Introduction
By the end of 2023, the market value of the pharmaceutical packaging sector is expected to reach USD 101 billion.1 Recognizing product codes using machine vision enables the storage and processing of package-specific manufacturing data, as well as the electronic search and extraction of codes and dates, which is important in the development of intelligent product handling systems.
Cardboard is typically used in pharmaceutical product packaging. Boxes made of cardboard have curved surfaces. When accurate text recognition of text printed on surfaces is needed using 2D machine vision, the curvature is a difficulty in itself as it causes uneven illumination of the packaging surface as presented in Figure 1. Several printing methods are used to print the expiration date and manufacturing batch codes that are important for the usage and handling of pharmaceutical packages. Changes in physical conditions in package imaging as well as printing methods producing low-contrast and irregularly shaped characters make code recognition more challenging. The recognition process is especially challenging because there are many variants in the codes used on various packages using different printing methods, as well as variances in the codes’ forms, structures, regularity, and colors. In the past ten years, product code recognition techniques have advanced, and several researchers have become more interested in this area of study.

Figure 1. Two cardboard pharmaceutical packages with the expiration date and batch codes printed on the curved packaging surfaces.
The purpose of this research is to demonstrate that, despite difficulties in the field, text characters with imperfections and inconsistencies in their forms on pharmaceutical packaging can be accurately recognized using appropriate pre-processing and deep learning techniques. In the experimental part of the study, a deep learning model trained on a real-life image set was used to evaluate the recognition of dot matrix and ink-printed characters, employing three key metrics: True Positives (TP), False Positives (FP), and False Negatives (FN). Subsequently, the performance of this deep learning model was compared with that of the Tesseract OCR method using the same metrics relevant for text characters recognition. It is important to note that information related to expiration dates and manufacturing batch codes on pharmaceutical packages is important for safety and must be accurate and reliable. The rest of the paper is organized as follows: the next section discusses related work found in the literature. The next section details the approach to using deep learning for recognizing manufacturing marking texts on pharmaceutical packaging. Then deep learning with focus on R-CNN and using it for expiration date and batch codes recognition is presented in the extent to which it serves this research work. Analysis of experimental results is then presented and finally, the conclusion and future works are presented in the final section.
Related works
Optical character recognition (OCR) for document images is a well-studied field.2 In OCR, characters are recognized by comparing groups of pixels detected in the source image with the model patterns that the system has been trained on. OCR software is used for the recognition of manufacturing markings printed on product surfaces where it is highly effective at recognizing regularly shaped characters with good contrast against a simple background.3 Product text recognition is performed on digital images produced by an imaging system that captures energy reflected from the product surface in the scene onto its image plane.3 Varying positions and orientations of the text in the camera scene, changes in illumination on the package surface, low contrast between text and background, irregular fonts, and motion blur of images acquired from moving packages reduces the usability of OCR methods in this high-accuracy task.3 Tesseract OCR is a widely used open-source optical character recognition program. It has been in use since 1985 and has evolved significantly throughout the years. Over time, Tesseract OCR has changed. Numerous languages are supported, image binarization is included, and Tesseract 4 added an OCR engine with a long short-term memory (LSTM)-based neural network, which process an input image line by line into boxes and then feeds them to the LSTM network, which produces the recognition result.4
The capability of different methods to recognize product texts printed with irregular characters on product packaging varies.3 Detecting text as binary large objects using K-nearest neighborhood (KNN) classification5 for opaque labels, and traditional OCR methods6 for consumer product cardboard packages have difficulties in recognizing irregular fonts. Although these techniques are fundamental, they often struggle to adapt to the diverse real-life conditions. Gabor filter-based methods,7,8 are robust against variations in surface shapes and uneven illumination, but face challenges in recognizing irregular characters, emphasizing the difficulty of adapting to them. A Histograms of Oriented Gradients (HOG) feature-based neural network,9 with an imaging environment with multi-directional illumination of the package surface and sub-images fusing alleviates problems related to low contrast and uneven illumination. However, methods performance on irregular font shapes and motion blur is still limited. In controlled imaging environments, deep learning methods, integrating Connectionist Text Proposal Neural Network (CTPN) for text area detection and capsule network (CapsNet) text recognition,10 tolerate packaging surface shape changes, uneven packaging surface illumination, and motion blur. The method is capable of handling character irregularities, including irregular fonts. The integration of two deep learning neural network methods, FCN, and R-CNN11 and Faster-CNN and LeNet DNN,12 effectively detects and recognizes text in various food and beverage packaging, even with irregular fonts. The method, as is possible for deep learning text recognition, directly detects and learns the most important characters features directly from source images, enabling generalization to various conditions, such as irregular characters, which pose challenges to traditional pattern-matching-based text recognition techniques.
Methods
This research focuses on using deep learning to recognize manufacturing marking texts printed on pharmaceutical packaging surfaces, which contain irregularities in character shapes. Previously, our research into recognizing manufacturing markings on cardboard pharmaceutical packages led to the development and introduction of a novel method for binarizing texts on curved packaging surfaces.13 This method employs source images acquired in a controlled imaging environment, enabling the accurate and robust binarization of texts while effectively addressing challenges associated with surface curvature. The text recognition ability of the trained R-CNN model is first evaluated using three key metrics. Additionally, the performance of this deep learning network for text recognition is compared with Tesseract OCR, using the same three key criteria. Text recognition of texts pressed without ink, stamped, or laser printed is excluded from the study. In the experimental recognition tests, we used a set of images of a Finnish health technology company taken from real medical packages, with dot matrix printed and pressed ink-marked texts. The study’s text recognition was performed on the packaging production batch and expiration date markings, and titles. An example of the binarized images used for text recognition is shown in Figure 2. In the experimental tests, real pharmaceutical packages have been used to ensure that the results of our research are reliable. Since the text recognition of pharmaceutical packages is a new area of research, the number of source images was limited. However, this limitation is only temporary, and research will continue as more source images become available.

Figure 2. Batch code and expiration date texts in a binarized images printed with a pressed ink-marked (left) and with the dot matrix printing methods.
Deep Learning
Deep Learning (DL) is a subset of machine learning in which neural networks are used to learn from data and generate predictions or choices. It is described as a method of teaching a computer to learn from data and make predictions or judgments using neural networks, much like a child does. Deep Learning can be used for a variety of tasks, including image classification, object detection, speech recognition, and natural language processing, because of its ability to interpret and analyze complex patterns in data.
Regions with CNN features (R-CNN)
In the paper ‘Rich feature hierarchies for accurate object detection and semantic segmentation,’ Girshick, Ross, et al.14 introduce an original R-CNN method for object detection from images, based on the use of region proposals. The paper details the operation of the detection layer, offering insights on how high-capacity convolutional neural networks (CNNs) are applied to bottom-up region proposals to localize and segment objects. It also discusses the strategy of using supervised pre-training for an auxiliary task when labeled training data is scarce, followed by domain-specific fine-tuning, which yields a significant performance boost.14
The object detection algorithm in the Region CNN model is based on using high-capacity convolutional neural networks to find and segment objects in a bottom-up manner. Training the CNN model with a limited labeled training set is achieved by training in two steps: first with supervised learning using a large dataset, and then fine-tuned with a targeted, limited dataset.14
In Region-CNN, the selective search method is used to produce region proposals. Selective search segments the image into multiple parts at various scales, iteratively combining these segments based on similarities in color, texture, or size, generating region proposals for potential object locations in the image. This process results in hundreds of region proposal areas (ROIs) from the image that potentially contain objects. Each region proposals area is scaled to a fixed size and fed into a convolutional network, which extracts features and classifies the regions. CNN uses a trained model to predict whether each area contains an object and, if so, which class of object it is. The output layer of the area CNN contains a classification layer (Classification Layer), which predicts the class of each region proposals. This layer produces probabilities that a given region belongs to a class defined in the training data. The Bounding Box Regression Layer produces adjustment values for the bounding boxes of the region proposals, allowing the creation of accurate, class-specific bounding boxes. By combining the results of these two layers, Region-CNN produces class-specific bounding boxes that are more accurate than the original region proposals.14
As a result, Region-CNN produces a set of bounding boxes classified according to objects, along with confidence scores for each detection. This information allows determining the location of the object in the image as well as their classes. In multi-object detection, the Region-CNN model handles multiple classes and area proposals, with separate SVM classifiers for each area. Each area proposal found by the selective search method (Region Proposal) is scaled and fed into a CNN, which extracts its features. These features are then fed into each SVM classifier, each trained to recognize one class. Class-specific score values: Each SVM produces a score value that reflects its confidence that the particular area belongs to the class it represents. Thus, for example, if the model has 20 classes, each area receives 20 score values, one from each SVM. Class selection based on score values: After obtaining the score values for each region from all SVM classifiers, R-CNN selects the class with the highest score for the given region as the final classification. Each region is assigned the class that the model predicts is most likely in that location.14
Non-Maximum Suppression (NMS): Since many region proposals may overlap with the same object, R-CNN uses a non-maximum suppression method to prune overlapping proposals. From each group of overlapping regions, the NMS selects the one with the highest point value and discards the others. Ensuring that each object detected is represented in the results only once according to the proposal with the highest score. Result: The result is a set of bounding boxes, each classified into the class with the highest score for that area, with overlaps pruned by NMS. This enables the identification and classification of multiple objects from the same image.14
The R-CNN model allows for accurate and efficient multi-object detection. The model classifies each proposed area into the class that receives the highest score from the separate SVM classifiers. Each area is assigned the class it most likely belongs to, allowing for the reliable detection of multiple objects from the same image.14
R-CNN for expiration date and batch codes recognition
In text character recognition, Regions with Convolutional Neural Networks (R-CNN) architecture combine rectangular region proposals with convolutional neural network features for character detection and classification. As illustrated in Figure 3, the process initiated by extracting multiple region proposals from the source image using the method of selective search (Figure 3a). Each proposed region, potentially containing text, is sent on to the convolution neural network to create a fixed-size feature vector ( Figure 3b). This feature vector serves as the input to a set of linear SVMs that are trained to classify character classes, producing initial classification ( Figure 3c). Detection is further refined using a bounding box refinement layer, which adjusts the coordinates of each proposed bounding box to better align with the actual text characters in the image (Figure 3d).14,15
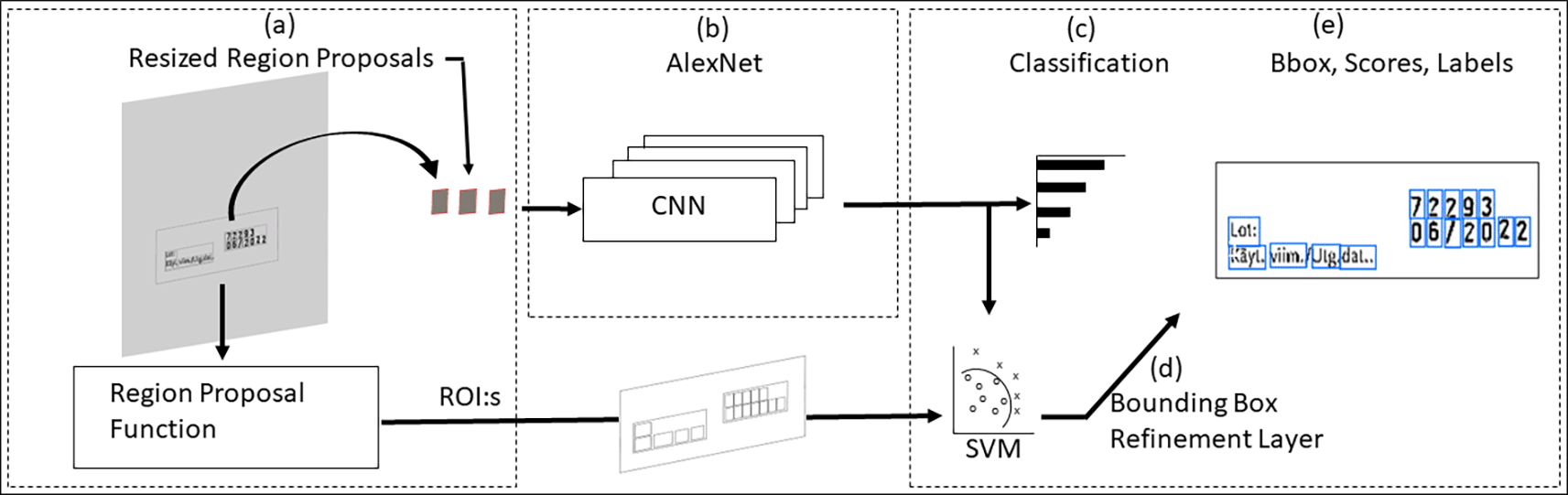
Figure 3. Region-CNN model working principle.
R-CNN’s training process, which combines a large, pre-trained network with a smaller, domain-specific network for fine-tuning, is well-suited for handling the limited datasets and complex labels typical of cardboard pharmaceutical packaging.
Training details
The dataset utilized for training the model contains 27 binarized source images: 16 with dot matrix characters and 11 with pressed, and ink-marked characters. With these images, the model was trained to recognize characters with inconsistencies in their shapes due to the different printing methods used on pharmaceutical packaging. The images were resized to fit the input size of 227 × 227 pixels to fit the input requirements of the pre-trained AlexNet model. The deep learning model employs a dual architecture, combining AlexNet and a region-based convolutional neural network (R-CNN). AlexNet, pre-trained on a large-scale image dataset, serves as a native feature extractor. In this setup, source images resized to 227 × 227 pixels undergo convolution-based feature extraction. This model follows the method proposed by Ross Girshick et al.,14 utilizing high-capacity CNNs for generating detailed region proposals to accurately locate and segment objects. Training was conducted using stochastic gradient descent with momentum optimization, starting with a learning rate of 1e-4, which was reduced by 0.02 after every eighth epoch to improve convergence. Other training parameters include 400 epochs and a mini-batch size of 58. The final layers of AlexNet were modified to match the number of 43 different object classes in the training dataset. To prevent network overfitting, data augmentation techniques such as rotations, scaling and translations were used. These augmented images were then used to train the Region-CNN, fine-tuning it for the specific tasks of detecting and recognizing varied text character features of pharmaceutical packaging. The dataset was randomly divided into a 70% training and 30% validation split for training and thorough validation. This method utilizes both AlexNet’s strengths for extensive initial learning and R-CNN’s strengths for targeted fine-tuning.
Key metrics for evaluating text character recognition models
In the evaluation of text recognition models, such as R-CNN, the most important metrics are True Positives (TP), False Positives (FP), and False Negatives (FN). In this domain True Negatives (TN) are not considered in the evaluation process as the concept of ‘non-character’ regions is inapplicable.16 IoU (Intersection over Union) is a common object detection evaluation metric. IoU measures the overlap between the ground truth boundary box and the boundary box detected by the algorithm.17 IoU, as defined in Equation (1), is calculated as the area of overlap between the ground truth bounding box and the predicted bounding box divided by the area of the union of these two.17
(1)
Positive samples are used in object recognition for supervised learning models, such as R-CNN’s application for text recognition, where the model classifies different areas as containing text. After training and testing, the sample group in such scenarios can be classified into three main states, as shown in Table 1.18
Table 1. Prediction result of the sample set.
| Actual positive | Actual negative |
|---|
| Predicted positive | True positives (TP) | False positives (FP) |
| Predicted negative | False negatives (FN) | (Not applicable) |
Positive samples may create the following scenarios:
1. TP (true positive), in which a region is correctly identified by the model as containing text, IoU ≥ α.
2. FN (false negative), in which model fails to detect text region that is actually present.
Negative samples, which are areas not containing text can create the following scenario:
These formulas are used to calculate precision and recall:
Precision is the proportion of all correctly retrieved samples (TP) that account for all retrieved samples (TP + FP).18 Its equation is, as given in (2):
(2)
The recall is the proportion of all correctly retrieved samples (TP) that accounts for all objects that should be retrieved (TP + FN).18 Its equation is, as given in (3):
(3)
The F1 Score, as defined in Eq (4), is the weighted harmonic average of precision and recall.18
(4)
Results
The experiments aimed to evaluate the recognition accuracy of the deep learning method for text recognition, using images of real-world pharmaceutical packages. The experiments were carried out on available dot matrix printed and ink-marked texts. The recognition results were achieved by comparing the from test image set to the ground truth data.
R-CNN evaluation in MATLAB
At first, the text recognition performance of the R-CNN model was analyzed using a dataset and evaluated using Precision, Recall, and F1 scores. Functions measure the performance of a multi-object detector. The precision metric considers both the number of correctly recognized characters and the number of incorrectly recognized characters. Recall determines the ability of the model to correctly recognize all characters in the image, considering both correctly recognized and those that fail to be recognized. The F1 Score combines precision and recall into a single metric, balancing the rate of correctly recognized characters with the model’s ability to recognize all characters in an image, encompassing both precise recognitions and any missed characters. Figure 4 illustrates the results of the proposed text recognition model’s precision (top), recall (middle), and F1 Score (bottom) at varying thresholds.
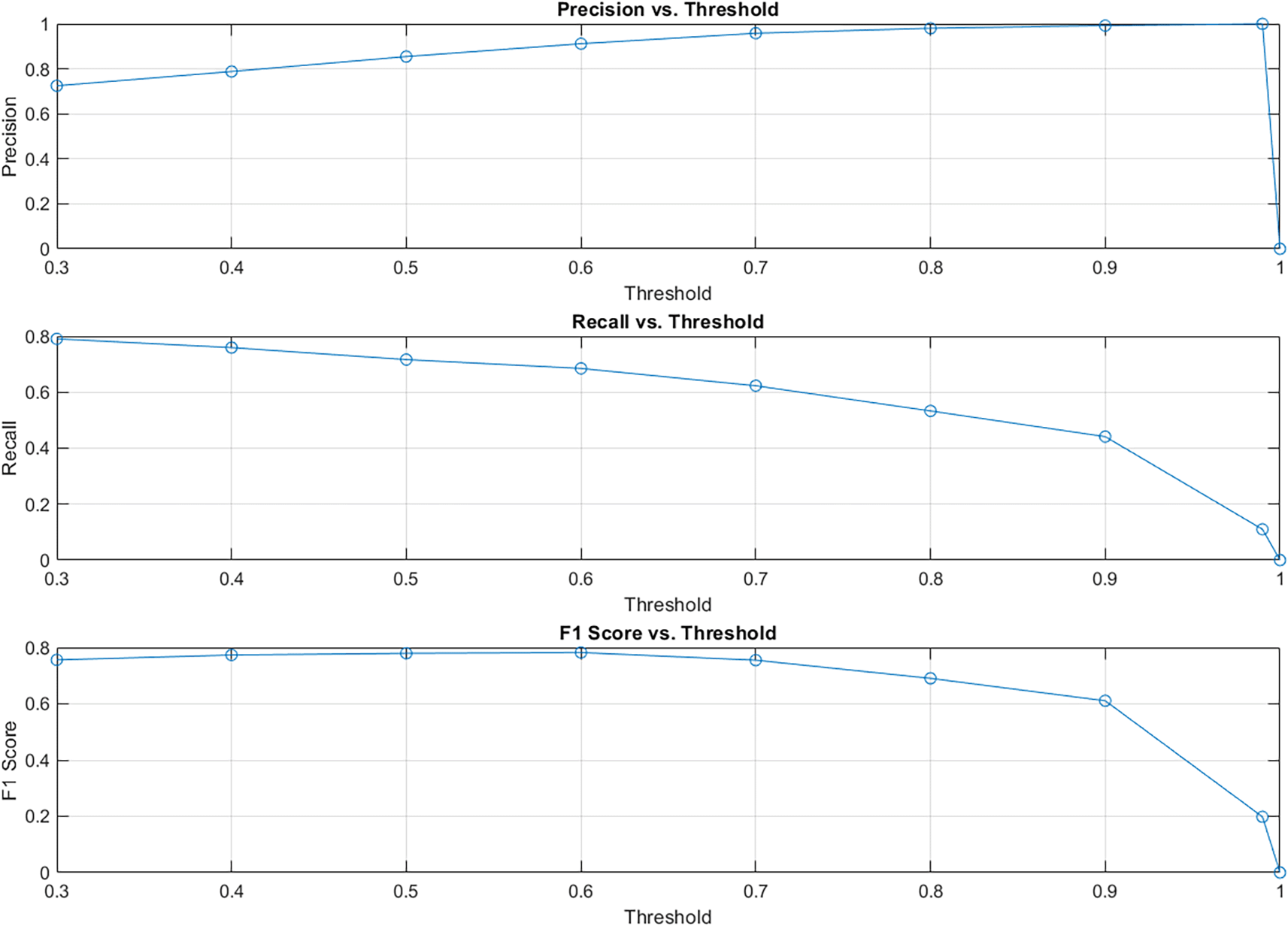
Figure 4. Results of the proposed text recognition model’s precision (top), recall (middle), and F1 Score (bottom) at varying thresholds.
The results in the graph where threshold values are determined by the overlap between the bounding boxes produced by the model and the ground truth, show that the model’s precision remains high across different IoU thresholds. A decreasing recall at higher IoU thresholds indicates the model’s increasing specificity at the expense of sensitivity. The F1 score, a combination of precision and recall, reaches its optimal score at an IoU threshold of 0.6. This threshold indicates the most balanced performance between detecting true positives and avoiding false positives, highlighting the model’s accuracy in distinguishing relevant text characters from background in complex image datasets.
Comparison to Tesseract OCR
In the second experiment, both the R-CNN deep learning model and Tesseract OCR were used to recognize text characters from the same data set. Initially, the total number of characters in each image was counted. The performance evaluation included counting the number of characters that were correctly identified, incorrectly recognized, unrecognized, and those identified more than once. This provided detailed insights into the character recognition accuracy of each method. Notably, the threshold value (α) for the R-CNN model was set to 0.99 to compare its recognition precision against the widely used Tesseract OCR.
Using the same three metrics as in the previous experiment, the text character recognition performance of the R-CNN deep learning model and the Tesseract OCR algorithms is compared in Table 2, with the targets being characters printed on the images.
Table 2. Text recognition performance comparison table based on three metrics.
| Region-CNN (%) | Tesseract OCR (%) |
|---|
| Precision | 91.1 | 38.3 |
| Recall | 72.7 | 61.3 |
| F1 Score | 80.9 | 47.1 |
The comparison reveals that the Region-CNN model achieved a precision of 91.1%, whereas the OCR method’s precision was 38.3%, indicating significantly fewer false positive detections by the Region-CNN model. The recall value of 72.7% indicates that the R-CNN model correctly identifies a significant portion of the characters on pharmaceutical packaging. However, fails to recognize 27.3% of the characters, meaning false negatives. OCR’s recall value of 61.3% to recognize manufacturing markings characters of images on pharmaceutical packages means about 38.7% of the appropriate markings remain unrecognized. The R-CNN model, with an F1 score of 80.9, accurately identifies a high percentage of characters (demonstrating high precision) and efficiently covers a significant proportion of all characters available in the dataset (indicating high recall).
The deep learning model has much higher accuracy and recall ratings. By balancing these factors, the F1 Score illustrates the amount better the model was in this test. In specific, the deep learning model shows to be a better text recognition method, especially able to precisely recognize characters containing more irregular shapes. Figure 5 illustrates the results of text recognition using the Region-CNN method.
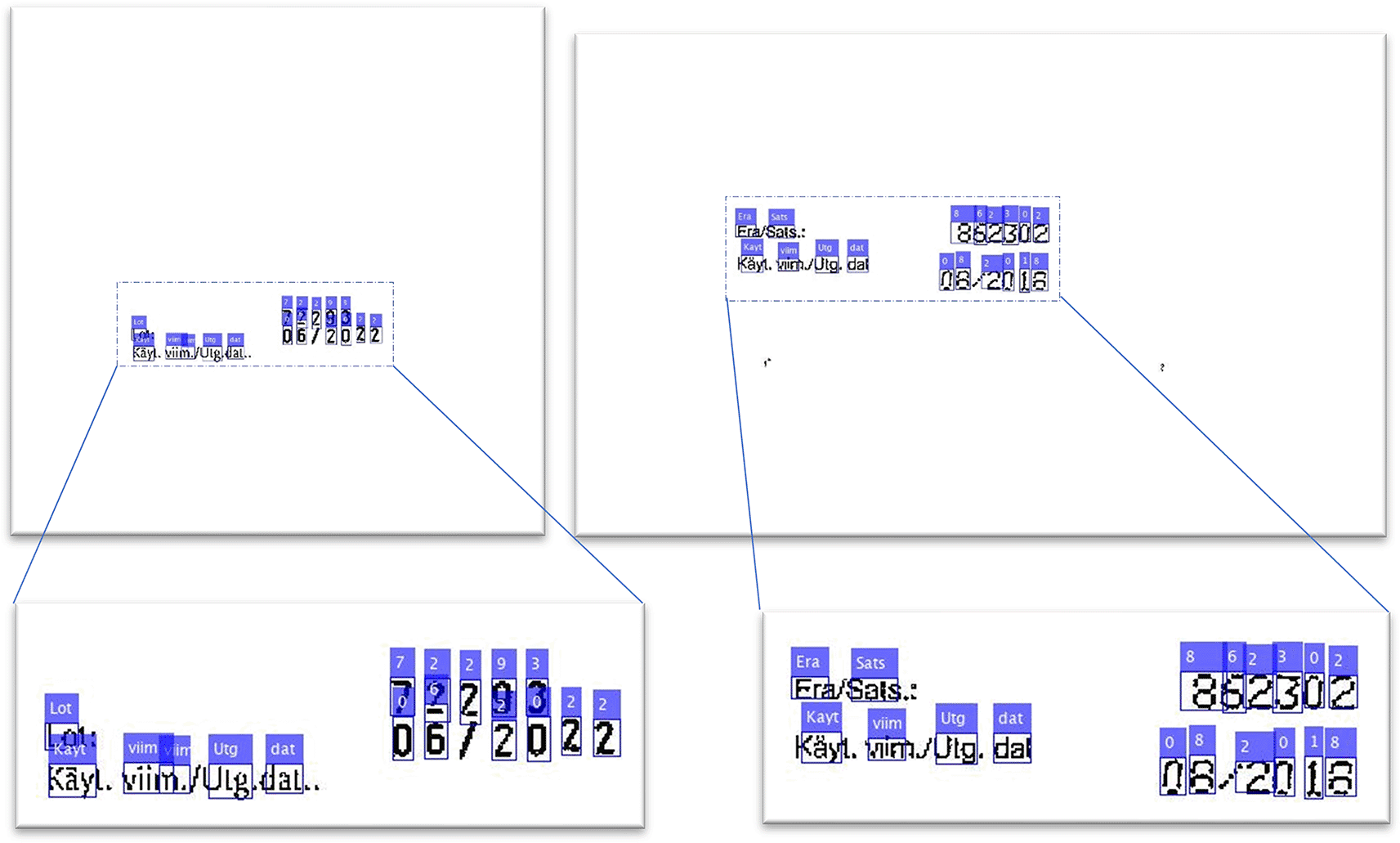
Figure 5. The result of deep text recognition in the whole image.
Left: recognized printed ink-marked packaging text. Right: recognized dot matrix printed packaging text.
Conclusions
In this paper, a novel application of deep learning for text recognition on pharmaceutical packages is presented. A method combining a pretrained Convolutional Neural Network (CNN) with Region-based CNN (R-CNN) is employed for comprehensive feature extraction from each proposed character region. This approach has achieved promising results in the recognition of manufacturing markings and texts with inconsistent character shapes.
Various methods for recognizing text printed on products have been developed. Commercial OCR engines are available that can recognize high-contrast regularly shaped texts printed on flat surfaces. In the industry, large amounts of perishable food and pharmaceutical packages are produced daily, and the texts printed on their surface are read by people several times during the operation. Text is printed on product surfaces using various printing methods to achieve cost-effective production. The pharmaceutical industry employs various printing methods, such as laser printing, pressed without ink, and pressed with ink, resulting in consistent character shapes. However, characters printed using dot matrix and manual stamping methods may have inconsistencies in their character shapes. In places where pharmaceutical product packaging is handled, such as pharmacies and drug storage facilities, where it is essential to recognize texts printed with various methods, a targeted method is required.
We compare the text recognition performance obtained using a Tesseract OCR and R-CNN based method with real-life pharmaceutical packaging in this study. We find that the deep learning method produces highly accurate recognition results that completely outperform the results obtained using a Tesseract OCR, indicating the limitations of optical text recognition for the research’s text recognition needs.
Although text recognition for pharmaceutical packaging texts printed with different methods is an essential task, it is still in its early stages due to the limited availability of source images of actual pharmaceutical packages for research purposes.
To the best of our knowledge, this is the first study in which deep learning is used to recognize inconsistencies in texts printed using different printing methods. We are confident that with more training data, the proposed method’s performance would increase even more.
In the following study, we focus on the domain-specific contextual processing of recognized text characters. This results in a three-phase text recognition pipeline targeted at recognizing manufacturing markings on pharmaceutical packaging. With this approach, we improve the understanding of how deep learning can be applied in this field.
Comments on this article Comments (0)