Keywords
Generative Adversarial Network, De novo Protein Design, Machine Learning, Neural Network, Deep Learning, Helical Proteins, Protein backbone, Long Short-Term Memory
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the INCF gateway.
Generative Adversarial Network, De novo Protein Design, Machine Learning, Neural Network, Deep Learning, Helical Proteins, Protein backbone, Long Short-Term Memory
The concept of amino acid sequences folding into globular protein molecules allows for proteins’ large functional diversity, mediating all the functional aspects of living organisms, thus winning themselves attention from biochemists for decades. The fusion of machine learning with computational biology is accelerating research in both fields and bringing humanity closer to the setup of performing most biological research quickly, cheaply, and safely in silico, while only translating the very crucial aspects of it. Having access to a large database of protein crystal structures has led to the use of machine learning to design proteins computationally.
De novo protein design (i.e. from the beginning) is very well explained in this review1. Proteins fold into a specific shape depending on the sequence of their amino acids, and of course shape dictates function. The driving forces that allow proteins to fold are the hydrogen bond interactions within the backbone and between the side chains, the Van der Waals forces, and principally the interaction of hydrophobic side chains within the core. The space of all possible sequences for all protein sizes is extremely large (as an example there are 20200 possibilities for a 200-residue protein). Thus, is it not surprising that natural proteins exist in clusters close to each other, which is logical since proteins would evolve away from a central functional protein to fold correctly and acquire new folds and functions, rather than go through the tedious ordeal of finding a totally new protein structure within the space of all possibilities. Thus, even though the Protein Data Bank adds about 10,000 new structures to its repository every year, most of these new structures are not unique folds.
The relationship between the sequence of a protein and its specific structure is understood, but we still lack a unified absolute solution to calculate one from the other. Hence why some research groups generated man-made protein designs by altering already existing natural proteins2, since randomly finding a functionally folded protein from the space of all possible protein sequences is more or less statistically impossible. On the other hand, other researchers have attempted de novo protein design by designing a topology from assembling short sequence peptide fragments taken from natural protein crystal structures3,4, these fragments are calculated statistically depending on the secondary structures they are found in. Sometimes this fragment system is combined with first physical principals to model the loops between secondary structures to achieve a desired three-dimensional topology5. Others have used parametric equations to study and specify the desired protein geometry6–11. These solutions employ an energy function, such as REF2015, that uses some fundamental physical theories, statistical mechanical models, and observations of protein structures to approximate the potential energy of a protein12. Knowing the protein potential energy allows us to guide our search for the structure of a protein given its sequence (the structure resides at the global energy minima of that protein sequence) thus attempting to connect the sequence of a protein with its structure. The critical tool is the energy function, the higher its accuracy the higher our confidence in knowing the computed structure is the real natural structure. Thus, using the energy function to perform structure prediction (going from a known sequence to find the unknown three-dimensional structure) can also be used to perform fixed-backbone design (going from a known three-dimensional structure to find the sequence that folds it). This is where this paper comes in. Where as in de novo design neither backbone nor sequence is known, knowing one results in finding the other using the same energy function1, and a good starting point is to design the backbone.
Other researchers have used machine learning for protein sequence design, employing the constraints (Cα-Cα distances) as the input features for the network and using a sliding window to read a sequence of residues, getting their types and constraints then predicting the next one giving the output prediction as an amino acid sequence13, this architecture reported an accuracy of 38.3% and performs what is called sequence design: designing a sequence for a backbone, so when the protein is synthesised it folds to that backbone. In fact, in the 5 paper the protocol first generates an all-valine backbone, then sequence designs that backbone. In this paper, we want to computationally generate a backbone so it can be sequence designed using other protocols such as RosettaDesign14,15 or the protocol from 13.
The protein’s backbone can be folded using the ϕ and ψ angles, which are the angles between Cα and N for ϕ and Cα and C for ψ that primarily move in an amino acid’s backbone (not the side chains), and thus can be used as features to control the topology of a backbone. They were even one of the features used to fold proteins and predict their structures in AlphaFold16.
But the question is: how do we decide the ideal angles for a helix, the length of each helix, the number of helices, as well as the lengths and angles of the loops between the helices that will also result is a compact folded protein backbone. These numerous values can be solved statistically using neural networks. Especially that we want to use the structures in the PDB to forward design (rather then discover) new protein folds that are not resulted from evolution.
The deep neural network architecture that we chose was a long short-term memory (LSTM) based generative adversarial network (GAN)17. The LSTM is usually used in natural language and data sequence processing, but in our model the LSTM was incorporated into a GAN. The model was constructed from two networks that worked against each other, the first was a generator network that was made up of a stack of LSTM layers, followed by fully connected layers, followed by a mixture density network (MDN) and worked by using random noise numbers as input to build the values for the ϕ and ψ angles. The other network was a discriminator that was made up of a stack of LSTM layers followed by fully connected layers and worked to studying the dataset and determining whether the output from the generator was a truly logical structure or not (fake or real)18.
Our effort in this paper was to use machine learning to learn the general fold of natural proteins, and using this generalising statistical concept to design novel protein backbone topologies, thus only getting the three dimensional backbone structure so it can be used in sequence design using other protocols. Our research at this moment was a proof of concept and only concerned with getting a new and unique folded ideal helical protein backbone rather than a protein with a specific sequence, nor a function, nor a specific predetermined structure. Our system resulted in random yet compact helical backbone topologies only.
The following steps were used to generate the augmented training dataset, along with details of the neural network architecture and how the output was optimised then evaluated.
The entire PDB database was downloaded on 28th June 2018 (~150,000 structures), and each entry was divided into its constituent chains resulting in individual separate structures (i.e: each PDB file had only a single chain). Each structure was analysed and chosen only if it contained the following criteria: contained only polypeptides, had a size between 80 and 150 amino acids without any breaks in the chain (a continuous polypeptide), a sum of residues that made up helices and sheets were larger than the sum of amino acids that made up loops, and the final structure having an Rg (radius of gyration) value of less than 15 88 Å. The chosen structures were then further filtered by a human to ensure only the desired structure concepts were selected, removing the structures that slipped through the initial computational filter. Furthermore, a diversity of structure folds were achieved rather than numerous repeats of the same fold (the haemoglobin fold was quite abundant). In previous attempts, a mixture of different structure classes were used, where some structures were only helices, some were only sheets, and the remaining were a mix of the two. However, that proved challenging in optimising the network, and as such a dataset made up of only helical protein structures was chosen for this initial proof of concept. The final dataset had 607 ideal helical structures. These structures were then cleaned (non-amino acid atoms were removed) in preparation to push them through the Rosetta version 3 modelling software that only takes in polypeptide molecules.
These 607 structures were augmented using the Rosetta FastRelax protocol19. This protocol performs multiple cycles of packing and minimisation. In other words, the protocol performs small slight random angle moves on the backbone and side chains in an attempt to find the lowest-scoring variant, but the random backbone angle moves is what we were after. Its originally intended function was to move a structure slightly to find the conformation of the backbone and side chains that corresponds to the lowest energy state as per the REF15 energy function. Since the protocol performs random moves, a structure relaxed on two separate occasions will result in two molecules that look very similar with similar minimum energy scores, but technically have different ϕ and ψ angle values. This is the concept we used to augment our structures, and each structure was relaxed 500 times to give a final dataset size of 303,500 structures.
Using only the ϕ and ψ angle values from a crystal structure it was possible to re-fold a structure back to its correct native fold, thus these angles were the only relevant features required to correctly fold a structure, Figure 1A details the range of angles in the un-augmented data. Each amino acid’s ϕ and ψ angle values were extracted and tabulates as in Table 1. This was the dataset used to train the neural network.
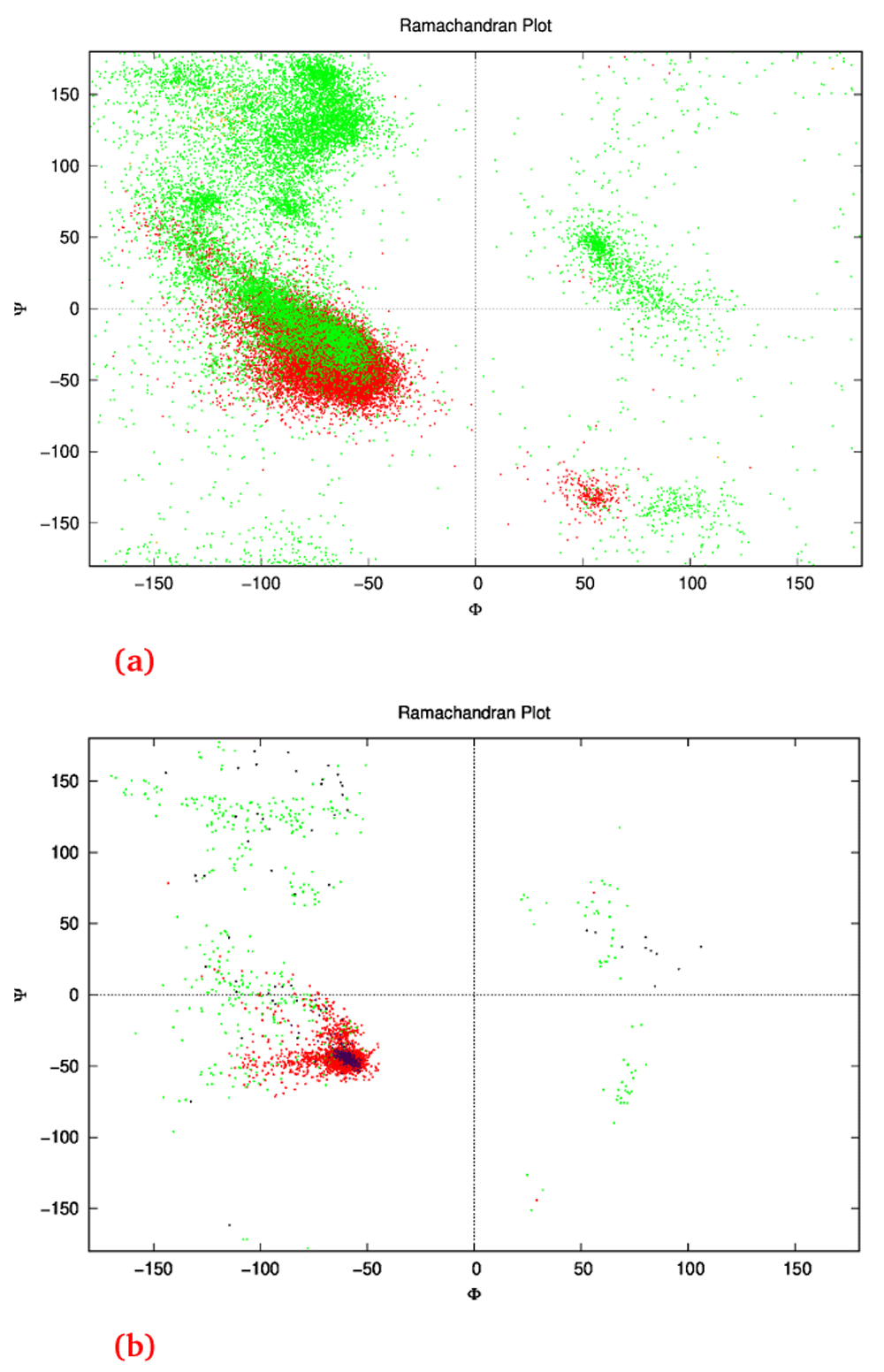
7A: Ramachandran plot of the dataset showing the ϕ and ψ angles of each amino acid for each structure. This is the unaugmented data of structures that are only made of helices. Green represents the angles on amino acids in loops, while red represents the angles of amino acids in helices. Some orange can be seen where the DSSP algorithm classified the amino acids as sheets (though there were none). One point to note; the angles here are represented between the range −180° to 180° as is conventional, while in the actual dataset the range was from 0° to 360°. 7B: The network’s output ϕ and ψ angles for 25 structures after the relaxation step. The green dots represent the angles of amino acids within loops, and red within helices clustering around the same location as Figure 1A within the fourth quadrant as is desired for an α-helix that has ideal angles around (−60°,−45°). These structures culminated to all 25 structures in Figure 4, and had an angle range for the helices (−127.4°<ϕ<−44.7°, −71.3°<ψ<30.6°) not including the outliers. The purple dots represent the helices in the control structures, and the black dots the loops.
The model in Figure 2 was built using the SenseGen model as a template18 and consisted of two networks: a generator G network and a discriminator D network. The G network was constructed from an LSTM layer with 64 nodes, followed by two dense fully connected MLPs with 32 nodes for the first layer and 12 nodes for the second one, both employed a sigmoid activation function:
Which was followed by an MDN layer employing an MDN activation function:
c: the index of the corresponding mixture component. α: the mixing parameter. 𝓓: the corresponding distribution to be mixed. λ: the parameters of the distribution 𝓓, as we denote 𝓓 to be a Gaussian distribution, λ1 corresponds to the conditional mean and λ2 to the conditional standard deviation. The training was done using the Adam optimiser, for each parameter ωj:
η:
η: initial learning rate. vt: exponential average of squares of gradients. gt: gradient at time t along ωj. The Adam optimiser had an MDN activation through time loss function defined to increase the likelihood of generating the next time step value. The loss defined as the root mean squared difference between the sequence of inputs and the sequence of predictions:
yt: output. xt: next step sample xt+1 = yt. The D network was constructed from an LSTM layer with 64 nodes, followed by a dense fully connected MLP layer with 32 nodes, and that was followed by a single dense MLP unit layer employing a sigmoid activation function, so that the output of this network was a prediction; the probability of the data being real (indicated by the integer 1) or fake (indicated by the integer 0). The network employed the cross-entropy loss function:
Where ti and si are the groundtruth and the neural network score for each class i in C. In a binary classification problem, such as the discriminator network output where C′= 2, the Cross Entropy Loss can be defined as:
Where it is assumed that there are two classes: C1 and C2. t1 [0,1] and s1 are the groundtruth and the score for C1, while t2 = 1 – t1 and s2 = 1 – s1 are the groundtruth and the score for C2. The G network used random noise as a starting seed, this noise was generated by taking a single randomly distributed number between [0, 1) as the first predicted values, these values were then reshaped to the same shape of the last item of the predicted value resulting in a final shape of (batch_size, step_number, 1). The network predicted the main parameters of the new value (µ, σ, π) several times (according to the number_of_mixtures value) and selected the single mixture randomly but according to the π value. It then predicted the next value according to the normal distribution using the µ and σ values. It added the final value to the prediction chain and then returned to step 2 until the predefined sequence length was obtained. The initial random number was stripped from the returned sequence. Once the networks were constructed, the dataset was normalised and the training was done as follows for each adversarial epoch:
1. Sample minibatch from dataset (Xtrue).
2. Sample minibatch from G network (XG).
3. Train the D network on the training set (Xtrue, XG).
4. Sample minibatch from dataset (Xtrue).
5. Sample minibatch from G network (XG).
6. Train the G network on the training set (Xtrue).
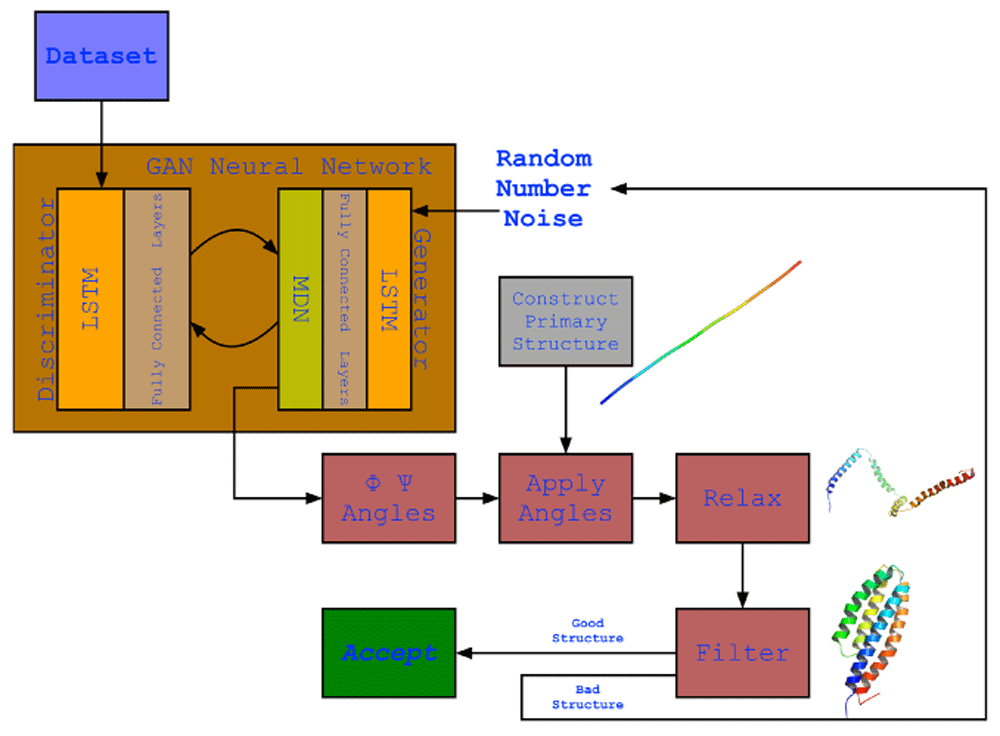
The full protocol showing the structure of the neural network model and its output. The model employing an LSTM within the generative network and another one within the discriminator network, these two networks work adversarially against each other. The network’s output is the generated ϕ and ψ angles which were applied to a primary structure (a fixed 150 valine length straight structure generated by PyRosetta) that resulted in the development of the secondary structures but not a final compact structure structure due to suboptimal loop structures as a result of their variability in the dataset. To overcome this, the structure was relaxed to bring bring the secondary structure helices together. This did result in more compact structures but was not always ideal, thus a filter was used to filter our non-ideal structures and keep an ideal structure when generated.
The neural network had the following parameters: the G learning rate was 0.001 while the D learning rate was 0.0003, a drop out rate of 50% was used along with a batch size of 4 over 18,000 epochs.
The output of the neural network was always a 150 ϕ and ψ angle value combination for a structure with 150 amino acids. A straight chain of 150 valines was computationally constructed using PyRosetta and used as a primary structure. Each amino acid in the primary structure had its angles changed according to the ϕ and ψ angle values, which ended up folding that primary structure resulting in secondary structures of helices and loops between them. The COOH end was trimmed, if it was a loop, until it reached the first amino acid that comprised a helix, thus variable structure sizes where generated. The structure ended up with helices and loops yet still with an open conformation. The generated structure was therefore relaxed using PyRosetta version 4 FastRelax protocol to idealise the helices and compact the structure. Furthermore, not every prediction from the neural network resulted in an ideal structure even after the relax step, therefore we employed a filter to filter out structures we deemed not ideal. The filter discards structures that were less than 80 amino acids, has more residues in loops than in helices, has less than 20% residues making up its core, and has a maximum distance between Cα1 and any other Cα greater than 88 Å (the largest value in the dataset). PyRosetta was used20 since it was easier to integrated the code with the neural network’s python script and combine the Rosetta engine with Biopython21 and DSSP22,23.
As a control we used the de novo protein design protocol using the Rosetta Script from the 5 paper’s supplementary material. The protocol was modified slightly to accommodate new updates in the Rosetta software suite, but maintained the talaris2014 energy function as in the original paper, and we used the protocol to design helical proteins. These proteins had to pass through several filters including a talaris2014 score of less the -150, a packing threshold of more than 0.50, and a secondary structure threshold of more than 0.90. We attempted to design proteins with 3, 4, and 5 helices to compare the backbone quality our neural network output to the output of the 5 paper.
This setup used the following packages: python 3.6.9, PyRosett 4, Rosetta 3, Tensorflow 1.13.1, BioPython 1.76, and DSSP 3.01 and was run on GNU/Linux Ubuntu 19.10. Further information on running the setup can be found on this GitHub repository which includes an extensive README file. To train the neural network a 3GB GPU and 12GB of RAM is recommended, while to run the trained neural network and generate a backbone structure an Intel i7-2620M 2.70GHz CPU and 3GB of RAM is recommended.
Detailed in Figure 2, executing the trained network will generate a set of random numbers that are pushed through the Generator network which (using the weights) will modify the values to become values in accordance with the ϕ and ψ angle topologies observed in the training dataset. A simple straight chain of 150 valines is then computationally constructed and the ϕ and ψ angles are applied to each amino acid in order, resulting in the appearance of helical secondary structures. Any tailing loops at the COOH end will be cut out since it interferes with the next step. This structure is then relaxed using the FastRelax protocol which moves the ϕ and ψ angles randomly in its attempt to find the lowest scoring configuration compacting the structure in the process. A filter is applied to determine whether the final structure is ideal or not, its parameters are detailed in the Methods section. If the structure passes the filter the script exists, otherwise it repeats the whole process.
The dataset was named PS_Helix_500 due to the fact that the features used were the ϕ and ψ angles, only strictly helical protein structures were used, and each structure was augmented 500 times.
The neural network was trained on the dataset for 18,000 epochs (further training collapsed the network, i.e. all outputs were exactly the same structure) with a generally sloping down mean loss as shown in Figure 3 indicating that the G network got better at generating data that the D network classified as real rather than fake. The network was used to generate the ϕ and ψ angles for 25 structures. In other words, random numbers were generated then pushed through the G network where they were modified (using the network’s trained weights) to become the ϕ and ψ angles for 150 residues. This is the angle profile. Using PyRosetta, a simple straight 150-valine chain was constructed and used as a primary structure. The generated ϕ and ψ angles were applied to this primary structure (each amino acid’s angles were changed according to the angle profile) resulting in a folded structure clearly showing helical secondary structures with loops between them. The last tailing loop at the COOH end was truncated, resulting in structures with variable sizes. The loop angles were within the area of the angles found in the dataset, but because they were generated independent of the thermodynamic stability of the structure, the structure did not come together into compact a topology. To push the structure into a thermodynamic energy minima it was relaxed using the PyRosetta FastRelax function which compacted the backbone topology while still having valines as a temporary placeholder sequence. This was repeated 25 times to result in the 25 structures in Figure 4. For comparison five control structures were generated using the de novo design protocol by the previous paper5. Figure 1B shows the Ramachandran plot of the 25 generated structures, where red are the amino acids within helices having angles clustering around the same location as Figure 1A in the fourth quadrant, as is desired for an α-helix, which has ideal angles around (−60°, −45°), our results had an angle range for the helices (−127.4°<ϕ<−44.7°, −71.3°<ψ<30.6°) not including the outliers, the five control structures show angles within the same region (purple for helices and black for loops). The structure generation setup was not perfect at achieving an ideal structure every time, so a filter was deployed to filter out suboptimal structures by choosing a structure that had more residues within helices than within loops, was not smaller than 80 residues, and had more than 20% residues comprising its core. Due to the random nature of the structure generation the efficiency of the network is variable, while generating the 25 structure in Figure 4 the fasted structure was generated after just 4 failed structures, while the slowest structure was generated after 3834 failed structures giving a success rate for the network between 25.0% at its best and 0.025% at its worst, and this took between ~1 minute and ~6 hours to generate a single structure with the desired characteristics utilising just 1 core on a 2011 MacBook Pro with with 4 core Intel i7-2620M 2.70GHz CPU, 3GB RAM, and 120GB SSD. For comparison the protocol by 5 took ~60 minutes for each of the control structures on the same machine. The protocol is summarised in Figure 2, and the results are compiled in Figure 4 showing all 25 structures and the 5 controls.
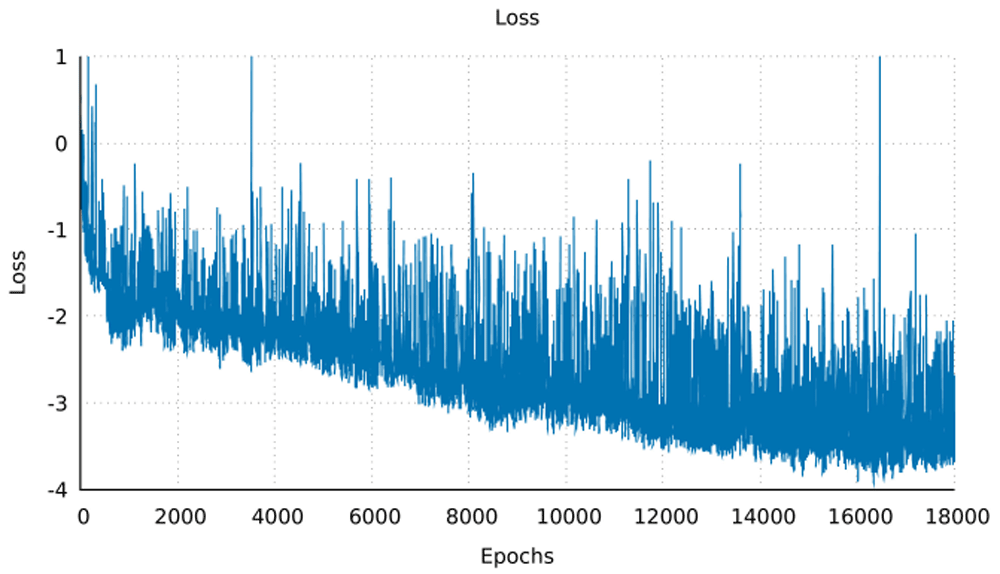
The mean loss of the whole network over epoch, for 18,000 epochs, showing a general downward trend. This indicates that in subsequent epochs the G network gets better at generating structures that the D network correctly classifies as real logical structures.

This figure shows all 25 structures that were generated using the neural network displayed using PyMOL24. It can be seen that all structures have compact helical structures of variable topologies. The 5 control structures at the bottom were generated using the protocol from the 5 paper showing better helices but similar compactness.
These 25 structures had on average 84.7% of their amino acids comprising their helices, along with and an average of 29.9% of their amino acids comprising their cores, Table 2 shows the Rosetta packing statistic for all 25 structures, along with the five controls, the top7 protein, and the five structures from the 5 paper all showing similar packing values.
The controls were the structures generated using the modified protocol from 5. For additional comparison the top7 (PDB ID: 1QYS)25 protein packing stat is measured along with the five structures from the protocol paper by 5.
In this paper we outlined how a neural network architecture can design a compact helical protein backbone. We attempted to test our network to generate structures that included sheets, but that failed, mainly due to the wide variation in the loop angles that did not compact a structure to bring the strands together, which sheets rely on more to develop compared to helices.
We demonstrated that the ϕ and ψ angles were adequate features to design a protein backbone topology only without a sequence. Although we understand the distribution of angles in the Ramachandran plot (the distribution of helix and sheet angles) the neural network’s power comes in the form of combining several dimensional spaces to take a better decision. Given its observation of natural proteins, it can calculate the ideal combination of angles that results in deciding the number and lengths of helices, the loops between them, that will still result in a compactly folded protein backbone.
The reason we concentrated our efforts on generating a backbone only is because once a backbone is developed it can be sequence-designed using other protocols, such as RosettaDesign14,15 or the protocol from 13.
Though our network had a wide variation of success rates, from high to low, that was due to the random nature of the setup, which was our target to begin with (to randomly generate backbone topologies rather than directly design a specific pre-determined topology). Generating multiple structures and auto filtering the suboptimal ones provided an adequate setup, this achieved our goal of de novo helical protein backbone design within a reasonable time (1–6 hours) on readily available machines.
As a control we used a slightly modified de novo design protocol from 5, which also performs backbone design (resulting in an all-valine backbone topology) followed by sequence design of that backbone. It has numerous advantages such as generating better helices, but the user must still pre-determine the topology to be generated (decide the number of helices, their lengths and locations, and the lengths of the loops between them), while this neural network automatically takes that decision and randomly generates different backbones, which can be very useful for database generation (see below).
The neural network is available at this GitHub repository which includes an extensive README file, a video that explains how to use the script, as well as the dataset used in this paper and the weights files generated from training the neural network.
For future work we are currently working on an improved model that uses further dataset dimensions and features that will allow the design of sheets.
There are many benefits to generating numerous random protein structures computationally. One benefit can be in computational vaccine development, where a large diversity of protein structures as scaffolds is required for a successful graft of a desired motif26–28. Using this setup, combined with sequence design, a database of protein structures can be generated that provides more variety of scaffolds than what is available in the protein databank, especially that this neural network is designed to produce compact backbones between 80 and 150 amino acids, which is within the range of effective computational folding simulations such as AbinitioRelax structure prediction simulation29.
Source code available from: https://github.com/sarisabban/RamaNet.
Archived Source code at time of publication: https://doi.org/10.5281/zenodo.3755343 [?]30.
License: MIT License.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)