Keywords
Polypharmacology, compound promiscuity, pharmaceutical targets, publicly available activity data, data growth, data confidence levels, promiscuity progression
This article is included in the Cheminformatics gateway.
Polypharmacology, compound promiscuity, pharmaceutical targets, publicly available activity data, data growth, data confidence levels, promiscuity progression
Comments to all three reviews have been posted to address more general points that were raised or points that we felt should not be specifically considered in our revision (e.g., issues that would likely modify the focus of our analysis). In our revision, the following points made by the reviewers have been addressed: The discussion of promiscuity and polypharmacology has been extended, the number of publications from which ChEMBL data originated was analyzed over time, a few definitions and analysis details have been further clarified, and promiscuity was also analyzed for compounds with varying logP values (as a measure of lipophilicity) and molecular weight. Additional results are presented in a revised Figure 1c and a new Figure 5 of the revision. The source data sets are made available via an open access deposition as specified in the manuscript.
See the authors' detailed response to the review by Christopher Southan
See the authors' detailed response to the review by John A. Lowe III
See the authors' detailed response to the review by Georgia B. McGaughey
Polypharmacology is an emerging theme in pharmaceutical research and refers to the property of many bioactive compounds or drugs to act on multiple physiological targets, modulate different signaling pathways, and elicit multi-target-dependent pharmacological effects1–3. Typically, polypharmacology is not considered to include toxic or other undesired side effects. The molecular basis of polypharmacology is provided by compound promiscuity, which is defined as the ability of small molecules to specifically interact with multiple targets4,5. It should be emphasized that this form of “specificity pattern promiscuity” is distinct from non-specific interactions or assay artifacts6–8. In light of the latter problems, it is important to identify compound classes that are frequently responsible for artificial activity readouts7,8, e.g. through reactivity under assay conditions. Even in the absence of interaction artifacts, the experimental assessment of promiscuity, e.g. by systematic compound profiling on target sets or families, might be affected by assay confidence limits or detection techniques9, as is the case with any screening experiment. Hence, it might sometimes be difficult to clearly distinguish between “assay promiscuity” and true target promiscuity. Furthermore, not all of the interactions between a compound and multiple targets might make positive contributions to polypharmacology; another point that merits consideration. However, compound promiscuity, as defined herein, is a condition sine qua non for polypharmacology.
In addition to experimental studies, promiscuity can also be assessed computationally by mining the rapidly increasing amounts of compound activity data that become available and systematically collecting target annotations for compounds3–5. For computational analysis, it is also of critical importance to carefully consider activity data integrity and confidence levels to arrive at reliable promiscuity estimates5. For compound data mining, public repositories are essential including ChEMBL10, the major public source of data from medicinal chemistry, PubChem’s BioAssay database11, the major source of screening data, and DrugBank12, which collects target annotations for drug candidates and drugs. Systematic computational analysis of promiscuity has been largely dependent on these resources (although proprietary pharmaceutical data have also been used).
In recent years, computational investigations have provided different promiscuity estimates, depending on the specific aims, study design, and data selection criteria that were applied. Drugs have been the major focal point of these studies. Early estimates on the basis of drug-target networks have suggested that a drug interacts with two targets on average13. Recently, it has been proposed that drugs directed against different target families bind to an average of two to seven targets, depending on their primary target families, and that more than 50% of current drugs bind to more than five targets3. For bioactive compounds, analysis of high-confidence activity data indicated that they interact with an average of one to two targets, with most promiscuous compounds being annotated with two to five targets from the same target family5,14. Moreover, the analysis of high-confidence activity data from 1085 PubChem confirmatory bioassays for 439 targets revealed that a confirmed hit interacted with only two targets on average, although nearly 80% of these active PubChem compounds were tested in more than 50 different assays15. Taken together, computational analyses of bioactive compounds from medicinal chemistry and screening sources indicated the presence of lower degrees of promiscuity overall than was detected for drugs.
These findings could be rationalized based on the assumption that drugs might often be more extensively tested against different targets than average bioactive compounds. However, this would not explain the relatively low degree of promiscuity observed for active compounds from screening libraries, many of which are extensively tested. Furthermore, promiscuity estimates from computational analysis are occasionally questioned in light of data sparseness16, referring to the fact that available active compounds have not been tested against all targets, which represents the vision and ultimate goal of chemogenomics17. Data incompleteness might principally lead to an underestimation of the degree of promiscuity. However, it remains unclear how significant such deviations might be. In fact, if one considers that millions of activity annotations are already available at present, it should be possible to deduce statistically meaningful trends from such large data samples. Such promiscuity trends might be detected by monitoring promiscuity over time as activity data grow. In a recent study, this type of analysis has been carried out for approved drugs18. For a set of 518 drugs, promiscuity was quantified over different time intervals considering activity data at different confidence levels. When only high-confidence activity records were considered, an increase in the average degree of promiscuity from 1.5 to 3.2 targets per drug was detected over a period of 14 years (from 2000 and 2014). By contrast, when all available activity data were considered, regardless of confidence levels, partially unrealistic increases in promiscuity were observed, ranging from six targets per drug on average in 2000 to more than 28 targets in 201418. For individual high-profile drugs, literally hundreds of target annotations were detected when no confidence criteria were applied. This study showed how dramatic the influence of data confidence levels on promiscuity assessment could be. Furthermore, when considering the results obtained on the basis of high-confidence activity data, the findings also corroborated conclusions drawn from earlier studies discussed above, which indicated that detectable promiscuity of active compounds and drugs might be lower overall than often assumed (and that these observations might not be largely determined by data incompleteness).
To further refine current promiscuity estimates, we report herein a detailed analysis of the degree of promiscuity of current bioactive compounds monitored over time, spanning a period of 39 years. Special attention was paid to compounds that were first recorded many years ago and are still available. Promiscuity was viewed in light of data growth and monitored using high- and low-confidence activity data. A large number of compounds qualified for this analysis and clear trends were detected. The results of our analysis are presented in the following.
The ChEMBL database10 that was analyzed collects large numbers of compounds and activity data, mainly from the medicinal chemistry literature and the PubChem BioAssay database11. The current ChEMBL version (v.20) contains 1,463,270 structurally distinct compounds with activity against 10,774 targets. From 1,148,942 assays, a total of 13,520,737 activity records originated, as reported in Table 1. To systematically explore data growth over time, our analysis focused on data for which publication dates were available, which included 913,972 compounds, 10,142 targets, 872,577 assays, and 5,258,052 activity records (Table 1). The growth of these data was monitored on an annual basis. For each year, the number of new entries that became available and the total (cumulative) number of entries was recorded.
For ChEMBL v.20 and subsets for which specific publication dates were available, the total number of compounds, targets, assays, and activity records (activities) is shown.
| Number of | Total | With publication dates |
|---|---|---|
| Compounds | 1,463,270 | 913,972 |
| Targets | 10,774 | 10,142 |
| Assays | 1,148,942 | 872,577 |
| Activities | 13,520,737 | 5,258,052 |
In order to investigate compound promiscuity over time as well as the effect of data confidence levels on promiscuity degrees, two data sets with different confidence were assembled from ChEMBL v.20. For the high-confidence data set, a series of selection criteria was applied. Compounds with direct interactions (i.e. assay relationship type “D”) with human single-protein targets at the highest confidence level (i.e. assay confidence score 9) were collected. The two ChEMBL parameters ‘assay relationship type’ and ‘assay confidence score’ qualitatively and quantitatively describe, respectively, the level of confidence that the activity against a given target is evaluated in a relevant assay system. Accordingly, type “D” and score 9 represent the highest level of confidence for activity data. In addition, two types of activity measurements were considered; assay-independent equilibrium constants (Ki values) and assay-dependent IC50 values. To ensure a high level of data integrity, only compounds with explicitly defined Ki and/or IC50 values were selected. Hence, approximate measurements such as “>”, “<”, and “~” were disregarded. Furthermore, activity records including the comments “inactive”, “inconclusive”, or “not active”, were discarded. Thus, this compound set exclusively contained high-confidence activity data. By contrast, the low-confidence data set comprised all compounds with reported interactions against human single-protein targets, regardless of their confidence levels and activity measurement types.
On the basis of the high- and low-confidence data sets, the progression of compound promiscuity was quantified. Activity records with publication dates were assigned to individual compounds. For each year, activity records were assembled. For instance, if a compound was reported to be active against target A in 1990, targets B and C in 2000, and target D in 2005, the cumulative activity records for this compound consisted of target A in 1990, targets A, B and C in 2000, and targets A, B, C, and D in 2005. Thus, the degree of promiscuity of this compound increased from 1 over 3 to 4. For the assessment of compound promiscuity, potency values were not taken into account. The degree of promiscuity was assessed on the basis of qualifying activity records. If a compound was tested in various assays against the same target in different years, yielding the same or different potency values, we only recorded the first year of reported activity. For a given year, the average degree of promiscuity was calculated over all qualifying compounds. In addition, subsets of compounds for which activity data first became available in 1994 (20 year activity history) or 2004 (10 year history) were separately monitored.
In ChEMBL v.20, publication dates were reported for 913,972 compounds, 10,142 targets, 872,577 assays, and 5,258,052 activity records (Table 1). Initially, the growth of these source data was analyzed over time. Figure 1 reports the number of new entries that became available each year since 1976 and the total (cumulative) number of entries for each year. As shown in Figure 1a, only 3188 compounds were reported in 1976. In 1977, 6496 compounds were published, yielding a total of 9684 compounds. Since then steady growth in compound numbers was observed until 2006 when the growth rate became nearly exponential, with ~50,000–80,000 compounds becoming available in 2007 and subsequent years. The number of new compounds published in 2014 was much lower, probably due to the likely situation that not all new compounds and activity data published in 2014 would have been deposited in the database by the end of the year. Similar growth trends were observed for targets (Figure 1b), assays (Figure 1c) and activity records (Figure 1d). The cumulative number of papers published over time was found to parallel the growth of assay data, as shown in Figure 1c. In a related study, compounds and targets published in the scientific and patent literature during 1991 and 2012 were analyzed in detail on the basis of the commercial GOSTAR database19.

The growth of compounds (a), targets (b), assays (c), and activity records (d) is reported. In (a), the number of new compounds becoming available each year is provided using blue bars (scale on the left vertical axis) and the cumulative number of compounds is given as a red line (scale on the right). Corresponding representations are used in (b)–(d). In (c), the cumulative number of publications (green) from which ChEMBL data originated is also reported (scale on the left).
In Table 2, the numbers of compounds, targets, assays, and activity records available in 1976 and 2014 are compared. Within this 39-year period, available activity records increased most significantly from 13,999 to 5,258,052 (by a factor of ~376). For compounds and assays, growth factors were comparable (~287 and ~261, respectively). The number of targets increased by a factor of ~79.
The numbers of compounds, targets, assays, and activity records available in 1976 and 2014 are compared.
| Number of | 1976 | 2014 | Increase (fold) |
|---|---|---|---|
| Compounds | 3188 | 913,972 | 286.7 |
| Targets | 128 | 10,142 | 79.2 |
| Assays | 3347 | 872,577 | 260.7 |
| Activities | 13,999 | 5,258,052 | 375.6 |
Overall, significant increases in the number of compounds, targets, assays, and activity records were observed, especially from 2007 on, thus providing a sound basis for the analysis of compound promiscuity progression over time.
Based on the selection criteria detailed above, two sets of compounds with high- and low-confidence activity data were assembled. In the low-confidence set, compounds with any reported activities against human single-protein targets were included, without applying additional data confidence criteria. By contrast, for the high-confidence set, additional criteria were applied including assay confidence levels as well as the type and integrity of potency measurements. As reported in Table 3, the high-confidence set contained 154,062 compounds active against 1449 targets, yielding a total of nearly 234,000 activity records with publication dates. In the low-confidence set, 361,159 compounds active against 2552 targets were available, yielding a total of nearly 782,000 activity records. Datasets of this magnitude were expected to reveal statistically relevant trends in promiscuity progression.
The numbers of compounds, targets, assays, and activity records with available publication dates are reported for the high- and low-confidence data sets, respectively.
| Number of | High-confidence set | Low-confidence set |
|---|---|---|
| Compounds | 154,062 | 361,159 |
| Targets | 1449 | 2552 |
| Assays | 27,876 | 141,319 |
| Activities | 233,971 | 781,707 |
Global estimate. For compounds in the high- and low-confidence data sets, the average degree of compound promiscuity was determined over the years, as reported in Figure 2. Early on, compounds from both data sets were mostly associated with single-target activities (corresponding to a promiscuity degree of 1). Beginning in 2004, a difference in promiscuity between the high- and low-confidence sets became apparent. However, only a limited increase in promiscuity was observed for compounds from both data sets. From 1976 to 2014, the average degree of promiscuity increased from 1 to 1.5 for the high- and from 1 to 2.2 for the low-confidence data set, thus indicating an overall low degree of promiscuity among bioactive compounds. More interestingly, the average degree of promiscuity for compounds in the high-confidence set only increased by 0.4 (i.e. by less than one target) after 1994 and essentially remained constant between 2004 and 2014, although the amount of available compounds and activity data dramatically increased after 2006 (Figure 1).
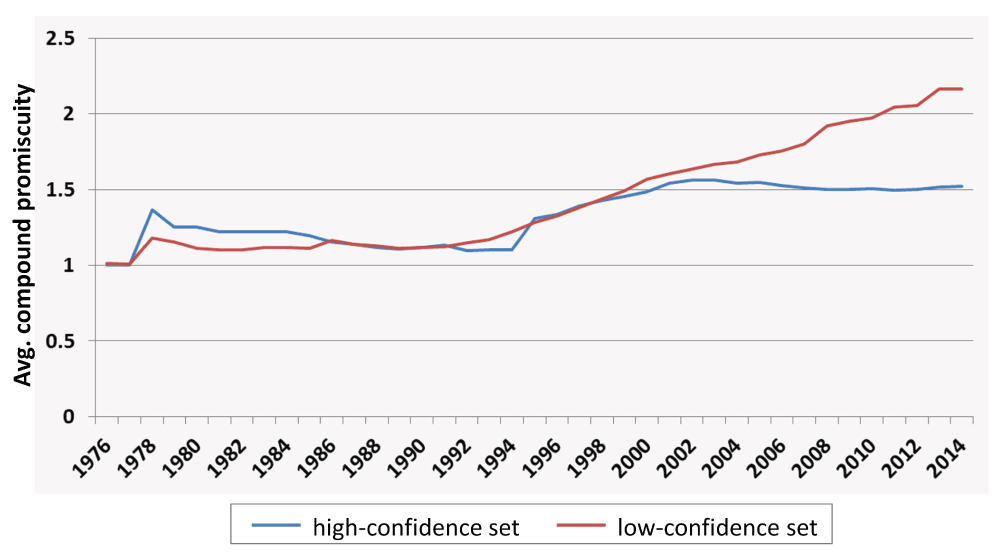
For compounds in the high- and low-confidence data sets, the average degree of compound promiscuity is reported over different years.
Promiscuity on a per-compound basis. In addition to the global assessment of compound promiscuity, progression of promiscuity was also monitored for individual compounds. Table 4 reports the number of compounds with increasing degrees of promiscuity over time. Strikingly, a total of 151,786 (i.e. 98.5%; high-confidence set) and 352,466 (97.6%; low-confidence set) compounds displayed constant degrees of promiscuity over time. Exemplary compounds are shown in Figure 3. These compounds were active against varying numbers of targets. Yet their degrees of promiscuity remained constant until 2014. It is unlikely that subsets of large numbers of compounds with a constant degree of promiscuity over many years have not been tested in various assays. For example, the compound shown at the bottom left in Figure 3 (CHEMBL340211) was reported to be active against two targets in 1993. However, no additional high-confidence activity data became available for this compound during the following 21 years. An abundance of such examples exists for compounds active across current targets.
The number of compounds with increasing degrees of promiscuity (∆Promiscuity) is reported for the high- and low-confidence data sets. For example, “0” indicates that the degree of promiscuity remained constant over time and “5” that the degree of promiscuity increased by five target annotations.
| ∆Promiscuity | #Compounds | |
|---|---|---|
| High-confidence set | Low-confidence set | |
| 0 | 151,786 | 352,466 |
| 1 | 1239 | 4099 |
| 2 | 469 | 1721 |
| 3 | 220 | 816 |
| 4 | 102 | 398 |
| 5 | 65 | 305 |
| 6–10 | 130 | 698 |
| 11–20 | 40 | 283 |
| 21–50 | 9 | 137 |
| > 50 | 2 | 236 |
| Total | 154,062 | 361,159 |
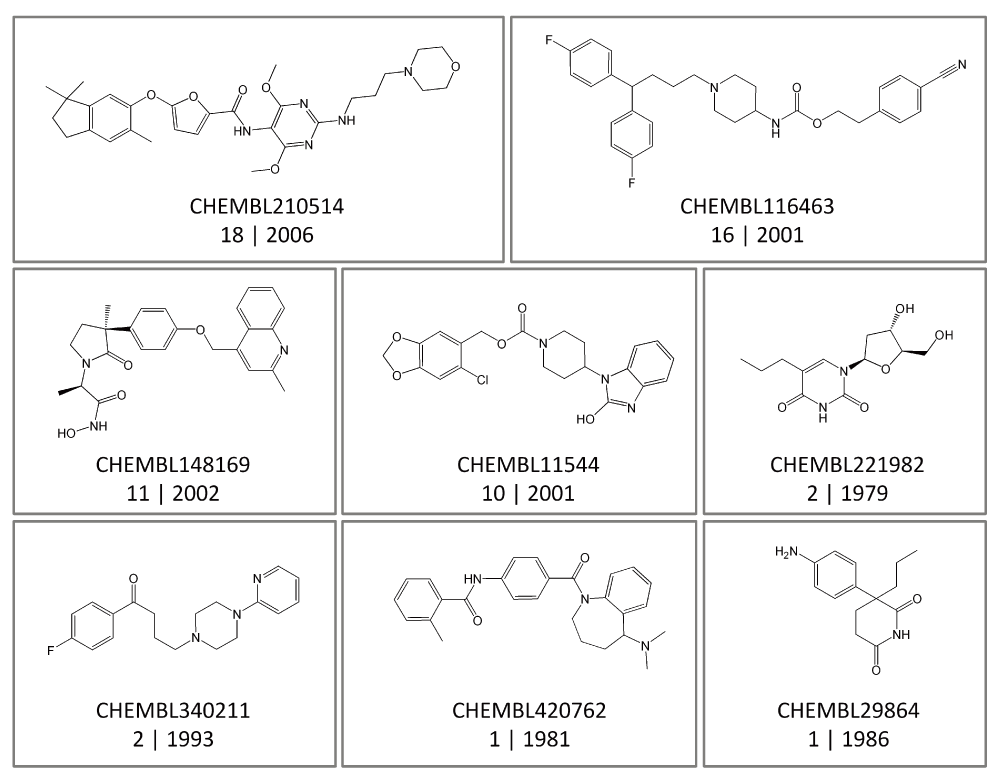
Shown are eight exemplary compounds from the high-confidence data set that displayed a constant degree of promiscuity over different time periods. For each compound, its ChEMBL ID, the degree of promiscuity, and the first year in which target-specific activities were reported are given. For example, “2 | 1993” (lower left) indicates that this compound was first reported in 1993 to be active against two targets and that this degree of promiscuity (i.e., 2) has remained constant until 2014.
Increases in promiscuity were only observed for 2276 and 8693 compounds in the high- and low-confidence sets, respectively (Table 4). Moreover, only 181 (high-confidence set) and 1354 (low-confidence set) compounds - a minute fraction of all monitored compounds - gained more than five target annotations over the years.
Compounds with 20 year activity history. Subsets of compounds reported to be active since 1994 were assembled. From the high- and low-confidence sets, 1040 and 19,351 qualifying compounds were obtained, respectively. Promiscuity progression over the subsequent 20 years was separately analyzed for these compound subsets. Figure 4a shows that the degree of promiscuity of the 1040 compounds from the high-confidence data set essentially remained constant, with an increase from 1.1 (1994) to only 1.2 (2014), hence representing lower promiscuity than the global degree of promiscuity determined for the high-confidence set. For the 19,351 compounds from the low-confidence set, the degree of promiscuity only increased from 1.3 to 1.6, which was also lower than the global degree of promiscuity for this set (Figure 4b). Hence, on the basis of activity data monitored over the course of 20 years, compound promiscuity only slightly increased and promiscuity rates were lower than might have been anticipated, although large amounts of activity data became available over time.

The average degree of promiscuity was compared for all high- (a) and low-confidence (b) set compounds (solid lines) and subsets of compounds reported to be active beginning in 1994 (dashed lines).
For compounds in the high- and low-confidence data sets, molecular weight (MW) and octanol/water (o/w) partition coefficient (logP) values were calculated using the Molecular Operating Environment20 and their degrees of promiscuity were calculated, as shown in Figure 5.

The average degree of promiscuity is reported for compounds in the high- and low-confidence data sets with increasing (a) molecular weight and (b) log P values. For each property value range, the number of corresponding compounds is provided at the bottom.
Figure 5a reports the average degree of promiscuity for compounds of increasing MW. Seven MW ranges were defined. The majority of compounds in the high- and low-confidence data sets had MW between 300 and 600 Da. In both data sets, the degree of promiscuity tended to decrease with increasing MW, consistent with previous observations5. For compounds with MW between 300 and 600 Da, the average promiscuity rates remained nearly constant.
In addition, the influence of lipophilicity on compound promiscuity was analyzed, as reported in Figure 5b (logP values were calculated as a measure of lipophilic character). Compounds covered a wide range of logP values. The majority of compounds in the high- and low-confidence data sets had logP values between 0 and 6. In general, average promiscuity rates first increased over low logP value ranges and then decreased over intermediate to high value ranges. Slightly different trends were observed for the high- and low-confidence sets. For compounds in the high-confidence set, hydrophilic compounds (i.e., having logP values between -4 and 0) displayed the highest degree of promiscuity. Compounds with logP values between 0 and 4 in the low-confidence set displayed above average promiscuity rates, i.e., 2.2. For compounds with further increasing logP values, promiscuity degrees declined. In the high-confidence set, compounds with logP values greater than 4 had an essentially constant degree of promiscuity. Surprisingly, these findings did not reflect the generally expected trend that compound promiscuity correlates with lipophilicity21. However, in another study22, decreasing assay hit rates were also observed for compounds with increasing lipophilicity22.
Up-to-date promiscuity levels were determined for all qualifying compounds, the subsets of compounds for which activity data first became available in 1994 (20 year activity history), and compound subsets for which activity data first became available in 2004 (10 year history). The results are reported in Table 5. The degree of promiscuity was consistently low in all cases and differences in promiscuity were only marginal. For the high-confidence set, the average degree of promiscuity ranged from 1.3 (20 year activity history) over 1.5 (all compounds) to 1.7 (10 year activity history). For the low-confidence set, it ranged from 1.6 (20 year history) over 2.0 (10 year history) to 2.2 (all compounds). Thus, bioactive compounds generally displayed only a low degree of promiscuity, regardless of the data set from which they originated.
For the high- and low-confidence data sets, the current average degree of promiscuity is reported for all compounds and compound subsets with activity records available since 1994 and 2004, respectively.
Currently available activity data provide an unprecedented source of information for the analysis of bioactive compounds. To assess the promiscuity of bioactive compounds in detail, available activity data have been assigned on the basis of publication dates to individual years, thus enabling the study of data growth and compound promiscuity on a time scale and in context. Monitoring compound promiscuity over time was expected to reveal sound trends concerning promiscuity progression and evolving magnitudes. Furthermore, to take data confidence explicitly into account, high- and low-confidence compound data sets were separately generated and analyzed. Data growth and promiscuity progression were ultimately monitored over nearly 40 years (beginning in 1976), both at a global level, as well as focusing on individual compounds or subsets of compounds (from the high- and low-confidence sets) with a 20 year or 10 year activity history. The analysis provided a perhaps unexpectedly clear picture and revealed generally low degrees of promiscuity for bioactive compounds, regardless of their activities and origins. Moreover, only minor increases in promiscuity over time were detected for compounds from all sets and subsets, although activity data dramatically increased since 2007. For the high-confidence set, the average degree of promiscuity only increased from 1 to 1.5 over time. Furthermore, even for the low-confidence set, an increase in the degree of promiscuity to only 2.2 was detected. Interestingly, in both cases, promiscuity was constant over time for most compounds. Moreover, for the high-confidence set, the degree of promiscuity essentially remained constant between 2004 and 2014, despite massive data growth. Given the extensive time course followed, the large data volumes accumulated, and the consistent trends detected, these findings could hardly be solely attributed to data incompleteness (although conclusions drawn from data mining might well be affected by data integrity and/or sparseness issues). In our systematic analysis, bioactive compounds were found to display only low degrees of promiscuity, with a surprisingly small influence of data confidence levels, and very limited promiscuity progression over time. The observed trends are anticipated to remain stable as compounds and activity data continue to grow at high rates and provide reference points for future studies of compound and drug promiscuity as the molecular basis of polypharmacology.
The data selection criteria specified in the Materials and methods section make it possible to reproduce all data sets from ChEMBL v.20, including publication dates. The resulting data set statistics are provided in the first part of the Results and discussion section. However, the data sets generated for this study are also made freely available. ZENODO: Sets of ChEMBL compounds with high or low confidence activity data, DOI: 10.5281/zenodo.1818223
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)