Keywords
Abrupt shifts, Time series analysis, Shift detection, R package, Methods
This article is included in the RPackage gateway.
This article is included in the Mathematical, Physical, and Computational Sciences collection.
Abrupt shifts, Time series analysis, Shift detection, R package, Methods
Abrupt shifts are found in time series in many fields, including but not limited to ecology1,2, climate3–6, medicine7 and engineering8. Abrupt shifts in time series can be caused by a range of different underlying dynamics. They are sometimes described as ‘tipping points’3,6 and are caused by an underlying mathematical bifurcation9, implying some change in control parameters governing the system in question. Alternatively, noise-induced transitions can occur between different attractors, triggered purely by stochastic variability. Sufficiently rapid forcing could also trigger an abrupt response from a system without passing a bifurcation10. In other situations, a strongly auto-correlated stochastic process (‘red’ noise) can produce what appear as abrupt shifts in time series, although it is debated whether they should be described as such11.
Our method is based on the presumption that when people search for abrupt shifts in time series by eye, they are looking for significant changes in the gradient of the time series over a short space of time. Hence we have designed a method based on looking for anomalous rates of change in a time series and released it as an R package called ‘asdetect’12 There exist several other methods of detecting anomalous changes in time series (change-point analysis13,14, STARS15, etc) which are based on looking for significant shifts in the distribution of the data. These attempt to fit generalised models to the data, or use t-tests (or other variants) to detect a significant shift in the distribution of segments of the time series. In contrast, our algorithm focuses more on the transition itself rather than the resulting behaviour of the time series (i.e. differences between the situation before and after). Thus, the approaches can be viewed as complementary. Our method should be intuitive to users, particularly those with little statistics experience. It is also useful for analysing a number of time series at once when it would be otherwise impossible to view them all individually.
Figure 1 provides a graphical representation of how our method differs from the widely-used ‘changepoint’ analysis package from R16. This method is used in the function as_detect() in our R package. For a time series that exhibits a typical abrupt shift that users might be searching for (Figure 1a), both methods detect a shift. For a drifting time series, however, a change in mean is detected from the change-point algorithm but an abrupt shift is not detected by our method (Figure 1b). These example time series, particularly the time series that exhibits the abrupt shift are used throughout the article.

The tool looks for changes in the gradient of the time series (blue) compared to the changepoint analysis R package that looks for changes in mean value over time (red). (a) An example time series that undergoes a bifurcation and hence there is an abrupt shift. (b) A drifting time series where a change in the mean is detected by the changepoint algorithm but this does not relate to an abrupt shift. These example time series are discussed in more detail later.
Our algorithm searches for anomalous changes in the gradient of a time series. We begin with a time series of length n (an example is shown in Figure 2), which we separate into l-sized segments. Across each segment, we fit a linear regression and record the gradient/coefficient of each of the n/l segments. For ls that are not factors of n and thus would give a remainder, we spread these remaining points equally at the start and end, such that our segments would focus on the centre of the time series rather than at the beginning or end.
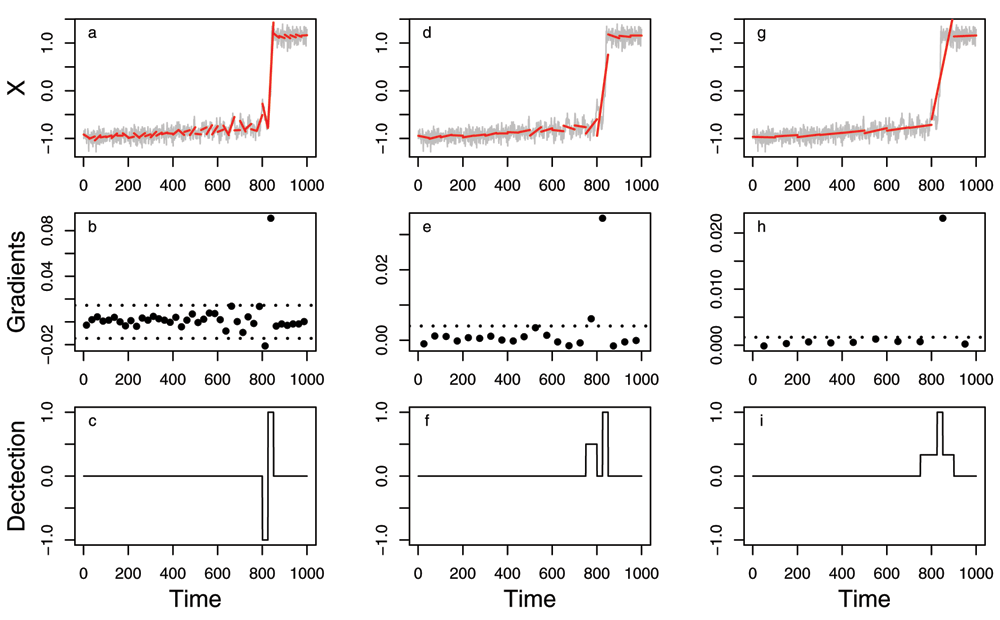
Three choices of l, 25 (a–c), 50 (d–f), and 100 (g–i) are shown. Full explanation of the plots is given in the main text. In (a), (d) and (g), the example time series is shown in grey with red lines showing the linear regressions fitted through each section. In (b), (e) and (h), the gradients of each linear regression are shown, along with dotted lines representing the 3 median absolute deviations (MADs). Panels (c), (f) and (i) show the evolving detection time series, which is described in detail in the main text.
We look for which of these gradients are significantly different by seeing which values lie outside ± 3 median absolute deviations (MADs) of the distribution of gradients. For those points in time that contribute to a significant gradient, we add or (subtract for significantly lower/negative gradients) 1 to the relevant l-long segment(s) of a ‘detection time series’ of length n which contains only 0s otherwise.
This process is repeated over a range of ls. The minimum and maximum l is chosen by the user (although both have a default; see below), and the process is repeated for all integers between these values. The resulting detection time series is divided by the number of ls tested, which gives a time series showing the (sign-included) proportion of times that a point contributed to a significant gradient. From this, a user-defined threshold (magnitude) can be used to determine if an abrupt shift is detected in the time series.
Our second function, where_as(), takes the detection time series as well as this threshold magnitude (between 0 and 1) to locate where the abrupt shifts are detected. The function records the indices where the detection time series is beyond the threshold magnitude, using the sign of the detection times series to distinguish increasing or decreasing abrupt shifts. The R function rle(), which computes the lengths of runs of equal values in a vector, is used on the differences of the list of indices that are above the threshold. This allows us to determine the sections of the time series that contain the detected abrupt shift(s). Within these subsets, we then find the maximum or minimum (depending on whether the detection is positive or negative) value to report as the position of an abrupt shift.
While it is easy to find a single maximum/minimum in the detection time series, our second function allows any number of abrupt shifts to be found, depending on how strict the user wants to be. If no values in the detection time series are found to be above the threshold level, our function will issue a warning and instead return the maximum detected value and position.
Our R package asdetect12 contains a number of functions which allows the user to detect abrupt shifts in either their own data, or in example time series created by functions within the package.
Our algorithm in as_detect() begins by separating a time series of length n into l-sized segments. Within each segment, we fit a linear regression of the form Y = a + bX where Y is the values in the time series, X is the vector, , b is the gradient of the regression model (which is recorded) and a is the intercept of the model (estimate of Y when X=0). For the set of gradients, we calculate how many are more than 3 median absolute deviations (MADs) away from the median of the set of gradients, where 1 MAD = median(|x-median(x)|). MADs are a substitute for standard deviations, which could be heavily influenced by large outliers. Points in the time series that contribute to significant gradients have a value of 1 added or subtracted to a detection time series, which is then divided by the number of l used.
The model for bifurcating example time series (shown in Figure 1–Figure 4) is:

(a) The example time series. (b) Detection time series is shown in black where it is above the threshold value (0.7, vertical dotted line; as described in the main text) and grey otherwise. Vertical dotted lines denote the range where the detection time series is above the threshold (778-872) whereas the solid lines denote the maximum detection value (0.99) and position (838).

Where x is the time series, µ is a parameter that causes the bifurcation. It runs linearly from 0 to at t=900, up to t=1000. Stochastic white noise is applied to the system (ση), sampled from a normal distribution with mean 0 and standard deviation σ which we set to 0.1. We start the time series at x=-1, the stable state when μ=0. This time series can be recreated with the function tip_eg() in our R package.
Our example time series of white noise and drifting white noise has the same level of stochastic forcing as the bifurcation time series above, centred on -1:
With the same parameter choices as in Equation (1). The value of D is set to 0 for our white noise time series, and ranges from 0 to 2 across the 1000 points of the drifting time series seen later. A similar time series, centred on 0 rather than -1 can be created from our function white_noise_eg() in our R package.
The flat start and end time series are created from combinations of the white noise and drifting white noise time series, using the D parameter. For example, for the flat start time series, D is set to 0 for the first 200 points and then increases at the same rate as previously, such that it runs linearly from 0 to 1.6 over the over 800 time points. The time series for the flat end, D runs from 0 to 1.6 over the first 800 time points, and then remains at 1.6 for the final 200 time points.
Our Pacific Decadal Oscillation (PDO) Index example is taken from the Joint Institute for the Study of the Atmosphere and Ocean, and is the first principal component of sea surface temperatures in the North Pacific once an annual cycle and general warming trend have been removed. This time series is not included within our package.
We use the cpt.mean() function of the R package ‘changepoint’, with its default settings as described in the help file of the function.
Our package is designed to be used in standard R and has no dependencies on other packages apart from installation. As asdetect12 is hosted on GitHub, users will first need to download the ‘devtools’ package, using the command install.packages(‘devtools’) in the R console. Then our package can be installed using the command devtools::install_github(‘caboulton/asdetect’) and then loaded with the command library(‘asdetect’).
Figure 2 shows an example of how the detection time series is built up, over three different l choices, for an example time series of data. A similar time series can be created with our tip_eg(), as described in the Methods. We note, as mentioned above, the full algorithm uses all integer values between the range prescribed, but only show three distinct values as a demonstration of how our method works. The model underlying the example time series exhibits a bifurcation at t=900; however, the system is forced with stochastic noise which causes the system to tip somewhat earlier. We stress that our algorithm is ignorant of how the shift in the time series occurs, but such a canonical example makes it clearer to illustrate its use.
We begin by using a value of l of 25 (Figure 2a) and fit the linear regressions through each 25 length segments (red lines; Figure 2a). There are two significant gradients found with l=25 (Figure 2b), a significantly negative gradient for the points 801–825 and a significantly positive gradient for points 826–850. This results in -1 and 1 values stored in the detection time series in Figure 2c. We then imagine we are next running the analysis using a value of 50 for l (Figure 2d), although in reality the value of l increases by 1 each time. This time there are significant positive gradients found for points 751–850 (Figure 2e), which counteracts the negatives found with l=25. This causes the points 801–825 to revert back to 0. We also divide the detection time series through by 2 as we have tried for both l=25 and 50 (Figure 2f). This results in a peak of 1 (gradients significantly positive for both values of l) for points 826–850, 0.5 for points 751–800 (those were only significantly positive for l=50) and 0 for points 801–825 (those which were significantly negative for l=25, and positive for l=50), as well as the 0s elsewhere. Finally, we again run the analysis using l=100 (Figure 2g). We find a significantly positive gradient for 801–900 (Figure 2h), leading to a detection algorithm that contains 1s at points 826–850, with 0.33 assigned to the other points between 751–900 (Figure 2i).
Running the full algorithm, for all values of l between 5 and 300 (rather than just 3 specific choices of l as shown in Figure 2), for the example time series (Figure 3a), we use the resulting detection time series in our second function (Figure 3b). We use a threshold of 0.7 and find that points 778–872 are above this threshold. Within this, we find the highest detection (0.993) at point 838 (Figure 3b). Point 838 in the example time series is the first point the time series is positive and as such is a good indicator that for this particular underlying system the time series has switched from one (disappearing) basin of attraction to the other.
Figure 4 shows that in contrast to the time series with an underlying bifurcation (Figure 4a, b), a time series of constant white noise (Figure 4c), has a maximum absolute detection value of (-0.115) and point 794 (Figure 4d). We also examine a time series of drifting white noise (Figure 4e), which shows a maximum detection value of 0.12 at point 518 (Figure 4f). These detection values from the other time series are much lower than those found in the time series with underlying bifurcation and would not be detected by our second algorithm (with only the maximum and a warning returned). We use the PDO index as a 4th example (Figure 4g). This is the major mode of climate variability in the North Pacific once the annual cycle and overall warning trend have been removed17. There is debate in the literature about whether or not there are abrupt shifts in the index, linked to changes in climate regime18,19, or if it is actually a red noise process that drifts above and below a single mean state11. This real-world time series acts as an interesting case study for our algorithm. Our method detects no significant abrupt shift (Figure 4h) with a maximum absolute detection value of -0.108 in May 1942. This suggests that, at least according to our method, that the PDO is a red noise process, as no shifts are detected.
A caveat of our algorithm is that it detects all anomalous gradients some of which would not be described as abrupt changes. For example, where a time series is relatively constant for a short period at the start before a longer period of increasing, then the short period at the start will be detected as anomalous (an unusually low gradient relative to the rest of the time series). This is also true if a short flat section is detected at the end of an increasing or decreasing time series. Examples of these cases are shown in Figure 5. Figure 5 also shows that these types of behaviour are not necessarily picked up strongly, with minimum detection values of -0.69 and -0.39 for increasing and decreasing time series, respectively. Similar behaviour is also detected for flat sections in otherwise decreasing time series. These are detected as increasing abrupt shifts (not shown).

Flat sections occur at the (a, b) start or (c, d) end of increasing time series are detected as decreasing abrupt shifts as their gradients are significantly lower than the rest of the time series.

The example time series (Figure 1 and Figure 2) is tested when using a threshold of (a) 0.7 (as in Figure 2), (b) 0.88, and (c) 0.95. A second smaller shift is detected with the middle threshold (refer to Figure 1 and Figure 2 to link this back to the original time series).
We have created a third function, shift_type(), that checks if the abrupt shifts that are detected within time series are ‘flat’ or not. True abrupt shifts that most users will be searching for will have stronger gradients closer to the detected position than the gradient of the time series overall. Our third function compares the absolute value of the gradient of a linear regression model fitted locally around the detected position compared to the absolute gradient of a linear regression fitted across the full time series. We treat those shifts with smaller gradients compared to the overall gradient as ‘flat’. The subset of the time series the local linear regression model is fitted to is a user defined choice, but we recommend (as is the default) it to be 10% of the total length of the time series, 5% either side. If a shift is detected within the first or last 5% (or within the length determined by the user), then the function will use data up to the start or end of the time series, even if this results in a smaller window that the model is fitted to.
To determine how our algorithm compares to the changepoint package, we compare the detections in six example time series, the tipping point time series, white noise, drifting white noise, and we also include two time series with flat sections at the beginning and end of otherwise increasing time series, which provides an example of what is described above. Analyses of the PDO index are also compared.
Table 1 shows the positions of abrupt shifts detected by both methods, including the detection value from our algorithm and the confidence value from changepoint. We also include the actual position that the abrupt shift is in the time series. In changepoint we use the cpt.mean() function. cpt.mean() searches for changes in the mean across the time series, and we use the ‘AMOC’ method such that a maximum of one will be detected. The position returned is the beginning of the second section that has a significantly different mean to the first.
Results in brackets are not detected as shifts by our algorithm, or deemed significant by the changepoint package.
| Time series | Actual position of abrupt shift | Our algorithm detection position | Our algorithm detection value | Changepoint position | Changepoint confidence value |
|---|---|---|---|---|---|
| Tipping point | 900* | 838 | 0.993 | 838 | 0.998 |
| White Noise | N/A | (794) | (-0.115) | N/A | N/A |
| Drifting | N/A | (518) | (0.128) | 520 | 0.917 |
| Flat start | 150 | (96) | (-0.689) | 537 | 0.881 |
| Flat end | 850 | (948) | (-0.392) | 520 | 0.917 |
| PDO Index | NA | (May 1942) | (-0.108) | (Feb 2014) | (3.6*10^-4) |
We find that both methods agree exactly with where the abrupt shift occurs in the tipping point time series. There are no abrupt shifts detected in the white noise series, with a detection value of -0.115 only being picked up if the user used such a low threshold for detection. The same is true of our algorithm for the drifting time series. However, the changepoint algorithm detects a change at point 520 (with confidence 0.917). For the flat time series, the detections from our algorithm are much closer to the actual change in the time series, although the detection values are relatively low. This is useful as it is not the type of abrupt shift that would usually want to be detected but is still highlighted. These types of anomalies are also picked up by our third function. Changepoint detects changes about half way through the time series, with much higher confidence values. This is a simple result of the changepoint method looking for changes in the mean.
While changepoint manages to detect the tipping point time series as well as our own method does, it struggles with time series where there is no abrupt shift but an overall trend. It is also noticeable that the confidence values are a lot higher than our detection values in the ‘flat’ time series, despite being further away from the actual transition. However, we iterate that the changepoint function is looking for changes in the mean over the time series and so although is used for detecting abrupt shifts, there is no differentiating between fast and slow shifts. It detects a shift in the drifting time series as that is what it is designed to do. Our method, however, which focuses on gradients, finds no abrupt shift.
The main inputs of our algorithm are the choice of minimum and maximum l. This depends on the length of the time series such that significant gradients can still be found. A significant gradient can only be found if there are three or more segments and thus the maximum value of l should be less than 1/3 of n, the length of the time series. Any choice of l above this will cause the maximum possible detection value to decrease as well as all the detection values to be lower than they otherwise would be. Having a choice of maximum l too low, however, may bias detection towards short term fluctuations in the time series rather than the type of abrupt shift-type behaviour that was intended. As a default of our function, a maximum value of l equal to 1/3 of n is used.
A choice for the minimum value is more difficult to determine. It is required to be big enough such that if a time series is ‘noisy’, then it will not detect significant gradient changes due to deviations caused by low-level noise. Less noisy (smoother) systems can have a smaller minimum value, and as such will pick up smaller abrupt shifts which would be difficult in a time series with more noise. We set a default of 5 points as a ‘rule of thumb’ for being able to find a significant coefficient in a linear regression model.
Another choice of variable is the threshold in our second function to determine where abrupt shifts are detected. Within a consecutive set of points, the function will search for the maximum value within this range. However, it does not take into consideration local maxima (or minima) that are still above the threshold. This is a design choice of our algorithm, as we assume that users will want to only find the largest abrupt shift locally, and that the smaller nearby shifts (local maxima/minima) have had their detection values inflated due to being near the large abrupt shift.
An example is found in our original case (Figure 2). We showed using a threshold of 0.7 that an abrupt shift was detected (Figure 3). However, using a threshold value of 0.88, we find another abrupt shift at point 800 (detection is 0.91), as well as the original at point 838 (detection: 0.99). This can be seen as a large excursion that (just) failed to leave the disappearing basin of attraction, in this case which is approaching an underlying bifurcation. Figure 6 shows that the local minimum in the detection time series is below the threshold and thus a new segment is detected. A threshold value of 0.95, again only detects the original shift.
We have outlined our method for detecting abrupt shifts in time series, which is based on looking for significant changes in gradient of the series. Our algorithms differ from those such as the changepoint R package, which looks for significant changes in mean values. We have shown that this method detects shifts in time series that drift when they would not ordinary be deemed abrupt shifts by users. Our alternative method does not suffer from this set-back. Furthermore, it is intuitive in its design, whilst allowing greater control for users to discover abrupt shifts of different magnitudes.
The PDO Index time series can be found at the Joint Institute for the Study of the Atmosphere and Ocean website.
Other, stochastic, time series were created using our package. To create a time series that contains an abrupt shift, the function tip_eg() is used. An example of white noise with or without drift can be created with the white_noise_eg(). Time series that began or ended with flat sections used a combination of two white_noise_eg() outputs that were stitched together to give the desired outcome.
Source code available from: https://github.com/caboulton/asdetect/.
Archived source code at time of publication: https://doi.org/10.5281/zenodo.263404412.
License: MIT License.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)