Keywords
Correlative Microscopy, Image Registration, In-silico labeling, Deep Learning
This article is included in the NEUBIAS - the Bioimage Analysts Network gateway.
This article is included in the Artificial Intelligence and Machine Learning gateway.
Correlative Microscopy, Image Registration, In-silico labeling, Deep Learning
TRAINING PROCESS:
We added more detail about the training workflow and discuss when retraining is necessary. The Jupyter training notebook now contains a description of training parameters and more documentation. We varied the number of training images and compared the resulting performance.
ERROR QUANTIFICATION:
We performed a quantification of the registration quality using manually aligned ground truth data as reference. If a few images from an experiment are included in the training set, the registration of the remaining images improves significantly (Table 1).
COMPARISON:
We now refer to ec-CLEM autofinder, which uses automatically detected landmarks for registration, but we did not perform a direct quantitative comparison. If suitable spots can be found, the performance on the same images should be similar. If not, then transferring the EM image to fluorescence using DeepCLEM could be used to generate input data for point-based registration in ec-CLEM.
SCOPE AND LIMITATIONS:
We added more detail regarding scope and limitations of this tool and its current requirements to abstract, introduction and discussion, including the need for at least three nucleoli if chromatin staining is used. To reflect the general applicability of the method, we replaced "fluorescent chromatin stain" by "fluorescent stain" in the abstract. We mention that widefield can be used, although with lower alignment precision, and that our tool could be used for other imaging methods if pairs of 2D slices are available.
MINOR CHANGES:
Changed "macro" to "plugin", "FIJI" to "Fiji". Added the information that standard histogram equalization in Fiji was used for preprocessing, and "Register Virtual Stack Slices" and similarity transform for registration. We encourage the reader to use more reproducible methods for generating training data.
See the authors' detailed response to the review by Christopher Schmied
See the authors' detailed response to the review by Reinhard Rachel
See the authors' detailed response to the review by Martin L. Jones
Correlative Light and Electron Microscopy (CLEM) combines the high resolution of electron microscopy (EM) with the molecular specificity of fluorescence microscopy. In super-resolution array tomography (srAT) for example, serial sections are imaged first under the fluorescence microscope using super-resolution techniques such as structured illumination microscopy (SIM), and then in the electron microscope1. With this technique, it is possible to identify and assign molecular identities to subcellular structures such as electrical synapses1,2 or microdomains in bacterial membranes3 that cannot be resolved by EM due to insufficient contrast.
To visualize and interpret the results of CLEM, the fluorescent images must be registered to the EM images with high accuracy and precision. Due to the different contrasts of EM and fluorescence images, automated correlation-based image alignment, as used e.g. for aligning EM serial sections4, is not directly possible. Registration is often done by hand using a fluorescent chromatin stain2, or semi-automatically with fiducial markers using tools such as eC-CLEM5. Further improvement and automation of the registration process is of great interest to make CLEM scalable to larger datasets.
Deep Learning using convolutional neural networks (CNNs) has become a powerful tool for various tasks in microscopy, including denoising and deconvolution as well as classification and segmentation, reviewed in 6 and 7. One interesting application of CNNs is the prediction of fluorescent labels from transmitted light images of cells, also called “in silico labeling”8,9.
We show here that this approach can be used to predict the fluorescent chromatin stain in electron microscopy images of cell nuclei. The predicted “in silico” chromatin images are sufficiently similar to real experimental chromatin images acquired with SIM to use them for automated correlation-based registration of CLEM images. Based on this observation, we developed “DeepCLEM”, a fully automated CLEM registration workflow implemented in Fiji10 and based on CNNs.
We used previously acquired imaging data of Caenorhabditis elegans and of human skin samples from healthy subjects. Sample preparation as well as the acquisition of the imaging data has been previously described in detail1,2,11. Briefly, C. elegans worms were cryo-immobilized via high-pressure freezing and subsequently processed by freeze substitution. All samples were embedded in methacrylate resin and sectioned at 100 nm. Ribbons of consecutive sections were attached to glass slides and labeled with fluorophores. Live Hoechst 33342 was used to stain chromatin and immunolabeling was used to visualize molecular identities. The sections were then imaged with SIM super-resolution microscopy. Next, they were processed for electron microscopy by heavy metal contrasting and carbon coating. The regions of interest previously imaged with SIM were then imaged again on the same sections with scanning electron microscopy, resulting in pairs of images that needed to be correlated.
To prepare ground truth for network training, we manually registered the chromatin channel to the EM images as described in 2. We selected 30 subimages and super-imposed them in the software Inkscape. By reducing the opacity of the chromatin images, they could be manually resized, rotated and dragged until the Hoechst signal coincided with the electron-dense heterochromatin puncta in the underlying EM images. To generate own training data, reproducible methods retaining a record of all transforms are recommended.
We implemented DeepCLEM as a Fiji10 plugin, using CSBDeep12 for network prediction. Preprocessing of the images as well as network training were performed in Python using scikit-image13 and TensorFlow14. First, a neural network trained on manually registered image pairs predicts the fluorescent chromatin signal from previously unseen EM images (Figure 1A). This "virtual" fluorescent chromatin image is then automatically registered to the experimentally measured chromatin signal from the sample using the “similarity” transform of the “Register Virtual Stack Slices” plugin in Fiji (Figure 1B). The transformation parameters from this automated alignment are finally used to register the other SIM images that contain the signals of interest to the EM image (Figure 1C).
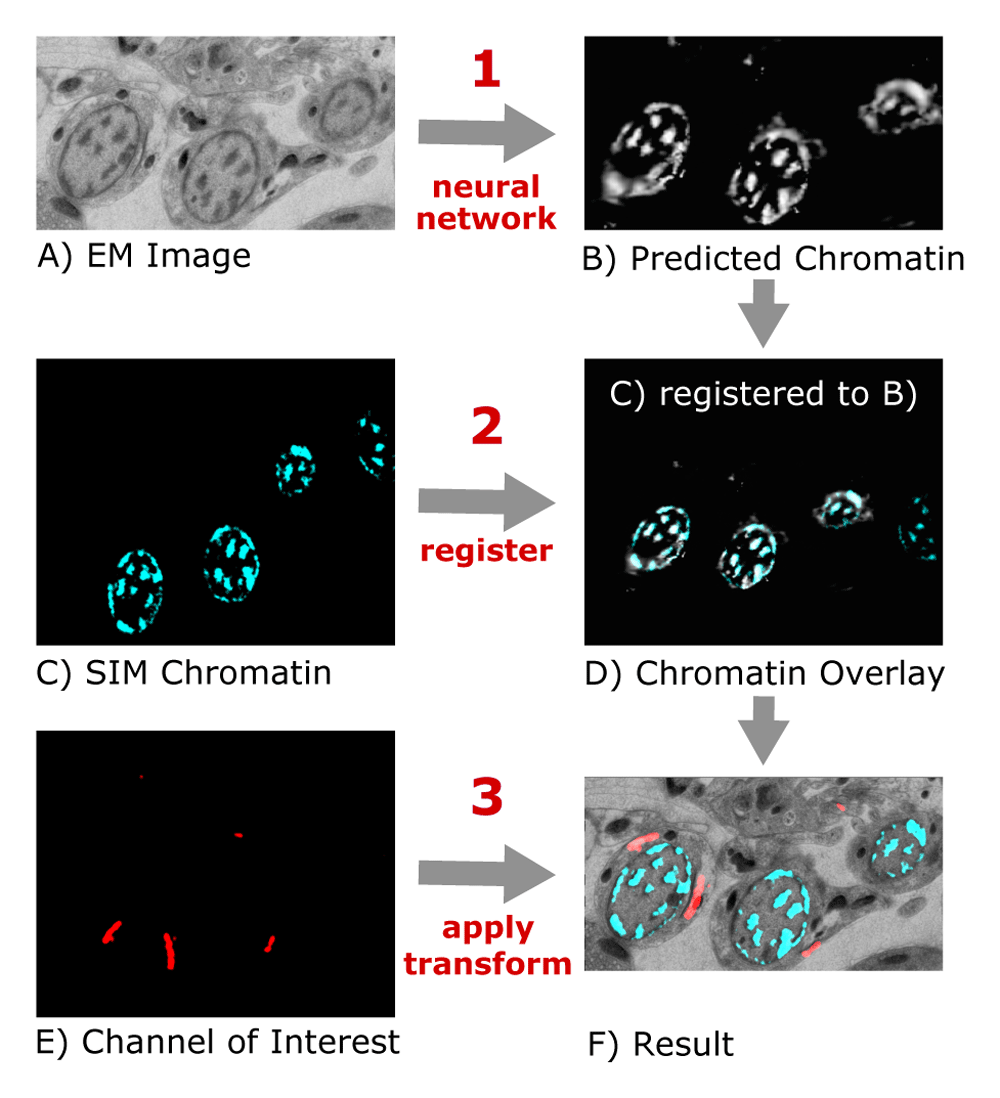
From the EM image (A), a CNN predicts the chromatin channel (B), to which the SIM image (C) is registered (D). The same transform is applied to the channel of interest (E) to obtain a CLEM overlay (F).
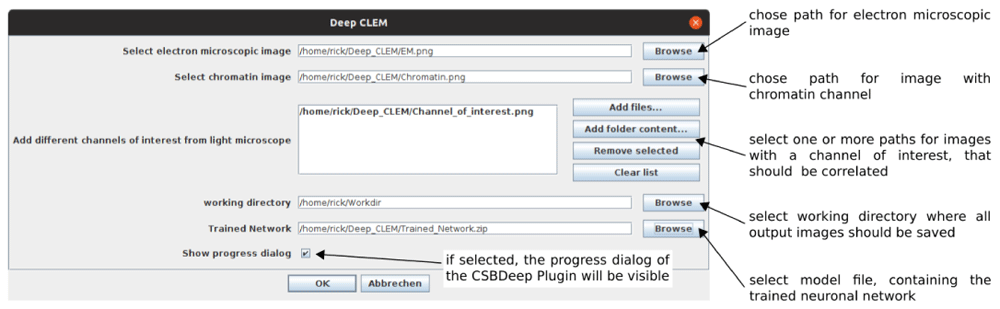
DeepCLEM requires Fiji10 with CSBDeep12 to run. The paths to the images and model file are entered in a user dialog (Figure 2). After running DeepCLEM, the correlated images and a .XML file containing the transform parameters are written to the output directory. The workflow is summarized in Figure 1; instructions for installing and running DeepCLEM are included in the repository. The network included in DeepCLEM was trained on in-house data and may work on images with similar contrast, but in most cases, re-training will be necessary – details on the workflow and training parameters are given in a Jupyter notebook in the repository. Running this notebook on a directory with 30-40 aligned ground truth image pairs will yield a model file that can be loaded in the DeepCLEM Fiji plugin.
We trained DeepCLEM on correlative EM and SIM images of C. elegans and on human skin tissue and compared prediction and registration results for different network architectures and preprocessing routines. A generative adversarial network (pix2pix) showed promising results in some images from the skin dataset, but overall performance was best using the ProjectionCARE network from CSBDeep12.
EM images had large differences in contrast even when acquired in the same laboratory. We compared different preprocessing routines, including normalization and histogram equalization, and found that standard histogram equalization in Fiji resulted in the best performance on our data. The best combination of preprocessing steps for optimizing contrast may however depend on the data.
We performed a quantification of the quality of the registration on four manually aligned images from an independent experiment, and applying a known shift or rotation. In 75% of cases the registration worked and had a very small error, while in 25% it was completely off by several 100 nm (Table 1). If two of the test images were included in the training set, the error was much lower, so DeepCLEM works best if a small number of images of each experiment are manually aligned and added to the training data. The remaining images are then reliably aligned. We also varied the number of images in the training set and found that 30-40 ground truth images are sufficient to obtain good alignment on the test set.
When applying DeepCLEM on images from a different experiment not represented in the training data, registration failed in 25% of cases (top part, image 1–4). If two manually aligned images were included in the training set, all other test images were successfully registered (bottom part, images 1–2).
We developed “DeepCLEM”, a fully automated CLEM registration workflow implemented in Fiji10 based on prediction of the chromatin stain from EM images using CNNs. Our registration workflow can easily be included in existing CLEM routines or adapted for imaging methods other than srAT where corresponding 2D slices need to be registered. If direct prediction of one modality from the other does not work, an alternative is to predict a common representation of both modalities, as described in Ref 15. While we found that "DeepCLEM" performs well under various conditions, it has some limitations: using chromatin staining for correlation requires the presence of at least three heterochromatin patches in the field of view. This limitation could be overcome by using e.g. propidium iodide to label the overall structure of the tissue. Widefield microscopy could be used where SIM is not available, but alignment quality is bounded by the lower-resolution channel.
The popular CLEM registration tool eC-CLEM5 has an “autofinder” function that detects corresponding features using spot finding or segmented regions. We did not perform a direct comparison, but results should be similar if suitable spots are found. If not, then image-to-image translation with DeepCLEM followed by point-based registration in eC-CLEM could be a promising alternative.
Source code, pretrained networks and example data as well as documentation are available online at:
Source code available from: https://github.com/CIA-CCTB/Deep_CLEM.
Archived source code at time of publication: https://doi.org/10.5281/zenodo.409524716
License: MIT License.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)