Keywords
SCKAN; SPARC; Chatbot; Flatmap; Large language model; FAIR; Anatomical visualization
This article is included in the Software and Hardware Engineering gateway.
SCKAN; SPARC; Chatbot; Flatmap; Large language model; FAIR; Anatomical visualization
The SPARC initiative consolidates connectivity and anatomical data across species to accelerate neuromodulation research and related applications,1 and is made accessible through the online SPARC Portal (SPARC, RRID:SCR_017041; https://sparc.science). Within this ecosystem, the SPARC Knowledge Graph includes the SCKAN database and its Natural Language Interface (NLI), which together allow users to query connectivity relationships between organs, nerves, and ganglia.2 SCKAN itself is registered as SCKAN (RRID:SCR_026088) and exposes curated connectivity relationships that can be reused across tools in the SPARC ecosystem. Q-SPARC is further listed as a resource on the SPARC Tools and Resources page (https://sparc.science/tools-and-resources/4A4tJH8PCbsrINgIlcH4ef), providing an official entry point for users to discover the tool.
Despite these strengths, the current SCKAN NLI exhibits several limitations that hinder its usability for researchers and educators.2 First, lack of multi-turn interaction: the platform currently supports only single-turn queries, preventing the accumulation of conversational context across interactions. This restriction reduces the depth and continuity of exploratory analysis, making it difficult for users to build upon prior results or maintain a coherent line of inquiry over time. Second, high latency in sequential queries: response delays disrupt the flow of sequential queries, undermining the efficiency of iterative workflows. Such latency is particularly problematic when researchers require rapid and adaptive questioning to refine or validate emerging hypotheses. Third, absence of spatial visualization: the lack of integrated Flatmap-based anatomical visualization limits the intuitive interpretation of spatial relationships in connectivity data. Without visual support, users face greater challenges in contextualizing anatomical insights within broader structural or functional frameworks.1 Fourth, restricted output formats: results are returned only as unstructured text, with no accompanying tabular or machine-readable formats such as CSV or JSON. This limitation constrains downstream computational processing, automated analysis, and integration with external analytical pipelines. Finally, insufficient FAIR alignment: the absence of persistent conversation history and weak integration with FAIR principles (Findable, Accessible, Interoperable, Reusable)3 reduces the platform’s capacity for reproducible, shareable, and interoperable research. These gaps hinder collaborative work and diminish the long-term reusability of outputs.
These limitations highlight the need for a more interactive, context-aware, and visualization-enabled interface for SCKAN connectivity exploration. Q-SPARC, a Python-based LLM-powered interface that layers retrieval-augmented generation and Flatmap visualization on top of SCKAN, addresses these gaps by enabling multi-turn conversational access, structured output generation, and integration with Flatmap anatomical visualization, while maintaining compatibility with the FAIR principles that underpin SPARC resources and the broader SPARC Portal ecosystem.
1. Overview of our solution
Q-SPARC integrates an LLM-powered conversational interface with a semantic indexing and retrieval pipeline,4,5,6 enabling users to submit natural-language queries and receive both narrative and structured outputs. The system supports multi-turn dialogue, maintaining conversational memory for context-aware reasoning and allowing users to build on prior queries. It also incorporates Flatmap visualization for anatomical context.
To clarify the model used in the implementation, Q-SPARC supports both local and cloud-hosted LLMs. In the hackathon prototype, we used Qwen2.5-72B as the default LLM, while GPT-4 and lighter-weight open-source models were also compatible in testing. This flexibility ensures adaptability across computational environments.
The tool is built on a modular architecture that separates query understanding, data retrieval, and visualization. This separation facilitates maintenance, scalability, and integration with other SPARC resources. To improve responsiveness, token and document flows are separated, asynchronous processing is applied, and local embedding caching minimizes repeated inference—together accelerating sequential queries without compromising reproducibility.
2. System architecture
Q-SPARC is implemented as a modular pipeline composed of multiple interconnected components, shown in Figure 1. The workflow begins when the user enters a natural language query into the input box. The query is processed by the Query Understanding LLM, followed by two-stage retrieval (embedding-based and reranking) from a local database. Relevant chunks are passed to the Reader LLM, which generates answers in both text and structured formats (JSON, CSV, TTL). The results can be displayed as text, tables, and Flatmap-based anatomical diagrams. Each module plays a specific role in transforming a natural language query into structured answers and visualizations.
• Interface: The process begins when the user enters a prompt into the input box on the web interface and clicks the submit button. The interface is designed to display three possible outputs: (1) a natural language text response, (2) a structured table, and (3) an optional Flatmap-based anatomical diagram.
• Query Understanding (LLM): The submitted query is processed by a local or server-hosted Large Language Model (LLM) responsible for interpreting the question and generating an internal search representation.
• First Retrieval (Embedding): The interpreted query is vectorized and matched against a local database of SCKAN knowledge using semantic embeddings. This first retrieval stage selects an initial set of candidate knowledge chunks.
• Second Retrieval (Reranking): The candidate chunks are reranked based on relevance, using additional scoring methods to ensure that the most relevant items are prioritized for the next stage.
• Reader (LLM): The top-ranked chunks are passed to a second LLM (Reader) which synthesizes the final answer, combining retrieved knowledge with reasoning capabilities. The Reader can produce both free-text explanations and structured outputs.
• Structured Output Formats: The system supports JSON, CSV, and TTL formats, ensuring that responses are interoperable with other tools and data pipelines.
• Visualization Adapter (Flatmap): When applicable, anatomical context is provided via Flatmap visualization, allowing users to see spatial relationships between structures described in the answer.
• Local Server and Data Flow: All processing can be run locally. Token flow and document flow, as shown in Figure 1, are separated to optimize efficiency and maintain modularity.
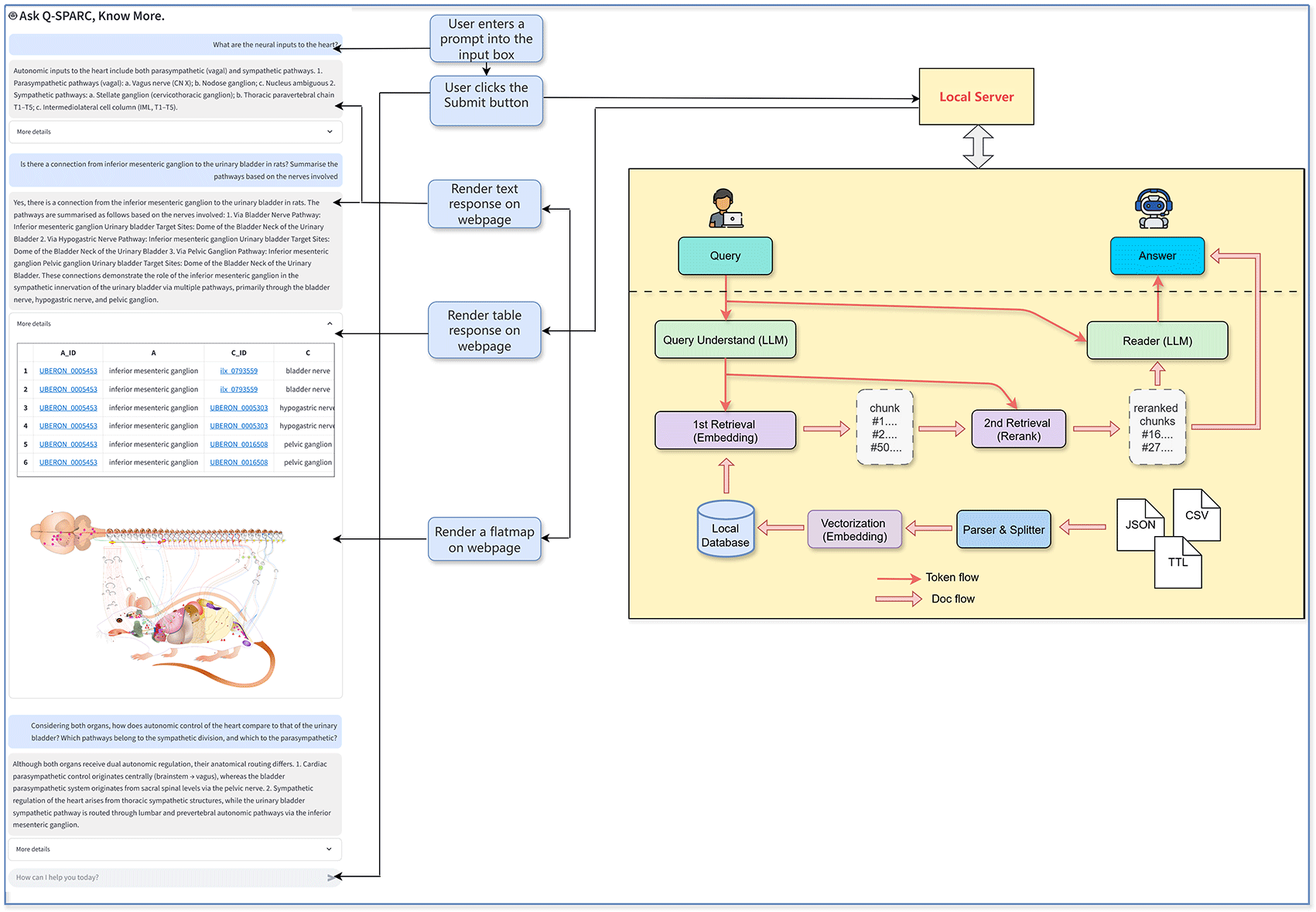
Overview of the Q-SPARC interactive chatbot framework integrating SPARC SCKAN connectivity with flatmap-based visualization. The system combines natural language input, knowledge graph querying and anatomical flatmap rendering to enable interactive exploration of neural connectivity.
General use:
Q-SPARC can be run locally or deployed on a server. The system requires Python 3.x and the dependencies listed in the accompanying requirements file. A containerized configuration is provided for reproducibility.
Using Q-SPARC:
A typical workflow involves:
1. Starting the backend service to handle data retrieval and processing.
2. Launching the frontend interface in a browser.
3. Entering a natural-language query, for example, “What are the input sources of the heart?”.
4. Viewing the outputs, which may include:
Tutorials:
The software is accompanied by a complete tutorial set that guides the user from installation through to advanced use. The tutorials cover:
• Installing dependencies and setting up the Python environment.
• Starting the backend and frontend components.
• Understanding the two-stage retrieval process.
• Generating and interpreting Flatmap visualizations.
Reproducibility:
All source code, documentation, and example data are distributed under an open-source license. The modular design allows adaptation for integration with other SPARC tools and datasets.
HZ: Data curation, Formal analysis, Writing – original draft.
DZ: Methodology, Writing – review & editing.
FX: Conceptualization, Software development, Validation, Project administration– review & editing.
MF: Conceptualization, Visualization, Project administration– review & editing.
YG: Supervision, Investigation, Writing – review & editing.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)