against manual assessment of estrogen receptor (ER) and progesterone receptor (PR) expression in breast cancer and have shown a strong correlation between automated image analysis and manual scoring techniques, suggesting that automated methods can serve as reliable alternatives.14–16 Some models were based on tissue microarrays, while others utilized whole slide images for analysis.14,17,18 Some of the algorithms used required training and inputs from pathologists, while others have used algorithms that do not require supervision.19,20 Automated or digital image analysis has several advantages, such as reducing the bias in sampling, reducing inter- and intra-reader variability, providing more consistent reporting, and significantly reducing pathologists’ workload.21
In our study, we demonstrated that the algorithm developed (Mimansa) was able to detect the relevant tumor regions from WSI, quantify immunohistochemical expression, generate ER and PR scores, and effectively replicate the ER and PR scores produced by pathologist visual scoring. Our study showed good agreement of the AI algorithm in assessing ER and PR scores with the ground truth, which was slightly lower than that of pathologists. There was no statistically significant difference between the scores of senior and junior pathologists as well as the algorithm. The overall agreement between the ER score and ground truth was 93.93%, and the PR score was 87.37%. Similar results were noted in a study by Jung et al., which showed 93% concordance for ER expression (197 cases) and 89.4% (199 cases) for PR expression by the algorithm.22 Shafi et al. observed 93.85 concordance for ER expression in their study on 97 cases23 and the Pearson correlation coefficient (PCC) score in our study was 0.937 and 0.887 for ER and PR, respectively, which was similar to the study by Bankhead et al., which showed a PCC of 0.908 and 0.862 for ER and PR, respectively.24 Sharangpani et al. found an agreement of 85% and 81% between the automatic determination of positivity/negativity of ER and PR-stained cells with manual scoring.15 Gokhale et al. reported 95% concordance between automated and manual scoring, while Mofidi et al. demonstrated a highly significant correlation (r2 = 0.844) between digital and manual ones.7,14
In our study, the algorithm demonstrated excellent agreement for negative (0–2) and strong positive (6–8) groups, with kappa values of .891 and .921 for ER expression and .829 and .856, respectively, for PR expression, and moderate agreement for the low positive (3–5 scores) group with a kappa of .587 for ER expression and .534 or PR expression, suggesting the need for refinement of the algorithm to identify low positive (3–5) scores. We identified reasons for the inaccuracies in this group with false-positive scores due to misinterpretation that occurred due to interspersed positive staining of normal breast acini, ductal carcinoma in situ component when the invasive component was negative, tissue folds with brown staining, stain artifact clumps on the tissue, non-specific staining of stromal cells, and cytoplasm of the cytoplasm of tumor cells. Shafi et al. also reported three cases of false-positive ER expression by DIA, which was mainly due to intermixed benign glands in the tumor area, ductal carcinoma in situ (DCIS) components, and tissue folding .21 However, these false-positive scores in our case could be mitigated by incorporating an option in the algorithm to manually exclude areas such as tissue folds, normal breast acini, etc. before re-running the analysis. Such misclassification errors occurring from poorly stained samples or samples of bad quality can be overcome by the ability of digital image analysis to reclassify or drop individual detected objects and recalculate the software provided results.25
We noticed 7 false-negative cases for ER and 18 for PR, with the majority occurring in the low positive score range, highlighting the need for further refinement in this category. Conversely, the AI algorithm identified two true-positive ER cases that were missed by all the pathologists. This capability highlights the potential of the algorithm to significantly influence patient treatment decisions by detecting subtle positive findings that could otherwise be overlooked. This ability of the algorithm to detect critical diagnostic errors demonstrates its potential for improving diagnostic accuracy. Studies have shown improved intra- and interobserver agreement by providing pathologists with computer-aided IHC measurements during the visual scoring process. It is possible that the pathologist missed some positive cells because of the sheer size of the images.18 Since consensus scoring by experts is impractical in routine practice, automated IHC measurements may provide a means to improve scores. Shafi et al. demonstrated increased efficiency in the ER assessment of breast cancer by integrating DIA in the workflow of pathologists.23 AI analyzer could be used as an aid to pathologists as a ‘second reader’ in harmonizing judgments that may diverge due to over- or underestimations.26 Jung et al. suggested utilizing the AI analyzer as a tool for second opinions, where pathologists can maintain their original workflow, requiring reinterpretation in only a selected subset of cases (approximately 10% for ER and PR).22
One of the drawbacks of the study was the scope of validation of the AI algorithm, which was primarily confined to enhancing the concordance of pathologist interpretations. Clinical validation, such as its impact on patient survival outcomes, was not performed.
The algorithm showed good agreement in scoring ER and PR expressions with the ground truth, making it a reliable tool for aiding diagnostic decision-making. It can serve as a valuable support tool for pathologists and provide a second opinion, particularly in low-positive cases where human error might occur. Notably, the algorithm identified two cases in which patients could benefit from anti-estrogen treatment, highlighting its potential clinical impact.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)