Keywords
fMRI, human, cognition, preprocessed,
This article is included in the INCF gateway.
fMRI, human, cognition, preprocessed,
The recently published Consortium for Neuropsychiatric Phenomics (CNP) dataset1 is large (272 participants), diverse (healthy controls as well as individuals diagnosed with schizophrenia, bipolar disorder, and attention deficit/hyperactivity disorder), and rich in phenotypic information (each participant filled 42 questionnaires) dataset. It is undoubtedly a rich resource for the academic community. However, before any brain behaviour relationships could be answered, computationally expensive and processing steps need to be performed2. In addition to requiring a lot of resources, a certain level of expertise in MRI data processing and fMRI task modelling is required before the data could be used to test scientific hypotheses.
To facilitate answering scientific questions using the CNP dataset, we have performed standard preprocessing as well as statistical modeling on the data, and are making the results of these analyses openly available. The preprocessing was designed to facilitate a wide range of analyses, and includes outputs in native (aligned with participants T1 weighted scan), MNI (volumetric) and fsaverage5 (surface) spaces. The data has not been denoised, but potential confound regressors have been calculated for each run, giving researchers the freedom to fit many different models that incorporate different denoising schemes. In addition, we also include group and single subject statistical maps for all tasks available in the original dataset. This preprocessed dataset joins the ranks of similar initiatives for other openly shared datasets3–5, and we hope it will be equally useful to the scientific community.
For scanning parameters and details of the task fMRI paradigms, see 1. The input dataset was acquired from OpenfMRI.org6 - accession number ds000030, revision 1.0.3.
Results included in this manuscript come from preprocessing performed using FMRIPREP version 0.4.4 (http://fmriprep.readthedocs.io), a Nipype7 based tool. FMRIPREP was run with the following command line arguments:
--participant_label {sid} -w $LOCAL_SCRATCH --output-space T1w fsaverage5 template --nthreads 8 --mem_mb 20000
Where {sid} was the participant label and $LOCAL_SCRATCH was temporary folder for storing intermediate results.
Within the pipeline each T1 weighted volume was corrected for bias field using N4BiasFieldCorrection v2.1.08, skullstripped using antsBrainExtraction.sh v2.1.0 (using OASIS template), and coregistered to skullstripped ICBM 152 Nonlinear Asymmetrical template version 2009c9 using nonlinear transformation implemented in ANTs v2.1.010. Cortical surface was estimated using FreeSurfer v6.0.011.
Functional data for each run was motion corrected using MCFLIRT v5.0.912. Functional data was skullstripped using combination of BET and 3dAutoMask tools and was coregistered to the corresponding T1 weighted volume using boundary based registration with 9 degrees of freedom - implemented in FreeSurfer v6.0.013. Motion correcting transformations, transformation to T1 weighted space and MNI template warp were applied in a single step using antsApplyTransformations v2.1.0 with Lanczos interpolation.
Three tissue classes were extracted from T1w images using FSL FAST v5.0.914. Voxels from cerebrospinal fluid and white matter were used to create a mask in turn used to extract physiological noise regressors using aCompCor15. The mask was eroded and limited to subcortical regions to limit overlap with grey matter, six principal components were estimated. Framewise displacement and DVARS16 was calculated for each functional run using Nipype implementation. In addition to those regressors global signal and mean white matter signal was also calculated.
The whole dataset was preprocessed in total three times. After each iteration the decision to modify the preprocessing was purely based on the visual evaluation of the preprocessed data and not based on results of model fitting. First iteration (using FMRIPREP 0.4.2) uncovered inconsistent output image field of view and issues with EPI skullstripping, second iteration (using FMRIPREP 0.4.3) uncovered two cases of failed normalization due to poor initialization. In the final iteration all those issues were resolved. In total the preprocessing consumed ~22,556 single CPU hours.
For more details of the pipeline see http://fmriprep.readthedocs.io/en/0.4.4/workflows.html.
For a full description of the paradigms for each task, please refer to1. We analysed the task data using FSL17 and AFNI18, implemented using Nipype7. Spatial smoothing was applied using AFNI’s 3dBlurInMask with a Gaussian kernel with FWHM=5mm. Activity was estimated using a general linear model (GLM) with FEAT17. Predictors were convolved with a double-gamma canonical haemodynamic response function19. Temporal derivatives were added to all task regressors to compensate variability in the haemodynamic response function. Furthermore, the following regressors were added to avoid confounding due to motion: standardised dvars, absolute dvars, the voxelwise standard deviation of dvars, framewise displacement, and the six motion parameters (translation in 3 directions, rotation in 3 directions).
For the Balloon Analog Risk Task (BART), we included 9 task regressors: for each condition (accept, explode, reject), we added a regressor with equal amplitude and durations of 1 second on each trial. Furthermore, we included the same regressors with the amplitude modulated by the number of trials before explosions (perceived as the probability of explosions). The modulator was mean centered to avoid estimation problems due to collinearity. For the conditions that require a response (accept, reject), a regressor was added with equal amplitude, and the duration equal to the reaction time. These regressors were orthogonalised with their fixed-duration counterpart to separate the fixed effect of the trial and the effect covarying with the reaction time. A regressor is added for the control condition.
In the retrieval phase of the Paired-Associate Memory Task (PAMRET), we modelled 4 conditions: true positives, false positives, true negatives, false negatives. For each condition, a regressor is modelled first with fixed durations (3s) and second with reaction time durations, with the latter orthogonalised with the former. With an extra regressor with control trials, there are 9 task regressors in total.
In the Spatial Capacity Task (SCAP), 25 task regressors were included. For each cognitive load (1 - 3 - 5 - 7) and each delay (1.5 - 3 - 4.5) with a correct response, two regressors were added: a regressor with fixed durations of 5 seconds and one with the duration equal to the reaction time, with the second orthogonalised with respect to the first. For both regressors, the onset is after the delay. The last regressor summarises all incorrect trials.
For the Stop-Signal Task (STOPSIGNAL), for each condition (go, stop - succesful, stop - unsuccesful), one task regressor was included with a fixed duration of 1.5s. For the conditions requiring a response (go and stop-unsuccesful), an extra regressor was added with equal amplitude, but the duration equal to the reaction time. Again, these regressors were orthogonalised with respect to the fixed duration regressor of the same condition. A sixth regressor was added with erroneous trials.
In the Task Switching Task (TASKSWITCH), all manipulations were crossed (switch/no switch, congruent/incongruent, CSI delay short/long), resulting in 8 task conditions. As in the SCAP task, we added for each condition two regressors: a regressor with fixed durations of 1 second, and one with the duration equal to the reaction time, with the second orthogonalised with respect to the first. There is a total of 16 regressors.
For subjects who are missing at least one regressor used in the contrasts, the task data are discarded. This is the case for example when no correct answers are registered for a certain condition in the SCAP task. For the SCAP task, we discarded 16 subjects; 14 subjects were removed for TASKSWITCH, 2 subjects for STOPSIGNAL, 2 subjects for BART, and 12 for PAMRET.
All modelled contrasts are listed in the Supplementary material. As is shown, all contrasts are estimated and tested for both a positive and a negative effect.
The total number of subjects modelled in the BART task is 259, while 244 subjects were modelled for the SCAP task. 254 subjects were included the TASKSWITCH task analysis, 197 subjects in the PAMRET task and 255 subjects in the STOPSIGNAL task.
Subsequent to the single subject analyses, all subjects were entered in a one-sample group level analysis for each task. Three second level analysis strategies were followed: (A) ordinary least squares (OLS) mixed modelling using FLAME17, (B) generalized least squares (GLS) with a local estimate of random effects variance, using FSL17, and (C) non-parametric modelling (NP) using RANDOMISE20, with the whole brain first level parameter estimates for each subject as input, and 10,000 permutations. The first two analyses use a group brain mask with voxels that were present in 100% of all subjects. For the permutation tests, a group mask was created where voxels were discarded for further analysis if less than 80% of the subjects have data in those voxels.
In addition to group level statistical maps, activation count maps (ACMs) were generated to show the proportion of participants that show activation, rather than average activation over subjects21. These maps indicate whether the effects discovered in the group analyses are consistent over subjects. As in 21, the statistical map for each subject is binarized at z=+/-1.65. For each contrast, the average of these maps is computed over subjects. The average negative map (percentage of subjects showing a negative effect with z < -1.65) is subtracted from the average positive map to indicate the direction of effects.
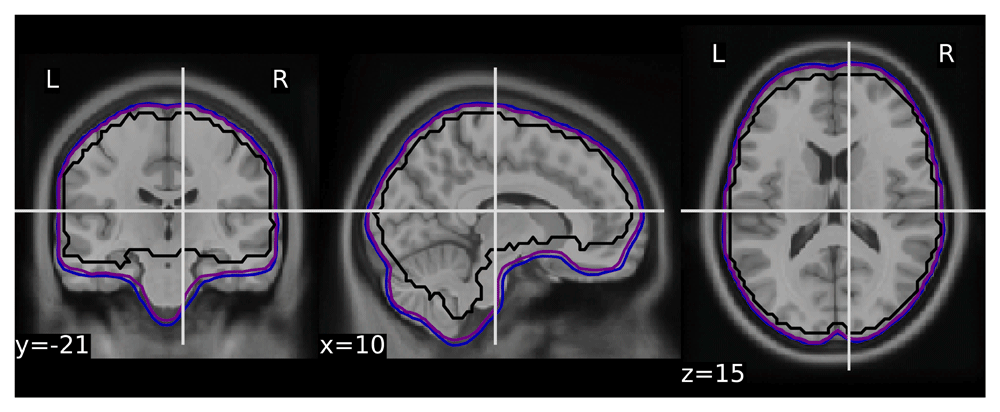
To validate the quality of volumetric spatial normalization we have looked at the overlap of the EPI derived brain masks in the MNI space (across all participants and runs - total of 1,969 masks - see Figure 1). The within subject coregistration and normalization worked well for the vast majority of participants, creating a very good overlap. All of the issues observed while processing the dataset are listed in Table 1.
A selection of the tested contrasts in the task analyses is shown in Figures 2 to 6. Figures were generated using nilearn22.
List of problems with the raw data we were aware of at the time of writing that impacted preprocessing.
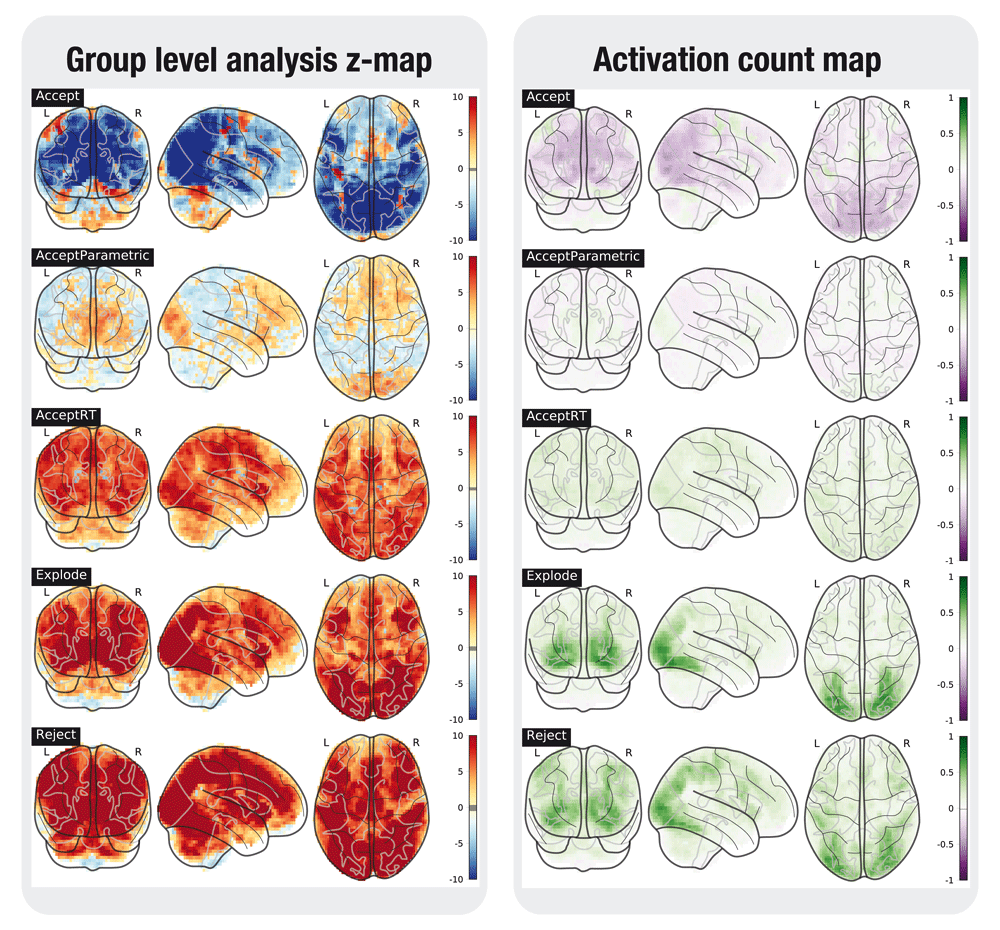
In the left plot, the statistical map of the one-sample group test, computed with randomise. The right plot shows the difference between the positive and the negative activation count maps.
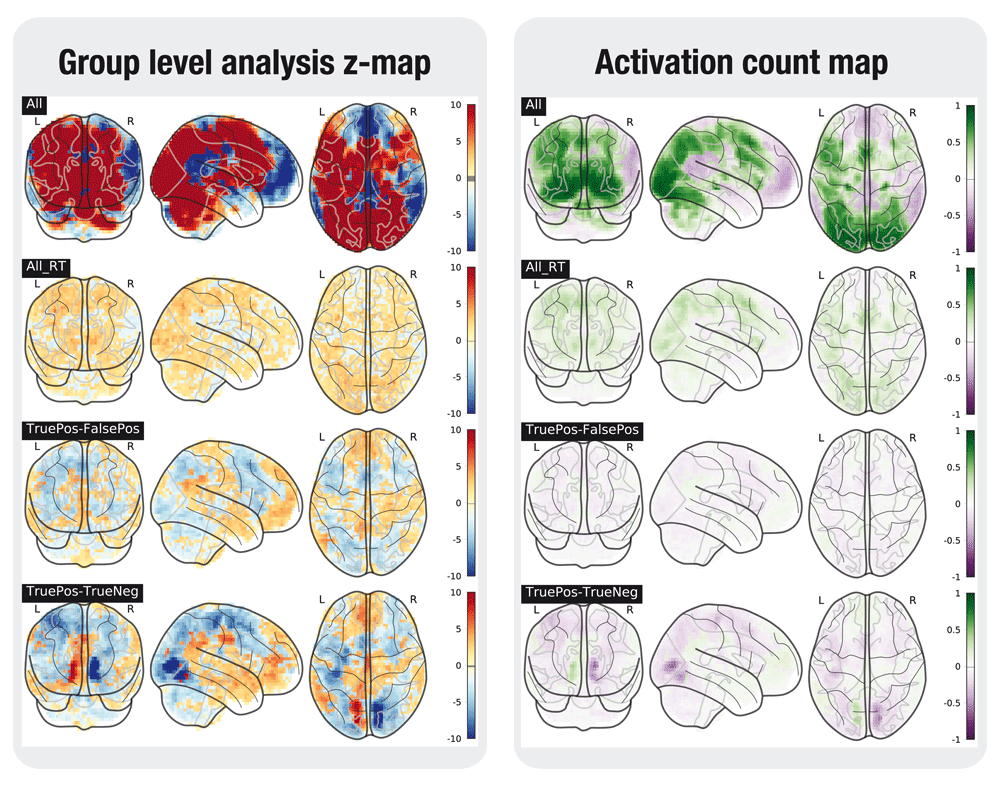
In the left plot, the statistical map of the one-sample group test, computed with randomise. The right plot shows the difference between the positive and the negative activation count maps.
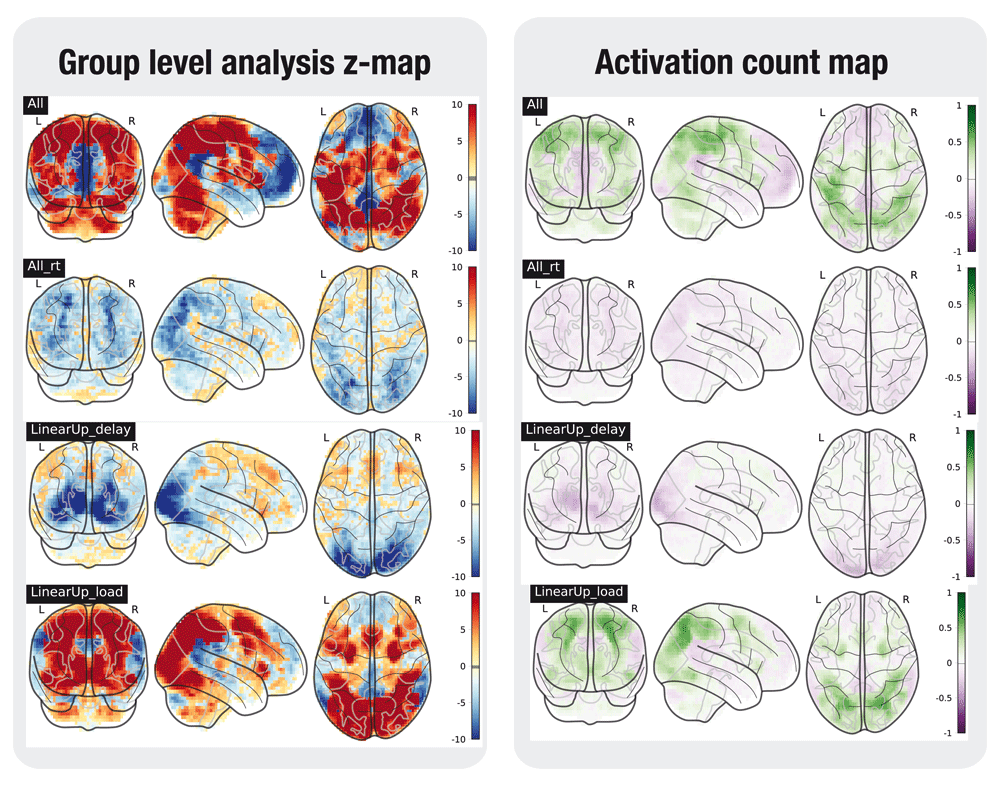
In the left plot, the statistical map of the one-sample group test, computed with randomise. The right plot shows the difference between the positive and the negative activation count maps.
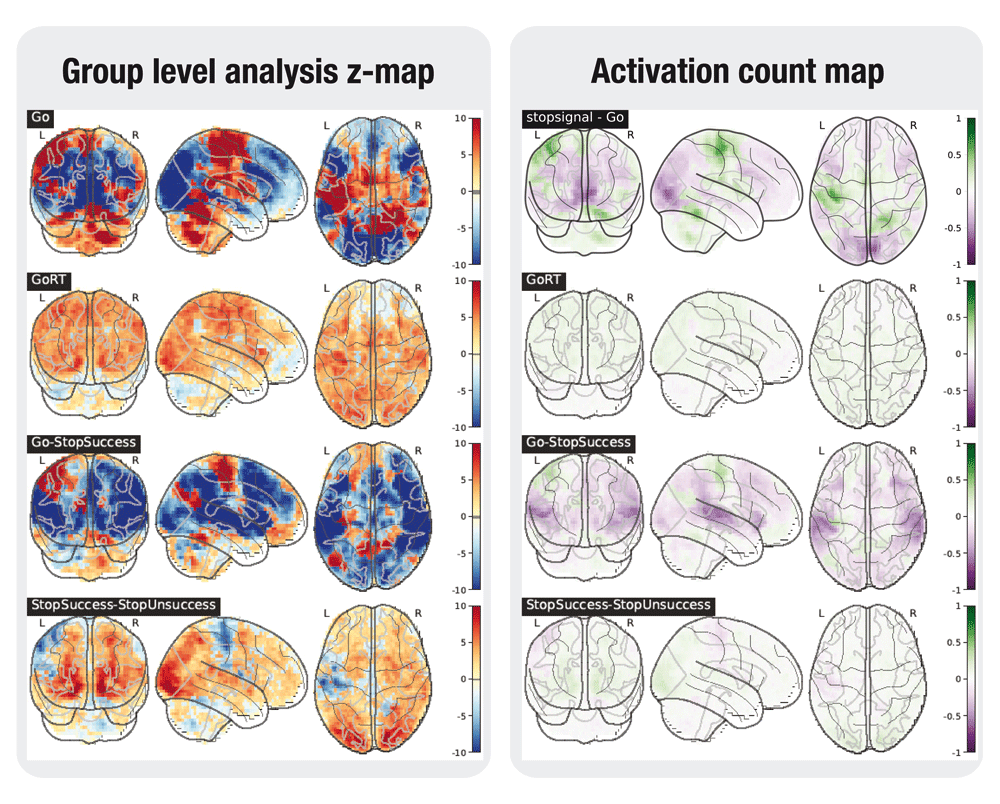
In the left plot, the statistical map of the one-sample group test, computed with randomise. The right plot shows the difference between the positive and the negative activation count maps.
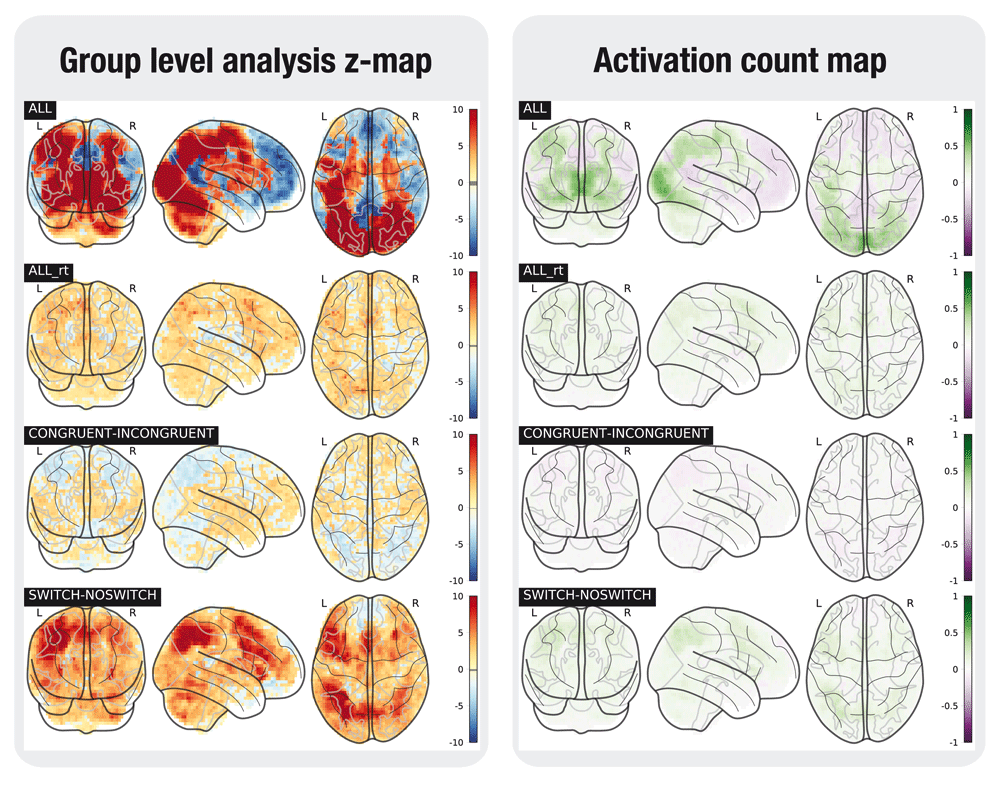
In the left plot, the statistical map of the one-sample group test, computed with randomise. The right plot shows the difference between the positive and the negative activation count maps.
The preprocessed images were deposited along the original dataset in the OpenfMRI repository – accession number: ds0000306, under the revision 1.0.4. The preprocessed data is organized according the draft BIDS derivatives specification. All FMRIPREP derivatives are organised under fmriprep/sub-<participant_label>/
Derivatives related to T1 weighted files are in the anat subfolder:
*T1w_preproc.nii.gz - bias field corrected T1 weighted file, using ANTS’ N4BiasFieldCorrection
*T1w_brainmask.nii.gz - brain mask derived using ANTS
*T1w_dtissue.nii.gz -tissue class map derived using FAST.
*T1w_class-CSF_probtissue.nii.gz, *T1w_class-GM_probtissue.nii.gz, *T1w_class-WM_probtissue.nii.gz - probability tissue maps.
All of the above are available in native and MNI space.
*T1w_smoothwm.[LR].surf.gii - smoothed GrayWhite surfaces.
*T1w_pial.[LR].surf.gii - pial surface.
*T1w_midthickness.[LR].surf.gii - MidThickness surfaces.
*T1w_inflated.[LR].surf.gii - FreeSurfer inflated surfaces for visualization.
*T1w_space-MNI152NLin2009cAsym_class-CSF_probtissue.nii.gz, *T1w_space-MNI152NLin2009cAsym_class-GM_probtissue.nii.gz, *T1w_space-MNI152NLin2009cAsym_class-WM_probtissue.nii.gz - probability tissue maps, transformed into MNI space.
*T1w_target-MNI152NLin2009cAsym_warp.h5 Composite (warp and affine) transform to transform participant's T1 weighted image into the MNI space
Derivatives related to EPI files are in the func subfolder:
*bold_space-<space>_brainmask.nii.gz Brain mask for EPI files.
*bold_space-<space>_preproc.nii.gz Motion-corrected (using MCFLIRT for estimation and ANTs for interpolation) EPI file
All of the above are available in the native T1 weighted space as well as the MNI space.
*bold_space-fsaverage5.[LR].func.gii Motion-corrected EPI file sampled to surface.
*bold_confounds.tsv A tab-separated value file with one column per calculated confound (see Methods) and one row per timepoint/volume
The results of the single subject task modeling are available in task/sub-<participant_label>/ and the group level results can be found in task_group/. Each subject-specific folder holds 5 folders - bart.feat, scap.feat, pamret.feat, stopsignal.feat, taskswitch.feat - with the results from the respective task modeling, organised as standard FEAT output. The group-level folder contains a folder for every task, in turn containing a folder for each contrast (see Supplementary material for naming conventions) and below those folders are the results of the three modeling strategies.
In addition, the dataset includes visual quality HTML reports (one per participant).
The results for each contrast in the one-sample group task analyses are deposited and can be interactively viewed in NeuroVault23: http://neurovault.org/collections/2606/.
Latest source code used to produce the task analyses: https://github.com/poldracklab/CNP_task_analysis
Archived source code as at the time of publication: http://doi.org/10.5281/zenodo.83231924.
License: MIT license.
All code has been run through a singularity container25, created from a docker container poldracklab/cnp_task_analysis:1.0 available on docker hub (https://hub.docker.com/r/poldracklab/cnp_task_analysis/).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)