Keywords
DNA Sequencing, Genome Informatics, Nanopore Sequencing, Compression, Data Storage
This article is included in the Nanopore Analysis gateway.
This article is included in the Python collection.
DNA Sequencing, Genome Informatics, Nanopore Sequencing, Compression, Data Storage
Oxford Nanopore Technologies’ (ONT) nanopore sequencing technology MinION provides a high-throughput, low-cost alternative to traditional Next-Generation Sequencing (NGS) technologies1. The sequencing device itself is handheld and connects by USB to a laptop computer. Together with all equipment and reagents required for DNA library preparation, the equipment required to use MinION is minimal; entire laboratories have even been transported overseas in a suitcase, allowing a versatile and agile approach towards DNA and RNA sequencing2.
Over the course of ONT’ Early Access Program, several improvements in software and chemistry have led to a rapid increase in yield, through an increase in average read length, an improvement in basecalling accuracy rates and an increase in total number of reads. In October 2015, the MinION Analysis and Reference Consortium (MARC), using R7.3 flow cells and SQK-MAP005 (2D) chemistry, reported a median of 60,600 reads with a median yield of 650,000 events across 20 MinION experiments3. In contrast, ONT claim to have obtained a total base yield of 17 gigabases using an R9.4 flowcell on the latest version of their MinKNOW software (https://nanoporetech.com/about-us/news/minion-software-minknow-upgraded-enable-increased-data-yield-other-benefits). The drastic increase in data generation from a single experiment is rapidly becoming the limiting factor in uptake of the technology.
The concerns over data storage extend beyond the data generation capabilities of a single flowcell. Recent attempts to perform de novo assembly of eukaryotic genomes have combined the data generated by multiple flowcells in order to gain sufficient coverage of the genome4. To this end, ONT have begun the pre-commercial release of the PromethION, a benchtop nanopore sequencing device with 48 flowcells. In addition, each of these flowcells contains 3000 channels, as opposed to the 512 channels in a single MinION flowcell, with data generation projected at 6 terabases per flowcell per day5.
Numerous methods have been developed for the efficient analysis of the increasingly large nanopore datasets. However, current methods to reduce the data storage footprint are extremely limited. Nanopore runs uploaded to online repositories, such as the European Nucleotide Archive, are bundled into a tarball, a process which facilitates upload as a single file, but does not decrease file size. Moreover, ONT runs bundled into a tarball (which could then be compressed using traditional means) are not able to be read by any existing nanopore analysis tools. Moreover, traditional compression technologies are poorly adapted to the needs of the individual user, many of whom have no need for a large portion of the data stored by ONT’s basecallers. Therefore, we developed Picopore, a tool for reducing the storage footprint of the ONT runs without preventing users from using their preferred analysis tools. Picopore uses a combination of storage reduction techniques, including built-in dynamic compression in the HDF5 file format, reduction of data duplication, efficient allocation of memory within the file, and the removal of intermediate data generated during basecalling, which is deemed unnecessary by the end-user.
Picopore is developed using the Python h5py module (http://www.h5py.org/), an interface to the HDF5 file format (http://www.hdfgroup.org/HDF5), used by ONT under the FAST5 file extension. Picopore implements a number of different compression methods, a selection of which are applied according to user preferences, before using HDF5’s h5repack to rebuild the file according to the reduced file size requirements.
Built-in GZIP compression. The HDF5 file format allows for both files and datasets within files to be written using a number of different compression filters, the most universally implemented being GZIP. GZIP applies traditional compression to the data stored in the HDF5 file with choices of compression level between 1 and 9. ONT’s default compression uses GZIP at level 1; Picopore increases this to level 9 in order to decrease disk space usage.
Dynamic memory allocation for variables. Data stored in the HDF5 file format uses fixed-size file formats provided by NumPy, which provides a vast array of options for storing integers, decimals and strings within high-dimensional datasets6. ONT’s native data is written using the largest data types provided by NumPy: 64-bit integers, 64-bit decimals, and "variable-size" strings. Picopore vastly reduces disk space usage by analyzing each dataset to determine the minimum number of bytes required by a given variable in the file, changing the data type accordingly.
Collapsing of file structure. The advantage of the HDF5 file format is that it provides a file directory-like storage format for datasets and properties, making reading and writing to the files straightforward and easy to understand. However, the inherent nature of the highly-structured file format requires HDF5 to allocate slots of memory to "groups", which represent the internal directory structure of the file. Picopore reduces the disk space used by this file metadata by collapsing the directory structure, while retaining the option for users to reverse this action when tools that only recognize the original file format are required.
Indexing of duplicated data. ONT’s most widely used basecalling software, the cloud-based Metrichor service (https://metrichor.com/s/), performs feature recognition (or "event detection"). This segments the electrical signal representing each nanopore read into events, each of which represents a period of time when the DNA was stationary in the nanopore. These events are then converted into basecalled data, which provides a single k-mer (at present a 5-mer) of DNA representing the bases in the nanopore contributing to the signal at that time. Each event corresponds to a single row in the basecalled dataset, and both the event detection and basecalled datasets thus store the mean signal, standard deviation, start time and length of the event. Picopore reduces disk space usage by indexing the basecalled dataset to the event detection dataset, removing the duplicated data while retaining the option for users to reverse this action when tools that require access to this data are required.
Removal of intermediate data. The primary function of all basecalling software is to generate a FASTQ file containing the genomic sequence and associated quality scores representing the read stored in each FAST5 file. While some software tools, such as nanopolish7 and nanoraw8, do make use of the signal, event detection and basecalled datasets, the large majority of analyses, including alignment, assembly and variant calling, simply require access to the FASTQ data. Picopore allows users to remove the intermediate data generated during the process of converting raw signal to FASTQ, while retaining the signal data, should they ever want to re-basecall the run to attain improved FASTQ data or to access this intermediate data at a later stage.
Requirements. Picopore is built in Python 2.7 (www.python.org) and runs on Windows, Mac OS and Linux. It requires the following Python packages:
In addition, Picopore requires HDF5 1.8.4 or newer, with development headers (libhdf5-dev or similar), including the binary utility h5repack, which is included therein.
Installation. The latest stable version of Picopore is available on PyPi and bioconda (see Software availability). It can be installed according to the following commands:
Linux and Mac OS: pip install picopore
Windows: conda install picopore -c bioconda -c conda-forge
Picopore can also be installed from source (see Software availability) using the command python setup.py install.
Execution. Picopore is run from the command-line as a binary executable.
Picopore accepts both folders and FAST5 files as input. If a folder is provided, it will be searched recursively for FAST5 files, and all files found will be considered as input.
There are three modes of compression available, each of which performs a selection of the techniques described above.
lossless: performs built-in GZIP compression and dynamic memory allocation for variables. This mode is both fast and allows continued analysis of data by any existing software.
deep-lossless: performs lossless compression, as well as collapsing of file structure and indexing of duplicated data. This mode obtains the best compression results without removing any data, but comes at the cost of requiring reversion before most software tools can analyse the data.
raw: performs lossless compression, as well as removal of intermediate data, partially reverting files to the "raw" pre-basecalled file format. This mode is fast, obtains the best filesize reduction, and allows continued analysis by tools that extract FASTQ and related data, but comes at the cost of removing intermediate basecalling data required for some niche applications, such as nanopolish, which cannot be retrieved by Picopore (but can be regenerated using basecalling software.)
Optional arguments include:
–revert: reverts lossless compressed files to their original state to allow high-speed access at the cost of disk usage;
–realtime: watches for file creation in the given input folder(s) and performs the selected mode of compression on new files in real time to reduce the footprint of an ongoing MinION run;
–prefix: allows the user to specify a filename prefix to prevent in-place overwriting of files;
–group: allows the user to select only one of the analysis groups on files that have been processed by multiple basecallers;
–threads: allows the user to specify the number of files to be processed in parallel.
To demonstrate the effectiveness of Picopore’s compression, we ran all three modes of compression on four toy datasets of 40 FAST5 files run using the R9 SQK-RAD001 (R9_1D), R9 SQK-NSK007 (R9_2D), R9.4 SQK-RAD002 (R9.4_1D) and R9.4 SQK-LSK208 (R9.4_2D) protocols. The files for the toy datasets were chosen randomly from the pass folder of four MinION datasets generated at the Australian Genome Research Facility (see Software and data availability). For the R9_1D dataset, DNA was extracted from the lung of a juvenile 129/Sv mouse using the DNeasy Blood and Tissue kit (Qiagen). For the R9_2D, R9.4_1D and R9.4_2D datasets, DNA was extracted from a culture of escherichia coli K12 MG1655 using the Blood & Cell Culture DNA Kit (Qiagen). Quality control performed by visualisation on the TapeStation (Agilent). Run metadata is shown in Table 1.
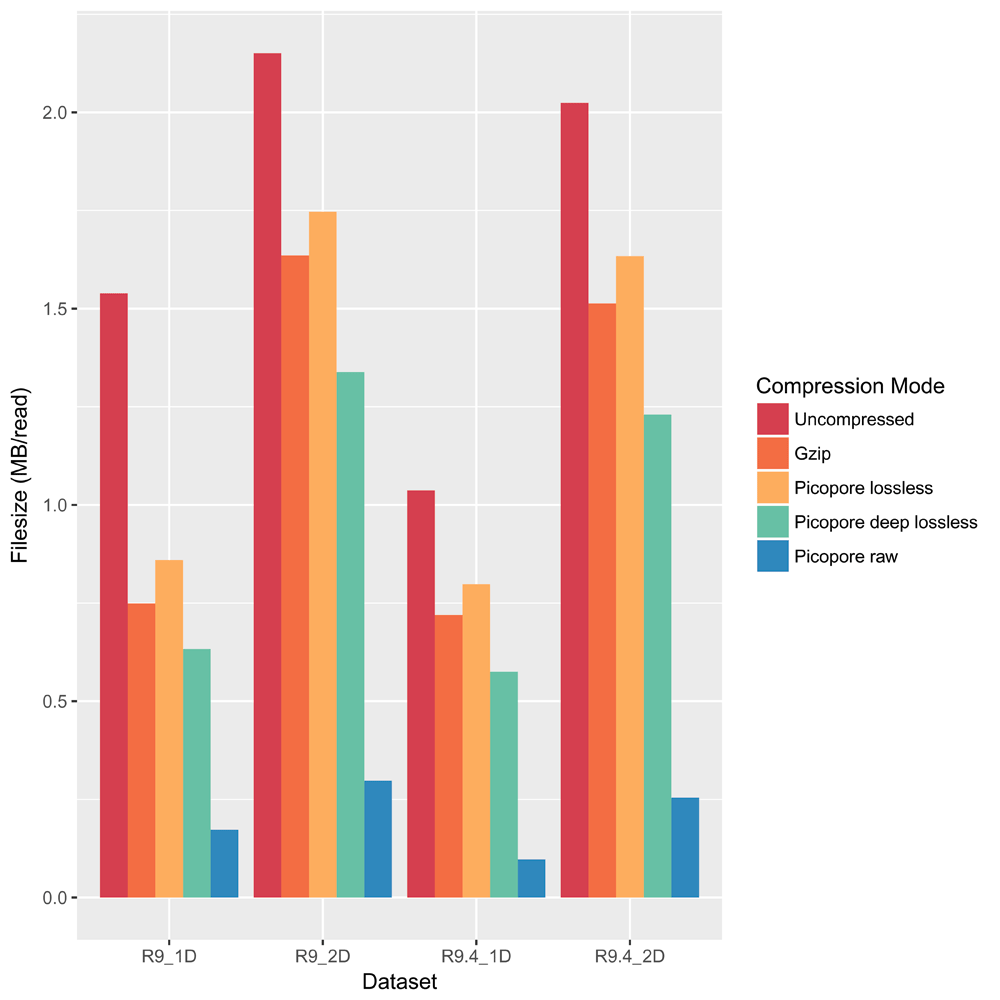
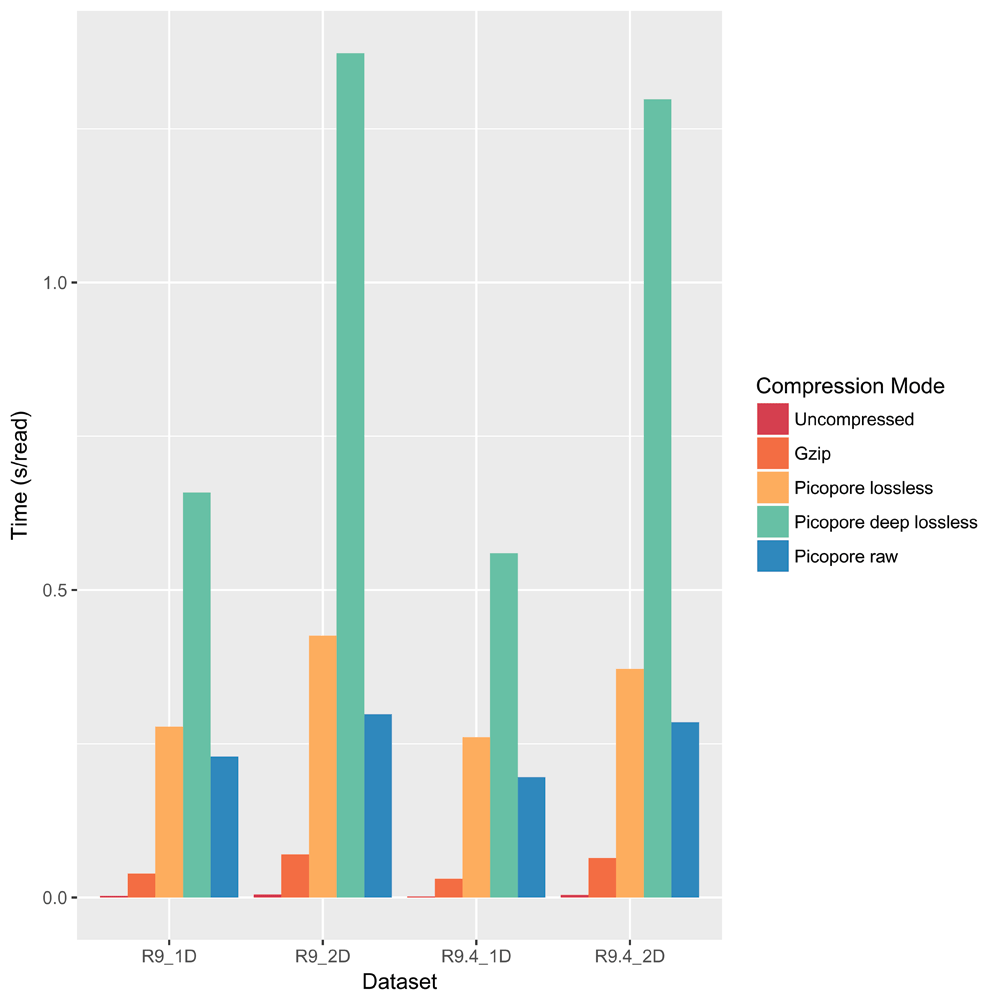
Each file was compressed and tarred using each of five methods: no compression, gzip (applied after tarring, as per convention), picopore lossless, picopore deep-lossless and picopore raw. Each of these methods was run on a single core. Figure 1 shows that lossless achieves only slightly less compression than gzip, giving an average reduction in size of 25% compared to gzip’s 32%, while deep-lossless and raw perform significantly better, giving average reductions in size of 44% and 88%, respectively. A dependent sample t-test (R v3.3.0) was run on individual compressed file sizes. Table 2 shows that each successive method of compression (excluding gzip, which does not compress individual files) gives a significant reduction in size from the previous. Figure 2 shows that while all of Picopore’s compression methods are much slower than gzip, raw is the fastest of these, followed by lossless and deep-lossless. Note that the tarring time makes up a maximum of 0.04 s/read in each case and is largely negligible.
| Mode 1 | Mode 2 | t-statistic | p-value |
|---|---|---|---|
| uncompressed | lossless | 33.58 | < 10−15 |
| lossless | deep-lossless | 20.14 | < 10−15 |
| deep-lossless | raw | 17.69 | < 10−15 |
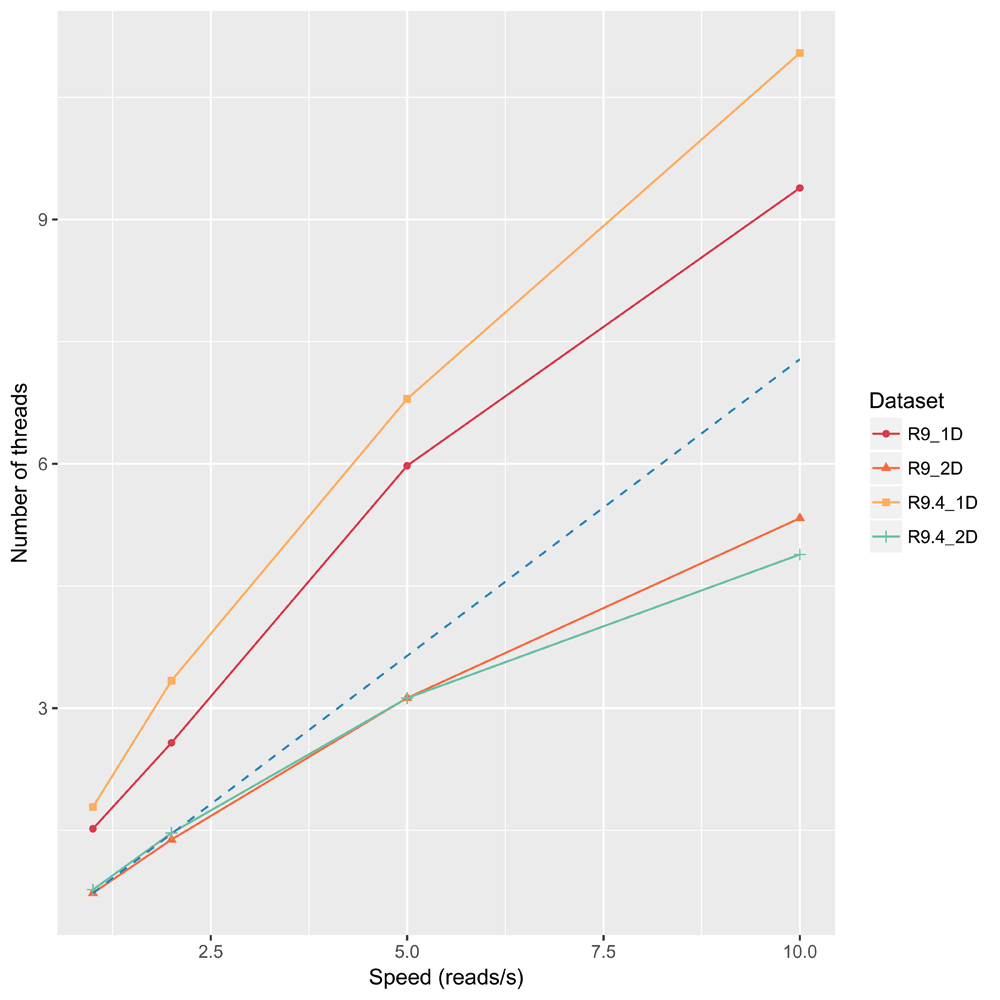
To demonstrate the effectiveness of Picopore’s multithreading, we ran deep-lossless, the most computationally expensive of the Picopore compression methods, on each dataset using 1, 2, 5, and 10 cores. Figure 3 shows an almost linear improvement in speed, showing that even on a small dataset, the multithreading overhead is relatively small.
It is clear that, due to the enormous reduction in disk space and low total time requirements, Picopore’s raw compression is the optimal compression mode for users who have no need for the intermediate event detection and basecalling data. The superior running speed of lossless compression over deep lossless compression may mean that this is the preferred method for users who wish to retain all data and need to compress the data in real-time; however, for users with these data retention requirements who wish to store data long-term on their file server, for whom speed of compression is not an issue, deep lossless compression provides the best option. All Picopore compression methods provide significant improvements over uncompressed or traditionally compressed files, and lossless and raw methods carry the added benefit that files can be processed using analysis tools in compressed form.
Although the compression has a high CPU cost, the capability of Picopore to run on multiple threads signifies that, if computing resources are available, the files can be compressed in a reasonably short period of time. Finally, extrapolating the running time per file to a real-time run of 500,000 reads over 48 hours (0.34 s/read), Picopore has the capability to run lossless (0.33 s/read) and raw (0.25 s/read) modes on a single core in real time. While deep-lossless requires multiple cores to keep pace with the MinION data generation, this adds little to the overall computational cost, and can reach real-time speed with just five cores (0.24 s/read). As data generation continues to increase in scale, further gains could be made by incorporating the compression methods used in Picopore into the basecalling software itself.
ONT’ MinION and PromethION sequencing devices promise to produce increasingly large datasets as the technology progresses toward commercial release. The disk space required to run and store one or multiple datasets from these poses a problem for service providers and users alike; Picopore provides three different solutions that cater to the different needs of users.
Although the trade-off between data retention, computing time and disk space is a compromise that cannot be perfectly resolved, Picopore provides user options to reduce their ONT datasets to the minimum viable size based on their intended use. This may involve real-time compression for laptop disk space concerns, reduction of bandwidth usage for transfer of datasets between laboratories, or reduction of the storage footprint on shared data servers.
Software for Linux or Mac OS available from: https://pypi.python.org/pypi/picopore
Software for Linux, Mac OS and Windows available from: https://anaconda.org/bioconda/picopore
Source code available from: https://github.com/scottgigante/picopore
Archived source code from: https://doi.org/10.5281/zenodo.3219579
License: GPLv3
Dataset 1. Output data generated using Picopore on four toy datasets. Each of the four toy datasets was compressed using each of Picopore’s three compression modes and GZIP. Datasets compressed using Picopore were tarred after compression, while the GZIP dataset was tarred before compression. doi, 10.5256/f1000research.11022.d15337010
The toy dataset used for the analyses in this paper is available on Zenodo: Toy datasets for compression by Picopore, doi: 10.5281/zenodo.32195911.
Chris Woodruff confirms that the author has an appropriate level of expertise to conduct this research, and confirms that the submission is of an acceptable scientific standard. Chris Woodruff declares he has no competing interests. Affiliation: Visiting Scientist at Bioinformatics Division of Walter and Eliza Hall Institute of Medical Research, Parkville, Victoria, Australia.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Click here to access the data.
Spreadsheet data files may not format correctly if your computer is using different default delimiters (symbols used to separate values into separate cells) - a spreadsheet created in one region is sometimes misinterpreted by computers in other regions. You can change the regional settings on your computer so that the spreadsheet can be interpreted correctly.
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Thanks very much for your comments.
My apologies for the error in the PromethION throughput, I had misunderstood the statement in the original reference. I will ... Continue reading Hi Wouter,
Thanks very much for your comments.
My apologies for the error in the PromethION throughput, I had misunderstood the statement in the original reference. I will issue a new version of the paper correcting this.
In regards to kmer length, ONT did indeed move to a 6-mer for the later HMM basecallers, but moved back to a 5-mer for the RNN - there is a brief introduction of this here on the Nanopore Community.
Cheers,
Scott Gigante
Thanks very much for your comments.
My apologies for the error in the PromethION throughput, I had misunderstood the statement in the original reference. I will issue a new version of the paper correcting this.
In regards to kmer length, ONT did indeed move to a 6-mer for the later HMM basecallers, but moved back to a 5-mer for the RNN - there is a brief introduction of this here on the Nanopore Community.
Cheers,
Scott Gigante