Keywords
pangenome,pharmacophore,EHEC, Escherichia coli
pangenome,pharmacophore,EHEC, Escherichia coli
One of the more prominent strain of Escherichia coli is the enterohemorrhagic (EHEC) pathotype associated with global outbreaks of bloody diarrhea and hemolytic uremic syndrome1. EHEC is one of the classical of examples of one health disease as the interface of animal health spills into human health. Within the cattle reservoir, sdiA gene is required by E. coli to survive the acidic rumen environment. SdiA is used by E. coli to sense acyl homoserine in a quorum sensing system2. However, it is considered as an orphan as the cognate acyl homoserine synthase is absent, and hence sdiA is considered an environmental sensor to sense the nearby microbial community. SdiA is stabilized by acyl homoserine lactone and acts as transcription factor glutamate decarboxylase needed for survival in the acidic environment. Hence blocking the ability of EHEC to survive the acidic ruminal environment is a proposed mechanism to control shedding in the cattle reservoir.
Whole genome sequencing of bacterial pathogens, particularly EHEC, is quickly transforming the workflows of epidemiological investigations. However, most bioinformatic pipelines used in clinical investigation use data reduction of genomes and artificially reducing diversity due to comparison of a limited number of housekeeping genes3. While wgMLST attempts to increase the number of genes, the assignment of a single reference genome appears to be inadequate in light of the pangenome. Various studies have shown that a significant number of genes that are present to the entire universe of genes within a species is missed for variant calling if only a single reference gene is used4. In this study we applied multi-scale approach to generate genome wide clustering using pangenome phylogeny using genome wide gene presence absence variation (PAV). We used this genome wide clusters as guide in generating the pharmacophore of sdiA as potential design strategy to control shedding by reducing the acid survival in the rumen.
We applied the concept of the pangenome, which represents the entirety of the genes that are present within a species, to a pathotype level. The EHEC pangenome represents the combination of genes seen in the EHEC pathotype. While the pangenome of E. coli was published in 2008 contained 8 genomes, we generated an updated EHEC pangenome with 153 genomes. The pangenome enables clustering of isolates using gene presence and absence. We used the genome wide comparison to generate clusters and genomic clade specific pharmacophore model of sdiA. This strategy enables to capture the pangenome wide variation of sdiA and ensures all conserved variants are targeted by the drug discovery pipeline enabling a pangenome to pharmacophore approach.
Whole genome sequences with the associated EHEC metadata was downloaded from Patric Database 3.5.28 using the keyword search for E. coli as organism and EHEC as the pathotype within the E. coli species5,6. This resulted to 196 results and 152 of which are closed genome and draft genomes while the remaining sequences are EHEC associated plasmids (Underlying data: Metadata from Patric Database of EHEC E. coli pangenome7).
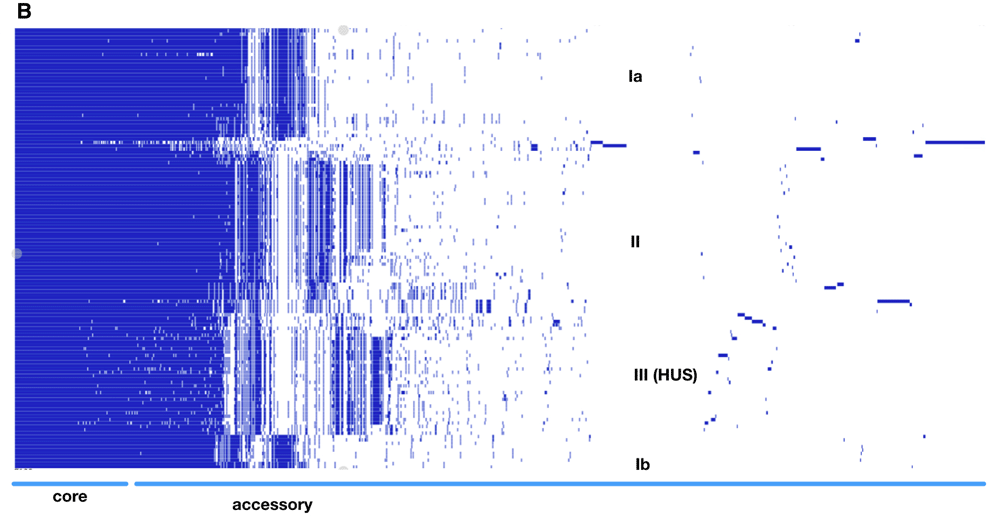
The genomes were annotated with Prokka 1.13.3 as per published protocol8. Gff files were extracted as input for the pangenome pipeline Roary 3.11.2 using the following parameters for not splitting paralogs (roary -s -p 32 *.gff) and the resulting presence absence matrix (Underlying data: EHEC E. coli pangenome presence absence matrix7) together with the accessory genome phylogeny visualized in Phandango 1.3.0 and is represented as Figure 1B9,10. Each blue bar represents an individual gene and solid blue blocks represent gene clusters. The accessory genome-based phylogeny newick file was visualized using iTol 4.311–13.
Snippy variant calling pipeline 4.3.5 was used to determine the synonymous and nonsynonymous protein mutations using sdiA of Escherichia coli O157:H7 str. Sakai as reference. The –contigs option was added to the standard commandline (snippy –outdir –ref sdiA_sakai.gbk). The resulting individual variants of sdiA was merged into EHEC E. coli sdiA variant calling data (Underlying data7).
SdiA genes were extracted from the pangenome output of Roary and protein in silico modelling performed using SWISS-MODEL14–18. SdiA protein sequences were used as targets to search for protein templates within the SWISS-MODEL library. Model selection was based on the template with the highest quality prediction by the target-template alignment.
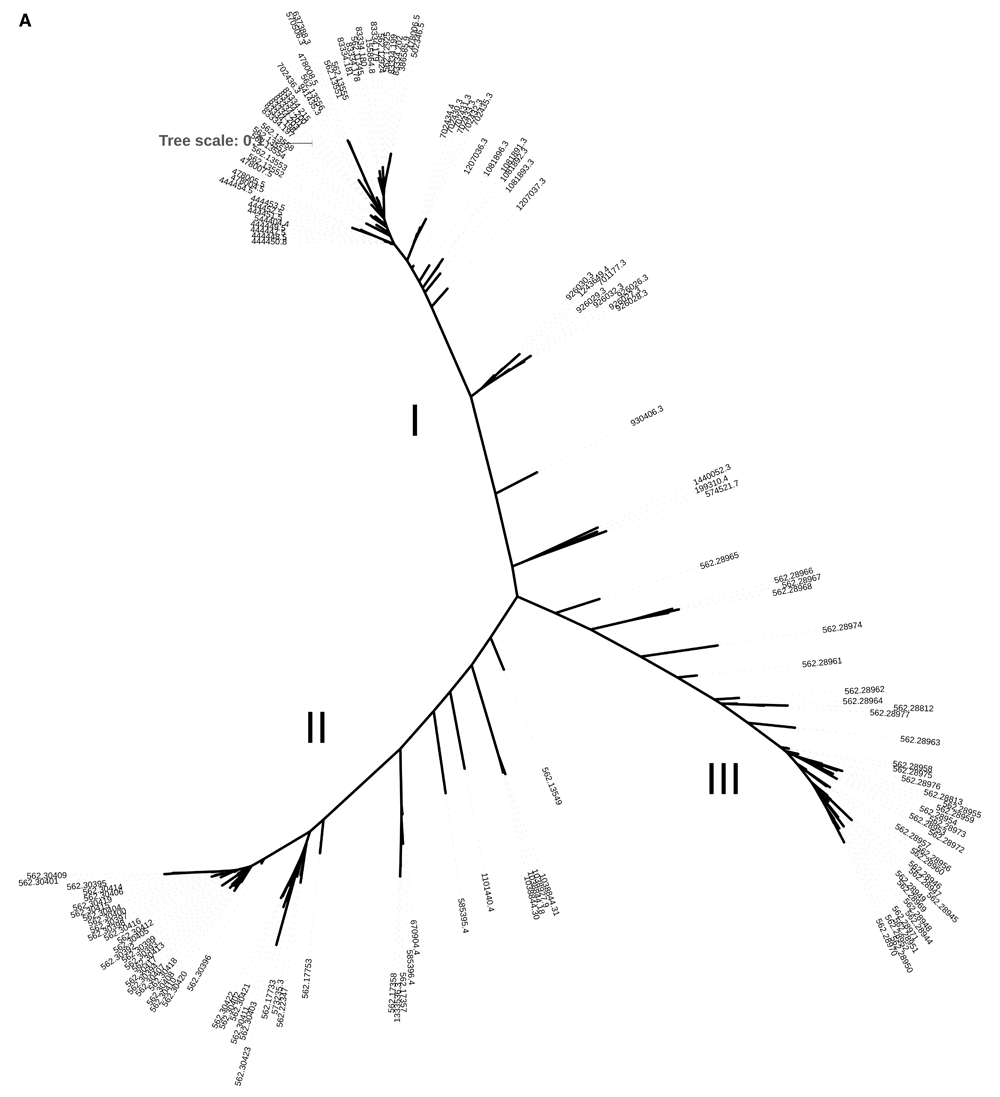
Three main genomic clades were generated using the pangenome PAV of genes (Figure 1A). Clade I includes the genomes isolated from the earliest reported outbreak in 1982 as well as the more recent cases. Clade II includes genomes from European (predominantly Czech and German) enterohemorrhagic E. coli isolates (EHEC) belonging to the O26 serotype, while Clade III includes cluster of cases associated with acute renal failure in children. Clade III is associated with hybrid pathotype of serogroup O80 has aside from Shiga toxin, an extra-intestinal virulence plasmid (pS88), is currently emerging in France. Specific gene clusters are found in cluster 1 and noticeably absent in cluster III, particularly prophages and associated genes (Underlying data: Table 2, Figure 1B). This indicates that specific genome wide gene presence and absence can be used for functional cluster instructive of the underlying epidemiological dynamics. The acquisition of genomic islands unique to individual isolates are well defined in the pangenome gene presence absence matrix (Figure 1B). The core genome is 2145 (Table 1) and total gene count within the EHEC pangenome is 17152, which is not that far off the total E. coli pangenome 22,00019. This enormous difference between the core gene and total gene highlights the variation between the different isolates, which can be strain specific and individual isolate specific as indicated by the pangenome data.
All of the examined genomes contain sdiA gene, which is contained within the 2145 core genome. Using sdiA of Escherichia coli O157:H7 str. Sakai for variant calling, we identified the nonsynonymous mutations that are widely distributed across the EHEC isolates (Figure 3). 45.0% (49/109) of the nonsynonymous mutation is due to conversion of arginine to lysine at position 189 of sdiA (Figure 2A). This amino acid is located with the α-6 domain, adjacent to the amino acid clusters associated with sdiA dimerization. Previous protein modelling determined role of the guanidinium group of arginine which enables interactions in three different directions enabling a more complex electrostatic interaction versus lysine as well as the higher pKa value in arginine that can yield a more stable ionic interaction compared to lysine20. The arginine to lysine mutations are found mostly in clade III isolates. The second ranked nonsynonymous mutation asparagine to serine at amino acid position 101 with 17.4% (19/109) which is located adjacent to η-4 phenylalanine which is associated with the ligand and distributed among the different clades (Figure 2B). β-5 domain alanine to threonine change at amino acid position 140 is the third ranked nonsynonymous mutation with 9.2 % (10/109) (Figure 2C). The fourth ranked nonsynonymous mutation is at amino acid position 138 with the conversion of cysteine to serine (Figure 2D) also within the β-5 domain. Both nonsynonymous variants of amino acid position 140 and 138 are found within clade II and III. None of the highly ranked nonsynonymous mutations impact the ligand interaction, indicating the conservation of the sdiA motif across the population in geographic and temporal distribution, which suggests the possibility of targeting sdiA for quorum sensing inhibition.
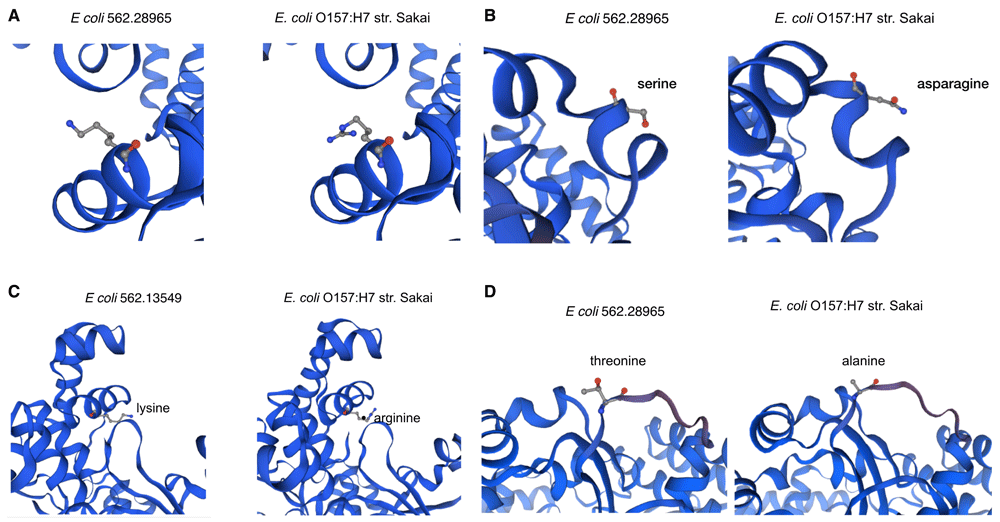

While EHEC pangenome is remarkably diverse, the allelic variants of sdiA, particularly nonsynonymous mutants, indicate the conservation of quorum sensing domain, indicating that targeting this structure can be effective across the different lineages of EHEC pathotype.
All underlying and extended data available from Open Science Framework: Supplemental Data for Pangenome guided pharmacophore modelling of enterohemorrhagic Escherichia coli sdiA, https://doi.org/10.17605/OSF.IO/BNZ857
Data are available under the terms of the Creative Commons Zero "No rights reserved" data waiver (CC0 1.0 Public domain dedication).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)