Keywords
Peer review, bias, nationality, gender, language, prestige, random intercept model, authors, reviewers
This article is included in the Research on Research, Policy & Culture gateway.
Peer review, bias, nationality, gender, language, prestige, random intercept model, authors, reviewers
Peer review is the “gold standard” for the evaluation of journal and conference papers, research proposals, on-going projects and university departments and there is a strong consensus in the scientific community that it improves the quality of scientific publications1,2. As reported by Armstrong, “journal peer review is commonly believed to reduce the number of errors in published work, to serve readers as a signal of quality and to provide a fair way to allocate journal space”3. Surveys of authors and expert reviewers4–6 show that this view is widely held. However, many members of the scientific community also believe that peer review is expensive, conservative and prone to bias2,7–18. Critics point to the major delays it introduces into the publication process17,19, to biases against particular categories of papers (e.g. studies challenging conventional wisdom20; replication studies21,22 and studies reporting negative results12,23), to the unreliability of the review process23–25), to its inability to detect errors and fraud26, and to unethical practices by editors and reviewers27,28.
Another common criticism of peer review is that it is prone to “social bias”29: certain categories of reviewer may have conscious or unconscious biases for or against particular categories of author (e.g. authors of a particular gender, authors coming from institutions in a particular geographical area, authors from institutions in English-speaking or non-English speaking countries, authors belonging to low or high prestige institutions). Attempts to measure these biases have given contrasting results. For example, an experimental study by Lloyd30 shows that manuscripts with female author names have a far higher acceptance rate when they are reviewed by female rather than male reviewers (62% vs. 21%). Along the same lines, a widely quoted study of grant awards in Sweden31 suggests that proposals from male candidates receive systematically higher evaluations than those from female candidates with similar academic records, a result confirmed by a recent follow-up study15. Similarly, a study of the introduction of double blind review in the journal Behavioral Ecology reports that blinding reviewers to author gender led by an increase in papers with female first authors, absent in other very similar journals32. However, the interpretation of this study has been contested33, and some ex post analyses of publication patterns indicate that differences in the way male and female reviewers review papers do not affect review outcomes34. Other studies have found robust effects of author gender on peer review results but do not determine whether these are the result of bias or of differences in the scientific merit of articles submitted by male and female authors35.
Other forms of social bias (e.g. bias for or against authors from particular geographical areas, language bias, bias in favor of authors from high prestige institutions) have been studied less frequently than gender bias but have also produced contrasting results, comprehensively reviewed by Lee and colleagues29. Several studies have shown, for instance, that journals favor authors located in the same country as the publisher36,37. Thus, a retrospective analysis by Link38 suggests that American reviewers are significantly more likely to accept a paper by another American author than a paper by an author of a different nationality. However, other studies indicate that American reviewers are actually more lenient to non-American than to American authors39. A study by Tregenza and colleagues40 shows that papers by authors from institutions in countries whose native language is English are more successful than papers by authors from institutions in other countries, an opinion shared by many commentators (for example41). However, the authors explicitly state that this is not necessarily a sign of bias and other studies have not found the same effect (e.g.42). Peters and Ceci43 report a quasi-experiment demonstrating that papers by authors from high-prestige institutions have a significantly higher chance of acceptance than similar papers by authors with less prestigious affiliations and participants in surveys of authors are reported to believe in such an effect44. However, to the knowledge of the authors, there is little observational evidence for this effect.
Attempts to remedy the weaknesses of traditional peer review have led to a diversification of peer review practices, for instance through the use of author-blind and non-selective review, the removal of traditional reviewer anonymity, and the introduction of various forms of community review. To date, however, there have been few attempts to measure their effectiveness. Furthermore, many past studies of bias in peer review are relatively old and it is not clear whether or how far biases detected in the past have been affected by changes in social attitudes. In response to these concerns, we analyze data for the peer review systems used in Frontiers (an open access publishing house which uses a novel interactive review process), three computer science conferences (CAEPIA2003, JITEL2007, and SINTICE07) held in Spain between 2003 and 2007 and four international computer science conferences (AH2002, AIED2003, ICALP2002 and UMAP2011), held between 2002 and 2011.
Frontiers is a large open access scientific publisher, which published its first journal in 2007. In January 2015, Frontiers had a portfolio of 49 open-access journals with over 50,000 researchers serving on its editorial boards and more than 380 academic specialty sections. Papers are published within these sections. Each paper is assigned to a scientist acting as the editor who coordinates the review process, and is responsible for publication/rejection decisions. Reviewers are selected automatically, based on the match between their individual specialties, and key words in articles submitted for review (or can also be assigned manually by the editor). During the review process, reviewers remain anonymous. However, accepted papers carry the names of their reviewers. This gives reviewers a strong incentive not to accept papers before they have reached a good level of quality.
The Frontier’s review system is designed not so much to select papers as to improve the quality of papers in a collaborative, interactive dialog between authors and reviewers. At the beginning of the review process, reviewers are asked to answer a series of open questions concerning different aspects of the paper (see Table 1). The precise set of questions depends on the nature of the paper (original research, review paper, etc.). Authors answer reviewer questions through an interactive forum. This possibility reduces misunderstandings and can significantly accelerate the submission process.
In addition to replying to open questions, reviewers can express their overall evaluation of the paper on a range of numerical scales (see Figure 1). However, the use of these scales is not mandatory. Nowhere in the process do papers receive an aggregate numerical score. The final decision to accept or reject a paper is taken by the journal editor, based on the overall results of the interactive review process. Acceptance rates are high. Of the papers in the Frontiers database that had reached a final publication/rejection decision on the date when we extracted the data, 91.5% were published and only 8.5% were rejected.

The conferences in these two datasets all used WebConf (http://WebConf.iaia.lcc.uma.es), a computerized system for managing the submission and review of conference papers. WebConf was developed by a team from Malaga University led by one of the authors (RC). WebConf implements a classical review process similar to the processes used by Springer, Elsevier and other large commercial publishers. Conference contributions are usually reviewed by three independent reviewers, occasionally by two or four. Reviewers are chosen by the conference program chair who draws on a database of potential experts called the program committee. In general, the program committee is made up of authors who have previously submitted papers in a particular area of research and have expressed their willingness to act as reviewers. The WebConf system suggests a list of potential reviewers based on the degree of matching between paper topics and reviewers field of expertise. The final selection is based on the judgment of the program chair.
Reviewers express their opinion of a paper in a conference-specific review form in which they assign scores to the paper on a number of separate scales, covering key areas of evaluation (typically including soundness, originality, clarity etc.) and textual comments. Scores on individual scales are usually expressed in terms of categories (typically: poor, fair, good, excellent). The final publication decision depends on the program chair. If one of the reviewers expresses a strongly negative view of a paper, it will typically be rejected. In cases where there is a very significant difference in reviewers’ opinions, the program chair can ask for an additional review. Acceptance rates vary between a minimum of 29.3% and a maximum of 87%. The combined acceptance rate for the seven conferences in the WebConf database was 57.9%.
Frontiers. The Frontiers database includes details of all authors and reviewers for all scientific papers submitted to Frontiers (N=8,565) between June 25, 2007 and March 19, 2012, the name of the journal to which the paper was submitted, the article type (review, original research etc.), the name and institutional affiliations of the authors and reviewers of specific papers, individual reviewer scores for the summary scales shown in Figure 1, and the overall review result (accepted/rejected). At the time of the analysis, 2,926 papers had not completed the review process and were excluded. In another 1,089 cases, reviewers had not assigned numerical scores to the paper, which could not therefore be considered. Our final analysis used 9,618 reviews, for 4,549 papers. Most of the papers in the database come from the life sciences. The majority of authors and reviewers come from Western Europe and Northern America. However, the database contains a substantial number of authors and reviewers from other parts of the world.
Spanish computer science conferences (IEEE-Spain). This dataset includes details of 1,131 reviews referring to 411 papers submitted to three IEEE conferences (CAEPIA2003, SINTICE2007 and JTEL2007). The majority of authors and reviewers for these papers come from institutions in Spain and Portugal. The data provided include the name of the conference to which the contribution was submitted, the type of contribution (poster, short paper, full paper etc.) the name, gender and institutional affiliations of the authors and reviewers of specific contributions, individual reviewers scores and the final decision (accepted/rejected). All the papers in the database are in the area of computer science.
International computer science conferences (IEEE-International). This dataset provides data for 2,194 reviews, referring to 793 papers submitted to four IEEE conferences (AH2002, AIED2003, ICALP2002 and UMAP2011), managed using WebConf and involving authors and reviewers from all over the world. This dataset provided the same data collected for IEEE-Spain.
Names of authors and reviewers were canonized: accent and symbols were removed; double spaces replaced by single spaces, and upper-case characters replaced with lower-case characters. Names were rewritten in the normalized form <first name, last name>. Intermediate names were omitted.
Names of institutions (universities, research institutions, companies) were canonized as above. After normalization, the name of the institution was recoded using the first three words in the full name.
Neither the Frontiers nor the WebConf databases included data for author and reviewer gender. In the Frontiers case, gender was inferred semi-automatically in a multistep process. First we matched the first names contained in our database to an open source dictionary providing genders for more than 40,000 first names used in different countries (gender-1.0.0.tgz, downloadable from http://pecl.php.net/package/gender). We then used volunteers of different nationalities (Chinese, Egyptian, Indian, Japanese, Korean, Turkish) to assign genders to first names not contained in the dictionary. Additional names were assigned by manually searching for specific authors and reviewers on Google and Facebook. At the end of this process, we were able to assign genders to 9,472 out of 11,729 authors and reviewers. The majority of unassigned names were Asian (mainly Chinese). This is a potential source of bias in our analysis. Genders for WebConf authors and reviewers were inferred using a similar procedure.
To ascertain possible country and regional biases, we assigned each author and reviewer to the country of the institution to which they were affiliated. Actors with multiple affiliations were assigned to the country of the first affiliation listed. The USA, UK, Scotland, N. Ireland, Ireland, Australia, Canada, and New Zealand were classified as English-speaking countries. All other countries were classed as non-English speaking.
Authors’ and reviewers’ affiliated institutions were classified in terms of their position in the 2012 Shanghai academic ranking of world universities for the life sciences (http://www.shanghairanking.com/FieldLIFE2012.html) (Frontiers) and for computer sciences (http://www.shanghairanking.com/SubjectCS2012.html) (WEBCONF). Rank was coded as a categorical variable with values 1 (rank 1–50), 2 (rank 51–200), 3: unclassified. Given the process used to normalize institution names, it is possible that a small number of institutions were misclassified.
Frontiers. The Frontiers review process produces a very low rejection rate. This means that the database used for our study contained relatively few rejected papers (N=478). To create a more informative indicator of reviewers’ evaluations, we computed for each paper the average of the scores expressed by each individual reviewer for the summary scales shown in Figure 1. A comparison between the distributions of scores for rejected and published papers (see Figure 2) clearly demonstrates the validity of the indicator. However, it should be noted that the indicator is a construction of the authors and played no role in the review process.
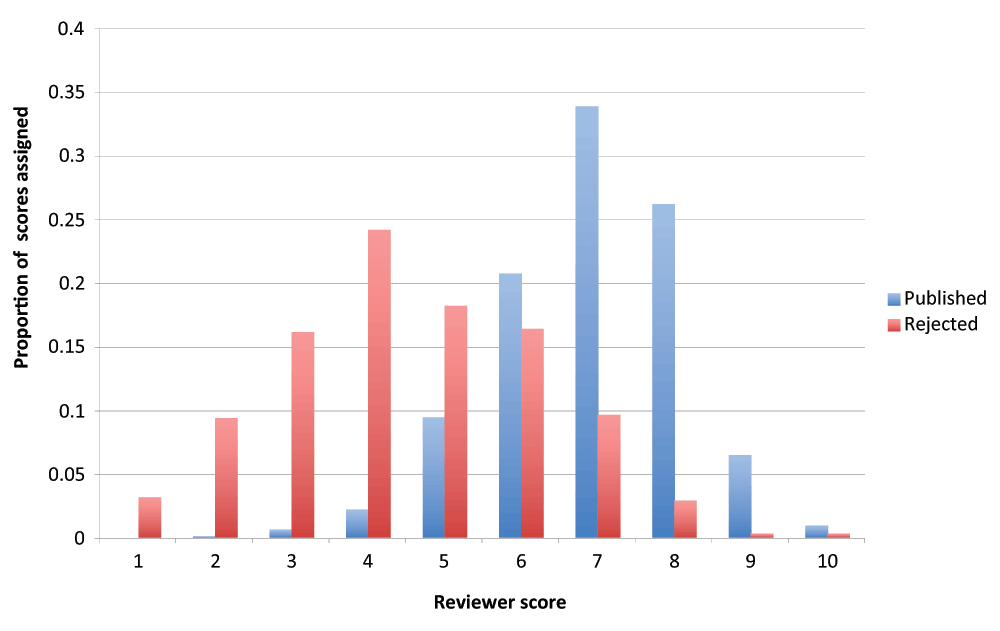
WebConf. The WebConf system asks each reviewer to assign an overall score to the paper he/she has just reviewed. Scores are expressed on a scale of 0 to 10.
For the purposes of the study, we define bias as the interaction terms ∂ij in the random intercept model:
y = b + µij + βijAi + γijRj + δijAiRj + ε (1)
where y denotes the score given in the review, b denotes the random intercept, i indexes properties of authors, j indexes properties of reviewers, and ε is the error term. This method is similar but not identical to the method proposed in45.
Given a factor F, such as region, the variables Ai and Rj are indicator (dummy) variables indicating that the first author and reviewer belong to categories i and j of factor F, respectively, that is:
IF one author belongs to category i of F, Ai=1, ELSE Ai=0 (2)
AND
IF one reviewer belongs to category j of F, Rj=1, ELSE Rj=0 (3)
Thus βij is the fixed effect of author category, γij is the fixed effect of reviewer category and δij is the fixed effect of the interaction between author and reviewer category. Since the expected value of the random intercept b is 0, the fixed effects allow us to estimate the following mean scores:
Gij = µij + βij + γij + ∂ij author in category i, reviewer in category j
Gi = µij + βij author in category i, reviewer not in category j
Gj = µj + γij author category i, reviewer in category j
G = µij author not in category i, reviewer not in category j.
We define bias Bij of reviewers from category j of factor F towards authors from category i by the expression:
Bij = (Gij – Gi) – (Gj – G) = ∂ij (4)
Since the intercept and main effects cancel out, bias is the interaction term ∂ij and does not depend on the main effects βij and γij. In other words, it is independent of any general tendency of authors in category i to write better papers than other authors, or of any tendency of reviewers in category j to give generally higher scores. In this setting, reviewers from category j are biased in favor of authors from category i, if Bij >0 and are biased against authors from category i if Bij <0. Bias is significant at a level α if we can reject the null hypothesis:
H0 : Bij = 0
Otherwise we assume absence of bias.
The majority of papers in our databases had multiple authors. In preliminary studies, we explored statistical models that used this data in different ways: (i) the model used only the properties of the first author, (ii) the model used only the properties of the last author, (iii) the model considered the properties of all the authors. The three approaches yielded similar results (data not shown). In what follows, we apply the first method, unless otherwise stated.
To illustrate the concept of bias defined in (4), consider a factor with two levels such as gender. Let i and j denote female (F), and and male (M). Then the terms Gij = GFF, Gi = GFM, Gj = GMF, and G = GMM, have the following meanings:
GFF : mean score when first author and reviewer are female
GFM : mean score when first author is female and reviewer is male
GMF : mean score when first author is male and reviewer is female
GMM : mean score when first author and reviewer are male
If we assumed that papers by female authors have the same quality as papers by male authors,
GFF – GFM > 0 (5)
would imply that female reviewers are biased in favor of female authors and
GMF – GMM > 0 (6)
would imply that female reviewers are biased in favor of male authors.
However, we cannot make this assumption. We therefore conclude that female reviewers are biased for or against female authors (BFF ≠ 0) only if (5) and (6), yield different results. If both were equal and positive, we conclude that females give higher scores than men regardless of the gender of the author. If female reviewers have a positive bias, this always implies a negative bias on the part of male reviewers and vice versa. By construction, this method cannot detect biases shared by all reviewers (e.g. a bias against female authors, or authors from a particular geographical region, shared by all reviewers, regardless of gender or geographical origin).
It should also be noted that, in our example, if B = (GFF – GFM) – (GMF – GMM) > 0 the following statements are equivalent:
Female reviewers are biased in favor of female authors
Female reviewers are biased against male authors
Male reviewers are biased against female authors
Male reviewers are biased in favor of male authors
Similarly, if B > 0, we can draw the following equivalent conclusions:
The automatic gender assignment program assigned genders to first authors and reviewers for 8,114 reviews from Frontiers, 1,131 from IEEE (Spain) and 2,194 from IEEE (International). The relative proportions of male first authors and reviewers (male authors: 70.0%–73.9%; male reviewers: 75.2–79.3%) were similar in all three datasets. In the Frontiers and IEEE (International) datasets, means scores for male first authors were significantly higher than those for female first authors (Frontiers: difference=0.07, p=0.034; IEEE International: difference=0.28, p=0.001). The IEEE (Spain) dataset showed the same pattern but the difference was not significant (difference=0.39, p=0.40). Reviewer gender had no significant effect on review scores in any of the datasets. In none of the data sets did the interaction between author and reviewer gender have a significant effect. In brief, none of the datasets showed evidence of gender bias. The significance of these results will be examined in the discussion. Complete data for the analysis can be found in Data Files 1–4.
The analysis examined the role of the region of first author and reviewer institutions in determining review scores and tested for possible regional bias. Authors and reviewers were grouped into 11 geographical regions (Africa, Australia/New Zeeland, Central America/Caribbean, Central Asia, Eastern Asia, Eastern Europe, Middle East/North Africa, South America, Southern Asia, Southern Europe, and Western Europe) according to the location of their respective institutions. To avoid problems with the convergence of the mixed model algorithm and to guarantee the statistical power of the analysis, pairs of first author/reviewer regions with less than 30 reviews were discarded. Distributions of author and reviewer regions differed significantly among the three datasets. In the Frontiers and International IEEE datasets, the majority of authors and reviewers came from institutions in North America and Western Europe, while the majority of authors and reviewers in the Spanish IEEE dataset, came from institutions in Southern Europe.
All three datasets showed large differences in the scores of first authors from different regions (see Table 2), which were statistically significant even after correction for multiple hypothesis testing. In the Frontiers dataset, authors from N. America scored significantly higher than authors from all other regions, whereas authors from E. Asia, E. Europe, S. Asia and Southern Europe scored significantly lower. In the IEEE (Spain) dataset, authors from Southern Europe scored higher than authors from other regions, whereas authors from North America scored lower. In the IEEE (international dataset) authors from N. America again scored significantly higher than authors from other regions, while authors from Africa and Central Asia scored lower.
In the Frontiers and IEEE (Spain) datasets, we detected no significant differences in scores from reviewers from different regions (not shown). In the IEEE (International) dataset reviewers from Australia/NZ and from Southern Asia gave scores that were significantly higher than the average for reviewers from other regions and reviewers from Western Europe gave scores that were significantly lower (not shown).
To test for bias, we applied the random intercept model to all author/review region pairs with more than 30 reviews (see Table 3). After application of the Bonferroni correction for multiple hypothesis testing, the Frontiers dataset showed no evidence of interaction between author and reviewer region and the other two datasets showed only very limited evidence (IEEE – Spain: bias of reviewers from S. Europe in favor of authors from E. Asia; IEEE – International: bias of North American reviewers in favor of authors from Eastern Asia). In none of the datasets did we find any evidence for regional biases previously reported in the literature (e.g. bias of North American reviewers in favor of North American authors). We conclude that regional bias has only a limited effect on review scores and that those biases that do exist are idiosyncratic to particular review systems. Full data for the analysis can be found in Data Files 5–8.
We hypothesized that reviewers could be biased against papers written by authors who were not native English speakers. We, therefore, analyzed potential reviewer bias for and against papers, whose first authors came or did not come from institutions in English-speaking countries. As a further test, we analyzed potential bias for and against papers, which had, or did not have, at least one author belonging to an institution in an English speaking country.
The Frontiers and the IEEE (International) datasets, both included large numbers of authors and reviewers, from institutions in native English-speaking and from non-English-speaking countries. In contrast, approximately 97% of the authors and reviewers in the IEEE (Spain) dataset came from Spain. Since none of the papers with an English-language first author, and only one paper with at least one English author, were reviewed by an English-language reviewer, it was not possible to measure bias using the random intercept model. This dataset was therefore discarded from the subsequent analysis.
In the remaining datasets, papers with a first author from an institution in a non-English-speaking country scored significantly lower that papers with first authors from institutions in an English speaking country, regardless of whether they were reviewed by native English-speaking or non-native English speaking reviewers (Frontiers: difference=-0.22, p<0.001; IEEE International: difference=-0.54, p<0.001). Reviewer language had no significant effect on score (Frontiers: difference=0.04, p=0.040; IEEE International: difference=0.01; p=0.80). In neither case did we find a significant interaction between author and reviewer language (not shown). Results for papers with at least one author from an institution in an English-speaking country were similar. Details of the analysis are shown in Data Files 9–11.
Reviewers from institutions with high academic prestige could be biased in favor of authors from other high prestige institutions and against authors from lower ranking institutions. To test this possibility, we classified all authors and reviewers in the three datasets by the position of their institutions in the Shanghai classifications, as described earlier.
The Frontiers and the IEEE International datasets both contained significant numbers of authors and reviewers from universities in all three categories. However, nearly all the authors and reviewers in the IEEE Spain dataset came from universities in category 3. Given the lack of data for authors and reviewers from higher-ranking institutions, this dataset was excluded from the subsequent analysis.
In the Frontiers dataset, authors from universities in category 1 scored significantly higher than authors from category 2 (difference=0.16, p=0.016) and from category 3 (difference=0.21, p<0.001), regardless of the origin of the reviewer. No significant difference was observed between the scores of authors in category 2 and 3 or between scores given by reviewers from institutions in different categories. In the IEEE International dataset, authors from universities in categories 1 and 2 both scored significantly higher than authors in category 3 (category 1: difference in scores=0.97, p=<0.001; category 2: difference in scores=0.89, p=<0.001) but there was no significant difference in their own respective scores (not shown). There was no significant difference between the scores given by reviewers in category 1 and the scores given by reviewers in categories 2 and 3. However, reviewers in category 2 gave significantly higher scores than reviewers in category 3 (difference in scores=0.28, p<0.001). Neither dataset showed a significant interaction between the prestige of author and reviewer institutions. In the IEEE (International) dataset, reviewers from institutions in category 1 gave higher scores to authors in category 3 than to authors in category 1, but the difference was not statistically significant (difference=0.48, p=0.059). Full details of the analysis are given in Data Files 12–14.
The results of the study (see Table 4) show that the scores received by papers in peer review depend strongly on the characteristics of the first author (gender, geographical location, language and prestige of the author’s institution). In summary, male authors receive higher scores than female authors, authors from some geographical regions receive higher scores than authors from others; authors from institutions in English-speaking countries receive higher scores than authors in non-English-speaking countries; authors from high prestige institutions receive higher scores than authors from lower-prestige institutions. In contrast, we find no evidence that scores are affected by the personal characteristics of reviewers, no significant interactions between author and reviewer gender, language, and institutional prestige and only limited evidence of an interaction between author and reviewer region. In brief, the study provides little evidence for bias, at least in the sense in which bias is defined in our study (see below).
The review systems considered in the study are very different. The majority of papers in the Frontiers dataset came from the life sciences; all the papers in the IEEE datasets were from specialized areas of computer science. Frontiers adopts a novel interactive review process; the conferences in the IEEE (Spain) and the IEEE (International) datasets used a traditional approach. Authors and reviewers in the Frontiers and the IEEE International datasets come from all over world. The IEEE (Spain) dataset is dominated by authors and reviewers from Southern Europe. Despite these differences, analysis of the three datasets gave very similar results. This suggests that the findings of this study could be valid for a broad range of peer review systems. The large size of the datasets used in the analysis (in total 12,943 reviews of 5,743 papers) provides additional evidence of robustness. The main differences between the datasets were in their patterns of regional bias, which are different in each dataset. Unfortunately the many differences between the Frontiers and the IEEE systems make it impossible to untangle the roles of different contributory factors.
The finding that author characteristics have a significant effect on review scores is compatible with two distinct explanatory hypotheses. The first is that papers submitted by authors with a particular characteristic (e.g. authors from institutions in a particular region) are, on average, of higher scientific merit than papers by authors with different characteristics (e.g. authors from institutions in other regions). The second is that reviewers share a general bias against authors with particular characteristics, regardless of their own characteristics (e.g. reviewers from institutions in English and non-English speaking countries share a bias against authors from non-English speaking countries). The methodology of the study cannot distinguish between these hypotheses; in fact, the only way to detect generalized bias would be through experimental studies, comparing review scores when reviewers are blinded to particular characteristics of the author to the scores given when they are not (for example30,43). Such studies are extremely valuable. However, their experimental nature means that they are unable to demonstrate the existence or absence of bias in operational review systems. This suggests that observational and experimental methods are complementary, and that it will not be possible to gain a complete picture of bias in peer review without using both methods.
The study found no evidence for social bias in terms of author gender, and the language and prestige of author institutions and only weak evidence of regional bias. The findings for gender match results from a previous study which used the interaction between author and reviewer characteristics as a measure of bias46. However, it apparently contradicts results from previous studies showing significant bias, with respect to gender (e.g.30,43) as well as for region (e.g.38), and institutional prestige (e.g.43). Given that the majority of studies showing bias are relatively old, it is possible that changes in social attitudes have reduced or eliminated some of the biases they observed. In some cases, (e.g.31) studies measured effects that were independent of reviewer characteristics, which, as explained earlier, are invisible to the methodology used in this study. In this case, the results of our study would complement rather than contradict previous results. We suggest, nonetheless, that, at least in the case of gender, it is implausible that modern female reviewers are biased against female authors. The most parsimonious explanation of our results is that, with the possible exception of regional biases, social bias plays at most a minor role in determining review outcomes.
Our study also found no significant differences between the scoring patterns of different categories of reviewer. These results, which were valid for all three datasets, contrast with previous findings showing significant differences in scoring practices between male and female reviewers34,47 and between reviewers from different countries47. However, there have been relatively few studies on this issue, and even these do not show a major impact of reviewer characteristics on the final outcomes of the review process34. Taken together, these results suggest that editors should not be over-concerned with the gender, language or institutional affiliation of the reviewers they choose for particular papers, though it could be useful to ensure a good regional balance among reviewers.
Our study does not evaluate the full set of potential biases described in the peer review literature. For instance, we do not consider confirmation bias or alleged reviewer biases in favor of positive results, sophisticated experimental and statistical methodology, or against interdisciplinary studies, replication studies, etc. These are important limitations. A second limitation is that the study methodology has so far been tested with just three peer review systems, all applying to scientific papers. It is possible that other forms of peer review, such as peer review of grant applications, are subject to different forms of bias.
In conclusion, our study shows the important role of authors’ personal characteristics in determining the scores received in peer review, but finds little evidence for bias due to interactions between author and reviewer characteristics. These findings do not rule out generalized bias against authors with specific characteristics or forms of bias not considered in the study.
To protect the identities of authors and reviewers, the source data used for this study have not been made public.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)