Keywords
Cascade system, Inverse Chen distribution, Maximum likelihood method, Shrinkage technique, Least Square estimation method, Weighted Least Square, Mean Squared criteria
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
Cascade system, Inverse Chen distribution, Maximum likelihood method, Shrinkage technique, Least Square estimation method, Weighted Least Square, Mean Squared criteria
A cascaded model in machine learning refers to a system where multiple models are sequentially arranged, with the output of one model serving as the input for the next. This approach leverages the strengths of various models to improve overall performance, particularly in complex tasks like image generation or named item recognition. The cascaded model has numerous practical uses, such as the localization of different diseases from chest X-ray images.1
Stress-strength reliability estimation assesses the likelihood that a system’s strength (its resistance to failure) surpasses the stress it endures. This is frequently represented as , where denotes strength and signifies stress. This notion is essential in multiple domains such as engineering, quality control, and economics, facilitating the evaluation of a system’s probability of success or failure under specified conditions.2–11 A large number of academics are studying stress-strength reliability to estimate the parameters of probability distributions. In 2021, the reliability of the type stress-strength for all Exponentiated Inverted Weibull, Lomax, Polo, and Gompertz Fréchet distributions was discussed.2–5 In 2022 and 2023, the considering reliability was developed by Refs. 6–11 for Generalised Exponential-Poisson, Power Rayleigh, and Inverse Chen distributions, respectively.
The Cascade Reliability model is a specific variant of the Strength-Stress model that addresses a certain (2+1) cascade configuration, featuring components and in operation, while component is designated as a standby element. Let and represent the strength of components and , respectively, while and denote the equivalent stress responses. If any component is active, it signifies a failure; let component C be active, with representing its strength and denoting the load applied to it. When and where and .12
A multitude of academics are investigating the Cascade Reliability model; Mutkekar and Munoli (2016) investigated a (1+1) cascade model related to the exponential distribution, focusing on reliability function estimators utilizing the Maximum Likelihood Estimator (ML) to estimate the parameters, addition that the UMVUE which is the Uniformly Minimum Variance Unbiased Estimator. They concluded that the UMVUE outperformed the ML.13 In 2018, Nada and Ahmed assessed the robustness of a specific stress-strength for (2+1) cascade mode with respect to Weibull distribution, characterized by unknown scale parameters when the shape parameter is known. Four distinct approaches were employed to assess reliability, with ML identified as the superior estimator.14 In 2019, they examined the reliability cascade (2+1) utilizing the Generalized Inverse Rayleigh and Inverse Weibull distributions, respectively. Through various methodologies, they demonstrated that Maximum Likelihood Estimation is the superior estimation approach.15,16 In 2021, the reliability was estimated for each of (1+1) and (2+2).17–19 In 2022, and 2025, (3+1) Cascade models for different distributions were derived, respectively.20,21
This paper aims to analyze and estimate the reliability of the (2+1) cascade Stress-Strength model, where both Stress and Strength adhere to the Inverse Chen distribution with unknown shape parameters , and a known parameter . Various methodologies will be employed, including Maximum Likelihood Estimation (ML), shrinkage estimation with shrinkage Weight Factor estimators ( ) and trigonometric shrinkage weight function ( ), least square estimation (LS), and weighted least square estimation (WLS). A comparative analysis of these five methods are conducted using the mean squared error criterion, derived from simulation studies, to evaluate the estimation results across the different methodologies based on MSE.
The Inverse Chen distribution is a versatile tool for modeling non-monotonic hazard functions and positively skewed data. It is well-suited for time-to-failure data in industrial operations, biomedical research, and engineering systems. The distribution can handle light-tailed and heavy-tailed phenomena due to its shape and scale parameters. Its strong right-skewness and leptokurtic features make it a strong substitute for traditional models. The Inverse Chen distribution has been used in real-world applications, such as stress-strength reliability under Bayesian frameworks, survival probability in medical research, and simulation of electronic components in geological and environmental research. Its empirical adaptability and theoretical stability make it a valuable addition to lifetime distributions.22–25
The Inverse Chen distribution is a two-parameter continuous probability distribution designed to model asymmetric lifetime data, especially in reliability analysis. Inverse Chen distribution with two parameters shape parameter and scale parameter.22,23,25 The Probability Density Function (PDF) in Eq. (1) and Eq. (3) for and , respectively. And the Cumulative Distribution Function (CDF) in Eq. (2) and Eq. (4) for and , respectively. The Inverse Chen distribution, which is a different version of the original Chen distribution introduced by Chen (2000), is used to describe lifetime data with hazard rates that go up over time. It can handle a wide range of danger shapes and is statistically defined on the positive real line. The distribution is good for modelling data that isn’t symmetric, like failure times, stress-strength reliability, and other types of data. It has been utilized in reliability engineering, biomedical research, stress-strength modelling, and geological and environmental studies. It can handle skewed and heavy-tailed data in a lot of different ways.22,23,25
The Cascade Reliability model is a particular form of the Strength-Stress model that pertains to a certain (2+1) cascade arrangement, incorporating components and , in operation, while component C serves as a standby element. If any component is active, it indicates a failure; let component C be active, with reflecting its strength and denoting the force exerted on it. When and where and .12
Let and be independent and identical random variables that are distributed Inverse Chen with unknown shape parameters and , and a known value λ = 3, such that ( and ), let indicate the strength with parameters , and refer to stress with parameters , then the probability density functions are and cumulative distribution functions are respectively9;
The (2+1) cascade model’s reliability function is provided by.13,14
Upon resolving the equation, obtain:
In compensating Eqs. (8) and (9) within Eq. (12), is getting as follows:
Substitution Eqs. (6), (10) and (11) in Eq. (5) says,
2.3.1 Maximum Likelihood Estimator (MLE)
Let for represent a strength random sample drawn from an IC ( , λ) distribution with sample size , where is an unknown shape parameter, and λ is a known parameter.
By taking the logarithm of the likelihood function ; . Next, derive L by , and the results equal zero. The maximum likelihood estimator for ( ) is obtained, which serves as the joint probability function, and has the following general form9:
Let and strength random sample from IC( IC( IC( with sample size respectively:
For the stress random variable, let and stress random sample from IC( IC( IC( with sample size respectively; the ML estimator for the unknown parameter is as
By substituting and in Eq. (12), then the estimation reliability of via the MLE can be summarized as follows:
2.3.2 Shrinkage Estimation Method
Let a classical shrinking estimator of the parameter α be into a prior guess α0 through the reduction weighting factor k( ) where 0 ≤ k( ) ≤1. Suppose that is too close to the genuine value of α. Accordingly, the procedure of the shrinkage estimator introduced by Thompson9:
2.3.2.1 The Shrinking Weight Factor Estimators (sh1)
The shrinkage weight factor is proposed as a function of sample sizes and ; respectively, which is assumed as the following formula.
i.e. = , = , such that , and this indicates in the resulting shrinkage estimators:
By substituting Eqs. (18) and (19) into Eq. (12), the reliability estimation can be derived approximately as follows:
2.3.2.2 The Trigonometric Shrinkage Weight Function (sh2)
= and = , that , implies the following shrinkage estimators:
Substituting Eqs. (21) and (22) into Eq. (12), the reliability estimation with the Trigonometric Shrinkage Weight Function estimator can be articulated approximately as follows:
2.3.3 Least Square Estimation Methods (LS)
The method of Least Square estimates the parameter by minimizing the Eq.14,16
Such that equivalent to plotting position ; . Let’s follow
After deriving Eq. (24) and equating the result to zero, get ;
The Least Square estimator and , where and
Substituting Eqs. (25) and (26) into Eq. (12), the reliability estimation obtained approximately by the least square approach is as follows:
2.3.4 Weighted Least Square Estimation Method (WLS)
The method of weighted least square estimators for the Inverse Chen distribution can be employed by minimizing the following equation:
From Eq. (24), it can be obtained:
By deriving (28) and make the result equal to zero, one can obtain the Weighted Least Square estimator and , where ;
Substituting Eqs. (29) and (30) into Eq. (12), the reliability estimation obtained approximately by the weighted least squares method is as follows:
The behaviour of estimated can be studied via a simulation approach using different methods. A statistical criterion has been employed for comparison of the results, MSE (mean squared error) that follows the formula:
The simulation analysis is done after repeated (1000) times to get independent different sizes samples.26
2.4.1 Random Sample Generated for Inverse Chen Distribution
Assume that a random variable U with a standard uniform distribution, IC data can be generated by the adoption of CDF inverse transformation, wherein if:
Then
2.4.2 Simulation analysis
The simulation program is developed using MATLAB 2023b software to facilitate the comparison of reliability estimators, which may be outlined by the following steps:
Step 1: Select random samples , and of sizes ( ) which represents a, b, c and d where a = (25,25,25,25), b = (50,50,50,50), c = (75,75,75,75) and d = (100,100,100,100) respectively, that are generated from Inverse Chen Distribution.
Step 2: Calculate the into Eq. (12) estimation value of all suggestion methods in Eqs. (16), (20), (23), (27), and (31), correspondingly. The real parameter values are selected for 4 experiments ( ) in Table 1.
| Exp. | ||||||
|---|---|---|---|---|---|---|
| 1 | 0.1 | 3 | 2 | 2 | 3 | 3 |
| 2 | 0.1 | 3 | 3 | 2 | 2 | 3 |
| 3 | 0.4 | 2 | 2 | 3 | 3 | 2 |
| 4 | 0.4 | 2 | 3 | 3 | 3 | 3 |
Step 3: Calculate the MSE for all proposed estimators using =1000 duplicates.
Step 4: Compare the simulation results; the best estimation method for the reliability is the one that estimates R with the smallest MSE value.
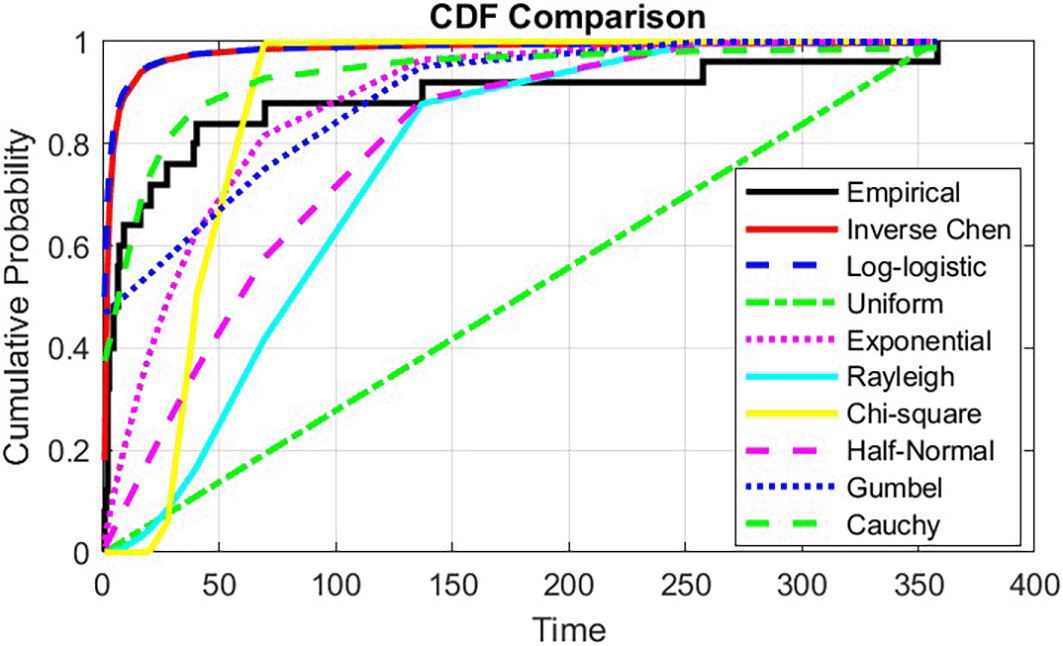
An analysis based on a real dataset is carried out in this section. According to,27 the application consists of 25 observations that show the size distribution of diamonds taken from a significant mining zone in South-West Africa. The diamond sizes, however, are as follows: 7.5, 7, 2.5, 4.5, 2, 2, 3, 2, 1, 1.5, 5, 7, 3, 1, and 2, 39, 358, 257.5, 137, 69.5, 40.5, 28, 20.5, 16.5, and 9. The information used in this application of diamonds with a sample size of 25 came from.27 To demonstrate that the inverse Chen distribution appears to be a more competitive model for these data than the Log-logistic, Uniform, exponential, Rayleigh, Chi-Square Half-Normal, Gumbel and Cauchy distributions. Table 6 is a descriptive statistics table that is telling us about the dataset of 25 observations of diamonds taken.
Four experiments have been done by the simulation technique in the current study. The discretion for the mentioned experiments is in Table 1.
Experiment 1 is shown in Table 2, which displays the values of the and MSE when .
Likewise, Experiment 2 is displayed in Table 3, which displays the values of the and MSE when . As well, Experiment 3 is shown in Table 4, which displays the values of the and MSE when . Finally, Experiment 4 appears in Table 5, which displays the values of the and MSE when .
While Table 6 shows the Chen distribution’s descriptive statistics for the application of diamonds with a sample size of 25. Where the mean (47.3) is much higher than the median (5), which means that the dataset is positively skewed (a few very large values are pushing the average up). The mode (2) and Q1 (2) show that small values happen a lot. The dataset is very spread out because the standard deviation (90.6) and variance (8208.6) are both very high. The IQR (26) shows that most of the data is fairly close together (between 2 and 28), but the extreme maximum (358) makes a big range.
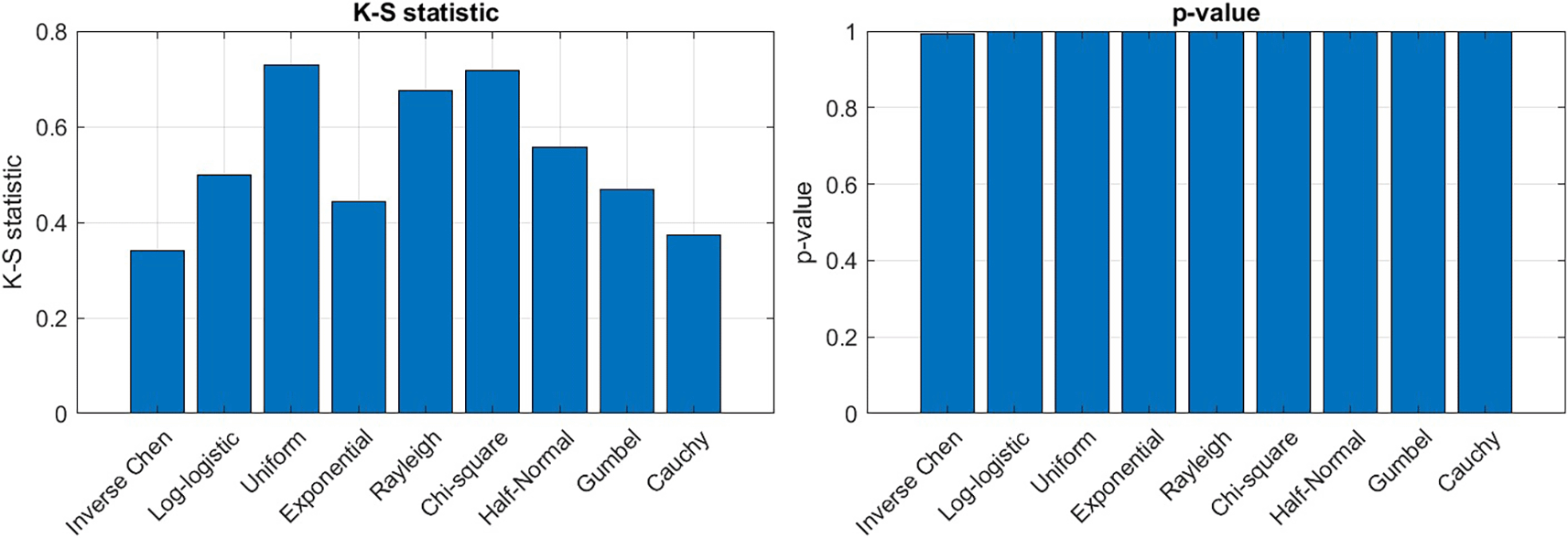
To ascertain the suitability of the inverse Chen distribution as a model for the dataset, the Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC), and Kolmogorov-Smirnov (K-S) distance, along with P-values, are employed, in addition to comparing the cumulative distribution function (CDF) of the specified distribution with the empirical CDF. Table 7 indicates that the Inverse Chen distribution has lower values for both AIC and BIC. This indicates that the Inverse Chen distribution may be the best fit for the dataset.
The empirical and calculated cumulative distribution functions of Inverse Chen and other particular distributions (Log-logistic, Uniform, exponential, Rayleigh, Chi-Square Half-Normal, Gumbel and Cauchy distributions), along with the histograms of the K-S statistic and P-value, are illustrated in Figures 1 and 2.
Based on the simulation technique, we draw the following results:
4.1.1 Within estimation method
For the maximum likelihood estimation (MLE): the mean squared error (MSE) is lower in sample size b and higher in sample size a. Generally, the MSE decreases from sample size a to b and thereafter increases from b to d.
➢ For sh1: lower mean squared error (MSE) is observed in sample size a, whereas higher MSE is noted in d. Generally, MSE increases from a to d.
➢ For sh2: lower mean squared error (MSE) is observed in d, whereas higher MSE is noted in a. Generally, MSE decreases with an increasing sample size from a to d.
➢ For LS: lower mean squared error (MSE) is observed in a, while higher MSE is noted in d. Generally, MSE decreases with an increasing sample size from a to d.
➢ For WLS: The mean squared error (MSE) is lower in a and higher in c. Generally, MSE increases with sample size from a to c and subsequently decreases from c to d.
➢ It is shown that 60% of sample size an achieves the lowest mean squared error, while 20% applies to b and d, respectively.
4.1.2 Between estimation techniques
The estimate technique sh2 exhibits the lowest mean squared error (MSE), indicating it is superior to the others. sh1 ranks second across all sample sizes, while the ranks of LS, WLS, and MLE fluctuate between third and fifth, depending on the sample size.
4.2.1 Within estimating technique
For the maximum likelihood estimation (MLE): the mean squared error (MSE) is lower for sample size b and higher for sample size c. Generally, the MSE decreases from sample size a to b and thereafter decreases from c to d.
➢ For sh1: For sample size a, the mean squared error (MSE) is lower, but for sample size d, the MSE is higher. Generally, the MSE increases as the sample size is augmented from a to d.
➢ For sh2: lower mean squared error (MSE) is observed in b, whereas higher MSE is noted in c. Generally, MSE decreases with increasing sample size from a to b and then increases; also, MSE decreases with the transition from c to d.
➢ For LS: The mean squared error (MSE) is lower in condition c and higher in condition b. Generally, MSE increases with larger sample sizes from a to b, and likewise rises from c to d.
➢ For WLS: The mean squared error (MSE) is lower in region D and higher in region B. Generally, MSE increases with sample size from a to b, whereas it decreases from c to d.
➢ It is indicated that 20% of sample sizes a, c, and d respectively meet the minimum mean squared error, whereas 40% pertains to sample size b.
4.2.2 Comparison of estimate methodologies
The estimate technique sh2 exhibits the lowest mean squared error (MSE), indicating it is superior to the others. sh1 ranks second across all sample sizes, while the ranks of LS, WLS, and MLE fluctuate between third and fifth, depending on the sample size.
4.3.1 Internal estimation method
For the maximum likelihood estimation (MLE): the mean squared error (MSE) is lower in sample size b and higher in sample size d. Generally, the MSE decreases from sample size a to b and thereafter increases from b to d.
➢ For sh1: lower mean squared error (MSE) is observed with sample size a, but higher MSE is noted with sample size d. Generally, the mean squared error (MSE) increases with the augmentation in sample size from a to d.
➢ For sh2: lower mean squared error (MSE) is acceptable in b, but higher MSE is acceptable in a. Generally, the mean squared error (MSE) diminishes as the sample size increases from a to b, while the MSE escalates as it increases from b to d.
➢ For LS: lower mean squared error (MSE) is acceptable in b, but higher MSE is acceptable in c. Generally, the mean squared error (MSE) diminishes as the sample size increases from a to b, and similarly, the MSE decreases as it increases from c to d.
➢ The mean squared error (MSE) is lower in sample set a compared to sample set b, but MSE increases from sample set c to sample set d. Generally, MSE rises with an increase in sample size from a to b.
➢ It is shown that 40% of sample size an achieves the minimum mean squared error, 40% for b, and 20% for c.
4.3.2 Comparison of estimate methodologies
The estimate technique sh2 exhibits the lowest mean squared error (MSE), indicating it is superior to the others. Subsequently, sh1 ranks second throughout all sample sizes, while the ranks of LS, WLS, and MLE fluctuate between third and fifth, depending on the sample size.
4.4.1 Within estimation method
For the maximum likelihood estimation (MLE): the mean squared error (MSE) is lower in sample size b and higher in sample size d. Generally, the MSE decreases from sample size a to b and thereafter increases from b to d.
➢ For sh1: For sample size a, the mean squared error (MSE) is lower, whereas for sample size d, the MSE is higher. Generally, the MSE increases as the sample size progresses from a to d.
➢ For sh2: lower MSE is observed in b, whereas higher MSE is noted in d. Generally, MSE decreases with an increasing sample size from a to b, and conversely, MSE increases from b to d.
➢ For LS: lower mean squared error (MSE) is acceptable in a, while higher MSE is acceptable in d. Generally, the mean squared error (MSE) increases with an expanding sample size from a to b, as well as from c to d.
➢ For WLS: The mean squared error (MSE) is lower in region d and higher in region b. Generally, MSE increases with larger sample sizes from a to b, and also rises from c to d.
➢ It is indicated that 40% of sample sizes a and b achieve the minimum mean squared error, while 20% pertains to d.
4.4.2 Between estimation methodologies
The estimate technique sh2 exhibits the lowest mean squared error, indicating it is superior to the others. Following sh2, sh1 ranks second across all sample sizes, while maximum likelihood estimation (MLE) ranks third, least squares (LS) ranks fourth, and weighted least squares (WLS) ranks fifth. Consequently, we assert that the trigonometric shrinkage estimation approach outperformed the other presented estimation methods according to the minimal mean squared error criterion.
In this research, the Cascaded model is used. In statistics, Cascaded models are essential for decomposing complex issues, enhancing precision, and guaranteeing resilience. They are extensively used in data science, machine learning, and reliability research. Cascaded model is applied to the proposed distribution (the inverse Chen distribution) because of the importance of it in statistical model for reliability research, lifetime data modeling, and stress-strength studies particularly when working with asymmetric or complex data. Several methods to estimate reliability are utilized, and then the Monte Carlo simulation method is employed to compare the reliability estimated by these methods via the Mean Square Error (MSE). Four cases are used for different sample sizes, and it is found that the shrinkage method is the best estimated method. Then some real data about diamonds are applied to the proposed distribution and compared the fit of the proposed distribution to the real data with the other distributions mentioned.
The proposed distribution is the best fit via the fit criteria; the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC), the Inverse Chen distribution has lower values for both criterion and it is the most appropriate. This suggests that the dataset could be best suited for the Inverse Chen distribution.
Without the use of AI technology, the authors independently produced all scientific components of this study, including statistical and mathematical derivations, statistical analyses, and findings. In compliance with open scientific and academic publishing standards, the Microsoft Copilot (October 2025 edition) was only used to improve language clarity, formatting, and structural organization.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)