Keywords
Single-cell RNA sequencing, cell type classification, gene expression profile, R package
This article is included in the RPackage gateway.
This article is included in the Bioconductor gateway.
This article is included in the Single-Cell RNA-Sequencing collection.
Single-cell RNA sequencing, cell type classification, gene expression profile, R package
Single-cell mRNA sequencing (scRNA-seq) promises to deliver elevated understanding of cellular mechanisms, cell heterogeneity within tissue, and developmental transitions1–5. A key challenge in scRNA-seq data analysis is the identification of cell types from single-cell transcriptomes. Manual inspection of the expression patterns from a small number of marker genes is still standard practice, which is cumbersome and frequently inaccurate. Unfortunately, current implementations of scRNA-seq suffer from several limitations3,6,7 that further compound the problem of cell type identification. First, only RNA levels are measured, which may not correlate with cell surface marker or gene expression signatures identified through other experimental techniques. Second, due to the low capture rate of RNAs, low expressing genes may face detection problems regardless of sequencing depth. Many previously established markers of disease or developmental processes suffer from this issue, such as transcription factors. On the data analysis front, over or under-clustering can generate cluster markers that are uninformative for cell type labeling. In addition, cluster markers that are unrecognizable to an investigator may indicate potentially interesting unexpected cell types, but can be very intimidating to interpret.
For these reasons, investigators struggle to integrate scRNA-seq into their studies due to the challenges of confidently identifying previously characterized or novel cell populations. Formalized data-driven approaches for assigning cell type labels to clusters greatly aid researchers in interrogating scRNA-seq experiments. Currently, multiple cell type assignment packages exist but they are specifically tailored towards input types or workflows8–13. As more and more approaches to the classification problem are introduced, benchmarking performance and compatibility to sequencing platforms and analysis pipelines becomes increasingly important.
We developed the R package clustifyr, a lightweight and flexible tool that leverages a wide range of prior knowledge of cell types to pinpoint target cells of interest or assign general cell identities to difficult-to-annotate clusters. Here, we demonstrate its basic usage and applications with transcriptomic information of external datasets and/or signature gene profiles, to explore and quantify likely cell types. The clustifyr package is built with compatibility and ease-of-use in mind to support other popular scRNA-seq tools and formats.
clustifyr requires query and reference data in the form of raw or normalized expression matrices, corresponding metadata tables, and a list of variable genes (Figure 1).
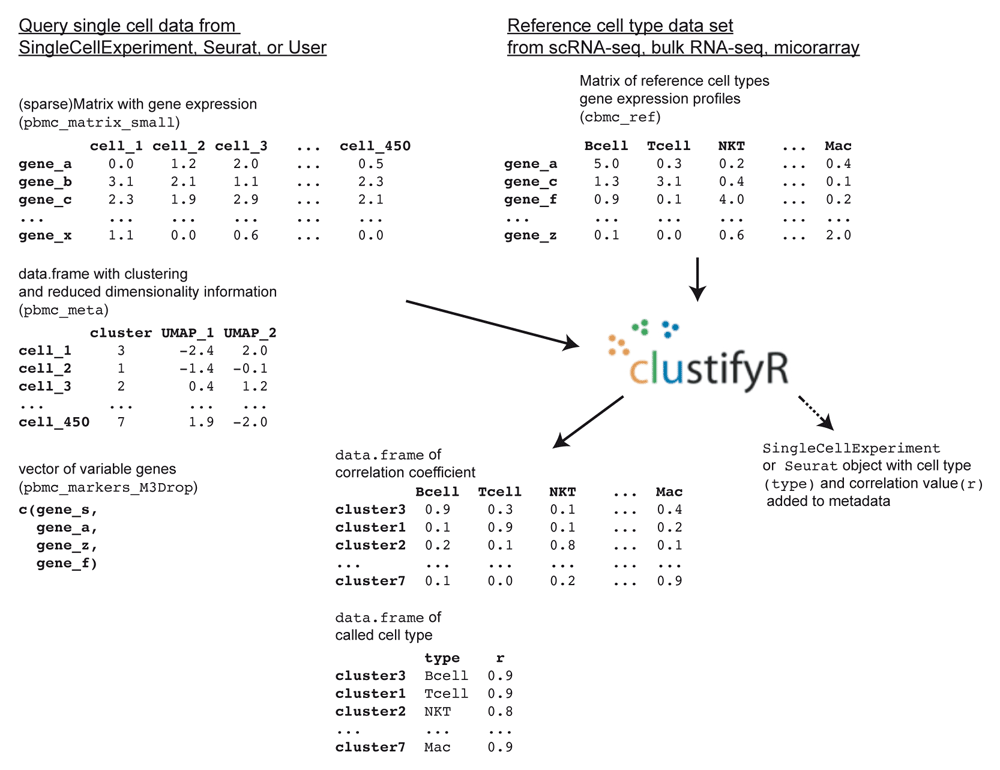
library(clustifyr) pbmc_matrix_small[1:5, 1:5] # query matrix of normalized scRNA-seq counts cbmc_ref[1:5, 1:5] # reference matrix of expression for each cell type pbmc_meta[1:5, ] # query meta-data data.frame containing cell clusters length(pbmc_markers_M3Drop$Gene) # vector of variable genes
clustifyr adopts correlation-based methods to find reference transcriptomes with the highest similarity to query cluster expression profiles, defaulting to Spearman ranked correlation, with options to use Pearson, Kendall, or Cosine correlation instead if desired. clustify() will return a matrix of correlation coefficients for each cell type and cluster, with the row names corresponding to the query cluster number and column names as the reference cell types.
res <- clustify( input = pbmc_matrix_small, metadata = pbmc_meta, cluster_col = "seurat_clusters", # column in meta.data with clusters ref_mat = cbmc_ref, query_genes = pbmc_markers_M3Drop$Gene ) res[1:5, 1:5] #> B CD14+ Mono CD16+ Mono CD34+ CD4 T #> 0 0.4700038 0.5033242 0.5188112 0.6012423 0.7909705 #> 1 0.4850570 0.4900953 0.5232810 0.5884319 0.7366543 #> 2 0.5814309 0.9289886 0.8927613 0.6394140 0.5258430 #> 3 0.8609621 0.4663520 0.5686564 0.6429193 0.4698687 #> 4 0.2814882 0.1888232 0.2506101 0.4140560 0.6125503
Query clusters are assigned cell types to the highest correlated reference cell type, with an automatic or manual cutoff threshold for query clusters dissimilar to all available reference cell types, to be labeled as “unassigned”.
res2 <- cor_to_call( cor_mat = res, # matrix of correlation coefficients cluster_col = "seurat_clusters", # column in meta.data with clusters threshold = 0.5 )
To better integrate with standard workflows that involve S3/S4 R objects, methods for clustifyr are written to directly recognize Seurat14 (v2 and v3) and SingleCellExperiment15 objects, retrieve the required information, and reinsert classification results back into an output object. A more general wrapper is also included for compatibility with other common data structures, and can be easily extended to new object types. This approach also has the added benefit of forgoing certain calculations such as variable gene selection or clustering, which may already be stored within input objects.
res <- clustify( input = sce_small, # an SCE object ref_mat = cbmc_ref, # matrix of expression for each cell type cluster_col = "cell_type1", # column in meta.data with clusters obj_out = TRUE # output SCE object with cell type ) SingleCellExperiment::colData(res)[1:10, c("type", "r")] #> DataFrame with 10 rows and 2 columns #> type r #> <character> <numeric> #> AZ_A1 pDCs 0.814336567702192 #> AZ_A10 Eryth 0.665800619720566 #> AZ_A11 pDCs 0.682088309107356 #> AZ_A12 Eryth 0.665800619720566 #> AZ_A2 B 0.634114583333333 #> AZ_A3 pDCs 0.814336567702192 #> AZ_A4 pDCs 0.814336567702192 #> AZ_A5 NK 0.655407634437123 #> AZ_A6 pDCs 0.682088309107356 #> AZ_A7 pDCs 0.71424223704931 res <- clustify( input = s_small3, # a Seurat object ref_mat = cbmc_ref, # matrix of expression for each cell type cluster_col = "RNA_snn_res.1", # name of column in meta.data containing cell clusters obj_out = TRUE # output Seurat object with cell type inserted as "type" column ) res@meta.data[1:5, ] #> orig.ident nCount_RNA nFeature_RNA RNA_snn_res.0.8 #> ATGCCAGAACGACT SeuratProject 70 47 0 #> CATGGCCTGTGCAT SeuratProject 85 52 0 #> GAACCTGATGAACC SeuratProject 87 50 1 #> TGACTGGATTCTCA SeuratProject 127 56 0 #> AGTCAGACTGCACA SeuratProject 173 53 0 #> letter.idents groups RNA_snn_res.1 type r #> ATGCCAGAACGACT A g2 0 Mk 0.6204476 #> CATGGCCTGTGCAT A g1 0 Mk 0.6204476 #> GAACCTGATGAACC B g2 0 Mk 0.6204476 #> TGACTGGATTCTCA A g2 0 Mk 0.6204476 #> AGTCAGACTGCACA A g2 0 Mk 0.6204476
In the absence of suitable reference data (i.e. RNA-seq or microarray expression matrices), clustifyr can build scRNA-seq reference data by averaging per-cell expression data for each cluster, to generate a transcriptomic snapshot. Direct reference-building from SingleCellExperiment or Seurat objects is supported as well.
new_ref_matrix <- average_clusters( mat = pbmc_matrix_small, metadata = pbmc_meta$classified, # or use metadata = pbmc_meta, cluster_col = "classified" if_log = TRUE # whether the expression matrix is already log transformed ) new_ref_matrix_sce <- object_ref( input = sce_small, # SCE object cluster_col = "cell_type1" # column in colData with cell identities ) new_ref_matrix_v3 <- seurat_ref( seurat_object = s_small3, # SeuratV3 object cluster_col = "RNA_snn_res.1" # column in meta.data with cell identities )
Data exploration plotting functions, for dimensional reduction scatter plots and heatmaps, are extended from ggplot2 and ComplexHeatmap packages, featuring colorblind-friendly default colors. Simple gene list-based methods (clustify_lists()) for sanity checks on positive and negative markers, via gene list enrichment or calculation of percentage detection by cluster, are implemented as well.
Correlation method. We benchmarked clustifyr against a suite of comparable datasets, PBMCbench16, generated from two PBMC samples using multiple scRNA-seq methods. Notably, for each reference dataset cross-referenced to other samples, clustifyr achieved a median F1-score of above 0.94 using Spearman ranked correlation (Figure 2A). Other correlation methods are on par or slightly worse at cross-platform classifications, which is expected based on the nature of ranked vs unranked methods. We therefore selected Spearman as the default method in clustifyr, with other methods also available, as well as a wrapper function to find consensus identities across available correlation methods (call_consensus()).
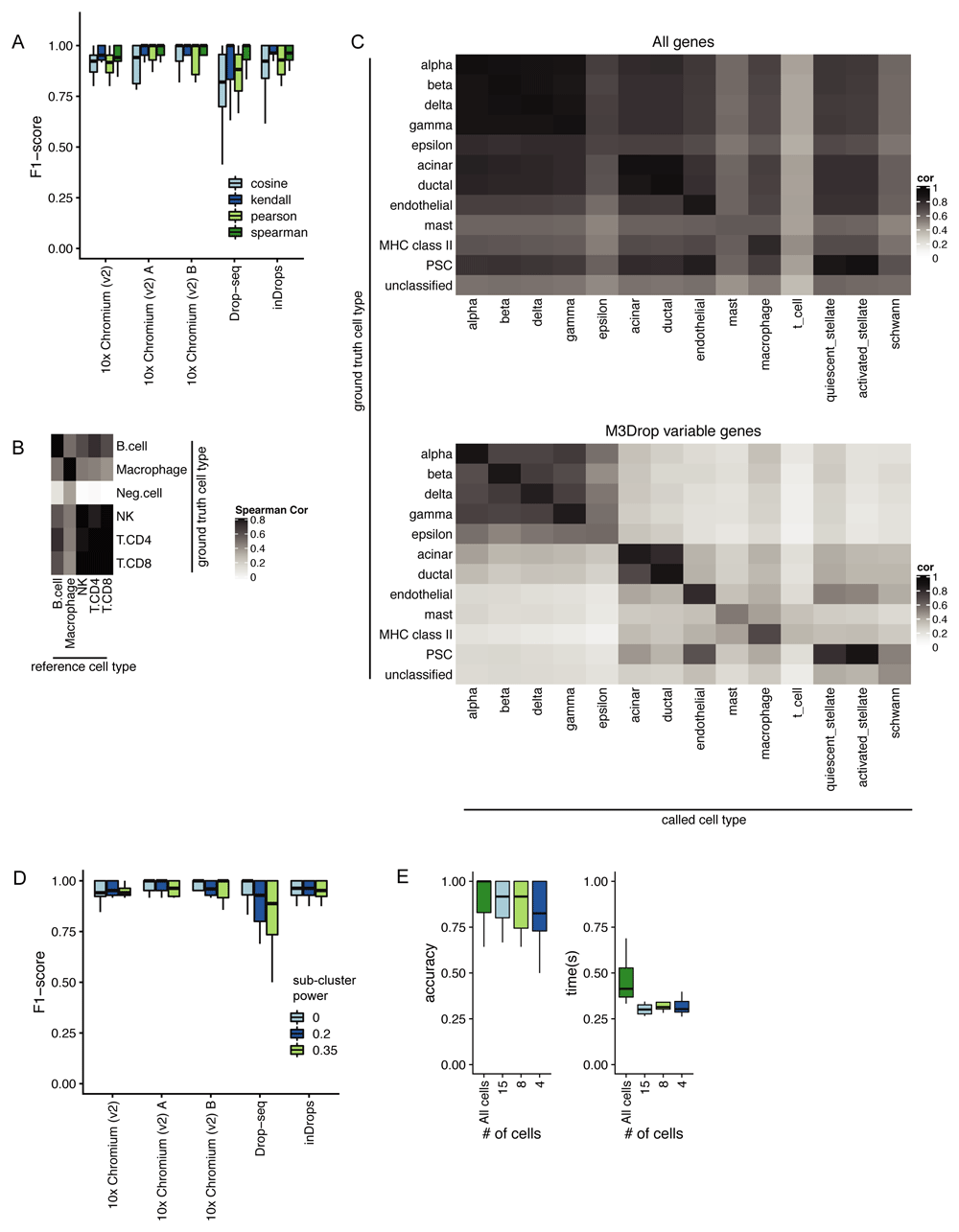
A) Comparison of accuracy of different correlation methods for classifying across platforms using the PBMCbench dataset. B) Heatmap showing correlation coefficients between query cell types and the reference cell types. Clusters with correlation < 0.50 are assigned as Neg.Cell by clustifyr. C) Comparison of classification power with and without feature selection. D) An assessment of the accuracy of using single or multiple averaged profiles as reference cell types was conducted using the PBMCbench test set. The number of reference expression profiles to generate for each cell type is determined by the number of cells in the cluster (n), and the sub-clustering power argument (x), with the formula nx. E)Accuracy and performance were assessed with decreasing query cluster cell numbers using the PBMCbench test.
Correlation minimum cutoff. Recognition of missing reference cell types, so as to avoid misclassification, is another point of great interest in the field. From general usage of clustifyr, we find using a minimum correlation cutoff of 0.5 or 0.4 is generally satisfactory. Alternatively, the cutoff threshold can be determined heuristically using 0.8 * highest correlation coefficient among the clusters. One example is shown in Figure 2B, using PBMC rejection benchmark data modified by the SciBet package17. Megakaryocytes were removed from reference data, and labeled as “neg.cells” for ground truth in test data. clustifyr analysis found the “neg.cells” to be dissimilar to all available reference cell types, and hence left as “unassigned” under the default minimum threshold cutoff. Next, we applied clustifyr to a series of increasingly challenging datasets from the scRNAseq_Benchmark13 unseen population rejection test. Without the corresponding cell type references, 57.5% of T cells were rejected and unassigned. When only CD4+ references were removed, 28.2% of test CD4+ T cells were rejected and unassigned. clustifyr was unable to reject CD4+/CD45RO+ memory T cells, mislabeling them as CD4+/CD25 T Reg instead when the exact reference was unavailable. However, these misclassifications are also observed with other classification tools benchmarked in the scRNAseq_Benchmark study13.
Variable gene selection. As the core function of clustifyr is ranked correlation, feature selection to focus on highly variable genes is critical. In Figure 2C, we compare correlation coefficients using all detected genes (>10,000) vs feature selection by the package M3Drop. A basic level of feature selection, e.g. M3Drop, Seurat VST (default takes top 2,000), or simply 1,000 genes with highest variance in the reference data, is sufficient to classify the pancreatic cells. In the case of other cell type mixtures, especially ones without complete knowledge of the expected cell types, clustering and feature selection will be of greater importance. clustifyr does not provide novel clustering or feature selection methods on its own, but instead is built to maintain flexibility to incorporate methods from other, and future, packages. We view these questions as a fast-moving fields18,19, and hope to benefit from new advances, while keeping the general clustifyr framework intact.
Subclustering. For scRNA-seq reference data, matrices are built by averaging per-cell expression data for each cluster, to generate a transcriptomic snapshot similar to bulk RNA-seq or microarray data. An additional argument to subcluster the reference dataset clusters is also available, to generate more than one expression profile per reference cell type. The number of subclusters for each reference cell type is dependent on the number of cells in the cluster (n), and the sub-clustering power argument (x), following the formula nx9. However, this approach does not improve classification in the PBMCbench data (Figure 2D). We envision its utility would greatly depend on the granularity of the clustering in the reference dataset.
Cells per cluster. After testing a general reference set built from the Mouse Cell Atlas20 to be of high accuracy in classification of the Tabula Muris data, we subsampled the query data (Figure 2E). As expected, with further downsampling of the number of cells in each query cluster, we observe decreased accuracy. Yet, even at 15 cells per tested cluster, clustifyr still performed well, with a further increase in speed. Based on these results, we set the default parameters in clustifyr to exclude or warn users of classification on clusters containing less than 10 cells. In addition, an intentional overclustering and classification function based on k-means clustering (overcluster_test()) is implemented in clustifyr for exploration of clustering quality.
Using clustifyr, peripheral blood mononuclear cell (PBMC) clusters from the Seurat PBMC 3k tutorial are correctly labeled using either bulk-RNA seq references generated from the ImmGen database9,21, processed microarray data of purified cell types22, or previously annotated scRNA-seq results from the Seurat CBMC CITE-seq tutorial14 (Figure 3).
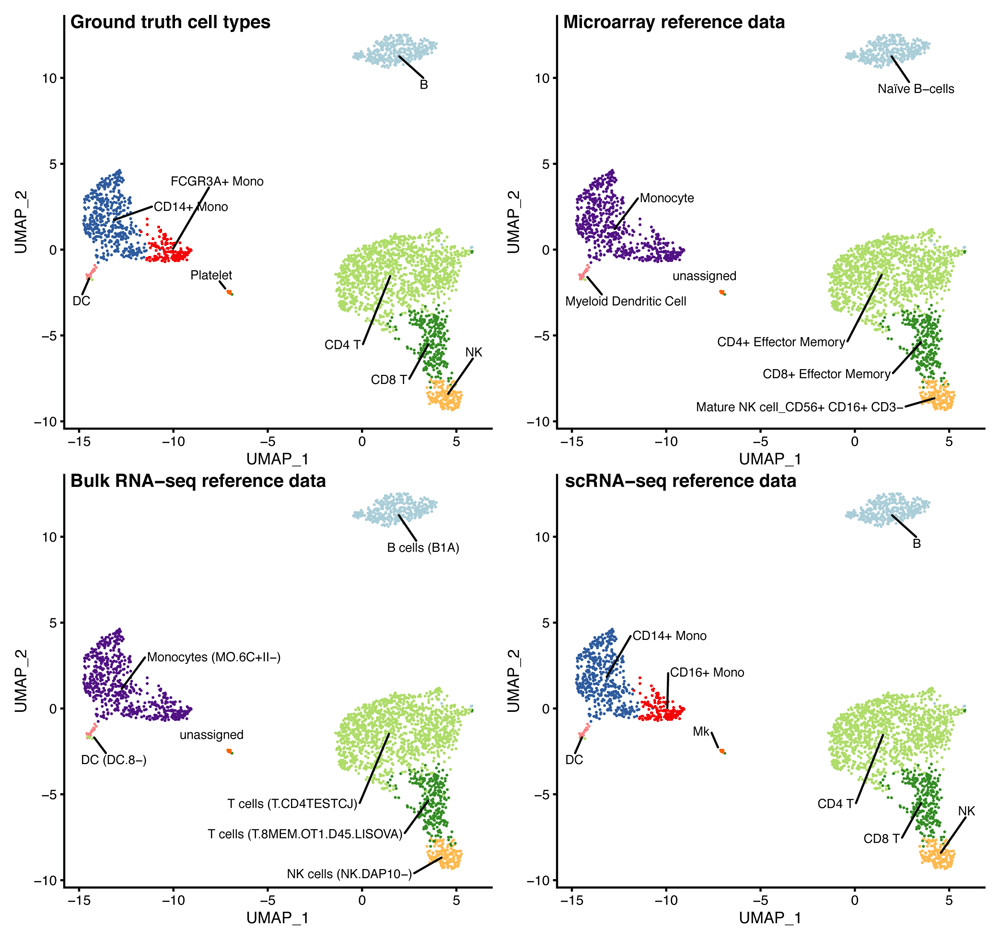
UMAP projections showing the ground truth cell types, or cell types called by clustifyr using different data sources (microarray or bulk RNA-seq data from purified cell types, or scRNA-seq data).
To assess the performance of clustifyr, we used the Tabula Muris dataset5, which contains data generated from 12 matching tissues using both 10x 3’ end seq (“drop”) and SmartSeq2 (“facs”) platforms. Using references built from “facs” Seurat objects, we attempted to assign cell type identities to clusters in “drop” Seurat objects. In benchmarking results, clustifyr is comparably accurate versus other automated classification packages (Figure 4A). Cross-platform comparisons are inherently more difficult, and the approach used by clustifyr is aimed at being platform- and normalization-agnostic. Mean runtime, including both reference building and test data classification, in Tabular Muris classifications was ~ 1 second if the required variable gene list is extracted from the query Seurat object. Alternatively, variable genes can be recalculated by other methods such as M3Drop23, to reach similar results. Correlation-based clustifyr classification performed better than hypergeometric-based gene list enrichment as implemented in clustify_lists.

A) Accuracy and run-time of classifications generated by clustifyr or existing methods using the Tabula Muris to benchmark cell type classifications across sequencing platforms. Each point represents a different tissue comparison. B) Performance comparison of clustifyr to existing methods by subsampling the Tabula Muris dataset. Cell numbers are listed in the facet labels. C) Performance comparison of clustifyr to existing methods testing against Allen Institute Brain Atlas data containing 34 cell types.
For scalability benchmarking, we adapted scRNAseq_Benchmark subsampling for the Tabula Muris dataset. Once again, clustifyr is accurate and efficient, compared to other developed methods (Figure 4B). We also reached similarly satisfactory results in scRNA-seq brain transcriptome data from mouse and human samples, as detailed by scRNAseq_Benchmark pipeline using data from the Allen Institute Brain Atlas13 (Figure 4C).
clustifyr was tested against scmap v1.8.08, SingleR v1.0.19, Seurat v3.1.114, latest GitHub versions of ACTINN11 and scPred12, and SVM as implemented in python3 scikit-learn v0.19.124. scRNA-seq Tabula Muris data was downloaded as seuratV2 objects. Human pancreas data wasdownloaded as SCE objects. In all instances, to mimic the usage case of clustifyr, clustering and dimension reduction projections are acquired from available metadata, in lieu of new analysis.
An R script was modified to benchmark clustifyr following the approach and datasets of scRNAseq_Benchmark13, using M3Drop23 variable gene selection for every test. R code used for benchmarking, and preprocessing of other datasets, in the form of matrices and tables, are documented in R scripts available in the clustifyr and clustifyrdata GitHub repositories.
We present a flexible and lightweight R package for cluster identity assignment. The tool bridges various forms of prior knowledge and scRNA-seq analysis. Reference sources can include scRNA-seq data with cell types assigned (or average expression per cell type, which can be stored at much smaller file sizes), sorted bulk RNA-seq, and microarray data. clustifyr, with minimal package dependencies, is compatible with a number of standard analysis workflows such as Seurat or Bioconductor, without requiring the user to perform the error-prone process of converting to a new scRNA-seq data structure, and can be easily extended to incorporate other data storage object types. clustifyr is designed to perform classification after previous steps of analysis by other informatics tools. Therefore, it relies on, and is agnostic to, common external packages for cell clustering and variable feature selection. We envision it to be compatible with all current and future scRNA-seq processing, clustering, and marker gene discovery workflows. Benchmarking reveals the package performs well in mapping cluster identity across different scRNA-seq platforms and experimental types. As we and others observe25, novel algorithms may not be necessary for cell type classification, at least within the current limitations of sequencing technology and our broadstroke understanding of cell “types”. Rather, the generation of community curated reference databases is likely to be critical for reproducible annotation of cell types in scRNA-seq datasets.
On the user end, clustifyr is built with simple out-of-the-box wrapper functions, sensible defaults, yet also extensive options for more experienced users. Instead of building an additional single-cell-specific data structure, or requiring specific scRNA-seq pipeline packages, it simply handles basic data.frames (tables) and matrices (Figure 1). Input query data and reference data are intentionally kept in expression matrix form for maximum flexibility, ease-of-use, and ease-of-interpretation. Also, by operating on predefined clusters, clustifyr has high scalability and minimal resource requirements on large datasets. Using per-cluster expression averages results in rapid classification. However, cell-type annotation accuracy is therefore heavily reliant on appropriate selection of the number of clusters. Users are therefore encouraged to explore cell type annotations derived from multiple clustering settings. Additionally, assigning cell types using discrete clusters may not be appropriate for datasets with continuous cellular transitions such as developmental processes, which are more suited to trajectory inference analysis methods. As an alternative, clustifyr also supports per-cell annotation, however the runtime is greatly increased and the accuracy of the cell type classifications are decreased due to the sparsity of scRNA-seq datasets, and requires a consensus aggregation step across multiple cells to obtain reliable cell type annotations.
To further improve the user experience, clustifyr provides easy-to-extend implementations to identify and extract data from established scRNA-seq object formats, such as Seurat14, SingleCellExperiment15, URD4, and CellDataSet (Monocle)26. Available in flexible wrapper functions, both reference building and new classification can be directly achieved through scRNA-seq objects at hand, without going through format conversions or manual extraction. The wrappers can also be expanded to other single cell RNA-seq object types, including the HDF5-backed loom objects, as well as other data types generated by CITE-seq and similar experiments27. Tutorials are documented online to help users integrate clustifyr into their workflows with these and other bioinformatics software.
clustifyr is available from Bioconductor:https://bioconductor.org/packages/devel/bioc/html/clustifyr.html
Up-to-date source code, tutorials, and prebuilt references available from: https://github.com/rnabioco/clustifyr
Archived source code as at time of publication:https://doi.org/10.5281/zenodo.371858828
Data used in examples and additional prebuilt references available from: https://github.com/rnabioco/clustifyrdata
License: MIT
Original raw data used in benchmarking is available from the following sources:
| Dataset | Source |
|---|---|
| PBMC 3k Seurat V3 object | https://www.dropbox.com/s/63gnlw45jf7cje8/pbmc3k_final.rds?dl=0 |
| CBMC CITE-seq | Accession number, GSE100866: ftp://ftp.ncbi.nlm.nih.gov/geo/series/GSE100nnn/GSE100866/suppl/GSE100866_CBMC_8K_13AB_10X-RNA_umi.csv.gz |
| Hematopoiesis microarray data | Accession number, GSE24759:https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE24759 |
| Tabula Muris as Seurat V2 objects | https://figshare.com/projects/Tabula_Muris_Transcriptomic_characterization_of_20_organs_and_tissues_from_Mus_musculus_at_single_cell_resolution/27733 |
| Mouse Cell Atlas | https://doi.org/10.6084/m9.figshare.5435866.v8 |
| Pancreatic scRNA-seq as SingleCellExperiment objects | https://hemberg-lab.github.io/scRNA.seq.datasets/ |
| Allen Institute Brain Atlas | http://celltypes.brain-map.org/rnaseq |
| PBMCbench | https://singlecell.broadinstitute.org/single_cell/study/SCP424/single-cell-comparison-pbmc-data |
| PBMC rejection test | http://scibet.cancer-pku.cn/document.html |
| ImmGen Database | http://www.immgen.org/ |
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)