Keywords
Sampling Error; Performance Evaluation; Efficiency; Data Envelopment Analysis; Non-parametric Tests; Banking industry
This article is included in the Manipal Academy of Higher Education gateway.
Sampling Error; Performance Evaluation; Efficiency; Data Envelopment Analysis; Non-parametric Tests; Banking industry
Additional literature supporting the research gap and a summary of the review in a table (Table 1) is added in the literature review section highlighting the gap.
Managerial and policy implications are added under the conclusion section.
Additional references are also added.
A new author was added.
See the authors' detailed response to the review by Katerina Fotova Čiković
See the authors' detailed response to the review by Weng Hoe Lam
Performance measurement and productivity improvement are vital for any organization as they help assess their performance and compare with benchmark organizations or set benchmarks to identify weak areas and opportunities for performance enhancement.1 Among the various performance indicators, efficiency is crucial and frequently used as an assessment tool against comparative benchmarks. Banks operate in a highly competitive market, and efficiency evaluation helps identify areas for improvement and develop sustainable strategies for performance enhancement, leading to a better competitive position in the industry. Financial ratio-based evaluation is adopted widely in performance assessment, which can be misleading as the benchmarks are arbitrary.2 This shortfall has increased the adoption of frontier performance evaluation methods across industries, including the banking sector.3,4 One commonly used non-parametric technique is Data Envelopment Analysis (DEA) in the banking industry. DEA is opined as the aptest approach for relative performance efficiency calculation for banks as DEA methodology is considered superior to traditional ratio-based analysis embraced for conventional performance evaluation.4 However, inferences drawn with DEA methodology based on samples can lead to possible sampling error.5,6 This study demonstrates the impact of such outlier samples that can skew the efficiency computed using DEA methodology with the secondary data available in financial statements and reports from a sample set of banks. The study offers a novel contribution along with statistical evidence on the possible sampling error that can creep into the performance evaluation of organizations while applying the DEA methodology.
As per DEA methodology, the efficiency of any service process or system can be computed as a ratio of output to input.7 Considering several inputs and outputs, the efficiency of each decision-making unit (DMU) can be written as
The model for efficiency computation considering the multiple outputs and multiple inputs based on the above is given by
Where “Em is the efficiency of the mth DMU”, “yjm is the output of the mth DMU”, “vjm is the weight of the output”, “xim is the input of the mth DMU”, “uim is the weight of the input” and “yjn and xin are the jth output and ith input”
Based on the Linear Programming problem technique, DEA computes efficiency with two assumptions of return to scale - constant and variable,7 where constant return to the scale-based assumption of DEA is referred to as the overall technical efficiency. At the same time, variable returns to scale decompose overall technical efficiency into two components: pure technical efficiency and scale efficiency.8
The available literature on the discrepancies that can happen in DEA methodology is very scant. Those discussions on variation in performance efficiency are primarily about sample size and the possible interpretation errors during decision-making. Zhang & Bartels8 analyzed the variation in efficiency based on sample size using Monte Carlo Simulation. Using data from electricity distribution companies, they evaluated the efficiency and proved that the estimated mean technical efficiency decreases with increased sample size. The impact of sample size on the results of models involving non-discretionary variables was studied by Staat.8 Smith5 discussed the model misspecification in DEA, specifically when the sample size is insignificant. Banker and Chang8 discussed the procedure to detect and remove the outliers in the DEA approach. However, their approach was to remove selected observations or samples. However, the variation that can creep in due to the inclusion and exclusion of a specific set of samples is not considered. While Johnson & McGinnis6 focused on the mathematical model of inefficient outlier detection, Chen & Johnson9 developed a mathematical model to detect efficient and inefficient outliers in efficiency computation.
Though the DEA model is a robust tool for assessing the relative efficiency of a group of homogenous DMUs, the key limitation of traditional DEA models is their inability to distinguish between efficient DMUs. As Wichapa et al.10 highlighted, cross-efficiency measurement offers a valuable extension to the standard DEA approach, enabling a more effective ranking of all DMUs and addressing this limitation. The methodological challenges in comparing different ranking datasets for DEA time-series efficient analysis11 have been emphasized. Vaninsky12 found the DEA model advantageous compared to other approaches in his study because the model was non-parametric. To overcome the inherent drawbacks of DEA, Jauhar and Pant13 tried to develop an efficient system for traditional multi-criteria performance evaluation tools, and the study resulted in a more realistic outcome. Addressing the sampling error in DEA involves dealing with population distribution uncertainties,14 multicollinearity,15 and careful model selection.16 Sampling errors in DEA can significantly impact the accuracy and stability of efficient estimates. This issue arises due to the population distribution uncertainty and input and output variables selection. The accuracy of DEA efficiency scores was questioned due to the uncertainty of the population distribution. This uncertainty can lead to misleading efficiency scores if not adequately addressed.14 The choice of the DEA model and the selection of input and output variables are critical; selecting the most appropriate model can help reduce the impact of sampling error.16 The study by Ahn et al.17 evaluated whether the input-output specification used in DEA for banks aligns with the criteria banks use in decision-making. Four bank behavior models were applied to determine input and output factors in DEA studies. A comparison of these models with standard DEA models reveals pitfalls and the study found that these issues prevent conventional DEA models from accurately capturing bank behavior, making the result less reflective of actual performance. Charles and Díaz18 have proposed an index that is a non-radial variation of traditional DEA scores, addressing common issues in DEA-based indexes, such as assigning unreasonable weights. Further, the authors recommended using a meta-frontier method to compare the competitive performances across different evaluation periods. Table 1 outlines the prior studies on sampling errors in Data Envelopment Analysis and identifies a few critical gaps in the literature, emphasizing the need for further investigation on whether sampling errors result in misleading results in performance evaluation.
| Source | Country of study | Sample description | Key findings | Gaps identified |
|---|---|---|---|---|
| 1 | India | The study included 42 companies operating in the OGP sector and forming part of the NSE 500 index | The study found that about 38% are technically efficient as well as scale efficient, whereas about 62% are pure technically efficient. | The study was limited to the OGP sector of India. |
| 5 | The UK | The study examined 10,000 observations using Monte Carlo simulation to yield a series. | The investigation revealed that the risk of misspecification is most consequential when simple models are incorporated with a small sample size. | The study examined the impact of using a mis-specified DEA model on efficiency scores. However, significant differences in the efficiency scores were overlooked. |
| 19 | India | The study included 27 PuSBs and 22 PrSBs, i.e., 49 banks' efficiency, have been measured. | The study revealed that PuSBs outperformed PrSBs in all categories of efficiencies. | The analysis was limited to measuring the OTE, PTE and SE of PuSBs and PrSBs from 2009 to 2010 and emphasized further empirical research in the field. |
| 20 | India | The analysis included a sample of 44 banks operating in India. | The study results found that slack and radial movements are crucial in efficiently utilizing resources. Lower technical efficiency and low performance lead to higher costs and increased customer service prices. | The study focused on assessing the underutilization of public goods & resources and the resulting poor technical efficiency and components. |
| 8 | Germany | The study included the original data for re-evaluation - which consists of 69 pharmacies. | The study disclosed, through reanalysis of the original data, that the efficiency scores are significantly affected by variations in the sample size inherent in the model. | The study was limited to demonstrating the effects of sample size on the results of models for non-discretionary variables through a reanalysis of the original study data. |
| 9 | Taiwan | The analysis encompassed a series of mathematical observations across all four case studies. | The model applications in the study indicated that the observations with low-efficiency estimates are not necessarily outliers. | The study tried to develop a unified model to identify efficient and inefficient DEA outliers. Furthermore, the study stretched the need for empirical evidence on the DEA model. |
| 11 | Germany | The study included 70 European universities with budget and staff input data for the period of 2011–2016. | The analysis found no evidence of a specific index data issues for the application of ranking data in DEA efficiency analysis | The primary attention of the study was analysing the methodological challenges specific to comparing different ranking datasets, particularly index-based versus additive data, for DEA Malmquist index time-series efficiency analysis. |
There is a significant amount of research on the performance evaluation of banks based on DEA.2–4,21–28 These prior studies have given insight into the efficiency of the performance of private and public sector banks in different contexts. These studies using DEA methodology have computed the efficiency based on the sample data collected from financial reports and published reports, and inferences are made according to the efficiency output from DEA methodology. However, the sampling error that can creep into performance evaluation studies using DEA methodology needs to be addressed, as it often gives misleading results regarding the efficiency of sample organizations under study. More precisely, which decision-making units under study must be chosen as the sample in the survey? The DEA methodology is a relative efficiency evaluation technique, and it will lead to misleading extrapolation when proper samples are not considered. Therefore, the problem statement framed is “Do sampling errors result in misleading results in performance evaluation using DEA methodology?
The study aims to critically analyze any significant difference in the efficiency scores due to the inclusion or exclusion of specific sample(s) in DEA methodology-based studies. State Bank of India (SBI) is the outlier to test the hypothesis, as stated below.
“There is no significant difference in the average efficiency scores between the two groups, SBI included and excluded, respectively.”
“There is a significant difference in the average efficiency scores between the two groups, SBI included and excluded, respectively.”
The performance efficiency scores of banks are calculated using DEA methodology.7 The study sample comprises 20 selected banks in India, which include fifteen public sector and five leading private sector banks based on their market share. The data for analysis for all 20 banks were retrieved from the published audited reports and Profit & Loss statements of banks available on the respective bank websites.29 The period of data collected is from 2014 to 2017 for all the 20 banks selected, which is before the demonetization policy implementation by the Government of India30 and before the mergers of many public sector banks in India31 so that the effects of such a major national-level policy implementation and mergers do not have any impact on the data analysis. Overall technical efficiency based on DEA methodology was computed with the input variables as total and employee expenses and net Non-Performing-Assets (NPAs), considering the two critical variables per the literature review: total income and operating profit as outputs. Efficiency was computed in two groups, with one group of DMUs including SBI (State Bank of India) and another group excluding SBI. SBI is selected for comparison sample as the values of all the variables for SBI considered in the study indicate it as an outlier and, hence, the most suitable sample to compare. The results were analyzed to study the efficiency distribution after the computation of performance efficiency scores of the DMUs. Further, the Mann-Whitney U test is adopted to test the differences in the average distribution between the two groups.32 The free version of the DEAFrontier tool32 was used to calculate efficiency scores using DEA methodology, and the open-source R programming software was used to perform the non-parametric hypothesis test. Data visualization was performed using Python open-source programming software.
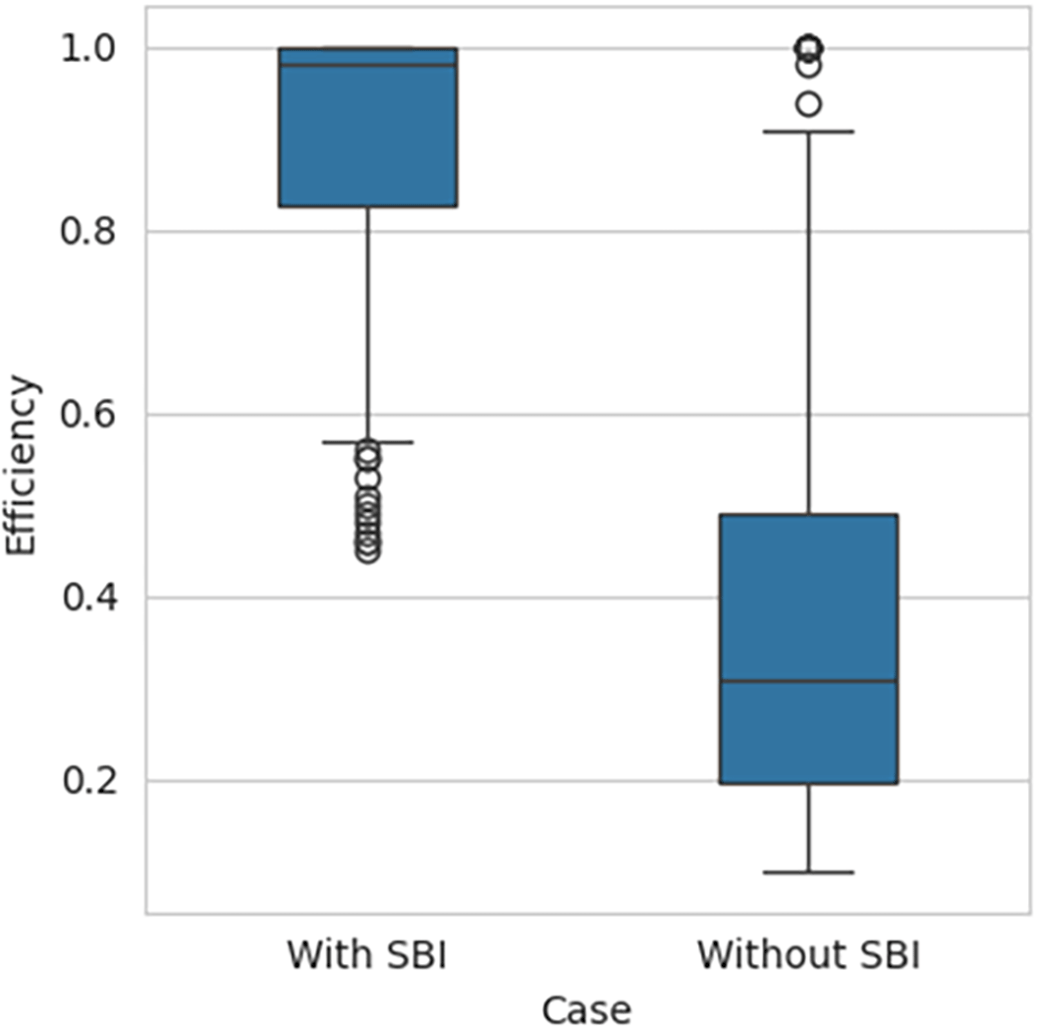
The performance efficiency score was calculated using DEA methodology, with the SBI sample included and later excluded for comparative analysis. The histogram showing the performance efficiency of the samples – with SBI included and SBI excluded, as shown in Figure 1 and Figure 2, respectively, indicates that the efficiency scores are not normally distributed. The box plot for the performance efficiency scores, with SBI included and SBI excluded, shown in Figure 3, also confirms that the efficiency scores are not normally distributed.
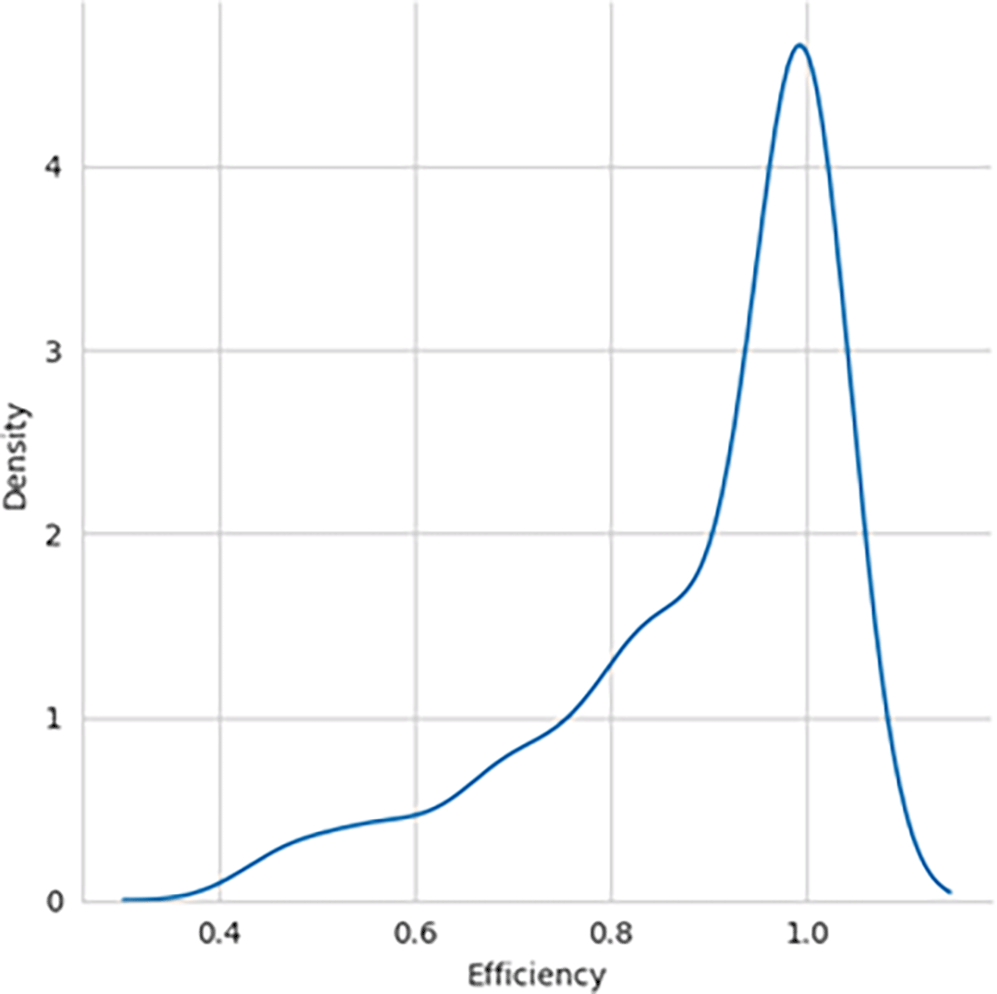

Shapiro-Wilk Test is performed to check for normal data distribution, and the test results are shown in Table 2. W-static and p-value for both SBI included and excluded confirm that the distributions are not typical. Skewness and Kurtosis measures also indicate that the efficiency of samples with SBI included having negatively skewed distribution and without SBI included as positively skewed.
| Measure | SBI included | SBI excluded |
|---|---|---|
| W | 0.77683 | 0.82856 |
| p-value | 2.2e−16 | 3.8392e−15 |
| Skewness | -1.29 | 1.19 |
| Kurtosis | 0.736 | 0..325 |
Since the data is abnormal, non-parametric tests are applied to test the hypothesis. The results of the Mann-Whitney U test for independent samples test are shown in Table 3. The p-value is almost equal to 0 at a 0.05 significance level.
| Minimum | 25% | Median | 75% | Maximum | p-value | |
|---|---|---|---|---|---|---|
| SBI included | 0.4492 | 0.8273 | 0.9800 | 1.000 | 1 | 5.34e−52 |
| SBI excluded | 0.0954 | 0.1986 | 0.3068 | 0.4923 | 1 |
Interpreting from Table 3, Ho can be rejected, indicating that there is a statistically significant difference in efficiency distribution between the performance efficiency calculated with SBI included and excluded. Wilcoxon signed-rank test with continuity correction33,34 was also performed to test the following hypothesis:
“There is no significant difference in the efficiency score calculated with SBI included and excluded.”
“There is a significant difference in the efficiency score calculated with SBI included and excluded.”
The p-value is almost 0 and is <0.05. Therefore, the authors fail to accept Ho, indicating a statistically significant difference in efficiency values computed with SBI and without SBI being considered in the sample. Spearman’s rank and Kendall Tau correlation tests are also conducted with the following hypotheses to increase the power of a statistical test.
“There is no association between the efficiency values”
“There is a significant association between the efficiency values”
According to Spearman’s rank correlation test, the p-value is almost 0.3671 and >0.05. Also, rho is very negligible, 0.06. Therefore, we fail to reject Ho, indicating no statistically significant association between the efficiency values computed with SBI and those without SBI being considered in the sample. Per the Kendall Tau correlation test, the p-value is almost 0.3165 and >0.05. Also, tau is very negligible, 0.048. Therefore, we fail to reject Ho, indicating no statistically significant association between the efficiency values computed with SBI and those without SBI being considered in the sample. The correlation plot and bar diagram shown in Figure 4 and Figure 5, respectively, also confirm the absence of any association between the efficiency values computed with SBI and those without SBI being considered in the sample.
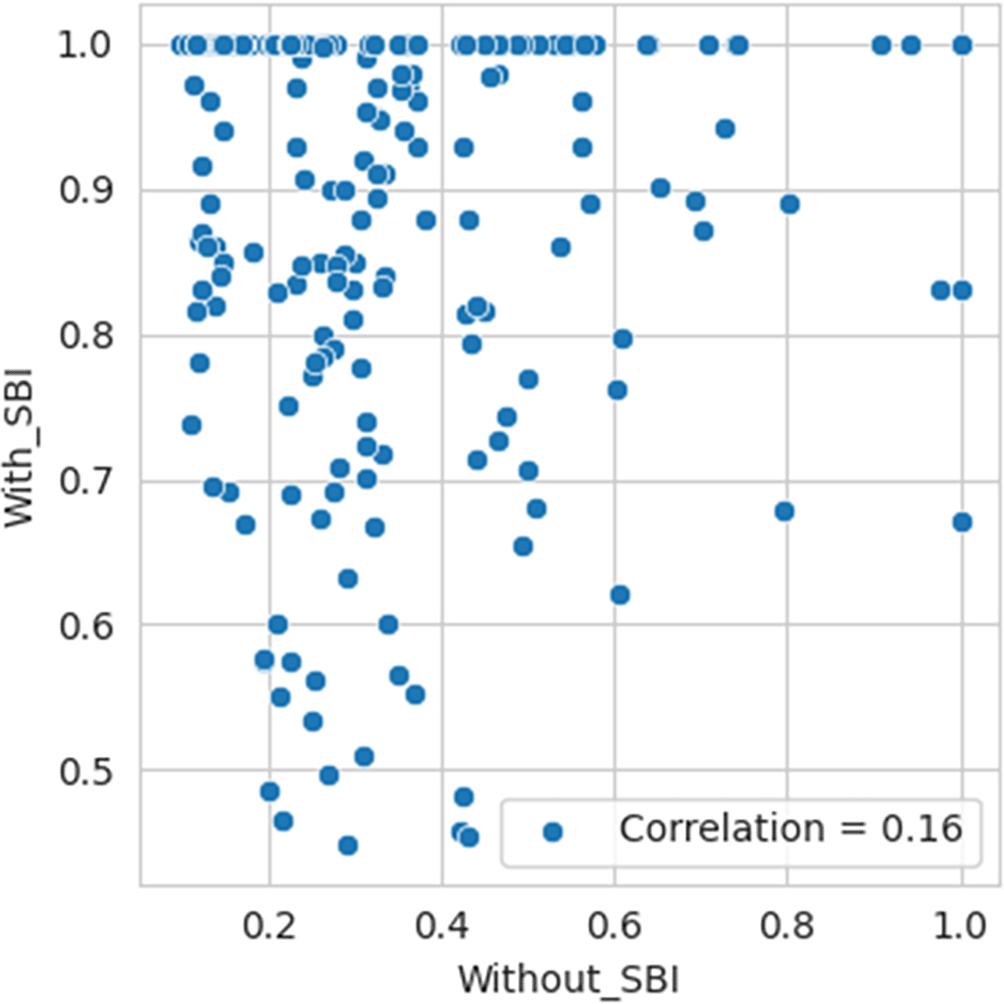

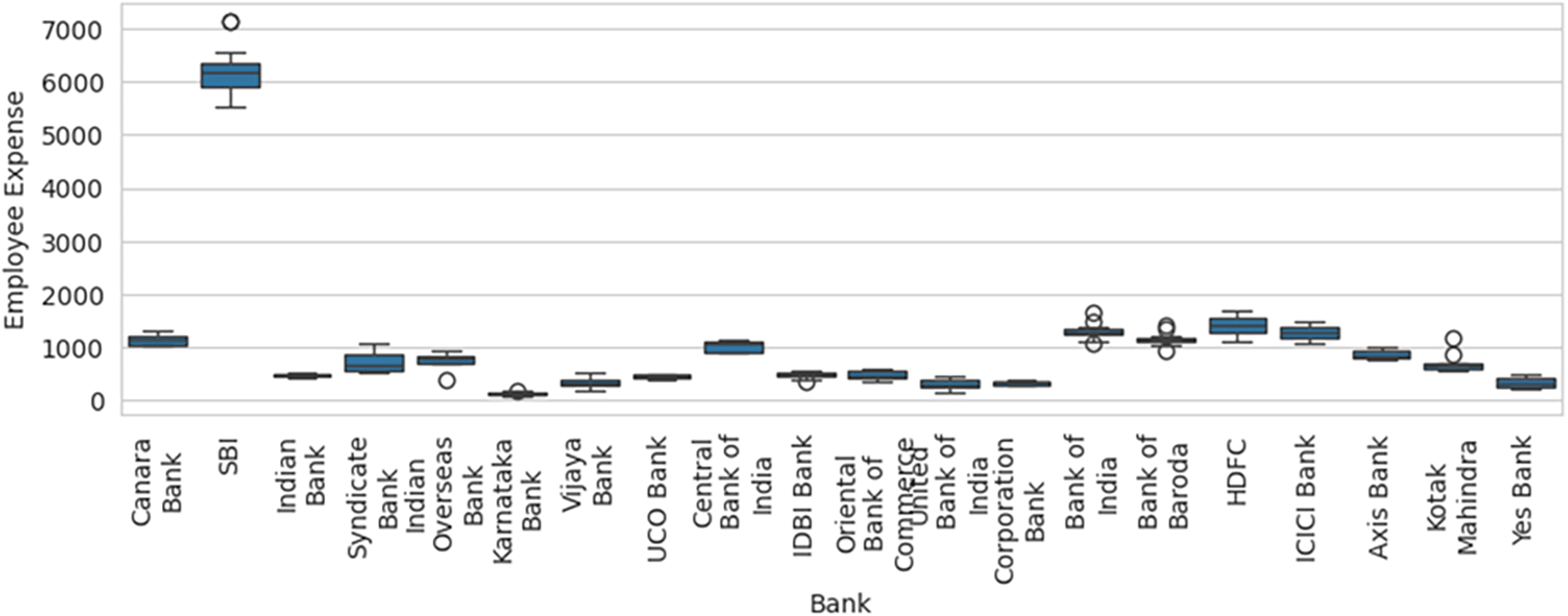
Therefore, inclusion and exclusion of a sample result in significant variation in the efficiency computed, which in statistical terms is sampling error. Blind consideration of sample units for performance efficiency computation will result in misleading results, flawed interpretations, and erroneous decisions. Before calculation of efficiency using DEA methodology, the box-and-whisker plot for one of the variable Employee Expenses with the outlier SBI included, as shown in Figure 6, along with basic descriptive statistical measures, can help to identify the outliers that can result in efficiency computation errors due to sampling. The box-and-whisker with SBI excluded, as shown in Figure 7, shows how the variables are distributed in a range that allows comparison and efficiency evaluation to be more realistic.
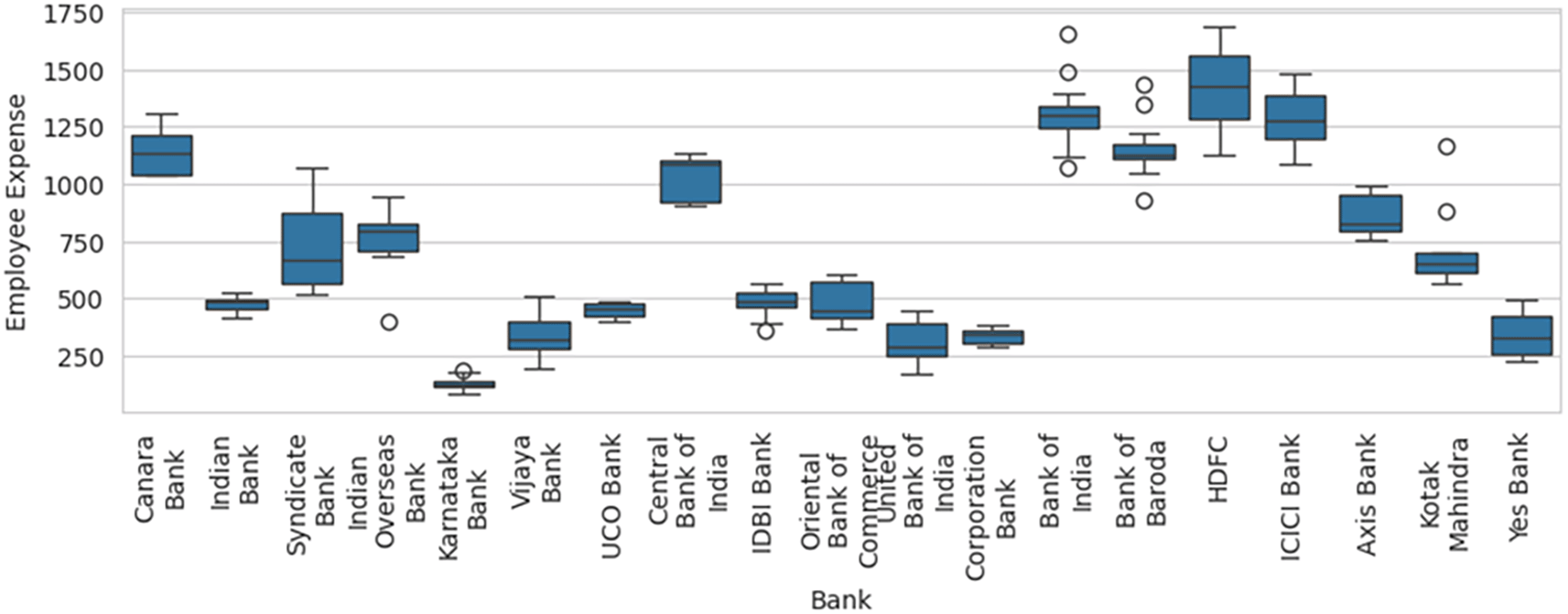
The relative efficiencies were calculated in two groups; one group included SBI as a DMU, and the other excluded SBI. The efficiencies thus calculated were tested for significant change in the average efficiency between the groups. The study provides statistical evidence on the sampling error that can creep into performance evaluation studies' DEA methodology. In practice, inferences were made based on samples, and various preventive measures must be taken to eliminate or avoid sampling error and related misleading results. The study offers a novel contribution along with statistical evidence on the possible sampling error that can creep into the performance evaluation of organizations due to the inclusion or exclusion of specific samples in the relative performance evaluation computation using DEA. The study also discussed how box-and-whisker can help quickly to identify the possible outlier that can cause skewed efficiency scores due to sampling error. The sampling error in DEA can significantly influence efficiency estimates' accuracy, leading to poorly addressed results. Decision makers should be cognizant of potential biases in efficiency results caused by sampling errors; therefore, considering enhanced models is crucial to achieving more accurate measurements and, thus, enabling effective resource allocation. Policymakers must establish measures to ensure more reliable efficiency evaluations, including measurement error corrections in DEA models. Also, supporting research focused on advanced DEA models that account for sampling errors can lead to better-informed policy decisions and enhance operational efficiency across various sectors. The study was limited only to major and selected sample banks. Future studies can consider all types of banks to get a holistic picture of the banking industry performance benchmark and outlier impacts. Future studies can adopt other relevant non-parametric tests and thus increase the statistical power to confirm the findings.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.






Comments on this article Comments (0)