Keywords
Functional data analysis, Functional median polish, fourier basis, Functional ANOVA, R programming
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
Functional data analysis, Functional median polish, fourier basis, Functional ANOVA, R programming
We sincerely appreciate your interest in our manuscript entitled “Robust Functional Data Analysis of Dollar Exchange Rates Using Functional Median Polish.” In preparing the revised version of this study, we made a substantial effort to improve the clarity, structure, and methodological presentation of the paper so that its contribution can be communicated more effectively to the scholarly community.
In the revised manuscript, we clarified the main objective of the study and emphasized that the work is intended as a robust exploratory functional analysis of exchange-rate data rather than a purely predictive exercise. We improved the presentation of the methodological framework by providing a clearer description of the functional representation of the monthly exchange-rate series, the role of the Fourier basis expansion, and the application of one-way and two-way Functional Median Polish procedures.
We also strengthened the interpretation of the empirical findings. The revised text now explains more clearly that the estimated functional center captures the dominant pattern of the exchange-rate series, while the annual and monthly effects remain limited and statistically weak. In addition, the discussion of FANOVA results and residual diagnostics has been refined to make the analytical conclusions more transparent and easier to follow.
Finally, we improved the conclusion by stating the practical implications of the study more explicitly, while also acknowledging its main limitations and suggesting several directions for future research. We hope that these revisions have enhanced the quality and readability of the manuscript and that the study will provide useful value for researchers interested in robust functional data analysis and exchange-rate modeling.
See the authors' detailed response to the review by Cristina Anton
See the authors' detailed response to the review by Kun Huang
Data analysis based mainly on exploratory approach have used robust methods for finding hidden patterns in complex data because parametric techniques do not suffice because of outliers or nonlinear structure. Median polish is a powerful exploratory method for the decomposition of 2-way tables to additive components that was developed by Tukey (1977).1 The entire effect, row effects, column effects, and residuals are estimated using medians rather than means, which decreases the sensitivity to extreme observations.
In its classical usage the method corresponds to an additive model where each cell is defined as the total of a grand effect, a row effect, a column effect and a residual term. It fits a model using an additive approach:
In model (1), denotes the overall effect, denotes the effect of row , denotes the effect of column , and denotes the residual term. For identifiability under the robust median-based formulation, the effects are defined subject to the constraints and . The model is estimated iteratively by subtracting row and column medians until the effects stabilize. This iterative median-based updating yields a robust additive decomposition that is less sensitive to anomalous observations than mean-based alternatives. Regarding this respect, Velleman and Hoaglin (1981) bridged theoretical concepts in exploratory data analysis with concrete computer-based applications.2 Emerson and Hoaglin (1983) along with Hoaglin, Mosteller, and Tukey (1983) afterwards have shown practical examples of median polish to its practical advantage.3,4 Fink (1988) introduced significantly stronger statistical treatment of this approach based on its limitations and convergence properties to further enhance the theoretical grounds of this powerful exploratory methodology.5
Functional data analysis (FDA) is an intuitive approach to the analysis of data seen along an analytic continuum (over time, space, or frequency). Instead of the repeated measurements from the FDA data being treated as simply isolated scalar observations, FDA portrays them as “smooth functional objects” that can be used to study continuous processes more effectively. Ramsay and Silverman (2005) laid down a basis for FDA, where the curves are taken as the basic observational units.6 This development in the FDA is particularly appropriate for economic, environmental, and healthcare information. Furthermore, functional depth evaluations—such as those by López-Pintado and Romo (2009)—helped improve the robustness of functional ordering and further facilitate identification centrality, as well as points at which outliers could be considered outlier on curves given samples.7 Sun and Genton (2012) extended Tukey’s median polish into the functional setting and also came up with the Functional Median Polish (FMP) method.8 This framework replaces every cell of a two-way table by a function, so that the additive decomposition is then done pointwise, based on functional medians. This makes FMP particularly applicable for time series data where seasonality and interannual structure are coupled. Similar advancements in Functional ANOVA (FANOVA), i.e., Bayesian formulations by Kaufman and Sain9 and later also by Sain10 extended the range of functional inference, integrating uncertainty into functional comparisons. Furthermore, modified functional boxplots were suggested for spatiotemporal visualization and outlier detection.11
Apart from methodological improvement, a few applied studies have demonstrated the flexibility of median polish and other related robust methods. As an example, Fitrianto et al. (2014) used median polish to analyze educational data.12 Ajoge et al. (2016) extended the Tukey’s original framework from Tukey by introducing covariates and making it applicable for both before-and-after studies.13 Hussein et al. (2017), expanded Tukey’s resistant line framework with a moving average method for smoothing and robustness enhancement.14 More recently, Jimenez et al.15–18 showcased the applicability of FDA- and FMP-related methods in real-world scenarios with subnational mortality and density-valued economic scales, suggesting their applicability in current high-dimensional environments.
Traditional decomposition, smoothing, or mean-based functional algorithms constitute the majority of the available studies on monthly exchange-rate series. While these approaches are relevant in all these settings, they can be sensitive to anomalies and, consequently, do not have the strength in being a unified framework, being made up of smooth functional representation and the robust additive decomposition and inferential analysis by the Functional ANOVA (FANOVA). Moreover, practical guidance remains scarce on when Functional Median Polish (FMP) represents a suitable exploratory description. Therefore this work will contribute to developing a robust functional framework to analyze monthly exchange rate series, based on Fourier-based functional representing and Functional Median Polish. The central issue is structural decomposition rather than forecasting. More specifically, the work evaluates whether a proper functional additive representation can offer interpretable understanding of yearly and monthly effects that fail to be modeled by classical time series. Towards the same goal one-way and two-way Functional Median Polish is used to determine the complete center, row effects, column effects and residual functions, and the final elements are tested by FANOVA. A practical algorithm for median polish.
The median polish technique for univariate data operates on data arranged in a two-way table by sweeping out row and column medians. The output consists of the estimates of model (1). Each cell in the table is subject to the same overall effect , together with row effects and column effects .
The estimation of the grand, row, and column effects using medians is performed through an iterative procedure applied to the data table, which undergoes a series of row and column sweeping operations. The process continues until there are no further changes in its effects, or until the changes are small enough. The overall impact of a row or column sweep may depend on which one is applied first. Nevertheless, there is usually no compelling reason to prefer one order over the other, and the difference is typically not substantial in most practical applications. In what follows, the functional median polish procedure begins with the row sweep.
The median polish technique for univariate data works by operating on data in two-way table by sweeping out row and column medians. A list of the model’s (1) estimates makes up the outcome. The table’s cells are all subject to the same overall effect , plus row effects and column effects .
The approach for determining grand, row, and column effects using medians is iterative on data table, which undergoes a series of row and column sweeping operations. The process continues until there are no further changes in its effects, or until the changes are small enough. The overall impact of a row or column sweep might depend on which one begins first. Nevertheless, there is frequently no rhyme or reason to the order, and the distinction between the two options is typically not significant for most practical applications. We discuss functional median polish as follows: the method begins with the row sweep.
Assume that the interest lies in examining functional data across the levels of one categorical factor, referred to here as the functional row effect. The one-way functional median polish model is written as follows:
Where, : observed function for year , : functional overall effect, : functional row effect, : functional residual and the number of rows and is the number , that and for all k.
To fit this model by medians, we suggest the following algorithm:
1. Write the functional value on the row’s side after calculating each row’s functional median. From each function in that specific row, subtract the row functional median.
2. Determine the functional median of all the available data, then note the result as the functional grand effect. Record the data as the functional row impact after deducting this functional grand effect from each row’s functional median.
3. Until the row functional medians remain unchanged, repeat steps 1-2 and add the new functional grand effect and functional row effect to the existing ones at each iteration.
When functional data are observed for each combination of two categorical factors, the effects of interest are the functional row effect and the functional column effect. The observations may then be decomposed as follows:
where denotes the functional column effect, subject to the same constraints as in Equation (2). In the following algorithm, FM denotes the functional median computed pointwise across functions. To fit this model by medians, we use the following algorithm: 1. Determine each row’s FM and record the functional value adjacent to the row. From each function in that row, subtract the row functional median. 2. Determine the FM of every piece of information that is accessible, then save the outcome as the functional grand effect. 3. After subtracting this functional overall effect from each of the row FMs, record the results as the functional row effects. 4. Determine the FM for every column and record the result beneath it. For each function in that specific column, subtract the column FM. Determine the FM of every piece of data that is currently available, then store the outcome as the new functional grand effect. Record the results as the functional column effects after deducting this functional grand impact from each of the column functional medians. 5. At each iteration, repeat steps 1-4 and add the new functional overall effect, functional row effect, and functional column effect to the existing ones until the row FM’s remain unchanged.
We analyzed a 34-year monthly series of U.S. dollar exchange rates comprising 408 observations, arranged as a 34 × 12 year-by-month matrix.14
The series was imported from a plain text file and reshaped in R so that each row represented one year and each column represented one month. The matrix structure acted as the starting point for both the exploratory analysis and subsequent functional representation. The monthly observations were mapped to the domain t ∈ [1,12] and a Fourier basis with nbasis = 7 was employed to make the functional form of the data possible. The choice was assessed through a sensitivity analysis using K = 5, 7, and 9 basis functions. For each specification, the generalized cross-validation (GCV) criterion and the reconstruction mean squared error were verified. K = 7 was chosen for this purpose because it attained a trade-off between smoothness and accuracy of the reconstruction, avoiding excessive smoothing relative to K = 5 and possible overfitting relative to K = 9. Then, the functional objects were generated by the fda and fda.usc packages. The smoothed curves, in particular, were initially modeled as fd objects and then fdata objects to be able to perform Functional Median Polish. Other plots and diagnostic displays were generated using ggplot2, whilst tidyr was employed for reshaping and preparation. For the one-way and two-way Functional Median Polish algorithms and for the following FANOVA, these functional features were the input. How the actual data preprocessing and analysis steps work is as follows:
1. The values were read from a text file into an m-vector and then converted into a Mydata1 matrix of dimension 34 × 12, with each row representing a year and each column representing a month. Boxplots and line plots were used to inspect the raw structure of the data before smoothing
2. The Fourier basis was created on the [1,12] domain, with nbasis = 7, and the data were transformed into functional objects using Data 2fd, then re-evaluated into an fdata matrix for robustness methods.
3. Functional visual diagnostics were used to highlight the center, dispersion, and possible outlying behavior in order to assess the appropriateness of the transformation and smoothing before applying the FMP procedure.
4. The one-way FMP was performed to extract the center and row effect, followed by two-way FMP to incorporate the column effect. FANOVA was then applied to the extracted components, and the residual structure was examined through visual diagnostics and classical one-way ANOVA on the resulting effect matrices.
The complete R code used in the analysis is provided in Appendix A for reproducibility.
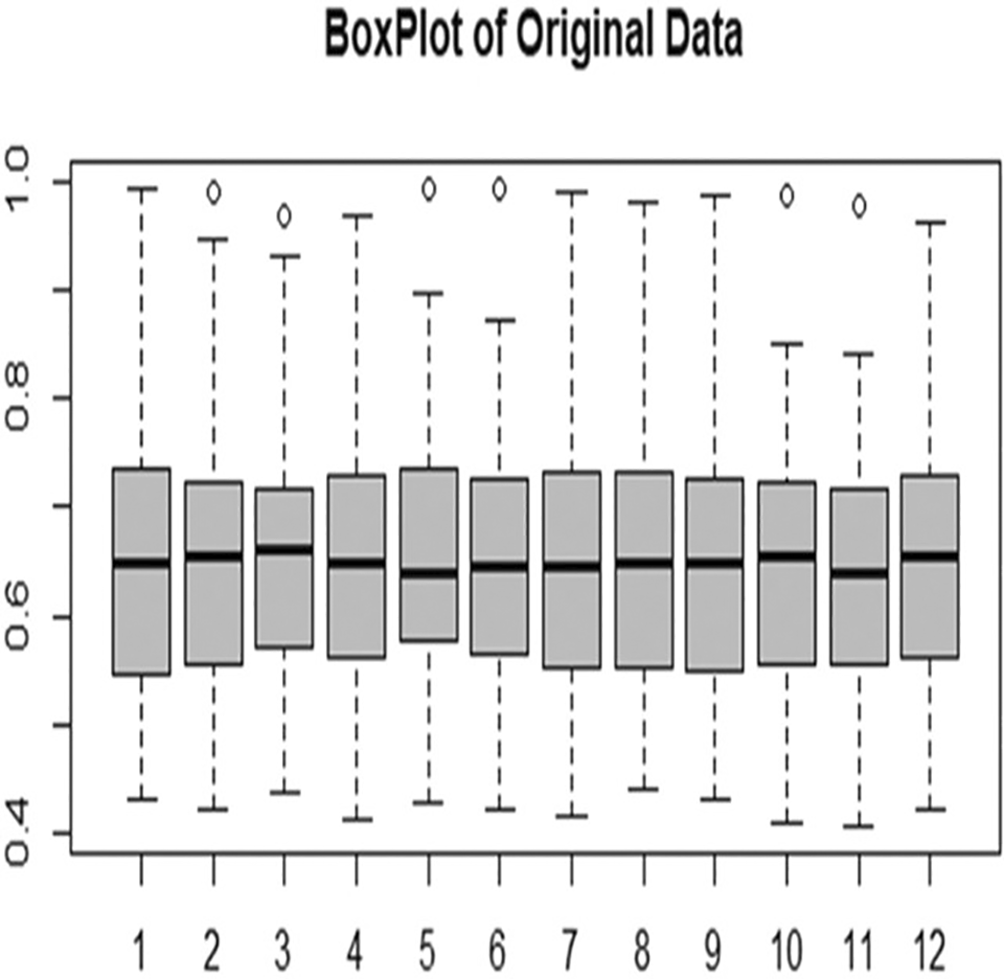
The boxplot was generated in Figure 10 to visualize the original data. The plot shows original exchange-rate observations divided over the months of the year. Data is similar: the central values look fairly similar with very little variability from month to month. Some infrequent deviations do occur in select years, but they do not change the data structure significantly. Extreme outliers are not dominant in this dataset so a robust functional framework is being used for stability over contamination.
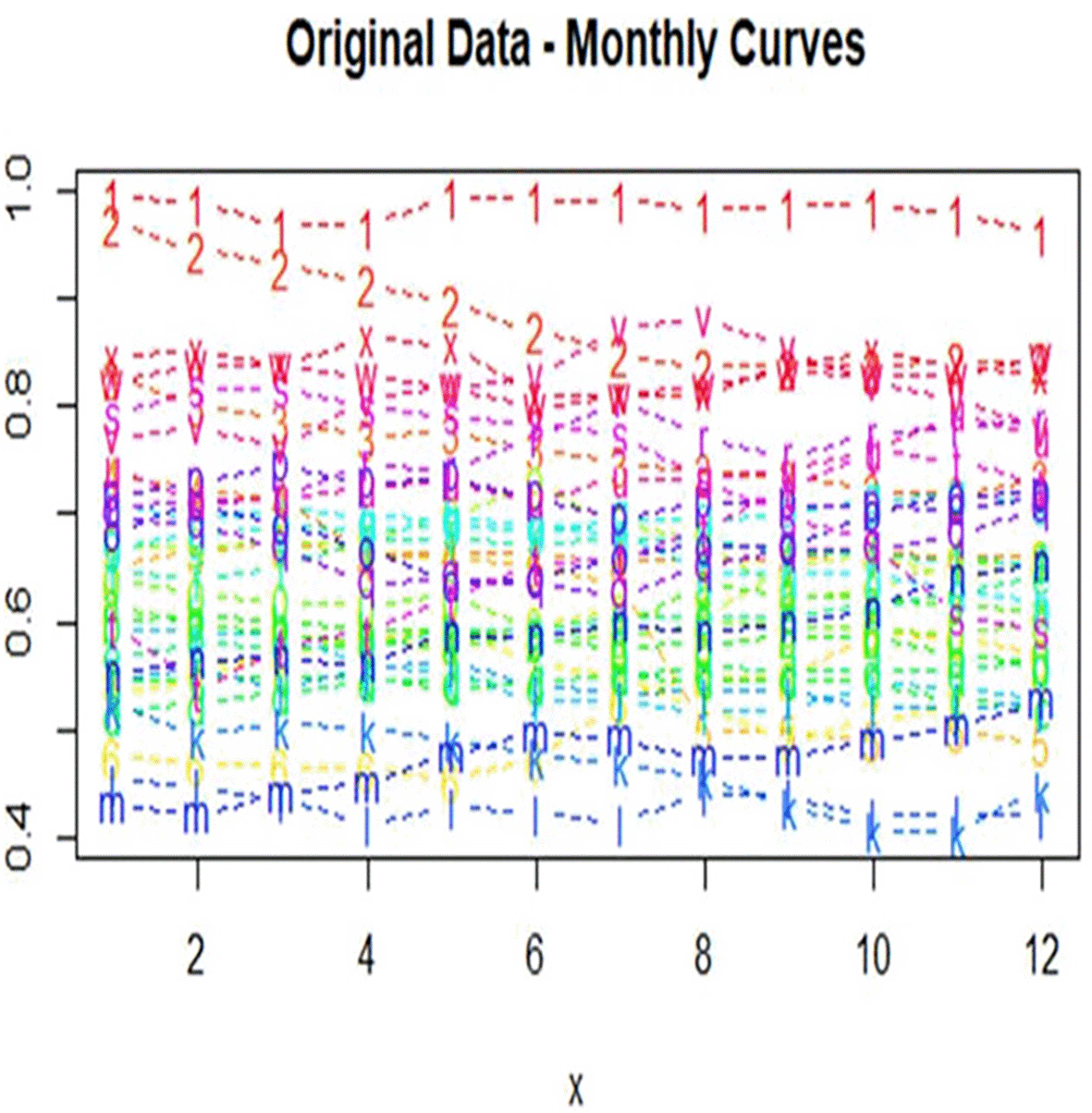
The monthly curves of data are presented in Figure 11. The figure shows the monthly trends over the exchange rates series over the years under study. Most of the slopes are stable with respect to months, indicating the uniformity of monthly behavior. There are some limited deviations in some few months but they don’t really change much. This indicates that the strong seasonality is not visually dominating in the raw measurements.
In the preliminary investigations and before loading the Functional Median Polish (FMP) algorithm, we performed a series of functional diagnostics (center, spread, and possible irregular graphs). These diagnostics serve as a baseline for evaluating the suitability of the functional transformation and the smoothing procedure before data is decomposed into center, row effects, column effects, and residuals. Functional boxplot of the smoothed exchange rate curves is provided in Figure 1.
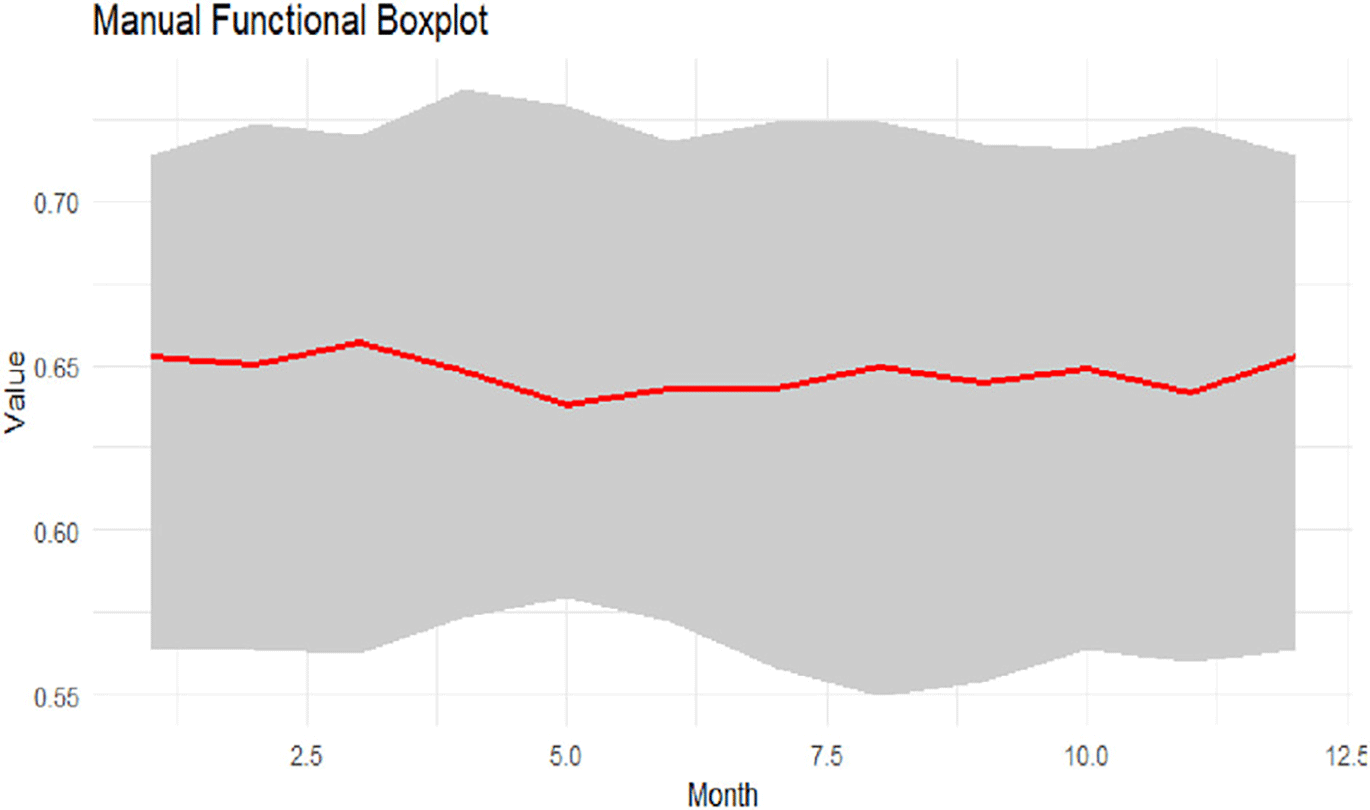
The red median curve varies about 0.64 to 0.65, suggesting that the monthly characteristics of exchange rate series are generally stable. The regions shaded above show the spread of central functions and moderate interannual variability in the monthly domain. The row effects’ heat map is depicted in Figure 2.
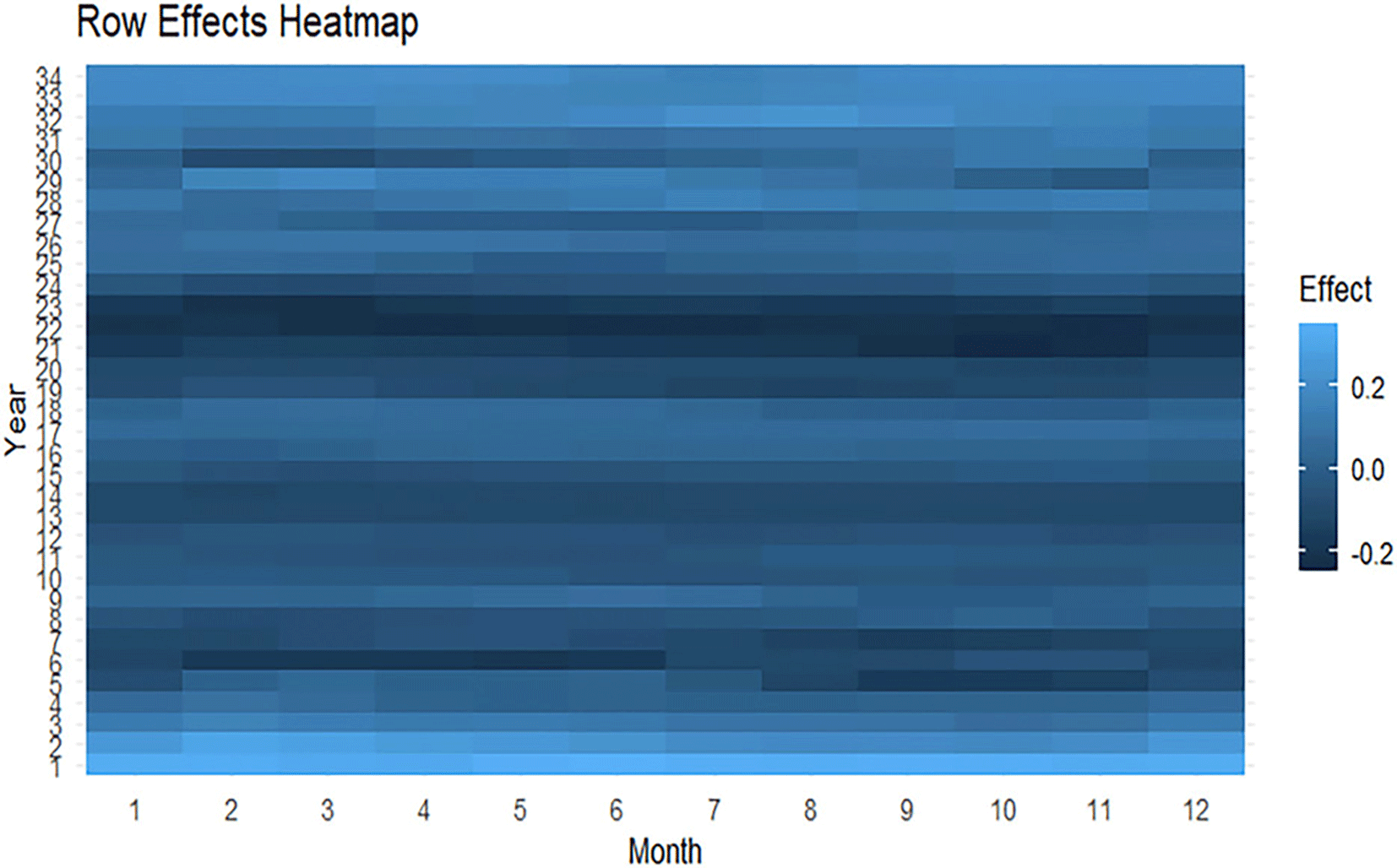
The heat map shows different years, some seem lighter and some darker, with positive and negative deviations from the center. It suggests an annual gap or an existence of differences but one that is quite limited.
The heatmaps for column effects are shown in Figure 3.
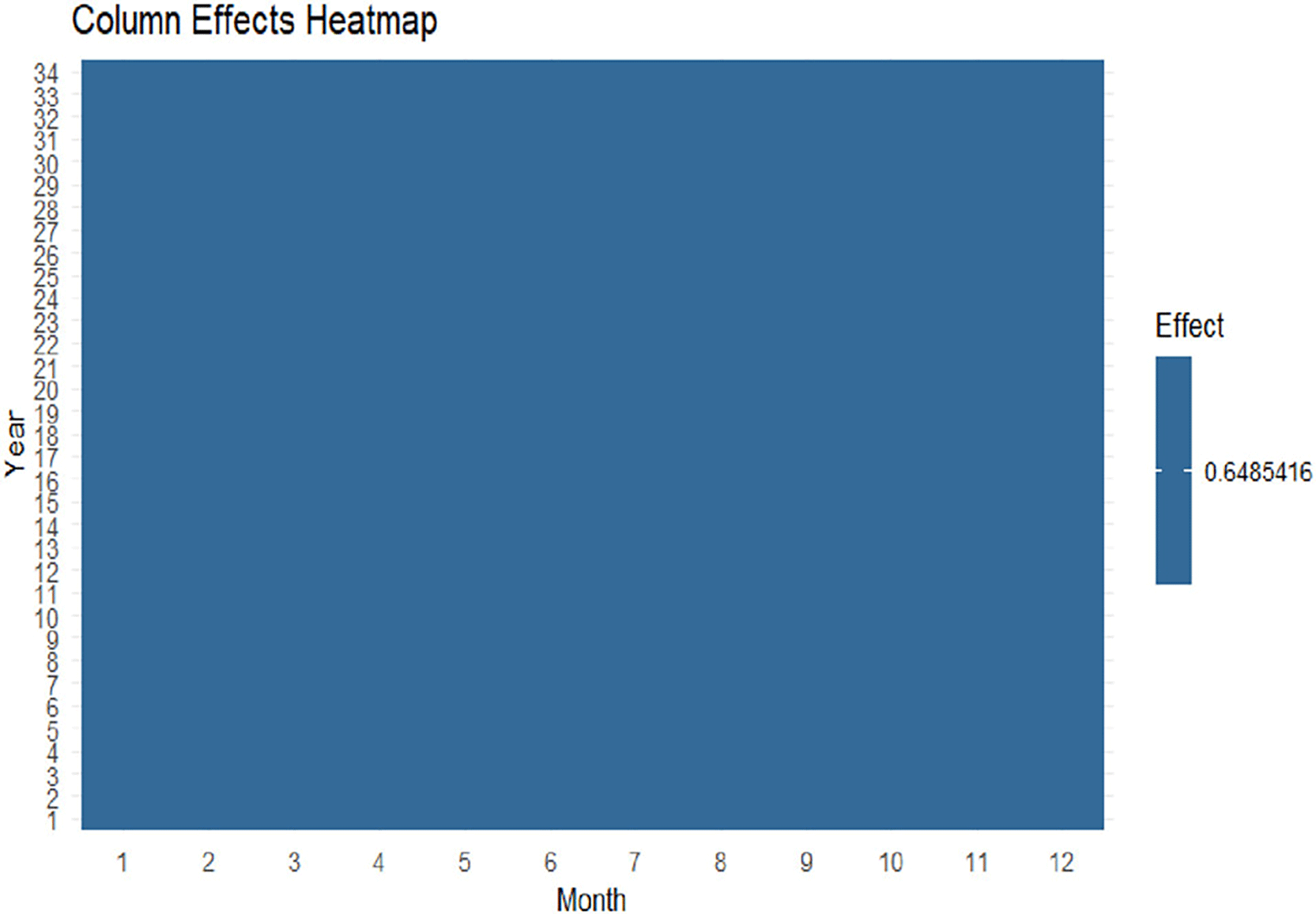
Almost the uniform color pattern and the color distribution in the figure confirm the fact the column effects are nearly invariant to all months. This means that the monthly effect has constant across the domain as a whole and adds no further effect to the overall structure.
Original, center, seasonally adjusted curves are depicted in Figure 4.
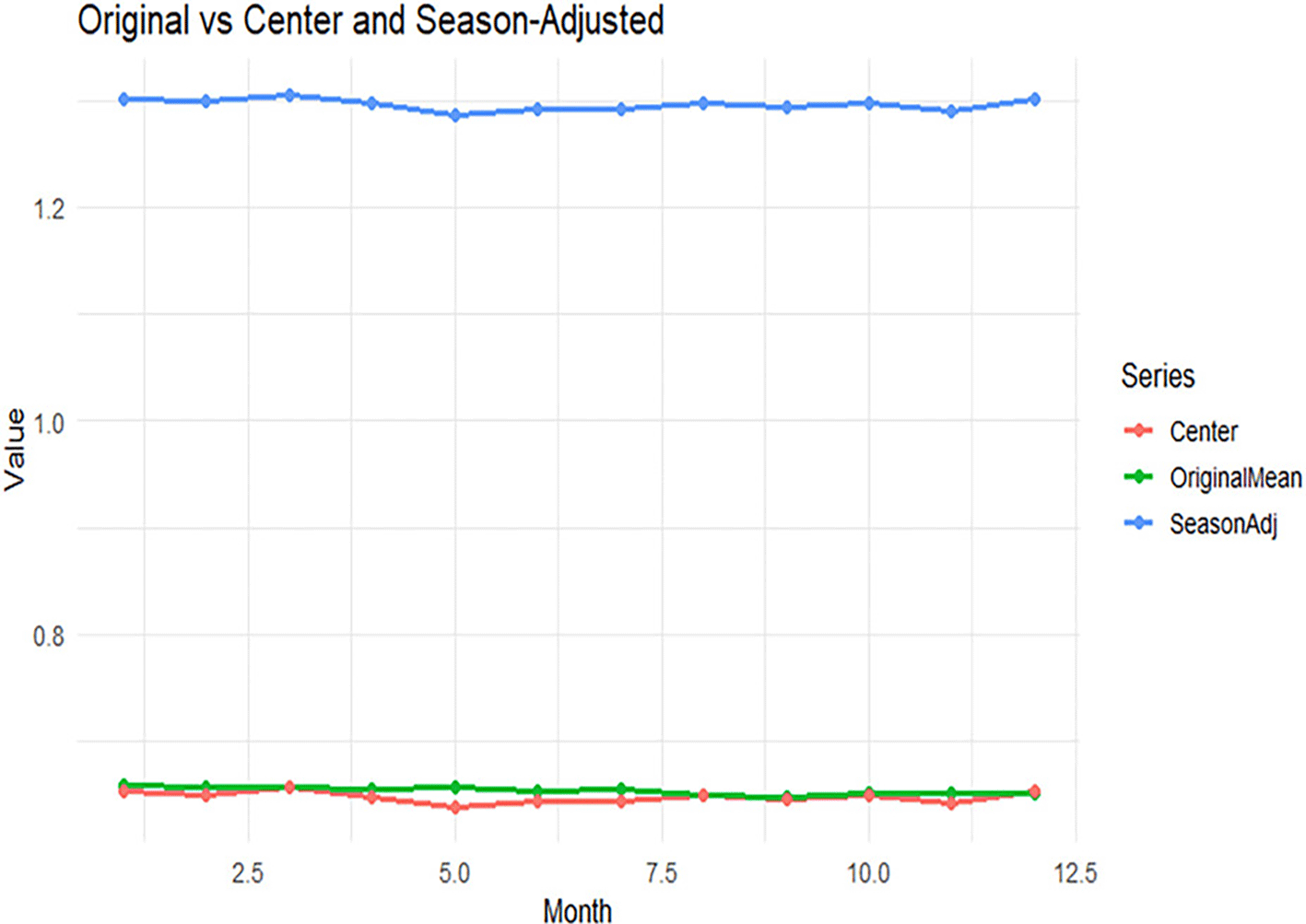
The center and original mean curves are close to each other in the monthly domain, indicating that the overall average pattern is stable. By contrast, the seasonally normalized curve shows some relatively higher level and also retains the very similar month over month shape. That means the adjustment adjusts the level of the series and at the same time the general monthly structure stays somewhat stable.
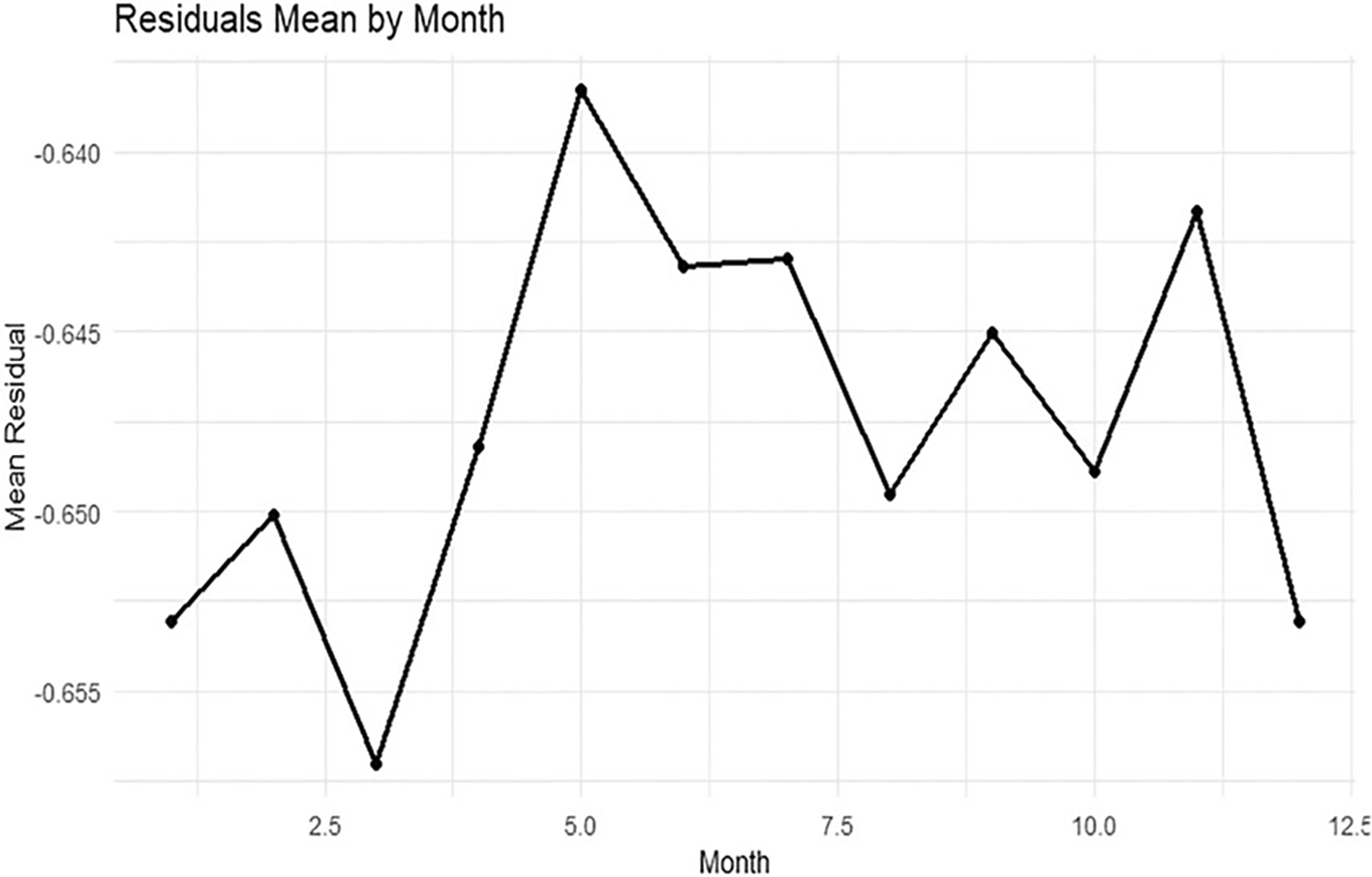
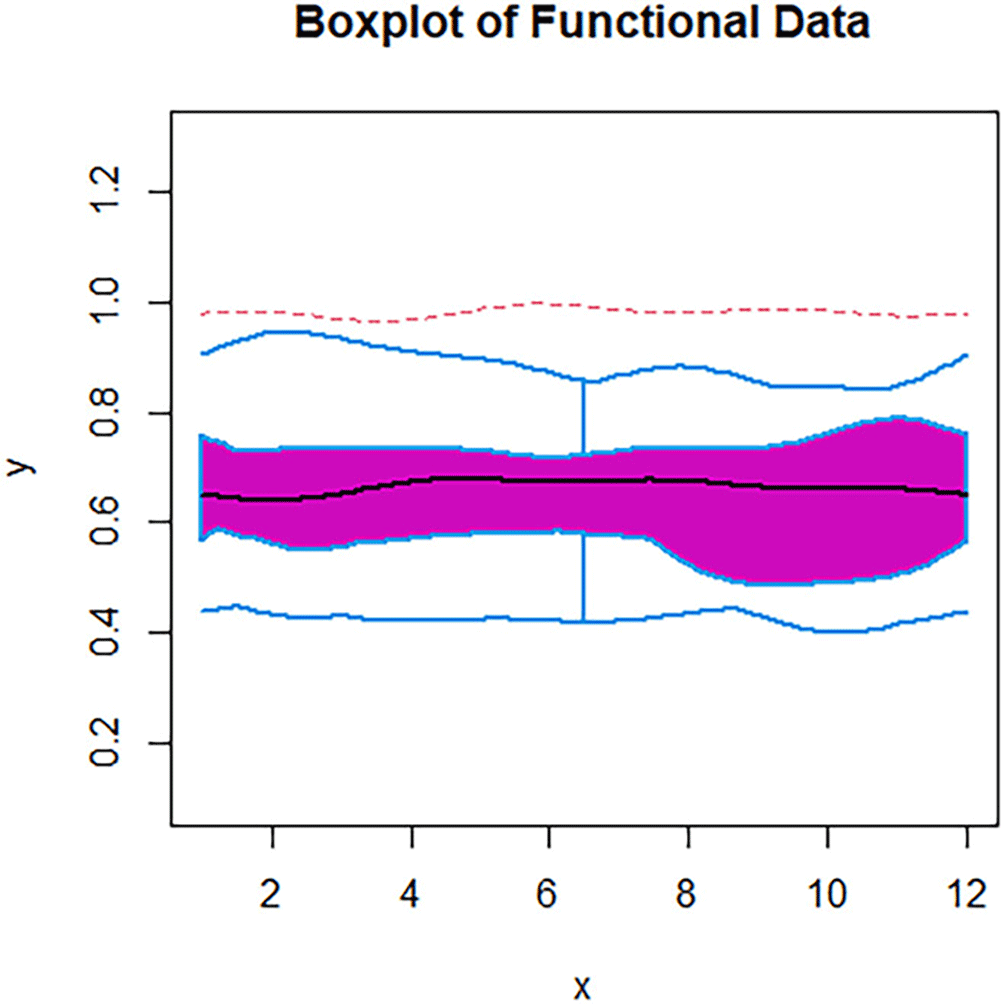
We also illustrate the functional boxplot from the transformed data in Figure 12. This figure was generated with fda package and shows plot of transformed functional observations. The black line points to the median, the shaded line the interquartile range and the boundaries the border which represent limits to locate the possible anomalously shaped lines. Some curves approach these limits, which imply mild departures from normal rather than extreme outlying behavior.
Table 2 presents the central function values obtained from the one-way Functional Median Polish, while Figure 13 shows the one-way center and row effects. The center curve remains relatively stable across the monthly domain, with values close to 0.64–0.65. The row effects fluctuate around zero with limited variation, indicating that differences between years are generally weak. This supports the view that the overall functional center is the dominant component in the one-way decomposition.
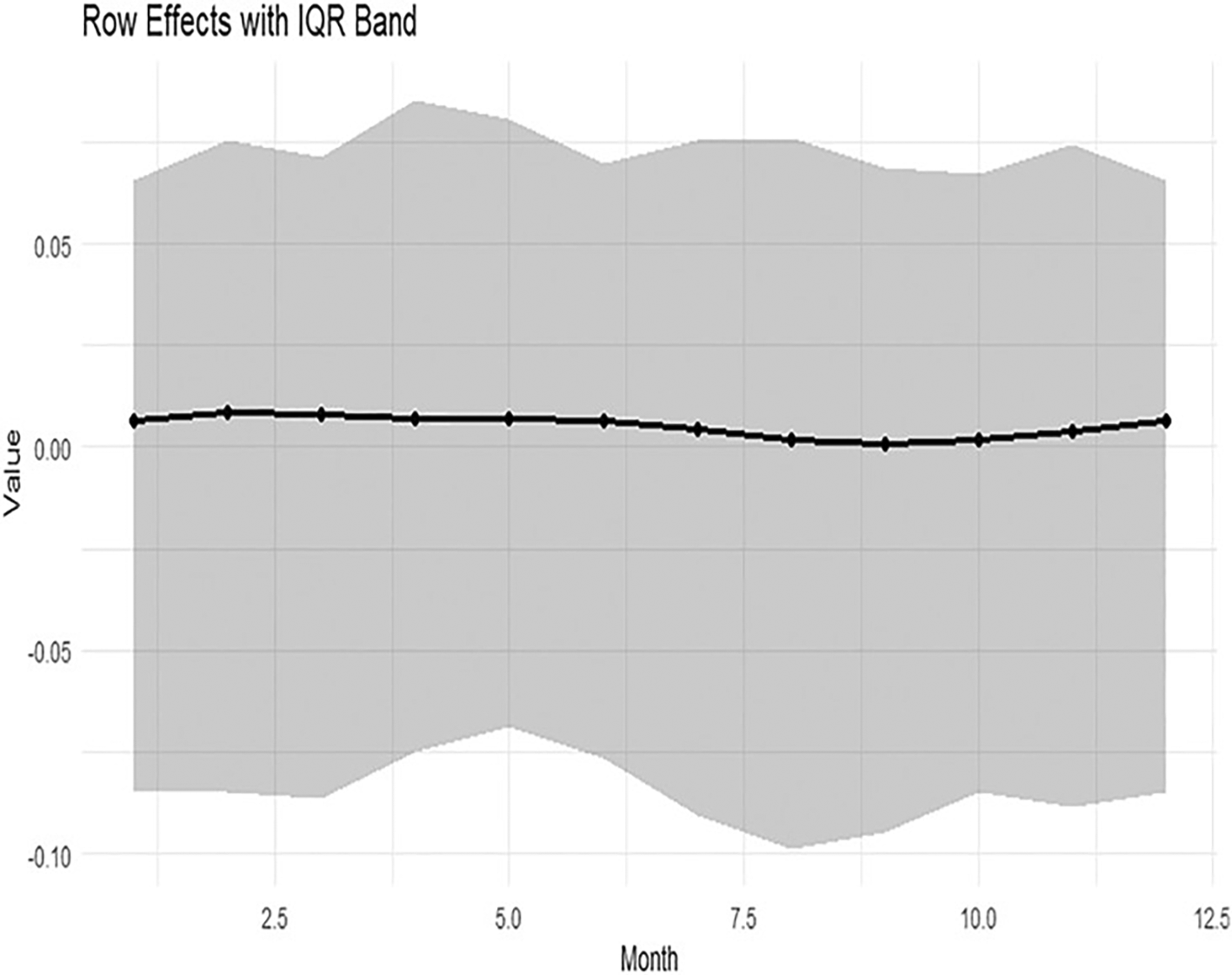
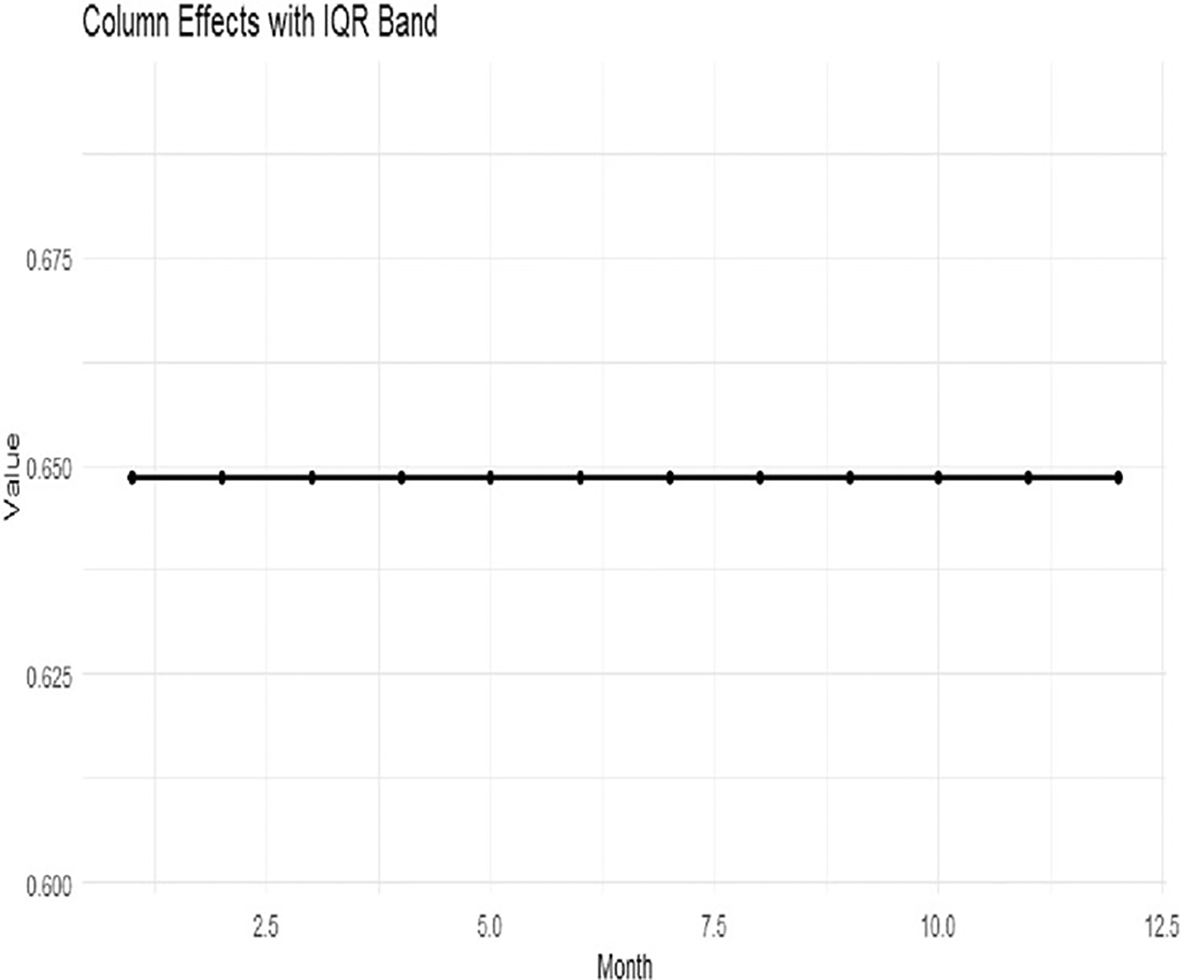
Figure 7 presents the Q-Q plot of the residuals, Figure 8 shows the row effects with the interquartile band, and Figure 9 displays the column effects across months.
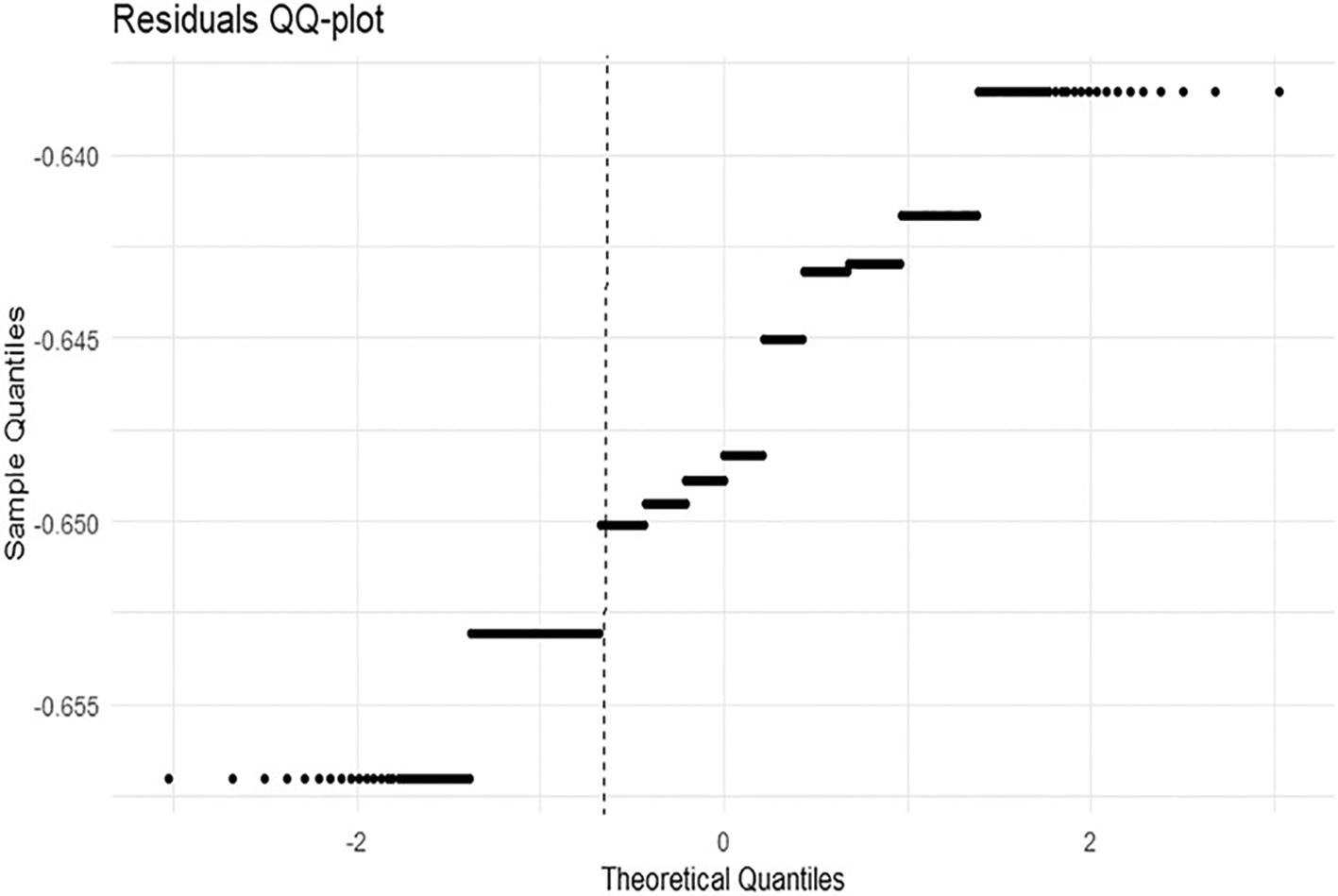
We demonstrate the Q-Q plot of the residuals for Figure 7. The plotted points deviate from an ideal normal pattern, particularly in the tails, indicating that the tails of the residual distribution may be heavier than would be anticipated by the normal assumption.
The row effects with the IQR band are presented in Figure 8. The median line of the row-effect curve is nearly zero in most months, and the surrounding band indicates very little interannual variability. Small deviations occur in some months, but the overall trend implies weak annual effects.
Figure 9 shows the column effects by month. The effects of the column remain nearly constant across the range of the month, with only minimal variation. This matches the heat diagram of column effects and suggests that the monthly component adds little further explanation. Figure 14 shows the mean functional components (center, row, column, and residuals) of the two-way Functional Median Polish.
The center and column mean curves stay nearly constant over months, and the row mean remains near 0, representing fairly weak annual spread for the variable. By comparison, the residual mean stays consistently negative and varies modestly between months. The residual structure of the residual component may also have some more variation; however, this behaviour indicates the stability of the principal structural elements.
The Figure 10 explain the Boxplot of Original Data.
The Figure 12 explain Boxplot of Functional Data.
The Table 2 shown Central Function Values Obtained from One-way Functional Median Polish, while Figure 13 explain Center One Way and Row Effects One Way.
| 1 | 2 | 3 | 4 | 5 | 6 | |
| [1,] | 0.6530329 | 0.6501276 | 0.657014 | 0.6482106 | 0.6382607 | 0.6431659 |
| 7 | 8 | 9 | 10 | 11 | 12 | |
| [1,] | 0.642981 | 0.649499 | 0.6450545 | 0.6488726 | 0.6416805 | 0.6530329 |
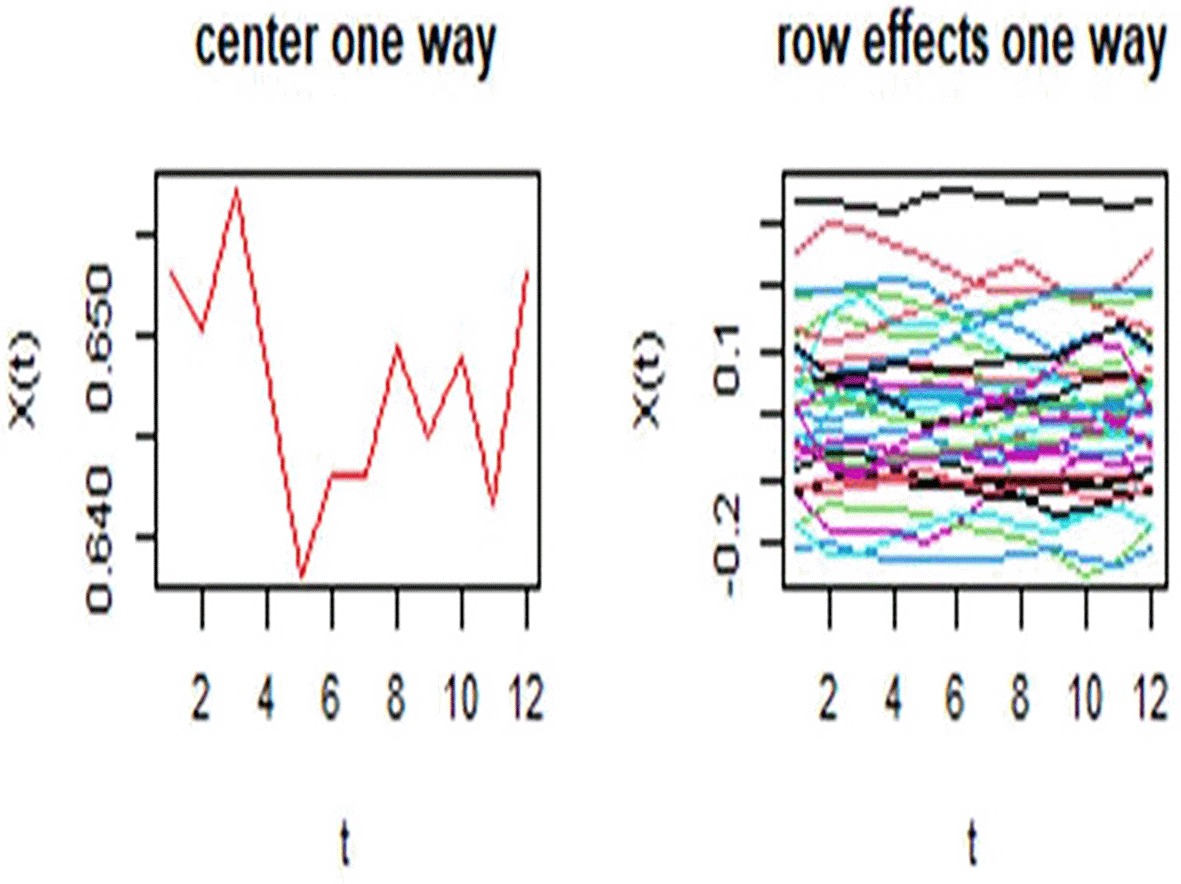
The figure shows the results of the One-Way Functional Median Polish (FMP). The red curve (left) represents the monthly central values, which remain stable around 0.64–0.65. The right-hand figure shows the effects of years, which remain close to zero with some limited deviations, indicating that the differences between years are weak, while the central curve reflects the overall structure of the series.
The Figure 14 explain Mean Functional Components (Center, Row, Column, and Residuals) from Two-way Functional Median Polish.
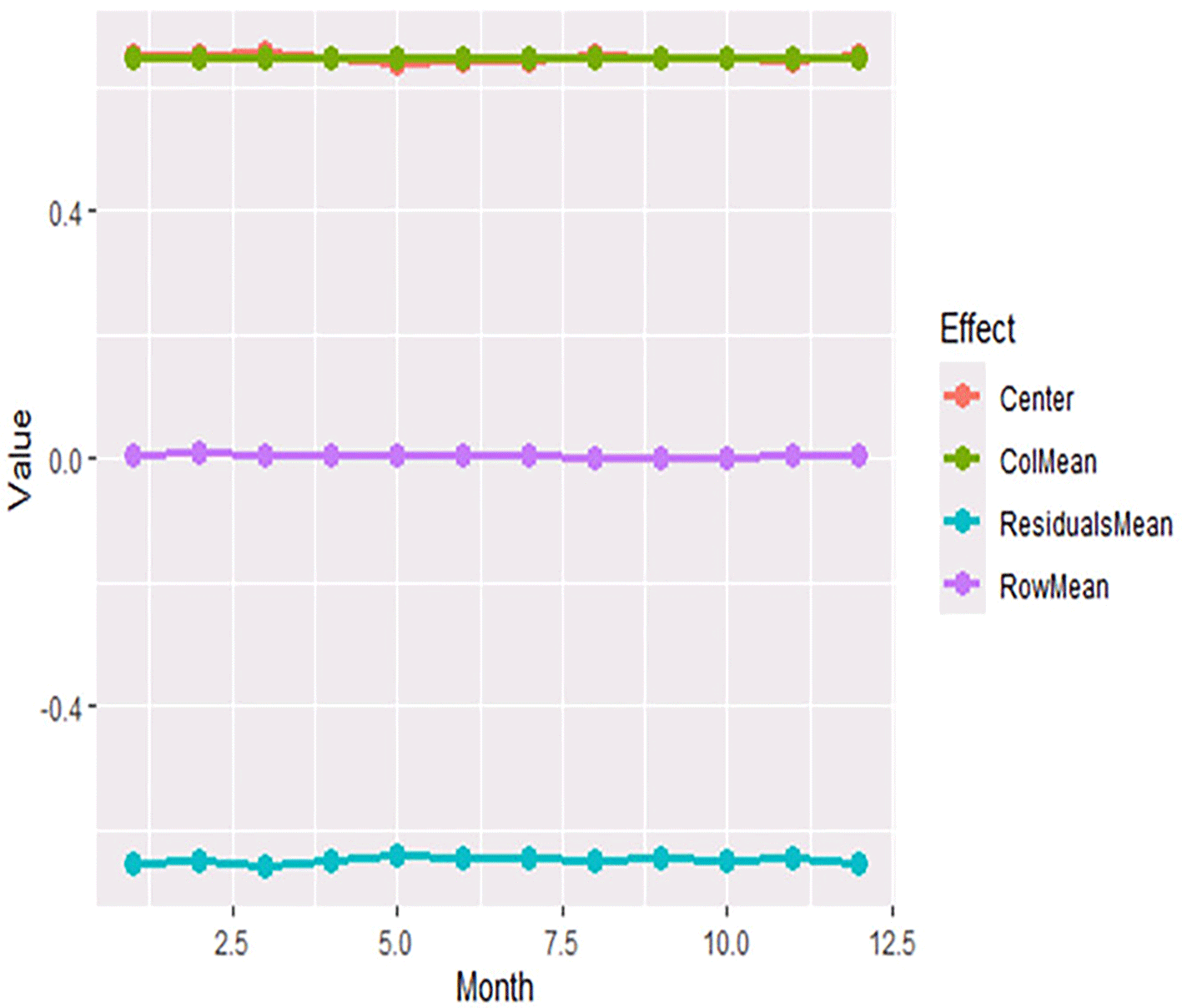
The figure shows the mean of the principal components resulting from the Two-Way Functional Median Polish. The central curve appears to be constant across months, while the row and column effects are close to zero, reflecting weak annual and seasonal variations. The figure shows the mean of the principal components resulting from the two-way Functional Median Polish. The center curve remains stable across months, while the row and column effects stay close to zero, indicating weak annual and monthly variation. The residual mean shows only modest fluctuation across the monthly domain, which suggests that the unexplained component is limited in structure.
The Figure 15 explain Residuals with IQR Band.
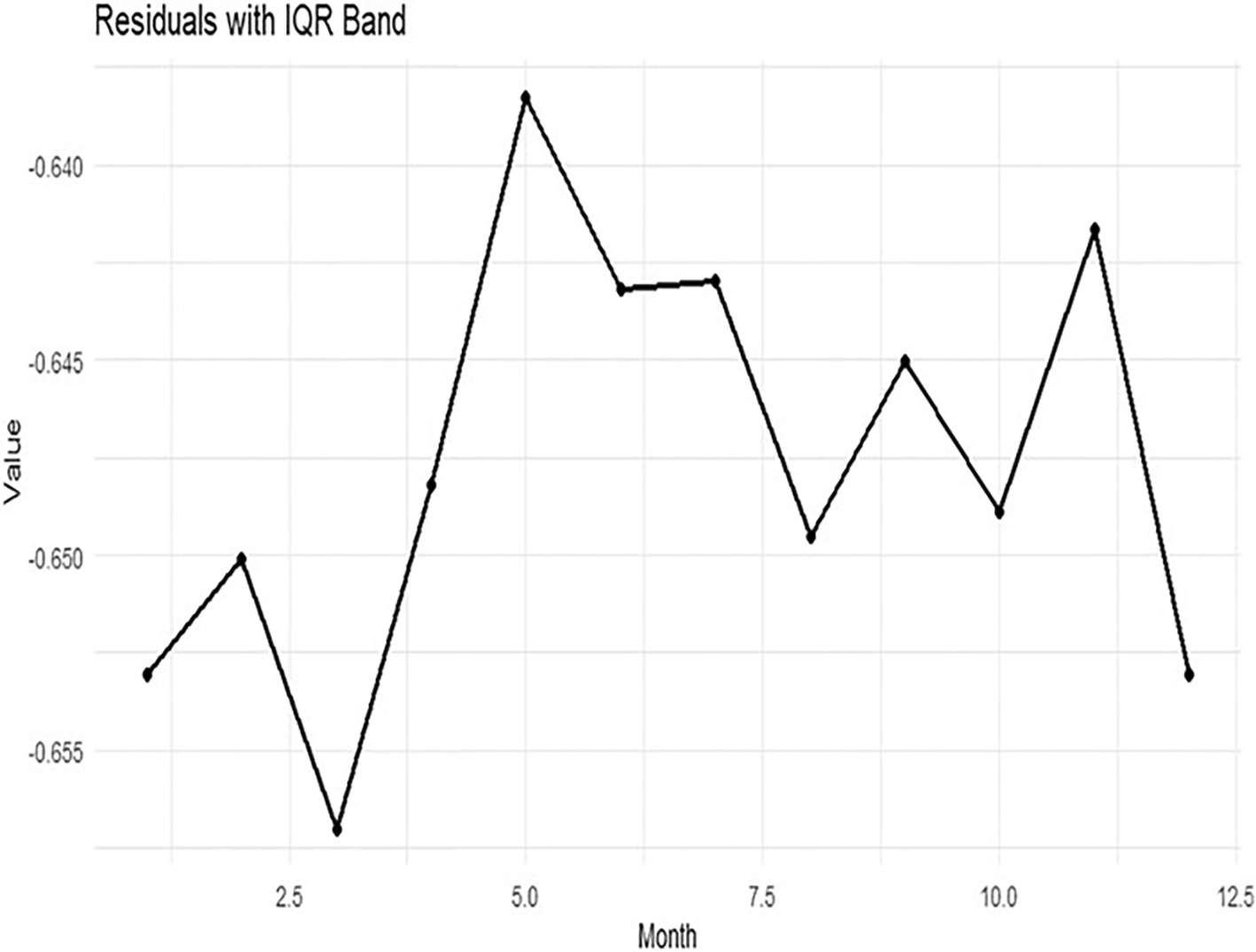
This figure displays the residual pattern across months together with its interquartile spread. The residual variation remains limited, although modest fluctuations appear from month to month. No clear recurring seasonal pattern is evident in the residual structure, which suggests that most of the systematic variation has already been absorbed by the extracted center, row, and column components. We notice that the residuals are concentrated in the negative range (around zero with slight dispersion), with significant fluctuations between months. Some months (such as July and August) show residuals closer to zero (less negative), while in other months, such as February, June, and October, the residuals are more negative. This suggests that the model did not fully explain all monthly variations, and that some unexplained variances remain, reflecting the possibility of seasonal components or nonlinear effects that were not captured.
While Figure 16 shows the ANOVA p-values for Functional Effects.
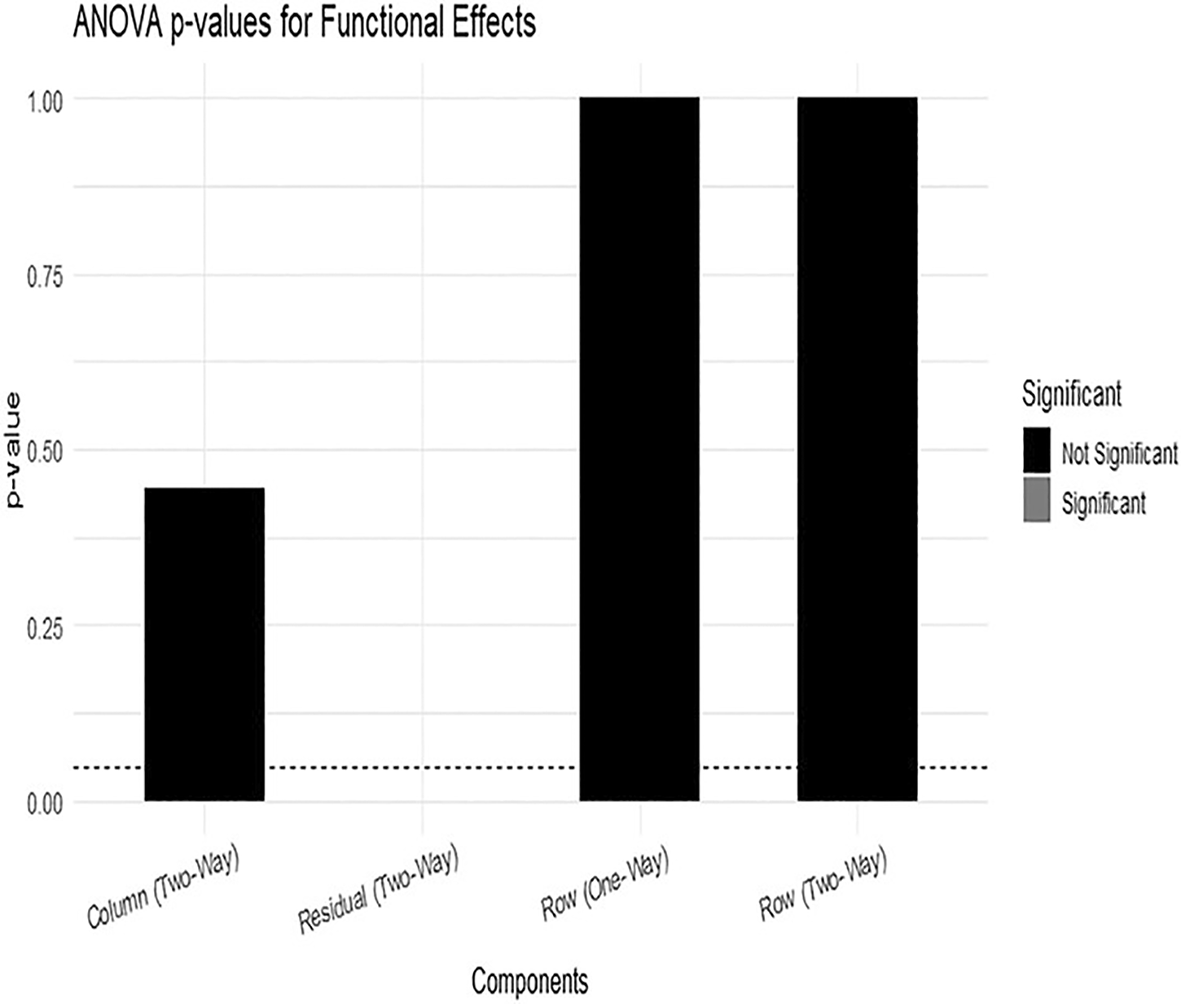
Figure 16 shows that all ANOVA p-values are above the 0.05 significance level, indicating that neither the row effects nor the column effects are statistically significant. The column effect in the two-way model is around 0.45, while the row effects in both the one-way and two-way models are close to 1.00, which further confirms the absence of meaningful functional effects. These results suggest that the series does not exhibit significant annual or monthly structural variation.
While Figure 17 shows Center vs Row/Column/Residual Means.
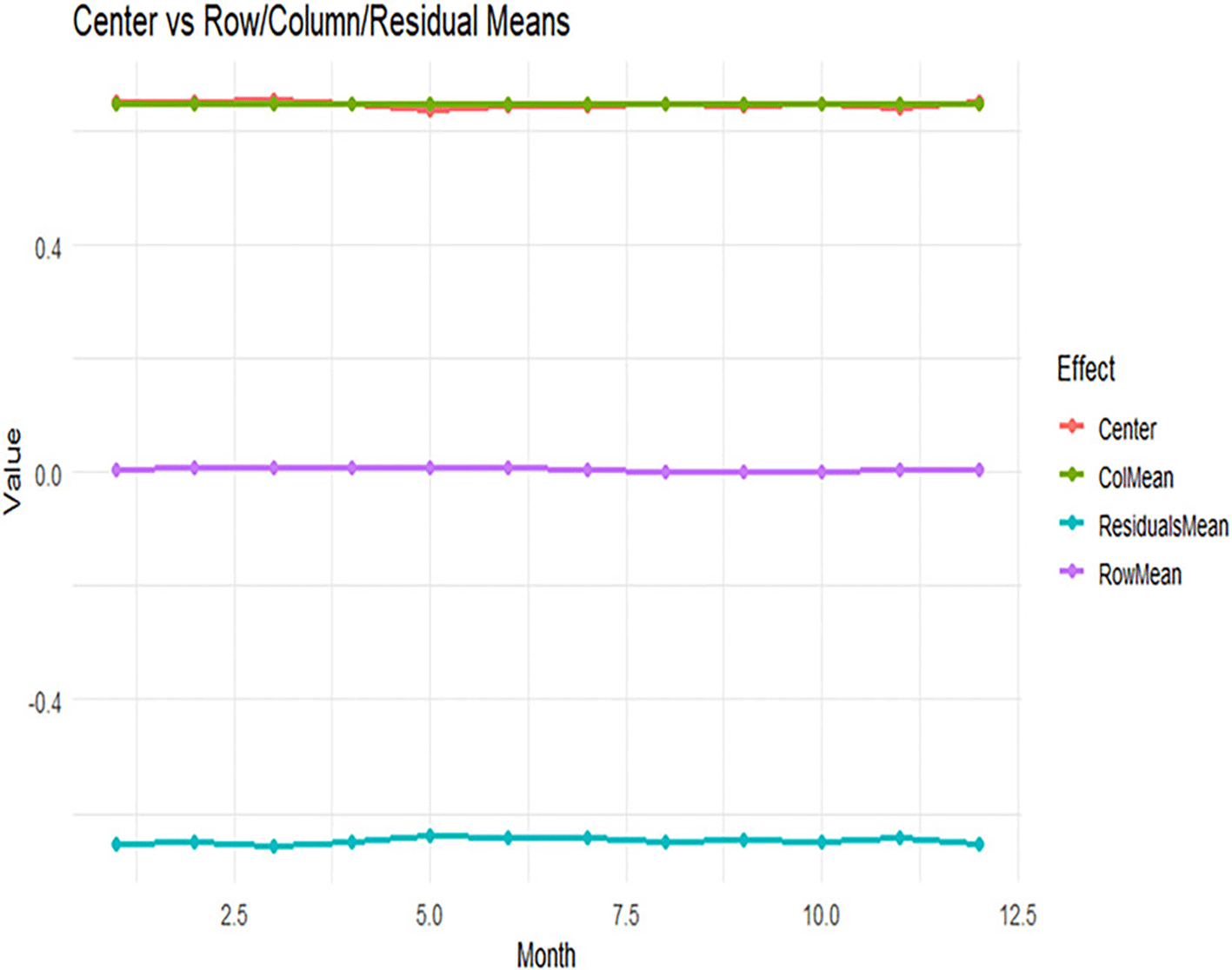
Figure 17 shows the center in comparison with the row, column, and residual means. The figure confirms that the center and column mean curves remain stable at a similar level across months, while the row mean remains close to zero. In contrast, the residual mean is consistently negative across the monthly domain. This indicates that the dominant structural component is the center, whereas the annual component is weak and part of the remaining variation is retained in the residual structure.
Overall, the figures indicate that the center represents the dominant structural component and remains relatively stable across the monthly domain. The annual effects (row effects) are weak and do not reflect statistically significant differences between years. The monthly effects (column effects) remain nearly constant and contribute little additional variation to the overall structure. The residual component retains part of the unexplained variation and exhibits some departure from normality. Taken together, these findings suggest that the exchange-rate series is characterized more by a stable functional center than by strong annual or monthly systematic effects.
The Fourier functional representation along with one-way and two-way Functional Median Polish (FMP) was reliable in giving a stable estimate of the overall functional center. However, both annual and monthly effects were not statistically significant using Functional ANOVA (FANOVA), suggesting a weak deterministic seasonal structure in the exchange rate series studied. This means that the main feature of the data is the overall functional level rather than systematic year- or month-specific effects.
In our study we make a contribution to the literature that the smooth functional representation on the monthly domain is combined with a robust one-way and two-way FMP decomposition along with the evaluation by FANOVA and standard diagnostic methods. This is an interpretable and robust exploratory framework that is appropriate for the analysis of monthly economic time-series data if structural component description is desired rather than model development. The primary limitations of this study include nominal exchange rate values without adjustment for inflation, missing institutional or explanatory covariates, univariate analysis, and a small number of observations per yearly curve.
The functional approximation is also dependent on the chosen basis and level of smoothing and therefore, it may affect the obtained components. Institutional and financial variables may be included in future work, the analysis might be extended using Functional Principal Component Analysis (FPCA) or multivariate functional models between official and parallel exchange markets, uncertainty could be quantified through bootstrapping procedures and out-of-sample predictive performance can be assessed.
Overall, the findings highlight the usefulness of robust functional decomposition methods for analyzing economic time-series data characterized by moderate variability and weak seasonal structure.
Source data: The monthly U.S. dollar exchange rate dataset analyzed in this study consists of 34 years of observations (408 values arranged in a 34×12 year-by-month matrix). These data were not generated by the authors and were obtained from previously published work https://www.rbnz.govt.nz/statistics/economic-indicators/b1. The authors collected, organized, and reformatted the data into a unified year–month (34 × 12) matrix to make them suitable for analysis. publicly accessible through the following link: https://github.com/Abdulsalamiraq/U.S._dollar_exchange_rates , or https://zenodo.org/records/17803613, or DOI: https://doi.org/10.5281/zenodo.20094143.14
The R code used for the practical implementation and analysis has been provided as supplementary material and is publicly available at the following Zenodo repository: https://doi.org/10.5281/zenodo.20094143.14
Data are available under the terms of the Creative Commons Attribution 4.0 International.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)