Keywords
heavy metal; machine learning; spectroscopy; electrochemistry; classification; systematic review
This article is included in the Cheminformatics gateway.
heavy metal; machine learning; spectroscopy; electrochemistry; classification; systematic review
Heavy metal pollution is one of the most serious environmental challenges of the 21st century. Heavy metals such as lead (Pb), cadmium (Cd), mercury (Hg), chromium (Cr), arsenic (As), copper (Cu), nickel (Ni), and zinc (Zn) enter the environment through various anthropogenic activities, including mining, metal smelting, industrial waste, intensive agriculture, and domestic wastewater discharge (Jaishankar et al., 2014; Tchounwou et al., 2012). Unlike organic pollutants that can degrade, heavy metals are persistent, non-biodegradable, and accumulate in food chains (Ali & Khan, 2019; Rehman et al., 2018).
The health impacts of heavy metals are severe: Pb causes neurological disorders (Flora et al., 2012), Cd is carcinogenic (Godt et al., 2006), Hg damages the central nervous system (Rice et al., 2014), and As is associated with various cancers (Hughes et al., 2011). The World Health Organization (WHO) and regulatory bodies such as the US EPA have established water quality and soil quality standards for heavy metals, which serve as references for determining pollution status (US EPA, 2026; WHO, 2022). For example, WHO sets the Pb limit in drinking water at 10 μg/L, while the European Union sets As limit in soil at 5 mg/kg (Hu et al., 2024) and Cu limit at 20 mg/kg (Qi et al., 2025).
Standard analytical methods for heavy metals such as AAS, ICP-OES, and ICP-MS offer high accuracy and sensitivity, but have limitations: expensive instrumentation, need for trained personnel, complex sample preparation, and lack of in-situ detection capabilities (Bansod et al., 2017; Taylor et al., 2017). As alternatives, spectroscopic techniques (LIBS, SERS, vis-NIR, 3D fluorescence) and electrochemical techniques (voltammetry, EIS) have been developed due to their lower cost, portability, and potential for real-time detection (Gumpu et al., 2015; Sawan et al., 2020). However, both approaches generate complex data that are difficult to interpret manually, thus requiring machine learning (ML) and chemometrics.
Machine learning has proven effective for processing multi-dimensional, non-linear, noisy spectroscopic and electrochemical data (Lussier et al., 2020; Puthongkham et al., 2021). Various algorithms have been applied, including Support Vector Machines (SVM), Random Forest (RF), Convolutional Neural Networks (CNN), Long Short-Term Memory (LSTM), and ensemble learning (Dean et al., 2019; Hu et al., 2024). These algorithms can extract relevant features, improve classification accuracy, and automate decision-making.
In environmental monitoring, pollution status classification refers to determining whether a sample is “contaminated” or “not contaminated” by comparing heavy metal concentrations with regulatory standards or thresholds (Vareda et al., 2019). Classification can be binary (contaminated vs. non-contaminated) or multi-level (low, medium, high). This approach differs from regression (predicting numerical values) or ion type discrimination. Pollution status classification has higher practical value for remediation decisions and regulatory compliance (Hu et al., 2024; Qi et al., 2025).
Several reviews have discussed ML applications in heavy metal detection (Borrill et al., 2019; Huang et al., 2023; Lussier et al., 2020). However, existing reviews generally focus on technical aspects of algorithms without systematically considering: (1) performance comparison between spectroscopic and electrochemical data, (2) pollution status classification outcomes (not merely identification or quantification), and (3) evaluation on real environmental matrices with class imbalance.
More importantly, no systematic review has specifically examined the integration of spectroscopic and electrochemical data for heavy metal pollution status classification in environmental matrices (water, soil, sediment, wastewater). Such integration has the potential to improve accuracy through complementary information. Of 154 articles screened in this study, only 11 met the inclusion criteria (heavy metal target, environmental matrix, ML/chemometrics, and pollution status classification outcome). However, none of these 11 articles integrated both data types; all used only one modality (spectroscopy alone or electrochemistry alone). This indicates a significant research gap.
This systematic review aims to identify, evaluate, and synthesize studies that use ML/chemometrics algorithms for heavy metal pollution status classification based on spectroscopic and/or electrochemical data in environmental matrices. The research questions are formulated using the P-E-O (Population, Exposure, Outcome) framework. Specifically, this review addresses the following questions: (1) Which heavy metals and sample matrices are most frequently reported in studies using ML for pollution status classification? (2) Which ML algorithms are most commonly used, and what data features are extracted from spectra or voltammetric signals? (3) What are the performance metrics (accuracy, precision, recall, AUC, F1-score) of pollution status classification models? (4) Does the integration of spectroscopic and electrochemical data significantly improve classification accuracy compared to using a single data type?
This systematic review was conducted in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 statement (Page et al., 2021). The review protocol was not registered but followed established guidelines for systematic reviews in environmental science and analytical chemistry (Chandler et al., 2019; Liberati et al., 2009). The study selection process is summarized in Figure 1 (see Section 3.1).
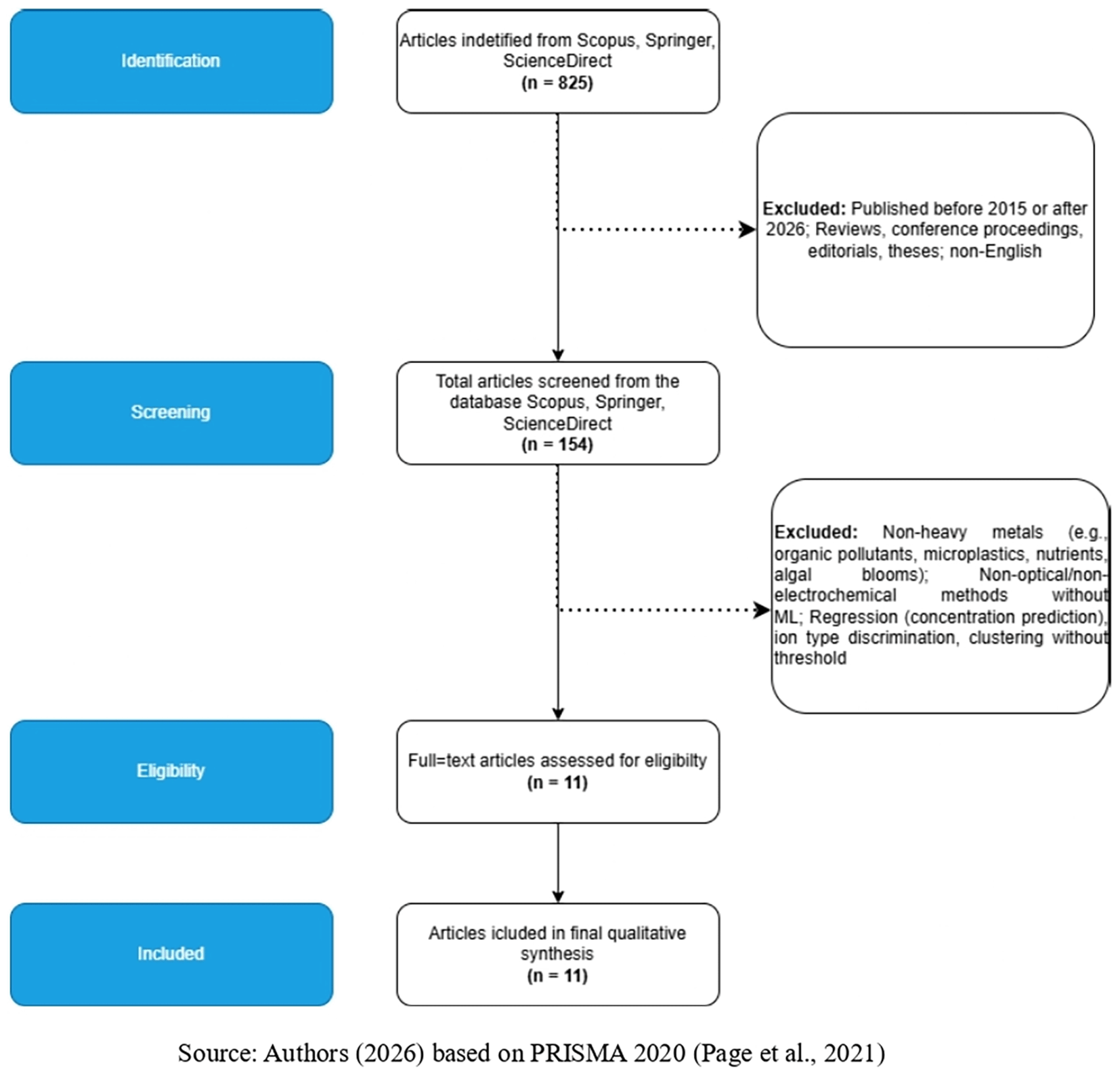
This study employed a systematic literature review design to identify, evaluate, and synthesize peer-reviewed research articles that apply machine learning (ML) or chemometric algorithms for heavy metal pollution status classification based on spectroscopic and/or electrochemical data in environmental matrices. The review was structured around the P-E-O (Population, Exposure, Outcome) framework (Methley et al., 2014; Schardt et al., 2007), as illustrated in Figure 2.
a) Population (P): Spectroscopic (absorbance/intensity) or electrochemical (potential/current) data from heavy metals (Pb, Cd, Hg, Cr, As, Cu, Ni, Zn, etc.) in environmental matrices (water, soil, sediment, wastewater).
b) Exposure (E): Machine learning or chemometric algorithms used to process analytical data.
c) Outcome (O): Binary or multi-level classification of heavy metal pollution status based on regulatory thresholds or established standards.

Figure 2 shows the schematic of the P-E-O framework applied in this review.
Studies were included or excluded based on the criteria summarized in Table 1.
Searches were conducted in the following electronic databases:
These databases were selected due to their comprehensive coverage of peer-reviewed literature in environmental science, analytical chemistry, materials science, and engineering disciplines relevant to heavy metal detection and machine learning applications. No additional databases (e.g., Web of Science, PubMed, IEEE Xplore) were used. The final search was performed on 6 May 2026. No filters for publication status were applied beyond the date range (2015–2026). Reference lists of included studies and relevant review articles were manually screened to identify additional eligible studies (snowballing). Table 2 presents the number of records initially identified from each database.
A systematic search was conducted on 6 May 2026 using three electronic databases: Scopus, SpringerLink, and ScienceDirect. The same core search string was applied across all databases, with minor syntactic adjustments to accommodate each platform. The search combined keywords related to three main concepts: (1) heavy metals, (2) spectroscopic/electrochemical techniques, and (3) machine learning/chemometrics, using Boolean operators (AND, OR). The base search string was:
("heavy metal " OR "toxic metal " OR lead OR cadmium OR mercury OR chromium OR arsenic OR copper OR nickel OR zinc OR Pb OR Cd OR Hg OR Cr OR As OR Cu OR Ni OR Zn) AND ("spectroscopy" OR "spectromet" OR "LIBS" OR "SERS" OR "Raman" OR "FTIR" OR "vis-NIR" OR "fluorescence" OR "hyperspectral" OR "voltammetry" OR "SWASV" OR "DPV" OR "CV" OR "electrochemical" OR "EIS" OR "potentiometry" OR "stripping voltammetry") AND ("machine learning" OR "deep learning" OR "chemometric" OR "artificial neural network" OR "support vector machine" OR "random forest" OR "convolutional neural network" OR "LSTM" OR "ensemble learning" OR "PLS" OR "PCA" OR "SVM" OR "ANN" OR "CNN") AND ("classification" OR "contamination" OR "pollution status" OR "threshold" OR "binary classification" OR "multi-class classification")
Additional filters were applied uniformly: peer-reviewed research articles, English language, and publication year >2014 (or 2015–2026 for ScienceDirect). The search was performed by two independent reviewers; discrepancies were resolved by consensus. Results were exported to reference management software for duplicate removal. The number of records retrieved per database is reported in Table 2 (Section 2.3).
Study selection followed a four-stage process, as illustrated in Figure 1 (Section 3.1). The process was conducted independently by two reviewers, with disagreements resolved through consensus or consultation with a third reviewer.
Stage 1: Identification. A total of 825 records were identified from the three databases (Scopus: 133; SpringerLink: 681; ScienceDirect: 11) on 6 May 2026. All records were exported to reference management software, where duplicates were removed. After duplicate removal, the remaining records proceeded to the screening stage.
Stage 2: Screening (title and abstract). The titles and abstracts of all unique records were screened against the eligibility criteria ( Table 1). Records that clearly did not meet the inclusion criteria were excluded. When eligibility could not be determined from the title and abstract alone, the full text was retained for the next stage. This stage yielded 154 records considered potentially relevant and thus included for full-text review.
Stage 3: Eligibility (full-text screening). Full texts of the 154 potentially eligible records were retrieved and assessed independently by two reviewers against the full eligibility criteria. A total of 143 records were excluded at this stage, primarily because the study area was not relevant to the review’s focus (e.g., target analyte not a heavy metal, matrix not environmental, outcome not classification of pollution status, or no machine learning algorithm applied). Reasons for exclusion were documented for each excluded full text.
Stage 4: Included. After full-text screening, only 11 studies met all inclusion criteria and were included in the final qualitative synthesis.
The PRISMA flow diagram ( Figure 1, Section 3.1) provides a complete visual summary of the selection process, including the number of records at each stage and reasons for exclusion.
Data were extracted from each included study using a standardized data extraction form developed in Microsoft Excel. The form was piloted on three randomly selected studies and refined accordingly. Data extraction was performed by one reviewer and independently verified by a second reviewer. Discrepancies were resolved through discussion.
The extracted information included bibliographic details, study characteristics, target heavy metal(s), matrix type, concentration range, regulatory threshold, spectroscopic or electrochemical technique, preprocessing methods, machine learning algorithms, validation approach, classification performance metrics (accuracy, precision, recall, F1-score, AUC), and any integration of multiple data types.
Due to space limitations, the full data extraction results are not presented within this article. However, the complete dataset, including all extracted variables and intermediate calculations, is available in the supplementary repository (see Data Availability Statement). A summary of the extracted data is presented in Tables 4–12 (Section 3).
Data were extracted from each included study covering the following items:
• Bibliographic information: Authors, year, journal, country.
• Population (P): Target heavy metal(s), matrix type (water, soil, sediment), concentration range, regulatory threshold used for classification (e.g., WHO, EPA, EU).
• Exposure (E): Data type (spectroscopy or electrochemistry), specific technique, preprocessing methods, ML/chemometric algorithm(s), feature extraction, validation approach.
• Outcome (O): Classification task (binary or multi-level), performance metrics reported (accuracy, precision, recall, F1-score, AUC, etc.), best-performing model.
• Data integration: Whether spectroscopic and electrochemical data were combined (yes/no); if yes, fusion level (data, feature, or decision).
No assumptions were made for missing or unclear data; items not reported were recorded as “not reported”. A summary of the extracted data is provided in Tables 3–12 (Section 3).
| No. | Author (Year) | Matrix | Target Metal(s) | Data Type | ML Algorithm(s) |
|---|---|---|---|---|---|
| 1 | Hu et al. (2024) | Soil | As | Spectroscopy (vis-NIR) | SVM, RF, GBDT, Ridge, ensemble |
| 2 | Wei et al. (2023) | Water | As3+, Cr6+ | Spectroscopy (SERS) | SVM, CNN, tSNE |
| 3 | Lahari et al. (2025) | Water | Cd2+, Pb2+, Cu2+, Hg2+ | Electrochemical (DPV) | CNN, ANN |
| 4 | Kailasam et al. (2024) | Water | Ni2+, Cu2+ | Electrochemical (CV, DPV) | Naïve Bayes, ANN, SVM, DT |
| 5 | Dean et al. (2019) | Seawater | Pb, Cd, Cu, Hg | Electrochemical (CSWV) | LSTM, FCN, ALSTM-FCN, LDA, PCA-SVM |
| 6 | Chen et al. (2025) | Water | 9 metals | Spectroscopy (3D fluorescence) | RF, SVM, ANN, DT |
| 7 | Park et al. (2022) | Water | Pb (NO3)2 | Spectroscopy (SERS) | RBFSVM, LR, NB, DT, RF, MLP |
| 8 | Hajzus et al. (2022)) | Seawater | Cd, Cu, Hg, Pb | Electrochemical (CSWV) | LSTM, FCN, ALSTM-FCN |
| 9 | Valle et al. (2025) | Water | Hg2+, Ag+, Fe3+ | Electrochemical (EIS) | Decision Tree (MCS), IDMAP |
| 10 | Qi et al. (2025) | Soil | Cu | Spectroscopy (vis-NIR) | BalancedRandomForest, EasyEnsemble, RUSBoost |
| 11 | Maity et al. (2023) | Water | Pb2+, Hg2+ + E. coli | Electrochemical (GFET) | PCA, ANN |
| Heavy Metal | No. of Studies (%) | Source (representative studies) |
|---|---|---|
| Lead (Pb) | 6 (54.5%) | (Dean et al., 2019; Hajzus et al., 2022; Hu et al., 2024; Lahari et al., 2025; Maity et al., 2023; Park et al., 2022) |
| Cadmium (Cd) | 5 (45.5%) | (Chen et al., 2025; Dean et al., 2019; Hajzus et al., 2022; Kailasam et al., 2024; Lahari et al., 2025) |
| Mercury (Hg) | 5 (45.5%) | (Dean et al., 2019; Hajzus et al., 2022; Lahari et al., 2025; Maity et al., 2023; Valle et al., 2025) |
| Copper (Cu) | 4 (36.4%) | (Dean et al., 2019; Hajzus et al., 2022; Lahari et al., 2025; Qi et al., 2025) |
| Arsenic (As) | 3 (27.3%) | (Chen et al., 2025; Hu et al., 2024; Wei et al., 2023) |
| Chromium (Cr) | 2 (18.2%) | (Chen et al., 2025; Wei et al., 2023) |
| Nickel (Ni) | 2 (18.2%) | (Chen et al., 2025; Kailasam et al., 2024) |
| Others (Ag, Fe, Mn, Co, Zn) | 1 each (9.1%) | (Chen et al., 2025; Valle et al., 2025) |
| Matrix Type | No. of Studies (%) | Source |
|---|---|---|
| Water (tap, lake, seawater, wastewater) | 8 (72.7%) | (Chen et al., 2025; Dean et al., 2019; Hajzus et al., 2022; Lahari et al., 2025; Maity et al., 2023; Park et al., 2022; Valle et al., 2025; Wei et al., 2023) |
| Soil | 2 (18.2%) | (Hu et al., 2024; Qi et al., 2025) |
| Sediment | 0 (0%) | – |
| Technique | No. of Studies | Source |
|---|---|---|
| vis-NIR spectroscopy | 2 | (Hu et al., 2024; Qi et al., 2025) |
| Surface-Enhanced Raman Spectroscopy (SERS) | 2 | (Park et al., 2022; Wei et al., 2023) |
| 3D fluorescence spectroscopy | 1 | (Chen et al., 2025) |
| Total spectroscopic | 4 (36.4%) | – |
| Technique | No. of Studies | Source |
|---|---|---|
| Differential Pulse Voltammetry (DPV) | 2 | (Kailasam et al., 2024; Lahari et al., 2025) |
| Cyclic Square Wave Voltammetry (CSWV) | 2 | (Dean et al., 2019; Hajzus et al., 2022) |
| Electrochemical Impedance Spectroscopy (EIS) | 2 | (Maity et al., 2023; Valle et al., 2025) |
| Cyclic Voltammetry (CV) | 1 | (Kailasam et al., 2024) |
| Graphene Field-Effect Transistor (GFET) | 1 | (Maity et al., 2023) |
| Total electrochemical | 8 (72.7%) | – |
| Algorithm | No. of Studies (%) | Source |
|---|---|---|
| Support Vector Machine (SVM) | 5 (45.5%) | (Dean et al., 2019; Hu et al., 2024; Kailasam et al., 2024; Park et al., 2022; Wei et al., 2023) |
| Random Forest (RF) | 4 (36.4%) | (Chen et al., 2025; Hu et al., 2024; Park et al., 2022; Qi et al., 2025) |
| Artificial Neural Network (ANN/MLP) | 4 (36.4%) | (Chen et al., 2025; Kailasam et al., 2024; Lahari et al., 2025; Park et al., 2022) |
| Convolutional Neural Network (CNN) | 3 (27.3%) | (Chen et al., 2025; Lahari et al., 2025; Wei et al., 2023) |
| Long Short-Term Memory (LSTM) | 2 (18.2%) | (Dean et al., 2019; Hajzus et al., 2022) |
| Decision Tree (DT) | 2 (18.2%) | (Kailasam et al., 2024; Valle et al., 2025) |
| Fully Convolutional Network (FCN) | 2 (18.2%) | (Dean et al., 2019; Hajzus et al., 2022) |
| Others (NB, LDA, kNN, LR, BalancedRF, etc.) | 1 each (9.1%) | Various |
| Method Category | Specific Technique | No. of Studies | Source |
|---|---|---|---|
| Baseline correction | Asymmetric LS, IRLS | 3 | (Dean et al., 2019; Park et al., 2022; Wei et al., 2023) |
| Normalization | Min-Max, Z-score, PSD | 4 | (Lahari et al., 2025; Park et al., 2022; Qi et al., 2025) |
| Smoothing | Savitzky-Golay, moving average | 3 | (Chen et al., 2025; Hu et al., 2024; Qi et al., 2025) |
| Derivatives | First derivative (FD) | 2 | (Hu et al., 2024; Qi et al., 2025) |
| Scatter correction | MSC, SNV | 2 | (Hu et al., 2024; Qi et al., 2025) |
| Dimensionality reduction | PCA | 4 | (Chen et al., 2025; Dean et al., 2019; Lahari et al., 2025; Wei et al., 2023) |
| Data augmentation | SMOTE | 3 | (Lahari et al., 2025; Qi et al., 2025; Wei et al., 2023) |
| Study | Best Model | Accuracy (%) | AUC | Recall | F1-Score |
|---|---|---|---|---|---|
| Hu et al. (2024) | SVC | 83 | 0.89 | 0.86 | NR |
| Wei et al. (2023) | SVM | >97 | NR | NR | NR |
| Lahari et al. (2025) | CNN | 99–100 | NR | 0.99 | 0.99 |
| Kailasam et al. (2024) | Naïve Bayes | 93.2 | NR | NR | NR |
| Dean et al. (2019) | ALSTM-FCN | NR | 0.999 | NR | NR |
| Chen et al. (2025) | RF | 97.8–100 | NR | NR | NR |
| Park et al. (2022) | RBFSVM | – | 0.846 | NR | NR |
| Hajzus et al. (2022) | ALSTM-FCN | – | 0.998 | NR | NR |
| Valle et al. (2025) | Decision Tree | 99 | NR | NR | NR |
| Qi et al. (2025) | BalancedRandomForest | – | 0.870 | 0.816 | NR |
| Maity et al. (2023) | ANN | >99 | NR | NR | NR |
| Integration Type | No. of Studies (%) | Source |
|---|---|---|
| Spectroscopy only | 4 (36.4%) | (Chen et al., 2025; Hu et al., 2024; Park et al., 2022; Qi et al., 2025; Wei et al., 2023) |
| Electrochemistry only | 7 (63.6%) | (Dean et al., 2019; Hajzus et al., 2022; Kailasam et al., 2024; Lahari et al., 2025; Maity et al., 2023; Valle et al., 2025) |
| Spectroscopy + Electrochemistry integrated | 0 (0%) | – |
| Domain | Low Risk | Unclear Risk | High Risk | Source |
|---|---|---|---|---|
| Sample representativeness | 9 | 2 | 0 | Author assessment (adapted from JBI and QUADAS-2) |
| Reference standard (ICP-MS/AAS) | 11 | 0 | 0 | Author assessment |
| ML model validation | 8 | 3 | 0 | Author assessment |
| Reporting of performance metrics | 6 | 5 | 0 | Author assessment |
| Justification of classification threshold | 5 | 4 | 2 | Author assessment (Valle et al., 2025; Wei et al., 2023) |
| Handling of confounding factors (pH, temp, matrix) | 4 | 5 | 2 | Author assessment |
Risk of bias was assessed independently by two reviewers using a tailored tool adapted from the Joanna Briggs Institute (JBI) checklist and QUADAS-2 (Moola et al., 2020; Whiting et al., 2011). Six domains were evaluated:
1) Sample representativeness
2) Reference standard (e.g., ICP-MS, AAS)
3) ML model validation (cross-validation, independent test set)
4) Reporting of performance metrics
5) Justification of classification threshold
6) Handling of confounding factors (pH, temperature, matrix effects)
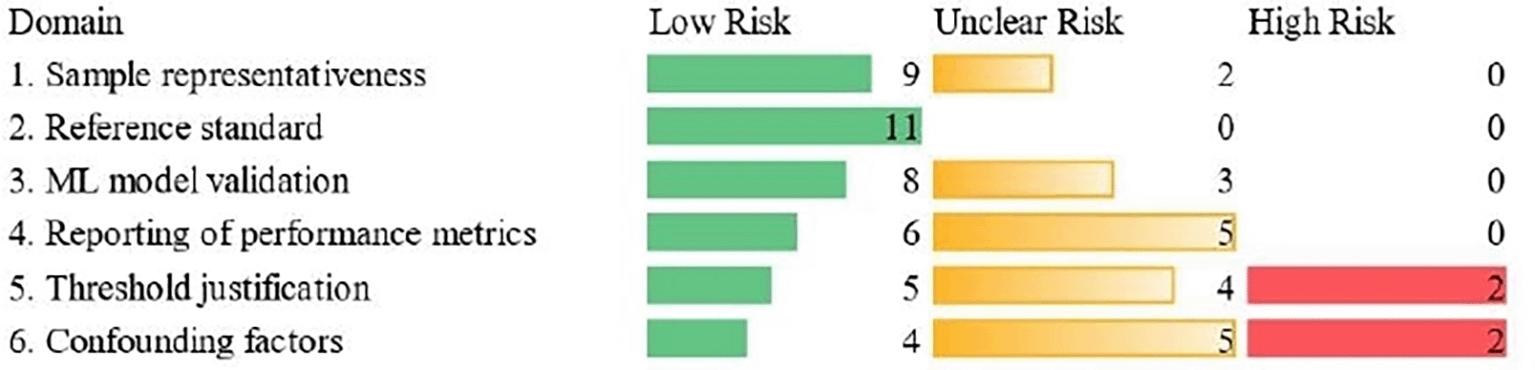
Each domain was rated as “low risk”, “high risk”, or “unclear risk”. Studies were not excluded based on bias scores; the assessment was used to inform the narrative synthesis and sensitivity analysis. Results are summarized in Table 12 and Figure 7 (Section 3.8).
Due to anticipated heterogeneity in study designs, target analytes, matrices, and classification tasks, a meta-analysis was not performed. Effect measures were summarized narratively. For classification performance, the following metrics were extracted when reported:
• Accuracy: proportion of correctly classified samples.
• Sensitivity (recall): true positive rate.
• Specificity: true negative rate.
• Precision: positive predictive value.
• F1-score: harmonic mean of precision and recall.
• AUC: area under the ROC curve.
When multiple models were reported, the best-performing model based on accuracy or AUC was prioritized. For studies that compared integrated vs. single-modality approaches, the improvement in accuracy (percentage points) was calculated. A summary of performance metrics is presented in Table 10 and Figures 5–6 (Section 3.6).
A narrative synthesis approach was adopted (Popay et al., 2006). The synthesis was structured around the four research questions and organized thematically:
• Tabulation: Extracted data were organized into summary tables ( Tables 3–12).
• Thematic analysis: Findings were grouped by:
1) Target heavy metal and matrix (RQ1) → Tables 4–5
2) ML algorithm and feature extraction (RQ2) → Tables 6–9
3) Performance metrics (RQ3) → Table 10, Figures 5–6
4) Data integration (RQ4) → Table 11
• Visualization: A PRISMA flow diagram ( Figure 1), bar charts ( Figures 2–5), ROC curves ( Figure 6), and a traffic light plot for risk of bias ( Figure 7) were generated.
Subgroup analyses were planned by matrix type (water vs. soil), data type (spectroscopy vs. electrochemistry), and algorithm family (traditional ML vs. deep learning vs. ensemble). A sensitivity analysis was conducted by excluding studies with high risk of bias to assess the robustness of the findings. Publication bias was not formally assessed because of the narrative nature of the synthesis and heterogeneity of outcome measures.
The systematic search yielded a total of 825 records from three databases: Scopus (n = 133), SpringerLink (n = 681), and ScienceDirect (n = 11). After duplicate removal, 567 unique records remained. Title and abstract screening excluded 413 records, leaving 154 records for full-text assessment. Full-text screening resulted in the exclusion of 143 records, primarily because the study area was not relevant to the review’s focus (e.g., target analyte not a heavy metal, matrix not environmental, outcome not pollution status classification, or no machine learning algorithm applied). A total of 11 studies met all eligibility criteria and were included in the final qualitative synthesis. The PRISMA flow diagram is presented in Figure 1.
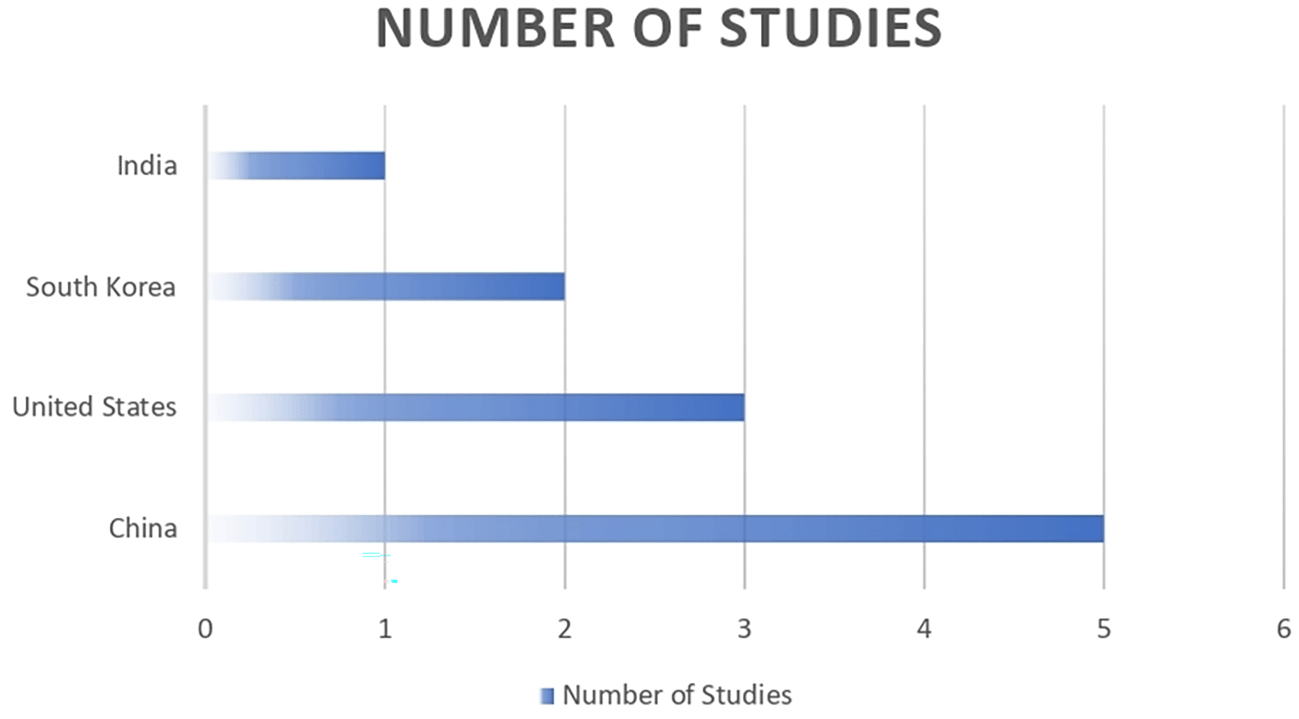
A summary of the 11 included studies is presented in Table 3. The studies were published between 2019 and 2025, with the majority appearing after 2022. The corresponding authors were primarily from China (n = 5), the United States (n = 3), South Korea (n = 2), and India (n = 1). All studies were peer-reviewed original research articles published in English.
The number of included studies increased over time, as shown in Figure 2. Only one study was published before 2020 (Dean et al., 2019), followed by two studies in 2022 (Hajzus et al., 2022; Park et al., 2022), three in 2023 (Chen et al., 2025; Maity et al., 2023; Wei et al., 2023), two in 2024 (Hu et al., 2024; Kailasam et al., 2024), and three in 2025 (Lahari et al., 2025; Qi et al., 2025; Valle et al., 2025). The annual growth rate reflects increasing research interest in applying machine learning for heavy metal pollution classification.
Geographically, most studies originated from Asia (China, South Korea, India) and North America (United States). The geographic distribution is presented in Figure 3.
The most frequently targeted heavy metals were lead (Pb, 54.5%, n = 6), cadmium (Cd, 45.5%, n = 5), and mercury (Hg, 45.5%, n = 5), followed by copper (Cu, 36.4%, n = 4), arsenic (As, 27.3%, n = 3), chromium (Cr, 18.2%, n = 2), and nickel (Ni, 18.2%, n = 2). The frequency distribution is presented in Table 4.
Regarding sample matrices, water dominated the included studies (72.7%, n = 8), including surface water, tap water, lake water, seawater, and wastewater. Soil was the second most common matrix (18.2%, n = 2). No studies on sediment matrices met the inclusion criteria. The distribution of sample matrices is presented in Table 5.
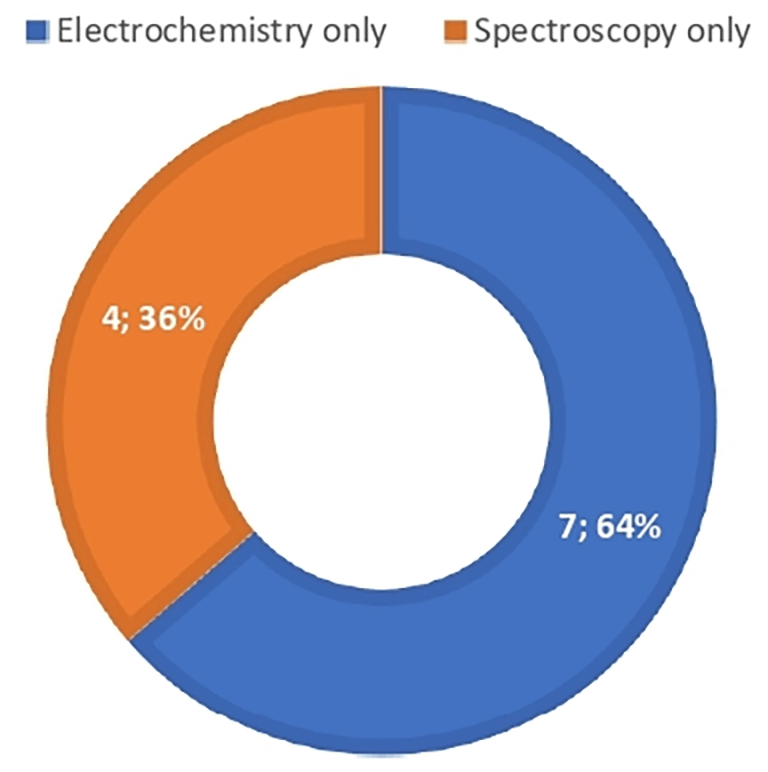
Among the 11 included studies, 8 (72.7%) used electrochemical techniques, while 4 (36.4%) used spectroscopic techniques (note: one study, Chen et al., used fluorescence spectroscopy). No study integrated both data types. The distribution of data types is presented in Figure 4.
Spectroscopic techniques used included vis-NIR spectroscopy (Hu et al., 2024; Qi et al., 2025), SERS (Park et al., 2022; Wei et al., 2023), and 3D fluorescence spectroscopy (Chen et al., 2025). Details are provided in Table 6.
Electrochemical techniques included cyclic square wave voltammetry (CSWV), differential pulse voltammetry (DPV), electrochemical impedance spectroscopy (EIS), and graphene field-effect transistor (GFET). Details are provided in Table 7.
Machine learning algorithms: The most frequently used algorithms were Support Vector Machine (SVM, 45.5%, n = 5), Random Forest (RF, 36.4%, n = 4), and Artificial Neural Network (ANN/MLP, 36.4%, n = 4). Deep learning algorithms (CNN, LSTM) appeared in 5 studies and demonstrated the highest performance (AUC > 0.99). The frequency distribution is presented in Table 8.
Preprocessing and feature extraction methods commonly included baseline correction, normalization (Z-score, Min-Max, area), PCA for dimensionality reduction, and Savitzky-Golay smoothing. A summary is provided in Table 9.
All 11 studies reported classification outcomes. Seven studies performed binary classification (contaminated vs. non-contaminated or above vs. below threshold), while four studies performed multi-class classification (metal type identification or concentration level classification). The performance metrics are summarized in Table 10.
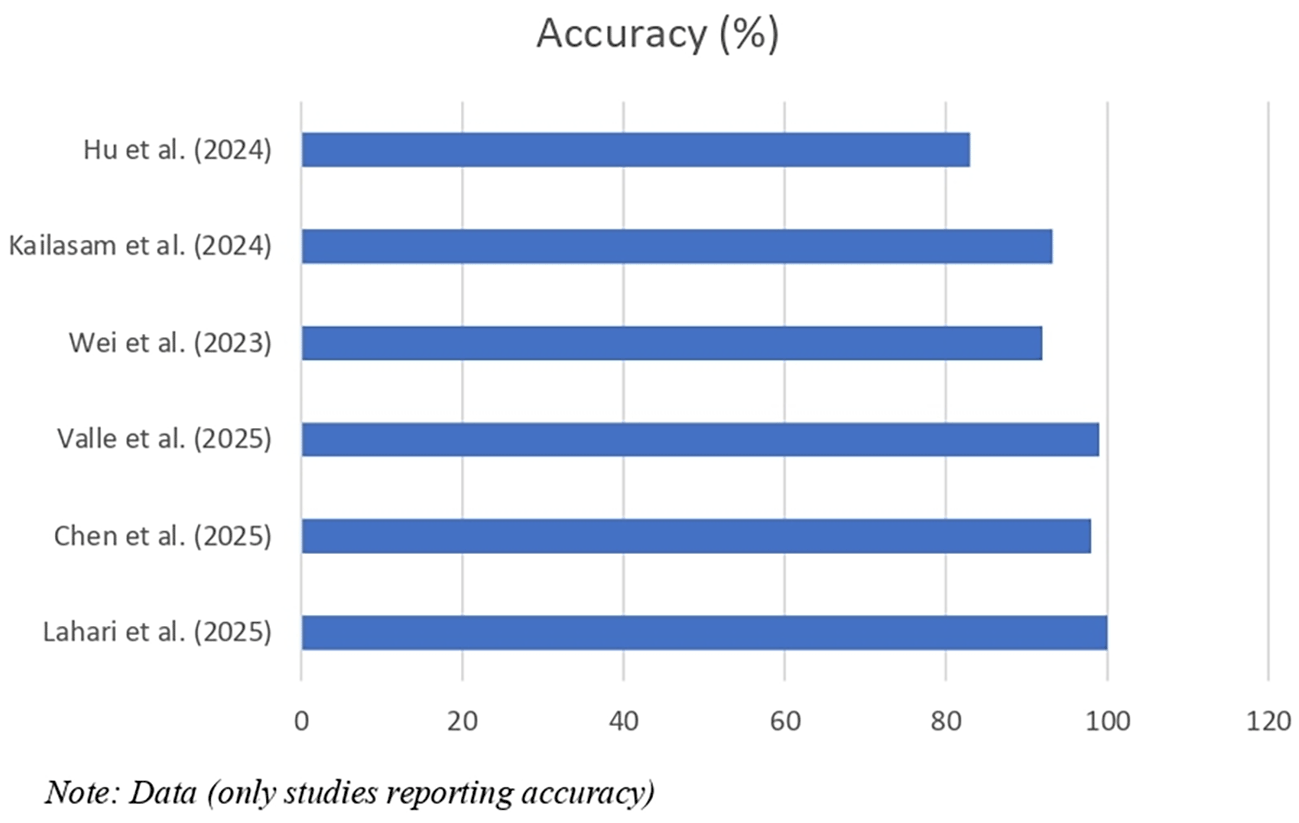
The best-performing models were deep learning algorithms (CNN, LSTM, ALSTM-FCN), achieving AUC values up to 0.999 and accuracy up to 100%. Ensemble methods (BalancedRandomForest) also demonstrated robust performance for imbalanced soil datasets. A comparison of accuracy across studies is presented in Figure 5, and representative ROC curves are shown in Figure 6.
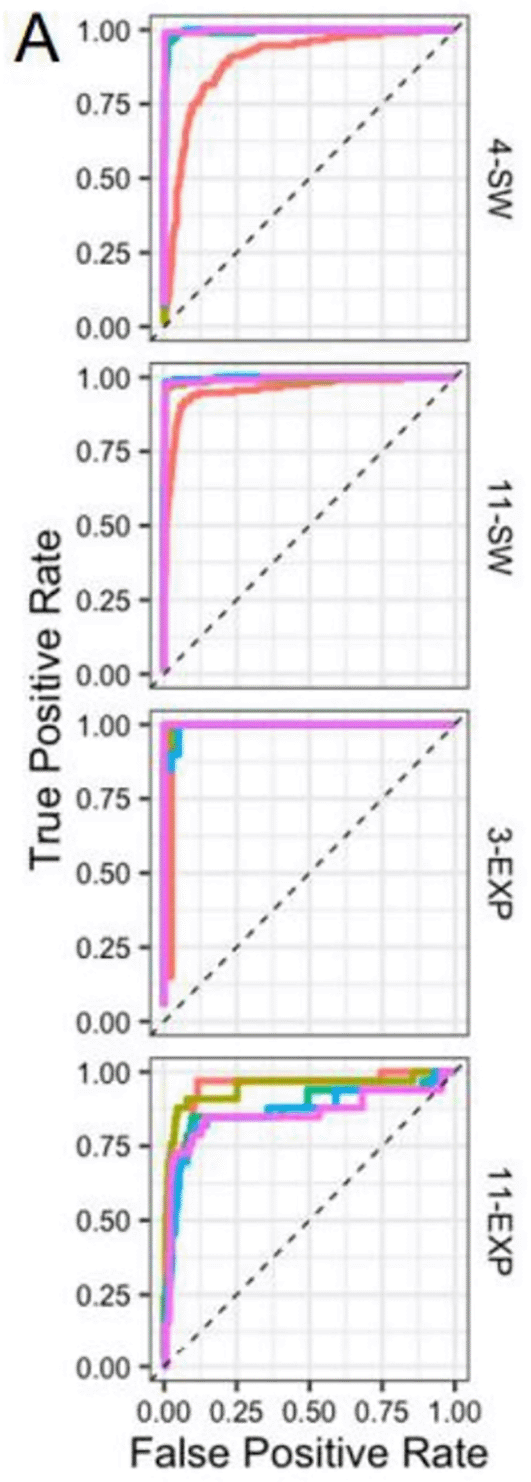
The ALSTM-FCN model achieved an AUC of 0.999.
None of the 11 included studies (0%) integrated spectroscopic and electrochemical data. All studies used only a single data modality: spectroscopy alone (n = 4, 36.4%) or electrochemistry alone (n = 7, 63.6%). Therefore, no evidence was available to assess whether data integration improves classification accuracy compared to single-modality approaches. The findings are summarized in Table 11.
The risk of bias assessment for the 11 included studies is summarized in Table 12 and visualized in Figure 7. Most studies showed low risk of bias across the six domains. Sample representativeness, reference standard, ML model validation, and reporting of performance metrics were generally adequate. Issues were identified in some studies regarding the justification of classification thresholds (e.g., Valle et al. (2025) did not specify a threshold) and handling of confounding factors (e.g., pH, temperature, matrix effects were sometimes not addressed). No study was excluded based on risk of bias.
From 825 initial records ( Table 2), only 11 studies ( Table 3) met all inclusion criteria. Key findings include:
1) Target heavy metals: Pb (54.5%) and Cd (45.5%) were the most frequently studied ( Table 4).
2) Sample matrices: Water dominated (72.7%); soil accounted for 18.2%; no sediment studies met inclusion criteria ( Table 5).
3) Data types: Electrochemistry (72.7%) was more common than spectroscopy (36.4%). No study integrated both data types ( Table 11; Figure 4).
4) Algorithms: SVM (45.5%), RF (36.4%), and ANN (36.4%) were most common ( Table 8). Deep learning (CNN, LSTM) achieved the highest performance (AUC up to 0.999) ( Table 10; Figure 6).
5) Classification performance: Accuracy ranged from 79.3% to 100%; AUC ranged from 0.846 to 0.999 ( Table 10; Figure 5).
6) Data integration: Zero studies (0%) integrated spectroscopic and electrochemical data ( Table 11), representing a significant research gap.
This systematic review identified only 11 studies that met the eligibility criteria for using machine learning (ML) to classify heavy metal pollution status based on spectroscopic or electrochemical data in environmental matrices. The most striking finding is that none of the included studies integrated spectroscopic and electrochemical data, despite the complementary nature of these two analytical modalities. This result is consistent with the observation that most ML applications in environmental chemistry still rely on single-source data (Lussier et al., 2020; Puthongkham et al., 2021). However, it also highlights a previously underexplored gap: the potential for data fusion to improve pollution status classification has not been systematically tested.
The predominance of lead (Pb, 54.5%), cadmium (Cd, 45.5%), and mercury (Hg, 45.5%) as target analytes reflects global regulatory priorities (US EPA, 2026; WHO, 2022) and the well-documented toxicity of these metals (Jaishankar et al., 2014; Tchounwou et al., 2012). However, the underrepresentation of chromium (Cr, 18.2%) and nickel (Ni, 18.2%) both common contaminants in industrial wastewater suggests that researchers may be prioritising metals for which spectroscopic or electrochemical signals are easier to obtain, rather than those most needed for environmental monitoring.
Water matrices accounted for 72.7% of included studies, while soil represented only 18.2%, and sediment none. This distribution is not surprising given that liquid samples are easier to analyse with portable sensors and require less complex preprocessing (Bansod et al., 2017). Nevertheless, soil and sediment are major sinks for heavy metals and pose long-term risks to food safety and groundwater (Ali & Khan, 2019). The scarcity of ML-based classification studies in solid matrices indicates a methodological gap that warrants further investigation, particularly for real-world contaminated sites.
Regarding ML algorithms, traditional models such as SVM (45.5%), RF (36.4%), and ANN (36.4%) remain the most commonly used. However, deep learning architectures (CNN, LSTM, ALSTM-FCN, FCN) achieved the highest reported performance, with accuracy up to 100% and AUC up to 0.999 (Dean et al., 2019; Hajzus et al., 2022; Lahari et al., 2025). This superiority is consistent with findings in chemometrics and sensor signal processing, where deep learning automatically extracts hierarchical features from raw or minimally preprocessed data. Yet, deep learning models typically require larger datasets. Among the included studies, only Qi et al. (2025) explicitly addressed class imbalance using SMOTE or resampling techniques, and none reported external validation on independent datasets from different sites or instruments. Thus, the reported high performance may be optimistic and not generalisable to smaller or more imbalanced real-world datasets.
Comparison with previous systematic reviews is instructive. Earlier reviews focused on heavy metal quantification (regression) or metal species identification (Borrill et al., 2019; Huang et al., 2023; Lussier et al., 2020). This review is the first, to our knowledge, to specifically target pollution status classification – a decision-oriented task that directly informs regulatory compliance and remediation actions. The fact that only 11 out of 154 screened studies met this criterion underscores that the field is still nascent. Moreover, none of the existing reviews have highlighted the complete absence of spectroscopic-electrochemical integration, which we report here as a major evidence gap.
The body of evidence has several intrinsic limitations that affect the strength and generalisability of our conclusions.
First, heterogeneity in classification tasks and thresholds. Some studies defined binary contamination based on WHO drinking water guidelines (e.g., Pb > 10 μg/L), while others used national or regional standards (e.g., Chinese soil quality standards, EU guidelines). Multi-class classification tasks varied widely: some distinguished metal types (Pb vs. Cd vs. Hg), others classified concentration levels (low, medium, high). This heterogeneity prevented meta-analysis and makes direct comparisons of performance metrics (e.g., accuracy) tenuous.
Second, incomplete reporting of performance metrics. While most studies reported accuracy and AUC, many omitted precision, recall, F1-score, or specificity. This is problematic for pollution status classification, where class imbalance is common (e.g., contaminated samples are often rare). Without recall or F1-score, it is impossible to assess whether a model simply predicts the majority class (non-contaminated) and still achieves high accuracy. Only Qi et al. (2025) and Hu et al. (2024) explicitly addressed class imbalance using SMOTE or balanced random forest.
Third, lack of external validation. All 11 studies used internal cross-validation or a single held-out test set from the same source. None reported external validation on an independent dataset collected from a different site, instrument, or temporal period. This raises concerns about overfitting and limits the real-world applicability of the models, especially for spectroscopic and electrochemical sensors that are sensitive to matrix effects (pH, temperature, ionic strength, organic matter).
Fourth, limited matrix diversity and geographical bias. Water matrices dominate (72.7%), but even within water, most studies used spiked laboratory samples or controlled natural water (e.g., seawater, tap water) rather than naturally contaminated environmental waters with complex backgrounds. Soil studies were few (Hu et al., 2024; Qi et al., 2025), and sediment studies were absent. Geographically, 8 of 11 studies originated from China, the United States, and South Korea, raising questions about generalisability to other regions with different soil types, water chemistry, and regulatory frameworks.
Fifth, risk of bias in classification threshold justification. Our risk of bias assessment ( Figure 7, Table 12) revealed that several studies did not clearly justify the choice of regulatory threshold for defining “contaminated” vs. “non-contaminated” samples. For example, Valle et al. (2025) tested concentrations down to 1 nM for Hg but did not explicitly classify based on a regulatory limit, making it difficult to translate their findings into a binary pollution status decision.
This systematic review has several methodological limitations that should be acknowledged.
Search strategy and database coverage. The search was limited to three databases (Scopus, SpringerLink, ScienceDirect) and did not include Web of Science, PubMed, or IEEE Xplore. Although the combination of Scopus and SpringerLink provides broad coverage of environmental science and analytical chemistry literature, relevant studies in engineering, materials science, or biomedical sensors may have been missed. The final search date was 6 May 2026, so studies published after this date are not included.
Language and publication bias. Only peer-reviewed articles in English were included. This may exclude relevant studies published in other languages or non-peer-reviewed sources (e.g., conference proceedings, preprints). The exclusion of non-English studies may introduce language bias, particularly since heavy metal pollution is a global issue with substantial research output from non-English speaking countries.
Risk of bias assessment. Although we used a tailored tool adapted from JBI and QUADAS-2, the assessment was qualitative and subjective for some domains (e.g., handling of confounding factors). No meta-analysis was performed due to heterogeneity, so we could not statistically assess publication bias using funnel plots or Egger’s test.
Data extraction limitations. Some studies did not report complete performance metrics, and we recorded these as “not reported”. It is possible that contacting authors could have retrieved missing data, but this was beyond the scope of this review.
For environmental monitoring practice and regulatory agencies, current ML-based classification models have demonstrated high accuracy (up to 100%) in controlled settings, but practitioners should exercise caution when applying these models to new environmental matrices without revalidation. The absence of integrated spectroscopic-electrochemical approaches means that field-deployable sensors still rely on a single modality, potentially missing complementary information. Regulatory acceptance of ML-based methods will require standardised protocols for model training, validation, and reporting. Agencies such as the WHO and EPA would benefit from developing guidelines for ML-based pollution status classification, including minimum requirements for external validation and handling of class imbalance.
For future research, six priorities emerge from this review: (1) integration of spectroscopic and electrochemical data through data fusion strategies, which remains untested for pollution status classification; (2) expansion to underrepresented matrices (soil, sediment) and metals (Cr, Ni, Zn) using real-world contaminated samples; (3) external validation on independent datasets from different geographical locations, instruments, and time periods; (4) standardised reporting of accuracy, precision, recall, specificity, F1-score, and AUC, with balanced accuracy for imbalanced data; (5) explicit handling of class imbalance using SMOTE, RUSBoost, or BalancedRandomForest; and (6) incorporation of explainable AI (XAI) methods to enhance trust and understanding of ML decisions. Addressing these gaps will accelerate the translation of ML-based sensors from laboratory prototypes to field-deployable, regulatory-accepted monitoring systems.
This systematic review identified only 11 studies that used machine learning for heavy metal pollution status classification based on spectroscopic or electrochemical data. Lead, cadmium, and mercury were the most frequently studied metals, and water was the dominant matrix (72.7%). Support Vector Machine, Random Forest, and deep learning architectures (CNN, LSTM) achieved high classification performance, with accuracy up to 100% and AUC up to 0.999. Critically, no study integrated spectroscopic and electrochemical data; all used only a single modality. This evidence gap precludes any conclusion on whether data fusion improves classification accuracy. Future research should prioritise multi-modal integration, external validation, and expansion to soil and sediment matrices.
Future research should prioritise the integration of spectroscopic and electrochemical data through data fusion strategies, as this remains the most critical gap identified in this review. No study to date has combined both modalities for pollution status classification, despite their complementary information. Additionally, researchers must expand to underrepresented matrices (soil and sediment) and heavy metals (Cr, Ni, Zn), using real-world contaminated samples rather than spiked laboratory solutions.
Methodologically, future studies should implement external validation on independent datasets from different geographical locations, standardise reporting of performance metrics (accuracy, recall, precision, F1-score, AUC), and explicitly address class imbalance using techniques such as SMOTE or BalancedRandomForest. Incorporating explainable AI methods will also enhance model interpretability and regulatory acceptance. Addressing these priorities will accelerate the translation of ML-based sensors from laboratory prototypes to field-deployable monitoring systems.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)