Keywords
Occupational Structure, Statistics, Intergenerational Mobility
Occupational Structure, Statistics, Intergenerational Mobility
Changes are made in order to improve readability and remove some misunderstandings that were seen in the reports. This includes edits to Tables. Detailed list of changes can be found in responses to the reviews.
See the authors' detailed response to the review by Gregory Clark
See the authors' detailed response to the review by Jan Stuhler
Recently usage of surnames in studies of intergenerational mobility, such as investigations of temporal changes of representations of different surnames in various social groups, has developed into an established tool of research (see e.g. Clark, 2015; Clark, 2012; Clark et al., 2015; Güell et al., 2015 and references therein; Santavirta & Stuhler, 2019 for a recent review). In a typical study, the frequency of occurrence of certain surnames in different professional or elite or other population groups is considered. This frequency is compared with the frequency of the surname’s occurrence in the general population. If it is found that the surname occurs in some group significantly more than in the general population, then the surname is overrepresented in the group. Conversely, if the surname occurs less, then it is underrepresented.
Probably the main result of the aforementioned extensive studies is that the over- or under-representations do not change over long periods of time, much longer than would be implied by the conventional mobility measures. Those measures average over society, thus hiding the underlying low mobility rates for a given surname. These studies have been performed for different countries and cultures (see Clark, 2015 and references therein).
In this work, we perform a study for a population of Russian-speaking Jews who have not been so far considered in this type of study. We investigate occupational distribution of three different groups in the population that are defined by different biases in the occupational distribution of their ancestors. The size of 9315 individuals of the studied pool of data allows us to derive rigorous statistics of the groups (we use here rounding, explained below). We demonstrate that the distributions are different beyond the uncertainty allowed by the confidence interval. This finding shows that biases in occupational distributions can be preserved for at least two centuries that passed, since all Jews have had an inherited surname. This provides yet another demonstration of comparatively slow surnames’ mobility, defined as social mobility of individuals with a given surname, (Clark, 2015). Our results also provide the occupational distribution of the Russian speaking Jewry of the twentieth century, a result that has its own interest.
The objectives of our study are quite similar to those of Clark (2012), where the statistics of several groups of surnames in Sweden are considered. Clark (2012) considered noble surnames, names that were once given to nobility; Latinized surnames were adopted by the educated class and certain other groups. Similarly, we consider rabbinical surnames (counterpart of nobility), surnames of craftsmen (hereafter called occupational), and others that fall outside of these categories (generic).
Rabbinical surnames are those whose first bearer was a rabbi. Rabbis constituted the elite of their time, the most respected class of the Jewish population, and they can be considered as a kind of the Jewish nobility. The rabbi of the surname’s origin could be a prominent figure living many centuries ago, for example as in the case of Luria, Shapiro or Halperin. Family names of these dynasties were often taken as a sign of distinction. However, other rabbinical families are “only” two hundred years old, for example Rabinovich. For these clans, in the beginning of their history, the profession of the rabbi was often passed from father to son for a number of generations. Occupational surnames derive from the name of the craft of the first bearer of the name. Craftsmen had the knowledge of their craft and present a rough counterpart to the educated class considered by Clark (2012), for example Schuster (shoemaker), Mednik (tinker) and Portnoi (tailor). In these families the professions were also often passed between generations. Finally, generic surnames consist mostly of surnames whose origin has nothing to do with the professions of their founder. Formation of Jewish surnames with few exceptions finished by the beginning of the 19th century, see e. g. Beider, 2008.
Our data was acquired over four years (November 2015 – February 2020) from individuals who were part of an educational family history program that was implemented by the Am haZikaron Institute for Science and Heritage of the Jewish People in Tel Aviv, Israel. Our program was obligatory for participants of a larger, very inclusive program so that to the best of our knowledge the only bias in the sample was some degree of affiliation with the Jewish people.
The individuals were Russian-speaking Jewish family members residing in the Former Soviet Union (FSU). They voluntarily provided genealogical data for the program via online forms that were sent to them before their arrival in Tel Aviv (see section Data collection). The forms were presented in the native language of the individual (Russian) and informed the individuals that their data could be used for future academic purposes. Completion of the form was taken as consent to allow their data to be used for this academic study (some participants chose not to complete the form). This study did not seek ethical approval as it was deemed low risk, none of the participants were considered vulnerable, the participants consented for their data to be used in future academic research, and all participants were over 18 years of age.
Data from an individual was not selected for inclusion in this study if it was intentionally distorted. Data verification was accomplished during a meeting in Tel Aviv between the authors. Upon the completion of the educational program, the participants returned to their home countries.
Information was obtained on professions of a participant’s family members for the last four generations. This resulted in a collection of data on individuals who were born throughout the 20th century. The educational programs at Am haZikaron are open to all, and so there was no known statistical bias toward any particular professions. Similarly, there is no known correlation between the starting letter of the name and the profession. Hence, to the best of our judgement, the obtained data, arranged alphabetically, is a random list of Jewish individuals and their professions. The randomness holds up to small clusters of individuals who belong to the same family and have some correlations. These correlations are yet to be studied and are not the focus of our study. It will be seen later that randomness is consistent with the statistics.
In the research by Clark et al. (Clark, 2015; Clark, 2012; Clark et al., 2015), the major source of information were professional directories that list all individuals in a particular professional area. In contrast, our data is a random pool of the population that necessitates a different methodology for analysis. We partitioned the population into the three groups of surnames (rabbinical, occupational, generic), which could be biased with respect to their occupational distribution due to the bias in their ancestry. We checked if the bias persists through time and found that there is a statistically significant difference in the professional preferences of the three groups.
We collected the data over four years until the pool included a statistically significant amount of surnames where the confidence interval allowed to reasonably fix the share of each profession in the total population. We obtained data on 858 (57.8.% men) bearers of rabbinical and 1057 (59.7% men) bearers of occupational surnames. The other 7471 (57.6% men) individuals had a generic surname, which was neither rabbinical not occupational. Men are slightly overrepresented since the maiden names of the female family members were sometimes unknown to the participants. This slight difference in gender composition of the groups may cause some professional bias; however, this is negligible compared with the magnitude of the groups’ differences (shown below).
The studied population included different birth cohorts. The earliest birth date for an individual in the data was 1858 and the latest 2001. We did not perform separate study of different cohorts since the data available for them would not be statistically significant. For adequate comparison of the groups, we must have roughly the same share of each group born in each of the considered generations. Therefore, we divided the historical period spanned by our data into four periods (1858–1894, 1895–1930, 1931–1966, 1967–2001; Table 1).
| Generation born | Surname (%) | ||
|---|---|---|---|
| Rabbinical | Occupational | Generic | |
| 1858–1894 | 2.0 | 2.3 | 2.2 |
| 1895–1930 | 44.8 | 46.3 | 43.7 |
| 1931–1966 | 37.4 | 35.6 | 38.0 |
| 1967–2001 | 15.8 | 15.8 | 16.1 |
From Table 1, it is seen that the birth date distributions of the groups are very similar so that the comparison of occupations is reasonable. The difference of shares of different generations holds for many reasons: each participant was asked to fill the data for two parents, four grandparents and eight great grandparents, where the data on the older generations was often forgotten, while the younger generation could still be studying or have no profession yet. However, the precise form of the birth date distribution is irrelevant for our comparative study, for only birth date distributions of different groups are similar.
The birthplaces were scattered all over the territory of the FSU. Jewish families have a long tradition of studying and those who would want to acquire education would typically receive such an opportunity. In other words, with a good approximation, an individual born into a Jewish family of the FSU would have an equal opportunity for getting that or another profession irrespective of birthplace. Therefore, we disregarded the geographical factor in our study.
No detectable bias toward some profession due to a different number of reported family members was observed. This number was never too large, and rarely reached five individuals (other ancestors were not Jewish and not considered by our study).
The data on professions was self-reported in the native (Russian) language of the participant and was not standardized. We processed the data to a standard of occupations according to the methodology below.
Grouping the data by profession. We separated the data into the three groups described (rabbinical, occupational, generic). We then grouped the professions into 23 narrower professional activities. These were defined either by their significant presence in the data, e.g. bookkeepers who constituted about 5% of all individuals, or by a unique character of the profession, for example interpreter/linguist. The groupings of professions, when performed, did not contradict the International Standard Classification of Occupations. The 23 categories of professions were as follows:
1. Engineer – by far the largest fraction of the studied population
2. Physician
3. Teacher
4. Bookkeeper
5. Worker
6. Creative profession
7. Economist
8. Head/chief officer
9. Nurse
10. Researcher
11. Clerical worker
12. Armed forces
13. Programmer
14. Salesmen
15. Businessman
16. Legal professional
17. Driver
18. Interpreter, linguist
19. Literary worker
20. Pharmacist
21. Librarian
22. Psychologist
23. Rarely occurring profession (other)
We calculated the number of individuals having each one of the above professions for each of the three studied groups of surnames. The main target of our study is the share of each profession (Pi) in each of the considered three groups of surnames. Thus, if N is the total number of members of Russian-speaking Jewish families with a generic surname then Pi*N is the total number of members of these families with the i-th profession. For instance, P21*N would be the total number of librarians. The data on the full group consisting of millions of people (as defined by the fraction of Russian-speaking Jews whose names are neither rabbinical nor occupational where we count not only our contemporaries but all those who lived in the twentieth century) are unavailable. Thus, we have the standard problem of constraining Pi from the incomplete information on the studied groups that is at our disposal. This is done by the statistical analysis relying on the observation that with good approximation our data constitute a random pool of the considered population groups.
A typical result of counting the professions is presented in Table 2 where the example of generic surnames is used. The total pool of data consisted of 7471 individuals. Due to presence of correlated clusters of individuals in the data, we found it instructive to use coarse-grained variables Xi(k) for the statistical calculations. These variables separate the data into blocks of hundreds. In contrast with individual data which is not randomly sampled, the blocks can be be considered as a result of random sampling where a hundred was taken from the population and then, independently, another hundred and so forth, see below. Moreover separation into blocks demonstrates what we can anticipate to see if we pick 100 members from the considered population: for the pool size of 100, the statistical properties are seen already. Frequencies of different professions in each block of 100 are similar with some fluctuations. The usage of the variables Xi(k) is necessary for the statistical considerations as explained in detail below, otherwise they give an idea how the described laws apply in practice when the sample sizes are moderate. The statistics of Xi(k) answers the question – if we took a pool of 100 representatives of one of the groups what would be the typical occurrences of each profession?
The first column provides the profession. The entries of the first row provide the considered range of numbers of people in the list considered in the corresponding column. For instance, the second column describes occupational distribution of 100 individuals with numbers from 1 to 100, the third column describes 100 individuals with numbers from 101 to 200 and so forth. Thus X7(300) is the number of individuals with the profession of economist in the range from 201 to 300. This number is located at the intersection of eighth row and fourth column, X7(300)=2 – our list contains two economists in the portion of the list defined by 201–300 range.
Thus we took out of our pool the first 100 individuals and determined the numbers Xi(100) of individuals with the i-th profession. Then we took 100 more individuals and determined the numbers Xi(200) of individuals with the i-th profession in the range of 101–200. Continuing in this way, we determined Xi(k) determined by the columns in Table 2. We used the pool size up to 1000 because this size allows comparison with the groups of rabbinical and occupational surnames where the total pool was about 1000. Thus, we used the pool of 7471 as the control size that allows to test how well the pool of 1000 individuals represents the whole considered group. Average over a limited pool size k gives an approximation pi(k) for Pi defined above. Up to fluctuations pi(k) monotonously approach Pi on increasing k and we can hope that a reasonable approximation to Pi can be obtained already from the largest k available from our data. Indeed, we demonstrate quantitatively that distributions derived from the pools of 1000 and 7471 individuals are rather similar. Thus, making the reasonable assumption that pool size of 7471 represents the full group accurately, which is proved by the calculation of confidence intervals, we conclude that the occupational distribution of the generic surnames can be derived quite accurately (quantified below) from the distribution of 1000 individuals. Assuming that the groups of bearers of rabbinical and occupational surnames are similar statistically we can then conclude that the distributions for these groups, derived from the study of about 1000 individuals, provide a good characterization of the full groups. Despite that, we rely in our conclusions on the rigorously defined confidence intervals; qualitatively it is probable that the means obtained from studies of 858 rabbinical and 1057 occupational surnames provide accurate idea of the full groups.
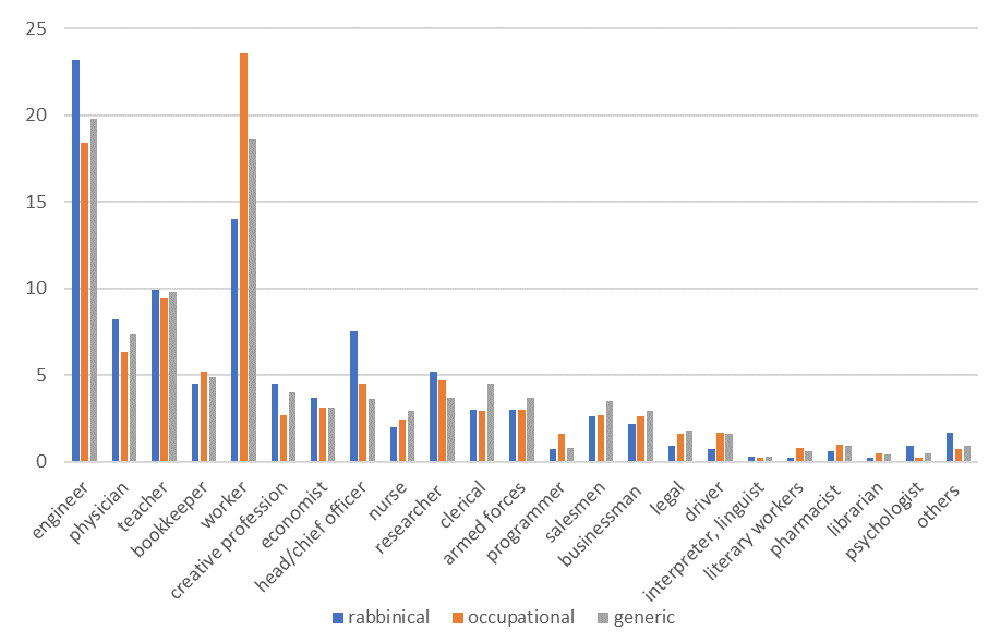
Distance between the distributions. There was a need for quantitative comparison of distributions Pi of the three considered groups (Figure 1). Thus, considering the finite pool sizes’ approximations to Pi in Figure 1 (in %), it is seen that they are different; however how different? To make the comparison, we calculated the distance between the distributions. There is no unique conventional definition of the distance between probability distributions. We used the Hellinger distance (see for example. Yang & Le Cam, 2000), whose definition can be understood by observing that since the distributions are normalized, then what needs the comparison are the shapes of the distributions. For instance, for all three distributions in Figure 1, the heights of all bars sum to 100 and only the shapes distinguish the distributions. The shapes can be compared by considering the overlap, which is conveniently defined by the Bhattacharyya coefficient (Bhattacharyya, 1943):
where k and p are indices of the considered two groups (in this equation and below); when there is a need to indicate to which group Pi refers, we use the notation for the Pi of rabbinical, occupational and generic surnames, respectively. The Bhattacharyya coefficient is the scalar product (type of overlap) of two vectors in 23-dimensional space with components and . The square root is introduced in the definition because are unit vectors in the 23-dimensional space, which allows definition of “the shape of the distribution” as the direction of these unit vectors. The coefficient changes between zero, holding for non-overlapping distributions, and one, holding for identical distributions. The Hellinger distance between the distributions is then defined as:
Thus, H(k, p) is proportional to the Euclidean distance between two vectors and in the 23 dimensional spaces. It provides a good definition of the distance because the Euclidean distance does. We will see below that on their own the distances do not allow the distributions’ comparison, however in conjunction with statistical analysis they become useful.
Confidence interval under the random sampling assumption. Our sample consists of 858 bearers of rabbinical surnames, 1057 bearers of occupational surnames and 7471 bearers of generic surnames (we often use in the calculations the rounded number of 7400). These samples are quite large; however, the population means that can be derived from them still contain quite a large uncertainty. Here we describe the derivation of the confidence interval, i.e. the interval within which the population means are contained with high probability (95% probability in our study). The derivation in this section is done assuming that our list of individuals is a random sample of the studied population groups. This is a good assumption up to the presence of sequences of 3–5 individuals with the same surname who belong to the same close family. These individuals can be assumed to have a certain correlation of professions, which violates the assumption of random sampling. The consistency of the assumption of random sampling despite these correlations will be demonstrated in the next section.
The material in the rest of this section is mostly well-known. We consider a total population of X individuals, of whom Xi have a property “i”. In the application of interest in this work, this property is a certain profession; however, the nature of this property is irrelevant for general considerations. We make a random sampling of the population, i.e. we pick an individual at random. Then, by definition of random sampling, the individual with property “i” is picked with probability pi = Xi/X. If we continue the random sampling, then the probability distribution of the number Xi(N) of individuals with the property “i” in randomly picked N individuals is given by the binomial distribution with the success probability pi. Here we assume that N is much smaller than both Xi and X so that the random sampling occurs in approximately identical conditions. The average and variance of Xi(N) are given by the well-known formulas of binomial distribution
where here and below the angular brackets stand for averaging. Large N binomial distribution can be approximated by Gaussian, implying that the distribution of Xi(N) is Gaussian and is determined uniquely by the mean and the variance above. We find that the distribution of x≡(Xi(N)- pi N)/[pi N(1- pi)]1/2 is the standard normal distribution with zero mean and unit variance. For this distribution, it is well-known that the probability that x will fall between -1.96 and 1.96 is approximately 0.95. This probability equals the probability that Xi(N)/N falls between pi-[pi(1- pi)/N]1/2 *1.96 and pi+[pi(1- pi)/N]1/2 *1.96 that is designated by and obeys
Our data provides Xi(N)/N, from which we want to find the confidence interval of pi that is the interval to which pi belongs with 95% certainty. If the observation provides the value Xobs for Xi(N) then, with 95% probability, the unknown quantity pi obeys
This inequality is equivalent to (Xobs - pi N)2 ≤1.962 pi N(1- pi), which gives
We find
where we defined
We have neglected terms of order 1/N and introducing (pi)obs≡ Xobs/N that
with 95% probability. This has the same form as Equation (2) above because pi and (pi)obs coincide in the leading order in N>>1. For not so large sample, however, there is a difference, the property which is often not mentioned in the discussions.
In the rest of this work we keep using the definition of the confidence interval by 95% certainty. This and the factor of 1.96 above are somewhat arbitrary. If we used 90% confidence interval instead, then 1.645 would be present in the formula above instead of 1.96. This would result in more differences between the studied groups; however, we prefer to stick to the more conservative estimate of the differences.
Data consistency with random sampling. We have already reported that the assumption of perfectly random sampling is not accurate. However, our data is still composed of independent information units where the unit is defined by the information provided by one participant. This unit is the information on the close family of the participant. Hence for a large number of participants, considering with very good approximation the information that they provide as independent, the data is still the sum of independent identically distributed random variables. The variable is the number of people with profession “i” in one reported family. Therefore, by the central limit theorem (see e.g. Gnedenko & Kolmogorov, 1968), the distribution of the number of representatives of each profession is still Gaussian, as in the case of random sampling. Having the Gaussian distribution, we can then evaluate the confidence interval and obtain the appropriate generalization of the results of the previous section. Below we quantify these considerations and provide the changes that are in order.
Table 3 provides a typical excerpt from our list of individuals and their professions. It is seen that some surnames are included multiple times. In Table 3, individuals with the same surname do not necessarily belong to the same family, as seen from the places of origin. In some cases (not shown), the bearers of the same names did belong to the same family and had similar professions. For instance in the list of 858 individuals with rabbinical surnames, we found two Berlins who were architects, two Wahls who were salesmen, two Halperins who were accountants, two Hellers who were teachers, three Hellers who were engineers, four Hellers who were economists, two Ginzburgs who were accountants and two who worked in delivery, two Gordovers who were engineers, two Gordons who were workers, and nine Horowitzs who were engineers. These correlations might cause the statistics to behave differently from the situation where each individual is picked at random from the studied group. This issue must be considered quantitatively. We observed previously that the number of reported people from the same family rarely exceeded five and typically was much less. For quantitative treatment of the effect of these correlations of limited range (below five), we consider the statistics of Xi(N) – the number of individuals with profession “i” in the list with total number of individuals N. We introduce the random variable xi(p). This variable equals 1 if the individual in place “p” of the list has profession “i” and 0 otherwise. Then
Some surnames are different spellings of the same name. These spellings were created in the course of family migrations during centuries because spellings of the same name in official documents differed in different countries, for example due to spelling mistakes in the records.
We assume that the list is ordered so that individuals with possible correlations of professions are grouped together; the list can be thought of as obtained in this way. We pick at random individuals from the considered group (bearers of rabbinical or occupational or generic surname) and then we pick their close family of random size as determined by the statistics of family sizes (which is of no interest here). This implies that xi(p) in the equation above have finite correlation range so that the variance < xi(p) xi(p+k)>- < xi(p) > < xi(p+k)> is non-zero for some positive integer k. k is bounded from above by kmax, which is formally given by the maximal family size, which is fifteen (individual, parents, great and great great-parents); however, this is five in reality as we have already explained. For large N>>kmax the distribution of Xi(N) is still Gaussian as in the case of random sampling. This can be seen as the result of application of the central limit theorem to the sum of independent random variables where each variable is the sum of xi(p) over one family, i.e.
Here we introduced the random variable (yfamily)l , which counts the number of representatives of profession “i” in the l-th family where l is the index of the family. Thus the statistics of (yfamily)l could be obtained by partitioning the considered group of population (rabbinical, occupational or generic) into families, where the family is defined as information unit in our data and not otherwise, with the unit’s definition given in the beginning of this section. Considering (yfamily)l with different l as independent, we conclude from the central limit theorem that Xi(N) is approximately Gaussian random variable, which is uniquely characterized by its mean and variance (a finer consideration can be done using the version of the central limit theorem for random variables with fast decaying correlations, see Gnedenko and Kolmogorov). These are given by
where we used directly the definition Xi(N)= ∑Np=1 xi(p). Here <xi(p)>= pi, where pi were defined in the previous section. We can consider the last sum as sum of diagonal and off-diagonal elements. The sum over the diagonal elements is readily found by using that xi(p)=1 with probability pi and xi(p)=0 with probability 1-pi. Thus <x2i(p)>=pi and
which is the same answer as for the random sampling. It is the sum of the off-diagonal terms ∑p≠k (<xi(p) xi(k)>- <xi(p) > <xi(k)>), a non-trivial quantity, which characterizes the correlations of professions within one family. Thus <xi(p) xi(p+1)> is the probability that two consecutive individuals from the list have identical profession “i”. This probability is larger than <xi(p)> <xi(p+1)>, which would hold if professions of the individuals were independent. The finite difference <xi(p) xi(p+1)>- <xi(p)> <xi(p+1)> is caused by the finite probability that individuals p and p+1 belong to the same family and thus have positively correlated professions. It seems inevitable that within-family correlations are positive so that
The left-hand side of the above equation is identically zero for k> kmax (see above). It is then readily seen from the definition in Equation (3) above that the variance obeys
where the constant ci is independent of N. The question is how different ci is from the random sampling value pi(1-pi) because of the described correlations.
We face the problem of estimating the normalized dispersion ci for our unknown sampling statistics. This can be done quite accurately in the case of bearers of generic surnames where we have data on more than 7400 individuals. This is accomplished by partitioning the list into 74 hundreds and considering the corresponding 74 numbers [Xi(100)]k with k running from 1 to 74 as independent realizations of Xi(100). Here the independence of [Xi(100)]k with different k holds due to 100>>kmax, which implies that the number of correlated professions in different hundreds is negligibly small in comparison with the total numbers. Indeed, we have
where <xi(p)(xi(k)> differs from <xi(p)><xi(k)> only for indices p and k in narrow vicinity of p=k=100, which can be neglected. We find the independent variables law <[Xi(100)]k[Xi(100)]k+1>=<[Xi(100)]k><[Xi(100)]k+1> (similar consideration can be done for higher order correlations). This independence is the reason why we group the data in blocks of 100 (of course the block size is not defined uniquely). We observe that Yi≡(1/74) ∑74k=1([Xi(100)] k)2 is a sum of independent Gaussian variables and hence it is Gaussian itself. The average of Yi is <(Xi(100))2> and its dispersion is
where we used independence of [Xi(100)] k with different k and that Gaussianity of [Xi(100)] k implies <([Xi(100)] k)4>=3 <([Xi(100)] k)2>2=3 <(Xi(100)])2>2. Thus the distribution of (Yi/<(Xi(100))2>-1) √37 is the standard normal distribution with zero mean and unit variance. We find that the value of Yi obtained from our data limits <(Xi(100))2> within the interval given by
with the confidence level of 95% (see above). The random sampling would give <(Xi(N))2>= pi N+N(N-1) pi2 with N=100 as seen readily from the properties of the binomial distribution. The comparison between the dispersion determined from our data and the dispersion predicted by the random sampling assumption is provided in Table 4.
The agreement is found to be much narrower than allowed by the confidence interval provided in the fourth and fifth columns.
We find that the observed dispersion agrees with the prediction of the random sampling assumption with accuracy which is well beyond what could be hoped for, as is clear from the confidence interval. Here we used for pi the values obtained from averaging over the sample of more than 7400 individuals, where we neglect the error using the large sample size. The observed agreement over as many as 23 categories is completely consistent with the assumption that the data are equivalent to random sampling of the group of bearers of generic surnames. In other words, the correlations between the profession of different individuals, which are present in the data, are negligible. Since these correlations do not seem to be different for other groups (bearers of rabbinical and artisanal surnames) then we will assume in the Results below that our data provides the random sampling of all the considered population groups. We have also derived dispersion for other groups and saw that the assumption works well (these comparisons are not provided since for these groups the sample of about 1000 individuals is too small for reaching rigorous conclusions).
The results for the occupational distribution of the generic surnames derived from data presented in Table 2 are given in Table 5. For this surnames’ class we have a rather large pool, which allows us to obtain a distribution with high accuracy, as presented in the third column, which gives the mean together with the confidence interval. It is seen that the means are fixed rather sharply and for many categories the range of values around the mean, allowed by the confidence interval, is narrow. Yet sharper results hold for the total pool of 9315 individuals consisting of all the surnames, i.e. the generic, rabbinical and occupational surnames together (here 9315 is found using the data on only 7400 out of 7471 individuals with generic surname). The distribution, presented in the fourth column, provides us with rather detailed information on the occupations of the Russian-speaking Jews that seemingly was not considered previously. Finally, the second column presents the same distribution, however obtained by restricting the pool of generic surnames to the first 1000 individuals. This distribution is provided for comparison with rabbinical and occupational surnames in Table 6 where the total available pool is about 1000 in both cases.
The third column provides population means together with the confidence interval as derived from the full pool of 7400 individuals. For comparison with other surnames’ classes, we present in the second column also the distribution that would be derived by using only the first 1000 names.
The second column provides the distribution of the generic surnames (considered previously), the third gives the distribution for the joined classes of generic and rabbinical surnames and the fourth for generic and occupational surnames.
We observe that the distributions of bearers of generic surnames and of the total considered population are rather similar. In fact, within the confidence interval, the distributions agree (we observe however quite significant difference in the predicted means in the rows marked with blue color). The Bhattacharyya coefficient of these distributions is 0.9998 and the Hellinger distance between the distributions is 0.014 (the calculation demands the full and not rounded numbers). The coefficient is very close to one and the distance is very small; however, the interpretation of these numbers is not obvious. We need a scale to tell which distance is large and which small because the vectors representing the distributions belong to a high-dimensional space. For comparison, the coefficient and the distance for the distributions of the generic surnames in the second and third columns of the table are 0.9975 and 0.05 respectively. These numbers are also very close to one or small despite the difference of the distributions being quite appreciable (the difficulty in introducing measures of similarity in high dimensional spaces is sometimes known as “the dimensionality curse”; see e.g. Aggarwal et al., 2001).
Thus, we compare the distributions of generic and all surnames directly (Table 5). The distributions, as given by the mean values, are very similar. We marked in blue the only three rows for which the distributions differ appreciably where the maximal difference is 12%. The distributions’ difference is insignificant both because the share of the rabbinical and occupational surnames in the total population is not that large (~20%), and the difference of the distributions of the generic, rabbinical and occupational surnames is not very large. Yet the difference exists, and it is statistically significant as we will demonstrate.
The lack of the appreciable difference between the total distribution and the generic distribution has the origin that is similar to that of measured high mobility rates in different countries. These measurements do not contradict low mobility rates measured by surname, as explained in Clark, 2015. Different surnames are over- or under-represented in different social groups for long periods of time; however, when society’s average is taken for deriving the mobility rate of society, the over- and under-representation average out producing overall high mobility rates. Similarly, the deviations of the rabbinical and occupational surnames’ distributions from that of the generic surnames often occur in opposite directions, so that after averaging the difference disappears. This point is illustrated in Table 6. We see that for the largest absolute deviations, marked in red, the deviations are opposite, including the row corresponding to head/chief officer. Indeed, for this row, the deviations of the generic and all surnames are strongest.
Furthermore, we see from Table 5 that population means predicted from the study of 1000 and 7400 individuals are consistent within the confidence interval. Moreover, the average values coincide with high accuracy – for 13 occupational categories the difference is <20% (these rows are left unmarked). For the rest of the categories, marked in red, the difference is larger; however it is never dramatic – the statistics derived from the study of 1000 individuals gives a very good idea of the much more precise statistics derived from 7400 individuals.
Finally, Table 7 presents the full data for the occupational distributions of the rabbinical, occupational and generic surnames. We saw on the example of the generic surnames (Table 5) that the means obtained from the pools of about 1000 individuals provide good orientation for the actual Pi. Therefore, we provide in separate columns the means of the three groups. It is seen that the differences are significant. For many categories, these differences continue beyond those allowed by the confidence intervals which are provided in the corresponding columns. Thus, we marked in red the rows where occupational distributions differ with 95% probability. We marked with blue the categories where the difference can be claimed with a slightly smaller probability of about 90%. The three Bhattacharyya coefficients and Hellinger distances measuring the similarity and difference of the considered three distributions are given respectively by
BC(r,g)=0.988, H(r,g)=0.1095, BC(o,g)=0.9942, H(o,g)=0.0763, BC(o,r)=0.9818, H(o,r)=0.1348,
The table tests the hypothesis that the occupational distributions of the groups are identical by checking the overlap of the confidence intervals. Shares Pi(in per cent) of the i-th profession are provided for each group together with their 95% confidence intervals. The sizes of the respective pools are provided in the first row. Confidence intervals of generic surnames are significantly narrower than in other groups thanks to much larger pool of available data. Red indicates Pi that are different beyond the statistical error; blue indicates those that are different with high probability, e.g. would differ if we used 90% confidence interval.
with obvious notations (e.g. H(r,g) is the distance between rabbinical and generic surnames’ distributions). We see that occupational and rabbinical surnames’ distributions are the most different pair whereas occupational and generic surnames’ distributions are the least different pair. This does not correspond to the differences in Table 7 (colored red/blue) where the largest number of differences is between the generic and rabbinical surnames. The reason is that the pools of rabbinical and occupational surnames are smaller, which results in a larger uncertainty due to finite confidence intervals. In contrast, the overlap coefficients and the distances above are derived from the mean values only and do not reflect the magnitude of the confidence intervals.
We recall that the overlap and distance for the distributions of 1000 and 7400 generic surnames are 0.9975 and 0.05, respectively. We see, by comparison with the equation above, that these distributions are closer than distributions of different groups which is necessary for consistency. Moreover, assuming that a similar difference between distributions of 1000 and 7400 would exist for rabbinical and occupational surnames (as would be found if we had a larger pool of data), we see that the numbers are consistent with the assumption that distributions of rabbinical and occupational surnames differ from the generic surnames’ distribution and from each other.
An individual’s choice of profession is determined by a multitude of genetic and environmental factors that are largely unknown. However, undoubtedly the family into which the individual is born is one of the main factors of influence. Family differences could persist for many generations via choice of partners. Indeed, marriages occur between individuals having similar social and genetic backgrounds who can preserve the differences in their offspring (see Güell et al., 2015; Clark, 2015). This reproduction mechanism (which is not a literal transmission of profession from generation to generation, that was never present in our data, but rather a transmission of certain statistical preferences in occupational choices) is, however, imperfect. The differences caused by family origin gradually dissolve with time and their complete disappearance has been observed to take centuries (Clark, 2015). In this work, we continued this direction of studies by comparison of occupational differences of the three groups of Russian-speaking Jewish families.
We observed that having a surname at which origin was a rabbi, a craftsman or neither of the above categories would create a difference of occupational preferences of the individual. For instance, some fraction of individuals having a rabbinical surname are actually the descendants of the rabbi who was at the name’s origin (and not unrelated individuals with the same surname). This results in a difference of occupational preferences of members of this group from the average preferences of the population. Since these names originated from nine to two hundred years ago then the differences in the preferences could be negligibly small today. However, previous studies, such as those reviewed by Clark (2015), indicate that the differences can still be appreciable. Our study confirmed that in fact the occupational preferences of bearers of rabbinical, occupational and generic surnames differ beyond statistical uncertainty. We remark that the studied groups themselves typically do not identify themselves as different. It can be firmly stated that most of the Russian-speaking bearers of the rabbinical surnames are either completely unaware of their name’s origin or see in it little meaning to their lives. Similar facts hold for the other groups. This differs from some cases, e.g. the case of Swedish nobility (Clark, 2015).
Can we understand the differences provided in Table 7? Most of the differences are readily explained by low mobility, making the assumption that bearers of the names correlate appreciably with the origin of the studied surnames. Thus, the proportion of engineers among the bearers of rabbinical surnames is higher than in the other two groups. This profession demands much study and abilities for complex mind constructions that is evidently present in the profession of Jewish rabbi. The largest difference between all the three groups is in the fraction of members of the groups who are workers. The fraction for rabbinical surnames is between 0.117 and 0.163; however for generic surnames it is enclosed between 0.177 and 0.195 and for occupational surnames it is between 0.208 and 0.264. The corresponding means of occupational and rabbinical surnames differ by 1.69 times. This is a significant difference, indicating the initial inclinations of bearers of rabbinical surnames for non-worker type of activity, and conversely inclinations of craftsmen toward that kind of activity, persisted for at least two hundred years of history. These conclusions and numbers are in complete accord with those provided by Clark (2015). We find that bearers of rabbinical surnames pick the profession of heads/chief officers more than twice as often than the bearers of generic surnames. This is reasonable since rabbis led their communities. The difference from occupational surnames is somewhat smaller. Another significant difference between the groups is that bearers of both occupational and rabbinical surnames have almost identical preferences for clerical work, which are less than those of generic surnames. Inclination for clerical work would not be anticipated from a rabbi or a craftsman.
We also calculated the occupational distribution of all the surnames, i.e. general Russian-speaking Jewish families, which is of its own interest. We demonstrated that the distribution is very similar to that of bearers of generic surnames. This indicates that, despite differences between generic, rabbinical and occupational surnames being pronounced, they average out in the distribution of the general population. This is both because the deviations of the occupational preferences of bearers of rabbinical and occupational surnames from those of generic surnames are often opposite and because those groups are not as many. Thus, in our pool, rabbinical and occupational surnames constitute 20.5% (1915 individuals) of the total, where 9.2% are rabbinical surnames.
The above difference between rabbinical, occupational and generic surnames finds reasonable explanation in the personal features of rabbis and craftsmen. Similarly, we could explain the bearers of occupational surnames preference for the profession of programmer. What came as a less intuitive result is that the share of researchers among the bearers of the rabbinical surnames is larger than the average; however not that large. Further studies are needed since the difference with our data can be claimed with less than 90% probability. The bearers of the rabbinical surnames were found to have preferences for creative professions that are larger, however not much larger than the average. The bearers of occupational professions have lower preference for these professions.
Probably the most surprising of our findings is that bearers of rabbinical surnames have almost twice lower preference for legal professions than the rest of the population. It seems that since the profession of the rabbi demands the ability to learn and apply the religious law, flexibility of mind, and ability to defend sometimes opposite viewpoints, then it must be the opposite. Indeed, we checked the names of famous Russian Jewish lawyers and discovered that their surnames are overwhelmingly generic (the most famous Jewish Russian lawyer living today has an occupational surname of Reznik, which means “ritual slaughterer” ). We do not have a good explanation for this observation; however, it seems to be confirmed by the lists of prominent people of the profession in question.
Finally, the proportion of drivers among the bearers of rabbinical surnames is less than in the general Jewish population, which appears reasonable. The mean fractions of literary workers and psychologists can differ by more than four times; however, the statistical error in these rather rare groups of the population is quite large and further studies are needed.
Here, we demonstrated the difference between the groups. The next step would be finding the actual mobility rates that characterize how fast the difference between the groups disappears. Thus, in our data we could consider the occupational distributions of each one of the four generations and compare them, where the generation is defined by an appropriate temporal period (see above and Clark, 2015). The pools that we have at our disposal are however too small for reaching definite conclusions. Therefore, the calculation of the intergenerational mobility is left for future work.
The dataset described here cannot be shared openly due to the identifiable nature of the data (surnames, occupations, birth dates, birthplaces). Any researchers wishing to access the underlying data can contact the corresponding author ([email protected]). Data will be shared under the following conditions: researchers will need to declare that they are currently undertaking similar research, that the data will not be shared with anyone other than the researcher who requested it, and it will be exclusively used for academic purposes.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)