Keywords
PubRunner, PubMed, biomedical text mining, text mining, natural language processing, BioNLP
This article is included in the Container Virtualization in Bioinformatics collection.
This article is included in the Hackathons collection.
PubRunner, PubMed, biomedical text mining, text mining, natural language processing, BioNLP
The National Library of Medicine’s (NLM) PubMed database contains over 27 million citations and is growing exponentially (Lu, 2011). Increasingly, text mining tools are being developed to analyze the contents of PubMed and other publicly searchable literature databases. The goal of many of these tools is to enable a biologist to easily consume the latest relevant research and reduce the time searching for important results that would guide their research. These tools cover a wide variety of tasks, including improved searches across Pubmed (Tsai et al.), knowledge base construction (Xie et al.), and identification of concept association (Jelier et al.). Furthermore, there is significant interest in producing preprocessed sets of text with named entity annotation and part-of-speech tagging for use in further text mining analyses (for example, Hakala et al.).
With this huge rate of publication, it is commonly stated that text mining is becoming an essential research tool (Scherf et al.). However, molecular biologists rely on text mining experts to run these tools on the latest publications and openly share their results. Often the results of these text mining analyses and the code used are not shared, the analysis is not kept up-to-date with the latest publications, or the analysis is not publicized well to the biology community. These problems hinder the widespread use of text mining in scientific research.
The challenge of maintaining up-to-date results requires additional engineering, which often goes beyond a basic research project. Some research is beginning to look at methods to maintain updated analysis on PubMed (Hakala et al.), but a general framework is needed. In order to encourage biomedical text mining researchers to widely share their results and code, and keep analyses up-to-date, we present PubRunner. PubRunner is a small framework created during the National Center of Biotechnology Information Hackathon in January 2017. It wraps around a text mining tool and manages regular updates using the latest publications from PubMed. On a regular schedule, it downloads the latest Pubmed files, runs the selected tool(s), and outputs the results to an FTP directory. It also updates a public website with information about where the latest results can be located. We hope it will help the text mining community in producing robust and widely used text mining tools.
PubRunner manages monthly runs of text mining analyses using the latest publications from PubMed without requiring human intervention. The PubRunner framework has several key steps, outlined in Figure 1. First, it queries the PubMed FTP server to identify new XML files and downloads them. It currently downloads the Baseline dataset and then updates with the Daily Updates files (https://www.nlm.nih.gov/databases/download/pubmed_medline.html). It tracks which files are new and downloads the minimal required set to be up-to-date. Second, it executes the text mining tool(s) on the latest downloaded PubMed files. A JSON configuration file manages the set of tools to be run and determines whether they can be executed on only the new incremental files or require the full set of Pubmed XML files. These tools are then run as Python subprocesses and monitored for exit status. Furthermore, PubRunner uses a timeout parameter to kill processes that exceed a time limit. PubRunner runs on the same private server used for the text mining analysis, but moves results to a publicly visible FTP after the analysis is complete. It requires FTP login information to be able to copy files.
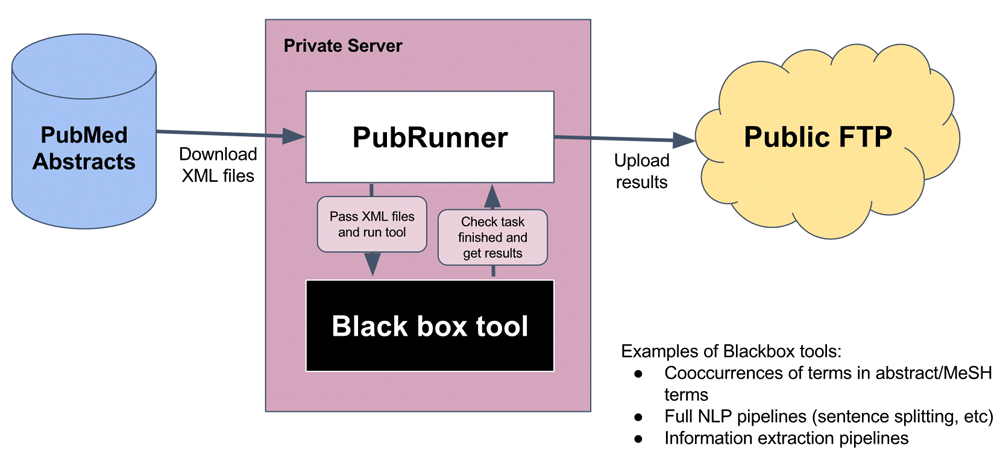
PubMed abstract files in XML format are downloaded to the PubRunner framework, processed by the text-mining tools, the output pushed to a public FTP site and an update sent to the central PubRunner website.
A central website was developed to track the status of different text mining analyses that are managed by PubRunner. These analyses may be executed on a variety of different researchers’ computers with results hosted on different FTPs. The website lists the tools with information about their latest run and where their code and results can be found. This allows text mining users to more easily find robust and up-to-date analyses on PubMed.
A key design goal of PubRunner is to make installation as straightforward as possible. This is to encourage widespread use of the framework and release of both tool code and results data. Accordingly, a Docker image containing PubRunner has been produced, and installation from the Github code is also very straightforward. Also, each PubRunner component (server, website, and FTP) can be built by using the Docker file available for each in the GitHub repository. Deploying a specific component is thus made easy. Notably, there is not one central PubRunner FTP server. The output of PubRunner can be transferred to a pre-existing FTP server (e.g. an institution’s FTP server) or a new FTP server can be set up using the Docker image. After PubRunner is installed, configuration involves setting the paths to the tools to be run and the login information for the FTP.
PubRunner currently has two dependencies: Python and R. The Docker file manages installation of these tools. The CPU and memory requirements required to run PubRunner depend on the associated text mining tools to be executed. PubRunner does require a reasonable amount of disk space, approximately 185GB, in order to download the full set of PubMed XMLs.
In order for a text mining tool developer to start using PubRunner, they first register their tool with the central website (http://www.pubrunner.org). Each tool should accept a set of Medline XML files as input and generate output files in a specific directory. The website gives them instructions on the necessary configuration settings so that their PubRunner instance can communicate with the central website. After each scheduled run of PubRunner on their remote server, an update message is sent to the website with a JSON packet of information. This information includes success status for the tools with URLs to the appropriate data. A potential extension to the website would hide tools that have failed for over three months and send notifications to the maintainers of each failed tool.
PubRunner was tested using three basic text mining tools that were developed specifically for testing the framework. These tools are also included in the Github repository. One of these tools, named CountWords, generated basic word counts for each abstract in a PubMed XML file. It takes as input a list of PubMed XML files, parses the XML for the AbstractText section, splits the text by whitespace and counts the resulting tokens to give a naïve word count. It then outputs the set of word counts along with the corresponding PubMed IDs to a tab-delimited file.
In order to test the robustness of the process management, two other tools that would fail were developed. The second tool, simply named Error, consistently failed. The third, named CountWordsError, uses the same code to calculate word counts as the first tool but would fail with a probability of 0.5. PubRunner successfully managed new runs of these test tools using updates from PubMed. At the time of publication, all three tools are deployed using PubRunner on a server hosted by the British Columbia Cancer Agency. PubRunner reruns the tools monthly and updates the results and status posted to the PubRunner website.
The PubRunner prototype reduces the additional engineering required for a text mining tool to be run on the latest publications. It will encourage the sharing of tool code and analysis data. At the moment, it can manage text mining runs using the latest Pubmed data. Future versions of the software will add additional corpora sources, such as PubMed Central, and allow easier integration of ontologies and other bioinformatics resources.
We hope to encourage more biomedical text mining developers to integrate their text mining tools into the PubRunner framework to develop an ecosystem of text mining tools running on the latest publications. This will certainly benefit biomedical researchers by allowing easier analysis of the latest publications so that new relevant knowledge is disseminated more easily.
PubRunner central website: http://www.pubrunner.org
Latest source code for the pipeline is publically available on GitHub: https://github.com/NCBI-Hackathons/PubRunner.
Archived source code as at time of publication: 10.5281/zenodo.556195 (Lever et al., 2017)
License: MIT
The Docker image is available at https://hub.docker.com/r/ncbihackathons/pubrunner/.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (1)