Keywords
Brassica, phenotypic trait data, data integration, FAIR data, phenotyping API, crop ontology, genotype-phenotype association, enhanced breeding
This article is included in the Agriculture, Food and Nutrition gateway.
Brassica, phenotypic trait data, data integration, FAIR data, phenotyping API, crop ontology, genotype-phenotype association, enhanced breeding
Brassica is a diverse genus that includes a number of species cultivated as important crops, providing edible roots, leaves, stems, buds, flowers and seed1. Due to their wide adaptation and ability to thrive under varying agroclimatic conditions2, Brassica crops are grown all over the world for food, animal fodder and industrial applications.
Given the importance of Brassica species worldwide, integrated approaches to research and plant breeding for crop improvement are required to address future challenges, such as satisfying increased demand for higher quality or producing reliable yields in a more variable environment with sustainable, lower input cultivation systems. Researchers have quantified many aspects of Brassica phenotypic diversity, including the content of industrially important compounds, yield in response to fertiliser input or degree of resilience to fungal pathogens and pests, such as flea beetles, to aid in crop improvement. The ability to host such data generated from these experiments in an open and accessible database promotes the comparison of trait measurements and calculation of genotype-phenotype (G X E) associations across multiple studies in meta-analyses, potentially identifying underlying common mechanisms or previously unrecorded correlations. This is especially important for plant breeders and researchers involved in pre-breeding, leading to generation of new crop varieties. For example, meta-analysis across different populations or environments can help confirm the location of key areas of the genome identified from multiple studies or assist and help avoid potential trait trade-offs of beneficial or deleterious alleles due to linkage drag. The ability to associate phenotypic data with genomic regions, DNA markers, and genome and transcribed sequence provides the potential to expedite the integration of favorable alleles via marker-assisted or genomic selection. However, few plant phenotype databases exist, despite the importance of phenotypic data to render meaning to sequence data.
Maintenance of easily accessible and reusable plant phenotypic data is challenging because, in contrast to standardised approaches used in sequence analysis, traits can be measured with a variety of protocols whose methods are not captured automatically, and there is mostly no consensus on methodologies to record any given trait. Moreover, there is a lack of controlled vocabularies to describe phenotyping metadata adequately. One possible reason is that, as opposed to publishing sequencing data in databases widely used by the research community, such as ArrayExpress3, GEO (Gene Expression Omnibus)4, ENA (European Nucleotide Archive)5 and SRA (Sequence Read Archive)6, it is not a requirement to submit phenotyping data to a public repository to accompany peer-reviewed publications. There is, to date, no single plant phenotypic database recommended by Nature’s Scientific Data. Compared to sequence data, the formal description of trait and associated meta-data tends to be more complex and crop or species specific.
Data re-use and re-analysis can lead to new knowledge and enhancement in understanding. For example, readily available datasets retrieved from a database can serve 1) as evidence for new claims, 2) to explore existing knowledge and identify gaps, 3) to bridge between research domains or 4) to help with selecting research directions. Additionally, databases can serve as tools for collaboration across countries, fields or areas of expertise and link between research and industry.
Existing Brassica-related databases and analysis tools mostly focus on Brassica genomic information. For example, BRAD7 hosts data on Brassica genomes and PlabiDB8 is a platform that, among others, hosts genomic data from Brassica napus. GnpIS is a complex system that besides sequence and genomic information aims to share transcriptome and phenotype data but at present these data is not publicly available. While these databases are useful in their own context, they do not focus on setting or demonstrate the value of community-wide phenotypic data standards, and therefore do not encourage universal trait sharing and data re-use.
Resources, such as TAIR (arabidopsis.org)9, or Araport (araport.org)10 and the 1001genomes project11, provide data storage and analysis tools for the Arabidopsis Scientific community. Due to the close evolutionary and taxonomic relatedness of the model plant Arabidopsis in the Brassicaceae, Arabidopsis-related databases or platforms for genotype and phenotype information provide valuable insights into the underlying Brassica biology, and potential insights into the crop analysis tools and resources of the future. However, current Arabidopsis resources are not directly applicable to recording genotype-phenotype specific traits of Brassica crops.
CropStoreDB12, the first systematic Brassica phenotype database, was launched as part of InterStoreDB steming from previous efforts such as Integrated Marker System for Oilseed Rape Breeding13, and BrassicaDB14,15. CropStore hosts Brassica trait data, connecting it with relevant sequences in SeqStore for genotype and phenotype data integration.
The Brassica Information Portal builds on the CropStoreDB schema, and provides the technologies to enable efficient storage, classification and management of phenotyping data. Its unique features are the universally applicable Brassica trait Ontology, a Digital Object Identifier (DOI) for each dataset, login via ORCiD (https://orcid.org/), cross-references to sequence information and primary data, user-friendly wizard-based submissions, and Application Programming Interface (API) based data submission and retrieval. In addition, submitted data can be kept private for a user-defined period of time. Extensions for visual data exploration and tools for associative analysis are intended in the future releases, to provide a desired set of features for the Brassica community.
To address the challenges facing a phenotypic trait database, the BIP has implemented rigorous use of ontologies and standards. One element is a dictionary of Brassica-specific traits created according to CropOntology16 for that purpose. The CropOntology phenotype annotation model is based on the combination of “trait method and scale”, as it is grounded in breeder’s datasetformats16. This makes it especially suitable for describing pre-breeding material traits hosted in the portal. The level of detail in the trait definition makes it possible to select meaningful traits for analysis. Hence, the CropOntology encourages a way of defining a trait to facilitate meta-analysis, integrated data analysis and data discovery, some of the main aims of the repository besides data storage.
Further incorporation of ontology includes plant anatomy terms from Plant Ontology17 and taxonomical classification from Gramene’s Taxonomy Ontology18. Cultivar names are curated, and submissions are checked against this curated list.
Initial minimal requirements for trial, population and trait description have been identified and are made compulsory during submission, to associate meaningful experimental meta-data with the trait scores. BIP development is benefiting from discussions on standard minimal requirements for plant phenotyping experiment (MIAPPE) data currently ongoing as part of the Excelerate project run by ELIXIR consortium. MIAPPE functions as a checklist of attributes that can be used to describe each experimental unit19,20, therefore by representation of the most useful information captured by researchers it allows comprehensive data sharing and reuse. A similar approach has been applied previously for other data types, including gene expression microarrays (MIAME), sequencing (GSC), metabolomics (MSI), and proteomics (MIAPE).
In BIP, we are focusing on information related to recording Project, Trial, Sample, Location, Treatment and Trial Environment. Our contribution includes the definition of MIAPPE fields and proposal of ontologies to ensure there is standardised content to describe Brassica phenotyping experiments mapped to these requirements. With regard to file types, the choice of standard input and output file is the .csv format, as it is readable by most software tools and humans alike. Further, the API allows for machine readable .json output format.
The content of the database includes population data with member lines and diversity sets with lines representing cultivars or other ex-situ genetic resource material. Linked to this hierarchical relationship of cultivars and lines are trait scores with associated experimental and organisational metadata. As this repository has inherited its structure and content from CropStoreDB, it also hosts historical QTL and linkage map data linked to experimental segregating populations and trait data. For obvious reasons we do not intend to cater directly for sequencing data, yet we continue to host genotyping data generated through modern DNA, RNA sequencing or genotyping arrays. The BIP currently hosts data from numerous pre-breeding programmes that include 22 plant trials, with 139,000 trait scores from 188 different varieties and 26,100 plant lines.
While the repository lays the foundation for more extensive integration of genotype and phenotype information and tools, it is already integrated with TGAC Browser21 to allow cross-linking of single nucleotide polymorphisms (SNPs) of interest to lines/cultivars in the BIP that may carry the corresponding SNP.
There are three main building blocks that constitute the BIP. The first element is the relational database, which stores and manages all BIP data. It uses PostgreSQL RDBMS technology. BIP’s initial data and the database schema were obtained from the CropStoreDB system and then underwent several transformations, including translation from the original MySQL format to the target PostgreSQL format, i.e. introduction of formal foreign keys and presence constraints, and a series of data curation procedures to ensure referential integrity. The BIP database is the core of the system, enacting all data management operations, issued both through the web interface and the REST API. The decision to transfer data to PostgreSQL was taken as it delivers more advanced, modern capabilities of data management than MySQL, while still being an open source and a free-of-charge solution. The overview of the database schema is presented in Figure 1.
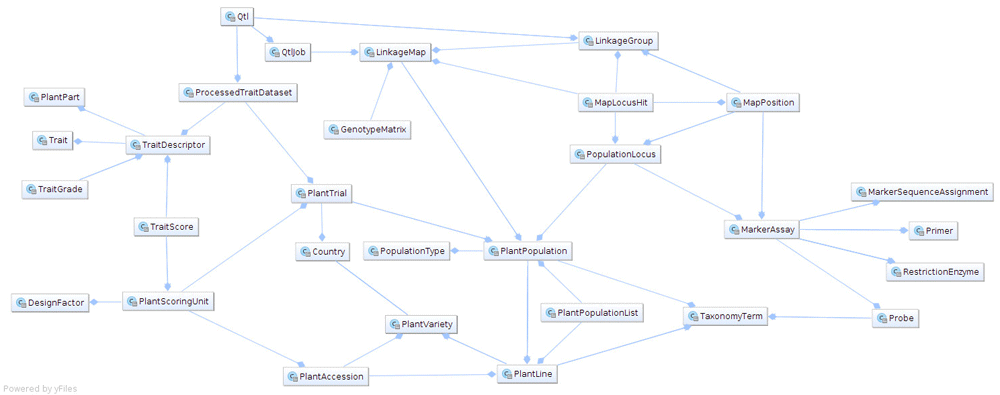
Some “operational” tables, which are used only internally by the system (e.g. for access rights), were omitted.
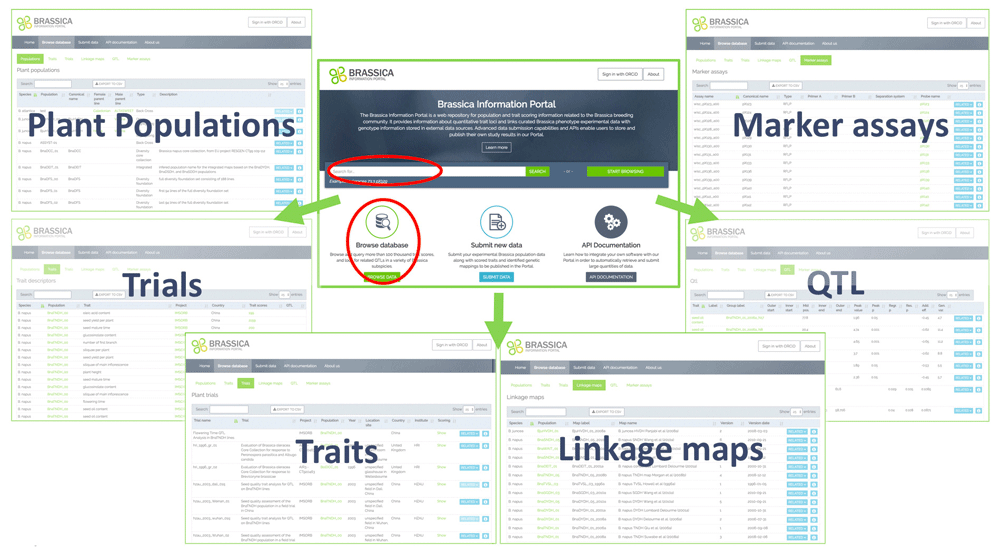
The second element is built on top of the database and is a modern web application. Its purpose is threefold: (i) it delivers advanced data browsing interfaces, which allow for data ordering, filtering and export to CSV documents (available to all users without registration; see Figure 2) (ii) it implements data submission wizards, explained in detail in the section below (for registered users only) (iii) and it gives the possibility of managing data through the API, which supports reading, loading, querying, searching, creating and publishing data.
The web application was created using the Ruby on Rails framework. All web requests are channeled through the Nginx web server, which in turn routes them to a web application logic server (a so-called reverse proxy setup). All traffic is secured with an encrypted HTTPS protocol. User registration is implemented using the third party authentication solution (orcid.org).
The third constituent element of the BIP is the data indexing and full-text search engine. It analyzes all records in every table of the database, including all new data being submitted by users, and creates a search index. The BIP web search functionality (present on the front page of the website; see Figure 2) and its API search capability (available via programmatic access to registered users) is integrated with the search engine in order to deliver the arbitrary term search. For every submitted search term, the engine first looks the term up in the index, and if found, responds with a set of data-table records that include this term. This element of the BIP is created using Elasticsearch technology.
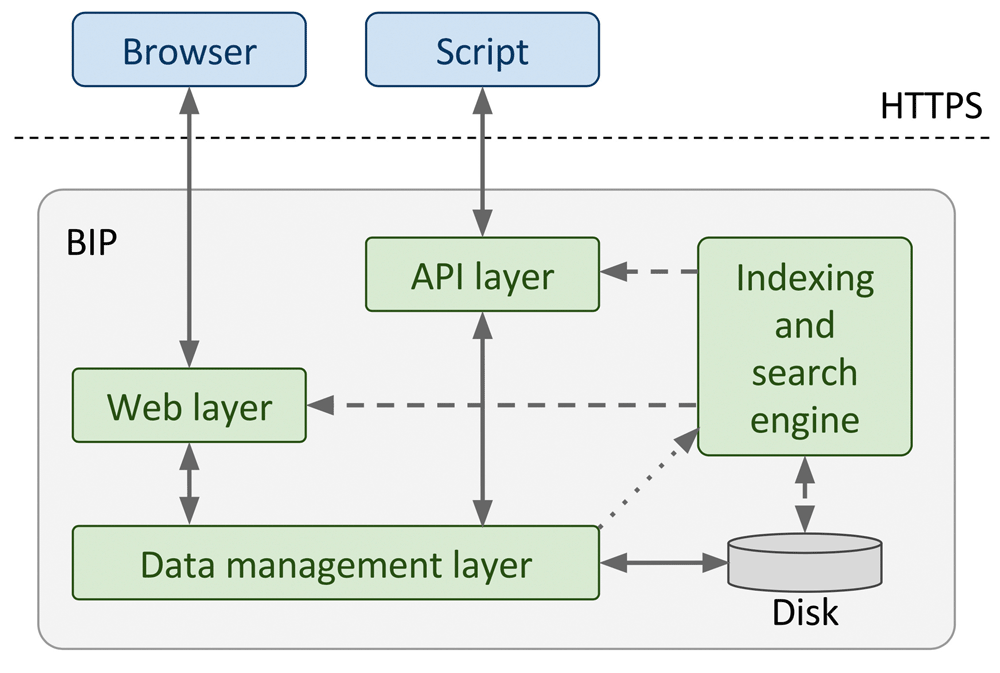
Users initiate actions with either their web browsers or API clients (blue elements). All requests go through respective access control layers (these ensure e.g. that a given set of data is accessible to the user), before they contact the data management layer to retrieve (or commit) data from (to) the database. Access mode is read/write (solid arrows). Additionally the search engine could be required to search through gathered data (dashed arrows) - it’s a read-only access mode. Finally, the data layer informs the search engine about any new data to be indexed (the dotted arrow).
All three elements are presented in Figure 3, together with respective data transfer channels between them. Deployment-wise, the database system, the web application logic server, and the indexing and search engine all reside within a single system. If, in the future, the scale of the data managed by the BIP becomes too high for current machine capabilities, it is possible to decouple these elements in order to distribute the load on several physical servers.
BIP operates at bip.earlham.ac.uk/ and is publicly accessible at this address, as a web resource. However, it is possible to use BIP open source to deploy one’s own BIP instance. In such a case, BIP will require a server, either physical or virtual, with at least two contemporary CPU cores, and at least four gigabytes of operational memory. Due to its internal architecture, described in the previous section, two processor cores are required to achieve a smooth user experience along with simultaneous maintenance of fast database and indexing engine responses. Since the DB and the web application itself makes a heavy use of disk caching mechanisms to provide faster response to user queries, it is also beneficial, though not absolutely required, to equip the server with fast hard drives. The storage space needed depends on the amount of data one plans to deposit in the instance of BIP, but the application itself has no high requirements in this respect, and 6 GB of storage space should be sufficient for both the operating system and all the components of BIP. Any up-to-date Linux operating system will be adequate to host BIP.
Several tables hosting interlinked population, trial, trait score, linkage map, QTL and marker assay data are accessible via the web-interface, either from a universal search, or by browsing the database for specific tables (Figure 2).
Accessing related data is facilitated by following the “Related” button in case of the Populations table, or by clicking onto a cross-linked field within the table (these appear green; Figure 4A). On top of each table, a search bar can query for specific components within the table (Figure 4A). Organisational and provenance metadata are made visible by clicking the blue information button for each row (Figure 4B). Each column can be sorted, resulting in global reordering across the whole table (Figure 4B, red arrow). The visible content of the tables can be downloaded as a .csv file, by clicking on the respective button on top of the table (Figure 4B).
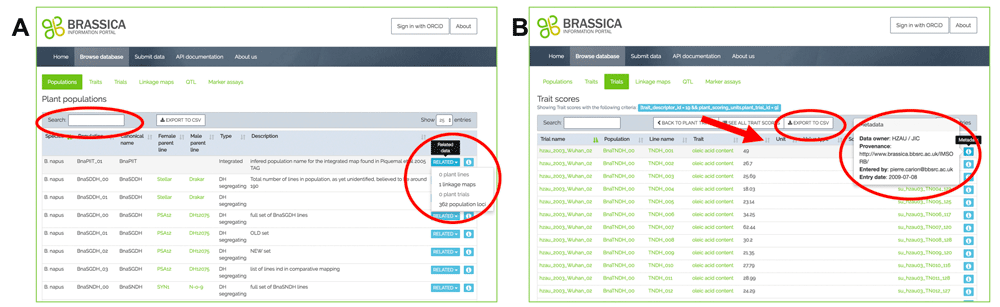
A) refined querying and access to related data B) reordering of results, function for bulk download of data with accompanying meta-data, display of the meta-data.
Experimental data is generally recorded in spreadsheet format. Therefore, both the web form wizard provided within the tool, and the available Ruby script client, use spreadsheet formats as templates to assist the user in uploading the data. Data are submitted in two separate logical batches. First, information about the experimental plant population needs to be submitted. Second, trait data from Trials performed on these plants are submitted during Trait Scoring Submission. This enables the submission of multiple trials per experimental Plant Population.
A wizard-based submission of Population and Trial Data data guides the user through all compulsory and optional field contents that can be submitted to the database. During Population Submission (Figure 5A), a four-step process asks the user to enter population related information, including the submission of the actual lines and associated metadata in a .csv template designed in step 3. The purpose of the template is to make it easier to appropriately format large data sets and avoids spelling mistakes in the uploaded file’s header. The standard template used during Population Submission is shown in Supplementary Figure 1B. Plant variety names are checked for their existence and correct spelling against the database. The final step is the submission of data provenance information. Compulsory metadata for Population Submissions is listed in Supplementary Table 1.
During Trial Submission (Figure 5B), the first steps involve entering trial related information, before the traits studied in the trial are selected or defined in step 2. To avoid duplicated traits, the interface suggests traits based on an elastic search using two or more letters typed by the user. If traits are unavailable, the user can define and add them manually (the Plant and Trait Ontology vocabulary is provided to assist the user in this task). A high quality of trait definition and trait measurement-interoperability between experiments is ensured by interposing a human curator between submitter and database.
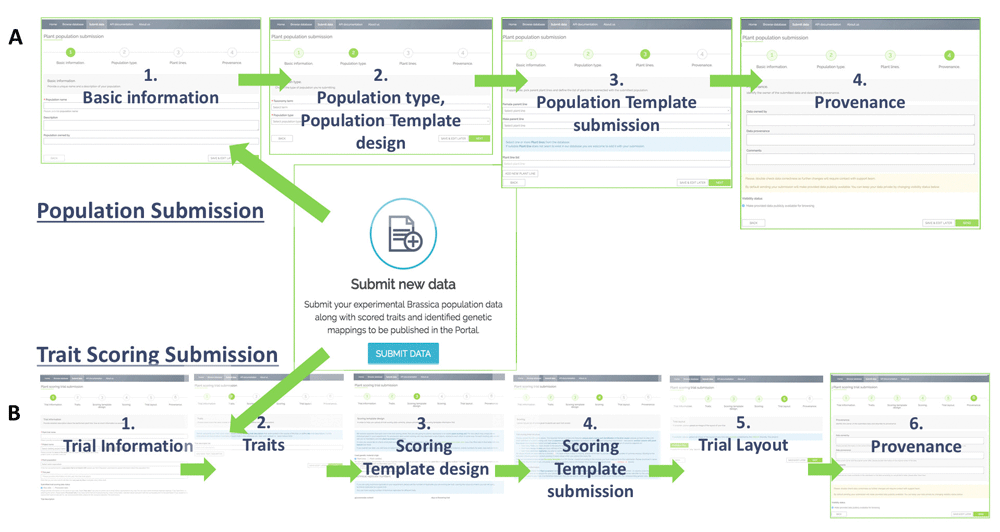
For the submission of trait measurements, the user designs a .csv template in step 3 (see Supplementary Figure 1A for an example template), and then submits the completed .csv file in step 4. Depending on the type of data submitted (raw vs. analysed data), the template can differ in the fields to be filled out. Compulsory metadata for Trial Submissions is listed in Supplementary Table 1. Finally, the user can upload an image presenting the experimental layout (for instance, the greenhouse plant pot setup on benches) in the case of raw data submission, and fill out provenance metadata in step 6. Whether data are submitted using the wizard or the API, the same metadata is compulsory.
Programmatic submission is executed using POST requests through the BIP API. The query exposes the part of the database data the user wants to submit data to. Content to be submitted needs to be assigned a corresponding field in the database and is presented as files in .json format. Programmatic extraction is also API based. GET requests placed to the database can be more comprehensive or specific than the interface-based strategy. These are then output in .json format, ready to feed into analytic workflows run in, for example, python. Full API documentation is available on the portal's website, including all table fields beyond those that are compulsory.
A Ruby submission client facilitates the automated submission of new experimental populations and trial data. It parses an input .csv file searching for the elements (input columns) to be submitted. These input columns need previously to have been mapped against the database fields by the registered user. For each line in the .csv, new entries are created in the database and this content is then submitted to the database using the BIP API. Using the Ruby client tool is not required - it is provided only as a convenient alternative to users who prefer scripting approach to data submission and analysis.
The registered user is entitled to upload data directly to the database, which may then become public within seconds of submission. However, to ensure confidentiality of data for an ongoing project, at user’s discretion, a submission embargo can keep data private for a defined period. Once public and older than the revocation period, datasets could be assigned (on user’s demand) with individual DOIs, which act as a reference in publications.
Data download can be performed via the web interface and the API. Using the interface, the user can download any visible table, by clicking the “Export to CSV” button on top of the tables. This downloads the complete table in .csv format (Figure 4b). Via the API, the user can use GET requests to interact with the database tables directly. This sometimes enables the user to retrieve more information than is displayed at the interface. The queries can be crafted according to the user’s needs for data. Example Ruby clients are available on Github for modification and retrieval of more complex data.
The Brassica Information Portal (BIP) has been designed as an open-access, open-source, phenotype data storage resource and will facilitate addition of other features in the future. The general motivation for the BIP was to develop technologies enabling efficient use of phenotyping data. The creation of the database and its standards lays the foundation for Brassica genotype-phenotype studies drawing phenotypic data from this repository.
Availability of a repository for integrative phenotype data should encourage the Brassica research community to store trait data in an open access repository, in a similar manner as for other data types, such as sequence, metabolomic and protein structure data, and share it with the research community. Ultimately, the Portal will facilitate understanding of Brassica diversity and trait variation for future research, breeding programmes and crop improvement.
With instant submission to the repository, it remains the primary responsibility of the submitter to guarantee the quality of the data. However, cross-linking with existing ontologies and spelling control holds errors in check prior to submission. Further, compulsory fields during submission ensure metadata minimal requirements are met for meaningful data interpretation in the future. Furthermore, each submission is granted a one week revocation period. During that time, the submitting author is asked to perform all important data quality checks, and in case any discrepancies or inconsistencies are found, the author is able to revoke the publication, repair the submitted dataset, and publish it again. After a week has elapsed since the submission, the data are made read-only, and it can no longer be altered or removed. Moreover, it can then be accessed and quoted by other users as long as the embargo is lifted. The author may request a DOI number assigned to the submission, so it is possible to cite it in publications.
Future plans include the support of submission of imaging data to CyVerse, allowing BIP to serve as a single entry-point for multiple data types relevant to crop improvement studies. At the same time, visualisation tools will be developed to call and display the CyVerse-hosted images from within the BIP interface. This will include 1) images of single plant parts underlying definitions of specific traits; 2) time lapse images of single plants; and 3) time lapse images of field trials generated by high-throughput techniques, e.g. drone flights. Statistical analysis of phenotypic data will be performed with incorporated of R/Shiny applications run directly on the BIP server. For example, association studies could be performed with uploaded genotyping data matching selected plant lines with corresponding trait measurements available in the BIP. More computationally costly operations will be supported through development and incorporation of analytical workflows executed externally, e.g. using CyVerse infrastructure. Additionally, linkage markers recorded in the database will be cross-linked with their corresponding sequences within EnsemblPlants22. This will make it possible to visualise the location of the markers in context with the genome sequence and genes in close proximity.
Finally, BIP API will be further refined by implementing additional content checks, e.g. by cross-linking to Global and European cultivar registers (Plant variety database - European Commission, Community Plant Variety Office, CPVO Organisation for Economic Co-operation and Development (OECD) Variety List Query) and to comply with ELIXIR standards (currently under development) to facilitate common data exchange and communication with other bioinformatics resources.
We have introduced the Brassica Information Portal, a web repository for Brassica phenotype data. This article describes the current state of development and future plans. We describe the back end database schema and the front end web-interface. Also, we describe programmatic and wizard-based submission of Population and Trial data together with fields compulsory for submission to the repository. It was originally intended that this repository meet the needs of the Brassica Research Community in the UK for relevant experimental data. However, it is apparent from discussions within the Multinational Brassica Genome Project that it can now fulfill a broader community infrastructure requirements. We therefore hope that BIP encourages data sharing and re-use by helping to integrate and harmonise datasets generated worldwide.
Brassica Information Portal can be accessed from: bip.earlham.ac.uk
Latest source code: https://github.com/TGAC/brassica
Archived source code as at time of publication: https://doi.org/10.5281/zenodo.46605023
License: GNU 3.0
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)