Keywords
High Throughput Sequencing, Next-Generation Sequencing, Laboratory Information Management System, Galaxy, Django
This article is included in the Galaxy gateway.
High Throughput Sequencing, Next-Generation Sequencing, Laboratory Information Management System, Galaxy, Django
The detection and characterization of emerging infectious agents has been a continuing public health concern. High Throughput Sequencing (HTS) Next-Generation Sequencing (NGS) technologies have proven to be promising for unbiased detections of pathogens in complex biological samples. They are efficient and provide access to comprehensive analyses.
In most large-scale genomic (re)sequencing initiatives involving both sequencing technology, genotyping expertise and computational analyses, the ultimate goal targets analysis of the data in a reference-free context. Depending on sufficient sequencing throughput and availability of reference genomes, raw sequence reads are to be handled by de novo assembly protocols. The choice of the most appropriate assembly algorithm will both depend on the number of sequenced DNA fragments and the genome size of the targeted species. Most well-acknowledged computational bottlenecks for those short-read assemblers concern memory footprints and difficulties in correctly handling repetitive sequences. Assembly very often results in discontinuous sequence contigs and hence insufficient genome coverage. Currently, de novo assembly yields better coverage for small genomes (i.e. bacterial and/or viral species), though assembly of genomes in a metagenomics setup is nowadays considered as complicated and very challenging. Concerning species with no reference in public databases, pre-processing steps are required to increase genome coverage. For example, the use of paired-end sequence data using different insert size libraries is a well established technique to increase assembly scaffold sizes.
Genotype calling from low coverage data may require extra steps of imputation, filling the gaps that remain due to lack of coverage, and results in more accurate genotypes. Identification of candidate haplotypes and inferring the genotype, by either “phasing” the data to known haplotypes or derivation from external reference panels, allows to better characterize missing genotypes among the individuals.
Current NGS platforms including Illumina, Ion Torrent/Life Technologies, Pacific Bioscience and Nanopore can generate reads of 100–10,000 bases long allowing better coverage of the genome at lower cost. However, these platforms also generate huge amounts of raw data. For example, the raw data produced by an Illumina HiSeq-2500 platform adds up to 1TB per run. Sequencing reads are recorded as FastQ formatted files along with the corresponding quality score for each nucleotide.
In addition to those sequence files, it has become important to also consider and store associated sample related metadata (collection date, location, etc.). Thus, NGS projects usually represent such a huge amount of relevant sample-specific sequences that efficient data management and visualization resources have become mandatory. The challenges accompanying HTS technologies raise the following issues: (1) How do we best manage the enormous amount of sequencing data? (2) What are the most appropriate choices among the available computational methods and analysis tools? The issue concerning the growing amount of data can be managed through a dedicated Laboratory Information Management System (LIMS), solely to organize and provide perspective regarding the information contained. The question regarding the lack of adapted intertwining among the wide spectrum of available tools, was in part filled by workflow management systems, even though it still requires fairly advanced knowledge of the tools available at hand.
Indeed, today, hundreds of bioinformatics tools are available, each with specific parameters and each available either through GUI or command lines. Galaxy1–3, is a scientific workflow management system, which provides means to build multi-step computational data-processing, quality control, and analytic results aggregation, while additionally ensuring analysis reproducibility. In addition to a system for composing pipelines, there is a need for an adapted computational infrastructure capable of doing the processing and data storage in a scalable manner.
MetaGenSense is a managing and analytical bioinformatics framework that is engineered to run dedicated Galaxy workflows for the detection and eventually classification of pathogens. It aims to integrate the capacity for large-scale genomic analysis and technical expertise in sequencing and genotyping technology among project partners. The web application was produced in order to facilitate access to high throughput sequencing analysis tools, acting as an information resource for the project and interacting research partners. This user-friendly interface has been designed to associate bio-IT provider resources (a local Galaxy instance, sufficient storage and grid computing power), with the input data to analyse and its metadata. The use of the available Galaxy tools is automated with MetaGenSense. Galaxy, as a pipeline management software, lets you define workflows and pushes the data through that pipeline. The pipeline manager ensures that all the tools in the pipeline get to run successfully, typically spreading the workload over a computational cluster. MetaGenSense is used at the Pasteur Institute to do the bulk of the data processing for a number of HTS projects, and can be adapted to launch any of the software packages available in the Galaxy workflow designer interface. A dedicated LIMS (postgreSQL-based) was developed to ensure data coherence. In more detail, the web interface design is based on the Django web framework (http://www.djangoproject.com). Moreover, the communication with Galaxy is ensured by the BiobBlend library2 which provides a high-level interface for interacting with the Galaxy application, promoting faster interaction, and facilitating reuse and sharing of scripts.
MetaGenSense is a bioinformatics application that is geared to ease the scientists’ work in management of NGS project-related data and results. MetaGenSense is built upon three major components, two of which are specific to the project: a dedicated LIMS and a Django-based web user-interface. The third component is Galaxy, which is the bioinformatics workflow management system. In the following paragraphs, we describe the interface’s implementation and discuss how communication between the different parts takes place, in a smooth and user-friendly, managing web-user interface.
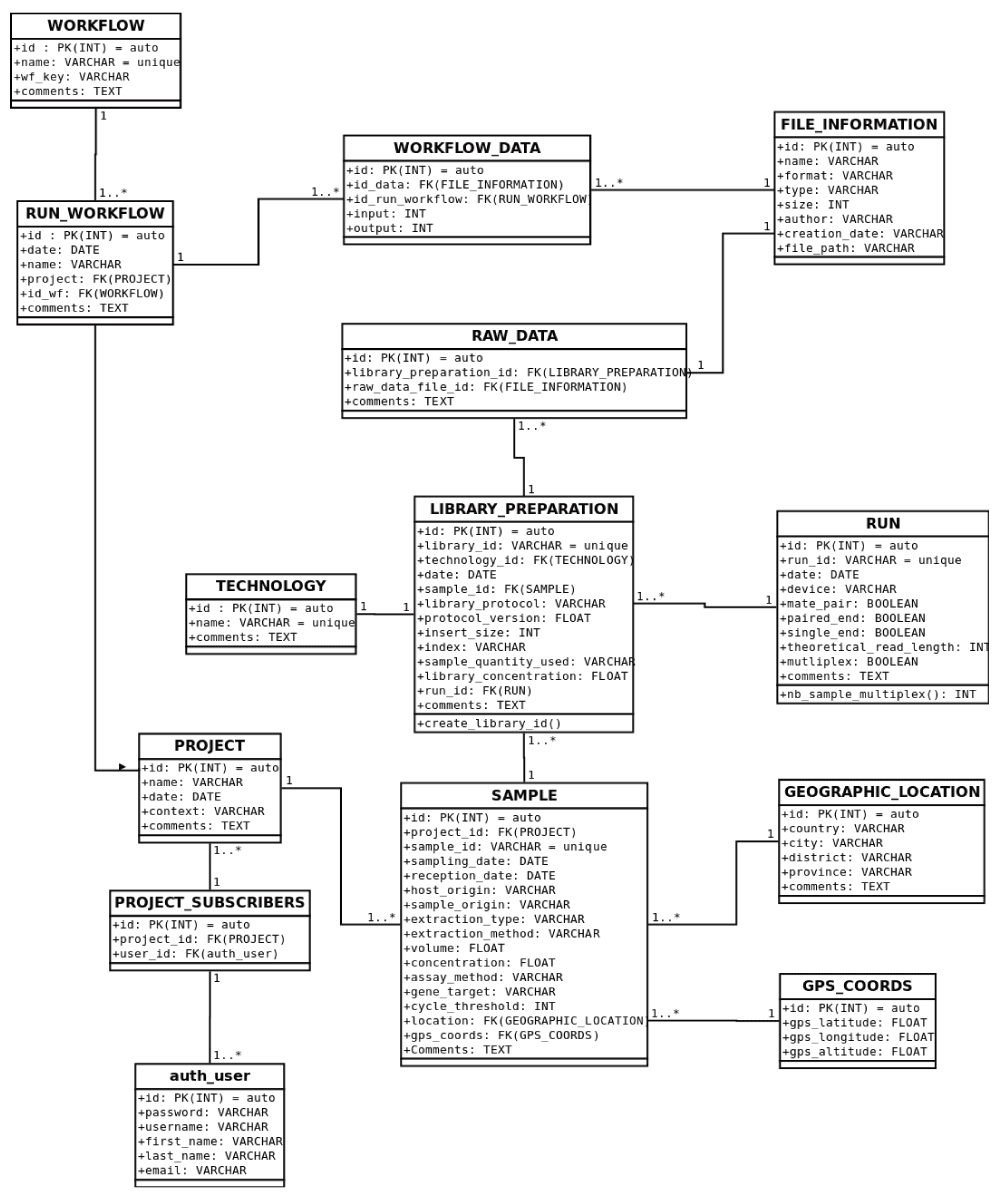
A LIMS can be described as a software-based laboratory that offers a set of key features that support modern laboratory operations. Those systems have become mandatory to manage the quantity of metadata related to both raw data and their analysis results, obtained through bioinformatic tools. In this project, the LIMS is based on a postgresql database. It was designed and structured with expert knowledge from biologists and bioinformaticians with sequencing competence, in order to answer their specific needs ensued by the sample management. Its main feature is that it was also designed to store interesting and worth sharing information obtained by the analysis, as well as the information about the type of workflow that was used to perform the bioinformatics treatment. The database’s schema is available in the Supplementary Figure 1. We provide here an excerpt of the existing tables (divided in three categories): (1) experimental data (LIBRARY_PREPARATION, SAMPLE, TECHNOLOGY, RUN, GEOGRAPHIC_LOCATION, GPS_COORDS), (2) bioinformatic metadata (RAW_DATA, FILE_INFORMATION, WORKFLOW_DATA, RUN_WORKFLOW, WORKFLOW), and (3) user and project data (PROJECT, PROJECT_SUBSCRIBERS, AUTH_USER).
Django is a high-level Python Web framework. It encourages rapid development and clean, pragmatic design. It is used by many known websites. Moreover, the python language (https://www.python.org/) has become a reference for scientific applications.
MetaGenSense is divided in 4 sub-applications which are: 1) user_management, 2) lims, 3) workflow_remote, 4) analyse. Each has a specific function, and the task-partitioning has been designed to allow independent evolution of each part according to the user’s needs.
1. user_management: manages user authentication. Examples of implementations comprehend communication with an LDAP user authentication database, but it can be used as a user management database.
2. lims: ensures the organization and the data partitioning according to the selected project. A project contains sample metadata, and enables to share them only with selected. This part of the application handles sample traceability, an important component of any present-day core resource laboratory.
3. worflow_remote: is in charge of the communication with Galaxy. It manages: (a) the instance connection, (b) the user histories (c) the data from galaxy libraries, (d) import of data from a data library to a Galaxy user-history instance. (e) Execution of the selected galaxy workflow. This application handles data storage and links the samples to the selected workflow. In practice, this application could access any of the BioBlend functionalities.
4. analyse: deals with the workflow result files. The user can choose to “save” a file in order to share the results with the other users involved in the project. Large data result files can be exported using the Galaxy export functionality or can be downloaded (if the results file can be dealt with through a web browser).
The following paragraph discusses communication between MetaGenSense and Galaxy. Scientists and data-managers use Galaxy to facilitate bioinformatics analysis. A large number of XML formatted tool-configuration files have already been integrated, facilitating the execution of e.g. a mapping tool like BWA4 through galaxy instead of executing it using the command line.
For programming purposes and in order to interact with Galaxy using command line, the Galaxy team initially implemented a Galaxy-API (which allowed, for example, retrieval of the user list of a Galaxy instance, to create a library for a specific user, etc.,). However, this project was rapidly replaced by a highly dedicated and specific python library called BioBlend5. This API gives access to most Galaxy functionalities through scripts and command lines. We prototyped our instances of BioBlend, and validated each task that MetaGenSense was submitting to Galaxy (Figure 1). At the time of development, specific functionalities were not fully ready to use (e.g. the Tools.run_tools function), which made us interact with the BioBlend development team for concomitant finishing and perfection of the tools and accompanying API.
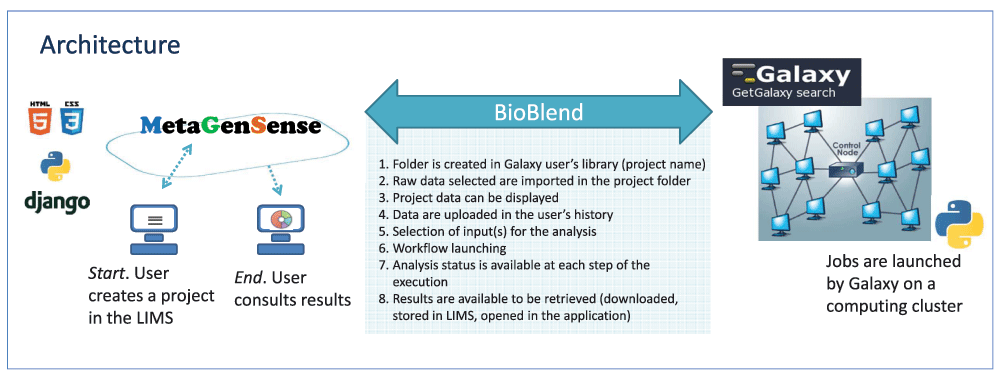
As mentioned earlier, the sub-application workflow_remote from the web interface uses BioBlend functionalities described in Figure 1.
Everything is integrated and automated except the big data management. Indeed, MetaGenSense senses when new files are copied within the exchange galaxy project directory, but those data need to be copied there using a UNIX terminal or a FileZilla-like solution (https://filezilla-project.org/).
The MetaGenSense project was initially implemented and validated for metagenomic analyses; most of its uses concern two prototyped workflows designed to preprocess raw fastq data, analyse it and determine the taxonomy distribution within the sample. However, any other type of workflow can be associated to the MetaGenSense application. This only requires an admin user and a workflow identifier.
We exemplify a use-case of MetaGenSense’s use through the analysis of a batch of biological samples for a dedicated project. The necessary steps to obtain a running MetaGenSense instance, with management of project data and analysis using workflows, are the following:
0/ Log onto MetaGenSense.
1/ Creation of a new project, with a name, a context, a short description and (most importantly) the other persons involved in the project.
2/ Start filling the LIMS database. Enter: a. the sample information b. the library sequencing protocol, c. the run details and d. the raw data file list. The raw data will be subjected to bioinformatic analysis.
3/ At this step, the user needs to use a terminal (or a FileZilla-like tool) to connect to its transfer directory. Create a subdirectory named after the project, and copy the raw data in that directory. This protocol enables MetaGenSense to detect (Sense) the files that will be copied into the Galaxy instance and analysed.
4/ Back on the MetaGenSense GUI, the user needs to click on the “Workflows” button, and click on “import new files” button to import into Galaxy the inputs that were transferred at the previous step.
5/ Create a Galaxy history,
6/ select the workflow,
7/ select the workflow input(s),
8/ launch the analysis,
9/ follow the workflow status,
10/ At each step, the user has three choices: If the results file sizes are larger than 2 GB, they can be exported (using the native Galaxy tools), or if the file sizes are smaller than 2 GB, they can be downloaded or saved in the LIMS, be tagged as interesting and shared with other project members.
11/ Visualization of the results by clicking on the “Analyse” button. All workflow inputs as well as LIMS result files are visible on this tab. Krona6 representation can easily be visualized if stored in html files.
The technology evolution in molecular biology, especially in NGS, has moved biology into the big data era (consisting of handling data, computation requirements, efficient workflow design, and knowledge extraction). With this trend, the challenges faced by life scientists have been shifted from data acquisition to data management, processing, and knowledge extraction. While many studies have recognized the big data challenge, few systematically present approaches to tackle it. New findings in biological sciences usually come out of multi-step data pipelines (workflows). Galaxy is such a workflow-managing tool dealing with big data. However, it is still necessary to globally optimize the data flow in an overall multi-step workflow in order to eliminate unnecessary data movement and redundant computation. On the other hand, data information traceability has become an inevitable requirement in a present-day laboratory setup. In the meantime, knowledge-embedded data and workflows are expected to be an integral part of future scientific publications.
We therefore, engineered MetaGenSense, a Django-based web interface which helps biologists, who are unfamiliar with the design of Galaxy workflows, to quickly obtain analysis results from HTS sequencing projects. It uses Galaxy as a workflow management software and the BioBlend API to remotely manage data upload, workflow execution as well as analysis of results. MetaGenSense covers data processing up to presentation of data and results in a genome browser compatible data format. Its main advantages encompass data handling through its incorporated LIMS, user and project handling in a cooperative context, it enables data sharing without compromising data confidentiality, it features automated workflow execution, resulting altogether in decreasing the data and analysis delivery time. MetaGenSense is available as open-source from GitHub, and can be deployed very easily. Though the prototyped tool is mainly focused on metagenomic sample analysis, its modularity allows it to be easily complemented, through project-specific Galaxy workflows, for a variety of other NGS related initiatives.
DC, ODA, MV, JBD and VC designed and implemented the software. DC, ODA and MV wrote the manuscript. VC supervised the project, contributed to discussion and reviewed the manuscript. All authors approved the final manuscript.
Damien Correia and Olivia Doppelt-Azeroual were financed by the “COMMISSARIAT A L’ENERGIE ATOMIQUE ET AUX ENERGIES ALTERNATIVES” in the scope of a national anti-terrorism fight NRBC project.
I confirm that the funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
{kind=link}
Comments on this article Comments (0)