Keywords
population model, pharmacokinetics, Akaike, information theoretic criterion
population model, pharmacokinetics, Akaike, information theoretic criterion
Population data consist of one or more measurements in two or more individuals. Such data can be characterized by mixed-effects models, where the mixed effects consist of fixed and random effects. Fixed effects are, for example, the times at which the measurements are obtained, and covariates such as demographic characteristics of the individuals. When mixed-effects models are fitted to population data, the question arises how many of those effects should be incorporated in the model. This is the so-called problem of variable selection1.
One strategy is to observe the change in goodness-of-fit by adding one more parameter and testing the significance of that change2. In the maximum likelihood approach, the objective function value (OFV), being the minus two logarithm of the likelihood function, is minimized. To attain a p-value of e.g., 0.05 or less, the decrease in OFV, when adding one parameter, should be 3.84 or more2.
Another strategy is to apply Akaike's information theoretic criterion (AIC), which can be written as
where D is the number of parameters in the model1–4. The model with the lowest value of AIC is considered the best one. In the case of just adding one parameter, the OFV needs to decrease only 2 points or more to be incorporated in the model, so the associated p-value > 0.05 seems too high to justify this strategy.
When additional model parameters are incorporated, the significance of one model parameter might change, but the interpretation of AIC does not4. However, when multiple significance tests are performed, the significance level of each individual test should be corrected to a lower value, so a decrease of 2 points for one parameter does again seem to be too low.
Even if the strategy of using AIC leads to optimal variable selection, the question arises if this is also the case when using mixed-effects models. In theory, the model that is best according to AIC is the one that minimizes prediction error3,5; and this is also true for a mixed effects model when predicting data for individuals for which no data have been obtained so far5.
In the literature, simulation studies have assessed the performance of AIC in selecting the model with the lowest prediction error, but to our knowledge these were never done for population data. In this article, we will define a toy pharmacokinetic model and observe the performance of AIC when adding fixed effects to this model, as well as when adding interindividual variability.
Consider the following function y(t), an infinite sum of exponentials, and its relationship with a (negative) power of time6:
Figure 1A shows that this function looks like a typical pharmacokinetic profile after bolus administration. This model is to be regarded as a toy model, because we do not expect it to adequately describe pharmacokinetic data, although variations of power functions of time have been shown to fit pharmacokinetic data well6. Here we will use the fact that if we approximate y(t) = 1/t by the following sum of M exponentials with K nonzero coefficients α and M fixed parameters λ (as chosen in the next subsections):
that with M time instants tj, we would need no less than K = M exponentials to obtain a perfect fit. Moreover, with noisy data, it might be that for K < M an optimal fit is obtained in the sense that the associated prediction error of the model is minimal. Figure 1B shows how eleven (in this case error-free) samples from this function can be approximated by sums of exponentials.
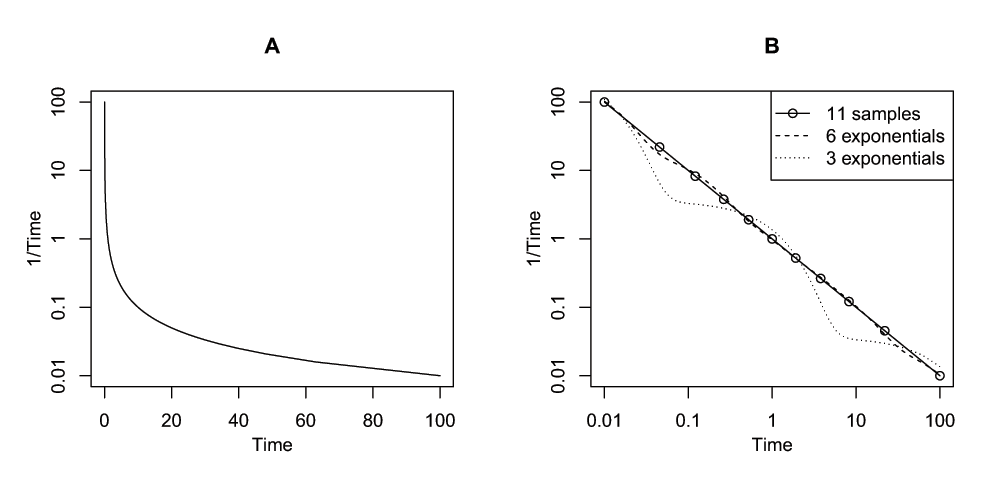
A: function y(t) = 1/t, and B: approximations obtained by fitting six and three exponentials to the depicted eleven samples. Note the log-lin and log-log scales for panels A and B, respectively. Time has arbitrary units.
In the following, the time instants tj, j = 1, …, M, centered around 1, were chosen within [1/tmax,tmax] according to
with γ = log(tmax)/log(M); tmax was set to 100 (see the time axis of Figure 1B for an example with M = 11). Simulated data were generated via
where εj denotes Gaussian measurement noise with variance σ2. The M time constants λ were fixed according to λm = 1/tm, m = 1, …, M. In this setting the model eq. (3) can be fitted to simulated data using weighted linear least squares regression, with weight factors ω(tj) = 1/tj (note that no precaution is needed against ε ≤ –1).
Population data consisting of N individuals were simulated via
where ηi denotes interindividual variability with variance ω2. The nonlinear mixed effects model for the population data was then written as:
Note that with N > 1, a perfect fit is no longer obtained with K = M, because the εi,j are generally different for different i (individuals).
Simulation data were generated via eq. (6), with random generators in R7. Model fitting was also done in R, with function "lm()" from package "stats", except for nonlinear mixed-effects model fitting for simulated data with ω2 > 0, which was done in NONMEM version 7.3 (beta version a6.5)8. Parameters α (see eq. (7)) were not constrained to be positive, so that it was not possible for parameters to become essentially fixed to zero, reducing the dimensionality of the model. Prediction error (ν2) was calculated with
using predictions based on eq. (7) with the random effects ηi = 0, and validation data zi(tj) also generated via eq. (6), but with different realizations of εij and ηi. The objective function OFV was also calculated at the estimated parameters using the validation data, denoted OFVv, which should on average be approximately equal to Akaike's criterion (see Supplementary material). OFVv was compared with AIC and also with Akaike's criterion with a correction for small sample sizes (AICc)4:
The above criteria were normalized by dividing them by the number of observations, and averaged over 1000 runs (unless otherwise stated; and runs where NONMEM's minimization was not successful were excluded). For plotting purposes, 95% confidence intervals or confidence regions for means were determined using R's packages "gplots" and "car", under the assumption that averages over 1000 variables are normally distributed.
Simulation parameters M and σ2 are expected to determine the number of exponentials K; if M increases and/or σ2 decreases, K will increase. Without inter-individual variance, so ω2 = 0, the information in the data increases as N increases, so that K is also expected to increase. With N = 2, M = 11 and σ2 = 0.5, pilot simulations indicated a K ≈ 4. When ω2 > 0, the prediction error will increase, but it is less easy to predict what its effect will be on K. For ω2 values of 0, 0.1, and 0.5 were selected - values that are encountered in practice. Because there is only one random effect in the mixed effects model, the relatively low number of individuals N = 5 was selected.
For a certain choice of M, there are 2M – 1 possible combinations of λs to choose for the terms exp(–λmtj) in the sum of exponentials (excluding the case of zero exponentials). Because accurate evaluation of all models at different parameter values is not feasible with respect to computer time, the set of possible combinations was reduced to one with evenly spaced λs. Table 1 gives an example for the case M = 11.
| K | m : 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 4 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| 5 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 6 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 7 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 |
| 8 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| 9 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 10 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| 11 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
Figure 2 shows the averaged prediction error versus number of exponentials for all possible choices of λ, with N = 2, M = 11, σ2 = 0.5, and ω2 = 0. From the figure it is clear that prediction error may indeed increase if the number of exponentials selected is too large. The bigger solid circles correspond to the models chosen in Table 1; in general the evenly spaced selection of exponents resulted in models with the smallest prediction error.
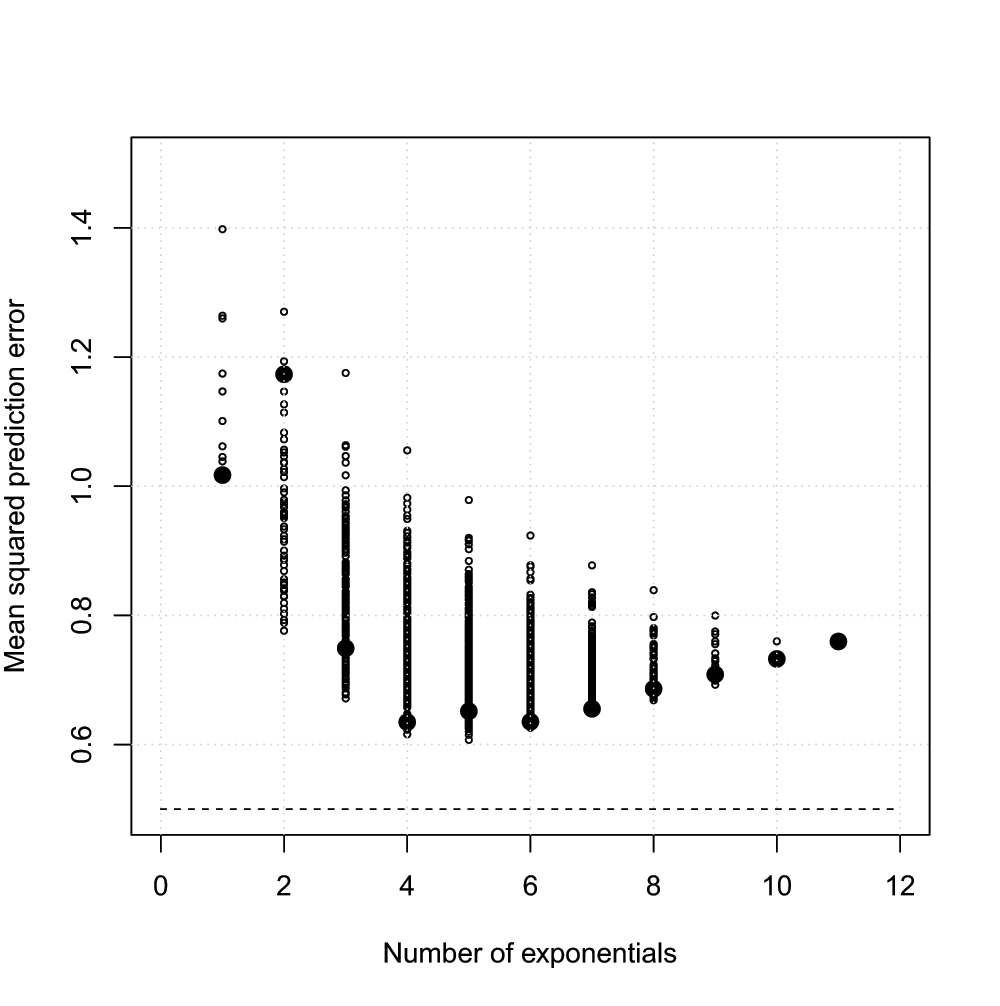
Mean squared prediction error ν2 (eq. (8)) as a function of the number of exponentials, with 2047 models, averaged over 100 runs, N = 2, M = 11, σ2 = 0.5, ω2 = 0. The dashed line represents the prediction error from the true model, so that ν2 = σ2. The bigger solid circles correspond to the models chosen in Table 1.
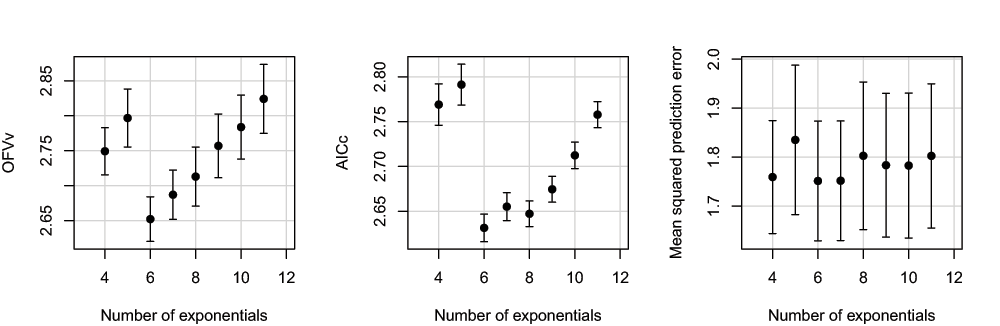
Figure 3 shows simulation results using the model set defined in Table 1, starting from K = 4, with parameters N = 5, M = 11, σ2 = 0.5, and ω2 = 0. The model with K = 6 exponentials had both minimal mean OFVv and minimal mean AICc (and minimal prediction error v2 (not shown)). With N = 5, M = 11, there are still visible differences between AICc and AIC; although AIC would in this case also select the optimal model, AIC appears to favor more complex models. Note that the sizes of the confidence intervals and confidence regions can be made arbitrarily small by choosing the number of runs higher than the selected number of 1000 (at the expense of computer time).
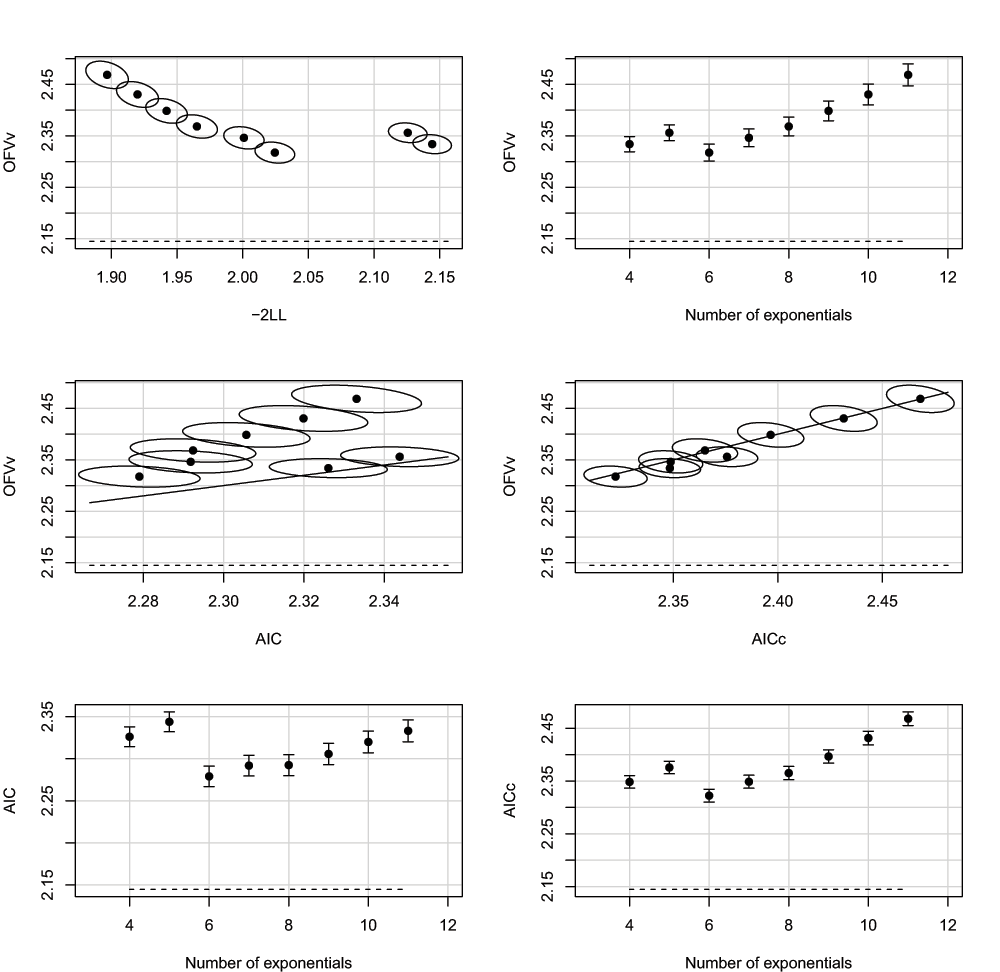
Mean OFVv as a function minus of two log likelihood (-2LL), the number of exponentials, AIC and AICc (top four panels), and AIC and AICc as a function of the number of exponentials (lower two panels), averaged over 1000 runs, N = 5, M = 11, σ2 = 0.5, ω2 = 0. The dashed lines represent the theoretical values for an infinite amount of data (see Supplementary material). Error bars and ellipses denote 95% confidence intervals and confidence regions, respectively. Each solid line in the middle panels denotes the line of identity.
Figure 4 shows simulation results with ω2 = 0.1; mixed-effects analysis was used to fit the population data. The main difference with the results of data with ω2 = 0 is the overall increase in OFVv and AICc. The optimal number of exponentials remained K = 6.
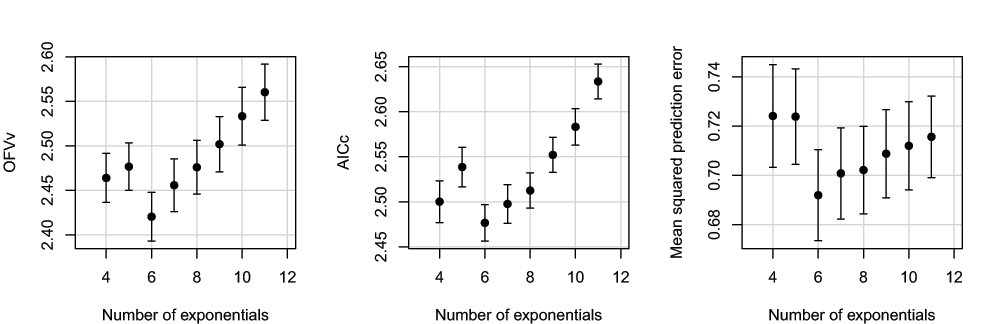
Figure 5 shows simulation results with ω2 set at the higher value of 0.5. The main differences with the results of data with ω2 = 0.1 are again the overall increase in OFVv, AICc and prediction error, and also in the variability in the prediction error. The optimal number of exponentials remained K = 6, although AICc begins to favor the models with larger K (a simulation with N increased to 7, both OFVv and AICc favored larger models; data not shown).
With the objective of creating a simulation context resembling pharmacokinetic analysis where concentration data are approximated by a sum of exponentials, the toy model y(t) = 1/t was chosen. In this setting, reality - the reality of the toy model - is always underfitted. When mixed effects models were fitted to simulated data, mean AICc was approximately equal to the validation criterion mean OFVv, and their minima coincided. With large interindividual variability, mean expected prediction error (ν2, see eq. (8), with random effects fixed to zero), was less discriminative between models, so that it became less suitable as a validation criterion.
Vaida and Blanchard proposed a conditional Akaike information criterion to be used in model selection for the "cluster focus"5. It is important to stress that the cluster focus as they defined is the situation where data are to be predicted of a cluster that was also used to build the predictive model. In that case, the random effects have been estimated, and then the question arises how many parameters that required. In our case, a cluster is the data from an individual; AIC was used in the situation of predicting population data consisting of individual data that were not used to build the model. This would seem to be the most common situation in clinical practice. Furthermore, AIC for the population focus is asymptotically equivalent with leave-one-individual-out cross-validation; AIC for the individual focus with leave-one-observation-out cross-validation9.
We chose to perform simulations using the model given by eq. (2) because approximating data with a sum of exponentials is daily practice in pharmacokinetic analysis where data are obtained from "infinitely complex" systems, and we cannot hope to find the "correct" model. The Bayesian information criterion (BIC) is consistent in the sense that it selects the correct model, given an infinite amount of data4. The reason that AIC can be used in "real-life" problems is that as the amount of data goes to infinity, the complexity, or dimension, of the model that should be applied should also go infinity10. Burnham and Anderson show that it is possible to choose the prior probability distribution for BIC in such a way that it incorporates the knowledge that more complex models should be favored if the amount of data increases, and so that the BIC "reduces" to AIC4,10. In the situation that the correct model set belongs to the set of evaluated models, a selection criterion that both finds the correct model and minimizes prediction error would be preferable - but Yang concluded that this may not be possible11.
In pharmacokinetic analysis, it may not really be appropriate to test (using a hypothesis test assuming a X2 distribution for the objective function) whether an added exponential is statistically significant12. Here the hypothesis H0: the data originate from a K-exponential model (and HA: the data originate from a higher dimensional model) is almost certain to be false. Furthermore, when taking a low p-value, it is also almost certain that the model selected has worse predictive properties. If a model is to be applied in clinical practice, for example for drug administration in a patient never studied before, the model should be as predictive as possible. However, it may be sensible to test whether a certain fixed effect has both a clinically and statistically significant effect, if it is costly to reach a false conclusion, for example in case of increased risks for patients, or in the field of drug development.
Intuitively, predicting data for an individual that cannot be "individualized" seems problematic because the data are predicted using a random effect ηi set to zero, instead of the value fitting for that individual. However, AIC is related to the expected model output; and for individual data not used in building the predictive model, the expected model of output is obtained with mixed effects set to zero, although nonlinearities may bias expectation - but this is also true for nonlinear models without mixed effects.
Furthermore, it should be noted that minimizing AIC has a more general interpretation, namely optimally capturing the information contained in the data4. Independent or future population data z are not just predicted by ŷ; also the distributions of the expected random effects ε and η are characterized by σ̂2 and ω̂2. That is why OFVv is the criterion to be used to assess the predictive performance of a model.
The simulated data were analyzed using weighted (non)linear regression, see eq. (6), where measurement noise was weighted according to the exact function value. In practice, when the weights are unknown, a choice must be made to weight the data according to the measurements or to the model output, depending on which is likely to be the most accurate. To match the latter case, simulated data should be generated (cf. eq. (6)) via
The likelihood function and AIC are both still well-defined if the model output ŷi(tj) ≠ 0. Prediction errors are to be calculated with
where ŷ possibly becomes arbitrarily close to zero for less than optimal models, and v2 may be based on long-tailed distributed numbers. To be able to compare prediction errors from different models, the weight factors could be chosen identical for all K to the model output of the largest model - see the Supplementary material for further analysis.
We recognize the following limitations of our study:
The model contained only one random effect, and therefore the number of random effect (co)variances was fixed to one. While the number of (co)variance parameters should be counted as ordinary parameters5, at least in well behaved situations13, we did not investigate the process of optimizing this part of a random effects model.
The nonlinearity in the mixed-effects model was simply due to a multiplicative factor exp(η) in the model output. Usually, random effects in pharmacokinetic models have more complex influence on the model output. However, the lognormal nature of exp(η) is a characteristic property of both our toy model and general pharmacokinetic models.
The characteristics of the exponentials incorporated in the regression models were evenly spaced, and the values of the rate constants λ were fixed. We expect that with more freedom in the specification of the set of models, prediction errors with overfitted models may be worse. However, the agreement between AICc and prediction error should persist.
We did not evaluate all possible models within their definition, but only those listed in Table 1, and it makes sense to limit the model set to avoid overfitting the data4,11. We did not address how to optimally select the rate constants λ. Stepwise selection methods have their disadvantages12. With stepwise forward selection, AICc may even perform worse than AIC14.
We did not evaluate the process of covariate selection. However, the set of exponentials may be viewed as a number of (somewhat correlated) predictors. It is therefore expected that the present findings also hold for other types of covariates.
In conclusion, the present simulation study demonstrated that in the presence of inter-individual variability in a relatively simple mixed effects modeling context, minimum mean AICc coincided with best predictive performance.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)