Keywords
sample size estimation; longitudinal study; repeated measure analysis; univariate analysis
This article is included in the Manipal Academy of Higher Education gateway.
sample size estimation; longitudinal study; repeated measure analysis; univariate analysis
‘Sample size’ is a term used in any experiment for defining the number of subjects selected or observed in the experiment. Sample used in an experiment is a subset of the entire target population. The target population refers to a group of individuals among whom the research is intended to be conducted in order to draw conclusions about the population. For e.g., for a type II diabetic test drug all humans who are suffering from type II diabetes would form the target population.
The number of participants in the sample effects the precision of our estimate and the power of the study to draw conclusions. The probability with which one would reject null hypothesis when null hypothesis is not true is said to be the power of the statistical test. So, power gives an idea on the chances of not committing an error of Type II. The size of the sample and the effect size are major factors which affects the power of a study. These are key concepts in designing a clinical trial.1 Sample size calculation is an important activity in setting up clinical trials to ensure achievement of trial objectives.
As an illustration, consider a study to compare the performance of a professional athlete taking a particular protein shake versus athletes who do not consume any special protein shakes. Narrowing down attention to a portion of the wider group is essential to enable tracking of the eating habits of every elite athlete in the world. This would entail choosing 100 professional athletes for our study at random; in this case, 100 would be the sample size. Based on the data gathered from a sample of 100 elite athletes, the study’s findings potentially characterize the population of all athletes in the sports industry. Lack of full coverage of the target population would result in the outcomes of the study having a margin of error. Given the limitation to examine every situation, the absolute precision of the effect of protein shake on the athlete’s performance would be hard to measure. Sampling error2 is the term used to describe this level of uncertainty or inaccuracy. It affects the estimator’s precision, which is a metric that is important for the chosen target population of all professional athletes.
Although sampling error cannot be completely eliminated, it can be reduced. A larger sample typically has a narrower margin of error. We require an appropriate sample size to examine and contrast in order to provide an accurate picture of the effects of protein shake consumption on performance. Note that there comes a point where increasing the sample size has no further effect on the sampling error (law of diminishing returns).3
Longitudinal studies take a longer time but help in determining causality as well as monitoring the trend over time. To see how sample size calculation was addressed in published longitudinal studies we searched the databases such as Scopus, Web of Science, PubMed, ScienceDirect, and Google Scholar using a range of key terms: “designing clinical trials”, “sample size calculation”, “longitudinal studies”, “randomized trials” and “repeated measures”. The ensuing literature review did not reveal much information on details of how the sample size was calculated for these published longitudinal studies.4,5
Formulae for deriving sample size in longitudinal studies is available from several papers.6,7 Basagaña, Liao and Spiegelma8 published a study in which the power as well as the sample size are discussed for time-varying exposures, but how this is practically applied to a longitudinal study design and its outcome is undocumented in published papers. Pourhoseingholi et al.,9 and Karimollah10 both published about the importance of various components for calculating the sample size in medical studies or clinical trials where often there would be more than one post baseline assessment, but sample size calculation is shown assuming single post baseline assessment. Manja and Lakshminrusimha published a two-part study11,12 which does give a good explanation on clinical research design, but sample size is not discussed in detail.
Most of the published studies which have assessments at multiple time points calculate the sample size based on the change from study end time point to baseline whereas a smaller number of papers emphasize on the use of multiple time points into consideration for calculating the sample size.6–8
The need for this research was prompted by this lack of proper usage of sample size calculation for longitudinal studies and to further explore which method for sample size calculation should be used in a longitudinal study resulting in correlated outcome data.
To explore the variation in sample size by considering multiple time point assessment versus the change from baseline to a single endpoint.
In an experiment for testing certain hypothesis with parallel group design, two or more independent groups are considered to be treated under different scenarios in order to compare the outcome of the scenarios. In our study we would consider the objective of comparison of two drugs.
Let (Xij) be the outcome of interest at jth (j = 1, 2, 3, …, t) time point for the ith (i = 1, 2, 3, …, n) patient in the two groups.
For the parallel group design, these 2n patients will be divided into two groups with 1: 1 ratio where one arm is assigned to receive the test drug and the other arm is assigned to receive the comparator drug.
Let be the population mean change from baseline for the test drug and comparator drug respectively.
Let be the sample mean change from baseline outcome for the test drug and comparator drug respectively, where and .
Change at single post-baseline assessment from baseline (Single time assessment analysis)
In a parallel group design study with two arms of equal size let the hypothesis be set as:
, There is no difference between the effects of test and comparator drug.
Vs
, Test drug is having larger effect as compared to comparator.
The test statistic assuming common standard deviation for both arms will be given by
Now If is true (and then , else if is true (i.e., , then will still be a normal but with a mean greater than zero.
If Type II error is denoted by then power will be simply and power is the probability to reject when is true. In probability equation it could be written as
Now in any study we would be looking for
After solving equation 5, we get
Here n is the sample size required per arm. We will use these formulae in calculating the sample size for single post baseline time point analysis.
Change from baseline with post baseline assessment at multiple timepoints (Multiple time points analysis)
In a parallel group design study with two arms of equal size and assessments taken at multiple time points let the hypothesis be set as:
, there is no difference between the effects of test and comparator drug.
, test drug is having larger effect as compared to comparator.
Where ,
Let be the contrast to be tested for the hypothesis and let
are the mean effect in arm one and arm two at time point “i” respectively in a study with t time points. can take any value depending on the hypothesis we want to test.
For e.g., if we want to see the difference between two drugs for change from baseline when t=2, then and the resulting will be
Where is the variance at time point i and represents the covariance between time point i and j.
The test statistic assuming similar variance-covariance matrix for both arms will be given by
Solving equations Equation 8 and Equation 9 for T we get
Now, If we follow similar steps as we did in single time point analysis above, we get
And solving Equation 12, we get13
We will use the formulae specified in Equation 13 to calculate the sample size for multiple time point analysis.
Appropriate sample size was calculated for multi-time and single time cases with different scenarios to achieve an overall mean treatment difference (0.9 points) between two treatment groups with common standard deviation (SD) (3.6 points) allowing 5% two-sided type I error and 85% power. The effect size and standard deviation used here are based on a real study.14 This was a three-year study with primary endpoint assessment at end of each year but the sample size calculation in this study was done on the basis of single time point. Since this study failed to recruit the expected number of patients and also had lot of missing data, the characteristics for the primary endpoints from the second year were used as it had equal number of patients in both arms and stabilized assessments.
We considered a two-arm parallel group scenario with one baseline and one post baseline timepoints to assess on change from baseline in absolute scale. Using the formulae in Equation 6 above for single timepoint analysis the sample size required per arm was 287 cases to show statistical significance.
Here again we considered two arm parallel groups with multiple timepoints and for studying we investigated six cases i.e., three, four, five, six, eight, and 10 timepoints. Each of this case corresponds to number of assessments including baseline. Three timepoints corresponded to the case with one baseline and two post baseline assessments, four timepoints corresponded to the case with one baseline and three post baseline assessments, five timepoints corresponded to the case with one baseline and four post baseline assessments and so on.
Figure 1 and Figure 2 represents each of this case as a line in the plot under different contrast types and correlation structures.
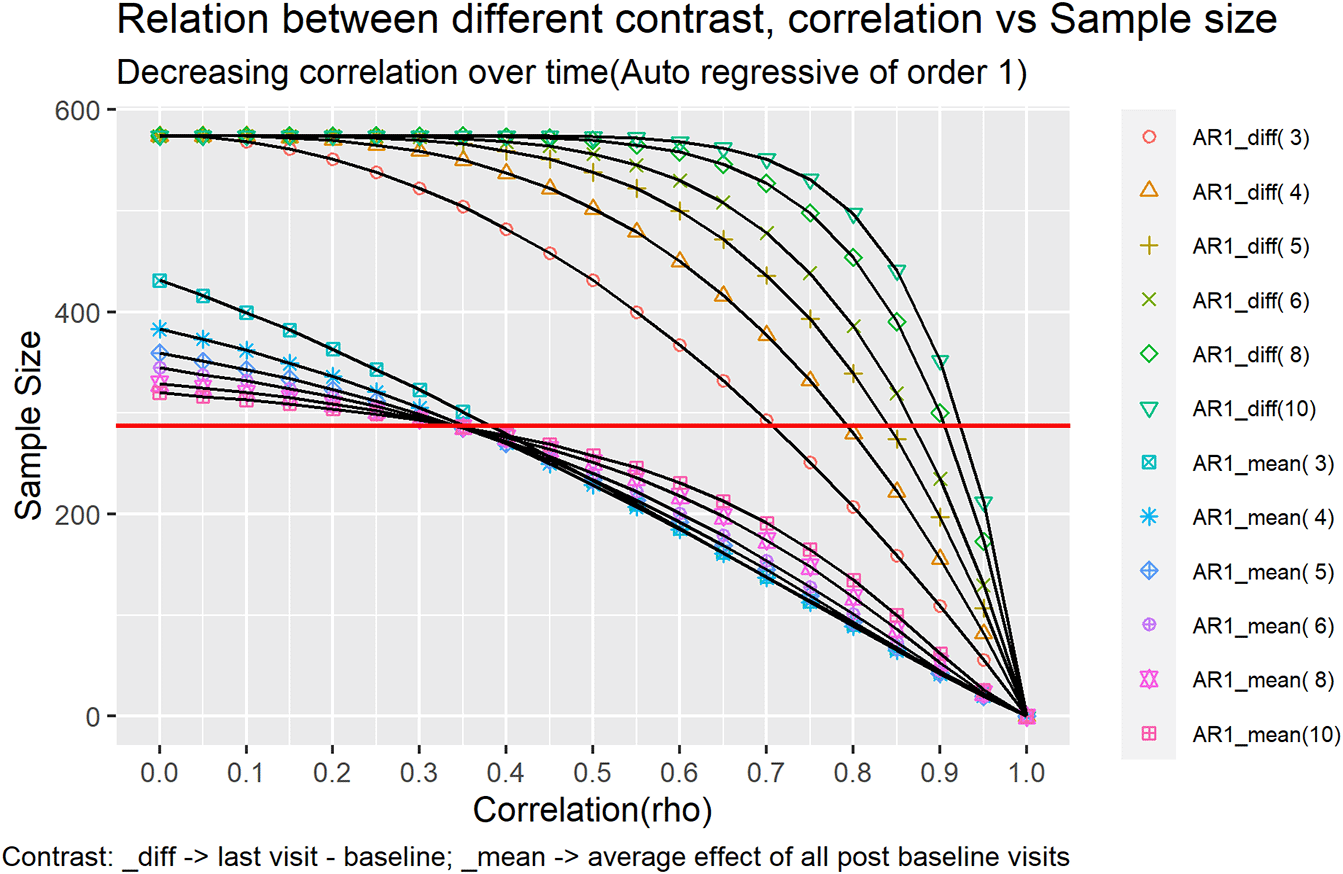
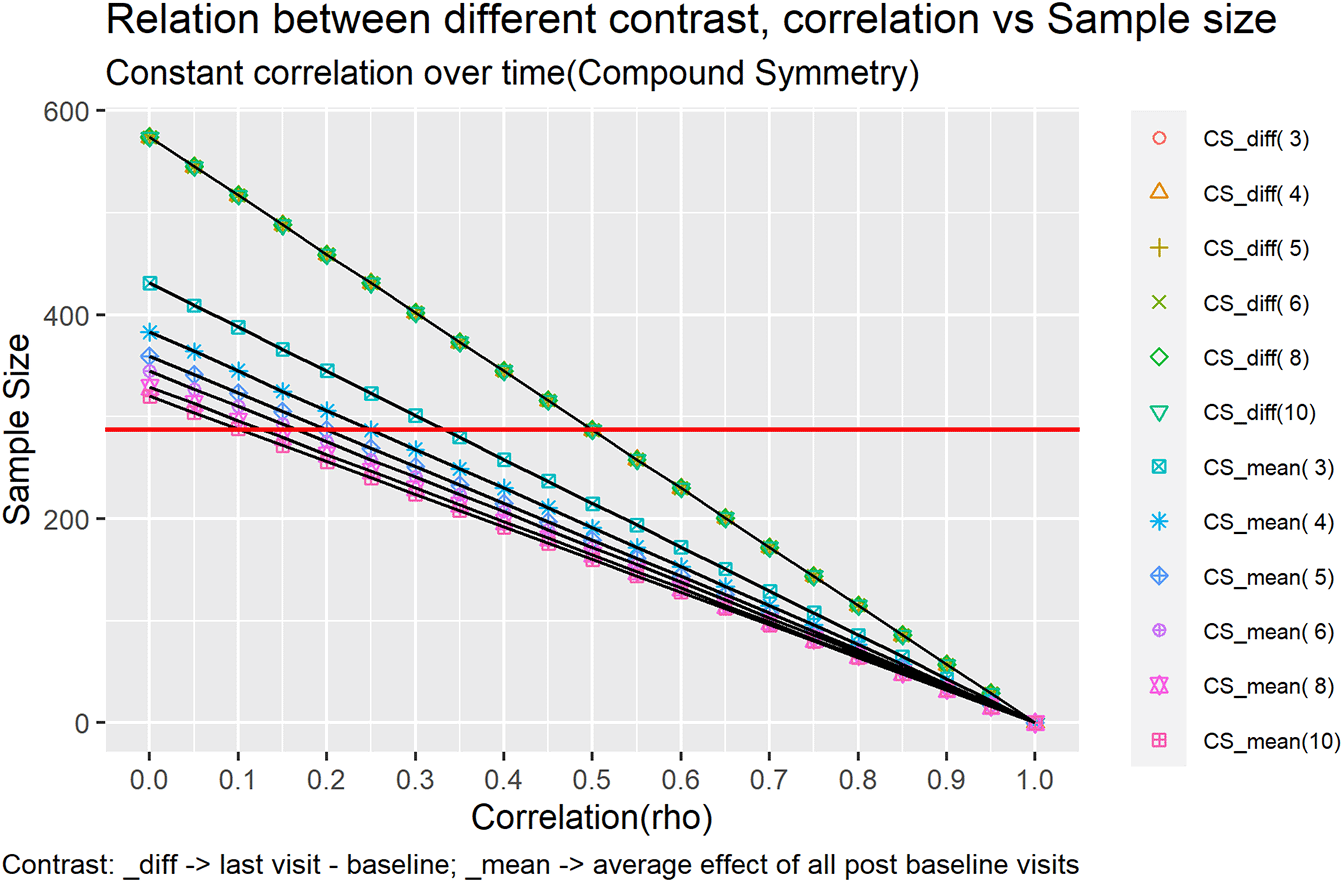
Keeping the SD as 3.6 we tried to vary over two different correlation structures:
Compound symmetry (CS)
Compound Symmetry just means that all the variances are equal and all the covariances are equal. So, the same variance and covariance are used for all subjects. In compound symmetry the covariances across the subjects and the variances (pooled within the group) of the different repeated measures are homogeneous.
Where σ2 is the common variance assumed to be similar over time and ρ is the assumed correlation. Order of variance covariance matrix will be × . ‘t’ is the number of time points.
Auto regressive of order 1(AR1)
This is the homogeneous variance first-order autoregressive structure. Any two elements that are adjacent have a correlation that is equal to rho (ρ), those separated by a third will have correlation ρ2, and so on. rho is restricted such that –1< ρ <1.
Where σ2 is the common variance assumed to be similar over time and ρ is the assumed correlation. Order of variance covariance matrix will be x . ‘t’ is the number of time points.
Also, we considered different scenarios of how we want to analyze the results at the end as different contrasts as described below.
We tried to investigate two types of contrasts.
1. Time-related contrasts i.e., mean over time (mean contrast).
Rationale: This contrast comes from the chronic types of disease where regular medicine is required, and the effect remains only for some time and then the disease condition reverses back.
This will be labelled in the legend of Figure 1 as CS_mean(i) and in the legend of Figure 2 as AR1_mean(i). For e.g., for five timepoints the contrast would look like c(-1, ¼, ¼, ¼, ¼).
2. Mean Difference (change at last time point from baseline) (diff contrast).
Rationale: This contrast comes from the types of disease where each dose reduces the disease severity and the over the course it is totally removed from the patient’s body. Here the total effect at the end of the treatment course as compared to the baseline is of interest.
This will be labelled in the legend of Figure 1 as CS_diff(i) and in the legend of Figure 2 as AR1_diff(i). For e.g., for five timepoints the contrast would look like c(-1, 0, 0, 0, 1).
Sample size was calculated for correlation ranging from 0 – 1 with intervals of 0.05 for both the plots Figure 1 and Figure 2. Sample Size was derived using the formulae mentioned in Equation 13.
All the trend lines for mean difference type of contrast overlaps each other. For mean difference type of contrast, the sample size doesn’t change for an increase/decrease in the number of visits. It changes with the correlation i.e., highly correlated (rho > 0.5) timepoints would need less sample size as compared to low correlated timepoints. Also, for correlation = 0.5 the multiple assessment sample size coincides with that of single time point assessment.
However, the sample size does vary when the contrast is set to mean over time. Multiple time point assessment with more timepoints requires less sample size as compared to that of multiple time point assessment with less time points for e.g., the multiple time point assessment with three timepoint requires 86 per arm with correlation 0.8 and the multiple time point assessment with 10 timepoints requires 64 per arm. On the same lines the multiple time point assessment with three timepoints requires 258 per arm with correlation 0.4 and the multiple time point assessment with 10 timepoints requires 192 per arm. This trend shows that the sample size required reduces when the correlation increases. For correlation = 0.1 to 0.35 the sample size coincides with that of single time point assessment.
Under mean over time contrast the multiple time point assessment requires lower sample size as compared to single time point assessment (287 per arm) for correlation greater than 0.35 and the sample size increases as correlation goes below 0.35.
Whereas for mean difference contrast the multiple time point assessment requires lower sample size as compared to single time point assessment (287 per arm) for correlation greater than 0.7 but requires higher sample size for correlation less than 0.7.
The trend changes shape for mean difference contrast vs mean over time contrast. Also, at certain point the increase in sample size attenuates for e.g., in case of mean difference type contrast with 10 time points the sample size required doesn’t changes when correlation drops below 0.55.
One of the hurdles in considering the longitudinal methodology for sample size calculation is the assumption on the covariance matrix. It is often easy to estimate the variance of single timepoint as compared to estimating the variance-covariance matrix for multiple time points.
The above derivations were done for trial design with parallel group, 1:1 ratio and two arms. If the ratio changes or if we have more than two arms or if the design is crossover, then the effective overall sample size would get effected in both the cases i.e., sample size with single time point as well as sample size with multiple timepoints, but the trend would remain the same as shown above in the figures and the results will still hold good. Similar trends should hold for other variance – covariance structures though they have not been simulated here.
Sample size changes depending on the analysis type and the data collected. Both the graphs in Figure 1 and Figure 2 in this study reveal that if response is assessed at multiple timepoints and the correlation between the paired observations is high (> 0.6) then one should consider using repeated measures analysis and consequently determine the size of the sample that is based on the multiple time points scenario which results in lower sample size requirement as compared to the sample size derived assuming single timepoint response assessment. This would reduce the cost, resources, and time in conducting the experiment fastening the new drug development. Also, repeated measures analyses will not drop the patients in which they have certain missing data as compared to single point analysis where the patient will be dropped if the response is missing hence may help in retaining the power.
Sample size derivation using longitudinal design method for studies with multiple assessments can be considered of substantial benefit in cost and time although the challenge of estimating the variance-covariance matrix remains.
Software available from: The Comprehensive R Archive Network (https://cran.r-project.org/)
Source code available from: https://github.com/Sarfaraz-Sayyed/Sample-Size-Variation.
Archived source code at time of publication: https://zenodo.org/badge/latestdoi/547747570.15
License: MIT License.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)