Keywords
Systems biology, bioinformatics, computational biology, machine learning, maximum entropy method, Bayesian statistics, RNA binding proteins, RNA Bind'n'Seq
This article is included in the Bioinformatics gateway.
Systems biology, bioinformatics, computational biology, machine learning, maximum entropy method, Bayesian statistics, RNA binding proteins, RNA Bind'n'Seq
RNA-binding proteins (RBPs) interact with RNAs at every step of their life cycle. Their modular structure, usually an assortment of RNA-binding domains, underlies their ability to interact with both RNAs and proteins, and couple various layers of gene expression.1 While RBPs are currently known, most remain to be functionally characterized. A first step in this process is to determine the interaction partners and the sequence/structure specificity of the RBP. Many RBPs recognize their targets in a sequence-specific manner, although the accessibility of binding sites within the targets also plays a role.2 The sequence specificity is usually represented in a position weight matrix (PWM), which specifies the probability of finding each of the four nucleotides at each position in the RBP binding site. This is an obvious simplification, as dependencies between positions in the binding site likely occur. However, training more complex models requires substantially more data, which are often not available. Moreover, the improvement in binding site predictability by more complex models is modest, at least in the case of other nucleic acid binding proteins, transcription factors.3 With the realization that the presence of a canonical RNA-binding domains is not necessary for the ability of a protein to bind RNAs4 came a pressing need to determine the determinants of RNA-RBPs interactions and the sequence/structure specificity of the proteins newly found to interact with RNAs.
The past two decades have seen the development and broad application of experimental methods for RBP target identification. They include in vivo high-throughput approaches such as HITS-CLIP, PAR-CLIP, iCLIP and eCLIP (reviewed in Ref. 5), and more recently-developed in vitro approaches such as RNA Bind’n Seq.6 While the CLIP methods rely on the sequencing of RNAs that interact and can therefore be crosslinked to RBPs in vivo, RNA Bind’n Seq relies on the affinity-dependent interaction of RBPs with random RNAs in vitro. The oligonucleotides whose interaction with the RBP (or domain thereof) of interest are computationally analyzed to identify short sequence motifs that are enriched in the affinity-selected pool of RNAs. So far, analyses of such data involved the identification of enriched k-mers (short oligonucleotide sequences of a specified length, ), and then a greedy alignment procedure yielded PWM representations of the RBP binding motifs. This left open the question of whether the derived PWMs accurately predicted the interaction energies of RBPs with their binding sites. In contrast, the aim of our work was to develop a biophysics-anchored method to directly infer the PWMs from RNA Bind’n Seq data. Our paper is organized as follows: Sec. 2 explains how we derive our thermodynamical model. We comment on the practical implementation of this model in Sec. 3, where we also explain how we account for sequence composition biases in the pool of oligomers. Results for different RBPs are presented in Sec. 4, where we also comment on the accuracy of the results obtained from this type of data for different RBPs. Concluding remarks are given in Sec. 5, and a list of publicly available data sets that we analyzed is provided in Sec. 6.
Our model is an adaptation of a Bayesian, thermodynamic model that was constructed to infer di-nucleotide weight tensors from SELEX data.7 In the following, we derive the log-likelihood of Bind’N Seq data given the PWM for the RBP of interest, which will be inferred by expectation-maximization as described in Sec. 3.
We assume that an RBP binds an oligomer over a binding site of length and that the likelihood of the binding taking place, according to Boltzmann’s law, goes as , where is the nucleotide at position , so . Therefore, each element of the position weight matrix (PWM) can be identified with , with their columns being normalized as .
Additionally, we account for the fact that there are genuinely two different ways of binding, sequence-specific binding as described by the PWM, and unspecific binding to RNAs with a probability . Combining these two possibilities, we arrive at the probability for an RBP binding to a site
Consequently, the chance of an RBP being bound somewhere on a longer oligomer with is
Eventually, the logarithmic likelihood of our library of oligomers reads
Our goal is to optimize the parameters in (2.5) such that they maximize the likelihood of our library to be realized in the present way. As a side note, it is equivalent to optimize , or its logarithm because the logarithm strictly increases as its argument increases and decreases as its argument decreases. Since the libraries are typically quite big it is beneficial for us to maximize the logarithm in order to keep the overall numbers under control. While the library , the copy number of a read , the read and binding site length and , and – with some limitations – the frequency priors are given from our data, the position-specific binding encoded by the PWM and the position-unspecific binding have to be obtained during the optimization process. Eventually, we want to obtain the the PWM, whereas represents a hidden parameter which will be inferred via the expectation-maximization procedure. In principle, this would also apply to the concentration but none of our final expressions depend on any more due to the linearization. Before diving into the details of the EM procedure’s implementation we would like to comment on how to infer the frequency priors .
RNA Bind’n Seq data does not only comprise libraries of pulled down RBP-bound reads at different, non-vanishing RBP concentrations, but also control experiments that do not contain any RBPs. The oligonucleotides that were used for RBP affinity-based selection were short, typically 20 nucleotides in length (c.f. Ref. 8). The number of possible 20mers is , much larger than the library sizes of . Thus, even in the absence of selection (), the expected overlap of two libraries is extremely small.
To preserve the statistical power of the foreground pool, i.e. use all the reads detected in the foreground sample in the analysis, even though they were not represented in the background sample, we would have to predict the frequency of foreground reads under the assumption of no selection for binding the RBP. A commonly used approach for this type of problem is to train a Markov model from the background pool and construct the expected frequency of each read in the foreground from the trained model, just as in Ref. 9. For an completely unbiased process of oligomer synthesis and capture, the degree of the Markov model would be , i.e. each base would be equally likely to occur at any position in the oligomer, and all 20mers would have the same prior frequency of occurrence . However, biases in the capture and sequencing of oligomers could lead to some sequences, with specific composition of short nucleotide motifs, being captured more often than others. To account for this possibility we trained Markov models of different orders and found that, in general, the higher the order of the model trained from the background sequences, the better the prediction of likelihood of sequences in the foreground samples. Thus, we used a Markov model of order , which allows the most accurate prediction of background reads frequencies with our computational resources.
Having constructed our model, with the final expression (2.5), and having constructed the background frequencies as described in the subsection above, the main remaining question is how to optimize the PWMs and such that the likelihood for the result being realized (c.f. (2.5)) is maximized. To this end, we rely on the expectation maximization algorithm.10,11 Provided that only some of our model parameters can be directly inferred from the data, the algorithm optimizes the “hidden” parameters to maximize (2.5). The expectation-maximization procedure (EM) can be divided into the following steps:
1. Initialize and the PWM elements with respectively well-defined real numbers, i.e. and . This can either be done in an entirely unbiased way or by pre-determining some motifs and specifying randomly or uniformly initialized positions in the PWM.
2. Optimize to maximize (2.5) holding the PWM fixed.
3. Updating the PWM with the new from the previous step. The update of the PWM works by splitting the data set into -mers (on a read ) and adding the weight
to all entries in the PWM corresponding to . Repeat that for all in , and over all in . Renormalize the PWM again by enforcing .
4. Repeat the previous two steps until convergence. We terminate the iteration when the quadratic difference between the current and the updated PWM is less than on average per entry, i.e. for the quadratic difference is less than . Usually, this takes iterations.
Our code is written in C++ and python and is publicly available.12
In analyzing Bind’n Seq datasets for various RBPs, we found that only a small subset of random initializations deliver a convergent EM process. The larger is the larger is the space of possible initializations, therefore it becomes increasingly unlikely to accidentally hit a region of initialization which converges. This could be compensated for by increasing the number of runs by a factor of for each additional position in the PWM. To avoid that, one can use the knowledge of previous runs, done with shorter PWMs and initialize the longer PWM from the shorter PWM, filling up the additional entries with randomly initialized values to check if the shorter PWM is part of a longer PWM. We carry on with this procedure until the EM algorithm does not find any minimum any more amongst 12 different random initializations of and the random initialization of the PWM at the additional positions. Sometimes, neither a fully random intialization nor an initialization of the PWM “guided” by prior knowledge lead the EM algorithm converging to a minimum in log-likelihood (2.5). The relative efficiency of the algorithm finding true maxima is displayed in Figure 1 for the RBPs discussed in the following section. We consider an outcome of the algorithm to be a “true” maximum if the posterior log-likelihood is larger than the initial one and the algorithm is not stuck in a region where is large, meaning that the unspecific binding dominates. The maximization algorithm is eventually terminated by a limit of 200 iterations. For readability, we list the used Bind’n Seq data files from Ref. 8 in Table 1 in Sec. 6.
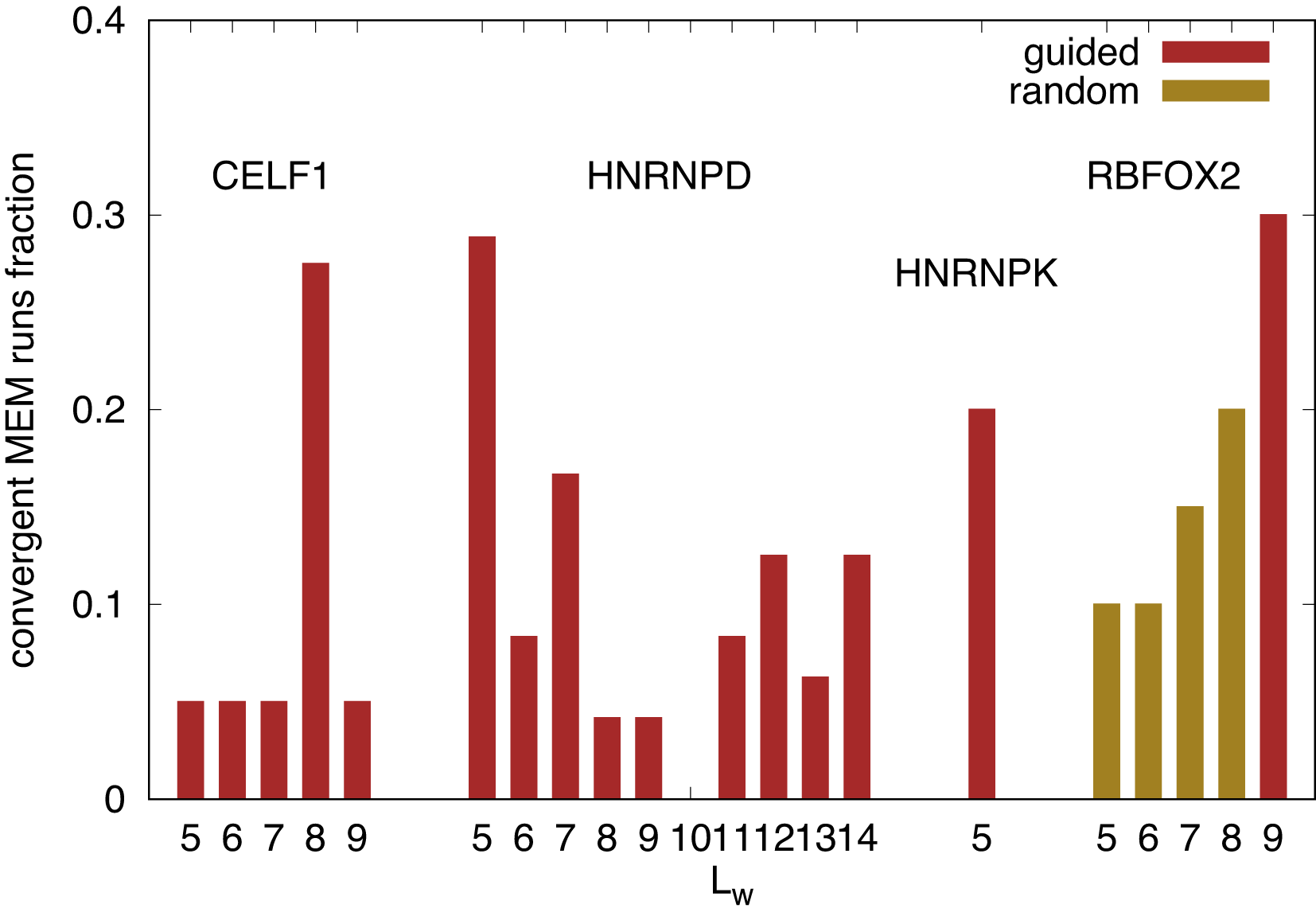
RBPs and binding site lengths with no convergent maxima of the log-likelihood (as described in the corresponding subsections, e.g. subsection 4.6) were discarded. While is always initialized with a negative random number, the PWM can be initialized either “guided” by already obtained shorter motifs or literature motifs (c.f. corresponding subsection of Sec. 4), or with a fully “random” PWM.
To benchmark our method, we started our evaluation with RBFOX2, a key regulator of alternative splicing13 that was extensively studied with a variety of methods (e.g. Ref. 14). The RBFOX2 Bind’n Seq dataset8 consists in nine libraries at nine different protein concentrations and two protein-free control libraries, all containing reads of 50 nucleotides (nts) in length, including the adaptor. RBFOX2 is widely used to benchmark computational analysis methods (c.f. Ref. 15) and thus the corresponding dataset was carefully generated, to include multiple, high-quality libraries. Established techniques like kmer-enrichment analysis and the streaming-kmer-algorithm (SKA) predict a consensus 6mer TGCATG as the most prominent motif followed by other GCATG-containing 6mers.15 Our results in Figure 2 reproduce the predicted TGCATG 6mer as a part of the motif Figure 2(a). Moreover, we find the subdominant PWM Figure 2(b) which has a quite substantial overlap with Figure 2(a) in the first four positions. We therefore consider an important real world data test of our code to be passed.
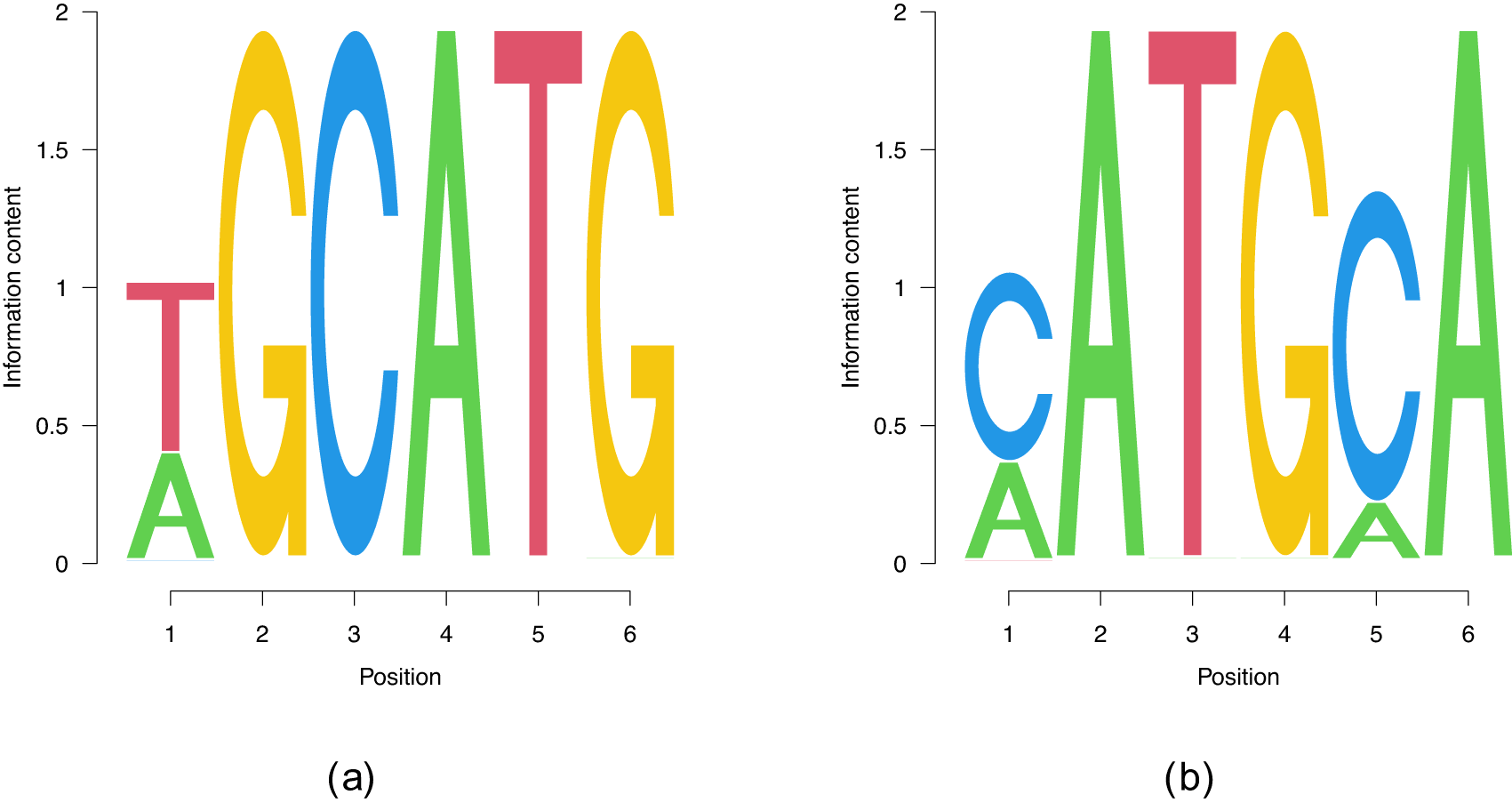
(a) The consensus motif that features a higher than (b). However, (b) is also present.
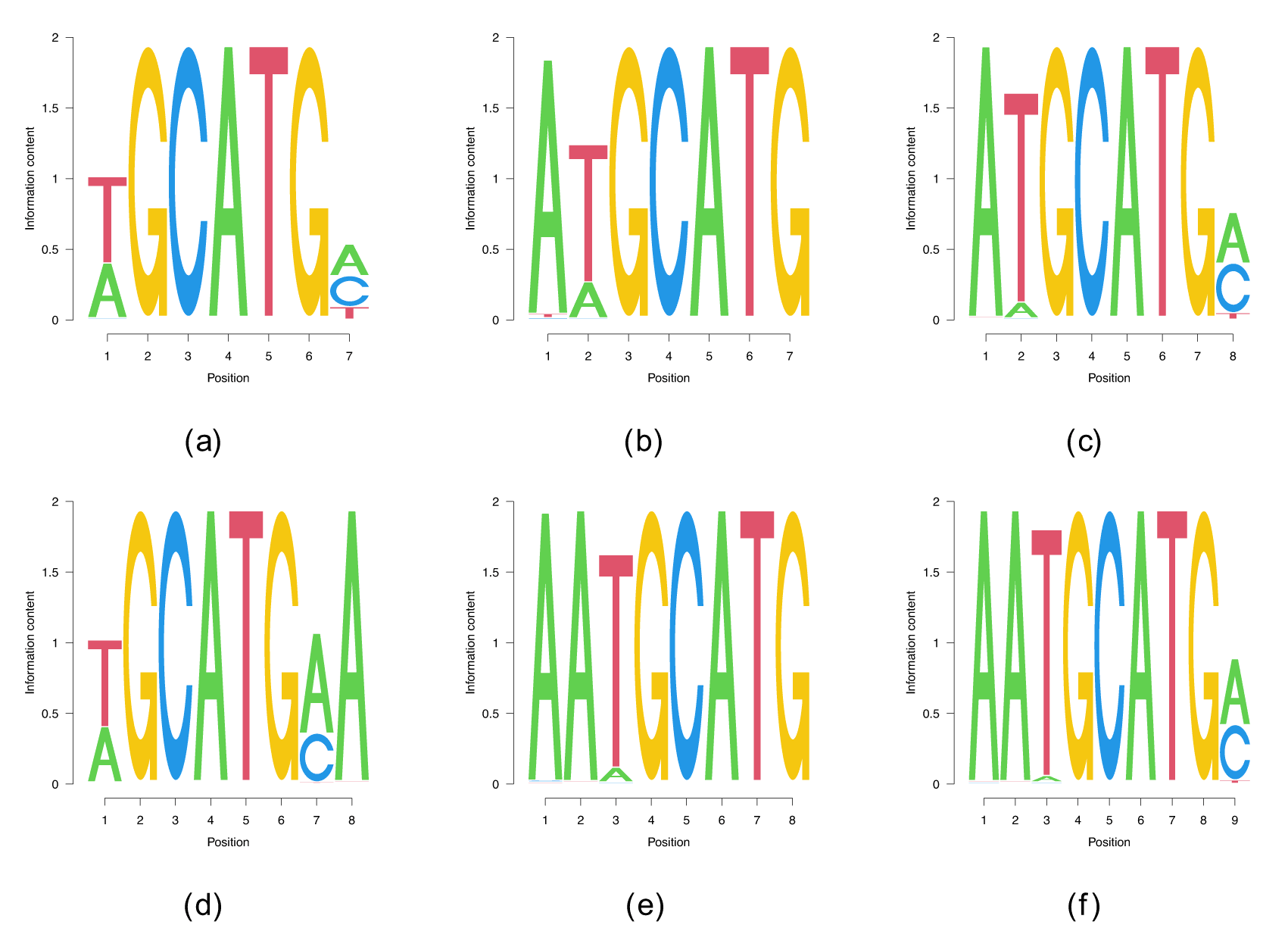
The big overlap of the motifs Figure 2 suggests also searching for longer motifs, which may subsume the shorter ones. Indeed, the motif shown in Figure 3(d) contains both 6mers. Along with that we find local minima in the probability landscape, i.e. PWMs of (see Figure 3). All motifs have the consensus TGCATG in common. For RBFOX2, we found no evidence for our model to converge beyond . The posterior probability – (2.5) at the optimized parameters – serves as a measure to compare and rank different motifs at equal . The Bayesian Information Criterion (BIC)16 estimates the information content of every obtained local minimum,
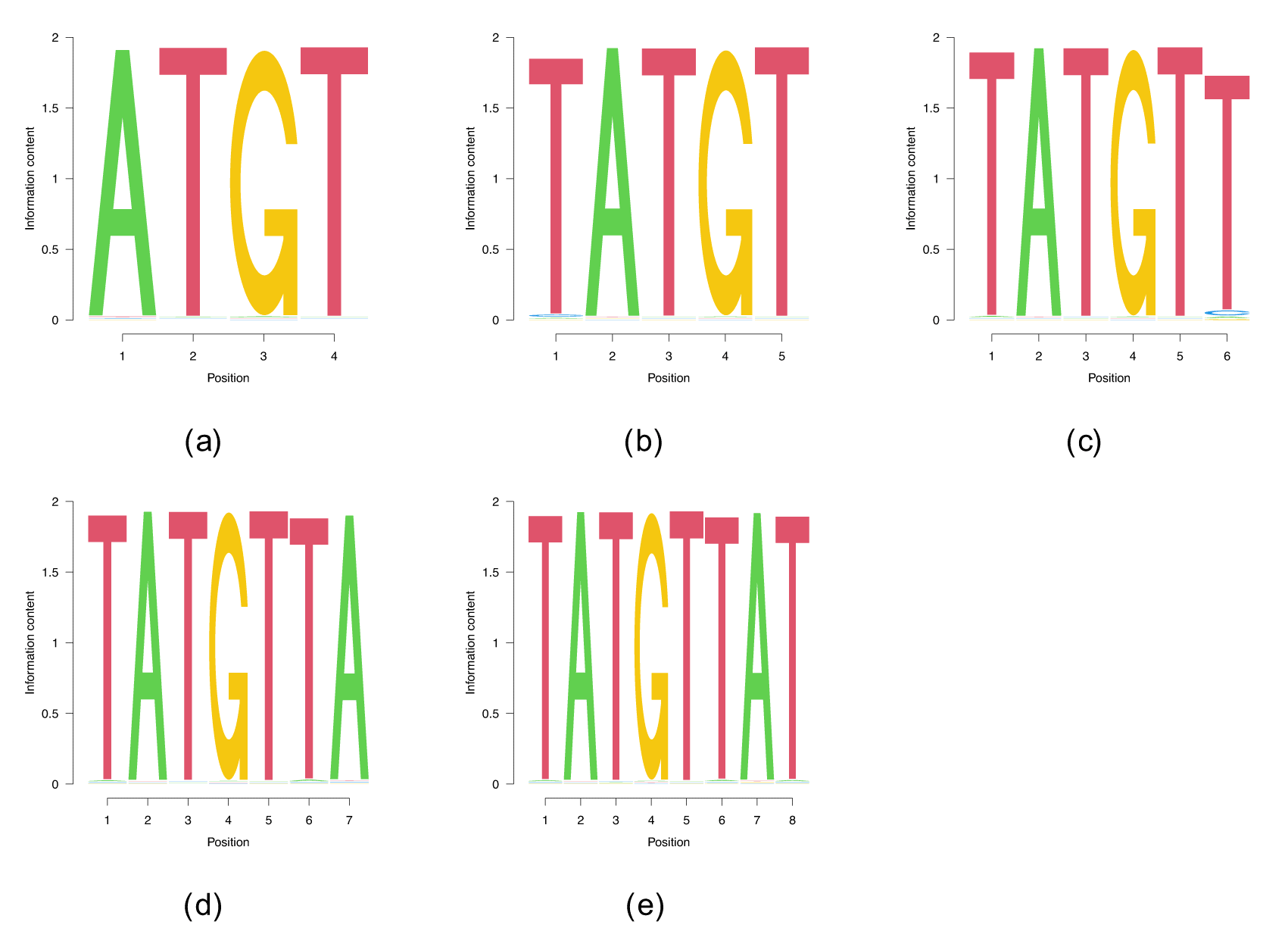
CELF1 is an RBP of the CUG-binding CELF family.18 CELF1 participates in multiple steps of post-transcriptional processing of RNAs, including splicing, translation and decay,19 and requires UGU motifs for high-affinity interaction with RNAs.20 The corresponding Bind’n Seq dataset8 consists of libraries generated for seven different RBP concentrations, each containing reads of . Since 40 runs with completely random PWM intialization for did not yield any local optima of the probability landscape we decided to test whether the biased initialization of the PWM with the known motif (/), which was found as as enriched 3-mer in RNA Bind’n Seq8 enables the recovery of longer motifs. Indeed, our procedure yielded multiple extended versions of TGT Figure 4 with up to . The context in which the reduced motif occurs is A/T-rich, the presence of an A immediately upstream indicates that CELF1 could recognize the AUG start codon. This could be interesting in light of CELF1 being a translational regulator of epithelial-mesenchymal transition via the binding of both cap-binding EIF4E and the poly(A)-binding protein.21
Within the class of heterogeneous ribonucleoproteins (hnRNPs), hnRNPD (also known as AUF1) is a well-known A/U-rich element RNA binding protein with important role in RNA decay.22 HNRNPD has been reported to bind clusters of AUUUA elements.22 The ENCODE-database8 lists AUAAU as another possible binding site for hnRNPD. While entirely random initializations do not deliver any convergent runs, we recover both AUAAU, and, with a smaller binding log-likelihood, AUUUA, as binding sites. Building on this shorter motifs enables the discovery of UAAAU-containg longer motifs that can be extended up to (see Figure 5), the highest length for which we found convergent results. We did find PWMs with which we omitted in Figure 5 since they are parts of the two PWMs.
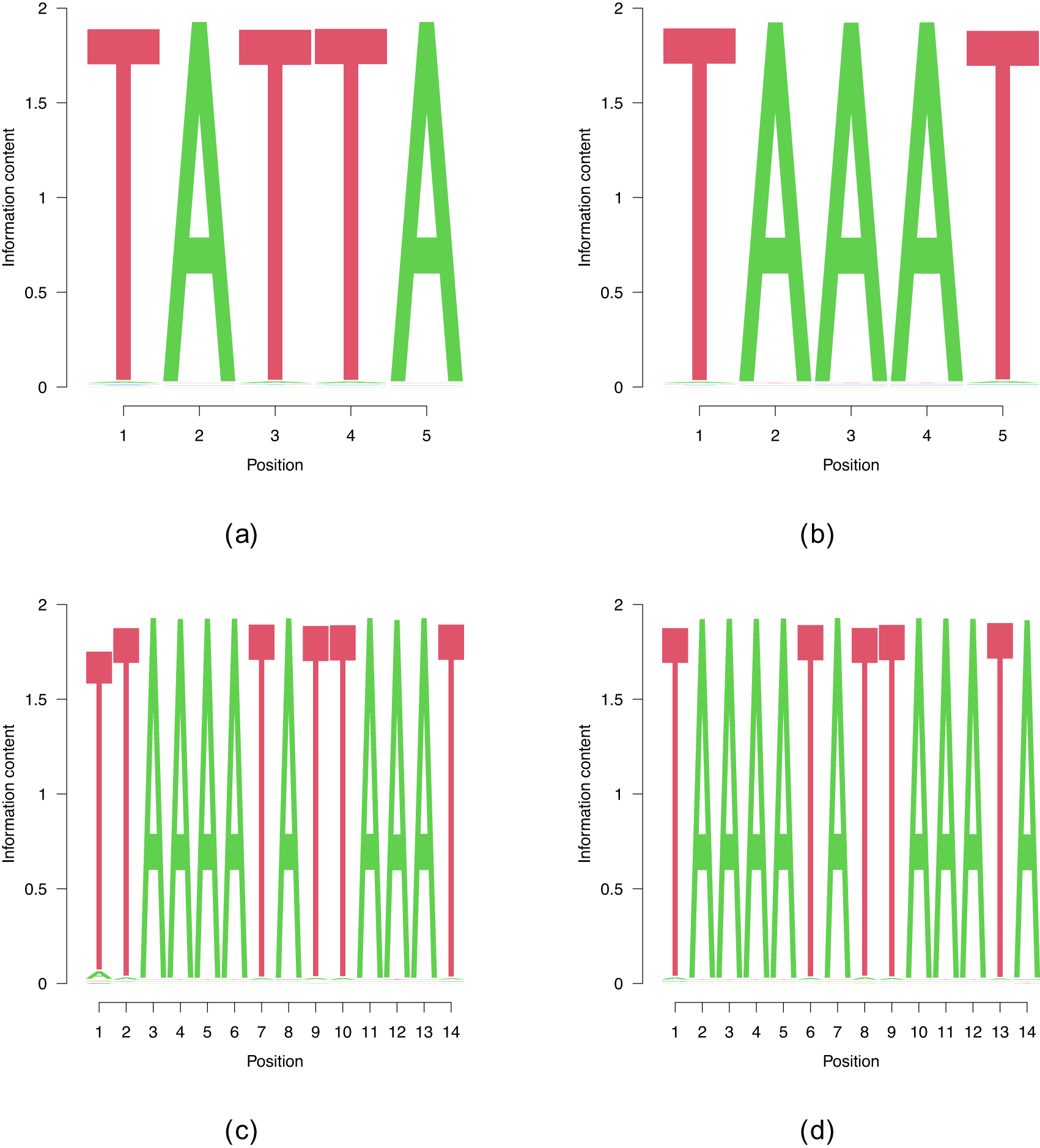
The benchmark cases are show in (a) and (b), whereas (c) and (d) show the two motifs of , the longest motifs that our algorithm found.
We were also interested in determining whether we can recover G/C-rich binding motifs from the data and therefore applied the model to heterogeneous nuclear ribonucleoprotein K (HNRNPK), a member of the poly(C) binding family of proteins.23 We could only recover one of the two consensus motifs reported in the ENCODE analysis of these data (GCCCA, from SKA8) when initialized with it. The second reported motif, with the CACGC consensus, could not be found by our algorithm even when the PWM was initialized with the motif itself and even when sequences containing the first motif were eliminated, indicating that this motif does not correspond to a local maximum of the likelihood function. We did not find any PWMs of in this data set, whether we used random initialization or shorter motif-guided initialization.
There are other proteins covered in the Bind’n Seq data8 whose specificity was studied before. For example, we analyzed the data corresponding to MBNL1,24 hnRNPL,25 FUS,26 TAF15.27 For these, our model did not deliver any convergent results, even if the PWM was directly intialized with the expected consensus motif. This indicates that the enrichment did not work equally well for all the RBPs studied with the Bind’n Seq method. Interestingly, expected motifs were identified for these proteins with another method, the so-called kmer-enhancement that underlies most of the consensus motifs reported in the ENCODE database.8 Kmer enhancements are computed by counting the number of occurrences of every possible kmer in the foreground samples (RBP concentration ) and in the background samples (RBP concentration ), and finally normalizing the foreground abundances by the background to extract the respective enhancement. The higher the enhancement of a given kmer, the higher the likelihood of it being bound by the RBP used in the experiment is thought to be. We computed these enhancements for 6mers, as done in the ENCODE studies. The results, shown in Figure 6 indicate that only RBFOX2 has a few highly enhanced 6mers with a clear hierarchy of enrichment, while all other investigated RBPs show a much flatter hierarchy of motif enhancements. An analysis of the Levenshtein distance of these motifs showed no clear difference in the pattern of distances among the leading motifs across the investigated RBPs. This suggests that these motifs correspond to many local minima of comparable depth, which precludes our algorithm finding clear PWMs representing the binding sites. Conversely, it becomes unclear whether the specificity of these RBPs would be well represented as weight matrices, or whether another model, for e.g. clusters of short, degenerate motifs may better represent the specificity of these RBPs.
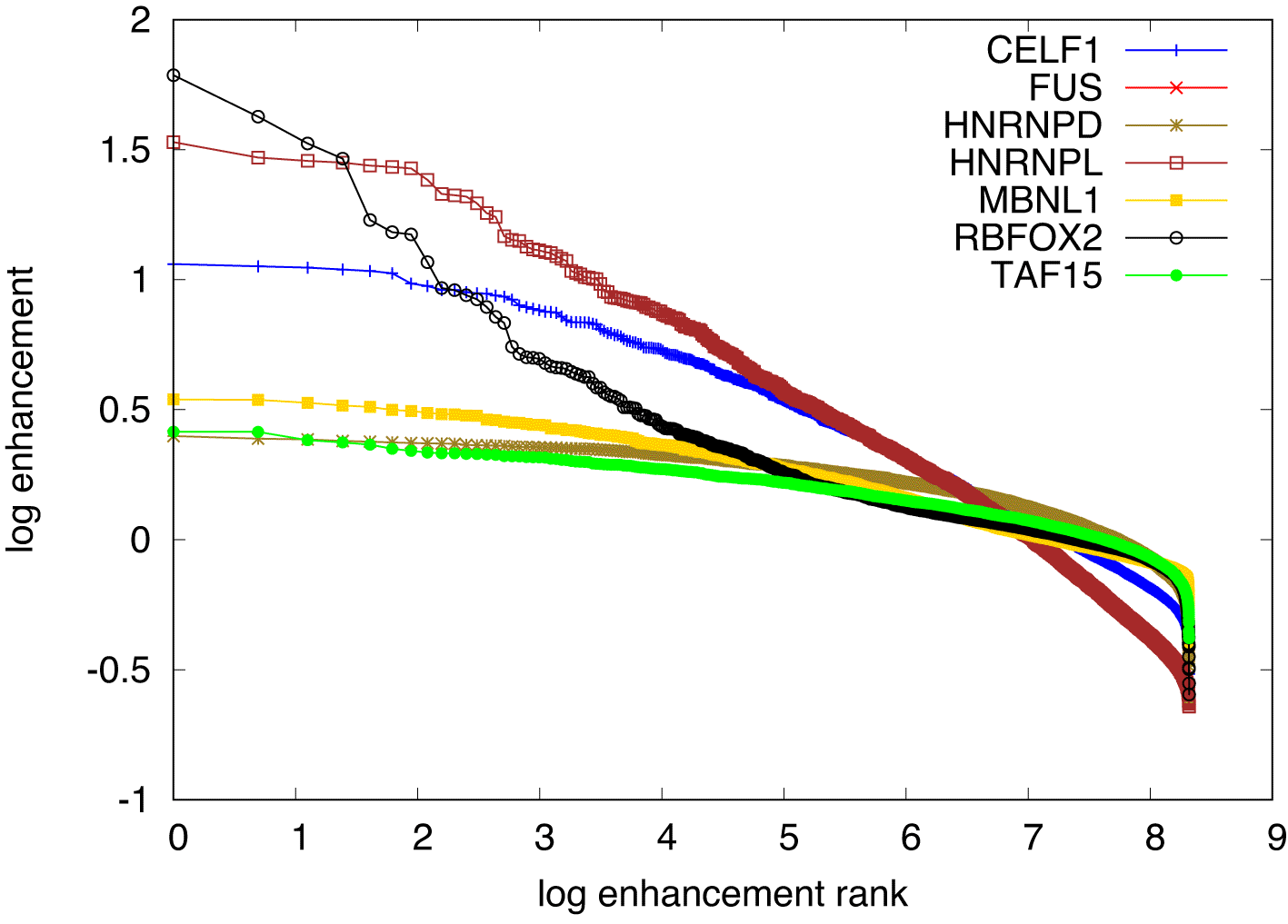
The top most enhanced motifs are RBFOX2: TGCATG, FUS: GCGCGC, hnRNPL: CACACA, MBNL1: GCTGCT, TAF15: GGGGGG, followed by variants thereof. All except the RBFOX2 motif are repeats of shorter oligomers.
We constructed a thermodynamical model that can be used to infer characteristic position weight matrices for the binding domains of RNA binding proteins from data obtained from affinity-based enrichment of oligonucleotides. Since we directly model the RBP-binding specificity as PWMs, our method bypasses arbitrary choices in the alignment of k-mers found to be individually enriched in the data. We evaluate our model on data in the public domain8 using expectation-maximization. For the benchmark case of RBFOX2, where very high-quality data is available, our model reproduces the known binding motif TGCATG where the first position features an almost uniform superposition of T and A in our result. Subdominantly, we find another PWM of as well as longer PWMs for RBFOX2. Unfortunately, our principled model does not robustly recover the binding motifs of other RBPs. For a few, e.g. CELF1, HNRNPD, HNRNPK, we can still recover the motifs as well as some longer variants, if the search starts from a PWM closely matching the expected motif. However, for most of the data sets our model did not deliver any prediction. Rather, other motifs, e.g. poly(A), often show higher enrichment in the data than the expected motifs. This indicates that experimental details that do not have to do with the affinity of the RBP for oligomers affect the frequency of oligomer capture in the data, complicating its analysis and raising questions about the biophysical realism of the motifs derived from the data. The motifs of the RBPs for which we did not recover a PWM tend to be more degenerate than those of RBPs for which some motif emerged. They consist of repeated occurrences of mono, di or trinucleotides. It is likely that for these motifs, it is crucially important to construct an appropriate background model. How to best do this remains to be determined in future work. Of note, while crosslinking and immunoprecipitation data is available for the proteins studied here, PWMs with enriched binding sites were also not recovered.28 Thus, it will be interesting to explore models that allow more flexible spacing of RBP contact points on RNAs in the future.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)