Keywords
neologism, lexical diffusion, scoping review, active learning, ASReview, bilingual evidence synthesis
neologism, lexical diffusion, scoping review, active learning, ASReview, bilingual evidence synthesis
Early neological research already raised questions about the spread, adoption, and survival of lexical innovations (e.g. Matoré, 1952; Guilbert, 1975), but the lack of large corpora and computational methods meant these processes could only be examined through small-scale or largely qualitative analyses. With the advent of large corpora and computational techniques, researchers can now trace neologisms’ trajectories with a level of precision that was previously impossible (e.g. Jiang et al., 2021). This methodological shift has opened the door to systematic investigations of why some lexical innovations diffuse widely while others remain marginal or disappear. Yet despite this expansion of empirical work, the field still lacks an integrated account of the linguistic and extralinguistic factors that shape these divergent outcomes.
Existing studies —whether classic (e.g. Quemada, 1971) or recent (e.g. Svanlund, 2018)—remain scattered across subfields and methodological traditions. Only two narrative reviews have attempted to catalogue factors influencing neological (non-)diffusion, both rooted in doctoral work (Kerremans, 2015; Kim, 2018). Their scope is limited: they focus primarily on terminology and linguistics, omit relevant NLP-driven research (e.g. Stewart & Eisenstein, 2018), and do not offer systematic or cross-linguistic comparison. Meanwhile, substantial new work has appeared since their publication (e.g. Urbatsch, 2015; Würschinger et al., 2018; Link, 2021), further widening the gap between available findings and existing syntheses.
These conditions make a state-of-the-art, cross-linguistic review both timely and necessary. Such a review can not only consolidate empirical results but also help bring coherence to a fragmented field by making theoretical claims, methodological practices, and operational definitions more comparable across studies, advancing earlier efforts to document and organize research on neology (e.g., Jean-Claude Boulanger, 1981; NeoCorpus1).
A type of knowledge synthesis (e.g. scoping review, systematic review) is called for rather than a traditional narrative review2, because the comparison of the treatment of an object in two different languages requires an exhaustive, systematic and reproducible methodology. A scoping review, rather than a systematic review, is the most appropriate approach because the objective of the present synthesis is to map how linguistic and extralinguistic factors associated with neological (non-)diffusion are conceptualized, operationalized, and investigated across the literature, rather than to estimate the direction or magnitude of a single effect. A preliminary search of Google Scholar and JBI Evidence Synthesis was conducted in January 2026, and no current or ongoing scoping or systematic reviews on this topic were identified.
Publication of a scoping review’s protocol offers both advantages to the research team and to the scientific community. For the research team, publication of the protocol favours (a) adjusting the review’s processes (scope, objectives, methodology, etc) in light of constructive peer feedback; and (b) reduction of mission creep (Haddaway et al., 2020), the gradual expansion of a study beyond its initial scope. Advantages for the scientific community include: (a) transparency of processes; (b) limitation of reporting bias; and (c) avoidance of study duplication and scientific waste.
The review aims to map the linguistic and extralinguistic factors examined in the existing literature in relation to the diffusion or non-diffusion of neologisms, across diverse languages, disciplines, and methodological traditions. This scoping review is guided by the PCC framework (Population, Concept, Context) recommended by JBI for scoping reviews.
The population/phenomenon consists of neologisms and lexical innovations examined in relation to their diffusion or non-diffusion.
The concept concerns the linguistic and extralinguistic factors associated with (non-)diffusion outcomes, including their conceptualization, operationalization, and reported directional influence.
The context includes the linguistic, methodological, disciplinary, historical, and publication contexts in which these factors are investigated.
On the basis of this PCC framework, the review will address the following research questions:
1. RQ1 — Factor landscape and reported effects: What linguistic and extralinguistic factors are linked in the literature to neological (non-)diffusion, and what roles (facilitating or inhibiting) are they reported to play in shaping neological trajectories?
2. RQ2 — Construct conceptualization and measurement: How are the core constructs—including (non-)diffusion factors, neologisms, and outcomes—defined and measured across the literature?
3. RQ3 — Investigative paradigms and contextual variation: How do these factors and their evidence architectures vary across methodological traditions, time periods, disciplinary boundaries, and linguistic varieties?
3.1.1. Concept
The concept targeted by this scoping review is “linguistic and extralinguistic factors associated with neological (non-)diffusion”. Linguistic factors are those relating to linguistic resources, operations, and structures broadly conceived. This includes factors such as word length, lexical semantics, and collocational networks. Extralinguistic factors refer first to properties of the denominated reality—its ontological status, distribution, and experiential salience—and, second, to the broader social context in which the neologism circulates. These include characteristics of the referent itself (e.g., real-world distribution, novelty, referential necessity) as well as sociocontextual elements such as the prestige of the coiner, the profile of early adopters, and attitudes toward the new term. Studies that do not investigate linguistic factors associated with (non-)diffusion or that investigate extralinguistic factors other than the referential, social and usage-based ones mentioned above (e.g. neurobiological factors, pedagogical factors) will be excluded from this review.
3.1.2. Languages
This scoping review will conduct an in-depth comparative synthesis of the relevant literatures published in two languages: English (the current scientific lingua franca; Tardy, 2004) and one language other than English (LOTE). Including a LOTE is methodologically important for two reasons. First, non-English literatures are frequently omitted from systematic-type knowledge syntheses (Neimann Rasmussen & Montgomery, 2018; Walpole, 2019), reinforcing forms of “epistemological domination” by English-language scholarship (Suzina, 2021). Second, excluding relevant LOTE sources may bias the review’s findings and reduce their interpretive usefulness. Including LOTE sources thus allows for the identification of language-specific conceptualizations and analytical traditions, thereby enriching the comparative synthesis and improving the interpretive robustness of the review.
Because the searches will be conducted separately using language-specific strategies—and therefore function operationally as two parallel scoping reviews—resource constraints required the selection of a single LOTE. French was chosen because (a) it is a major world language in which substantial scholarship on neology has been published since the mid-20th century (e.g., Georges Matoré, Louis Guilbert, Jean-François Sablayrolles); this tradition is also reflected in contemporary scholarly infrastructures devoted to neology, including Neologica — the only journal dedicated specifically to neology, which publishes predominantly French-language work — and the Congrès international de néologie des langues romanes (CINEO), (b) it is fully accessible to the research team, and (c) it is, together with English, one of Canada’s official languages, aligning with the review’s institutional context. Documents whose full text is written in languages other than English or French will be excluded. We acknowledge that other LOTEs, including Spanish (e.g. González Fernández, 2017) and Catalan (e.g. Nogué & Vila i Moreno, 2008), would also be highly relevant. This language restriction is discussed further in the Limitations section. Table 1 below summarizes the languages and temporal coverage considered in this review.
| Language | Approximate coverage in the literature | Notes |
|---|---|---|
| English | 1960s–2020s | Major body of work; includes linguistics + NLP |
| French | 1950s–2020s | Strong neology tradition; Neologica, Matoré, Guilbert, Sablayrolles |
| Other LOTEs (e.g., Spanish, Catalan) | unknown | Not included in the review but relevant (e.g., González Fernández 2017; Nogué & Vila i Moreno 2008) |
3.1.3. Neologisms
Much has and doubtless will yet be written on the subject of the “true” definition of neologisms (Oreški, 2021) and what does or does not qualify as such (for a discussion, see Cabré Castellvı et al., 2021). For this reason, we will not, for the purposes of this study, presuppose any particular definition of neologisms. The neologisms investigated or discussed in the to-be-included documents may thus be of any type –formal, semantic, syntagmatic, borrowings, phrases, etc. The focus of the document may be either synchronic (e.g. “neologisms in contemporary Swahili”) or diachronic (e.g. “neologisms in early 20th-century Wales”). However, to maintain a clear focus on contemporary theorization and empirical approaches to neological (non-)diffusion, we will include only documents that investigate neologisms in 20th- or 21st-century linguistic data or that develop 20th- or 21st-century theoretical discussions of neological (non-)diffusion. Studies whose empirical or theoretical focus lies exclusively outside this temporal window will be excluded.
3.1.4. Types of documents
This scoping review will consider peer-reviewed documents of all types, such as empirical articles, edited volumes and monographs. The following types of “grey” literature will be considered as well: doctoral dissertations, and conference proceedings.
Purely theoretical or expository works will be eligible only when they make a substantive original conceptual contribution, such as proposing a new framework, redefining key constructs, refining taxonomies, or introducing novel relationships among (non-)diffusion factors. Works that restate existing frameworks without conceptual or empirical extension will be excluded. We acknowledge that a continuum often exists between the reuse of existing frameworks and the introduction of novel contributions, making the boundary difficult to draw. In such cases, eligibility will be determined based on explicit evidence of conceptual or empirical extension (e.g. new definitions, relationships, operationalizations, or data), with decisions applied consistently and documented in the audit trail.
Empirical works will be eligible even when they build on previously established frameworks, provided they contribute original data, new operationalizations, novel empirical testing, or new evidence regarding neological (non-)diffusion factors.
3.1.5. Date of publication
Documents published since January 1952 will be included. This date was chosen because it is –to the best of our knowledge— the year in which the first document directly related to several of our research questions was published (i.e. Matoré, 1952).
The proposed scoping review will be conducted in accordance with the Joanna Briggs Institute (JBI) methodology for scoping reviews, and both its reporting and the presentation of its results will adhere to the PRISMA-ScR guidelines (i.e. Preferred Reporting Items for Systematic Reviews and Meta-Analysis: Extension for Scoping Reviews; Tricco et al., 2018).
3.2.1. Search strategy
In alignment with the PCC framework (Population/Phenomenon, Concept, Context) used to structure the review questions (see Section 2), the search strategy was developed around two core conceptual blocks: (1) neologisms, corresponding to the population/phenomenon of interest, and (2) lexical diffusion, corresponding to the central concept under investigation.
Initial feasibility testing suggested that explicitly searching for terms such as factor, predictor, or determinant substantially reduced sensitivity, as the relevant literature tends to discuss the observable outcomes of diffusion (e.g., spread, uptake, conventionalization, implantation, success) rather than explicitly naming the explanatory factors themselves in titles, abstracts, or keywords.
Consequently, the final search strategy prioritized terms referring to neologisms and their (non-)diffusion-related outcomes, allowing the explanatory factors to be identified during the screening and data charting stages rather than through direct retrieval terms.
Near-synonymous terms for these two conceptual blocks (neologism and (non-)diffusion) were identified through preliminary searches in English- and French-language sources and refined iteratively in collaboration with the research team and information specialist. A selection3 of these terms are presented in Table 2.
The full search strategy will aim to locate both published and unpublished documents. The search strategy, including all identified keywords and index terms, will be adapted for each included database and/or information source.
To support full reproducibility, four of the complete database-specific search strategies, including syntax adaptations across bibliographic sources, are openly available in the project’s OSF supplementary repository (https://doi.org/10.17605/OSF.IO/GJY39).
3.2.2. Sources of evidence selection
Many studies have emphasized that exploiting multiple databases is necessary to maximize literature coverage in a systematic-type review (Gusenbauer, 2022; Gusenbauer & Haddaway, 2020; Pozsgai et al., 2021). We have thus selected several general databases to be searched:
• Web of Science (core collection as provided by Université Laval; Editions = SCI-EXPANDED, SSCI, AHCI, CPCI-S, CPCI-SSH, BKCI-S, BKCI-SSH, ESCI, CCR-EXPANDED, IC);
• Linguistics and Language Behavior Abstracts (LLBA) (Proquest);
• Communication and Mass Media Complete (EBSCO);
• Sociological abstracts (Proquest);
• Google Scholar;
French-language databases to be searched include:
The study selection process will be documented using a PRISMA 2020 flow diagram; the version in Figure 1 reflects the ongoing status of the review.
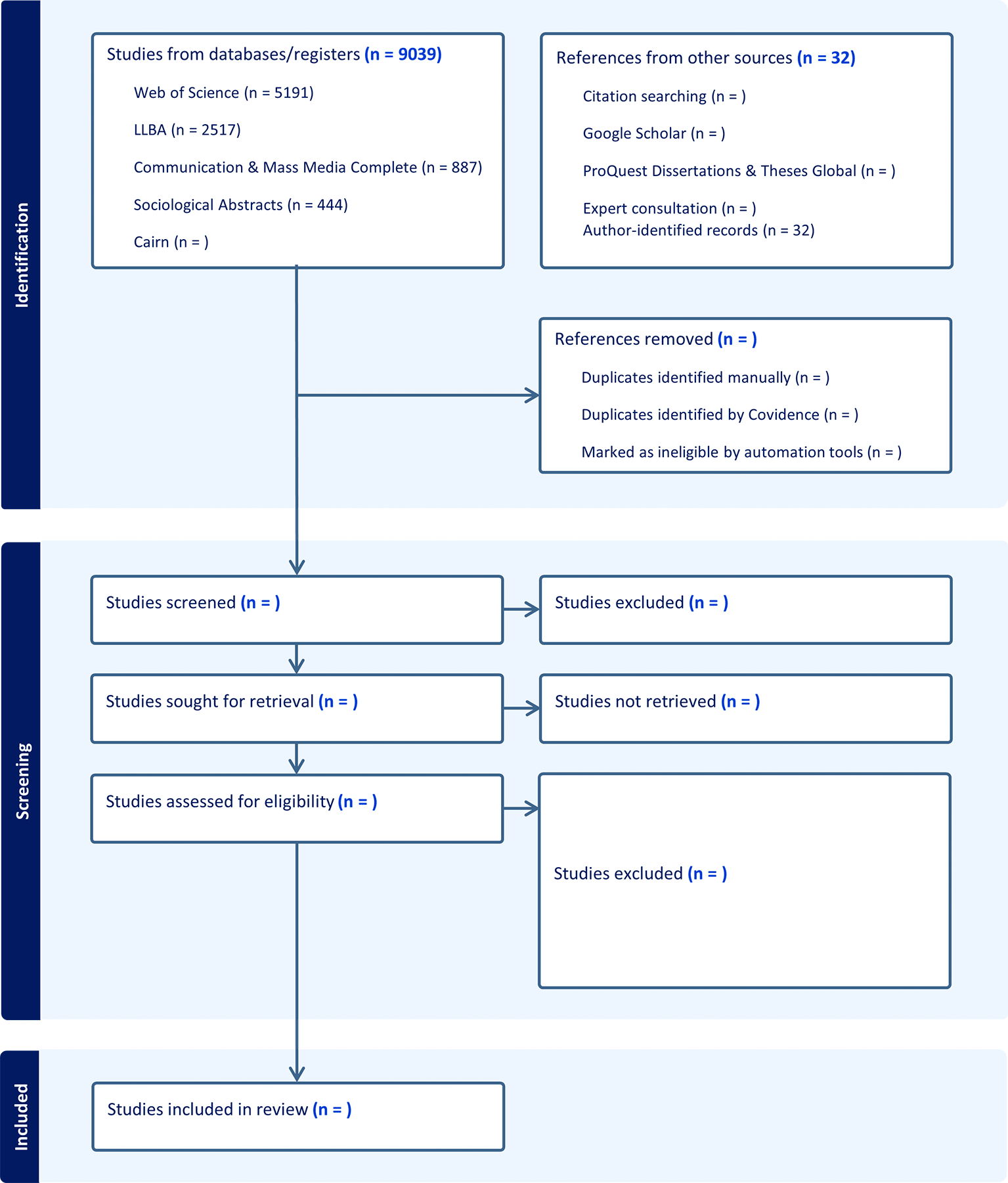
Figure 1. The diagram summarizes the identification, deduplication, screening, eligibility assessment, and inclusion stages that will be used to document the selection of studies examining factors associated with neological diffusion and non-diffusion. Database and supplementary source counts shown are preliminary and will be updated during the review process. The diagram is adapted from the PRISMA 2020 statement for systematic reviews and scoping reviews.
3.2.3. Consultation of experts in neology
To enhance the completeness of the review and to identify potentially relevant sources not captured by database searches, a small number of domain experts in neology will be consulted. This consultation will be facilitated through existing professional networks in the field, including ENEOLI – The European Network On Lexical Innovation (www.eneoli.eu). Experts will be asked to suggest key publications, keywords or research strands relevant to neological (non-)diffusion. Any additional sources identified through this process will be screened against the same eligibility criteria as all other records and will be reported transparently.
Because this review involves unusually large and conceptually diverse evidence bases, the workflow requires additional structure. The next section explains how human judgment and machine-learning prioritization are combined to manage screening at scale. Given the anticipated volume of records and the conceptual complexity of the planned synthesis, this review is operationally treated as a large scoping review (see Alexander et al., 2024), requiring enhanced piloting, semi-automated prioritization, and explicit version control procedures. The workflow for evidence selection, screening, and data extraction integrates human judgment with machine-learning-based prioritization to manage a large evidence base while ensuring that all eligibility decisions remain fully human-led.
3.3.1. Deduplication and record preparation
Duplicate detection will be performed using a reproducible Python workflow built around the BibDedupe library (Wagner, 2024). Exact DOI matches and highly confident metadata-based matches will be linked automatically. Duplicate clusters lacking persistent identifiers or presenting conflicting bibliographic fields will undergo manual verification by the first and fourth authors (GFM and DD) prior to final record consolidation. Records will be managed and exchanged in standard formats (e.g., RIS, CSV).
3.3.2. Title and abstract screening
Following a pilot test, titles and abstracts will then be screened by one or more independent reviewers against the inclusion criteria for the review. To reduce the manual burden associated with screening a very large number of records, screening prioritization (AI-assisted screening) will be incorporated into the workflow. This approach relies on active learning, a machine-learning technique increasingly used in knowledge synthesis (Gates et al., 2019) in which the algorithm iteratively estimates the likely relevance of unscreened records on the basis of prior human inclusion and exclusion decisions. As screening progresses, these predictions are continuously updated, allowing the most potentially relevant records to be presented earlier in the screening process. The screening process will continue until a conservative stopping criterion is reached, indicating that the remaining unscreened records are highly unlikely to contain additional relevant studies (see discussion of the SAFE protocol - a stopping rule for active learning–assisted screening based on recall estimation and yield stabilization- at the end of this subsection).
Screening prioritization will be incorporated into the workflow following the general logic of the SYMBALS protocol (van Haastrecht et al., 2021) (Systematic Review Methodology Blending Active Learning and Snowballing), in which active learning is embedded within a broader, human-directed evidence-selection pipeline; see Figure 2 below.
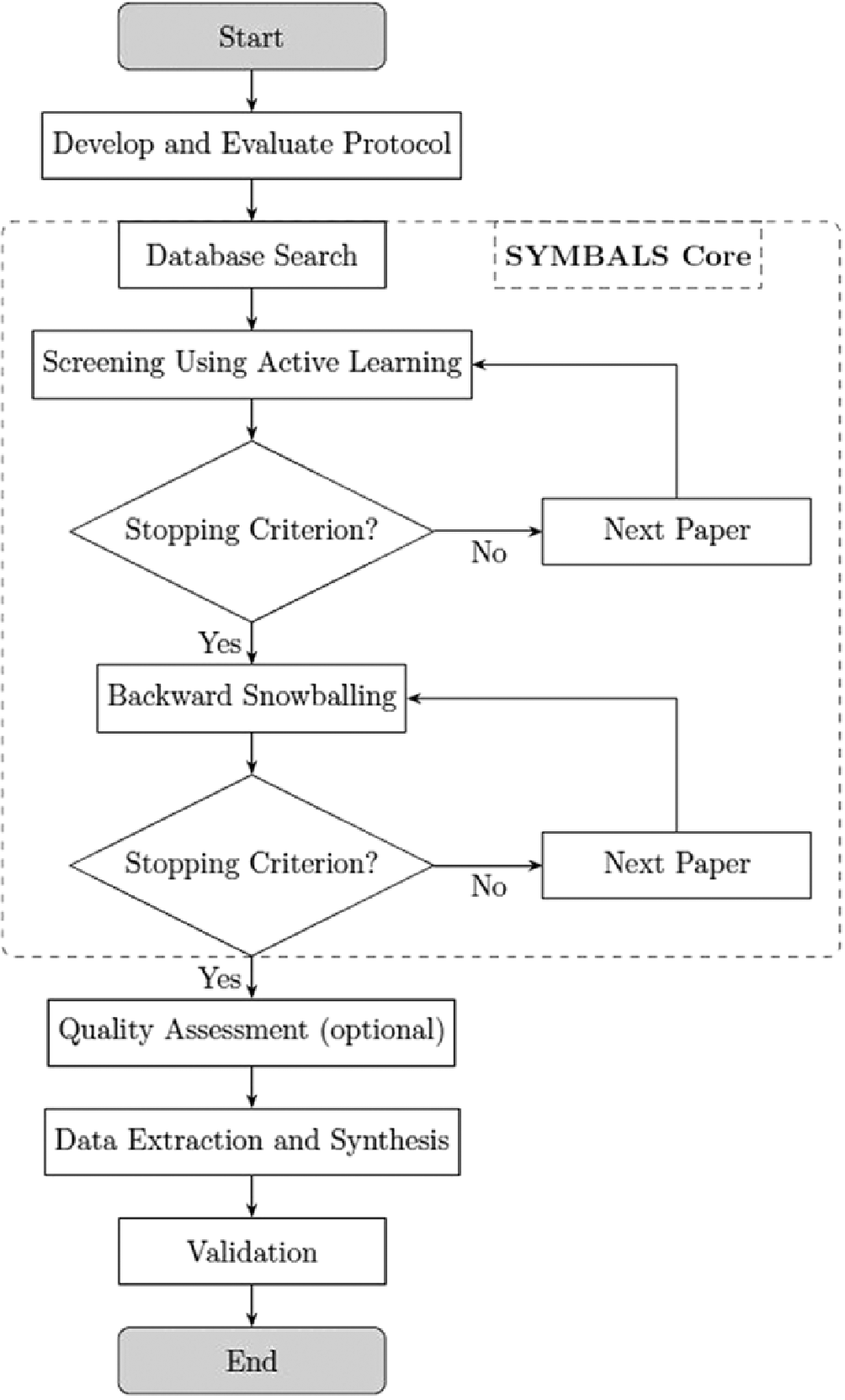
Figure 2. SYMBALS-inspired active-learning screening workflow underlying the study selection process used in the present scoping review. The figure illustrates the iterative screening and backward snowballing components of the workflow and their associated stopping criteria. Additional procedures used in the present review, including forward citation chaining, are described in the main text. Adapted from van Haastrecht et al. (2021) under the Creative Commons Attribution 4.0 International (CC BY 4.0) license.
This active-learning cycle, combining manual assessment, model updating, and relevance-based prioritization, continues until the stopping criterion is reached. Following this stage, backward citation chaining (locating further sources by reviewing the references cited in included studies) is conducted on included records, with additional screening performed until a second stopping criterion is met. We will also perform forward citation chaining (i.e. identifying additional relevant studies by examining later publications that cite a document already included in the review). The final set of included studies then proceeds to data extraction and synthesis. All inclusion and exclusion decisions are stored throughout the process to ensure a complete and auditable screening trail.
Because screening will involve thousands of records, the workflow requires a prioritization method that reduces manual burden while preserving recall. The active-learning (prioritization; i.e. relevance-ranking) software selected for this review is ASReview v3 (van de Schoot et al., 2021), an open-source active-learning tool that prioritizes records by estimated relevance on the basis of prior reviewer decisions. Importantly, ASReview does not make inclusion or exclusion decisions; it only determines the order in which records are presented for human screening.
Because no single ASReview stopping criterion has been shown to generalize reliably across datasets (Kempny et al., 2025), we will adopt the SAFE (Semi-Automated Full Evidence) procedure; (Boetje & van de Schoot, 2024), which combines multiple safeguards to reduce the risk of premature stopping in large-scale screening tasks. Specifically, SAFE structures screening into four stages:
(1) an initial random screening phase to generate a training set of relevant and non-relevant records;
(2) active-learning-based prioritization, in which human reviewers screen records in the order suggested by the model;
(3) model switching, in which a second classifier is used to identify potential false negatives; and
(4) a final quality-control pass to ensure that highly relevant studies have not been systematically missed.
Machine-assisted screening will continue until SAFE’s conservative stopping criteria are met. In practice, this entails continuing screening until successive batches of records yield no new inclusions and the remaining records are consistently ranked as low relevance by the model, with additional safeguards provided by model switching and a final quality-control pass. All inclusion and exclusion decisions will be made manually by human reviewers.
3.3.3. Full-text screening
Potentially relevant sources will be retrieved in full and their citation details imported into Covidence. Records retained following title and abstract screening will proceed to full-text assessment. Documents not available in machine-readable format will be handled as described in the data extraction stage (Section 3.3.4). Full-text screening will be conducted manually by human reviewers against the predefined eligibility criteria. Any disagreements arising at this stage will be resolved through discussion or consultation with an additional reviewer. Reasons for exclusion at the full-text stage will be recorded and reported in the final PRISMA flow diagram.
3.3.4. Human-led data extraction with AI-assisted second evaluation
All studies retained after full-text screening will proceed to the data extraction stage. For documents not available in machine-readable format, OCR will be applied where feasible using ABBY FineReader (build 16.0.14.7295); otherwise, relevant information will be extracted manually. Data extraction will be performed by at least one human reviewer using the custom extraction form described in Section 3.4.1. In line with guidance for large scoping reviews emphasizing extensive piloting and early troubleshooting (Alexander et al., 2024), the charting instrument is currently in its third calibrated iteration following preliminary pilot extraction exercises. The custom extraction form was developed in accordance with Büchter et al.’s (2021) recommendations. Extracted data will include (i) information about the neologisms investigated in the included documents, (ii) the linguistic and extralinguistic (non-)diffusion factors identified, (iii) methodological characteristics of the included studies, and (iv) key document metadata (e.g., publication year, document language). The principal variables included in the data-charting instrument are summarized in Table 3. The complete coding framework, including variable definitions, coding rules, and extraction procedures, is specified in a separate project codebook that will be made available through the project OSF repository (https://doi.org/10.17605/OSF.IO/Y6UEB).
Extracted and processed data will be stored in structured formats (e.g., CSV, JSON) to support downstream analysis. The extraction form may be refined iteratively during the charting process, and all modifications will be documented in the final review. In line with methodological guidance for large scoping reviews emphasizing consistency and manageability of high-volume charting workflows (Alexander et al., 2024), categorical variables will use predefined controlled response sets wherever possible to support harmonization across reviewers and AI-assisted charting.
To support data quality under resource constraints, AI-assisted extraction will be used as a secondary evaluation layer. Recent validation studies suggest that large language models (LLM) can function as reliable second raters for data extraction in evidence syntheses (Motzfeldt Jensen et al., 2025; see also Frazer-McKee & Gignac, submitted). In the present workflow, AI-assisted extraction will not replace human extraction but will serve exclusively as a supplementary quality-control procedure, used to identify potential omissions, inconsistencies, or coding divergences in selected fields. AI-assisted second rating will be conducted using a Large Language Model (LLM), such as Microsoft Copilot or ChatGPT. The LLM will be used to generate independent extraction suggestions based on structured prompts. All prompts used for AI-assisted extraction will be documented in the OSF repository. Their performance will be assessed during calibration of the extraction instrument and iteratively refined based on agreement with human extraction. Given documented limitations in recall and the risk of hallucinated outputs (Flemyng et al., 2025), all final extraction decisions will remain human-led.
A subsample of extracted studies will additionally undergo independent verification by a second human reviewer (DD and NG). Discrepancies —whether between human reviewers or between human and AI-assisted extractions— will be resolved through discussion or, where necessary, consultation with an additional reviewer. This multi-layered workflow is designed to maximize feasibility, transparency, and data quality at scale.
3.4.1. Data analysis
Analyses will be based on the data extracted using the data-charting instrument, with the primary emphasis placed on mapping the linguistic and extralinguistic factors associated with neological (non-)diffusion, including how these factors are defined, operationalized, and investigated across the literature. Building on this central mapping objective, additional descriptive and comparative analyses will be undertaken to examine broader patterns across key metadata dimensions and to identify evidence gaps where relevant. Consistent with the aims of a scoping review, no meta-analysis (i.e. statistical synthesis of effect sizes across studies) will be conducted.
1. Diffusion-factor mapping. All linguistic and extralinguistic factors will be inventoried and subsequently grouped into higher-level categories during the analysis stage using an inductive classification approach. To make sense of the wide variation in how key constructs are defined, we apply a structured analytic approach. Given prior observations of definitional heterogeneity in the terminology and neology literature (Quirion & Lanthier, 2006), definitional statements will be decomposed into atomic propositions and organized into proposition matrices, in which rows represent definition instances and columns represent conceptual features. Where sufficient definitional recurrence is observed within a factor family, these matrices will additionally support Agglomerative Hierarchical Clustering, a bottom-up clustering method that groups similar definitions based on shared conceptual features, to identify recurrent definitional families, partial overlaps, and zones of conceptual convergence and disagreement. We will also report (i) the frequency with which each factor or factor category is investigated and (ii) which factors are most commonly examined jointly.
2. Outcome definitions and operationalizations. We will catalogue how studies define and measure neological “(non-)diffusion” (e.g., success/uptake/conventionalization/failure), and relate outcome types to study designs and factor types.
3. Cross-linguistic, cross-disciplinary, and diachronic comparisons. Using metadata dimensions including publication language, broad research field, study design, and major time periods, we will examine differences in factor selection, operationalizations, outcome definitions, and methodological approaches across the included literature, where the volume and distribution of included studies permit meaningful comparison. Higher-order interaction comparisons across multiple dimensions will be considered exploratory and only possibly undertaken where dense and interpretable study distributions permit.
4. Evidence gaps. We will identify under-studied factors, rare factor combinations, recurrent methodological limitations, and poorly covered contexts (languages/domains/data types), and summarize these narratively and visually (tables/figures/evidence-gap maps).
Findings will be summarized using a combination of narrative synthesis, descriptive frequency mapping, and visual evidence-mapping approaches consistent with scoping review methodology.
3.4.2. Data presentation
Following recommendations for large scoping reviews to avoid “death by tables” and improve interpretability of complex evidence maps (Alexander et al., 2024), results will be presented through visual knowledge-mapping approaches (e.g., alluvial diagrams, heatmaps, and conceptual network maps), particularly for factor taxonomies and definitional disagreement. Best data visualization practices, such as those identified by Schwabish (2021) and Aigner et al. (2011), will be adhered to. For instance, per best practice, data visualizations will seek to summarize multiple studies rather than to present studies individually (Lockwood et al., 2019). All data visualizations will be described fully, and these descriptions will be related explicitly to the study’s research questions.
3.4.3. Data availability
All data, intermediary data, scripts, and outputs (included, intermediary, and discarded) will be stored in the Open Science Framework (OSF; www.osf.org), a long-term, DOI-issuing digital archive (Foster & Deardorff, 2017). The URL of this repository is provided in Sections 6 and 7 and will be included in the final review.
Data and code will be shared using accessible formats (e.g., .csv for data, .txt for scripts), accompanied by a detailed README file describing the structure of the repository, the contents of each file, and the study’s processing pipeline, following established recommendations for reproducible research documentation (Vilhuber et al., 2022). All code, prompts, and processing steps will be documented and made available to ensure transparency and reproducibility.
We aim to submit the scoping review for publication in a peer-reviewed journal in Spring of 2027.
At the time of protocol submission, database feasibility searches and search-string piloting have been completed. Preliminary calibration exercises for the data-charting instrument have also been conducted. Following pilot extraction on a purposive sample of 12 seed articles, the charting framework has reached its third calibrated iteration. Title and abstract screening have not yet begun.
The factors underlying neological (non-)diffusion are of interest to both fundamental and applied research, including terminologists and organisations involved in language management and planning. However, the existing literature remains structurally fragmented, with considerable heterogeneity in how such factors are conceptualized, operationalized, and empirically investigated (Quirion & Lanthier, 2006). Systematically comparing and collating these factors is therefore a necessary step toward structuring the field. Bringing them together within a common analytical framework makes it possible to identify patterns of convergence and divergence, detect gaps in the literature, and clarify the underlying conceptual space. This, in turn, provides a stronger basis for study design —including the examination of interactions between factors— and contributes to a closer alignment between theoretical claims and empirical practices. The review thereby seeks to render the existing evidence base more comparable and cumulatively usable, and to provide a reference framework for future empirical and applied work.
This proposed scoping review has several strengths, including:
(i) adherence to a well-established methodological framework for scoping reviews;
(ii) the development and adaptation of the search strategy and the study’s protocol in collaboration with an experienced academic librarian specialized in knowledge synthesis methods;
(iii) coverage of the relevant literatures published in two major world languages over a 74-year period;
(iv) a replication package;
(v) the implementation of a human-supervised AI-assisted workflow to support the management and analysis of a large-scale scoping review;
(vi) pre-registration and publication of the study’s protocol.
To contextualize the methodological choices made above, we outline several limitations that readers should keep in mind.
First, the review is restricted to documents written in English and French. This decision reflects both the study’s comparative design and resource constraints, but limits coverage of relevant literature in other languages.
Second, the screening process may miss a small proportion of relevant documents. Screening will be conducted primarily by a single reviewer and supported by semi-automated prioritization, both of which are known to reduce recall relative to dual independent screening (Gartlehner et al., 2020; Gates et al., 2019; Waffenschmidt et al., 2019; Yu et al., 2018; Yu & Menzies, 2019). However, this limitation is mitigated by conservative stopping criteria and citation chaining. Moreover, perfect recall is less critical in a scoping review, which aims to map a field rather than provide effect estimates based on an exhaustive search of the literature.
Third, parts of the data charting will be conducted by a single reviewer (GFM), which may increase the risk of extraction errors (see Buscemi et al., 2006; Horton et al., 2010; Lee et al., 2021; Mathes et al., 2017). To mitigate this, a multi-layered quality-control workflow will be implemented, including AI-assisted second rating and targeted human verification.
Finally, the review is subject to search-related limitations arising from terminological variation across disciplines and time periods. Despite efforts to construct a comprehensive search strategy, some relevant terms or studies may not be captured.
This protocol concerns the synthesis of evidence drawn exclusively from publicly available documents and does not involve human participants, identifiable personal information, or animals. In accordance with Université Laval’s local research ethics policies, research ethics board approval is not required.
Given the iterative nature of this large-scale scoping review, minor refinements to operational procedures (e.g., search syntax adaptations across databases, calibration procedures, or extraction-form clarifications) may become necessary. Any substantive amendments to the protocol will be transparently documented in the final review, including the nature of the change, its justification, the date implemented, and the review stage affected.
A generative AI tool (ChatGPT 5.3, OpenAI) was used in a limited capacity to assist with language editing, phrasing refinement, and formatting support. It was not used to generate original scientific content, conduct analyses, determine eligibility decisions, or make methodological decisions. All content was critically reviewed and validated by the authors.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)