Keywords
Heart disease, Preprocess, Feature selection, Machine learning.
This article is included in the Manipal Academy of Higher Education gateway.
This article is included in the Artificial Intelligence and Machine Learning gateway.
Heart disease, Preprocess, Feature selection, Machine learning.
Currently, CVD is of great concern in the medical field. CVD is the most common chronic and death-causing disease. Worldwide, a higher percentage of people die of CVD, as per the World Heart Report (WHO).1 It also states that approximately 85% of CVD-suffering patients end up heart attacks and strokes. A survey conducted by the WHO also states that approximately 20 million people die of CVD every year. This mass death holds 31% of total deaths caused globally. This number may increase to 24 million in another five years if early detection and treatment are not performed.2 An attack occurs due to a clot of blood, cholesterol, fat, and other substances deposited in the arteries of the heart. This blocks the flow of blood to certain parts of the heart and causes it to stop. The reasons for heart attacks include obesity, diabetes, sedentary lifestyle, stress, unhealthy diet practices, high blood pressure, and cholesterol. If blood goes to or inside the brain clots, stroke occurs as blood circulation stops.3 A heart attack occurs when the heart fails to pump blood into all parts of the body.4 Symptoms of CVD include shortness of breathing activity, variation in heartbeat, dizziness, sweating, nausea, discomfort in the chest area, and swelling of the feet. With an early sense of symptoms and appropriate medication, patients can come out of danger. Other causes of CVD include obesity, high BP, alcohol intake, lack of physical activity, genetic mutations, and high cholesterol. If detection occurs earlier, the patient can change their lifestyle, include more physical activities, and avoid alcohol and smoking, which can help reduce the mortality rate.5
Current laboratories are equipped to diagnose heart disease using the patient’s medical history and symptoms experienced by the patient. Finally, doctors analyze the reports generated from the lab to make a final decision. A few studies say that approximately 67% of patients are predicted accurately in the presence of CVD.6 For accurate detection, there is a need for an automatic system that is essential for the accurate prediction of CVD. Recent research on machine learning models helps to improve decision-making, which leads to many research opportunities in the health domain,7 especially in the early detection of CVD and other chronic diseases, which avoids deaths. Machine learning is used in many applications including disease risk detection, tumor detection, and other health-related issues. It provides predictive modeling techniques to overcome current limitations. Machine learning models are used in the majority of healthcare domains owing to their predictive modeling techniques. Because of this advancement, doctors can save time by investing in reports, which can then be used to provide highly accurate medications. Because of this advancement, doctors can save time by investing in reports, which can then be used to provide highly accurate medications. Machine learning models include regression and classification phases. The classification phases of machine learning models are widely employed in the health domain. Supervised machine learning models provide greater accuracy in detecting whether a patient is healthy or unhealthy.8
In 2024,9 the author proposed machine learning methods to detect heart disease using the dataset presented in Kaggle. The dataset was named Heart 2020. Employed stack of machine learning models, such as Random Forest, Decision Tree, LightGBM, and Logistic Regression and LightGBM. They achieved the highest accuracy of 76.9%, and limitation of study was that exposure to various datasets was essential. Statlog from the UCI website Cleveland dataset was used to train and test the machine learning model. Achieved 88.87% of maximum accuracy for Cleveland and 88.88% for Statlog dataset.12 The same dataset was employed by another researcher; however, novelty exists in feature extraction and classification. Employed feature selection suggested by PCA and RFE. For classification, bagging, boosting, and ensembling were performed with an ANN. Achieved accuracy was 94.1%.13 They prepared a comparison table by comparing ensemble classifiers with existing machine-learning models. The new methods employed for feature extraction are OneR, GA and Correlation. Achieved An accuracy of 67% by SVM and 8.16% by using correlation method with hybrid models. The dataset employed was from the Framingham Heart Study.14 A few adaptive feature selection methods have gained importance in extracting features using RFE methods. The author15 used these adaptive feature selection methods along with the RFE methods. For classification, SVM, LR, decision tree, and random forest (RF) were employed and achieved a high accuracy of 97.4% by RF. With several other datasets, many research work was carried upon and achieved high accuracy in machine learning models 96.21%17 and 95.08%.16 With few modifications in feature extraction by using sequential feature selection based on gradient boosting accuracy has been increased to 98.78%.19 Another feature extraction such as Recursive Feature Elimination with cross-validation proposed by,18 increased existing performance by 14.81%. Later, using the same two machine learning models, SVM and KNN10 proposed a methodology for feature extraction by the year 2024. Feature attributes were selected from the chi-square statistic method, and the optimizer employed was cuckoo search optimization. The etched features are fed to the classifiers. Researchers moved to deep learning and hybrid models to predict heart disease, in this fashion in year 2024 author had employed CNN-UMAP and achieved an accuracy of 91.88%. Feature selection techniques include Relief, UMAP, and LDA. Based on the study, the gap identified is based on three aspects: first, on the dataset, to train and test the model requires patient data. If the number of patients was small, the model could be overfitted. Hence, there is a need for more patients to provide efficient accuracy. Improvement of feature extraction methods by selecting features using various methods. The Objective of this study was to generate a dataset with a higher number of patients (1300) compared to the existing 300 patients’ data and to design and develop an AI-based machine learning model to predict heart disease in patients.
The contribution of the current research work starts with the preparation of the dataset and has combined two datasets (VA Long Beach, 303 patients; cardiovascular disease, 1000 patients) to increase the number of patients. The number of patients had increased to 1303. The selection of feature attributes was based on 0.75 and 0.5 and evaluated for every feature set. Along with the correlation features selected by the chi-square test, they were trained and tested on machine learning models. For classification, six machine learning methods were employed to evaluate the datasets. To increase the accuracy of the model, other parameters such as F1 score, precision, and recall are tabulated. Tuning machine-learning models to provide good accuracy. To avoid under-and overfitting the deltastop, max_depth was tuned in the XGBoost classifiers.
Section 1 describes the introduction of heart diseases and their death ratios globally. It also describes how machine-learning models can address this with minimum time. Section 2 describes the related work on detecting heart diseases using machine learning. Section 3 describes the proposed methodology for detecting machine learning methods. Finally, conclusions on the proposed work and future directions are provided.
This section [ Figure 1] describes the steps involved in the detection of heart disease. The steps are as follows:
1. Collection of the dataset
2. Pre-process the dataset to identify missing values and fill them.
3. Evaluate the feature attributes based on correlation
4. Train machine learning models
5. Evaluation of models
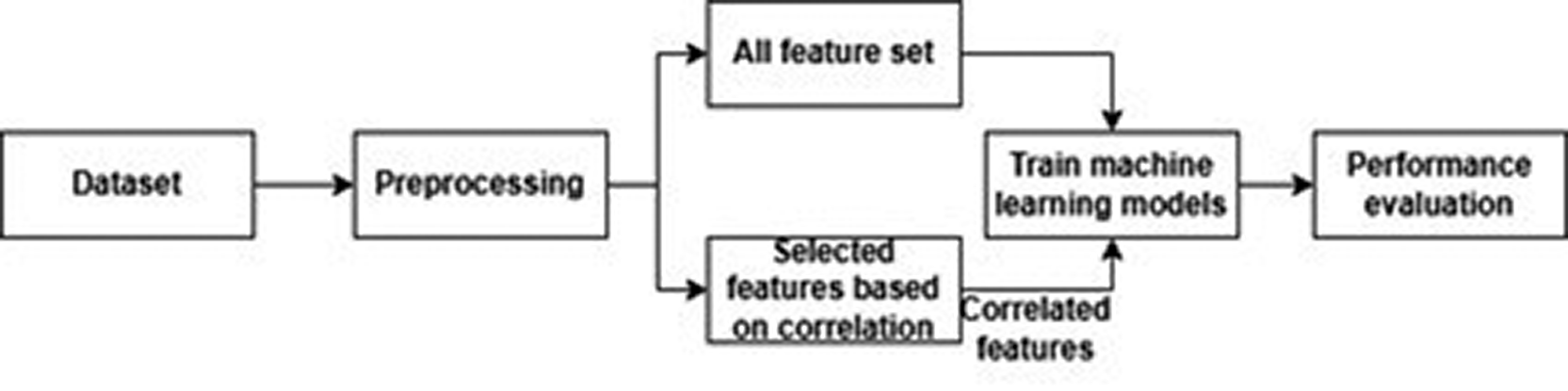
The first step in every machine learning model is data collection, and we collected a dataset by combining two datasets, namely, the Cleveland, Hungary, Switzerland, and Long Beach V. datasets and the archive dataset from Kaggle.21,22 A combination of both datasets recorded 1303 patients with a total of 13 features. In the pre-processing step, missing values are handled by calculating the sum of the neighboring rows. This replacement increases the accuracy of machine learning models. Later, feature selection is performed using the correlation (0.75 and 0.5) between features and features selected by the chi-square test. The next step is to apply machine learning models to predict CVD. The model was evaluated after it was trained with all features and two sets of correlation values. The dataset was divided into training and testing groups in a 70:30 ratio. To avoid overfitting and underfitting, the models were tuned.
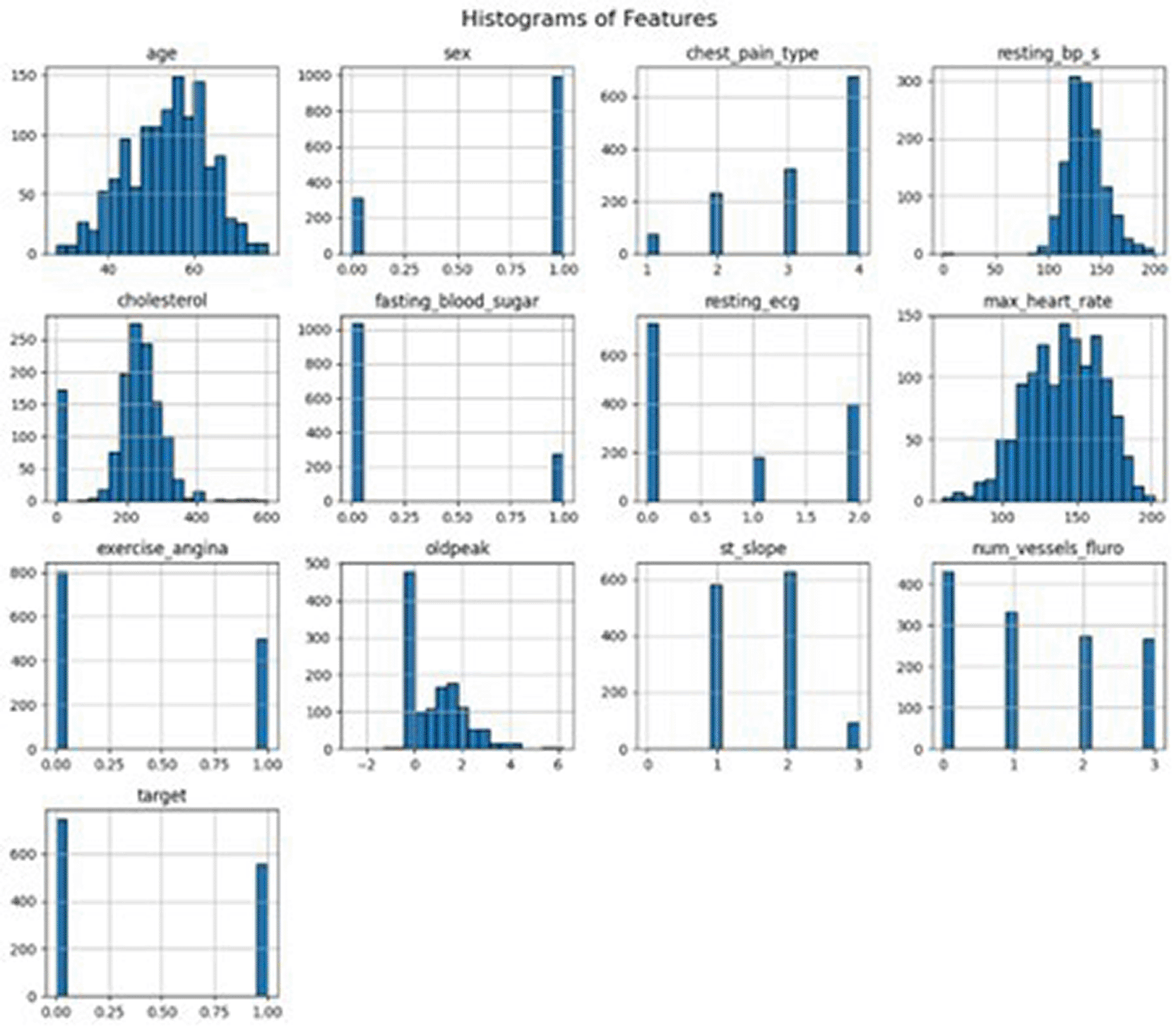
The dataset has 13 features, including one feature as a target (which indicates healthy and unhealthy states), and it is extended to every patient. This is a balanced dataset with both categorical and numerical variables, which is ideal for developing predictive models and analyzing heart diseases. When an attribute has less than ten different classes, it is considered categorical or nominal. Some of them include sex, type of chest pain, fasting blood glucose level, ECG findings, and many more. The gender attribute is binary, with ‘1’ for male and ‘0’ for female based on the sex attribute. Chest pain type (cp) is categorized into four distinct classes: These subtypes include typical angina, atypical angina, non-anginal chest pain, and asymptomatic chest pain. Fasting blood sugar (fbs) was also binary, depicting a value of more than 120 mg/dL (1 for true, 0 for false).
Three classes were used to classify the results of the resting electrocardiogram (resting): normal, ST-T wave changes, and definite LVH. Another binary variable, exercise-performed angina (exang), assigns a value of 1 to indicate the presence of chest pain during exertion and a value of 0 to indicate its absence. There were three types of slopes for the peak exercise ST segment: downslope, flat, and upslope. While the fluoroscopy visualization of the number of major vessels (ca) ranges from 0 to 3, the thalassemia attribute (thal) categorizes the heart status as either normal, fixed defect, or reversible defect.
The numerical features return continuous data, which is valuable for fine-grained analysis, as opposed to nominal features. These variables included age, resting systolic blood pressure in millimeters of mercury (trestbps), serum cholesterol in milligrams per deciliter (chol), maximum achieved heart rate (thalach), and ST segment depression compared to rest (oldpeak). They record specific clinical parameters that are crucial for assessing the cardiovascular function.
It is also critical to recognize that the target attribute has been transformed into a binary variable from its original quantification into five classes that represent varying degrees of heart disease risk. This simplifies the problem by transforming it into a classification problem, with the goal of ascertaining whether a person has heart disease [ Table 1].
In order to increase number of patients in the dataset combining two datasets namely
The two datasets shared almost the same features, but different names were provided to the features. Table 2 shows naming conventions; the thallium feature is not present in 2 cardiovascular diseases, hence leaving these features and considering the rest of the features. The statistical data for each attribute, including the minimum, maximum, mean, standard deviation, 25%, 50%, and 75%, are displayed in Table 3. As a result, various machine learning models have been trained using a combined dataset to identify the classifier that is most effective in detecting CVD.
| a) Integer type feature attributes details | ||||
|---|---|---|---|---|
| Feature/measure | Age | Resting bps | Chol | oldpeak |
| Mean | 53 | 132.00 | 217 | 0.94 |
| Std | 9.313 | 18.27 | 95 | 1.09 |
| Min | 28 | 0 | 0 | −2.6 |
| 25% | 47 | 120 | 197 | 0 |
| 50% | 54 | 130 | 233 | 0.6 |
| 75% | 60 | 140 | 271 | 1.6 |
| max | 77 | 200 | 603 | 6.2 |
If no value is assigned to a particular variable in an observation, it is referred to as missing or incomplete. These missing values can originate from different circumstances, such as when the respondent fails to answer some questions, failure of the sensor, data loss during transfer, disruption in the network connection, or a mathematical operation, such as division by zero. In datasets [ Figure 2], missing values can be indicated by spaces, hyphens, or other marks that differentiate them from other regular values.
The missing values may or may not affect the statistical validity of the outcome. However, the outcomes may lack robustness or accuracy due to omitted information, even though analysis can move forward with incomplete data. Even if each individual variable has only a small percentage of missing data, the cumulative amount across the dataset may be significant, thereby influencing the analysis results. It is worthwhile to replace the observations rather than deleting them because observations with missing values can be quite informative. The strategies include:
• It preferable to use the mean value of the variable of interest to avoid bias.
• The Cleveland heart dataset contains missing values for the nominal attributes thal (thalassemia) and ca (the number of major vessels). These were handled as follows.
• This attribute had four items with missing values that were replaced by the most frequent value, which was zero and occurred 176 times in 299 records.
Earlier studies used multiple supervised machine learning models on a single dataset to predict CVD. Six machine learning models are discussed in this section to predict patients who may be at risk of CVD.
Regression models estimate the target variables on a continuum rather than grouping the outcomes into categories. Linear regression is the basic form of regression analysis, which assumes linearity and attempts to minimize the error between the actual and predicted values. Other types include polynomial and ridge regression, which are for more complex relationships, or when regularization is required.22,23
Naïve Bayes is a probabilistic classifier that relies on the assumption of feature independence and is derived from the base Bayes formula. This algorithm is computationally efficient and is widely applied to text categorization, spam detection, and sentiment analysis. However, it is efficient and can work well in various real-life situations, particularly when dealing with big data. Based on the input features, it assigns an instance to the class with the highest posterior probability.24
Random Forest is another type of meta-cascade that is composed of many decision trees, where the bagging technique is adopted for increased precision and stability. A subset of the data is used to train each tree, and the final decision (class for classification or mean for regression) is made by considering the results of all the trees. This is less prone to overfitting than individual decision trees, and is flexible for tasks involving structured data.25
Logistic regression is a classification algorithm that predicts probabilities by applying a sigmoid function, which is appropriate when the output is binary. Although closely related to linear regression, it transforms the results into the range of [0, 1]. It has been applied in disease prediction, email classification, and customer churn analysis because of its simplicity and interpretability.27
The gradient-boosting framework XGBoost is popular and often wins machine-learning competitions because it is built for high performance. It iteratively constructs decision trees, gradually corrects the mistakes made in prior steps, and employs shrinkage to curb overlearning. It performs well when dealing with missing values and large structures.14 Modifications were performed to avoid under-and overfitting.
• The maximum depth was set to five, and the tree did not grow beyond level 5. If a deeper model is overfitted, it is restricted to five.14
• The delta step is set to 0.1: when there is an imbalanced dataset, the model learning rate will be very low. During these stages, the small-delta step model adjusts the weights accordingly and reduces overfitting.25
• Gamma is set to 0.6; this term is called regularization, which controls the complexity of the model when new trees are added. 0.6 gives good results during new tree additions.14
These modifications in the model help to fight during imbalance dataset and avoids overfitting.
LightGBM is a gradient boosting framework that supports multiclass classification and regression problems and is based on a speed-optimized decision tree. It contains a histogram-based algorithm to build a decision tree for the learning process and manages the memory well. Its approach, such as leaf-wise tree growth, makes it faster than XGBoost for a variety of tasks including recommendations, clicks, and ranking.26
To select important features for improving classification that are correlation-based (with two 0.75 and 0.5), chi-square feature selection is employed in the current research. Correlation describes the similarity between two components. This method determines which feature is highly efficient in predicting targets individually. The highly correlated features [ Table 4] between each other, have considered two thresholds to collect correlated values are 70% and 50% of target values. These features have low redundancy and are highly relevant to the target classes.28
| Correlation value | Feature name | Feature number |
|---|---|---|
| 75% | Chest pain type | 3 |
| Exercise_angin | 9 | |
| St_slope | 11 | |
| 50% | Sex | 2 |
| Chest pain type | 3 | |
| Fbs | 6 | |
| Exercise_sngin | 9 | |
| St_slope | 11 |
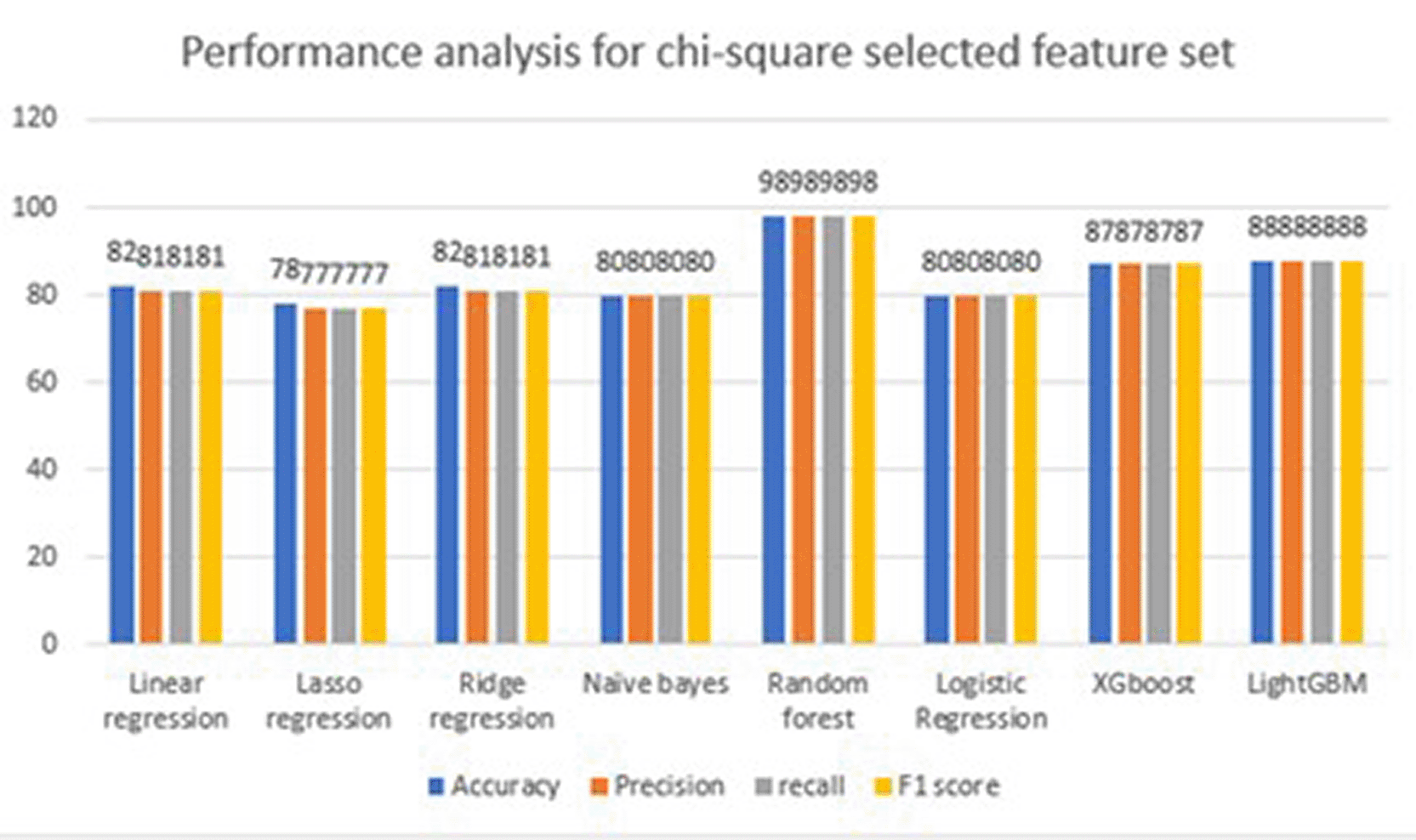
Another feature selection method called chi-square attribute evaluation is the arrangement of filters in the order of the computed chi-square statics29 of 10 features. It computes the score of all features with the target values and selects the top ten features. The attributes selected from the chi-square [ Table 5] by eliminating the last two features and training with chi-square-suggested features using machine learning algorithms.
This section provides an overview of the results obtained by using the proposed model. The implementation starts with a collection of datasets. We combined the two datasets21,22 to form 1303 patients. The details of the dataset consist of 13 features, including a target feature for healthy and unhealthy individuals, and are ideal for developing predictive models and analyzing heart disease. It includes categorical and numerical variables, such as sex, chest pain type, fasting blood glucose level, ECG findings, exercise-performed angina, and the slope of the peak exercise ST segment. Numerical features, such as age, resting systolic blood pressure, serum cholesterol, maximum achieved heart rate, and ST segment depression compared to rest, provide continuous data for fine-grained analysis.
The target attribute, initially quantified into five classes, was converted into a binary variable, making it easier to determine whether a person had heart disease. Considering these features, models are trained and evaluated, and this is performed by selecting three different sets of features from 13 features. First, all models are trained using the full 13 features; second, all models are trained using the features selected by the chi-square test. Finally, the models are trained using the features selected by the correlation. Had chosen the correlation 0.75 and 0.50 each other because 0.75 indicates a strong relationship between the features. On the other hand, 0.50, was moderately related to each other. This provides the highest and moderate features that help achieve higher accuracy.
The dataset employed for all cases is initially discussed, and the results for different cases are provided in the following subsections.
The instance of the employed dataset is obtained by combining the two datasets [ Figure 3], namely Cleveland, Hungary, Switzerland, and the VA Long Beach23 with 303 patient data and Cardiovascular Disease21 with 1000 patient data.
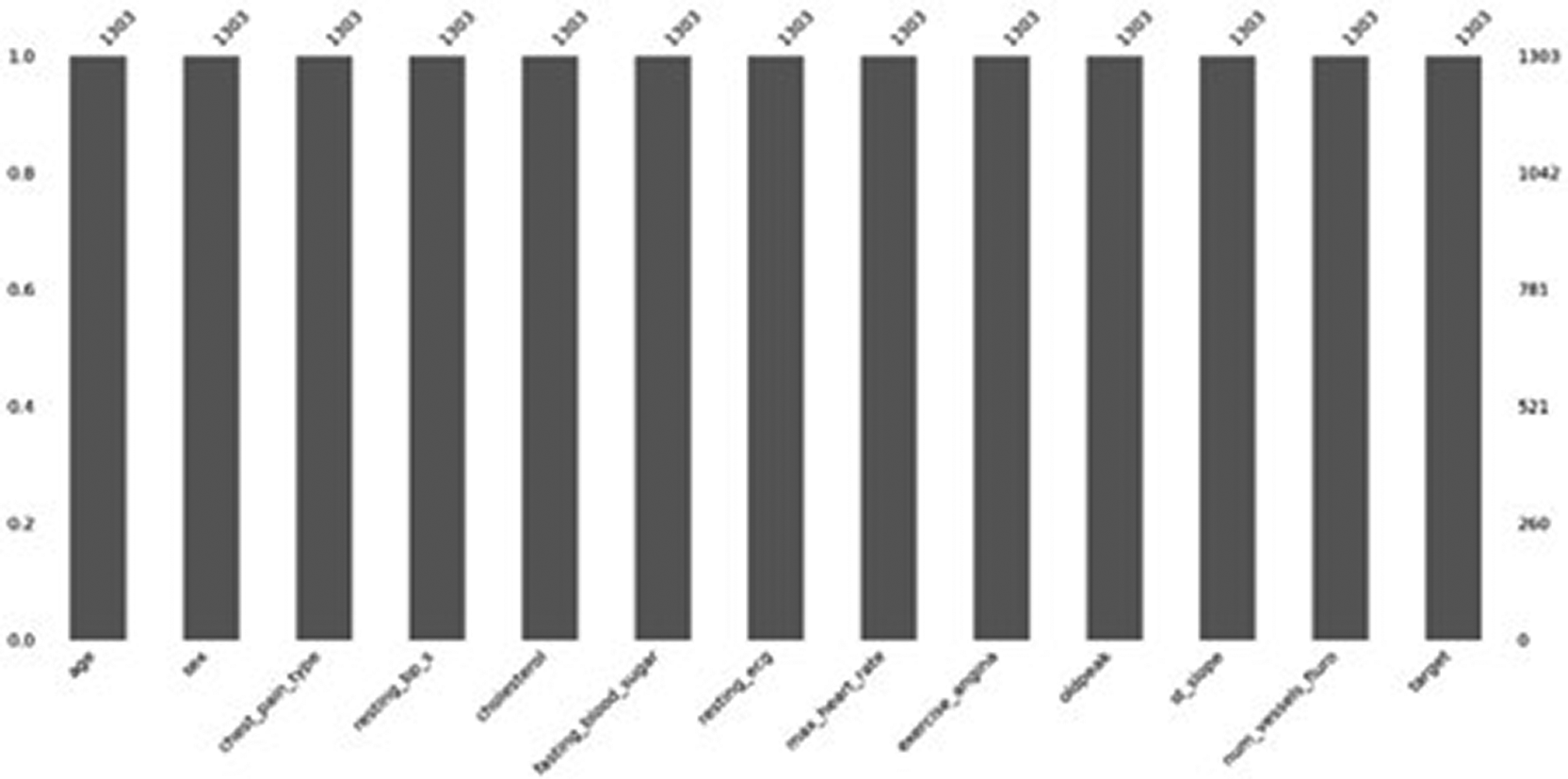
The dataset information [ Figure 4], which includes the total number of entries, number of features recorded per patient, data type, and count of NaN values (black, NA data, or missing values).

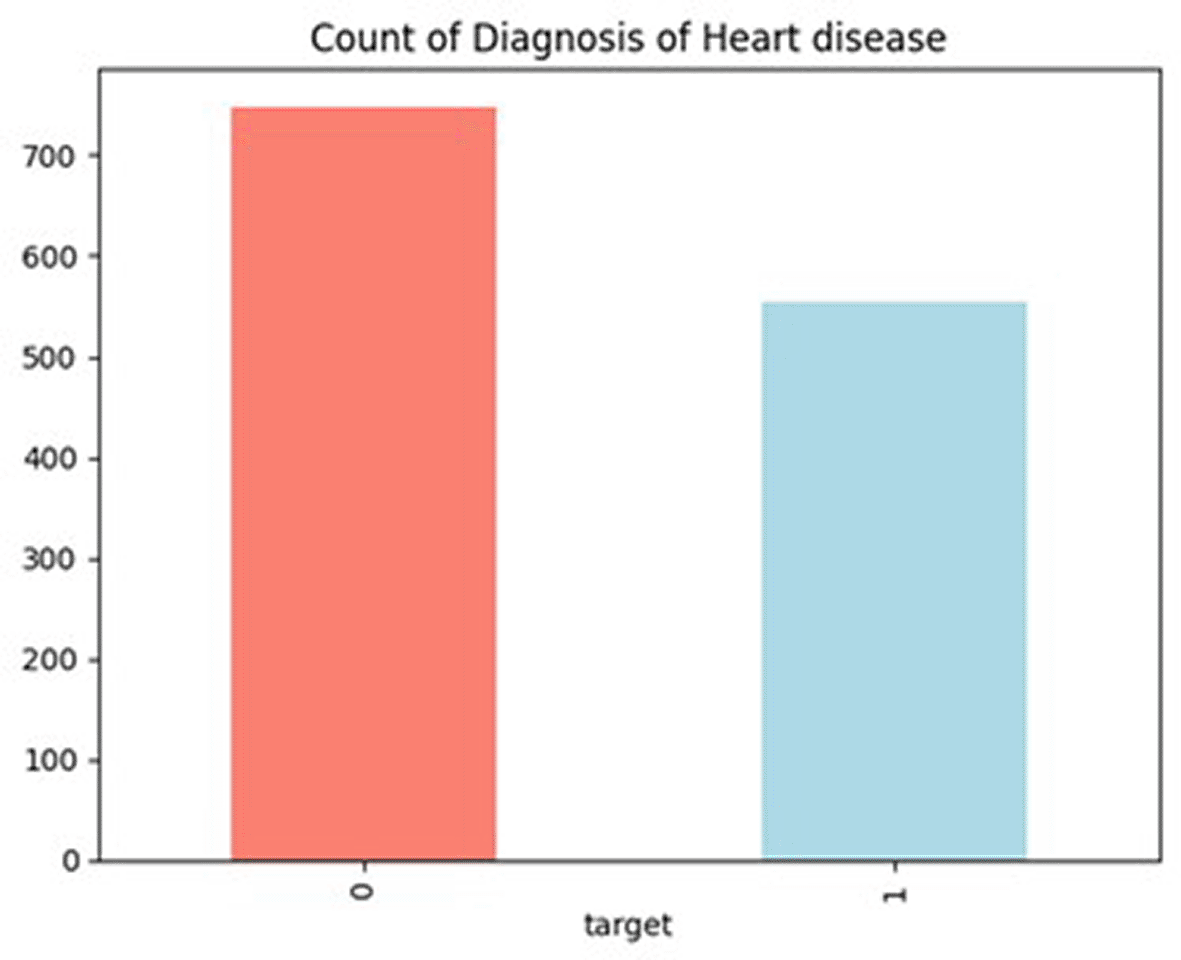
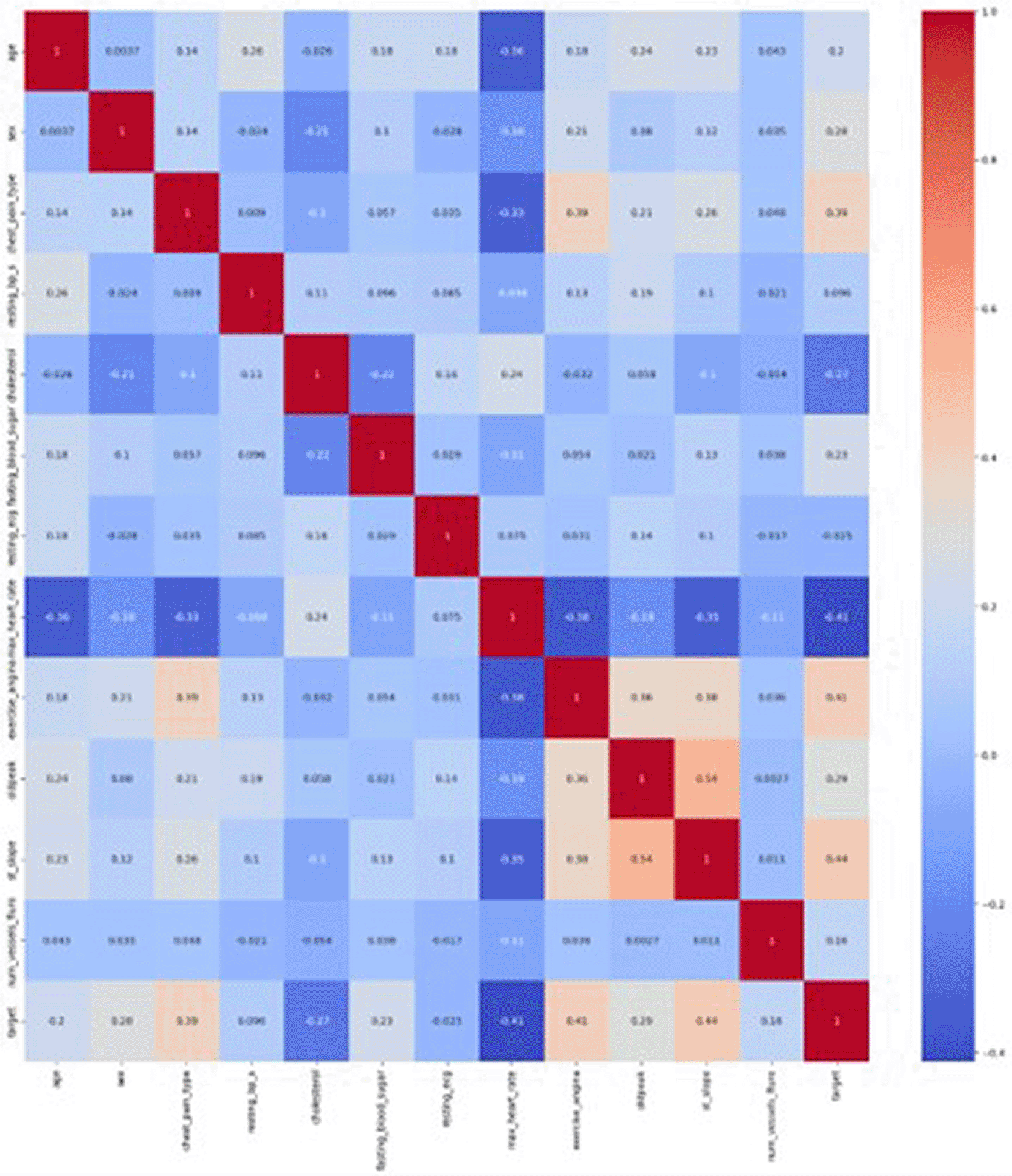
The distribution of healthy and unhealthy patients [ Figure 5] indicates that the dataset is imbalanced in nature. To address this, a few modifications are made to the XGboost algorithm, as stated in Section 3.3. To visualize missing values, a bar chart is plotted using msno, which provides data points for every column if missing values are present in any column gaps present in the bar charts. There is no discontinuity in the graph [ Figure 6], which clearly indicates that there are no missing values in any column, and the 1303 values indicate that all columns have 1303 entries in the dataset. The heat map [ Figure 7] for the dataset is computed, which gives Pearson correlation coefficients and denotes −1,+1, and 0 + 1, indicating that the value is highly correlated, −1 is a negative correlation, and 0 means no correlation between the target and features. The data [ Figure 8] for training and testing values. If 50% is shown, then the dataset is balanced.

The performance metrics are listed in Table 6, which includes the confusion matrix, accuracy, precision, recall, and F1 score for the different machine learning models employed. For the analysis in this section, we consider a full set of features. A full set of features means that all 13 features are considered for predicting the health of a patient. Eight machine-learning models have been considered for prediction. To determine the model’s performance, we considered metrics such as the accuracy, precision, recall, F1 score, and confusion matrix. Of these machine learning models, random forests outperformed in the detection of diseases. It achieved a high accuracy of 97.77 and rest metrics such as precision, recall, F1 score of 98.
In addition to the accuracy, the model achieved good values in other metrics, which shows that the model is robust to real-world data. In the confusion matrix, the predictions of True Positive (TP) and true negative (TN) were quite good; there were fewer than 12 and 9 patients that were misclassified as false positive and false negative, respectively. This indicates that the misclassification from the model was comparatively less. A graphical representation of the performance metrics considering the full feature set. Figure 9 shows the performance metrics in a visual chart format. This provides a clear view of which model provides greater accuracy in detecting the heart condition of a patient.
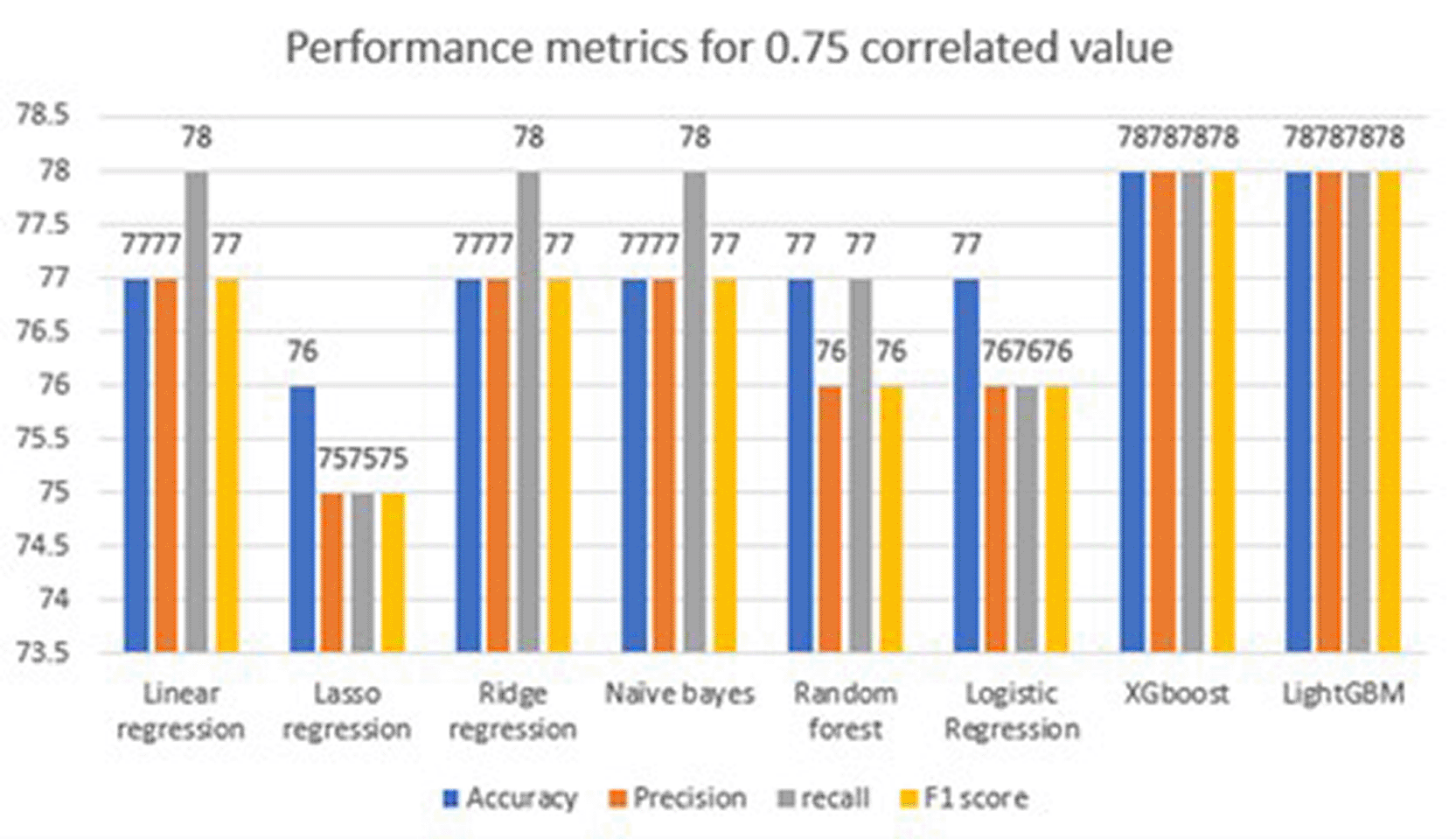
Performance metrics [ Table 7] by considering correlation of 0.75 and 0.50 and feature names are chest pain type, exercise angin and st_slope. It also includes the confusion matrix, accuracy, precision, recall, and F1 score for the different machine-learning models employed. The analysis in this section did not consider the full set of features. Instead of all features, 0.75 correlation features are selected. This means that out of 13 features, three correlated features were selected to predict the health of the heart. We considered eight machine learning models for prediction. To determine the model performance, we considered metrics such as the accuracy, precision, recall, F1 score, and confusion matrix. Of these machine learning models, LightGBM outperformed the others in the detection of diseases. It achieved a high accuracy of 77 and metrics, such as precision, recall, and F1 scores of 76, 77, and 76, respectively. As the number of features decreases, it becomes difficult for the model to learn. The accuracy of the model is lower because three features are considered to train the model. Similarly, in accordance with the accuracy, other metric values are also lower. The confusion matrix shows TP and TN values of 186 and 116, respectively, which are good, but not excellent, to adopt models for real-world patient analysis. False positives and negatives are 54 and 35, respectively, which give incorrect predictions. Due to the wrong prediction of healthy as unhealthy and unhealthy patients as healthy lands, the entire family is at risk. Unhealthy patients are left untreated, and healthy patients undergo unnecessary treatment and financial overhead. A graphical representation of the performance metrics considering the full feature set. The performance metrics [ Figure 10], making them easier to interpret than tables. This helps to highlight which model achieves higher accuracy in identifying heart conditions in patients.
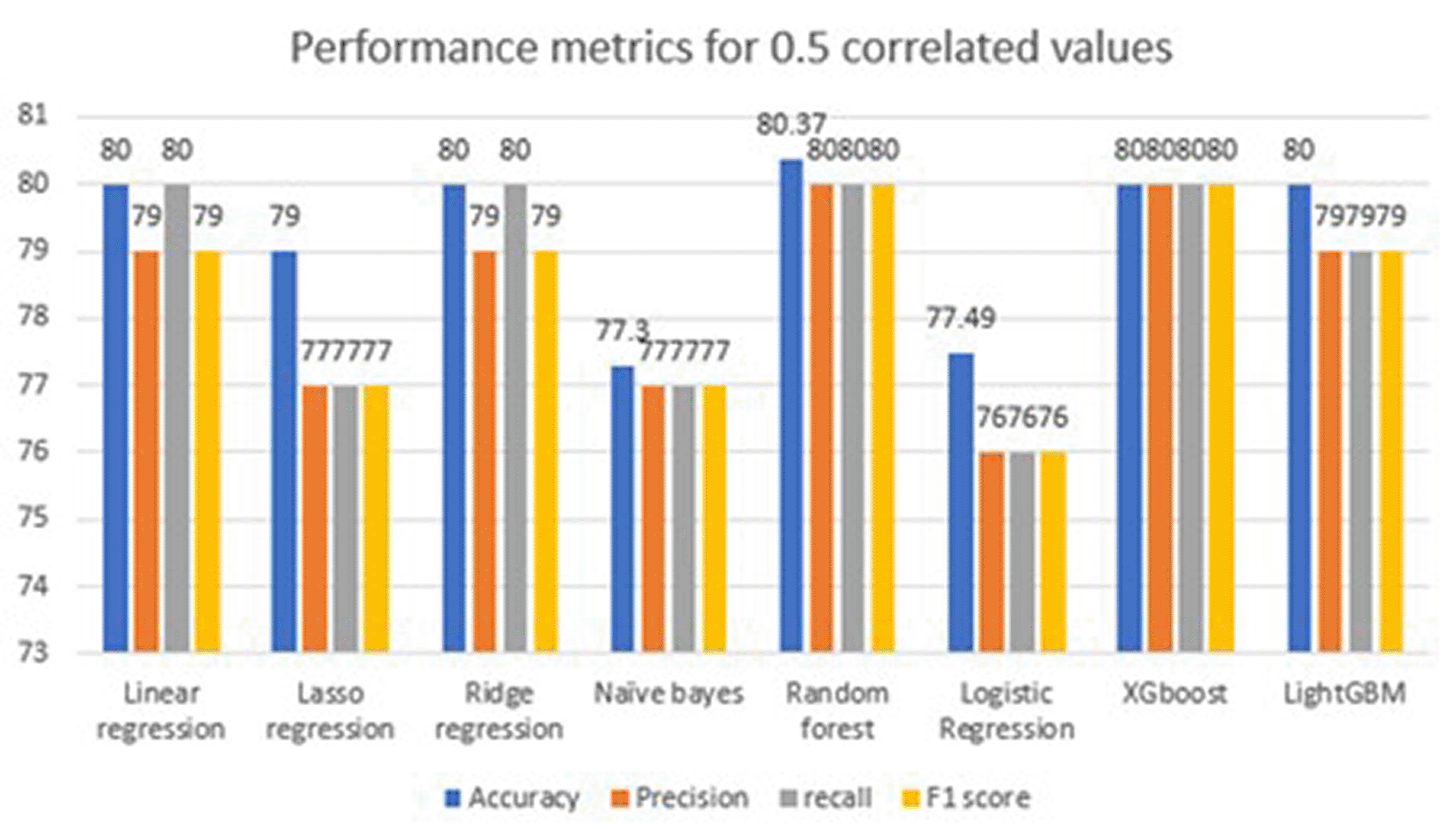
Performance metrics [ Table 8] by considering correlation of 0.75 and 0.50 and feature names are sex, chest pain, fasting blood sugar, exercise_angin and st_slope. The analysis in this section did not consider the full set of features. Instead of all the features, with 0. Five correlation features are selected. This means that out of 13 features, three correlated features were selected to predict the health of the heart. Eight machine-learning models have been considered for prediction. To determine the model’s performance, we considered metrics such as the accuracy, precision, recall, F1 score, and confusion matrix. Of these machine learning models, random forest outperformed in the detection of diseases. It achieved a high accuracy of 80.37, and other metrics, such as precision, recall, and F1 score, were 80. As the number of features decreases, it becomes difficult for the model to learn. The accuracy of the model is lower because three features are considered to train the model. In a similar fashion, in accordance with the accuracy, other metric values are also less. The confusion matrix shows TP and TN values of 103 and 76, respectively, which are good but not excellent for the adoption of models for real-world patient analysis. False positives and negatives are 103 and 76, respectively, which give incorrect predictions. Owing to incorrect predictions, there will be unnecessary overhead for the respective families. A graphical representation of the performance metrics considering the full feature set [ Figure 11] provides a good overview of an eagle’s eye view by observing line graphs.
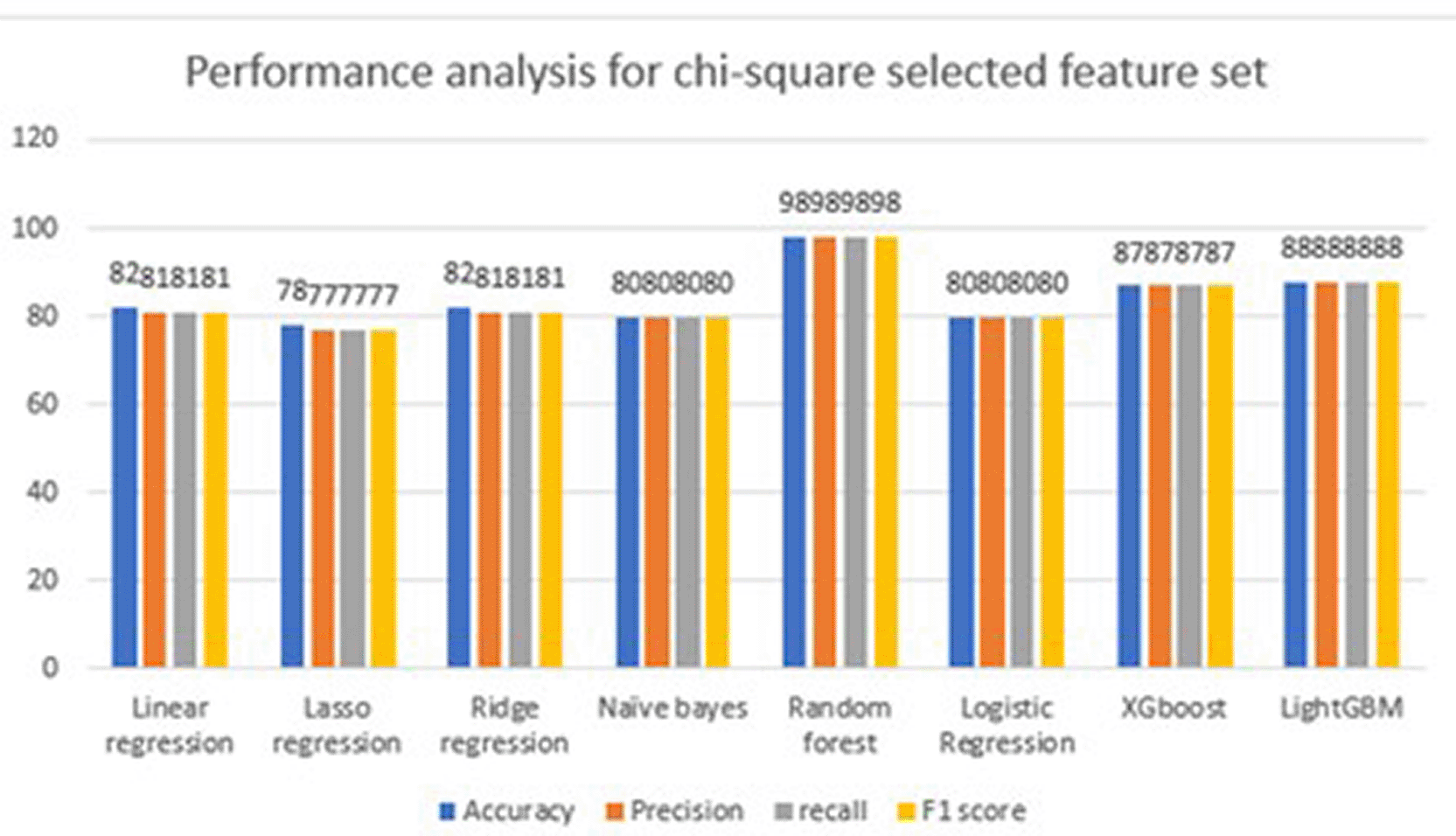
The performance metrics [ Table 9] using the chi-square feature matrix, and the feature names are age, chest pain, resting_bp, fasting blood sugar, max_heart_beat, exercise_angin, oldpeak, st_slope, and num_vessls_fluro. The analysis in this section did not consider the full set of features. Instead of all feature sets, we selected features using chi-square. This means that out of 13 features, nine features were selected to predict the health of the heart. Eight machine-learning models have been considered for prediction. To determine the model performance, metrics such as accuracy, precision, recall, F1 score, and confusion matrix were used. Of these machine learning models, random forest outperformed in the detection of diseases. It achieved a high accuracy of 98 and other metrics, such as precision, recall, and F1 score of 98. The selected features are robust and efficient, facilitating efficient detection. In addition to accuracy, precision, recall, f1 score and confusion matrix were used to measure the efficiency of the model. The confusion matrix shows TP and TN values of 495 and 396, respectively, which are good, but not excellent, to adopt models for real-world patient analysis. False positives and negatives are 13 and 8, respectively, which give incorrect predictions. There are a few numbers of wrong predictions, which help in providing excellent results in detecting the health of a patient’s heart. A graphical representation [ Figure 12] of the performance metrics considering the full feature set. A clearer view can be seen in the chart compared to the table, which makes it easier to understand which model’s performance is better than the other seven machine-learning models.
In printed volumes, illustrations are generally black and white (halftones), and only in exceptional cases, and if the author is prepared to cover the extra cost for color reproduction, are color pictures accepted. If color illustrations are necessary, please send color-separated files if possible. Color pictures are welcomed in the electronic version at no additional cost. The current study utilized two datasets, which were combined by leaving the data from the Cleveland dataset and combined with the CVD dataset to make 1303 patients to predict CVD risk. With all feature sets, the maximum accuracy achieved was 97.77% the random forest algorithm. Not only is accuracy considered, other performance metrics such as f1 score (98%), recall (98%), precision (98%) models are considered as models that provide robustness in detection. The feature selection processes considered were correlation-based and Chi-square-based feature selection. Results analysis showed that the chi-square selected features list achieved a high accuracy, precision, f1 score and recall. Highest accuracy achieved compared to full feature set the chi-square feature selection method was 98%.
The current study focuses on feature selection and evaluation of machine learning models to find robust models for predicting CVD risk earlier. The employed datasets were Cleveland, Hungary, Switzerland, and the VA Long Beach21 with 303 patient data and cardiovascular disease20 with 1000 patient data. These two datasets were combined to form data from 1303 patients by ignoring that feature from Cleveland, as it is not present in the cardiovascular disease dataset. Three types of feature selection mechanisms were adopted: correlation-based, with correlated values of 0.75, 0.5, and chi-square. Of these feature selection methods, the chi-square-based feature list achieved good accuracy. Excellent performance is achieved by a random forest algorithm in predicting CVD using features selected by chi-square. The highest accuracy of 98% was achieved performed by the random forest classifier. The current research covers six machine learning models and two regression models, and eight machine learning models were trained and evaluated on features selected by three feature selection methods. In the future, one can apply deep learning models can be applied to increase the accuracy of the model and to adopt more feature selection methods and models to predict CVD at earlier stages.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (1)