Keywords
Functional dependencies, Data mining, Electronic health records, Relational database, FDTool, Rule discovery
This article is included in the Python collection.
Functional dependencies, Data mining, Electronic health records, Relational database, FDTool, Rule discovery
Functional dependencies (FDs) are key to understanding how attributes in a database schema relate to one another. An FD defines a rule constraint between two sets of attributes in a relation1 r(U), where U = {v1,v2,…,vm} is a finite set of attributes (Yao et al., 2002). A combination of attributes over a dataset is called a candidate (Yao et al., 2002). An FD X → Y asserts that the values of candidate X uniquely determine those of candidate Y (Yao et al., 2002). For example, the social security number (SSN) attribute in a dataset of public records functionally determines the first name attribute. Because the FD holds, we write {SSN} → {first_name}.
Definition 1. A functional dependency X → Y, where X,Y ⊆ U, is satisfied by r(U), if for all pairs of tuples ti, tj ∈ r(U), we have that ti [X] = tj [X] implies ti [Y] = tj [Y] (Yao & Hamilton, 2008).
In this case, X is the left-hand side of an FD, and Y is the right-hand side (Yao et al., 2002). If Y is not functionally dependent on any proper subset of X, then X → Y is minimal (Yao et al., 2002). Minimal FDs are our only concern in rule mining FDs, since all other FDs are logically implied. For instance, if we know {SSN} → {first_name}, then we can infer that {SSN, last_name} → {first_name}.
The search space for FDs can be represented as a power set lattice of nonempty attribute combinations. Figure 1 gives the nonempty attribute combinations of a relation r(U) such that U = {A,B,C,D}. There are 2n – 1 = 24 – 1 = 15 attribute subsets in the power set lattice (Yao & Hamilton, 2008). Each combination X of the attributes in U can be the left-hand side of an FD X → Y such that X → Y is satisfied by relation r(U) (Yao & Hamilton, 2008). Since the attribute set itself U trivially determines each one of its proper subsets, it can be ignored as a candidate. There remain 2n – 2 = 24 – 2 = 14 nonempty subsets of U that are to be considered candidates.
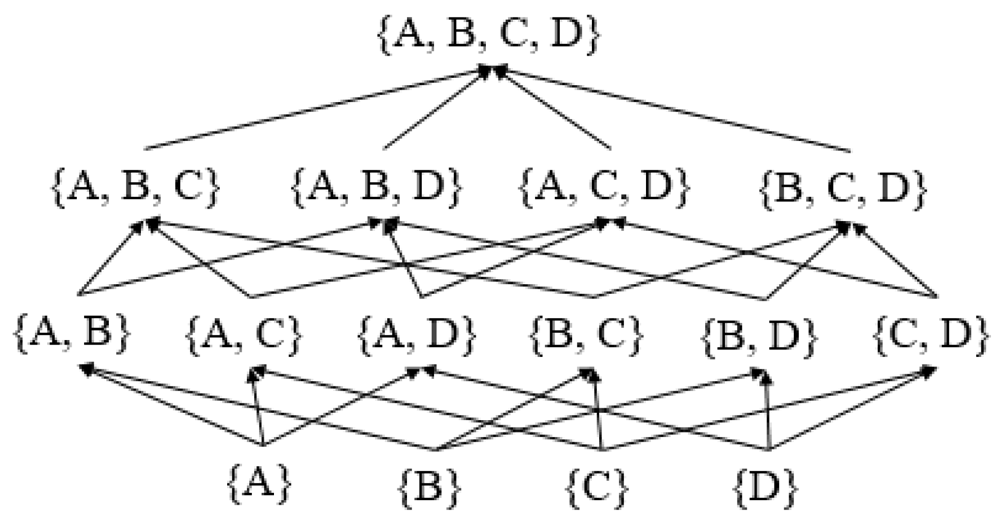
There are n · 2n–1 – n = 4 · 24–1 – 4 = 28 edges (or arrows) in the semi-lattice of the complete search space for FDs in relation r(U) (Yao & Hamilton, 2008). The size of the search space for FDs is exponentially related to the number of attributes in U. Hence, the search space for FDs increases quite significantly when there is a greater number of attributes in U. For instance, when there are 12 attributes in a relation, the search space for FDs climbs to 24,564. This gives reason to be cautious of runtime and memory costs when deploying a rule mining algorithm to discover FDs.
The algorithms used to discover FDs differ in their approach to navigating the complete search space of a relation. Their candidate pruning methods vary and sometimes the methods used to validate FDs do as well. These differences affect runtime and memory behavior when used to process tables of different dimensions.
A common data structure used to validate FDs is the partition. A partition places tuples that have the same values on an attribute into the same group (Yao et al., 2002).
Definition 2. Let X ⊆ U and let t1,…,tn be all the tuples in a relation r(U). The partition over X, denoted ∏X, is a set of the groups such that ti and tj, 1 ≤ i, j ≤ n, i 1≠ j, are in the same group if and only if ti [X] = tj [X] (Yao et al., 2002).
It follows from Definition 2 that the cardinality of the partition card(∏A(r)) is the number of groups in partition ∏A (Yao & Hamilton, 2008). The cardinality of the partition offers a quick approach to validating FDs in a dataset.
Theorem 1. An FD X → Y is satisfied by a relation r(U) if and only if card(∏X) = card(∏XY) (Huhtala et al., 1999).
Theorem 1 provides an efficient method to check whether an FD X → Y holds in a relation2. Huhtala et al. (1999) proved it to support a fast validation method for relations consisting of a large number of tuples.
Efforts in relational database theory have lead to more runtime and memory efficient methods to check the complete search space of a relation for FDs. In place of needing each arrow in a semi-lattice checked, we can infer the FDs that logically follow from those already discovered. Such FDs are to be discovered as a consequence of Armstrong’s Axioms (Maier, 1983) and the inference axioms derivable from them (Ramakrishnan & Gehrke, 2000), which are
– Reflexivity: Y ⊆ X implies X → Y;
– Augmentation: X → Y implies XZ → YZ;
– Transitivity: X → Y and Y → Z imply X → Z;
– Union: X → Y and X → Z imply X → YZ;
– Decomposition: X → YZ implies that X → Y and X → Z.
These axioms signal the distinction between FDs that can be inferred from already discovered FDs and those that cannot (Maier, 1983). Exploiting what can be derived from Armstrong’s Axioms allows us to avoid having to check many of the candidates in a search space.
Definition 3. Let F be a set of functional dependencies over a dataset D and X be a candidate over D. The closure of candidate X with respect to F, denoted X+, is defined as {Y | X → Y can be deduced from F by Armstrong’s Axioms} (Yao & Hamilton, 2008).
The nontrivial closure3 of candidate X with respect to F is defined as X* = X+ \ X and written X* (Yao & Hamilton, 2008). Definition 3 gives room to elegantly define keys. Informally, a key implies that a relation does not have two distinct tuples with the same values on those attributes. Keys uniquely identify all tuple records.
Definition 4. Let R be a relational schema and X be a candidate of R over a dataset D. If X ∪ X* = R, then X is a key (Yao et al., 2002).
A candidate key X of a relation is a minimal key for that relation. This means that there is no proper subset of X for which Definition 4 holds.
Existing functional dependency algorithms are split between three categories: Difference- and agree-set algorithms (e.g., Dep-Miner, FastFDs), Dependency induction algorithms (e.g., FDEP), and Lattice traversal algorithms (e.g., TANE, FUN, FD_Mine, DFD) (Papenbrock et al., 2015).
Difference- and agree-set algorithms model the search space of a relation as the cross product of all tuple records (Papenbrock et al., 2015). They search for sets of attributes agreeing on the values of certain tuple pairs. Attribute sets only functionally determine other attribute sets whose tuple pairs agree, i.e., agree-sets (Asghar & Ghenai, 2015; Papenbrock et al., 2015). Then, agree-sets are used to derive all minimal FDs.
Dependency induction algorithms assume a base set of FDs in which each attribute functionally determines each other attribute (Papenbrock et al., 2015). While iterating through row data, observations are made that require certain FDs to be removed from the base set and others added to it. These observations are made by comparing tuple pairs based on the equality of their projections. After each record in a dataset is compared, the FDs left in the base set are considered valid, minimal and complete (Papenbrock et al., 2015).
Lattice traversal algorithms model the search space of a relation as a power set lattice. Most of such algorithms, (i.e., TANE, FUN, FD_Mine) use a level-wise approach to traversing the search space of a relation from the bottom-up (Papenbrock et al., 2015). They start by checking4 for FDs that are singleton sets on the left-hand side and iteratively transition to candidates of greater cardinality.
Papenbrock et al. (2015) released an experimental comparison of the aforementioned FD discovery algorithms. The seven algorithms were re-implemented in Java based on their original publications and applied to 17 datasets of various dimensions. They found that none of the algorithms are suited to yield the complete result set of FDs from a dataset consisting of 100 columns and 1 million rows (Papenbrock et al., 2015). Hence, it is a matter of discretion to choose the algorithm best fitting the dimensions of a dataset.
The experimental results show that lattice traversal algorithms are the least memory efficient, since each k-level5 can be a factor greater than the size of the previous level (Papenbrock et al., 2015). Difference- and agree-set algorithms and dependency induction algorithms perform favorably in memory experiments as a result of their operating directly on data and efficiently storing result sets. Lattice traversal algorithms scale poorly on tables with many columns (≥ 14 columns) due to memory limits (Papenbrock et al., 2015).
Lattice traversal algorithms are the most effective on datasets with many rows, because their validation method6 operates on attribute sets as opposed to data (Papenbrock et al., 2015). This puts such algorithms in a special position to rule mine clinical and demographic record datasets, which often consist of long and narrow sets of participant records. Difference- and agree-set algorithms and dependency induction algorithms commonly reach time limits when applied to datasets of these dimensions (> 100,000 rows) (Papenbrock et al., 2015).
Lattice traversal algorithms iterate through k-levels represented in a power set lattice. If the lattice is traversed from the bottom-up, we say the algorithm is level-wise.
Definition 5. Let X1, X2,…, Xk, Xk+1 be (k + 1) attributes over a database D. If X1X2… Xk → Xk+1 is an FD with k attributes on its left hand side, then it is called a k-level FD (Yao et al., 2002).
The search space for FDs is reduced at the end of each iteration using pruning rules. Pruning rules check the validity of candidates not yet checked with FDs already discovered and those inferred from Armstrong’s Axioms (Yao & Hamilton, 2008). After a search space is pruned, an Apriori_Gen principle generates k-level candidates with the (k – 1)-level candidates that were not pruned (Yao & Hamilton, 2008).
Apriori_Gen:
– oneUp: generates all possible candidates in Ck from those in Ck–1.
– oneDown: generates all possible candidates in Ck–1 from those in Ck.
Level-wise lattice traversal algorithms stop iterating after all candidates in a search space are pruned. In this case, Apriori_Gen generates the null set ∅ raising a flag for the algorithm to terminate. This has the effect of shortening runtime to the degree that FDs are discovered and others are inferred.
The level-wise lattice traversal algorithms TANE, FUN, and FD_Mine differ in terms of pruning rules. FUN and FD_Mine expand on the pruning rules of TANE. Released by Huhtala et al. (1999), TANE prunes a search space on the basis that only minimal and non-trivial7 FDs need be checked. TANE restricts the right-hand side candidates C+ for each attribute combination X to the set
which contains all the attributes that the set X may still functionally determine (Papenbrock et al., 2015). The set C+ is used in the following pruning rules (Papenbrock et al., 2015).
• Minimality pruning: If an FD X \ A → A holds, A and all B ∈ C+ (X) \ X can be removed from C+ (X).
• Right-hand side pruning: If C+ (X) = ∅, the attribute combination X can be pruned from the lattice, as there are no more right-hand side candidates for a minimal FD.
• Key pruning: If the attribute combination X is a key, it can be pruned from the lattice.
Key pruning implies that all supersets of a key, i.e., super keys, can be removed, since they are by definition non-minimal (Huhtala et al., 1999).
Like TANE and FUN, FD_Mine is structured around the level-wise lattice traversal approach and the aforemented pruning rules. Unlike the other two algorithms, FD_Mine, authored by Yao et al. (2002), uses the concept of equivalence as means to more exhaustively prune the search space of a candidate (Papenbrock et al., 2015). Informally, attribute sets are equivalent if and only if they are functionally dependent on each other (Papenbrock et al., 2015).
The proofs demonstrating that no useful information is lost in pruning candidates from equivalent attribute sets are reproduced in this section and were originally developed by Yao & Hamilton (2008). The equivalence pruning method can be derived directly from Armstrong’s Axioms.
Definition 6. Let X and Y be candidates over a dataset D. If X → Y and Y → X hold, then we say that X and Y are an equivalence and denote it as X ↔ Y.
After a k-level is fully validated, i.e., each k-level candidate is checked, FD_Mine determines equivalent attribute sets with the FDs already discovered.
Theorem 2. Let X, Y ⊆ U. If Y ⊆ X+ and X ⊆ Y+, then X ↔ Y (Yao & Hamilton, 2008).
Proof. Since X → X+ and Y ⊆ X+, Decomposition implies that X → Y. By a similar argument, Y → X holds. Because X → Y and Y → X, we have by definition that X ↔ Y holds.
Lemma 3 and Lemma 4 are derived from Armstrong’s Axioms with the assumption of the equivalence X ↔ Y.
Lemma 3. Let W,X,Y,Y',Z ⊆ U and Y ⊆ Y'. If X ↔ Y and XW → Z, then Y'W → Z (Yao & Hamilton, 2008).
Proof. Suppose that X ↔ Y and XW → Z. This implies that X → Y. By Augmentation, YW → XW. By Transitivity, YW → XW and XW → Z give that YW → Z. By Augmentation, Y' \ Y can be added to both sides of YW → Z to give that YW(Y' \ Y) → Z(Y' \ Y). By Y ⊂ Y', we know that Y'W → Z(Y' \ Y). Then, by Decomposition, Y'W → Z.
Lemma 4. Let W,X,Y,Z ⊆ U. If X ↔ Y and WZ → X, then WZ → Y (Yao & Hamilton, 2008).
Proof. By X ↔ Y, we know that X → Y. By Transitivity, WZ → X and X → Y imply WZ → Y.
Theorem 2 checks attribute sets X and Y for the equivalence X ↔ Y. FD_Mine assumes that the attribute set Y is generated before X. By Lemma 3 and Lemma 4, we know that for equivalence X ↔ Y, no further attribute sets Z such that Y ⊆ Z need be checked (Yao & Hamilton, 2008). Hence, Y is deleted as a result of the following pruning rule.
• Equivalence pruning: If X ↔ Y is satisfied by relation r(U), then candidate Y can be deleted. (Yao & Hamilton, 2008).
Exploiting the equivalence pruning method leaves FD_Mine in a more aggressive position to prune candidates than TANE. This offers an advantage in terms of runtime and memory behavior (Yao et al., 2002).
The pseudo-code proposed in the second version of FD_Mine (Yao & Hamilton, 2008) will under certain circumstances output non-minimal FDs (Papenbrock et al., 2015). FD_Mine references an Apriori_Gen method (Agrawal et al., 1996) stating that for each pair of candidates p, q ∈ Ck–1 the set p ∪ q is to be placed in Ck if card(p ∪ q) = k. Example 1 shows that the Apriori_Gen method referenced and utilized by FD_Mine can violate minimality pruning by checking supersets that need not be checked. Figure 2 gives the power set lattice of the relation described in Example 1 pruned by FD_Mine.
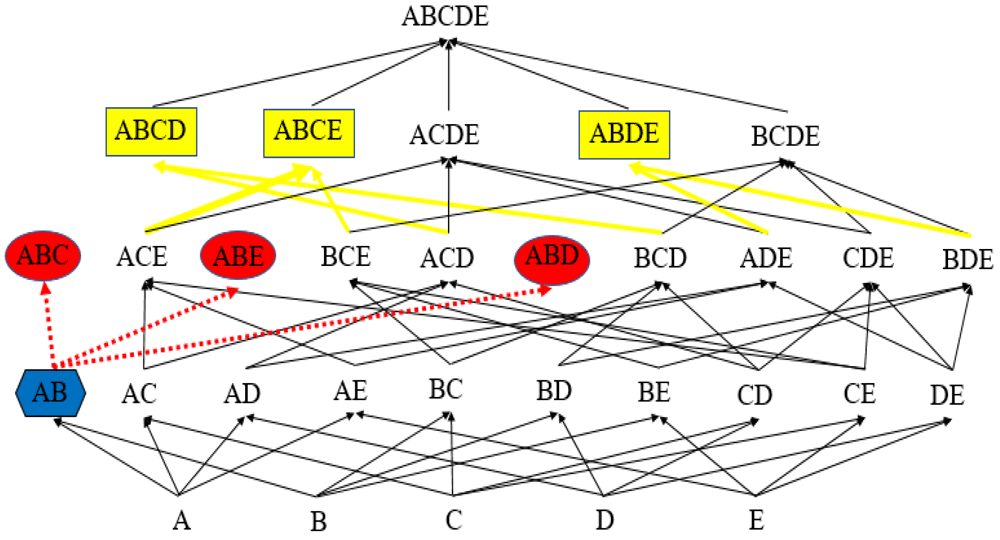
FD_Mine deletes the candidates ABC, ABE, and ABD (red ovals) as a result of finding the candidate key AB (blue hexagon). It generates supersets of AB (yellow rectangles) at the next level.
Example 1. Let r(U) be a relation such that U = {A,B,C,D,E}. Suppose that AB is a key and that there are no other FDs in r(U). Since AB is a key, we know by definition that AB ∪ AB* = U. Provided this and that there are no other FDs in r(U), the candidates ABC, ABD and ABE are deleted from C3, and so C3 = Prune(Apriori_Gen(C2)) = {ACE, BCE, ACD, BCD, ADE, CDE, BDE}8. Then, C4 = {ABCD, ABCE, ACDE, ABDE, BCDE}. Because it must be that AB* = {C, D, E}, the algorithm validates the FDs ABCD → E, ABCE → D, and ABDE → C. Since E, for example, is functionally dependent on the proper subset AB ⊆ ABCD, ABCD → E is non-minimal.
The Apriori_Gen principle presented in TANE (Huhtala et al., 1999) more effectively generates candidate level Ck+1 from Ck. It requires that Ck+1 only contains the attribute sets of size k + 1 which have all their subsets of size k in Ck (Huhtala et al., 1999); i.e.,
In reference to Example 1, this method does not insert the candidate ABCD in C4, without loss of generality, because ABC ⊆ ABCD but ABC ∉ C3. Thus, the non-minimal FD ABCD → E is not checked.
FD_Mine will under the circumstance described in Example 1 set closure values incorrectly. In line 2, FD_Mine iterates through Ck–1, as opposed to oneDown [Ck], which can cause the Prune() function to ignore setting the closure values of certain candidates. In Example 1, FD_Mine does not accurately set the closure ABCD* to E, since E is not saved to the closure values of the candidates ACD, BCD ⊆ ABCD at the previous level. Iterating through oneDown [Ck] sets the closure of a candidate to the union of the closure values of its proper subsets, so that the closure values of deleted candidates are not lost among their supersets.
Properly assigned closure values can allow the algorithm to avoid checking many non-minimal FDs. This is because the ObtainFDs module, i.e., the validation method, only checks12 the right-hand side attributes vi for which vi ∈ U \ X+ (Yao & Hamilton, 2008). Hence, provided that Pruning rule 3 asserts the equality ABCD* = E, ABCD → E need not be checked.
FDTool (Buranosky, 2018) is a command line Python application executed with the following statement: $ fdtool /path/to/file13. For Windows users, this is to be run from the directory in which the executable fdtool.exe resides, which will likely be C:\Python27\Scripts for those installing with pip install fdtool. For other systems, installation automatically inserts the file path to the fdtool command in the PATH variable. /path/to/file is the absolute or relative path to a .txt, .csv, or .pkl file containing a tabular dataset. If the data file has the extension .txt or .csv, FDTool detects the following separators: comma (‘,’), bar (‘|’), semicolon (‘;’), colon (‘:’), and tilde (‘∼’). The data is read in as a Pandas data frame14.
Dependencies:
1. Python2 (https://www.python.org/), recommended version 2.7.8 or later.
2. Pandas data analysis library (https://pandas.pydata.org/) via: pip install pandas.
FDTool provides the user with the minimal FDs, equivalent attribute sets and candidate keys mined from a dataset. This is given with the time (s) it takes for the code to terminate (after reading in data), the row count and attribute count of the data, the number of FDs and equivalent attribute sets found, and the number of FDs checked. This is printed on the terminal after the code is executed as shown in Figure 3. The information is saved to a .FD_Info.txt file.
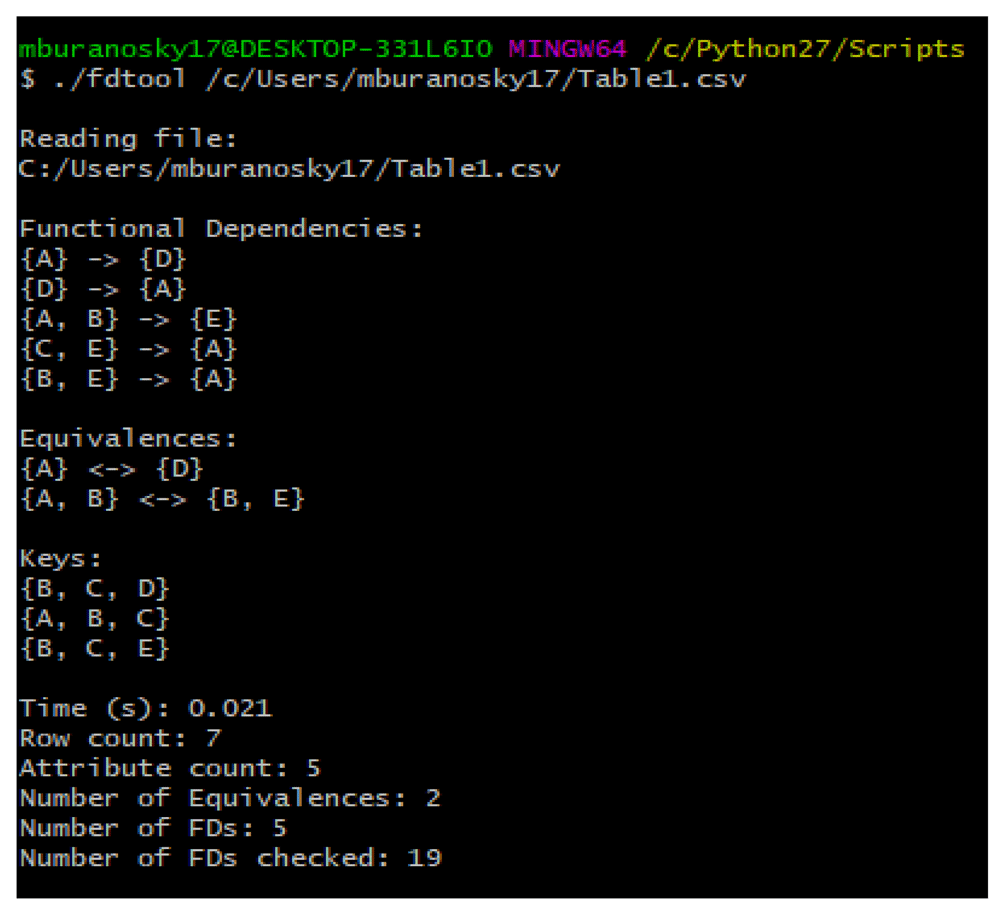
Figure 3 shows the printed output of FDTool.exe applied to the contents of Table 1. The output file Table1. FD_Info.txt is saved to the directory from which the executable is run.
FDTool is a Python based re-implementation of the FD_Mine algorithm with additional features added to automate typical processes in database architecture. FD_Mine was published in two papers with more detail given to the scientific concepts used in algorithms of its kind (Yao et al., 2002; Yao & Hamilton, 2008). The two versions of FD_Mine were released with different structures but make use of the same theoretical foundation (Papenbrock et al., 2015), which is fully supported in mathematical proofs of the pruning rules used (Yao & Hamilton, 2008). FDTool was coded15 with special attention given to the pseudo-code presented in the second version of FD_Mine (Yao & Hamilton, 2008).
The Python script dbschema.py in FDTool/fdtool/modules/dbschema is taken from dbschemacmd (https://www.elstel.org/database/dbschemacmd.html.en): a tool for database schema normalization working on functional dependencies (Elmasri & Navathe, 2011). It is used to take sets of FDs and infer candidate keys from them. The operation first assigns the left-hand side attribute combinations of a set of FDs to dictionary keys and their closures to the corresponding values. It then reduces the set of FDs to a minimum coverage16. Candidate keys are assembled using the minimum coverage and closure structure by adding attributes to key candidates until each minimal attribute set X for which X+ = U is found. Details on the dbschema operations are described in FDTool/fdtool/modules/dbschema/Docs.
FDTool was initially created to help decompose datasets of medical records as part of Clinical Archived Records research for Environmental Studies (CARES). CARES currently contains 12 datasets obtained from the medical software firms Epic and Legacy. The attribute count in this database ranges from 4 to 18; the row count ranges from 42,369 to 8,201,636.
To limit the strain on computational resources, FDTool has a built in time limit of 4 hours. FDTool reaches this preset limit (triggering program termination) when applied to the PatientDemographics dataset (42369 rows × 18 columns) and the EpicVitals_TobaccoAlcOnly dataset (896962 rows × 18 columns). The remaining 10 CARES datasets are given in Table 217.
The results from Table 2 show that runtime is primarily determined by the number of attributes in a dataset. For instance, the LegacyPayors dataset (1465233 rows × 4 columns) has slightly more rows (13% increase) but far fewer attributes (60% decrease) as compared to the AllLabs dataset (1294106 rows × 10 columns). The runtime of LegacyPayers (9.4 s.) is much less than that of AllLabs (999.8 s.), because AllLabs has many more arrows in its powerset lattice,
than does LegacyPayers (28). Hence, FDTool has more FDs to check when applied to AllLabs. It is clear that the attribute count of a dataset has a much greater effect on the runtime of FDTool than does row count.
Many of the arrows in the powerset lattice of a candidate are pruned by FDTool. AllLabs has 5110 arrows in its powerset lattice. However, FDTool only checks 818 FDs, as there are many inferred from the 43 FDs found. This follows from the Prune() function, which deletes many of the candidates to check partially as a result of mining 4 equivalent attribute sets. FDTool terminates after 5 k-levels when applied to AllLabs.
We want to improve its performance so that FDTool is better equipped to handle datasets of different dimensions. Using the dependency induction algorithm FDEP, the reach of FDTool could be extended to datasets with fewer rows and more than 100 columns (Papenbrock et al., 2015). This might also require upgrading the source code with multicore processing methods, such as a Java API, to reduce runtime and avoid reaching memory limits. A formal proof of the the dbschema operations is also desired.
Another goal is to increase the functionality provided by FDTool. This would mean implementing the pen and paper methods typically used to normalize relational schema and decompose tables. Our intent is to incorporate these changes in newer versions of FDTool, released at regular periods, so as to develop it as Python software that could automate much of what is done in the database design process.
While the authors fully support the open dissemination of data for verification and replication purposes, CARES data cannot be released as it contains Protected Health Information. However, the CARES data is accessible to any researcher who has an approved IRB and submits a data request to the Carolina Data Warehouse for Health (https://tracs.unc.edu/index.php/services/informatics-and-data-science/cdwh; use the “Submit a CDW-H Project Data Request” link). The authors will be happy to send the CARES data exactly as utilized in this manuscript to any researcher with an approved request from the Carolina Data Warehouse for Health.
FDTool is available from the Python Package Index: https://pypi.org/project/fdtool/
Latest source code: https://github.com/USEPA/FDTool.git
Source code at time of publication: https://zenodo.org/record/1442843
License: CC0 1.0 Universal. Module FDTool/fdtool/modules/dbschema released under a modified C-FSL license.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)