Graves N, Barnett AG, Burn E and Cook D. Smaller clinical trials for decision making; a case study to show p-values are costly [version 2; peer review: 1 approved, 2 approved with reservations]. F1000Research 2018, 7:1176 (https://doi.org/10.12688/f1000research.15522.2)
NOTE: If applicable, it is important to ensure the information in square brackets after the title is included in all citations of this article.
1Institute of Health and Biomedical Innovation, Queensland University of Technology, Brisbane, QLD, 4059, Australia 2Nuffield Department of Orthopaedics, Oxford University, Oxford, OX3 7LD, UK 3Princess Alexandra Hospital, Brisbane, Brisbane, QLD, 4102, Australia
Background: Clinical trials might be larger than needed because arbitrary levels of statistical confidence are sought in the results. Traditional sample size calculations ignore the marginal value of the information collected for decision making. The statistical hypothesis testing objective is misaligned with the goal of generating information necessary for decision-making. The aim of the present study was to show that for a case study clinical trial designed to test a prior hypothesis against an arbitrary threshold of confidence more participants were recruited than needed to make a good decision about adoption.
Methods: We used data from a recent RCT powered for traditional rules of statistical significance. The data were also used for an economic analysis to show the intervention led to cost-savings and improved health outcomes. Adoption represented a sensible investment for decision-makers. We examined the effect of reducing the trial’s sample size on the results of the statistical hypothesis-testing analysis and the conclusions that would be drawn by decision-makers reading the economic analysis.
Results: As the sample size reduced it became more likely that the null hypothesis of no difference in the primary outcome between groups would fail to be rejected. For decision-makers reading the economic analysis, reducing the sample size had little effect on the conclusion about whether to adopt the intervention. There was always high probability the intervention reduced costs and improved health.
Conclusions: Decision makers managing health services are largely invariant to the sample size of the primary trial and the arbitrary p-value of 0.05. If the goal is to make a good decision about whether the intervention should be adopted widely, then that could have been achieved with a much smaller trial. It is plausible that hundreds of millions of research dollars are wasted each year recruiting more participants than required for RCTs.
Keywords
decision making, RCT, sample size, waste in research
This is an update in response to the review from Stephen Senn. The title has been changed, there is a new Figure 3, we have added a new "Counter-exmple of no treatment" sub-heading in the Methods section, and have expanded the Discussions section.
This is an update in response to the review from Stephen Senn. The title has been changed, there is a new Figure 3, we have added a new "Counter-exmple of no treatment" sub-heading in the Methods section, and have expanded the Discussions section.
Informed patients, thoughtful clinicians and rational health planners make decisions about the services and treatments provided using the best information available, and all decisions are made under conditions of uncertainty1,2. We examine a situation where sufficient evidence arises from a clinical trial to inform a decision about changing services before the conventional statistical stopping point for a clinical trial is reached. This paper is about the tension between the ‘precision’ and the ‘impact’ of a scientific measurement3 and how that tension might dictate the sample size of a clinical trial.
Imagine a new treatment is compared against the best contemporary alternative in a well conducted randomised controlled trial (RCT). The design requires 800 participants in total based on a standard sample size calculation of 5% type 1 error and 80% power. The new treatment is more efficacious, prolongs life of high quality and saves more money than it costs to implement. The evidence to support these conclusions can be seen in the data after only 200 trial participants have been recruited, but primary outcomes are not yet statistically significant. Clinical equipoise, the cornerstone of ethical treatment allocation is lost, yet the conventions of hypothesis testing and arbitrary power calculation demand a further 600 participants are recruited. The information arising from the additional 600 participants is unlikely to change the actions of a rational decision maker who wishes to adopt the new treatment. Yet scarce research funds are used up meaning opportunities to fund other research are lost, and some patients have been consented and allocated to a treatment that we could not recommend, nor would we chose for ourselves or our families.
The utility of clinical trials for those managing health services and making clinical decisions is under debate and traditional paradigms are being challenged4. The chief claim of this paper is that an RCT designed to test a hypothesis using traditional rules of inference might have more participants than required, if the goal is to make a good decision. Waste in research arises from routine use of arbitrary levels of statistical confidence5 and because the trial data are considered in isolation6. The marginal value of the information acquired for the purpose of making a good decision is not made explicit. Important information for the purpose of decision making often lies outside the clinical trial process. The plausibility of our claim is demonstrated by re-analysing a recent RCT7.
Choosing a sample size for hypothesis testing
For the design of superiority trial, the aim is to have a high likelihood of sufficient evidence to confidently reject a null hypothesis that two treatments are equivalent when treatments differ by a specified difference. This difference is usually based on either clinical importance or a best guess of the true treatment effect. Inference based on this approach has two types of potential errors. A false-positive or type I error of rejecting the null hypothesis when there is no difference, with probability α. A false negative or type II error of not rejecting the null hypothesis when there is an effect, with probability β. The sample size of the trial is calculated to give an acceptable type I error rate and power (1–β), typically 0.05 for α and 0.8 to 0.9 for the power. The final analysis summarises the incompatibility between the data and the null hypothesis8. If the p-value is below the standard 5% limit the null hypothesis of no effect is rejected. A ‘statistically significant’ result is then celebrated and typically used to support a decision to make a change to health services.
Choosing a sample size for decision making
We assume the objective of decision-makers who manages health services is to improve outcomes for the populations they serve. Because this challenge will be addressed with finite resources not every service or new technology can be made available for a population. Decision-makers therefore require knowledge of the health foregone from not funding services displaced by the services that are funded9. The services that are provided should generate more health benefits per dollar of cost when compared to those that are not. With this criterion satisfied the opportunity cost from the services not provided is minimised. A rational decision maker will logically follow these rules: do not adopt programmes that worsen health outcomes and increase cost; adopt programmes that improve health outcomes and decrease costs; and, when they face a situation of increased cost for increased health outcomes they prioritise programmes that provide additional health benefits for the lowest extra cost10. They will continue choosing cost-effective services until available health budgets are exhausted. An appropriate and generic measure of health benefit is the quality adjusted life year (QALY)11. While this approach does not consider how health benefits are distributed among the population there is a framework for including health inequalities in the economic assessment of health care programmes12.
In choosing a sample size for a clinical trial to evaluate a new service or technology a decision-maker will consider the uncertainty in the conclusion about how costs and health benefits change by adoption. The aim is to reduce the likelihood of making the wrong decision. They will make rational and good decisions, and they will manage uncertainty rather than demand an arbitrarily high probability of rejecting a null hypothesis. Methods are available to estimate the expected value of information and so the optimal sample size for a trial is dependent on the context specific costs and benefits of acquiring extra information13. Each decision is context dependent and the ‘one size fits all’ approach to sample size calculation is arbitrary and potentially wasteful. This holistic approach should be a priority for designing, monitoring and analysing clinical trials.
Methods
The TEXT ME RCT: A case study
A case study to illustrate the differing evidential requirements of the ‘hypothesis-testing’ and ‘decision-making’ approaches is provided by the RCT of the Tobacco, Exercise and Diet Messages (TEXT ME) intervention14. This health services program targeted multiple influential risk factors in patients with coronary heart disease, with SMS text messages. Advice and motivation was provided to improve health behaviours and it was supplementary to usual care. The hypothesis was that the intervention would lower plasma low-density lipoprotein cholesterol by 4.5 mg/dL at 6 months for participants compared with those receiving usual care15. The required sample size was 704 participants for 90% power15 and the trial recruited and randomised 710 participants7. The mean difference between the intervention and control group was –5 mg/dL, (95% CI –9 to 0 mg/dL). With a p-value of 0.04, the null hypothesis was rejected. Evidence for health effects were also sought on other biomedical and behavioural risk factors, quality of life, primary care use and re-hospitalisations. Clinically and statistically significant effects were also found for systolic blood pressure (mean difference –8 mmHg, p<0.001), body mass index (–1.3 kg/m2, p<0.001) and current smoking (relative risk of 0.61, p<0.001).
The TEXT ME trial data were used to inform an economic evaluation of the potential change to costs and health benefits measured in quality adjusted life years to the community from a decision to adopt the programme16. The observed differences in low-density lipoprotein cholesterol, systolic blood pressure and smoking were combined with reliable external epidemiological evidence to estimate the reduction in acute coronary events, myocardial infarction and stroke and were extrapolated over the patients expected remaining life times. The costs of providing the intervention, the projected costs of the treatment of acute events and general primary care use and expected mortality were all informed by data sources external to the primary trial16. The findings revealed that TEXT ME was certainly going to lead to better health outcomes and cost savings. The conclusion was that a rational decision-maker should fund and implement the TEXT ME program. Once available an informed clinician would then recommend TEXT ME to coronary patients, and enough patients would sign up to create benefits for individuals and the health system. Using the TEXT ME study, we consider whether the same decision could have been made at an earlier stage with fewer participants enrolled in the primary trial.
Data analysis
We examine the effect of a reduced sample size on the results of both the hypothesis-testing analysis for differences in low-density lipoprotein cholesterol, and the economic evaluation of the intervention. From the original 710 participants, smaller samples between 100 and 700 patients in increments of 100 were considered with the resampling done with replacement. The ‘p-value’ and ‘economic’ analyses were re-run using the data provided by the randomly selected patients and this process was repeated 500 times for each sample size. The simulations and figures were created using R (version 3.1.0). The code is available on GitHub https://github.com/agbarnett/smaller.trials but we are unable to share the primary data from the TEXT ME RCT.
Counter-example of no treatment effect
To illustrate this approach with treatments that are equally effective, we used the same methods as above, but created data using the TEXT ME trial where the two groups had equivalent outcomes. We did this by randomly allocating patients to the TEXT ME intervention or usual care, and then resampling with replacement to create a new version of the study sample. We assumed there was no risk reduction for the TEXT ME group, and used the same uncertainty in risk reduction as per the previous model.
Results
The effect of reducing the sample size for hypothesis-testing objectives was to simulate studies that traditional hypothesis testing approaches would deem underpowered, see Figure 1.
Figure 1. P-values increase as sample sizes decrease for the observed differences in low-density lipoprotein cholesterol (based on 500 simulations per sample size).
The dotted horizontal line is the standard 5% threshold. The boxes are the 25th and 75th percentiles with the median as the central line. The upper whisker extends from the third quartile to the largest value no further than 1.5 * IQR from the quartile (where IQR is the inter-quartile range). The lower whisker extends from the 1st quartile to the smallest value at most 1.5 * IQR of the quartile. Data beyond the end of the whiskers are called ‘outlying’ points and are plotted individually.
Only for a sample size of 500 participants or more would the majority of trials find a statistically significant difference in average low-density lipoprotein cholesterol between groups (Figure 1). Even at a sample size of 700 around 30% of trials would be expected to make the ‘wrong’ inference of not rejecting the null hypothesis. This is consistent with a priori analytic estimates of sample size to address the hypothesis.
To inform decision making using cost-effectiveness as the criterion, reducing the sample size has little effect on the conclusion of whether to fund, recommend and participate in TEXT ME, see Figure 2. For every simulation for each sample size the decision to adopt TEXT ME led to cost savings shown on the y-axis and gains to health, measured by QALYs shown on the x-axis.
Figure 2. The conclusion for decision-making becomes more uncertain but does not change with decreasing sample size.
The x-axis shows the QALY gains for TEXT ME over usual care, and the y-axis shows the cost savings.
A sample size of 100 or more in the primary trial would convince a risk neutral and rational decision maker that TEXT ME is both cost-saving and health improving, and so should be adopted. The imprecision surrounding this inference increases as the sample size reduces, but the decision-making inference does not change. If the goal is to make a good decision about whether TEXT ME should be adopted widely, then that could have been achieved with a much smaller trial, one that enrolled as few as 100 patients. This would have been a cheaper and quicker research project releasing scarce research dollars for other important projects.
When we simulated studies where there was no treatment effect, all the costs of implementing the TEXT ME program of around 1.5 million dollars for the cohort of 50,000 patients were incurred, but none of the health benefits and associated cost savings were realised. The estimates of change to health benefits straddled the zero line with a spread covering a relatively small change in QALYs of around 20 lost to 12 gained. The inference for decision makers is clear at any sample size that adoption would be a poor decision (Figure 3).
Figure 3. The conclusion for decision-making is clear when there is no treatment effect, costs are increased for no change to health benefits for all sample sizes.
sample.size
QALY
Costs
ICER
Costs.stan
100
925.1334193
-9087916.9
-9823.358134
-9.0879169
200
966.8440768
-9675511.284
-10007.31298
-9.675511284
300
889.0585106
-9370276.023
-10539.54932
-9.370276023
400
970.1534934
-10165102.84
-10477.82945
-10.16510284
600
854.0719449
-8710700.269
-10199.02401
-8.710700269
700
761.0969295
-9694477.498
-12737.50704
-9.694477498
100
872.4665985
-10279510.44
-11782.12491
-10.27951044
200
922.2324104
-10131397.79
-10985.73166
-10.13139779
300
967.0931307
-10021783.67
-10362.79067
-10.02178367
400
916.4017729
-9131872.284
-9964.922105
-9.131872284
500
756.8751992
-7250724.548
-9579.815213
-7.250724548
600
791.5881207
-8503292.076
-10742.0663
-8.503292076
700
786.4679751
-7397152.203
-9405.535174
-7.397152203
100
748.8025595
-7532876.891
-10059.89736
-7.532876891
200
984.2007786
-10328209.78
-10494.00692
-10.32820978
300
831.040369
-9298046.064
-11188.44091
-9.298046064
400
882.3964032
-9713217.308
-11007.77074
-9.713217308
500
748.467448
-7378084.331
-9857.588799
-7.378084331
600
739.642639
-8155771.893
-11026.63836
-8.155771893
700
1083.137948
-11782766.85
-10878.36214
-11.78276685
100
949.9992549
-9964171.897
-10488.61022
-9.964171897
200
924.5380797
-10141714.86
-10969.49393
-10.14171486
300
999.6524794
-11314729.91
-11318.66338
-11.31472991
400
900.0614571
-9441532.319
-10489.87516
-9.441532319
500
827.5864981
-9306067.019
-11244.82703
-9.306067019
600
931.0998829
-9433975.411
-10132.07668
-9.433975411
700
986.7194613
-10610450.09
-10753.25917
-10.61045009
100
873.9859278
-10823332.12
-12383.87458
-10.82333212
200
539.5631032
-4916515.203
-9112.030036
-4.916515203
300
871.4054566
-9199573.034
-10557.16712
-9.199573034
400
756.2871958
-8011140.224
-10592.72227
-8.011140224
500
807.1758771
-8275036.497
-10251.83821
-8.275036497
600
837.8533494
-9001372.624
-10743.37488
-9.001372624
700
967.3569897
-10667118.85
-11027.0758
-10.66711885
100
311.4749076
-6402872.614
-20556.62417
-6.402872614
200
953.363766
-10011249.58
-10500.97553
-10.01124958
300
960.3002607
-11434663.05
-11907.38305
-11.43466305
400
945.5635258
-9717397.417
-10276.83191
-9.717397417
500
994.4749784
-9923415.227
-9978.546915
-9.923415227
600
1007.368712
-10088736.86
-10014.93966
-10.08873686
700
949.8272133
-9541741.969
-10045.76605
-9.541741969
100
805.1868566
-9988251.316
-12404.88619
-9.988251316
200
798.1897027
-7751425.402
-9711.25708
-7.751425402
300
766.9873002
-7533654.539
-9822.39802
-7.533654539
400
1084.610335
-12867104.01
-11863.34262
-12.86710401
500
604.8163102
-5880475.389
-9722.746045
-5.880475389
600
919.5817103
-10500546.51
-11418.82923
-10.50054651
700
743.9957175
-7462309.462
-10030.04357
-7.462309462
100
832.6646875
-8357880.235
-10037.51013
-8.357880235
200
761.3060941
-8610706.98
-11310.44011
-8.61070698
300
905.035291
-8439107.526
-9324.617073
-8.439107526
400
879.8643077
-9206901.404
-10464.00146
-9.206901404
500
768.224576
-9246355.24
-12036.00552
-9.24635524
600
753.6737489
-8999320.521
-11940.60498
-8.999320521
700
816.4134375
-8578378.43
-10507.39495
-8.57837843
100
673.1977558
-7399574.561
-10991.68037
-7.399574561
200
820.7177009
-8176648.83
-9962.80307
-8.17664883
300
895.3591217
-10049808.18
-11224.33215
-10.04980818
400
802.8059143
-8162017.433
-10166.86261
-8.162017433
500
783.3021306
-8603350.029
-10983.43754
-8.603350029
600
949.5882921
-9786376.877
-10305.91569
-9.786376877
700
782.31523
-8554009.103
-10934.2229
-8.554009103
100
983.8428507
-11155347.84
-11338.54642
-11.15534784
200
774.6808903
-6913445.509
-8924.24945
-6.913445509
300
868.0947695
-9019059.717
-10389.48745
-9.019059717
400
1003.032832
-10896083.32
-10863.13725
-10.89608332
500
842.7815391
-7916199.758
-9392.943949
-7.916199758
600
953.2038188
-9321800.698
-9779.4412
-9.321800698
700
839.611061
-8890799.199
-10589.18779
-8.890799199
100
702.652593
-8520157.674
-12125.70445
-8.520157674
200
805.5936394
-9271872.012
-11509.36596
-9.271872012
300
589.3630088
-5539426.71
-9399.00643
-5.53942671
400
819.9186189
-8054871.535
-9823.989052
-8.054871535
500
878.3388359
-9597036.733
-10926.34908
-9.597036733
600
975.189126
-11394638.24
-11684.54194
-11.39463824
700
767.1403313
-8623988.119
-11241.73475
-8.623988119
100
749.7801788
-6294316.392
-8394.882354
-6.294316392
200
1004.927224
-10194553.03
-10144.56847
-10.19455303
300
853.2114054
-9624247.493
-11280.02677
-9.624247493
400
737.6420908
-7068190.858
-9582.141457
-7.068190858
500
882.4409288
-8653749.126
-9806.604436
-8.653749126
600
842.5695047
-9447954.456
-11213.26419
-9.447954456
700
829.3559321
-8353272.822
-10071.99985
-8.353272822
100
1132.253966
-11794148.91
-10416.52249
-11.79414891
200
957.3003611
-10936078.94
-11423.87425
-10.93607894
300
625.0443645
-6098737.676
-9757.287678
-6.098737676
400
795.3520889
-8529075.203
-10723.6472
-8.529075203
500
868.7851811
-9264360.216
-10663.57992
-9.264360216
600
947.3412574
-10787081.68
-11386.69048
-10.78708168
700
950.9957101
-10108223.34
-10629.09458
-10.10822334
100
972.1366054
-9778081.313
-10058.34083
-9.778081313
200
728.4349123
-7903806.619
-10850.39512
-7.903806619
300
854.7972006
-9133140.919
-10684.57046
-9.133140919
400
746.8024657
-8286410.046
-11095.85255
-8.286410046
500
1020.029401
-11324896.26
-11102.51945
-11.32489626
600
957.1315704
-9653896.822
-10086.2798
-9.653896822
700
894.0956439
-9894724.591
-11066.74063
-9.894724591
100
615.9135253
-5592099.58
-9079.358303
-5.59209958
200
866.9159296
-9167523.905
-10574.87075
-9.167523905
300
910.2896822
-10319896.68
-11336.93689
-10.31989668
400
623.723261
-6682474.919
-10713.84593
-6.682474919
500
899.766854
-8849845.51
-9835.709629
-8.84984551
600
825.2871521
-8420907.549
-10203.60916
-8.420907549
700
885.1441307
-9247274.786
-10447.19664
-9.247274786
100
684.3133194
-6807073.534
-9947.305338
-6.807073534
200
1238.482157
-13761538.44
-11111.61624
-13.76153844
300
1105.158401
-12474160.9
-11287.21537
-12.4741609
400
791.0911701
-8633809.699
-10913.79859
-8.633809699
500
915.4004154
-10336362.86
-11291.63007
-10.33636286
600
990.6082701
-10181342.89
-10277.86987
-10.18134289
700
840.8546806
-8357515.553
-9939.310258
-8.357515553
100
1088.715121
-13015928.44
-11955.31154
-13.01592844
200
864.1309813
-9062333.467
-10487.22203
-9.062333467
300
787.0285257
-7775469.722
-9879.527194
-7.775469722
400
727.6762612
-7719352.85
-10608.2241
-7.71935285
500
783.2958675
-9004986.679
-11496.27753
-9.004986679
600
842.1036306
-8879879.841
-10544.87776
-8.879879841
700
903.5667369
-8733464.784
-9665.54481
-8.733464784
100
772.8240866
-8980746.023
-11620.68597
-8.980746023
200
728.4396228
-7174746.353
-9849.472939
-7.174746353
300
853.8150596
-8086380.361
-9470.880455
-8.086380361
400
880.8998789
-10743895.83
-12196.50052
-10.74389583
500
873.3190095
-9073376.839
-10389.5332
-9.073376839
600
970.3502616
-10560320.07
-10882.99812
-10.56032007
700
994.7535125
-10782927.85
-10839.79872
-10.78292785
100
476.9731415
-3685815.148
-7727.510895
-3.685815148
200
899.4393624
-8367901.907
-9303.464198
-8.367901907
300
677.4208636
-6464559.933
-9542.900551
-6.464559933
400
669.935571
-6761866.456
-10093.30859
-6.761866456
500
757.514801
-7937436.955
-10478.25989
-7.937436955
600
709.4725001
-7197725.828
-10145.17945
-7.197725828
700
896.1739731
-9944269.405
-11096.36042
-9.944269405
100
509.194495
-3940921.809
-7739.521633
-3.940921809
200
843.1455492
-9021394.789
-10699.68856
-9.021394789
300
493.0802075
-4593466.105
-9315.859843
-4.593466105
400
747.663107
-7709647.411
-10311.65954
-7.709647411
500
850.0222666
-8347580.16
-9820.425285
-8.34758016
600
699.2769258
-6997438.807
-10006.67768
-6.997438807
700
911.9998552
-9670313.38
-10603.41548
-9.67031338
100
862.7810992
-9630655.092
-11162.33898
-9.630655092
200
814.97837
-10847751.78
-13310.47814
-10.84775178
300
692.9714494
-6561266.557
-9468.30719
-6.561266557
400
973.8753853
-10795153.95
-11084.73847
-10.79515395
500
861.5884372
-9095508.027
-10556.67374
-9.095508027
600
871.4553434
-9299231.92
-10670.92191
-9.29923192
700
898.9196372
-8808011.358
-9798.441366
-8.808011358
100
900.1580384
-11095222.14
-12325.8602
-11.09522214
200
812.98454
-7977837.626
-9813.025012
-7.977837626
300
787.5934874
-9337052.026
-11855.16663
-9.337052026
400
635.9776593
-6327176.82
-9948.740695
-6.32717682
500
1172.291824
-11916600.1
-10165.21642
-11.9166001
600
855.9030459
-9221106.657
-10773.54112
-9.221106657
700
844.7740799
-9493434.193
-11237.83792
-9.493434193
100
800.8747198
-9569658.892
-11949.00857
-9.569658892
200
561.5618959
-5347791.428
-9523.066766
-5.347791428
300
648.4706794
-7217104.248
-11129.42262
-7.217104248
400
939.6638715
-10581278.5
-11260.7059
-10.5812785
500
845.4816334
-8665334.936
-10248.99252
-8.665334936
600
827.3938173
-9001634.832
-10879.50459
-9.001634832
700
935.9200689
-10599575.53
-11325.29997
-10.59957553
100
423.4015973
-6182300.076
-14601.50391
-6.182300076
200
744.9544323
-8849410.822
-11879.13037
-8.849410822
300
677.7880009
-6698720.575
-9883.209155
-6.698720575
400
802.3277821
-8770755.747
-10931.6366
-8.770755747
500
977.0877761
-10209345.64
-10448.74974
-10.20934564
600
821.2999952
-8706874.396
-10601.33258
-8.706874396
700
812.0011841
-8218805.047
-10121.66633
-8.218805047
100
1222.304202
-13985092.05
-11441.58061
-13.98509205
200
1004.156046
-12753121.99
-12700.3388
-12.75312199
300
764.6356128
-7079593.763
-9258.781104
-7.079593763
400
817.923861
-8481857.257
-10369.98388
-8.481857257
500
799.9491401
-8680319.573
-10851.08932
-8.680319573
600
912.0807701
-9832904.218
-10780.73844
-9.832904218
700
898.6604459
-9966334.492
-11090.21159
-9.966334492
100
693.220657
-6892731.488
-9943.05553
-6.892731488
200
781.1541729
-7644009.988
-9785.533065
-7.644009988
300
919.2116905
-9821242.214
-10684.41831
-9.821242214
400
820.771825
-8124733.082
-9898.893743
-8.124733082
500
875.7576825
-10316992.47
-11780.6474
-10.31699247
600
851.805464
-8838149.357
-10375.78383
-8.838149357
700
823.3712115
-8352980.18
-10144.85333
-8.35298018
100
1082.580784
-12173968.47
-11245.32104
-12.17396847
200
741.8716642
-8752208.869
-11797.47022
-8.752208869
300
865.7268207
-7652964.065
-8839.929505
-7.652964065
400
1015.819747
-10607835.1
-10442.63525
-10.6078351
500
933.1098887
-10794687.32
-11568.50597
-10.79468732
600
939.8482202
-10349191.24
-11011.55593
-10.34919124
700
843.5153718
-8965668.561
-10628.93323
-8.965668561
100
1301.632517
-14253982.75
-10950.85023
-14.25398275
200
580.2062612
-7186136.297
-12385.48561
-7.186136297
300
897.9971265
-7819026.896
-8707.184762
-7.819026896
400
919.8887584
-10673578.3
-11603.11853
-10.6735783
500
882.4917718
-9302086.385
-10540.70608
-9.302086385
600
887.9416264
-9512118.361
-10712.5492
-9.512118361
700
895.9304537
-9587346.142
-10700.9937
-9.587346142
100
557.3503487
-6628680.895
-11893.2031
-6.628680895
200
802.3089612
-7406484.16
-9231.461343
-7.40648416
300
877.0616345
-10384487.79
-11840.08897
-10.38448779
400
893.8736932
-10116554.94
-11317.65597
-10.11655494
This is a portion of the data; to view all the data, please download the file.
Dataset 1.Data used for a simulation of Figure 2.
Discussion
RCTs have become “massive bureaucratic and corporate enterprises, demanding costly infrastructure for research design, patient care, record keeping, ethical review, and statistical analysis”17. A single phase 3 RCT could today cost $30 million or more18 and take several years from inception to finalisation. These trials are powered for arbitrary rules of statistical significance. Critics of this approach3 argue “that some of the sciences have made a mistake, by basing decisions on statistical significance” and that “in daily use it produces unchecked a loss of jobs, justice, profit, and even life”. The mistake made by the so called ‘sizeless scientist’ is to favour ‘Precision’ over ‘Oomph’. A ‘sizeless scientist’ is more interested in how precisely an outcome is estimated and less interested in the size of the implications for society or health services of any observed change in the outcome. They do not appear interested in the facts that “significant does not mean important and insignificant does not mean unimportant”. Even experts in statistics have been shown to interpret evidence poorly, based on whether the p-value crosses the threshold of 5% for statistical significance19.
Researchers today are calling for a shift towards research designed for decision making20. Yet this is not new, in 1967 Schwartz & Lellouch21 made a distinction between ‘explanatory’ and ‘pragmatic’ approaches. The former seeks ‘proof’ of the efficacy of a new treatment and the latter is about ‘choosing’ the best from two treatments. Patients, clinicians and payers of health care are interested in whether some novel treatment or health programme should be adopted over the alternatives.
There are many choices to be evaluated and many useful clinical trials to be undertaken, yet research budgets to support these are insufficient22. Funding a larger number of smaller trials to enable correct decisions about how to organise health services more frequently is a sensible goal. A hypothesis-testing approach maintains that a uniform level of certainty around these decisions is desirable, and needed by all stakeholders: managers, clinicians and patients. Yet the costs and benefits of every decision made are context-specific. Striving to eliminate uncertainty is likely to be inefficient use of research funding, where the benefit of achieving a given level of certainty is low or the prescribed precision unnecessary. We are not the only group that are advocating for this approach, and others have used cost-effectiveness as a criteria for dynamically deciding the necessary size of an ongoing trial23. There is a wider literature on decision making including economic data. Decision-making should address the costs and benefits throughout the life cycle of an intervention24, with consideration of whether decisions could be made based on current evidence and whether additional research needs to be undertaken25. Other considerations for decision making under conditions of uncertainty have been established and reviewed in detail26.
Our observations contradict advice by Nagendran et al.27 who suggest researchers aim to “conduct studies that are larger and properly powered to detect modest effects”. This approach promotes using p-values for decision making without a more encompassing evaluation of all outcomes that are relevant for decision-making.
We suggest the decision making approach to sample size calculation would often lead to smaller trials, but not always. If rare adverse events had a substantial impact on cost and health outcomes the trial may be larger than a hypothesis testing trial powered for a single outcome, which was not the adverse event. This may especially be the case for trials of new drugs. There are some good arguments against smaller trials. A large trial with lots of data might help future proof an adoption decision. If costs, frequencies of adverse events or baseline risks change over time then a large trial might render sufficient information to defend the adoption decision in the future as compared to a small trial. There might also not be another opportunity to run an RCT, for ethical or funding reasons, and so gathering a lot of data when the chance arises could be wise. Smaller trials, despite being well designed, might find a positive result that overestimates the real effect28. This may have happened with our example of TEXT ME and a more conservative estimate of the intervention effect would likely come from a meta-analysis or repeated trial. Indeed Prasad et al.29 found from 2,044 articles published over 10 years in a leading medical journal, 1,344 were about a medical practice, 363 of them tested an established medical practice and for 146 (40%) the finding was that practice was no better or worse than the comparator implying a reversal of practice. Those who deliver health services are unlikely to be rational and risk neutral. There is often scepticism and inertia when a change to practice is suggested and some clinicians will only change when evidence is overwhelming. Lau et al.30 did a cumulative meta-analysis of intravenous streptokinase for acute myocardial infarction with mortality as the primary outcome. They showed the probability the treatment reduced mortality was greater than 97.5% by 1973 after 2,432 patients had been enrolled in eight trials. By 1977, after 4,084 patients had been enrolled in thirteen trials the probability the treatment was effective was more than 99.5%. By 1988, 36 trials had been completed with 36,974 patients included confirming the previous conclusion.
Our case study demonstrates - for a single carefully conducted trial - that more information might have been collected than was necessary for a good decision to be made about a decision to adopt the intervention. We did not cherry pick this trial, but selected it because it was a recent economic analysis and had broad implications for health. The differences in necessary sample sizes and evidence will depend on context and design of trials. It might often be that smaller and so faster and cheaper trials are sufficient for good decision-making. This would release scarce research dollars that funding bodies could use for other valuable projects. Our approach is part of the drive toward increasing the value of health and medical research, which currently has a poor return with an estimated 85% of investment wasted31. Further, as adaptive trials gain traction, decision based designs provide flexibility, facilitating faster evolution of implementable findings.
Data availability
The datasets used and/or analysed for the TEXT ME trial are not publicly available due to data sharing not being approved by the local ethics committee. To access the data, the corresponding author of the primary trial should be contacted ([email protected]).
A random sample of the TEXT ME clinical trial data that has similar features to the TEXT ME data is provided in the code used to create the simulations and figures, which is available on GitHub: https://github.com/agbarnett/trials.smaller
The TEXT ME trial was supported by peer-reviewed grants from the National Heart Foundation of Australia Grant-in-Aid (G10S5110) and a BUPA Foundation Grant. We acknowledge the team who designed and conducted the TEXT ME trial and allowed us to re-analyse the data for the purpose of this paper: Clara Chow, Julie Redfern, Graham Hillis, Aravinda Thiagalingam, Stephen Jan, Maree Hackett, Robyn Whittaker. They did not provide editorial input or endorsement. The TEXT ME trial was administered by The George Institute for Global Health, Sydney Medical School, University of Sydney, Sydney, Australia.
Regarding the extra activity for this paper the authors declare that no grants were involved in supporting this work.
Faculty Opinions recommended
References
1.
Hunink MM, Weinstein MC, Wittenberg E, et al.:
Decision making in health and medicine: integrating evidence and values. Cambridge University Press; 2014. Publisher Full Text
2.
Tversky A, Kahneman D:
The framing of decisions and the psychology of choice.
Science.
1982; 211(4481): 453–8. PubMed Abstract
| Publisher Full Text
3.
Ziliak S, McCloskey D:
The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice, and Lives. Ann Arbor, MI.: The University of Michigan Press;
2008. Publisher Full Text
4.
Woodcock J, Ware JH, Miller PW, et al.:
Clinical Trials Series.
N Engl J Med.
2016; 374(22): 2167. Publisher Full Text
5.
Claxton K:
The irrelevance of inference: a decision-making approach to the stochastic evaluation of health care technologies.
J Health Econ.
1999; 18(3): 341–64. PubMed Abstract
| Publisher Full Text
6.
Goodman SN:
Toward evidence-based medical statistics. 1: The P value fallacy.
Ann Intern Med.
1999; 130(12): 995–1004. PubMed Abstract
| Publisher Full Text
7.
Chow CK, Redfern J, Hillis GS, et al.:
Effect of Lifestyle-Focused Text Messaging on Risk Factor Modification in Patients With Coronary Heart Disease: A Randomized Clinical Trial.
JAMA.
2015; 314(12): 1255–63. PubMed Abstract
| Publisher Full Text
8.
Wasserstein RL, Lazar NA:
The ASA's statement on p-values: context, process, and purpose.
Am Stat.
2016; 70(2): 129–33. Publisher Full Text
9.
Claxton K, Palmer S, Longworth L, et al.:
A Comprehensive Algorithm for Approval of Health Technologies With, Without, or Only in Research: The Key Principles for Informing Coverage Decisions.
Value Health.
2016; 19(6): 885–91. PubMed Abstract
| Publisher Full Text
10.
Phelps CE, Mushlin AI:
On the (near) equivalence of cost-effectiveness and cost-benefit analyses.
Int J Technol Assess Health Care.
1991; 7(1): 12–21. PubMed Abstract
| Publisher Full Text
11.
Torrance GW:
Measurement of health state utilities for economic appraisal.
J Health Econ.
1986; 5(1): 1–30. PubMed Abstract
| Publisher Full Text
13.
Claxton K:
Bayesian approaches to the value of information: implications for the regulation of new pharmaceuticals.
Health Econ.
1999; 8(3): 269–74. PubMed Abstract
| Publisher Full Text
14.
Redfern J, Thiagalingam A, Jan S, et al.:
Development of a set of mobile phone text messages designed for prevention of recurrent cardiovascular events.
Eur J Prev Cardiol.
2014; 21(4): 492–9. PubMed Abstract
| Publisher Full Text
15.
Chow CK, Redfern J, Thiagalingam A, et al.:
Design and rationale of the tobacco, exercise and diet messages (TEXT ME) trial of a text message-based intervention for ongoing prevention of cardiovascular disease in people with coronary disease: a randomised controlled trial protocol.
BMJ Open.
2012; 2(1): e000606. PubMed Abstract
| Publisher Full Text
| Free Full Text
16.
Burn E, Nghiem S, Jan S, et al.:
Cost-effectiveness of a text message programme for the prevention of recurrent cardiovascular events.
Heart.
2017; 103(12): 893–4. PubMed Abstract
| Publisher Full Text
17.
Bothwell LE, Greene JA, Podolsky SH, et al.:
Assessing the Gold Standard--Lessons from the History of RCTs.
N Engl J Med.
2016; 374(22): 2175–81. PubMed Abstract
| Publisher Full Text
18.
Sertkaya A, Birkenbach A, Berlind A, et al.:
Examination of clinical trial costs and barriers for drug development: report to the Assistant Secretary of Planning and Evaluation (ASPE). Washington, DC: : Department of Health and Human Services; 2014. Reference Source
19.
McShane BB, Gal D:
Statistical Significance and the Dichotomization of Evidence.
J Am Stat Assoc.
2017; 112(519): 885–95. Publisher Full Text
20.
Lieu TA, Platt R:
Applied Research and Development in Health Care - Time for a Frameshift.
N Engl J Med.
2017; 376(8): 710–3. PubMed Abstract
| Publisher Full Text
21.
Schwartz D, Lellouch J:
Explanatory and pragmatic attitudes in therapeutical trials.
J Clin Epidemiol.
2009; 62(5): 499–505. PubMed Abstract
| Publisher Full Text
23.
Pertile P, Forster M, La Torre D:
Optimal Bayesian sequential sampling rules for the economic evaluation of health technologies.
J R Statist Soc A.
2014; 177(2): 419–438. Publisher Full Text
24.
Sculpher M, Drummond M, Buxton M:
The iterative use of economic evaluation as part of the process of health technology assessment.
J Health Serv Res Policy.
1997; 2(1): 26–30. PubMed Abstract
| Publisher Full Text
25.
Sculpher MJ, Claxton K, Drummond M, et al.:
Whither trial-based economic evaluation for health care decision making?
Health Econ.
2006; 15(7): 677–87. PubMed Abstract
| Publisher Full Text
26.
Claxton K, Palmer S, Longworth L, et al.:
Informing a decision framework for when NICE should recommend the use of health technologies only in the context of an appropriately designed programme of evidence development.
Health Technol Assess.
2012; 16(46): 1–323. PubMed Abstract
| Publisher Full Text
27.
Nagendran M, Pereira TV, Kiew G, et al.:
Very large treatment effects in randomised trials as an empirical marker to indicate whether subsequent trials are necessary: meta-epidemiological assessment.
BMJ.
2016; 355: i5432. PubMed Abstract
| Publisher Full Text
| Free Full Text
28.
Barnett AG, van der Pols JC, Dobson AJ:
Regression to the mean: what it is and how to deal with it.
Int J Epidemiol.
2005; 34(1): 215–20. PubMed Abstract
| Publisher Full Text
29.
Prasad V, Vandross A, Toomey C, et al.:
A decade of reversal: an analysis of 146 contradicted medical practices.
Mayo Clin Proc.
2013; 88(8): 790–8. PubMed Abstract
| Publisher Full Text
30.
Lau J, Schmid CH, Chalmers TC:
Cumulative meta-analysis of clinical trials builds evidence for exemplary medical care.
J Clin Epidemiol.
1995; 48(1): 45–57; discussion 59-60. PubMed Abstract
| Publisher Full Text
31.
Chalmers I, Glasziou P:
Avoidable waste in the production and reporting of research evidence.
Lancet.
2009; 374(9683): 86–9. PubMed Abstract
| Publisher Full Text
32.
Barnett A:
agbarnett/smaller.trials: First release of R code for smaller clinical trials (Version v1.0).
Zenodo.
2018. http://www.doi.org/10.5281/zenodo.1322459
1
Institute of Health and Biomedical Innovation, Queensland University of Technology, Brisbane, QLD, 4059, Australia 2
Nuffield Department of Orthopaedics, Oxford University, Oxford, OX3 7LD, UK 3
Princess Alexandra Hospital, Brisbane, Brisbane, QLD, 4102, Australia
Graves N, Barnett AG, Burn E and Cook D. Smaller clinical trials for decision making; a case study to show p-values are costly [version 2; peer review: 1 approved, 2 approved with reservations]. F1000Research 2018, 7:1176 (https://doi.org/10.12688/f1000research.15522.2)
NOTE: If applicable, it is important to ensure the information in square brackets after the title is included in all citations of this article.
track
receive updates on this article
Track an article to receive email alerts on any updates to this article.
Share
Open Peer Review
Current Reviewer Status:
?
Key to Reviewer Statuses
VIEWHIDE
ApprovedThe paper is scientifically sound in its current form and only minor, if any, improvements are suggested
Approved with reservations
A number of small changes, sometimes more significant revisions are required to address specific details and improve the papers academic merit.
Not approvedFundamental flaws in the paper seriously undermine the findings and conclusions
Mark DB. Reviewer Report For: Smaller clinical trials for decision making; a case study to show p-values are costly [version 2; peer review: 1 approved, 2 approved with reservations]. F1000Research 2018, 7:1176 (https://doi.org/10.5256/f1000research.17883.r151315)
This article addresses an important and provocative idea, namely that we are making our clinical trials larger and more expensive than is necessary for rational decision making. I suspect the authors are correct but would offer several general reasons why
... Continue reading
This article addresses an important and provocative idea, namely that we are making our clinical trials larger and more expensive than is necessary for rational decision making. I suspect the authors are correct but would offer several general reasons why I think the case they have presented overlooks some key elements that help explain why things are less than optimally efficient in the sense proposed by the authors.
First, the trial they use to illustrate their ideas is a relatively simple test of text messaging to improve risk factor management. The intervention was not expensive and did not involve any complex risk benefit considerations. However, most of the trials that affect clinical management and that have a large health care budgetary impact involve interventions that are very expensive (with the potential to generate annual expenditures in the US of multiple billions of dollars a year) and often involve complex issues of risk and benefits. Regulatory approval in the US has typically involved many smaller trials leading up to two pivotal phase III trials that generally both need to be "positive" on their primary endpoint, meaning they need to show the treatment effect has a p< 0.05. Failing to achieve the requisite level of "evidence" in this context will typically result in a decision not to grant regulatory approval, in which case the company developing the therapy is faced with the decision about whether to abandon the work and investment to that point or to invest more in what may be an even larger and more expensive next trial. Regulators in the US at least currently are charged with ensuring treatments are both safe and effective before granting market approval and they do not have any responsibility for addressing cost effectiveness or budget impact. So these decision makers at least would not accept a lower standard of evidence in order to improve efficiency and the level of evidence has a big effect on their decision making.
Second, clinical practice guideline committees and major clinical journals also triage clinical trial interpretation according to strict statistical significance criteria. Many trials published in journals such as NEJM have had the tested therapy declared ineffective because of a p value in the range of 0.06 to 0.10. In such situations, guideline committees are very likely to accept the official interpretation and make recommendations accordingly. These decision makers also do not have any interest in accepting lower levels of precision in order to improve the efficiency of the health care system. Part of the difficulty here is the (mis)understanding of what significance tests/p values can and cannot tell us about the outcomes of a clinical experiment/RCT, as the authors discuss. Fixing that by getting clinicians and statisticians and guideline committees to use more flexible, comprehensive interpretive approaches to evidence has proven quite difficult.
Third, the authors describe their target audience as health care decision makers managing health care services. The assumptions of economics regarding the decisions being made by rational decision makers who have the goal of maximizing the health benefits for the largest number of their population possible is an interesting model but it's not clear that it describes any actual health care system and how it functions. In the US, the primary focus is on budget impact not efficiency. In countries where economic analysis is required for reimbursement, budget impact still seems to be a dominant consideration.
The implications for the paper would seem to be that the authors should consider in their presentation a bit more about what the needed infrastructure is in order for their recommendations to be adopted. What kind of trials would be suitable for smaller tests accepting less precision in exchange for more rapid efficiency and lower costs? One area might be implementation trials, in other words, trials testing the deployment into the practice of things we already know work from prior, large pivotal trials. The example provided seems to fit in this category.
The global nature of scientific medicine means that the knowledge about effective but expensive therapies is widely available to providers and patients across health systems. Health systems can therefore no longer refuse to provide their citizens with advances simply because of the expense, but at the same time they have to control the growth of health care spending. Making more therapies available with a greater uncertainty accepted in the estimated treatment effect may be difficult to sell as a general concept. One could, I suppose, argue that if regulatory approval were not so expensive, companies would not need to charge such high prices for new advances. Not clear that there is any appetite among health regulators for moves in this direction and even if some countries did adopt such a program, the developers of new therapies facing the global market forces might not benefit enough to alter pricing.
Besides some forms of implementation research, I think what the authors are proposing could work in the context of "evidence free zones", areas of medicine where there is little beyond anecdote and expert opinion to use in decision making. In that context, an inexpensive trial that provides some reliable evidence, accepting a higher level of uncertainty, can still be used to change/guide practice and policy. Despite all the trials that get reported every year, much of current practice guidelines still consist of expert opinion, as large clinical trials are only done in select areas where funding sources exist willing to support the work. Most of clinical medicine falls outside these zones.
In summary, I think the authors have raised an important and interesting issue. I would ask them to consider discussing a bit more of the real world nuances of how and where this might work and where it is unlikely to be accepted.
Is the work clearly and accurately presented and does it cite the current literature?
Yes
Is the study design appropriate and is the work technically sound?
Partly
Are sufficient details of methods and analysis provided to allow replication by others?
Yes
If applicable, is the statistical analysis and its interpretation appropriate?
Partly
Are all the source data underlying the results available to ensure full reproducibility?
Yes
Are the conclusions drawn adequately supported by the results?
Partly
Competing Interests: No competing interests were disclosed.
Reviewer Expertise: Clinical trials, outcomes research, clinical economics, cardiovascular medicine
I confirm that I have read this submission and believe that I have an appropriate level of expertise to confirm that it is of an acceptable scientific standard, however I have significant reservations, as outlined above.
Mark DB. Reviewer Report For: Smaller clinical trials for decision making; a case study to show p-values are costly [version 2; peer review: 1 approved, 2 approved with reservations]. F1000Research 2018, 7:1176 (https://doi.org/10.5256/f1000research.17883.r151315)
Julious S. Reviewer Report For: Smaller clinical trials for decision making; a case study to show p-values are costly [version 2; peer review: 1 approved, 2 approved with reservations]. F1000Research 2018, 7:1176 (https://doi.org/10.5256/f1000research.17883.r46419)
While I agree with the sentiments of the authors that there can be instances where a conventional sample size calculation may not be appropriate. I do have an issue with the generalisations they are making from a single trial to
... Continue reading
While I agree with the sentiments of the authors that there can be instances where a conventional sample size calculation may not be appropriate. I do have an issue with the generalisations they are making from a single trial to studies costing $30m.
The gold standard for an assessment of efficacy right or wrong is a formal hypothesis test. There is a need to definitively show evidence of clinical effect for most interventions.
The example that was quoted in the paper is a cheap intervention. Low cost interventions may be anticipated to observed small effects: so small that the expense of undertaking a clinical trial could be prohibitively expensive.
I have recent experience of two trials investigating low cost interventions in the U@UNI trial and the PLEASANT trial.1,2,3,4 In both these trials the interventions could be shown to be cost effective (or cost saving). It could be contended in both the sample size could have been based on cost effectiveness.
In summary, therefore, there is merit in what the authors are suggesting but there needs to be consideration as to when the arguments could be applied.
Is the work clearly and accurately presented and does it cite the current literature?
Yes
Is the study design appropriate and is the work technically sound?
Yes
Are sufficient details of methods and analysis provided to allow replication by others?
Yes
If applicable, is the statistical analysis and its interpretation appropriate?
No
Are all the source data underlying the results available to ensure full reproducibility?
Yes
Are the conclusions drawn adequately supported by the results?
No
References
1. Chloe T, Penny B, Mark S, Alan B, et al.: The cost-effectiveness of an updated theory-based online health behavior intervention for new university students: U@Uni2. Journal of Public Health and Epidemiology. 2016; 8 (10): 191-203 Publisher Full Text 2. Epton T, Norman P, Dadzie AS, Harris PR, et al.: A theory-based online health behaviour intervention for new university students (U@Uni): results from a randomised controlled trial.BMC Public Health. 2014; 14: 563 PubMed Abstract | Publisher Full Text 3. Julious SA, Horspool MJ, Davis S, Bradburn M, et al.: PLEASANT: Preventing and Lessening Exacerbations of Asthma in School-age children Associated with a New Term - a cluster randomised controlled trial and economic evaluation.Health Technol Assess. 20 (93): 1-154 PubMed Abstract | Publisher Full Text 4. Franklin M, Davis S, Horspool M, Kua WS, et al.: Economic Evaluations Alongside Efficient Study Designs Using Large Observational Datasets: the PLEASANT Trial Case Study.Pharmacoeconomics. 2017; 35 (5): 561-573 PubMed Abstract | Publisher Full Text
Competing Interests: No competing interests were disclosed.
Reviewer Expertise: Medical statsitics, clinical trials
I confirm that I have read this submission and believe that I have an appropriate level of expertise to confirm that it is of an acceptable scientific standard.
Julious S. Reviewer Report For: Smaller clinical trials for decision making; a case study to show p-values are costly [version 2; peer review: 1 approved, 2 approved with reservations]. F1000Research 2018, 7:1176 (https://doi.org/10.5256/f1000research.17883.r46419)
Senn S. Reviewer Report For: Smaller clinical trials for decision making; a case study to show p-values are costly [version 2; peer review: 1 approved, 2 approved with reservations]. F1000Research 2018, 7:1176 (https://doi.org/10.5256/f1000research.17883.r38819)
NOTE: it is important to ensure the information in square brackets after the title is included in this citation.
Reviewer Report09 Oct 2018
Stephen Senn,
Competence Center for Methodology and Statistics, Luxembourg Institute Of Health, Strassen, Luxembourg; School of Health and Related Research, University of Sheffield, Sheffield, UK
First let me apologise for a stupid slip in my first review. I referred to sampling without replacement and the authors quite rightly corrected me and pointed out that they sampled with replacement. That is, in fact, what I meant
... Continue reading
First let me apologise for a stupid slip in my first review. I referred to sampling without replacement and the authors quite rightly corrected me and pointed out that they sampled with replacement. That is, in fact, what I meant to say.
Second, let me acknowledge that the authors have gone some way to answering my criticisms. However, I am not completely satisfied, so before changing my overall judgement of the paper, I am going to explain the problem again.
Consider an alternative to sampling with replacement that will produce almost the same results they did. This is to compare a super trial in which the values for every patient in the TEXT ME trial are copied a huge number of times to create a million versions of each patient. Thus every patient in the trial has 999,999 identical virtual siblings. Where the TEXT ME trial had 710 patients we now have 710 million patients. Let us call this trial MegaText. If all these patients were real, then in the huge population of MegaText the effect seen would be the true effect. Now we can actually sample without replacement from MegaText and the result will be almost identical to sampling with replacement from the TEXT ME trial. The only slight difference is that in sampling without replacement from MegaText once a patient has been chosen there is a very slightly reduced chance of the patient being chosen again but since there are so many copies, this hardly matters.
Therefore, sampling from the TEXT ME trial is almost identical to sampling from the MegaText trial and it thus follows that we are sampling from a population in which there is a genuine treatment effect and there is no uncertainty about this. Thus the right decision is known to be to implement the program. Of course, and their simulation shows this, if the trial is small enough, you will sometimes choose the wrong treatment. If the purpose of the trial is pragmatic in the sense of Schwartz and Lellouch(Schwartz, D. & Lellouch, J., 1967), then it is this Type III error that has to be guarded against.
However, this raises the second issue. The decision to always choose what appears to be the better of two treatments being compared, however weak the evidence, is logical if no further evidence can be obtained. However, it is not necessarily logical if more information can be obtained at a modest cost. To see this, consider the case where a new treatment N is being compared to a standard treatment S and high values are good, as would be the case if we are measuring utility. The Bayesian posterior distribution for difference in effects (N-S) is mainly in the positive area: it is more probable than not, taking all things into account that it is better to use N. However, there is a non-negligible probability that actually S is better. If information can be obtained at low cost it may be worth doing so just to exclude the possibility that S is after all better.
Thus, I have some unease that the combination of starting with a proven treatment and showing that if one had carried out a smaller trial one would often come to an apparently good choice of treatment if one had to be made is quite as relevant to the practical problem that choosing a sample size is meant to solve. This is not to say that common approaches to doing this are good: far from it. They ignore the dimension of cost and this cannot be rationale.
Thus, if what the authors wish to say is: “just because a trial has not found a significant result it does not follow that it cannot be used to decide to implement a new treatment if no further information will be forthcoming” there are some circumstances under which I could agree. If they wish to imply that standards should generally be less stringent than they currently are, I do not think this sort of investigation is particularly relevant.
References
1. Schwartz D, Lellouch J: Explanatory and pragmatic attitudes in therapeutical trials.J Chronic Dis. 1967; 20 (8): 637-48 PubMed Abstract
Competing Interests: As far as I am aware I have no competing interests. I maintain a general statement of interests here: http://www.senns.demon.co.uk/Declaration_Interest.htm
Reviewer Expertise: I am a medical statistician with many years experience in dealing with problems associated with drug development and regulation.
I confirm that I have read this submission and believe that I have an appropriate level of expertise to confirm that it is of an acceptable scientific standard, however I have significant reservations, as outlined above.
Senn S. Reviewer Report For: Smaller clinical trials for decision making; a case study to show p-values are costly [version 2; peer review: 1 approved, 2 approved with reservations]. F1000Research 2018, 7:1176 (https://doi.org/10.5256/f1000research.17883.r38819)
Nicholas Graves, Institute of Health and Biomedical Innovation, Queensland University of Technology, Brisbane, 4059, Australia
31 Oct 2019
Author Response
We thank the reviewer for the additional comments and try to respond to the key issue that arose in the first review.
The reviewer says “simulating only from the case where
...
Continue readingWe thank the reviewer for the additional comments and try to respond to the key issue that arose in the first review.
The reviewer says “simulating only from the case where the intervention is beneficial is not adequate”, but we simulate because we are not certain the intervention is beneficial. Hence, we simulate from the observed data in order to see whether the intervention is beneficial on a meaningful scale.
In general, these simulations use multiple outcomes, some of which may have a positive mean (e.g., improvement in blood pressure and the associated health benefits/ health utility) and some have a negative mean (e.g., increase in costs). Hence, it is a composite estimate that is more complex that just one mean being positive or not.
We used this approach for another important question about whether a hand hygiene campaign should be funded and showed the conclusions varied for different states and territories of Australia, see Table 3 of this paper…
In South Australian, Tasmania & Western Australia the positive difference in the main outcome was not large enough to justify a decision to continue the campaign. But in Queensland, ACT and New South Wales we concluded the opposite.
We are not simply reliant on a single positive mean, which should happen for around 50% of studies where the intervention has no effect and hence is quite easy to achieve. Instead, we are looking at whether the observed difference is meaningful using the observed variation in the sample.
It is possible to use scenario analysis to simulate results under more pessimistic scenarios, such as a null treatment effect but reduction in costs, and these can be informative for decision makers.
We thank the reviewer for the additional comments and try to respond to the key issue that arose in the first review.
The reviewer says “simulating only from the case where the intervention is beneficial is not adequate”, but we simulate because we are not certain the intervention is beneficial. Hence, we simulate from the observed data in order to see whether the intervention is beneficial on a meaningful scale.
In general, these simulations use multiple outcomes, some of which may have a positive mean (e.g., improvement in blood pressure and the associated health benefits/ health utility) and some have a negative mean (e.g., increase in costs). Hence, it is a composite estimate that is more complex that just one mean being positive or not.
We used this approach for another important question about whether a hand hygiene campaign should be funded and showed the conclusions varied for different states and territories of Australia, see Table 3 of this paper…
In South Australian, Tasmania & Western Australia the positive difference in the main outcome was not large enough to justify a decision to continue the campaign. But in Queensland, ACT and New South Wales we concluded the opposite.
We are not simply reliant on a single positive mean, which should happen for around 50% of studies where the intervention has no effect and hence is quite easy to achieve. Instead, we are looking at whether the observed difference is meaningful using the observed variation in the sample.
It is possible to use scenario analysis to simulate results under more pessimistic scenarios, such as a null treatment effect but reduction in costs, and these can be informative for decision makers.
Nicholas Graves, Institute of Health and Biomedical Innovation, Queensland University of Technology, Brisbane, 4059, Australia
31 Oct 2019
Author Response
We thank the reviewer for the additional comments and try to respond to the key issue that arose in the first review.
The reviewer says “simulating only from the case where
...
Continue readingWe thank the reviewer for the additional comments and try to respond to the key issue that arose in the first review.
The reviewer says “simulating only from the case where the intervention is beneficial is not adequate”, but we simulate because we are not certain the intervention is beneficial. Hence, we simulate from the observed data in order to see whether the intervention is beneficial on a meaningful scale.
In general, these simulations use multiple outcomes, some of which may have a positive mean (e.g., improvement in blood pressure and the associated health benefits/ health utility) and some have a negative mean (e.g., increase in costs). Hence, it is a composite estimate that is more complex that just one mean being positive or not.
We used this approach for another important question about whether a hand hygiene campaign should be funded and showed the conclusions varied for different states and territories of Australia, see Table 3 of this paper…
In South Australian, Tasmania & Western Australia the positive difference in the main outcome was not large enough to justify a decision to continue the campaign. But in Queensland, ACT and New South Wales we concluded the opposite.
We are not simply reliant on a single positive mean, which should happen for around 50% of studies where the intervention has no effect and hence is quite easy to achieve. Instead, we are looking at whether the observed difference is meaningful using the observed variation in the sample.
It is possible to use scenario analysis to simulate results under more pessimistic scenarios, such as a null treatment effect but reduction in costs, and these can be informative for decision makers.
We thank the reviewer for the additional comments and try to respond to the key issue that arose in the first review.
The reviewer says “simulating only from the case where the intervention is beneficial is not adequate”, but we simulate because we are not certain the intervention is beneficial. Hence, we simulate from the observed data in order to see whether the intervention is beneficial on a meaningful scale.
In general, these simulations use multiple outcomes, some of which may have a positive mean (e.g., improvement in blood pressure and the associated health benefits/ health utility) and some have a negative mean (e.g., increase in costs). Hence, it is a composite estimate that is more complex that just one mean being positive or not.
We used this approach for another important question about whether a hand hygiene campaign should be funded and showed the conclusions varied for different states and territories of Australia, see Table 3 of this paper…
In South Australian, Tasmania & Western Australia the positive difference in the main outcome was not large enough to justify a decision to continue the campaign. But in Queensland, ACT and New South Wales we concluded the opposite.
We are not simply reliant on a single positive mean, which should happen for around 50% of studies where the intervention has no effect and hence is quite easy to achieve. Instead, we are looking at whether the observed difference is meaningful using the observed variation in the sample.
It is possible to use scenario analysis to simulate results under more pessimistic scenarios, such as a null treatment effect but reduction in costs, and these can be informative for decision makers.
Senn S. Reviewer Report For: Smaller clinical trials for decision making; a case study to show p-values are costly [version 2; peer review: 1 approved, 2 approved with reservations]. F1000Research 2018, 7:1176 (https://doi.org/10.5256/f1000research.16927.r37678)
NOTE: it is important to ensure the information in square brackets after the title is included in this citation.
Reviewer Report07 Sep 2018
Stephen Senn,
Competence Center for Methodology and Statistics, Luxembourg Institute Of Health, Strassen, Luxembourg; School of Health and Related Research, University of Sheffield, Sheffield, UK
The authors propose that when a clinical trial is sought to inform practical decision-making, conventional standards of 'proof' may be too stringent and in consequence resources may be wasted. They illustrate this by simulating from a particular clinical trial, the
... Continue reading
The authors propose that when a clinical trial is sought to inform practical decision-making, conventional standards of 'proof' may be too stringent and in consequence resources may be wasted. They illustrate this by simulating from a particular clinical trial, the TEXT ME trial, using progressively smaller sample sizes and suggest that a useful decision could have been made with fewer patients.
The general argument presented is interesting and the conclusion that trials are sometimes too big if practical decision making is the object may well be correct. In this respect, a key distinction was made just over 50 years ago by Schwartz and Lelouch1 between what they called explanatory or pragmatic approaches. In the former case 'proof' of the efficacy of a new treatment may be sought. In the latter case one may simply wish to choose the (plausibly) better of two treatments.
However, unless I have misunderstood what the authors are doing (which I do not exclude but in that case they should clarify this) the simulation is not a valid proof of what they claim, even for the example chosen.
The problem is the following. By simulating from the particular trial results, they are simulating from a universe in which the treatment is effective. This would be true even if the results from the TEXT ME trial had not been 'significant'. It is true of any trial in which the observed results favour the intervention. To see this consider that valid statistical analyses will typically have type I error rates in excess of a chosen nominal value if the mean under the intervention is greater (assuming high values are good) than the mean in the control group in the population in question. Provided that the type I error rate is controlled when this is not the case, this is a desirable property of such tests.
Usually, the population in question is taken to be the population of all possible randomisations of the patients. Here, the authors sampled without replacement from the population. The population from which they are sampling is the population of results in the full TEXT ME trial. However, this is a population in which on average the results were better for the intervention.
Hindsight is an exact science but those making practical healthcare decisions are involved in the quite different game of foresight and they need to know whether the decision they are about to make is a reasonable one. This requires their allowing for the possibility that the intervention is useless or even harmful. Thus a mixture of possible situations has to be considered: simulating only from the case where the intervention is beneficial is not adequate.
In fact the precise nature of the mixture envisaged can have a huge effect on the inferences. Recently, a number of authors have called for statistical standards of evidence to be modified in the opposite direction. For instance Benjamin et al.2 have suggested that the standard of p=0.005 should be adopted. David Colquhoun3 has proposed an even more stringent standard of P=0.001. This flows from the particular approach to Bayesian hypothesis testing which places a lump of probability on no difference between treatments. (See my blog4 for a discussion.) In my opinion, these are not good suggestions for a number of reasons, including that such prior distributions are far too informative and that these authors implicitly assume, which is far from obviously the case, that the explanatory purpose of clinical trials is more important than the pragmatic one.
However, I agree entirely with the authors, that as soon as practical decision-making involving economics is involved, it is the value of information that is important. In this connection, I can recommend the work of Forster, Pertile and colleagues5,6. See also Burman et al. 7
Thus, I think to make good their claim, the authors would, at the very least, need to simulate from a universe in which the intervention was not necessarily better than the control. Unless I have misunderstood, this was not the simulation they undertook.
Is the work clearly and accurately presented and does it cite the current literature?
Partly
Is the study design appropriate and is the work technically sound?
Partly
Are sufficient details of methods and analysis provided to allow replication by others?
Partly
If applicable, is the statistical analysis and its interpretation appropriate?
No
Are all the source data underlying the results available to ensure full reproducibility?
Yes
Are the conclusions drawn adequately supported by the results?
No
References
1. Schwartz D, Lellouch J: Explanatory and pragmatic attitudes in therapeutical trials.J Chronic Dis. 1967; 20 (8): 637-48 PubMed Abstract 2. Benjamin D, Berger J, Johannesson M, Nosek B, et al.: Redefine statistical significance. Nature Human Behaviour. 2018; 2 (1): 6-10 Publisher Full Text 3. Colquhoun D: An investigation of the false discovery rate and the misinterpretation of p-values.R Soc Open Sci. 2014; 1 (3): 140216 PubMed Abstract | Publisher Full Text 4. Senn SJ: Double Jeopardy: Judge Jeffreys upholds the law. 2015. Reference Source 5. Pertile P, Forster M, Torre D: Optimal Bayesian sequential sampling rules for the economic evaluation of health technologies. Journal of the Royal Statistical Society: Series A (Statistics in Society). 2014; 177 (2): 419-438 Publisher Full Text 6. Jobjörnsson S, Forster M, Pertile P, Burman CF: Late-stage pharmaceutical R&D and pricing policies under two-stage regulation.J Health Econ. 2016; 50: 298-311 PubMed Abstract | Publisher Full Text 7. Burman C-F: Decision Analysis in Drug Development. In: Dmitrienko A, Chuang-Stein C, Agostino R, eds. Pharmaceutical Statistics Using SAS: A Practical Guide.Cary: SAS Institute. 2007. 385-428
Competing Interests: No competing interests were disclosed.
Reviewer Expertise: I am a medical statistician with many years experience in dealing with problems associated with drug development and regulation.
I confirm that I have read this submission and believe that I have an appropriate level of expertise to confirm that it is of an acceptable scientific standard, however I have significant reservations, as outlined above.
Senn S. Reviewer Report For: Smaller clinical trials for decision making; a case study to show p-values are costly [version 2; peer review: 1 approved, 2 approved with reservations]. F1000Research 2018, 7:1176 (https://doi.org/10.5256/f1000research.16927.r37678)
Nicholas Graves, Duke NUS Graduate Medical School, Singapore
27 Sep 2018
Author Response
The authors propose that when a clinical trial is sought to inform practical decision-making, conventional standards of 'proof' may be too stringent and in consequence resources may be wasted. They
...
Continue readingThe authors propose that when a clinical trial is sought to inform practical decision-making, conventional standards of 'proof' may be too stringent and in consequence resources may be wasted. They illustrate this by simulating from a particular clinical trial, the TEXT ME trial, using progressively smaller sample sizes and suggest that a useful decision could have been made with fewer patients.
The general argument presented is interesting and the conclusion that trials are sometimes too big if practical decision making is the object may well be correct. In this respect, a key distinction was made just over 50 years ago by Schwartz and Lelouch1 between what they called explanatory or pragmatic approaches. In the former case 'proof' of the efficacy of a new treatment may be sought. In the latter case one may simply wish to choose the (plausibly) better of two treatments.
RESPONSE: Thanks for flagging this interesting paper on trials and pragmatic decision making. We certainly agree with them that, “many trials would be better approached pragmatically.” We have included this paper in the discussion section.
However, unless I have misunderstood what the authors are doing (which I do not exclude but in that case they should clarify this) the simulation is not a valid proof of what they claim, even for the example chosen.
RESPONSE: Our aim was to illustrate the principles of this approach using a case study rather than provide “proof” that this approach is always better. We have changed the title to reflect this.
The problem is the following. By simulating from the particular trial results, they are simulating from a universe in which the treatment is effective. This would be true even if the results from the TEXT ME trial had not been 'significant'. It is true of any trial in which the observed results favour the intervention. To see this consider that valid statistical analyses will typically have type I error rates in excess of a chosen nominal value if the mean under the intervention is greater (assuming high values are good) than the mean in the control group in the population in question. Provided that the type I error rate is controlled when this is not the case, this is a desirable property of such tests.
RESPONSE: We agree, although our approach includes the changes to costs from implementing the TEXT ME intervention, so the mean difference also has to also be practically significant in order to recover these costs.
Usually, the population in question is taken to be the population of all possible randomisations of the patients. Here, the authors sampled without replacement from the population. The population from which they are sampling is the population of results in the full TEXT ME trial. However, this is a population in which on average the results were better for the intervention.
RESPONSE: We sampled with replacement. Using our approach, the group means were not always greater in the intervention group. For the primary outcome of LDL cholesterol, the mean was worse in the TEXT ME sample compared with usual care for around 22% of simulations when using the smallest sample size of 100. The mean difference in the secondary outcome of systolic blood pressure was stronger in the original data, and in simulations the mean in the TEXT ME sample was always lower (better) compared with the usual care group.
Hindsight is an exact science but those making practical healthcare decisions are involved in the quite different game of foresight and they need to know whether the decision they are about to make is a reasonable one. This requires their allowing for the possibility that the intervention is useless or even harmful. Thus a mixture of possible situations has to be considered: simulating only from the case where the intervention is beneficial is not adequate.
RESPONSE: Our aim is to provide results that are useful for decision makers, including estimates of uncertainty about the decision.
In fact the precise nature of the mixture envisaged can have a huge effect on the inferences. Recently, a number of authors have called for statistical standards of evidence to be modified in the opposite direction. For instance Benjamin et al.2 have suggested that the standard of p=0.005 should be adopted. David Colquhoun3 has proposed an even more stringent standard of P=0.001. This flows from the particular approach to Bayesian hypothesis testing which places a lump of probability on no difference between treatments. (See my blog4 for a discussion.) In my opinion, these are not good suggestions for a number of reasons, including that such prior distributions are far too informative and that these authors implicitly assume, which is far from obviously the case, that the explanatory purpose of clinical trials is more important than the pragmatic one.
RESPONSE: We agree and the tension of the explanatory versus pragmatic trial is a key motivation for this paper. These adjustments to the use of the p-value remain focused on the p-value and it how can inform decisions. These adjustments have been motivated by prior abuses and misinterpretations of the p-value, which is a prosaic statistic. Our approach aims to give decision makers, working under conditions of scarce resources, more meaningful statistics regarding changes to costs and health benefits.
However, I agree entirely with the authors, that as soon as practical decision-making involving economics is involved, it is the value of information that is important. In this connection, I can recommend the work of Forster, Pertile and colleagues5,6. See also Burman et al. 7
RESPONSE: Thanks for flagging these interesting papers.
Thus, I think to make good their claim, the authors would, at the very least, need to simulate from a universe in which the intervention was not necessarily better than the control. Unless I have misunderstood, this was not the simulation they undertook.
RESPONSE: We have added just such a simulation, which shows that when there’s no treatment benefit there is a positive cost from the intervention that is not outweighed by any quality of life benefit. The cost-effectiveness plot shows clear evidence against adopting the intervention. We have added the methods and results for this new simulation and include Figure 3.
References
1. Schwartz D, Lellouch J: Explanatory and pragmatic attitudes in therapeutical trials.J Chronic Dis. 1967; 20 (8): 637-48 PubMed Abstract
2. Benjamin D, Berger J, Johannesson M, Nosek B, Wagenmakers E, Berk R, Bollen K, Brembs B, Brown L, Camerer C, Cesarini D, Chambers C, Clyde M, Cook T, De Boeck P, Dienes Z, Dreber A, Easwaran K, Efferson C, Fehr E, Fidler F, Field A, Forster M, George E, Gonzalez R, Goodman S, Green E, Green D, Greenwald A, Hadfield J, Hedges L, Held L, Hua Ho T, Hoijtink H, Hruschka D, Imai K, Imbens G, Ioannidis J, Jeon M, Jones J, Kirchler M, Laibson D, List J, Little R, Lupia A, Machery E, Maxwell S, McCarthy M, Moore D, Morgan S, Munafó M, Nakagawa S, Nyhan B, Parker T, Pericchi L, Perugini M, Rouder J, Rousseau J, Savalei V, Schönbrodt F, Sellke T, Sinclair B, Tingley D, Van Zandt T, Vazire S, Watts D, Winship C, Wolpert R, Xie Y, Young C, Zinman J, Johnson V: Redefine statistical significance. Nature Human Behaviour. 2018; 2 (1): 6-10 Publisher Full Text
3. Colquhoun D: An investigation of the false discovery rate and the misinterpretation of p-values.R Soc Open Sci. 2014; 1 (3): 140216 PubMed Abstract | Publisher Full Text
4. Senn SJ: Double Jeopardy: Judge Jeffreys upholds the law. 2015. Reference Source
5. Pertile P, Forster M, Torre D: Optimal Bayesian sequential sampling rules for the economic evaluation of health technologies. Journal of the Royal Statistical Society: Series A (Statistics in Society). 2014; 177 (2): 419-438 Publisher Full Text
6. Jobjörnsson S, Forster M, Pertile P, Burman CF: Late-stage pharmaceutical R&D and pricing policies under two-stage regulation. J Health Econ. 2016; 50: 298-311 PubMed Abstract | Publisher Full Text
7. Burman C-F: Decision Analysis in Drug Development. In: Dmitrienko A, Chuang-Stein C, Agostino R, eds. Pharmaceutical Statistics Using SAS: A Practical Guide.Cary: SAS Institute. 2007. 385-428
The authors propose that when a clinical trial is sought to inform practical decision-making, conventional standards of 'proof' may be too stringent and in consequence resources may be wasted. They illustrate this by simulating from a particular clinical trial, the TEXT ME trial, using progressively smaller sample sizes and suggest that a useful decision could have been made with fewer patients.
The general argument presented is interesting and the conclusion that trials are sometimes too big if practical decision making is the object may well be correct. In this respect, a key distinction was made just over 50 years ago by Schwartz and Lelouch1 between what they called explanatory or pragmatic approaches. In the former case 'proof' of the efficacy of a new treatment may be sought. In the latter case one may simply wish to choose the (plausibly) better of two treatments.
RESPONSE: Thanks for flagging this interesting paper on trials and pragmatic decision making. We certainly agree with them that, “many trials would be better approached pragmatically.” We have included this paper in the discussion section.
However, unless I have misunderstood what the authors are doing (which I do not exclude but in that case they should clarify this) the simulation is not a valid proof of what they claim, even for the example chosen.
RESPONSE: Our aim was to illustrate the principles of this approach using a case study rather than provide “proof” that this approach is always better. We have changed the title to reflect this.
The problem is the following. By simulating from the particular trial results, they are simulating from a universe in which the treatment is effective. This would be true even if the results from the TEXT ME trial had not been 'significant'. It is true of any trial in which the observed results favour the intervention. To see this consider that valid statistical analyses will typically have type I error rates in excess of a chosen nominal value if the mean under the intervention is greater (assuming high values are good) than the mean in the control group in the population in question. Provided that the type I error rate is controlled when this is not the case, this is a desirable property of such tests.
RESPONSE: We agree, although our approach includes the changes to costs from implementing the TEXT ME intervention, so the mean difference also has to also be practically significant in order to recover these costs.
Usually, the population in question is taken to be the population of all possible randomisations of the patients. Here, the authors sampled without replacement from the population. The population from which they are sampling is the population of results in the full TEXT ME trial. However, this is a population in which on average the results were better for the intervention.
RESPONSE: We sampled with replacement. Using our approach, the group means were not always greater in the intervention group. For the primary outcome of LDL cholesterol, the mean was worse in the TEXT ME sample compared with usual care for around 22% of simulations when using the smallest sample size of 100. The mean difference in the secondary outcome of systolic blood pressure was stronger in the original data, and in simulations the mean in the TEXT ME sample was always lower (better) compared with the usual care group.
Hindsight is an exact science but those making practical healthcare decisions are involved in the quite different game of foresight and they need to know whether the decision they are about to make is a reasonable one. This requires their allowing for the possibility that the intervention is useless or even harmful. Thus a mixture of possible situations has to be considered: simulating only from the case where the intervention is beneficial is not adequate.
RESPONSE: Our aim is to provide results that are useful for decision makers, including estimates of uncertainty about the decision.
In fact the precise nature of the mixture envisaged can have a huge effect on the inferences. Recently, a number of authors have called for statistical standards of evidence to be modified in the opposite direction. For instance Benjamin et al.2 have suggested that the standard of p=0.005 should be adopted. David Colquhoun3 has proposed an even more stringent standard of P=0.001. This flows from the particular approach to Bayesian hypothesis testing which places a lump of probability on no difference between treatments. (See my blog4 for a discussion.) In my opinion, these are not good suggestions for a number of reasons, including that such prior distributions are far too informative and that these authors implicitly assume, which is far from obviously the case, that the explanatory purpose of clinical trials is more important than the pragmatic one.
RESPONSE: We agree and the tension of the explanatory versus pragmatic trial is a key motivation for this paper. These adjustments to the use of the p-value remain focused on the p-value and it how can inform decisions. These adjustments have been motivated by prior abuses and misinterpretations of the p-value, which is a prosaic statistic. Our approach aims to give decision makers, working under conditions of scarce resources, more meaningful statistics regarding changes to costs and health benefits.
However, I agree entirely with the authors, that as soon as practical decision-making involving economics is involved, it is the value of information that is important. In this connection, I can recommend the work of Forster, Pertile and colleagues5,6. See also Burman et al. 7
RESPONSE: Thanks for flagging these interesting papers.
Thus, I think to make good their claim, the authors would, at the very least, need to simulate from a universe in which the intervention was not necessarily better than the control. Unless I have misunderstood, this was not the simulation they undertook.
RESPONSE: We have added just such a simulation, which shows that when there’s no treatment benefit there is a positive cost from the intervention that is not outweighed by any quality of life benefit. The cost-effectiveness plot shows clear evidence against adopting the intervention. We have added the methods and results for this new simulation and include Figure 3.
References
1. Schwartz D, Lellouch J: Explanatory and pragmatic attitudes in therapeutical trials.J Chronic Dis. 1967; 20 (8): 637-48 PubMed Abstract
2. Benjamin D, Berger J, Johannesson M, Nosek B, Wagenmakers E, Berk R, Bollen K, Brembs B, Brown L, Camerer C, Cesarini D, Chambers C, Clyde M, Cook T, De Boeck P, Dienes Z, Dreber A, Easwaran K, Efferson C, Fehr E, Fidler F, Field A, Forster M, George E, Gonzalez R, Goodman S, Green E, Green D, Greenwald A, Hadfield J, Hedges L, Held L, Hua Ho T, Hoijtink H, Hruschka D, Imai K, Imbens G, Ioannidis J, Jeon M, Jones J, Kirchler M, Laibson D, List J, Little R, Lupia A, Machery E, Maxwell S, McCarthy M, Moore D, Morgan S, Munafó M, Nakagawa S, Nyhan B, Parker T, Pericchi L, Perugini M, Rouder J, Rousseau J, Savalei V, Schönbrodt F, Sellke T, Sinclair B, Tingley D, Van Zandt T, Vazire S, Watts D, Winship C, Wolpert R, Xie Y, Young C, Zinman J, Johnson V: Redefine statistical significance. Nature Human Behaviour. 2018; 2 (1): 6-10 Publisher Full Text
3. Colquhoun D: An investigation of the false discovery rate and the misinterpretation of p-values.R Soc Open Sci. 2014; 1 (3): 140216 PubMed Abstract | Publisher Full Text
4. Senn SJ: Double Jeopardy: Judge Jeffreys upholds the law. 2015. Reference Source
5. Pertile P, Forster M, Torre D: Optimal Bayesian sequential sampling rules for the economic evaluation of health technologies. Journal of the Royal Statistical Society: Series A (Statistics in Society). 2014; 177 (2): 419-438 Publisher Full Text
6. Jobjörnsson S, Forster M, Pertile P, Burman CF: Late-stage pharmaceutical R&D and pricing policies under two-stage regulation. J Health Econ. 2016; 50: 298-311 PubMed Abstract | Publisher Full Text
7. Burman C-F: Decision Analysis in Drug Development. In: Dmitrienko A, Chuang-Stein C, Agostino R, eds. Pharmaceutical Statistics Using SAS: A Practical Guide.Cary: SAS Institute. 2007. 385-428
Nicholas Graves, Duke NUS Graduate Medical School, Singapore
27 Sep 2018
Author Response
The authors propose that when a clinical trial is sought to inform practical decision-making, conventional standards of 'proof' may be too stringent and in consequence resources may be wasted. They
...
Continue readingThe authors propose that when a clinical trial is sought to inform practical decision-making, conventional standards of 'proof' may be too stringent and in consequence resources may be wasted. They illustrate this by simulating from a particular clinical trial, the TEXT ME trial, using progressively smaller sample sizes and suggest that a useful decision could have been made with fewer patients.
The general argument presented is interesting and the conclusion that trials are sometimes too big if practical decision making is the object may well be correct. In this respect, a key distinction was made just over 50 years ago by Schwartz and Lelouch1 between what they called explanatory or pragmatic approaches. In the former case 'proof' of the efficacy of a new treatment may be sought. In the latter case one may simply wish to choose the (plausibly) better of two treatments.
RESPONSE: Thanks for flagging this interesting paper on trials and pragmatic decision making. We certainly agree with them that, “many trials would be better approached pragmatically.” We have included this paper in the discussion section.
However, unless I have misunderstood what the authors are doing (which I do not exclude but in that case they should clarify this) the simulation is not a valid proof of what they claim, even for the example chosen.
RESPONSE: Our aim was to illustrate the principles of this approach using a case study rather than provide “proof” that this approach is always better. We have changed the title to reflect this.
The problem is the following. By simulating from the particular trial results, they are simulating from a universe in which the treatment is effective. This would be true even if the results from the TEXT ME trial had not been 'significant'. It is true of any trial in which the observed results favour the intervention. To see this consider that valid statistical analyses will typically have type I error rates in excess of a chosen nominal value if the mean under the intervention is greater (assuming high values are good) than the mean in the control group in the population in question. Provided that the type I error rate is controlled when this is not the case, this is a desirable property of such tests.
RESPONSE: We agree, although our approach includes the changes to costs from implementing the TEXT ME intervention, so the mean difference also has to also be practically significant in order to recover these costs.
Usually, the population in question is taken to be the population of all possible randomisations of the patients. Here, the authors sampled without replacement from the population. The population from which they are sampling is the population of results in the full TEXT ME trial. However, this is a population in which on average the results were better for the intervention.
RESPONSE: We sampled with replacement. Using our approach, the group means were not always greater in the intervention group. For the primary outcome of LDL cholesterol, the mean was worse in the TEXT ME sample compared with usual care for around 22% of simulations when using the smallest sample size of 100. The mean difference in the secondary outcome of systolic blood pressure was stronger in the original data, and in simulations the mean in the TEXT ME sample was always lower (better) compared with the usual care group.
Hindsight is an exact science but those making practical healthcare decisions are involved in the quite different game of foresight and they need to know whether the decision they are about to make is a reasonable one. This requires their allowing for the possibility that the intervention is useless or even harmful. Thus a mixture of possible situations has to be considered: simulating only from the case where the intervention is beneficial is not adequate.
RESPONSE: Our aim is to provide results that are useful for decision makers, including estimates of uncertainty about the decision.
In fact the precise nature of the mixture envisaged can have a huge effect on the inferences. Recently, a number of authors have called for statistical standards of evidence to be modified in the opposite direction. For instance Benjamin et al.2 have suggested that the standard of p=0.005 should be adopted. David Colquhoun3 has proposed an even more stringent standard of P=0.001. This flows from the particular approach to Bayesian hypothesis testing which places a lump of probability on no difference between treatments. (See my blog4 for a discussion.) In my opinion, these are not good suggestions for a number of reasons, including that such prior distributions are far too informative and that these authors implicitly assume, which is far from obviously the case, that the explanatory purpose of clinical trials is more important than the pragmatic one.
RESPONSE: We agree and the tension of the explanatory versus pragmatic trial is a key motivation for this paper. These adjustments to the use of the p-value remain focused on the p-value and it how can inform decisions. These adjustments have been motivated by prior abuses and misinterpretations of the p-value, which is a prosaic statistic. Our approach aims to give decision makers, working under conditions of scarce resources, more meaningful statistics regarding changes to costs and health benefits.
However, I agree entirely with the authors, that as soon as practical decision-making involving economics is involved, it is the value of information that is important. In this connection, I can recommend the work of Forster, Pertile and colleagues5,6. See also Burman et al. 7
RESPONSE: Thanks for flagging these interesting papers.
Thus, I think to make good their claim, the authors would, at the very least, need to simulate from a universe in which the intervention was not necessarily better than the control. Unless I have misunderstood, this was not the simulation they undertook.
RESPONSE: We have added just such a simulation, which shows that when there’s no treatment benefit there is a positive cost from the intervention that is not outweighed by any quality of life benefit. The cost-effectiveness plot shows clear evidence against adopting the intervention. We have added the methods and results for this new simulation and include Figure 3.
References
1. Schwartz D, Lellouch J: Explanatory and pragmatic attitudes in therapeutical trials.J Chronic Dis. 1967; 20 (8): 637-48 PubMed Abstract
2. Benjamin D, Berger J, Johannesson M, Nosek B, Wagenmakers E, Berk R, Bollen K, Brembs B, Brown L, Camerer C, Cesarini D, Chambers C, Clyde M, Cook T, De Boeck P, Dienes Z, Dreber A, Easwaran K, Efferson C, Fehr E, Fidler F, Field A, Forster M, George E, Gonzalez R, Goodman S, Green E, Green D, Greenwald A, Hadfield J, Hedges L, Held L, Hua Ho T, Hoijtink H, Hruschka D, Imai K, Imbens G, Ioannidis J, Jeon M, Jones J, Kirchler M, Laibson D, List J, Little R, Lupia A, Machery E, Maxwell S, McCarthy M, Moore D, Morgan S, Munafó M, Nakagawa S, Nyhan B, Parker T, Pericchi L, Perugini M, Rouder J, Rousseau J, Savalei V, Schönbrodt F, Sellke T, Sinclair B, Tingley D, Van Zandt T, Vazire S, Watts D, Winship C, Wolpert R, Xie Y, Young C, Zinman J, Johnson V: Redefine statistical significance. Nature Human Behaviour. 2018; 2 (1): 6-10 Publisher Full Text
3. Colquhoun D: An investigation of the false discovery rate and the misinterpretation of p-values.R Soc Open Sci. 2014; 1 (3): 140216 PubMed Abstract | Publisher Full Text
4. Senn SJ: Double Jeopardy: Judge Jeffreys upholds the law. 2015. Reference Source
5. Pertile P, Forster M, Torre D: Optimal Bayesian sequential sampling rules for the economic evaluation of health technologies. Journal of the Royal Statistical Society: Series A (Statistics in Society). 2014; 177 (2): 419-438 Publisher Full Text
6. Jobjörnsson S, Forster M, Pertile P, Burman CF: Late-stage pharmaceutical R&D and pricing policies under two-stage regulation. J Health Econ. 2016; 50: 298-311 PubMed Abstract | Publisher Full Text
7. Burman C-F: Decision Analysis in Drug Development. In: Dmitrienko A, Chuang-Stein C, Agostino R, eds. Pharmaceutical Statistics Using SAS: A Practical Guide.Cary: SAS Institute. 2007. 385-428
The authors propose that when a clinical trial is sought to inform practical decision-making, conventional standards of 'proof' may be too stringent and in consequence resources may be wasted. They illustrate this by simulating from a particular clinical trial, the TEXT ME trial, using progressively smaller sample sizes and suggest that a useful decision could have been made with fewer patients.
The general argument presented is interesting and the conclusion that trials are sometimes too big if practical decision making is the object may well be correct. In this respect, a key distinction was made just over 50 years ago by Schwartz and Lelouch1 between what they called explanatory or pragmatic approaches. In the former case 'proof' of the efficacy of a new treatment may be sought. In the latter case one may simply wish to choose the (plausibly) better of two treatments.
RESPONSE: Thanks for flagging this interesting paper on trials and pragmatic decision making. We certainly agree with them that, “many trials would be better approached pragmatically.” We have included this paper in the discussion section.
However, unless I have misunderstood what the authors are doing (which I do not exclude but in that case they should clarify this) the simulation is not a valid proof of what they claim, even for the example chosen.
RESPONSE: Our aim was to illustrate the principles of this approach using a case study rather than provide “proof” that this approach is always better. We have changed the title to reflect this.
The problem is the following. By simulating from the particular trial results, they are simulating from a universe in which the treatment is effective. This would be true even if the results from the TEXT ME trial had not been 'significant'. It is true of any trial in which the observed results favour the intervention. To see this consider that valid statistical analyses will typically have type I error rates in excess of a chosen nominal value if the mean under the intervention is greater (assuming high values are good) than the mean in the control group in the population in question. Provided that the type I error rate is controlled when this is not the case, this is a desirable property of such tests.
RESPONSE: We agree, although our approach includes the changes to costs from implementing the TEXT ME intervention, so the mean difference also has to also be practically significant in order to recover these costs.
Usually, the population in question is taken to be the population of all possible randomisations of the patients. Here, the authors sampled without replacement from the population. The population from which they are sampling is the population of results in the full TEXT ME trial. However, this is a population in which on average the results were better for the intervention.
RESPONSE: We sampled with replacement. Using our approach, the group means were not always greater in the intervention group. For the primary outcome of LDL cholesterol, the mean was worse in the TEXT ME sample compared with usual care for around 22% of simulations when using the smallest sample size of 100. The mean difference in the secondary outcome of systolic blood pressure was stronger in the original data, and in simulations the mean in the TEXT ME sample was always lower (better) compared with the usual care group.
Hindsight is an exact science but those making practical healthcare decisions are involved in the quite different game of foresight and they need to know whether the decision they are about to make is a reasonable one. This requires their allowing for the possibility that the intervention is useless or even harmful. Thus a mixture of possible situations has to be considered: simulating only from the case where the intervention is beneficial is not adequate.
RESPONSE: Our aim is to provide results that are useful for decision makers, including estimates of uncertainty about the decision.
In fact the precise nature of the mixture envisaged can have a huge effect on the inferences. Recently, a number of authors have called for statistical standards of evidence to be modified in the opposite direction. For instance Benjamin et al.2 have suggested that the standard of p=0.005 should be adopted. David Colquhoun3 has proposed an even more stringent standard of P=0.001. This flows from the particular approach to Bayesian hypothesis testing which places a lump of probability on no difference between treatments. (See my blog4 for a discussion.) In my opinion, these are not good suggestions for a number of reasons, including that such prior distributions are far too informative and that these authors implicitly assume, which is far from obviously the case, that the explanatory purpose of clinical trials is more important than the pragmatic one.
RESPONSE: We agree and the tension of the explanatory versus pragmatic trial is a key motivation for this paper. These adjustments to the use of the p-value remain focused on the p-value and it how can inform decisions. These adjustments have been motivated by prior abuses and misinterpretations of the p-value, which is a prosaic statistic. Our approach aims to give decision makers, working under conditions of scarce resources, more meaningful statistics regarding changes to costs and health benefits.
However, I agree entirely with the authors, that as soon as practical decision-making involving economics is involved, it is the value of information that is important. In this connection, I can recommend the work of Forster, Pertile and colleagues5,6. See also Burman et al. 7
RESPONSE: Thanks for flagging these interesting papers.
Thus, I think to make good their claim, the authors would, at the very least, need to simulate from a universe in which the intervention was not necessarily better than the control. Unless I have misunderstood, this was not the simulation they undertook.
RESPONSE: We have added just such a simulation, which shows that when there’s no treatment benefit there is a positive cost from the intervention that is not outweighed by any quality of life benefit. The cost-effectiveness plot shows clear evidence against adopting the intervention. We have added the methods and results for this new simulation and include Figure 3.
References
1. Schwartz D, Lellouch J: Explanatory and pragmatic attitudes in therapeutical trials.J Chronic Dis. 1967; 20 (8): 637-48 PubMed Abstract
2. Benjamin D, Berger J, Johannesson M, Nosek B, Wagenmakers E, Berk R, Bollen K, Brembs B, Brown L, Camerer C, Cesarini D, Chambers C, Clyde M, Cook T, De Boeck P, Dienes Z, Dreber A, Easwaran K, Efferson C, Fehr E, Fidler F, Field A, Forster M, George E, Gonzalez R, Goodman S, Green E, Green D, Greenwald A, Hadfield J, Hedges L, Held L, Hua Ho T, Hoijtink H, Hruschka D, Imai K, Imbens G, Ioannidis J, Jeon M, Jones J, Kirchler M, Laibson D, List J, Little R, Lupia A, Machery E, Maxwell S, McCarthy M, Moore D, Morgan S, Munafó M, Nakagawa S, Nyhan B, Parker T, Pericchi L, Perugini M, Rouder J, Rousseau J, Savalei V, Schönbrodt F, Sellke T, Sinclair B, Tingley D, Van Zandt T, Vazire S, Watts D, Winship C, Wolpert R, Xie Y, Young C, Zinman J, Johnson V: Redefine statistical significance. Nature Human Behaviour. 2018; 2 (1): 6-10 Publisher Full Text
3. Colquhoun D: An investigation of the false discovery rate and the misinterpretation of p-values.R Soc Open Sci. 2014; 1 (3): 140216 PubMed Abstract | Publisher Full Text
4. Senn SJ: Double Jeopardy: Judge Jeffreys upholds the law. 2015. Reference Source
5. Pertile P, Forster M, Torre D: Optimal Bayesian sequential sampling rules for the economic evaluation of health technologies. Journal of the Royal Statistical Society: Series A (Statistics in Society). 2014; 177 (2): 419-438 Publisher Full Text
6. Jobjörnsson S, Forster M, Pertile P, Burman CF: Late-stage pharmaceutical R&D and pricing policies under two-stage regulation. J Health Econ. 2016; 50: 298-311 PubMed Abstract | Publisher Full Text
7. Burman C-F: Decision Analysis in Drug Development. In: Dmitrienko A, Chuang-Stein C, Agostino R, eds. Pharmaceutical Statistics Using SAS: A Practical Guide.Cary: SAS Institute. 2007. 385-428
Alongside their report, reviewers assign a status to the article:
Approved - the paper is scientifically sound in its current form and only minor, if any, improvements are suggested
Approved with reservations -
A number of small changes, sometimes more significant revisions are required to address specific details and improve the papers academic merit.
Not approved - fundamental flaws in the paper seriously undermine the findings and conclusions
Spreadsheet data files may not format correctly if your computer is using different default delimiters (symbols used to separate values into separate cells) - a spreadsheet created in one region is sometimes misinterpreted by computers in other regions. You can change the regional settings on your computer so that the spreadsheet can be interpreted correctly.
How to fix it
Save downloaded CSV file
Open spreadsheet program (e.g. Excel)
Click the ‘Data’ tab at the top
Click the ‘From text’ icon (top left)
Browse for downloaded CSV file, click ‘Import’
Ensure ‘Delimited’ radio button is selected, click ‘Next’
Check one of the appropriate delimiter checkboxes (you can visualize the formatting by looking at the data preview below these options)
Graves N, Barnett AG, Burn E and Cook D. Dataset 1 in: Smaller clinical trials for decision making; a case study to show p-values are costly. F1000Research 2018, 7:1176 (https://doi.org/10.5256/f1000research.15522.d212377)
Adjust parameters to alter display
View on desktop for interactive features
Includes Interactive Elements
View on desktop for interactive features
Competing Interests Policy
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Examples of 'Non-Financial Competing Interests'
Within the past 4 years, you have held joint grants, published or collaborated with any of the authors of the selected paper.
You have a close personal relationship (e.g. parent, spouse, sibling, or domestic partner) with any of the authors.
You are a close professional associate of any of the authors (e.g. scientific mentor, recent student).
You work at the same institute as any of the authors.
You hope/expect to benefit (e.g. favour or employment) as a result of your submission.
You are an Editor for the journal in which the article is published.
Examples of 'Financial Competing Interests'
You expect to receive, or in the past 4 years have received, any of the following from any commercial organisation that may gain financially from your submission: a salary, fees, funding, reimbursements.
You expect to receive, or in the past 4 years have received, shared grant support or other funding with any of the authors.
You hold, or are currently applying for, any patents or significant stocks/shares relating to the subject matter of the paper you are commenting on.
Stay Updated
Sign up for content alerts and receive a weekly or monthly email with all newly published articles

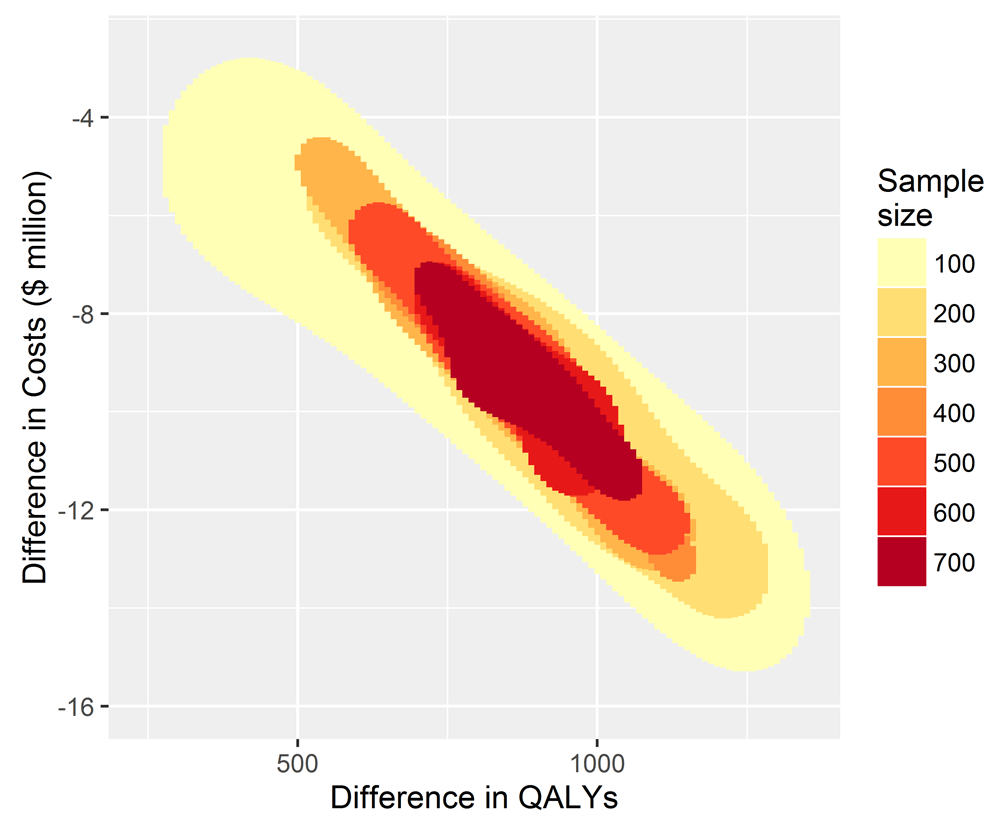
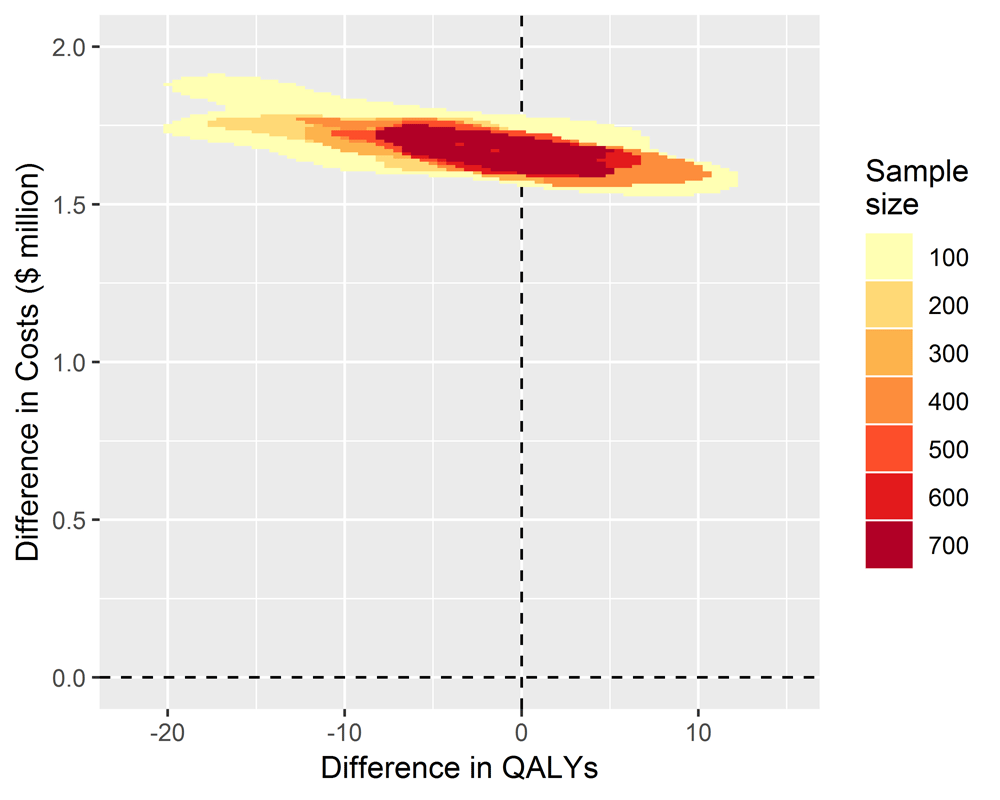
Comments on this article Comments (0)