Keywords
meta-research, research funding, peer review, citations, research impact
This article is included in the Research on Research, Policy & Culture gateway.
meta-research, research funding, peer review, citations, research impact
Winning funding is an important stage of the research process and researchers spend large amounts of their time preparing applications1. Applications are typically assessed using relatively small panels of 3 to 12 peer reviewers, sometimes including external reviewers with additional expertise, which is similar to the journal process of editors and reviewers. Given the importance of funding processes to researchers’ careers and the progress of science, there is surprisingly little research on whether funding systems reliably identify the best research. A recent systematic review found there are many unanswered questions in funding peer review, and concluded, “there is a need for open, transparent experimentation and evaluation of different ways to fund research”2. A prior systematic review similarly concluded that studies to examine the accuracy and soundness of funding peer review are “urgently needed”3. Whilst a systematic review of innovations for effectiveness and efficiency in peer review funding found only eight studies and called for more studies4.
The majority of funding systems rank applications using the mean score from the review panel, and award funding from the highest to the lowest ranked applications, stopping when the budget is exhausted (exceptions are sometimes made for applications below the funding line because of national research priorities). An interesting recent idea is that an application’s mean score may not be the only statistic worth considering, and that the standard deviation in peer reviewers’ scores may also be a useful statistic for ranking applications5. A zero standard deviation means all panel members gave the same score. Larger standard deviations indicate more disagreement between panel members, and this disagreement may be useful for identifying high-risk research that may also have a higher return.
Using the mean score for ranking may allow panel members to “sink” an application by awarding a low score that pulls the mean below the funding line. Including a measure of reviewer disagreement in funding could ameliorate such “sinking” and allow applications that have strong support from a few reviewers to be supported. This may also increase the diversity in what kinds of applications are funded. Some peer review systems already recognise this issue by giving each panel member a wildcard which allows them to “float” an application above the funding line regardless of other panel members’ scores. At least one funding scheme also includes patient and stakeholder reviewers to increase the diversity of viewpoints6.
A recent systematic review found “suggestive” evidence that funding peer review can have an anti-innovation bias2 and that innovation and risk may not often be sufficiently addressed in review feedback7. There is evidence that riskier cross-disciplinary research has lower success rates8. Some researchers feel they need to write conservative applications that please all members of the panel to achieve a good average score9. However, supporting risky research can have huge benefits for society when it pays off10. In a survey of Australian researchers, 90% agreed with the statement: “I think the NHMRC [the main Australian funding body for health and medical research] should fund risky research that might fail but, if successful, would change the scientific field”11.
Previous studies have investigated the association between an application’s mean score (or ranking based on the mean) and subsequent citations, where citations are used as a measure of success. Many studies using large sample sizes found either no association or only a weak association between the mean score and the citations of subsequent publications12–16. Other studies have shown a positive association between higher mean peer review scores and increased citations17,18, including a study that used the same data analyzed here19. To our knowledge, no previous study has empirically estimated how the disagreement in peer reviewers’ scores may also predict citations.
We examined 227 successful grant applications submitted to the American Institute of Biological Sciences between the years 1999 to 2006. These successful applications came from 2,063 total applications (overall 11% success rate). The applications covered a wide range of biomedical research areas, including vision, drug abuse, nutrition, blood-related cancer, kidney disease, autoimmune diseases, malaria, tuberculosis, osteoporosis, arthritis and autism. Applications were assessed by between 2 and 18 peer reviewers, with a median of 10 reviewers. Panels evaluated an average of 25 applications over two days. Ninety percent of applications were reviewed by on-site panels with an average size of 10 reviewers, and 10% of applications were reviewed via teleconferences of 3 reviewers. Further details on the funding process is available in a previous study of how the applications’ mean scores predicted citations19.
Our key predictor is the peer reviewers’ scores. Individual peer reviewers, who were not conflicted, scored applications between 1.0 (best) to 5.0 (worst) in 0.1 increments. To determine funding, the score was averaged across all reviewers. In this study we also consider statistics that measure within-panel disagreement, which are the standard deviation and the range (largest minus smallest score).
The primary outcome is the citation counts from publications associated with the successful application. The publication data for the funded applications were taken from the mandatory final reports submitted by the applicants. On average, these reports were submitted 5 years after the application’s peer review. Publications were produced from 1 to 8 (average 4.3) years after the review date. Only peer-reviewed publications were counted, confirmed through PubMed and Web of Knowledge searches. Publications listed in the final report as “submitted” or “in preparation”, were included if they could be found as peer-reviewed published papers. Citations were counted in 2014 using Web of Knowledge.
This analysis used 20,313 citations from 805 peer reviewed publications. The total citation level per funded application was the cumulative citations of all publications. As citations are time-dependent they were standardized using the average citation level of all publications by scientific field and year, using data from a published calculation using the Thomson Reuters Essential Science Indicators database20. These published average rates were determined for 2000–2010 by scientific field, assessed in 2011 and displayed a linear relationship with time (e.g., R2 = 0.99 for the field of molecular biology). We chose molecular biology because it was the highest cited field and in general was the field most applicable to the funded applications.
Because the Reuters curve was assessed in 2011, we extended the curve for 2014, back calculating using a linear fit which had a very high R2 of 0.99. In this way, we could most accurately standardize the data for the relationship between publication date and citation level and could calculate the Total Relative Citation per application. A total relative citation of 1 meant the application achieved the average number of citations, whereas values above 1 meant a higher than average number of citations.
We note that a recent study that used both unadjusted citation counts and relative citations, found the two measures gave similar results when used as the key outcome variable21.
The total relative citations were modelled using a multiple regression model. We ran two models with the three application variables:
Our aim was to examine two measures of panel disagreement: the standard deviation and range. We included mean score because it has already been shown to be an important predictor for these data19 and we were interested in the additional value of a measure of disagreement. We adjusted for review year (1999 to 2006) because there was a difference in the application score statistics over time, and because year was associated with citation numbers, hence it was a potential confounder.
The citations were first base e log-transformed because of their positive skew. We added a small positive constant of 0.1 before using the log-transform because some citations were zero. The estimates were back-transformed and plotted to show the results on the original relative citations scale. Using equations the multiple regression model was:
where Y are the citations and γ are random intercepts to adjust for the potential within-panel correlation in citations (where p(i) is the panel number for application i and M is the total number of panels). The mean (µ) had a constant (β0) and the three application predictors (X) which were first transformed using a fractional polynomial function.
Associations between the score statistics and citation outcomes could be non-linear, for example a larger difference in citations for a change in mean score from 1.0 to 1.1 compared with a change from 2.0 to 2.1. To model this potential non-linearity we used fractional polynomials to examine a range of non-linear associations between the scores and citations22. The fractional polynomial function is:
We examined the eight transformations of: P = {−2, −1, −0.5, 0, 0.5, 1, 2, 3} and chose the optimal P using the deviance. The optimal P was chosen for each of the three predictors, meaning we examined 83 = 512 models in total. We only present results for the best model with the smallest deviance. We checked the distribution of the model residuals for multi-modality and outliers, and used Cook’s distance to find influential observations.
Sixteen (7%) observations were missing the score standard deviation and 32 (14%) observations were missing the score range because the individual peer reviewer scores were no longer available for some applications at the time of this retrospective analysis. These missing observations were imputed using linear regression with the application variables: review year, mean score, score standard deviation, minimum score, maximum score and range. We used five multiple imputations.
All analyses were made using R version 3.4.423 with the imputations using the “MICE” package24. The code and anonymized data are available here: http://doi.org/10.5281/zenodo.129938425.
We report our results using the STROBE guidelines for observational research26.
The histograms in Figure 1 show the distributions of total relative citations and the application score statistics: mean, standard deviation, minimum, maximum and range (maximum minus minimum). There was a strong positive skew in citations with one outlying relative citation of 104; the next largest citation was 34. To counter this positive skew we used a base e log transform in later analyses. There was also a positive skew in the score standard deviation and range, and we also log-transform these predictors.
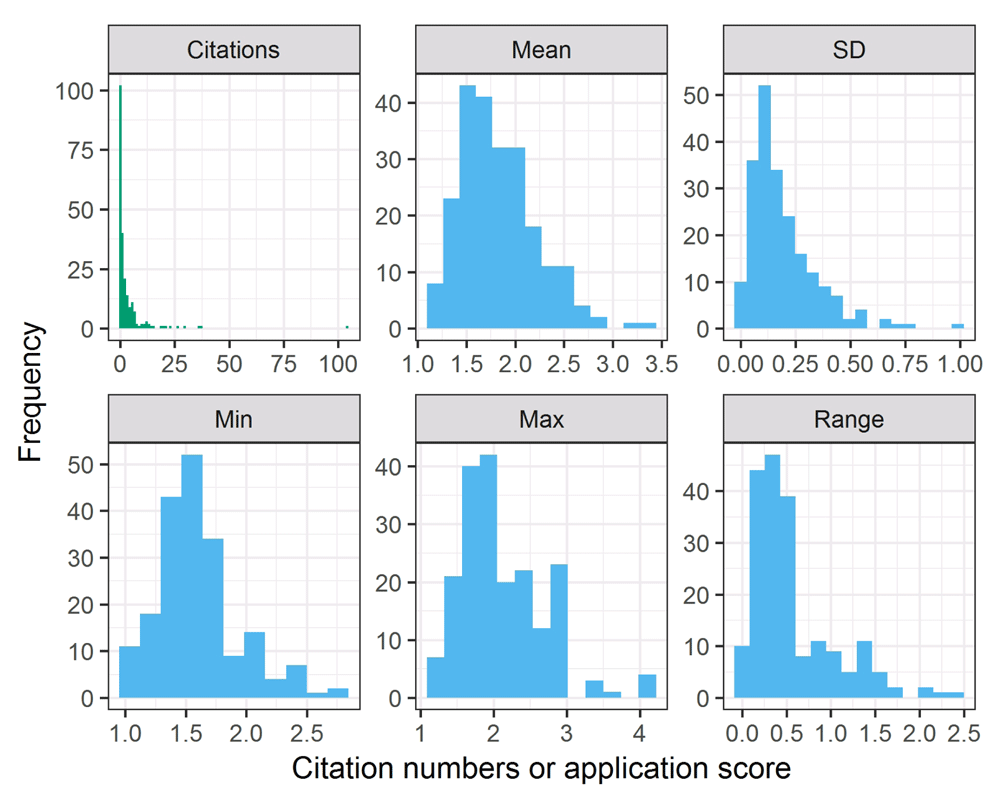
The lower the mean score, the better the application did in peer review.
The scatter-plots in Figure 2 show the associations between the application score statistics. There was a strong correlation between the standard deviation and maximum (0.80), but not between the standard deviation and minimum (0.05). This indicates the largest disagreement is where at least one panel member has given a poor score (remembering lower scores are better). Applications where there was one dissenting panel member with a good score were unlikely to be funded as their mean score would not be competitive, and hence are not in this sample. There was a strong positive correlation between the two measures of panel disagreement, the standard deviation and range (0.93).
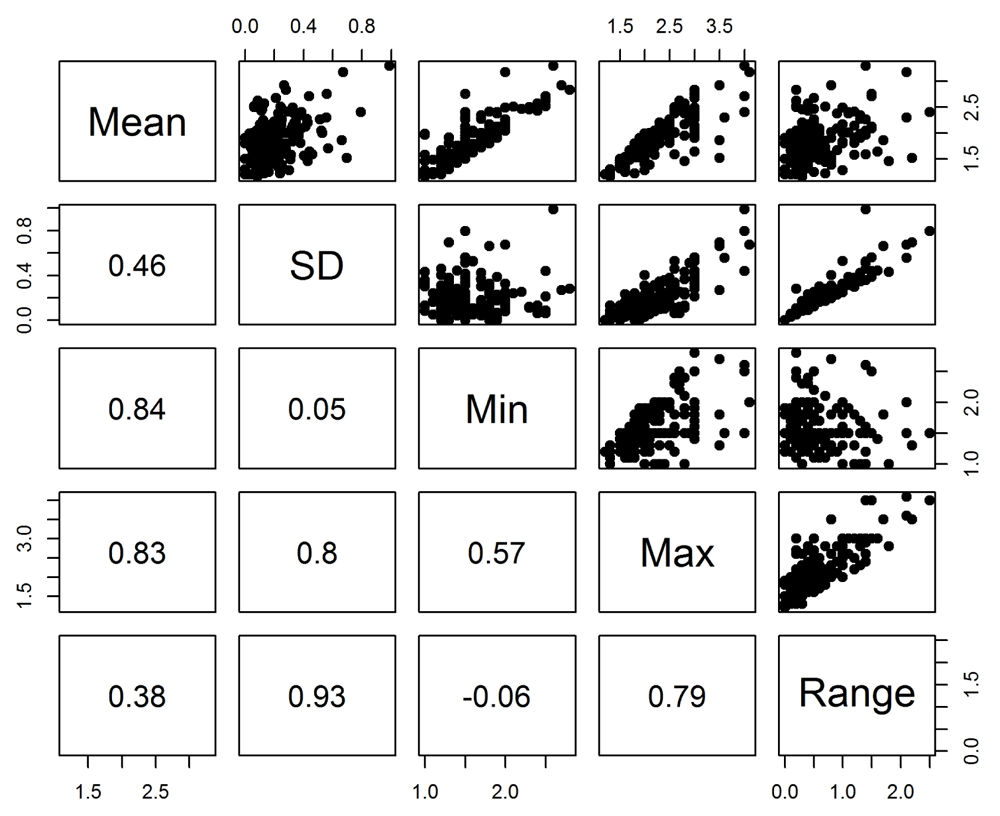
The numbers in the bottom-left diagonal of the plot matrix are the Pearson correlations.
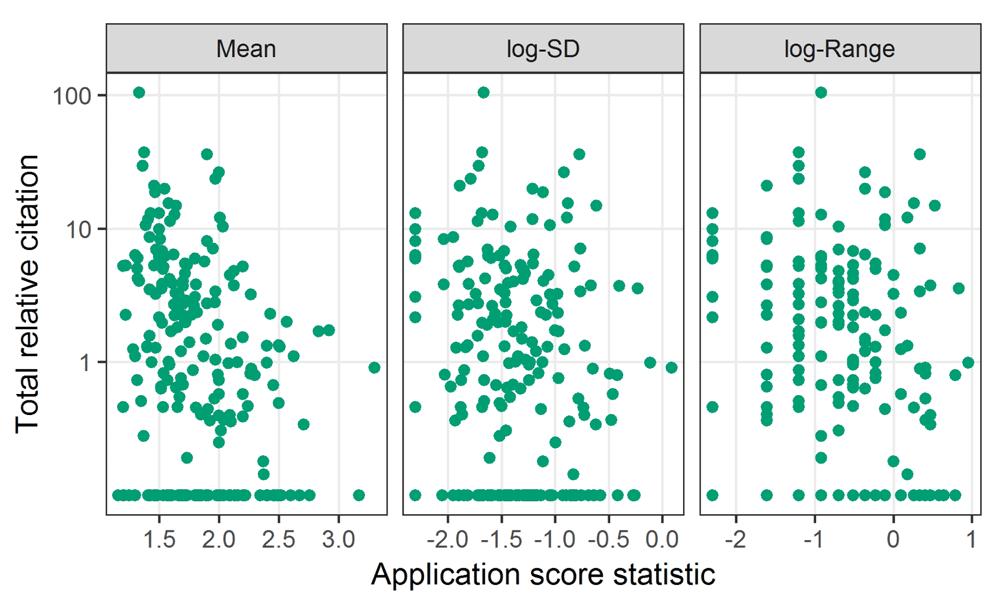
The scatter-plots in Figure 3 show the association between total relative citations and the score statistics. We used the log-transformed citations and the standard deviation and range to remove the skew and so show a clearer association. The variance in log-citations appears relatively stable over the score statistics, somewhat confirming the validity of log-transforming the citations27. The points along the bottom of the y-axis are the 74 applications (33%) with no citations. Some association between mean score and citations is visible, with a generally downward pattern in citations for increasing score. There is no clear association between citations and either the standard deviation or range.
The results from the multiple linear regression models are in Table 1. Only the application’s mean score had a statistically significant association with citation numbers.
FP = fractional polynomial.
The predictions from the multiple linear regression models are in Figure 4. There was a reduction in citations for applications with a higher (worse) mean score. The mean lines are flat for both the standard deviation and range, indicating no association between these score statistics and citation numbers. The 95% confidence intervals for the standard deviation are very wide for large standard deviations. The application with the largest standard deviation was influential according to Cook’s statistic, and removing this application had little impact on the mean line but did reduce these wide intervals (see additional results at https://github.com/agbarnett/funding.disagree). The model residuals had an approximately symmetric and unimodal distribution with no outliers.
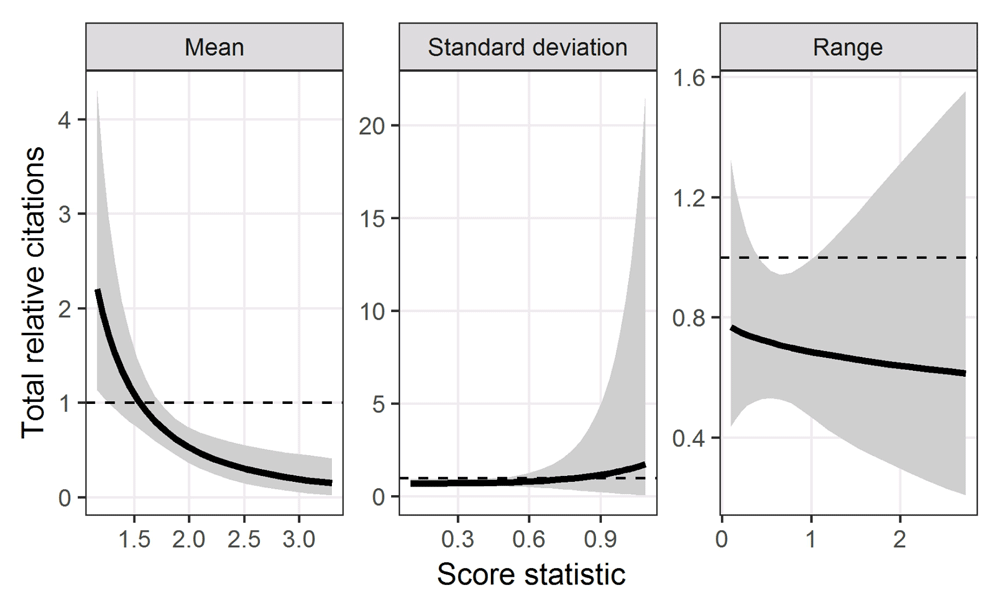
The solid lines are the means and the grey areas are 95% confidence intervals. The dotted horizontal line at 1 represents the average citations, so values above this are better than average.
We found a statistically significant association between an application’s mean score and subsequent citation counts, with the result in the expected direction because applications with better scores had more citations (on average). The largest size of the increase is also practically significant as the highest scores have a mean of 2 (Figure 4), meaning double the average citations.
We found no association between the two measures of reviewer disagreement and citations counts. It appears that any disagreement between peer reviewers did not indicate an application with a potentially high return.
Disagreements between reviewers about an application can stem from different sources. Disagreements about the proposed methods may mean the study is not viable and would struggle to produce valid results and/or publish papers. Disagreements about the application’s goals may reflect a difference of opinion about the potential impact, and it is these disagreements that are likely more subjective and hence where a higher return is possible if one reviewer is right. Disagreements between reviewers can also occur for more trivial reasons such as the dynamics of the panel and personal disagreements28. A more sophisticated measure of panel disagreement to those used here may be more predictive of the benefits of the research, but such measures would need to be well-defined and prospectively recorded at the panel meeting. Some reviews already breakdown scores into separate areas, such as track record and innovation, and reviewer disagreement could be examined using these separate scores. Each reviewer brings their own experience and biases to the funding process and such intellectual differences influence application scores29,30. Indeed, some recent research has recently indicated that there is more variability in score across reviewers than across proposals31 and previous results indicate inter-rater reliability as very low32. An application’s average score is somewhat due to the “luck of the draw” of what reviewers were selected33. Variations can also occur because of the way the application is summarised at the panel meeting28,34. If a larger disagreement leads to high-risk returns then we might expect an increase in the variance in citations for larger score standard deviations and ranges. This is because there might be more “failures” with zero citations, but also more big returns. Our multiple regression models only examined a change in mean citations and a different statistical model would be needed to examine a change in variance. However, the scatter-plots in Figure 3 show no sign of an increasing variance in citations for higher standard deviations or ranges.
Some have argued that studies like ours are invalid because: 1) they only consider funded applications and do not include unfunded studies, 2) an application’s score is not the only criteria used to award funding (e.g., applications with low scores awarded funding because of national priorities), and 3) because budgets are frequently cut, meaning the actual research may differ from the application35. Studies that follow funded and unfunded fellowship applicants are possible, e.g., 36, but this is very difficult when examining projects that need specific funding37. We believe, despite the limitations of bibliometric measures, it is reasonable to expect a dose-response association between scores and citations within funded applications. Samples that include applications that were funded for reasons other than their mean score, such as national priorities, increase the variance in the key predictors of application scores statistics and hence increase statistical power. Cuts to the budget are important and can hinder the planned research. However, assuming the reviewers believed the study was still viable with the reduced budget, such studies still test the ability of a panel to predict what research will have the greatest return.
Citations are an imperfect measure of the impact of research because many citations have little worth and scientists often report that their most highly cited work is not their best38. Studies that examine more detailed outcomes such as translation into practice or cost-benefits would be incredibly useful, however these studies would themselves require funding as it would involve further data collection, analyses and interviews of the applicants. Our results may not be generalisable to other funding schemes, especially as there are large differences between fields in their perceptions of what makes a good application28. It would be useful to examine whether reviewer disagreement is associated with research impact in other funding schemes and in larger sample sizes.
We found no association between two measures of reviewer disagreement when assessing an application and the subsequent research impact of that application as measured by citation counts.
The code and anonymized data are available here: http://doi.org/10.5281/zenodo.129938425.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)