Keywords
K-Means Clustering; data-driven recruitment; workforce selection; cluster visualization; construction competencies
This article is included in the RPackage gateway.
K-Means Clustering; data-driven recruitment; workforce selection; cluster visualization; construction competencies
This revised version addresses the reviewers’ methodological, transparency, and interpretive concerns by strengthening analytical rigor, clarifying the study scope, and situating the findings within current discussions on data-driven recruitment and algorithmic governance.
The manuscript now provides a clear justification of participant selection, explicitly explaining that clustering was conducted on 30 applicants who passed document screening from an initial pool of 161 applicants. The screening criteria are described in detail, and the analysis is framed as an exploratory examination of a pre-screened assessment sample rather than a predictive or comprehensive recruitment optimization model.
Methodological revisions include clearer documentation of data preprocessing, confirmation that all variables were measured on a uniform 0–100 scale, and explicit discussion of centroid initialization and algorithm sensitivity. To address robustness concerns, the clustering analysis was replicated using multiple random initializations in R (nstart), and solution stability was assessed. Internal cluster validity metrics (silhouette coefficient and Davies–Bouldin Index) are now reported as descriptive diagnostics, reinforcing the exploratory nature of the findings. A brief outlier and sensitivity check has also been added, indicating that the cluster structure is not driven by a single extreme observation.
To improve readability, detailed centroid iteration and distance calculation tables have been moved to extended data, while the main text focuses on final clustering outcomes and their interpretation. The Results and Discussion sections have been reorganized to emphasize competency profiles, visual interpretation using 2D, 3D, and hierarchical plots, and cautious analytical insights.
The Introduction and Discussion have been strengthened by incorporating international perspectives on AI-assisted recruitment, transparency, and fairness, including references to the NIST AI Risk Management Framework, U.S. EEOC guidance on adverse impact under Title VII, and the European Union Artificial Intelligence Act. Data availability and ethical statements have been updated, and extended data have been deposited in Zenodo under a new DOI.
See the authors' detailed response to the review by Sonia Najam Shaikh
See the authors' detailed response to the review by Olivia Kembuan and Ferdinan Sangkop
See the authors' detailed response to the review by Deepak Gupta
See the authors' detailed response to the review by Ali Pişirgen
In the modern workplace, workforce selection is a critical component of human resource development, particularly in sectors that require a combination of technical expertise and adaptive capability. Career development and career transformation are influenced not only by formal qualifications but also by individuals’ ability to adapt to changing work environments and collaborate effectively with diverse stakeholders. Data-driven approaches to workforce analysis have therefore gained attention as tools to support more structured and transparent evaluation processes (Pala, 2021).
Recruitment involves more than sourcing candidates; it requires systematic decision-making informed by job analysis, organizational needs, and available labor characteristics (Widodo, 2018). Job analysis plays a central role in defining task requirements, competency expectations, and qualification standards, thereby helping organizations align applicants with role-specific demands. From the applicant’s perspective, successful job search outcomes depend on understanding personal competencies, evaluating labor market opportunities, and developing skills that match employer expectations (London, 1973).
In the construction sector, technical competencies such as AutoCAD drafting, the ability to prepare planning and supervision reports, and adaptability to dynamic project environments are particularly valued (Gangl, 2003). These competencies are increasingly important in large-scale infrastructure development contexts. In Indonesia, national strategic projects such as the Nusantara Capital City (Ibu Kota Nusantara, IKN) development have intensified demand for construction personnel with both technical proficiency and social adaptability (Irmawan et al., 2023; Supriyanti et al., 2023). Managing and interpreting recruitment assessment data in such contexts presents practical challenges, especially when organizations must evaluate multiple competency dimensions simultaneously.
Cluster analysis offers a data-driven approach to explore patterns within applicant assessment data by grouping individuals with similar characteristics. Clustering techniques partition data into internally homogeneous and externally heterogeneous groups, thereby supporting structured interpretation of complex multivariate information (Jain et al., 1999). Among these techniques, K-Means clustering is widely used due to its computational simplicity and interpretability, making it suitable for exploratory analysis of recruitment-related datasets. In recruitment contexts, clustering can be applied to post-screening assessment data to identify competency profiles rather than to make automated hiring decisions.
Beyond operational efficiency, the use of data-driven tools in recruitment raises broader issues of transparency, governance, and fairness in algorithm-assisted selection. International guidance emphasizes that AI-enabled assessment should be accompanied by risk management, documentation, and ongoing monitoring of unintended impacts (NIST, 2023). In addition, U.S. Equal Employment Opportunity Commission (EEOC) guidance highlights that employers should assess whether algorithmic or AI-based selection procedures produce adverse impact under Title VII and aligns such assessment with the Uniform Guidelines on Employee Selection Procedures (EEOC, 2023). Similarly, the European Union Artificial Intelligence Act classifies certain AI systems used in employment-related contexts as high-risk, reinforcing expectations for accountability and safeguards when analytics influence employment decisions (European Union, 2024). Accordingly, this study positions K-Means clustering as an exploratory decision-support technique rather than an automated hiring system; cluster labels are interpreted cautiously as descriptive competency profiles and are intended to complement human review rather than replace managerial judgment.
This study applies K-Means clustering to recruitment test data from a construction consulting firm, focusing on candidates who passed document screening and completed in-person assessments. Using three core variables—AutoCAD drafting skills, planning and supervision report-writing skills, and adaptability—the study demonstrates how unsupervised clustering can support exploratory analysis of applicant competency profiles within a real organizational context.
Clustering is an unsupervised analytical technique used to group objects into clusters based on attribute similarity, such that objects within the same cluster exhibit higher similarity than those in other clusters (Jain et al., 1999). By minimizing within-cluster variation and maximizing between-cluster differences, clustering supports pattern discovery and interpretation in complex datasets (Manikandan et al., 2018; Darmi & Setiawan, 2016). For organizational and workforce analytics, clustering provides a data-driven means of understanding heterogeneity among individuals without requiring predefined class labels.
Among various clustering approaches, K-Means clustering is one of the most widely applied methods due to its simplicity, efficiency, and interpretability. K-Means partitions data into k clusters by iteratively assigning observations to the nearest centroid and updating centroid positions until convergence is achieved (Jain et al., 1999). Because of its relatively low computational cost, K-Means is suitable for applied settings where rapid analysis and transparent interpretation are required (Fadhli, 2017).
Previous studies demonstrate applicability across domains. In educational research, K-Means has been used to analyze student preferences and learning achievement patterns (Firza & Sarjono, 2020). In organizational contexts, it has been applied to group employees based on discipline and performance indicators to support human resource decision-making (Agustina & Prihandoko, 2018). Comparative studies suggest that while alternatives such as Fuzzy C-Means may offer advantages in some conditions, K-Means remains computationally efficient and practical for many real-world applications (Wiharto & Suryani, 2020).
1.2.1 K-Means algorithm
K-Means is a partition-based clustering algorithm that divides data into a predefined number of clusters by minimizing the average distance between data points and their respective cluster centroids (Widiyaningtyas et al., 2017). The algorithm operates iteratively, beginning with the selection of initial centroid values and proceeding through repeated reassignment of data points based on distance calculations until cluster membership stabilizes (Purba et al., 2018). Prior work emphasizes that K-Means can be sensitive to initialization and the scale of input variables, highlighting the need for transparent methodological choices in applied studies (Jain et al., 1999).
1.2.2 Worker recruitment
Recruitment is a strategic organizational process aimed at attracting and selecting individuals whose competencies align with job requirements and organizational objectives. Job analysis plays a critical role in defining tasks, responsibilities, and qualification standards, thereby guiding recruitment and selection decisions (Widodo, 2018). In the construction sector, recruitment emphasizes a combination of technical competencies—such as drafting and report preparation—and adaptive capabilities, reflecting the dynamic and collaborative nature of construction projects (Gangl, 2003). The job search process seeks to match job seekers with appropriate opportunities and can be supported through technology-enabled and data-driven methods (Green et al., 2011). Given the multidimensionality of applicant data, clustering methods such as K-Means offer a way to organize assessment results into interpretable competency profiles that can support early-stage evaluation (Jain et al., 1999).
This study employed a quantitative, exploratory research design using unsupervised clustering to analyze recruitment assessment data from a construction consulting firm. The primary objective was to explore competency-based grouping patterns among job applicants using K-Means clustering as a decision-support tool, rather than to predict hiring outcomes or evaluate post-employment performance.
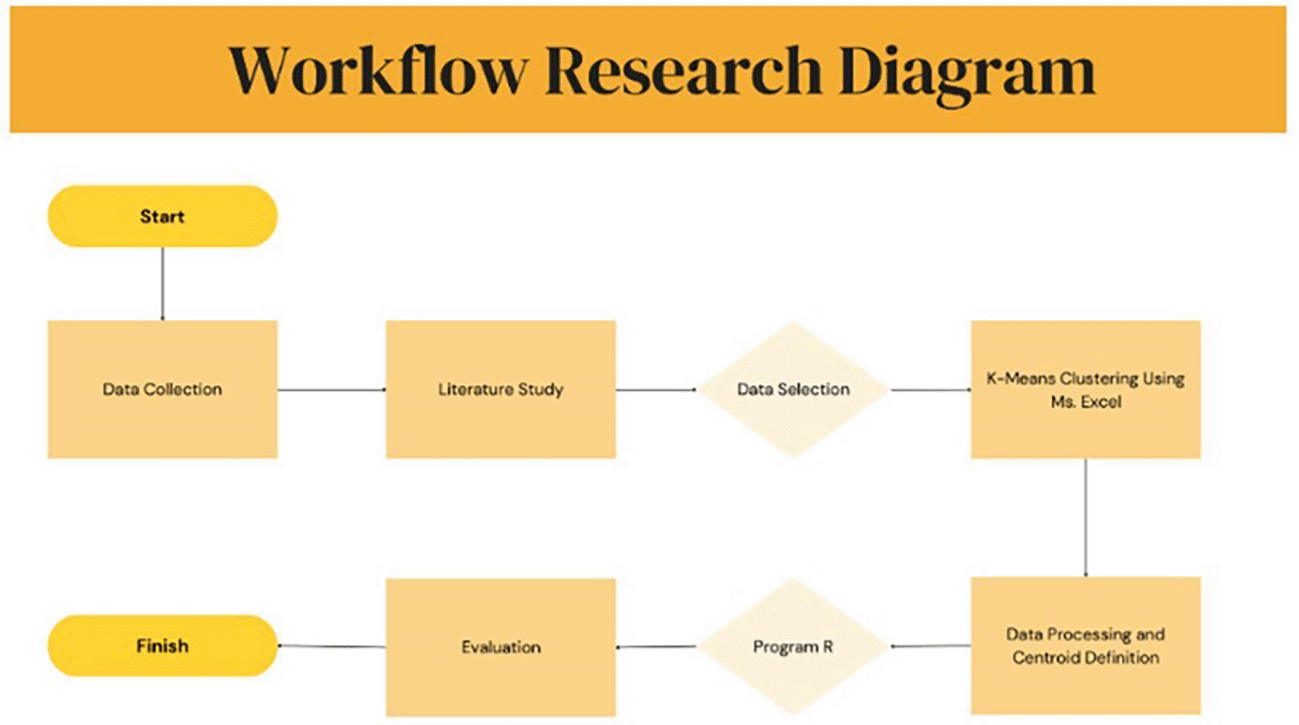
The data were obtained from CV Ardantama Putra Perkasa as part of its internal recruitment process. Although the vacancy was advertised through JobStreet Indonesia, all data analyzed in this study originated exclusively from the company’s internal screening and testing procedures.
A total of 161 applicants applied for the position. Applicants were shortlisted through the company’s standard document-screening procedure conducted by the HR team and the hiring unit. Screening focused on administrative completeness and role relevance, including:
(i) completeness of required documents;
(ii) educational background and relevance to construction consulting work;
(iii) evidence of relevant technical exposure (e.g., drafting/reporting-related tasks or portfolio where available); and
(iv) basic eligibility criteria specified in the vacancy announcement.
From this screening stage, 30 candidates who met the minimum requirements were invited for in-person testing. Only these 30 candidates were included in the clustering analysis because complete assessment scores were available for all three variables. This design improves internal consistency of the tested dataset but limits generalizability to the full applicant pool.
Candidates were evaluated using three competency indicators relevant to construction consulting roles:
Each variable was assessed on a numerical scale from 0 to 100, with higher scores indicating stronger performance.
The dataset was reviewed for completeness and consistency. All 30 candidates had complete scores across the three assessment variables; therefore, no records were excluded at this stage. Because all variables were measured using the same scale (0–100), the analysis used raw scores without additional normalization to preserve the meaning of the original assessment scores.
A basic outlier and sensitivity check was conducted by examining distances to cluster centroids and visually inspecting the 3D scatter plot. A leave-one-out sensitivity test removing the most distant observation did not materially change the overall three-cluster interpretation; validity metrics changed only slightly (mean silhouette increased from 0.16 to approximately 0.18; DBI remained approximately 2.0). This suggests the reported structure is not driven by a single extreme case.
K-Means clustering was applied to group candidates based on similarity across the three assessment variables. The number of clusters was set to k = 3, reflecting the company’s practical need to differentiate candidates into three evaluative groups for recruitment support.
Initial centroid values were specified as starting points based on preliminary inspection of score distributions during exploratory analysis. These initial values were used to initiate iteration rather than to impose predetermined outcome categories. Euclidean distance was used to assign candidates to the nearest centroid, after which centroid positions were updated as the mean of cluster members. The algorithm iterated until cluster assignments stabilized.
The clustering workflow was implemented using a combination of spreadsheet-based calculations (for transparency of manual steps) and the R programming language (for reproducibility, validity checks, and visualization). Intermediate iteration tables are provided as extended data.
2.5.1 Initialization and stability checks
Because K-Means can be sensitive to initialization, the analysis was repeated in R using the built-in kmeans() function with multiple random initializations (e.g., nstart = 50). Solution stability was assessed by comparing convergence outcomes (within-cluster sum of squares) and checking consistency of cluster memberships across repeated initializations. This step ensured that the reported three-cluster structure was not an artifact of a single starting configuration. Minor membership differences across runs occurred for borderline profiles, which is plausible in small samples with overlapping competency distributions.
Clustering results were visualized using two-dimensional and three-dimensional scatter plots. Two-dimensional plots illustrated relationships between AutoCAD drafting skills and planning/supervision report-writing skills, while three-dimensional plots incorporated adaptability as a third axis.
Clusters were subsequently labeled as “Rejected,” “Under Consideration,” and “Accepted” based on their relative position in the multivariate competency space. These labels represent analytical interpretations of score patterns and do not constitute formal hiring decisions made by the company.
This study focuses on exploratory grouping of recruitment assessment data from a pre-screened subset of applicants. The clustering results were not validated against final hiring decisions or post-employment performance outcomes. Accordingly, findings should be interpreted as structured analytical support rather than definitive evidence of selection effectiveness.
To provide quantitative support for the cluster structure, internal validity indices were calculated. The silhouette coefficient was computed using Euclidean distances to estimate how well each candidate matched its assigned cluster relative to other clusters. The Davies–Bouldin Index (DBI) was calculated to evaluate average cluster similarity based on within-cluster dispersion relative to between-cluster centroid distances. These indices were interpreted as descriptive diagnostics of separation quality rather than evidence of predictive utility.
This study analysed recruitment assessment records from CV Ardantama Putra Perkasa, obtained from the company’s internal testing and selection process. A total of 161 applicants submitted applications, of whom 30 candidates meeting minimum screening criteria were invited for in-person testing. Each candidate was assessed on three indicators measured on a 0–100 scale: AutoCAD drafting skills (X), planning and supervision report-writing skills (Y), and adaptability (Z). Candidate characteristics and scores are summarised in Table 1.
Overall, the score distribution shows meaningful heterogeneity across candidates—particularly in adaptability and planning/supervision report-writing—indicating variation in both technical and interpersonal readiness. This variability provides a suitable basis for exploratory clustering analysis.
Using K-Means clustering with k = 3, the 30 assessed candidates were grouped into three distinct clusters based on similarity across AutoCAD drafting skills, planning and supervision report-writing skills, and adaptability. The final cluster assignments are summarized in Table 2. These clusters represent analytical competency profiles derived from multivariate similarity patterns rather than formal hiring decisions determined by company policy.
The first cluster is characterized by relatively lower combined scores across the three assessed competencies. The second cluster consists of candidates with moderate and mixed competency scores, reflecting intermediate profiles that may warrant further evaluation. The third cluster comprises candidates with consistently higher scores across technical and adaptive dimensions, indicating stronger and more balanced competency profiles.
The clustering process involved iterative centroid updates until cluster memberships stabilized. To maintain readability, detailed iteration tables are provided as extended data, while the main text focuses on the stabilized results and their interpretation. Re-running clustering with multiple random initializations in R produced highly similar solutions, suggesting the three-cluster structure was not dependent on a single manual initialization. Minor membership differences across runs occurred for borderline profiles, which is expected in small samples with partially overlapping competency distributions.
The final clustering output generated from the R environment, including cluster labels and competency scores for each applicant, is presented in Table 3.
3.2.1 Cluster validity metrics
Internal validation indicated modest cluster separation. The mean silhouette coefficient was 0.16, suggesting partial overlap among competency profiles, which is plausible given the small pre-screened sample. The Davies–Bouldin Index was 2.05, indicating moderate distinctiveness among the three clusters. These values support interpreting the clusters as exploratory competency groupings rather than sharply separated classes.
To support interpretation, two-dimensional and three-dimensional visualizations were generated. Figure 2 presents a 2D scatter plot based on AutoCAD drafting skills and planning/supervision report-writing skills, showing visible separation between lower, intermediate, and higher competency profiles along key technical dimensions.
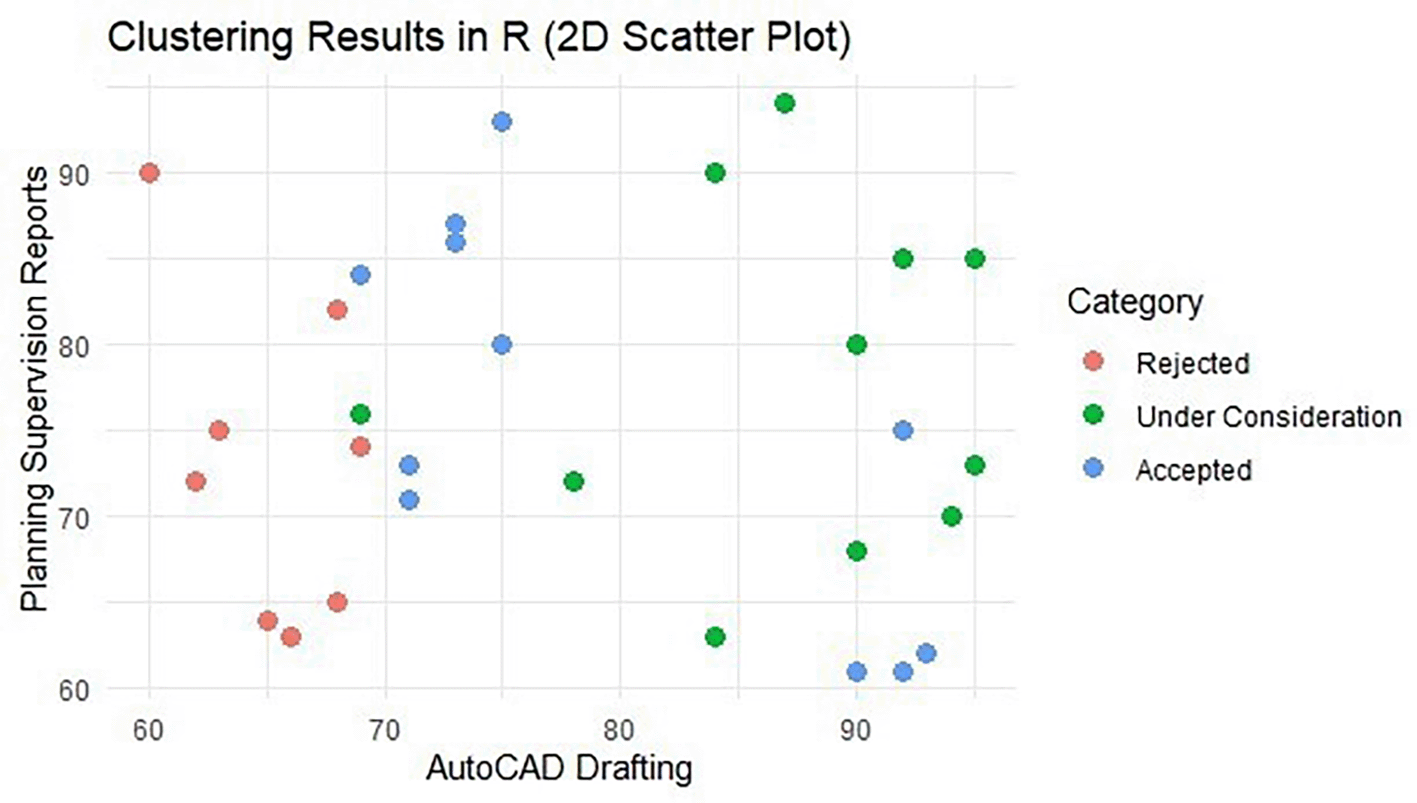
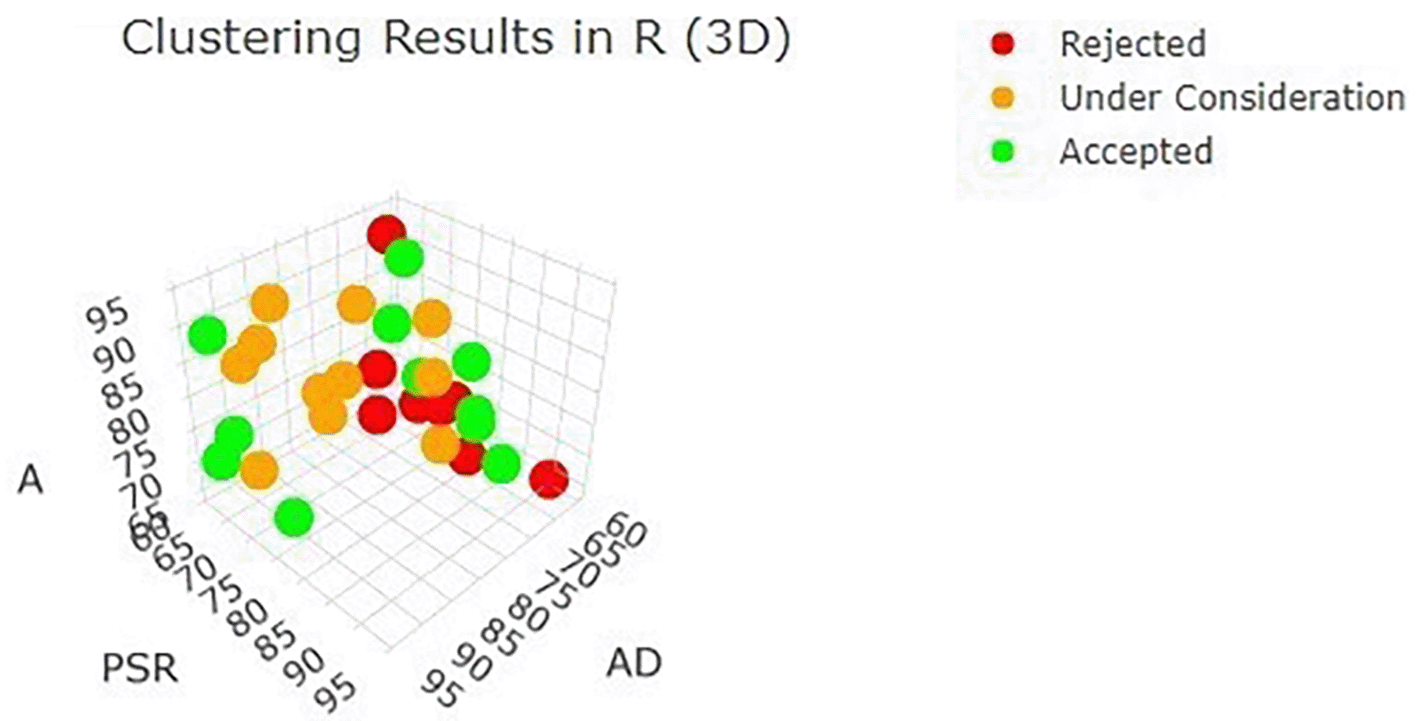
Figure 3 extends the visualization into three dimensions by incorporating adaptability as a third axis. The 3D scatter plot reveals clearer spatial separation among clusters, particularly distinguishing candidates who combine strong technical skills with high adaptability from those with lower overall competency scores.
For clarity of interpretation, the clustered dataset sorted by category is provided in Table 4.
To further examine structural consistency, hierarchical clustering projected onto principal component space is presented in Figure 4. Although hierarchical clustering was not employed as the primary analytical method, the observed grouping patterns broadly align with the K-Means classification, providing additional support for the stability of the three-cluster structure within this dataset.
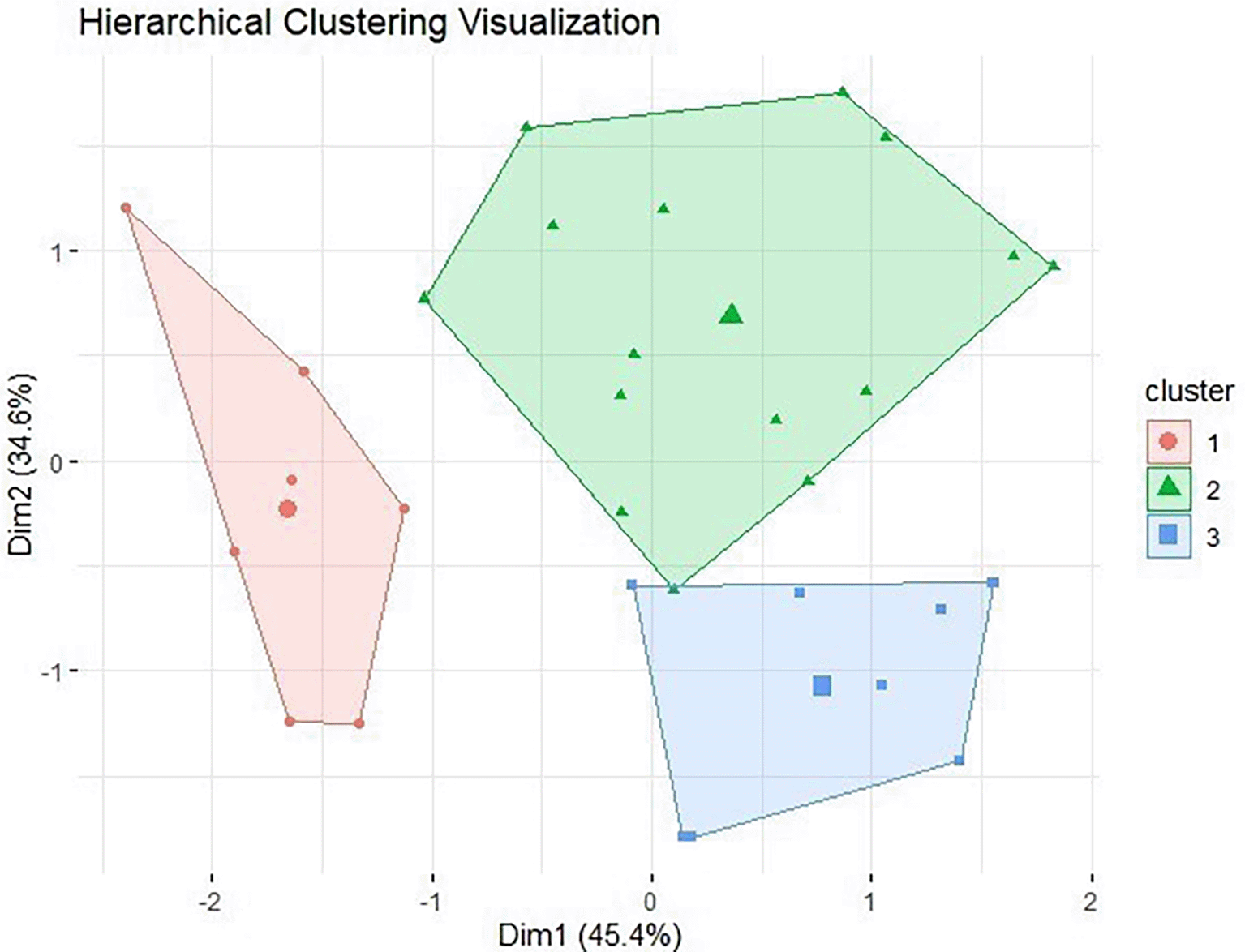
The clustering results demonstrate that K-Means can be used as an exploratory tool to organize recruitment assessment data into interpretable competency profiles within a construction consulting context. Candidates grouped in the higher-scoring cluster tend to exhibit stronger performance across both technical and adaptive dimensions, consistent with prior research emphasizing the importance of combining technical competence with adaptability in project-based and construction-related work environments (Gangl, 2003; Brown & Hesketh, 2005).
The intermediate cluster represents candidates with mixed strengths, suggesting development potential rather than clear acceptance or rejection outcomes. This aligns with literature highlighting the role of structured training and targeted skill development in enhancing workforce readiness and career progression (Rawat et al., 2024). Rather than constituting definitive recruitment decisions, this cluster highlights individuals who may benefit from managerial attention, follow-up assessment, or additional training.
Importantly, the clustering approach does not replace professional judgment in recruitment. Instead, it provides a structured analytical perspective that can support transparency and consistency in early-stage evaluation. This aligns with contemporary views that HR analytics is most effective when it complements human expertise rather than automates decision-making processes (Akkermans et al., 2024).
From an ethical and governance perspective, the analysis is intended to structure early-stage assessment information rather than to automate acceptance decisions. Guidance on trustworthy AI and employment decision tools emphasizes the need for documentation, monitoring, and attention to bias risks when analytics are used in consequential settings (NIST, 2023; EEOC, 2023). Accordingly, the cluster labels in this study are treated as descriptive competency profiles and should be used alongside human review, transparent documentation, and periodic evaluation of potential disparate impact.
Several limitations should be considered when interpreting these findings. First, the analysis was conducted on a pre-screened subset of candidates who passed document screening and participated in in-person testing; therefore, results may not generalize to the full applicant pool. Second, internal validity indices indicated modest separation, suggesting partially overlapping competency profiles that are plausible in a small filtered sample. Third, the clusters were not externally validated against final hiring decisions, expert HR evaluation, or subsequent job performance outcomes.
Despite these limitations, the results illustrate how clustering can function as a practical decision-support tool in recruitment contexts involving multidimensional competency assessments. Future research could extend this approach by applying clustering to larger and more diverse applicant pools, incorporating additional competency indicators, comparing alternative clustering methods, and validating cluster profiles against post-hire performance indicators.
This study explored the use of K-Means clustering as an exploratory analytical approach for organizing recruitment assessment data in a construction consulting context, based on three competencies: AutoCAD drafting skills, planning and supervision report-writing skills, and adaptability. Using data from a pre-screened group of applicants, the analysis identified three distinct competency profiles reflecting different patterns of technical and adaptive capabilities.
The identified clusters indicate that applicants with stronger and more balanced combinations of technical competence and adaptability tend to form a distinct group, while candidates with mixed or lower competency profiles are grouped separately. These results should be interpreted as analytical groupings based on similarity patterns rather than as definitive hiring decisions or evidence of predictive effectiveness. This interpretation is consistent with conceptual discussions emphasizing the importance of adaptability and skill alignment in contemporary labor markets (Gangl, 2003; Brown & Hesketh, 2005).
Quantitative diagnostics suggested modest separation (mean silhouette = 0.16; DBI = 2.05), supporting cautious interpretation of the clusters as exploratory profiles in a small screened sample. The use of two-dimensional and three-dimensional visualizations enhanced interpretability by illustrating how multivariate competency combinations differentiate applicant profiles. The observed alignment between K-Means results and supporting hierarchical visualization further suggests structural consistency within the analyzed dataset, although external validation against hiring outcomes or job performance was beyond the scope of this study.
From a practical standpoint, the findings suggest that clustering-based analysis may support early-stage recruitment evaluation by helping organizations structure and interpret multidimensional assessment data in a transparent and systematic manner. More broadly, clustering as a decision-support mechanism can be situated within wider discussions on data-driven analysis as a means of structuring managerial judgment rather than replacing it (Diván, 2017). When used alongside professional expertise, such approaches align with contemporary perspectives on human resource analytics that emphasize analytical support over automated decision-making (Akkermans et al., 2024).
In addition, the presence of an intermediate competency cluster highlights applicants who may benefit from further evaluation or targeted skill development initiatives, echoing research on structured training and career development (Rawat et al., 2024; Donald et al., 2024). While career sustainability and job insecurity were not directly examined, the inclusion of adaptability as a clustering dimension resonates with broader discussions on adaptive capacity in uncertain career contexts (Van der Heijden et al., 2024).
Overall, this study provides a practical illustration of how unsupervised clustering techniques can be applied to recruitment assessment data in the construction sector. By emphasizing transparency, interpretability, and cautious use of analytics within governance and fairness considerations (NIST, 2023; EEOC, 2023), the study contributes to ongoing discussions on data-driven decision-support tools for workforce selection and development.
Ethical review and approval were not required for this study because the researchers analyzed fully anonymized secondary data that had been lawfully transferred by CV Ardantama Putra Perkasa under a formal Data Usage Agreement (No. 12/X/S-K/APP/2024). According to Indonesian national research ethics regulations (Permenkes RI No. 74/2016, Article 11) and the general principles of the Declaration of Helsinki, research involving secondary anonymized non-clinical data that cannot identify individuals is exempt from institutional ethical review. Therefore, this study qualifies for an ethics exemption.
Informed consent for data use was not obtained directly by the researchers, as all data were collected by CV Ardantama Putra Perkasa under standard recruitment procedures. The company confirmed, through the Data Usage Agreement (No. 12/X/S-K/APP/2024), that job applicants had authorized the use of their anonymized recruitment test results for evaluation and administrative purposes in accordance with Indonesian data protection regulations (UU ITE and PP 71/2019). Because the researchers received only anonymized secondary data and had no access to identifiable information, this study meets the criteria for consent exemption.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)