Keywords
Bioinformatics, Cancer Proteomics, Survival Analysis, TCGA
Bioinformatics, Cancer Proteomics, Survival Analysis, TCGA
After receiving the very generous reviews, the new version of the manuscript reflects our attempts at improving the readability and flow of the manuscript. In doing so, we have tried to address the shared major concern of the reviewers in terms of grammatical and typographical errors. Additionally, as Dr. Zenklusen has suggested, we updated the description of the clinical and survival data source.
See the authors' detailed response to the review by Jean Claude Zenklusen
See the authors' detailed response to the review by Austin Gillen
Improving prognostic prediction and the identification of potential therapeutic targets is of particular interest to clinicians. Quantification of messenger RNA at a genome-wide level has proven valuable in the discovery of gene expression profiles, which can serve as biomarkers for clinical outcomes in cancer1. However, RNA quantification of tumor or patient cohorts is a proxy for protein level, with many cellular processes above transcription that ultimately regulate protein level. The availability of protein-level quantifications for the TCGA cohort allows for more relevant clinical outcome predictions compared to mRNA levels. Currently, TCGA-based applications provide entry-level analysis in correlational, differential, and survival modalities for the RPPA information. However, survival analysis in these applications rely on median- or mean-based survival data and do not allow for the use of clinical variables2–4.
With these limitations in mind, we developed a new open-source web application, TRGAted (Figure 1). Built on the R shiny framework, TRGAted is an intuitive data analysis tool for parsing survival information based on over 200 proteins in 31 cancer types. TRGAted is comprised of processed RPPA information, survival information, and code, allowing users to run instances locally or modify the code with ease.
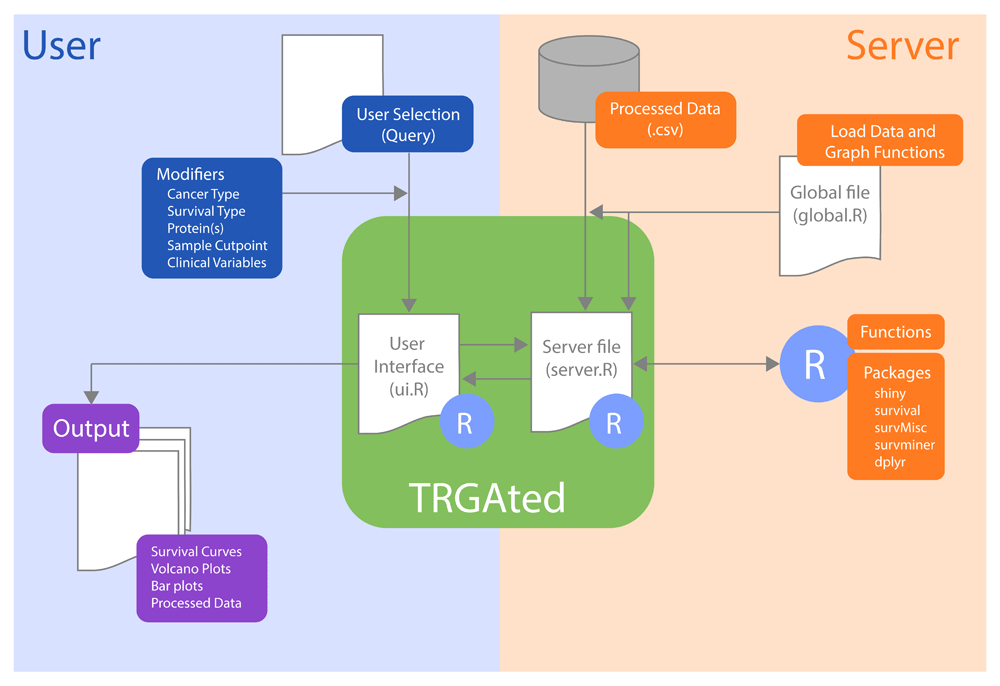
Each file communicates within the R Shiny framework. On the user side (left, blue), users select pertinent cancer type, protein of interest, and clinical variables into the CSS-enabled user interface. This information is received by the server file enabling the subsequent run in R. On the server side (right, orange), the specific cancer type from the database, R packages, and functions are retrieved and executed. After execution, the server file provides both tabular and graphical output (purple) to the user interface.
Level 4 TCGA RPPA data for each cancer type was downloaded from the TCPA Portal developed by the MD Anderson Cancer Center4. Across all proteins, individual values were scaled using Z-scores. A summary of information available for each cancer datasets is in Table 1. Additionally, uveal melanoma (UVM) was excluded from the datasets due to a low number of samples with RPPA quantification (n=12). Clinical and survival information for each cancer data set was downloaded from recent work by Liu, et al.5. Overall survival, disease-specific survival, disease-free interval, and progression-free interval information was added to primary tumor RPPA quantifications for each cancer type. Unlike other cancer types, metastatic samples were retained for skin cutaneous melanoma (SKCM) RPPA-based dataset due to the highly metastatic nature of the disease. SKCM in the TRGAted application consists of 96 primary tumor samples and 258 metastatic samples. Of the 8,167 samples available in the TCPA, overall survival (OS) data was available for 7,714 patients, disease-specific survival (DSS) data was available for 7,240 patients, disease-free interval (DFI) data was available for 3,887 patients, and progression-free interval (PFI) data was available for 7,315 patients (Table 1).
The TRGAted application was written and tested using R v3.5.1. The interactive plots are made using shiny (v1.1.0) and ggplot2 (v3.0.0). Plots can be downloaded as .png, .pdf, or .svg files. Data used to generate the individual plots can be downloaded as .csv files.
Operation: Minimum system requirements for running TRGAted locally are modest and include an Intel-compatible CPU and 1 gigabyte of RAM. Running TRGAted from the shiny server requires a modern browser and an internet connection.
Kaplan-Meier survival curves can be generated by selecting the cancer type, survival type and protein(s) of interest (Figure 2). Kaplan-Meier curves are generated using the survival (v2.41-3) and the survminer (v0.4-1) R packages. Multi-protein survival analysis utilizes mean values of protein probes, similar to gene-expression-based survival analysis platforms6. Hazard ratios for two-group comparisons, either median or optimal cut-off, utilize the Cox proportional hazards regression model in the survival R package; with the reported hazard ratio comparing high versus low protein groups. Optimal cut-off feature uses the surv_cutpoint function of the survminer package, calculating the minimal p-value based on the log-rank method. This function uses the maximally selected rank statistic (maxstat, v0.7-25) R package, which finds the maximal standardized two-sample linear rank statistic7. In order to find clinically or biologically meaningful biomarkers, the minimal proportion cutpoint, or the maximal disparity comparison, was set at 15% versus 85% of samples. Clinical variables dependent on the cancer type selected can be used to filter patients into user-defined groupings. Clinical information available across all types include: subtype, tumor stage, histological type, gender, age, response to primary therapy.
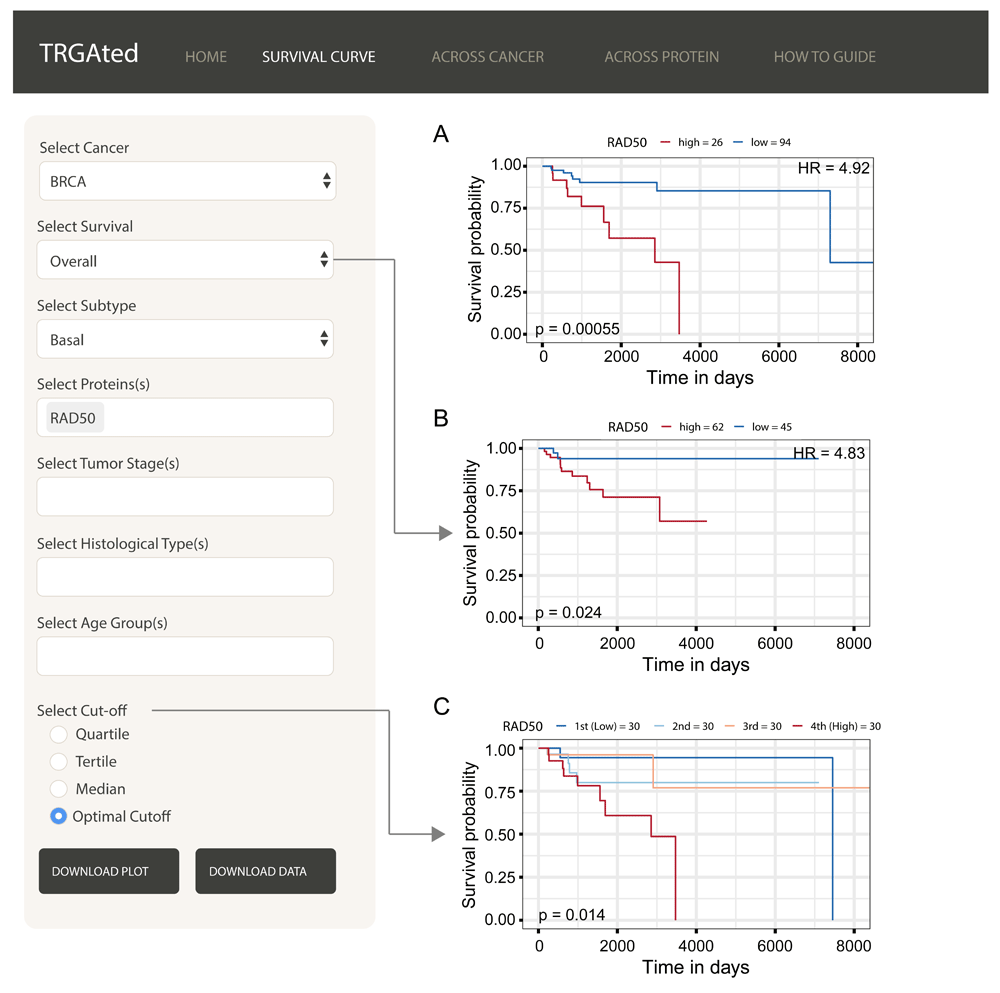
The interface shows an example of an overall survival curve for the RAD50 protein in the basal subtype of breast cancer using the optimal cutpoint (A). Disease-specific survival, disease-free interval, and progression-free interval can also be selected (B). The cutpoint can be varied to separate samples based on protein level into quartiles, tertiles, medians or separating into two groups based on the lowest p-value (C).
TRGAted also allows for Cox proportional hazard modeling across all proteins in each cancer type or for a single protein across all cancer types. Hazard ratios and p-values are based on the Cox regression model. Values filtered from the volcano plots are proteins with –log10(p-values) less than 0.1 and hazard ratios greater than 20. These filters were implemented to improve visualization and to reduce artifacts of the analysis pipeline, respectively. The volcano plot can be graphed as linear or natural-log transformed, to assist in the visualization of good prognostic indicators. Visualizing the proportional comparison for the volcano plots is also available.
In order to demonstrate the functionality of TRGAted, we present a basic survival analysis examining the aggressive, highly-metastatic subtype of breast cancer, known as basal-like breast cancer. We found in this cancer, RAD50, involved in homologous recombination of DNA, as a novel poor prognostic marker.
Survival curves: Survival curves can be generated by selecting the cancer type, survival type, and protein or proteins of interest (Figure 2A). We also selected the subtype information to more closely examine basal-like breast cancer. Other survival types and clinical variables can be selected (Figure 2B). Samples can be divided into quartiles, tertiles, median or optimally for p-values based on the protein of interest (Figure 2C). Here we can see that the DNA repair protein, RAD50 is a poor prognostic marker for overall (Figure 2A) and disease-specific survival (Figure 2B) in basal-like breast cancer.
Across cancer: TRGAted can be used for biomarker discovery by examining the hazard ratios for all proteins available by cancer type or subtype, like basal-like breast cancer (Figure 3A). The volcano plot displays good prognostic markers on the left in blue and poor prognostic markers on the right in red. Having selected the optimal cutoff feature, a bar chart can also be generated to examine the proportion of samples in the high and low protein groups (Figure 3B). Protein labeling is adaptive for both the volcano plot and bar chart and will only label significant proteins (p-value ≤ 0.05). Here we see the RAD50 is one of the most significant predictors of poor overall survival in basal-like breast cancer (Figure 3A and B).
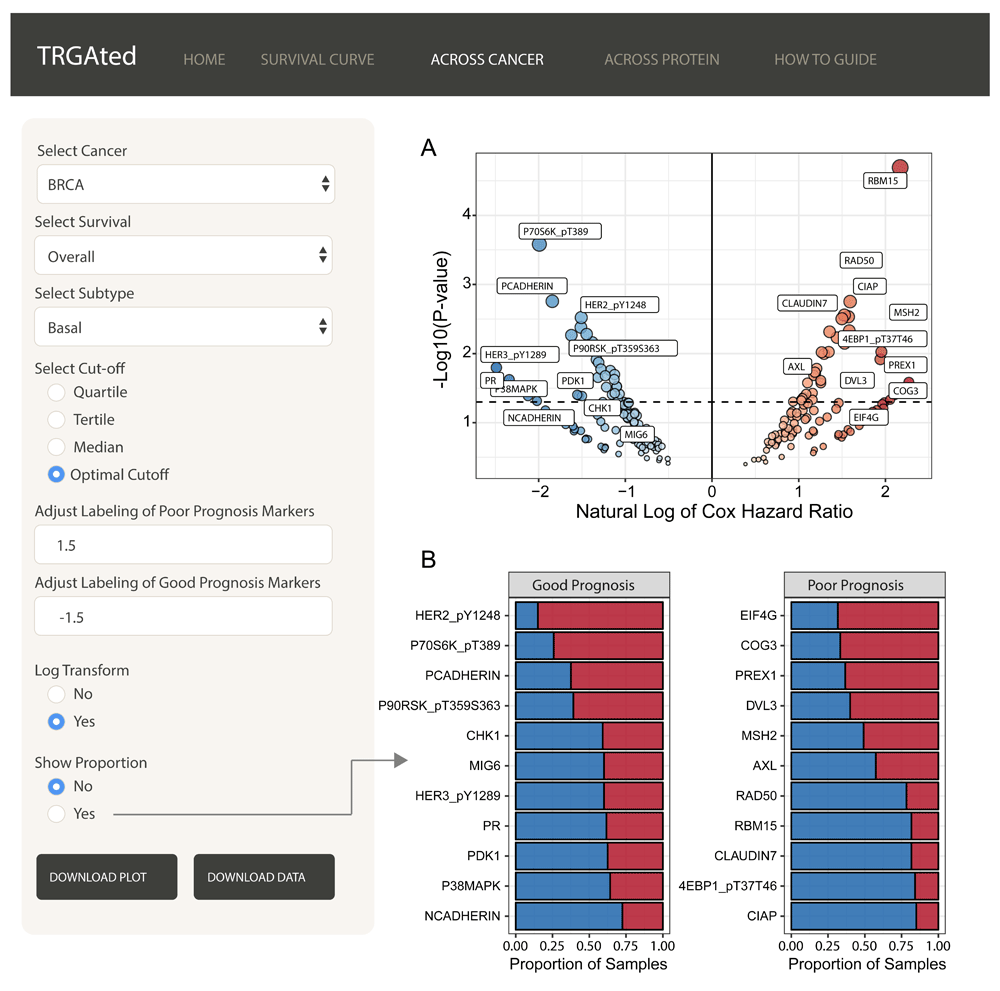
The interface shows an example of the visualization of Cox hazard ratio of each protein across the basal subtype of breast cancer (A). Good prognostic markers appear on the left in blue, while poor prognostic markers are on the right in red. The natural log transformation allows the graph to be centered at 0 and makes the visualization of good prognostic markers easier. Labeling for proteins can be adjusted to include more or less protein. Proportional comparisons for protein using the optimal cutpoint function is available as well (B).
Across protein: TRGAted can also be used to examine the survival outcomes of a protein of interest across multiple cancers. Here, RAD50 predicts poor survival in only five cancer types, prostate, adrenocortical, breast cancer, low-grade glioma, and head and neck cancers (Figure 4A). A summary of the hazard ratios can also be visualized by selecting for the barplot function (Figure 4B).
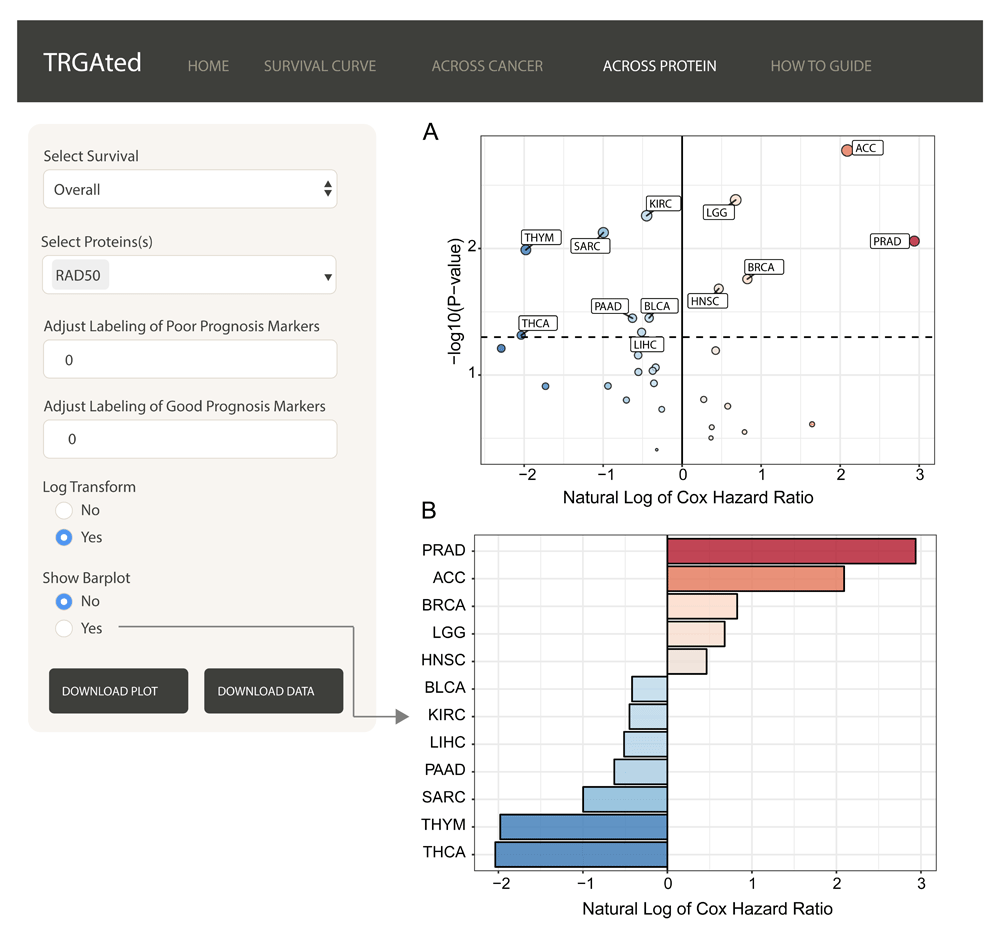
The interface shows an example of the visualization of Cox hazard ratio of for RAD50 across all 31 cancer types (A). This feature is similar to the Across Cancer tab with the ability to adjust labels and log-transform the Cox hazard ratios. Additionally, the hazard ratios for significant cancer types can be visualized using a bar chart (B).
TRGAted is an open-source survival analysis application designed to allow for quick and intuitive exploration of TCGA protein-level data. This survival analysis improves on current TCGA pipelines by providing greater diversity of clinical and survival options and relying on protein-level data. In addition to log-rank and Cox regression modeling, TRGAted allows users to download graphical displays and processed data for up to 7,714 samples across 31 cancer types. Built on the R shiny framework, a literate code architecture, the code for TRGAted is annotated and easily modified from our GitHub repository. Under the GNU General Public License v3.0, we encourage interested groups to modify TRGAted for greater usability. Downloading and modifying TRGAted is streamlined by the relatively small size of TRGAted, totally 27.2 megabytes for the application, processed data, and built-in instructional guide.
Release 4.2 of the TCGA replicate-based normalized (level 4) RPPA data is available for 32 cancer types from the TCPA Portal at http://tcpaportal.org/tcpa/download.html. Processed data is available at https://github.com/ncborcherding/TRGAted.
Source code is available from GitHub: https://github.com/ncborcherding/TRGAted/tree/v1.0.0
Archived source code at time of publication: http://doi.org/10.5281/zenodo.13238288
License: GNU General Public License v3.0
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)