Keywords
Computer assisted qualitative data analysis software, Microsoft Word, comments, coding, thematic analysis, code hierarchy tree
Computer assisted qualitative data analysis software, Microsoft Word, comments, coding, thematic analysis, code hierarchy tree
Updates in the software:
- Many tweaks in analysis code to improve the software performance on large datasets.
- We added visualization tools: Code Co-Occurrence Matrix and File Code Matrix.
- We added search and move features in the code hierarchy.
- We added capability to drag and drop codes from the code list or code hierarchy into other software.
Updates in the manuscript:
- We added a few citations to make the introduction more recent and more convincing.
- We amended new features illustration to Use case 1 (with two additional Figures)
- We amended a distinct use case for performance of software on a large dataset of Persian/Arabic text.
- We amended a Table and discussion about comparison of the WordCommentsAnalyzer capabilities with other QDA tools.
- We revised the conclusion so that it better summarizes the points made in the article.
See the authors' detailed response to the review by Ronggui Huang
See the authors' detailed response to the review by Yazdan Mansourian
Commercial qualitative data analysis (QDA) software tools such as NVivo, MAXQDA and Atlas.ti seem to be the most popular in the qualitative research community1,2, especially in health research. For example, a study found that 763 published articles in the Scopus database (between 1994 and 2013) used Atlas.ti and NVivo in their work, and that the majority of these studies were published in health sciences journals3. However, learning to use these complex software tools may be inconvenient for some researchers. In fact, research has shown that learners of complex qualitative tools often struggle with confusions, frustrations, and feelings of inadequacy4. Moreover, using complex QDA software may create a feeling for the researcher that they are forced to work within the software structures5. Besides, the purchase of commercial QDA software may not be affordable for some researchers. On the other hand, free or open-source solutions that are available often do not provide a smooth editing and markup experience (e.g., QDA Miner Lite does not support Persian and Arabic languages; CATMA and CAT6 are not fast due to their web-based nature). For these reasons, some researchers use professional word-processing programs for their qualitative research projects.
The use of Microsoft Word for QDA is commonly documented7,8. Using Word comments provides a straightforward way to annotate specific portions of the text and attach keywords or categories (codes) to them. However, as the amount of data grows, organizing codes in Word comments becomes an exhausting task.
In this article, we present WordCommentsAnalyzer, a free, open-source tool that allows qualitative researchers to automate organization of the qualitative codes through a fast and easy-to-learn graphical user interface (GUI) while coding the textual material using Microsoft Word as professional, familiar word-processing software.
This software is written in C# programming language using .NET Framework 4.5.2. The software also makes use of OpenXml library to extract comments from Word documents. Recent versions of Word store documents in XML format. OpenXml provides an easy way to query comments from a document. To facilitate assigning multiple codes to a piece of text, we assume a simple convention: different codes are entered in a comment with line breaks between them (as the descendant paragraphs of the comment element). The software uses a relational model approach to store the extracted codes and uses language integrated queries to collect different text portions related to each code, to calculate the code frequencies and to sort the codes by frequency. The main visual interface of the program consists of three side-by-side panels (Figure 1). The left panel shows the codes in the comments with their counts, the middle one provides a code tree that the user can intuitively organize their codes in and the right panel shows the data extracts pertaining to each code. In the left panel, the code list can be filtered to find specific codes. The user can place codes in the code hierarchy simply by using drag-and-drop. The tree also allows for moving codes in the hierarchy if needed. The user can introduce a new parent code or a code that is of a higher level of abstraction. Additionally, the codes are changed or combined by being wrapped in new codes. The code hierarchy tree is saved as a tab-indented text file in the data folder (codehierarchy.txt). The tree is auto-saved every minute and can also be manually saved by clicking Save button. The previous tree files are backed up in a subfolder of the data folder. When a collection of codes develops after coding several documents, the user can drag and drop the codes into the word-processing software to avoid memorizing them. In addition to organization tools available in the GUI, the software offers two visualization tools: Code Co-Occurrence Matrix visualizes the number of co-occurrences of sets of two codes in the data and File Code Matrix visualizes the number of occurrences of each code per Word document.

The left panel shows the codes in the comments with their counts, the middle panel provides a code tree for intuitive organization of the codes and the right panel shows the data extracts pertaining to each code (or to children of a parent code). The code list in the left panel can be filtered to find specific codes. The user can place codes in the code hierarchy simply by using drag-and-drop. The tree also enables the user to move codes in the hierarchy if needed. The user can introduce a new parent code. The codes are changed or combined by being wrapped in new codes.
The requirements for this software are Windows 7 or later and .NET Framework 4.5.2. After installing the .NET Framework, the user can unzip the latest release package from the GitHub link and run the “WordCommentsAnalyzer.exe” executable file. The program supports XML Word documents (using the .docx extension). Older Word documents (using the .doc extension) can be easily converted to XML documents by Word 2003 or later (there are also resources available on the web to batch-convert older Word documents). The program allows multiple Word files to be analyzed. This feature can be utilized to separate transcripts of different interview or focus group sessions into different files.
To illustrate how to use the software, we first present a mini-study of Twitter’s Tweets from 17 January 2017 to 10 April 2018. The Tweets with the #successfulaging hashtag were copied into two Word documents based on the year in which the Tweets were posted (Supplementary File 1). We reviewed the Tweets and added comments (line-break-separated codes) to portions of texts containing interesting notions related to successful aging. Two examples of these text portions are reproduced in Figure 2.
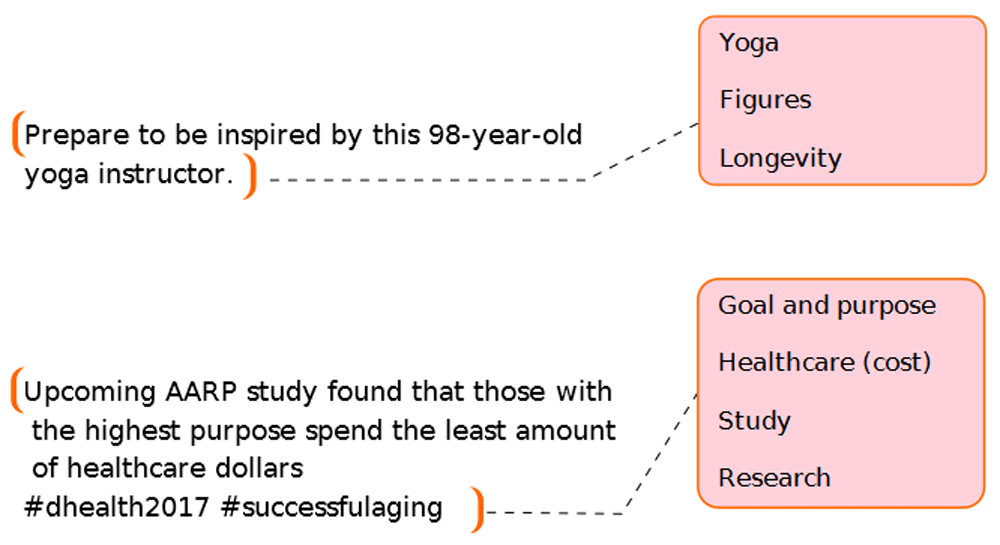
The codes describe notable topics concerning the text samples.
After adding comments to Word documents, we run WordCommentsAnalyzer, select the folder containing the Word documents and click Analyze. The program analyzes the comments and shows a list of codes with their counts in the left panel. The middle panel enables us to organize the codes by placing them in a code hierarchy (Figure 3). For example, we can find several codes related to health by filtering the code list by the word of “health”. Then we add the code of “Health”, which is a parent code, to the hierarchy by dragging and dropping it onto the root node (“Code Hierarchy”) or the empty area. The codes of “Brain health”, “Physical health”, and “Health care” can then be drag-and-dropped onto the node of “Health”. Likewise, “Oral health” is inserted into “Physical health”. When organizing the codes, we could check the right panel to assure the data extracts support the codes. Also, the codes inserted into the hierarchy will be highlighted in the code list to help keep track of the organized codes.
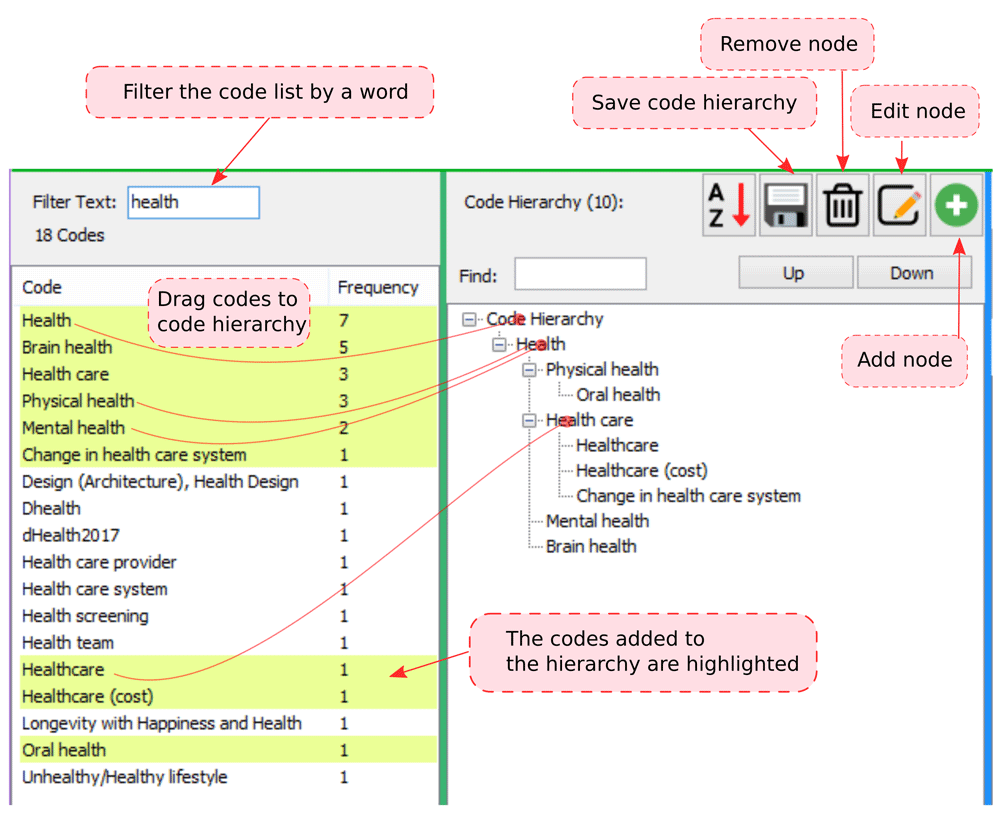
The user can find specific codes by filtering the code list (e.g., by the word of “health”) and organize the codes (from the left panel) by dragging and dropping them into the code hierarchy tree (the right panel).
As the number of codes in the code hierarchy increases, moving or reorganizing codes becomes cumbersome, particularly when the user intends to move a code to another distant code or find specific codes in the deeper branches of the hierarchy. The software offers two features for smooth reorganization of codes: search specific words in the hierarchy and move codes through a pop-up window (Figure 4). Consider we want to review all the codes containing “retirement” in the Tweets data. We type a portion of this word (“retire”); by looping through the results (clicking Down), we realize that the “Retirement communities” is currently a child node of the “Communities”. Thinking that this node better suits the “Retirement” node, we can right-click it and select Move Retirement communities, then search for the “Retirement” node in the pop-up window, and move the “Retirement communities” to its appropriate place.

WordCommentsAnalyzer facilitates finding and moving specific codes by two features: 1) the user can search particular words in the hierarchy; 2) the user can move codes to other codes that are not visible in the current view by means of a pop-up window.
Figure 5 presents a formatted version of codehierarchy.txt (Supplementary File 2) when we organized the Tweet codes with at least two counts. As shown in this figure, the themes of health, retirement, happiness and being active represent the richest themes in the Tweets of #successful aging.

When we organized the Tweet codes with at least two counts. The large branches of the code tree can help the researcher identify the richest themes in the data. Thus, themes of health, retirement, happiness, and being active are probably the major themes in the Tweets with the hashtag #successfulaging.
WordCommentsAnalyzer also allows for getting basic visual representation of the data. By clicking Visualize, a new window with two tabs appears. In Code Co-Occurrences Matrix tab, we see two identical instances of the codes lists. By checking codes in these lists, the software builds a co-occurrence matrix with the checked codes in the lists as the columns and rows. The numbers in the matrix cells show the number of text segments that share the corresponding pair of codes and the cells’ color intensities are associated with the c-coefficients9. Creating the co-occurrence matrix for the Tweets data, allows inferring some thematic proximity between the codes with high co-occurrence. For instance, that the codes of “Longevity” and “Figures” have relatively high co-occurrence shows the Tweets’ tendency to present model figures as very aged (see Figure 6a). Also, the high co-occurrence between “Marketing” and “How to” may indicate that the Tweeters often use “How to” phrases for marketing purposes.

Basic visualization features of WordCommentsAnalyzer: Code Co-Occurrences Matrix (a) and File Code Matrix (b). WordCommentAnalyzer offers two visualization tools. Code Co-Occurrence Matrix enables the researcher to recognize patterns of codes co-occurrence in the data. The numbers in the co-occurrences matrix are counts of text segments that share the corresponding pair of codes and colors of the cells reflect c-coefficients9. High co-occurrence suggests thematic proximity between a pair of codes. For instance, in the co-occurrence matrix generated by the software for the Tweets data (a), there is a high co-occurrence between the “Longevity” and “Figures” codes, which shows that the Tweets tend to present model figures as very aged. File Code Matrix assists the researcher in inspecting the various data parts (e.g., different interview or focus group sessions) in terms of the codes or themes they contain. For example, this figure (b) demonstrates that while the coder(s) coded more Tweets with “Longevity” than they coded with “Brain health” in the 2017 document, this pattern was reversed in the 2018 document.
In the File Code Matrix tab, we can generate a matrix of the number of paragraphs with a certain code in each document. For example, the matrix in Figure 6b demonstrates that while the number of Tweets coded with “Longevity” was smaller than ones with “Brain health” in 2017, the former is greater than the latter in 2018.
The purpose of this use case was twofold: to test the performance of WordCommentsAnalyzer against a large dataset and to test the software when working with Persian/Arabic texts.
We collected the abstracts of eight Iranian journals in health sciences published until Aug 2018. We collected each journal issue into a Word document and assigned the keywords as codes for each abstract (All the journals were licensed by Creative Commons, CC BY 4.0 or CC BY-NC 4.0; the commented Word files and code hierarchy text file are available in Supplementary File 3). The dataset was quite large, comprising 388 files, 4624 paragraphs, and 10378 codes. We tested the software on an ASUS U41J laptop (Intel(R) Core(TM) i5 CPU [email protected] processor; Hitachi SATA/300, 5400 RPM hard drive). The analysis was completed in a few seconds. We organized 1000 frequent codes into the code hierarchy. Although the number of the nodes was large, all the panels remained responsive and the search functions responded almost instantly. Also, the visualization tools had decent performance; creating The Code Co-Occurrence Matrix took a few seconds when the matrix was smaller than 100x100 and took less than 30 seconds when it was as large as 500x500; the software created File Code Matrix for 1000 codes and 388 files in about 30 seconds. The software also performed well in all the operations including code search when working with Persian/Arabic characters.
As mentioned at the introduction, WordCommentsAnalyzer is based on the idea that users code the textual data in the word-processing software and subsequently organize the open codes in an effective user-friendly environment. Thus the users of this software are not able to do analysis on non-textual data such as images, audio, and video. Besides, the users must do operations of coding, re-coding, and removing codes on the word-processing side. Therefore we compared only analytical capabilities of the software for textual data (i.e., what is done after open coding) with other QDA software (Table 1). In contrast to other tools, WordCommentsAnalyzer provides no memo-writing features. It offers features to count codes, to do simple queries on the codes and to organize them in a hierarchy. However, it does not allow complex queries (e.g., using Boolean or proximity operators). The recent version of the software generates basic visualizations such as Code Co-Occurrence Matrix and File Code Matrix but does not provide sophisticated visualizations like mind mapping tools. It is noteworthy that, RQDA (another free, open-source software) offers similar features as well but not in the GUI (the user have to write R syntax).
The table presents analytical capabilities of three popular commercial QDA software tools and one free, open source QDA program along with features of WordCommentsAnalyzer. Because the focus of WordCommentsAnalyzer is on the analytic work after coding data, we did not include features of these software tools used for raw data manipulation and/or coding. Although WordCommentsAnalyzer offers no memo-writing or mind-mapping features, it provides features to do simple queries on the codes and to organize them in a hierarchy. In addition, it provides basic visualization tools.
The rationale for developing WordCommentsAnalyzer was to facilitate organization and analysis of codes for researchers interested in using Word for data annotation. Despite that the query tools of this QDA software are somewhat limited and it includes no memo-writing/mind-mapping tools, it is free and open-source and provides basic code query and visualization tools through an easy-to-learn GUI. WordCommentsAnalyzer may provide a good option for researchers who see commercial QDA software as too advanced, complex or costly for their research purposes. By using this free software, the qualitative researcher can utilize a convenient word-processing application yet they reduce the efforts of manual organization of the codes.
Source code available from: https://github.com/ehsabd/word-comments-analyzer.
Archived source code at time of publication: https://doi.org/10.5281/zenodo.140472812.
License: GNU General Public License 3.0.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)