Keywords
Native DNA/RNA sequencing, Data augmentation, White noise, Long-read sequencing, Adaptive sampling, Metagenomics, Diagnostics
This article is included in the Nanopore Analysis gateway.
This article is included in the Genomics and Genetics gateway.
Native DNA/RNA sequencing, Data augmentation, White noise, Long-read sequencing, Adaptive sampling, Metagenomics, Diagnostics
Long-read sequencing is revolutionizing DNA/RNA sequencing by simplifying the workflow of genomic research with the advantages of long reads.1 This novel technology has contributed to numerous unsolved problems in the field of genomics, including the completion of the human genome through the Telomere-to-Telomere Consortium (T2T)2 and the Human Pangenome Reference Consortium (HPRC).3–5 Among the long-read sequencing technologies, nanopore sequencing has several unique advantages by utilizing the biophysical properties of nanopores and nucleic acids.6,7 This technology measures changes in ionic current flows across a protein nanopore as a string of nucleic acids passes through to reconstruct the genetic sequence from the electric signals.8 This signal conversion process further employs advanced computational methods such as neural networks and parallel computing, leveraging recent technological advancements spanning various fields.9,10 Notable advantages of nanopore sequencing over other sequencing methods include the ability to sequence native DNA/RNA and the ability to sequence selectively through depletion or enrichment. Direct sequencing of native DNA/RNA generates additional information on the sequences. This epigenetic information, such as the detection of DNA and RNA methylation, plays a key role in understanding many diseases, including cancer.11,12 Furthermore, nanopore sequencing has an important feature of adaptive sampling, which selectively depletes or enriches sequences of interest.13 This is achieved by dynamically controlling the voltage across individual nanopores to eject unwanted sequences or allow targeted sequences to continue through the pore, based on rapid basecalling and alignment to reference genomes. Adaptive sampling leverages advanced neural networks and parallel computing to perform real-time analysis and decision-making, allowing researchers to focus sequencing resources on regions or organisms of interest.9
Despite these advantages, nanopore sequencing also requires a high input quantity of DNA/RNA to fully leverage these features of direct sequencing and adaptive sampling. For instance, most protocols recommend an input DNA/RNA quantity of at least 500 ng and 1,000 ng for Flongle flow cells and MinION flow cells, respectively. This high input quantity of DNA/RNA is necessary for the adapter efficiency in the ligation preparation, as well as the long-read sequencing of DNA/RNA.14 This requirement is a limiting factor in utilizing nanopore sequencing in genomic studies involving biological samples with small quantities of DNA/RNA. In scenarios involving small DNA/RNA quantities within samples, an extra PCR step is often employed to amplify these scarce sequences, undermining the capacity of nanopores to capture epigenetic information. Moreover, it necessitates the quantification of DNA/RNA during each sequencing experiment, typically with a stringent quantity threshold. These experimental criteria often lead to the abandonment of direct sequencing or long-read sequencing in numerous studies.15
Here, we introduce a novel method called Noise-Augmented Direct (NAD) sequencing, which augments a sample of a small DNA quantity (<500 ng) with the ‘noise’ DNA to selectively sequence only the target sequence using adaptive sampling ( Figure 1). The noise or background DNA, such as human DNA during sequencing experiments, is commonly considered an undesirable form of contamination that needs to be identified and eliminated.16,17 However, the concept of adding noise to increase the generalization performance with real-world data is widely utilized in other fields. For instance, data augmentation with white noise is known to improve the accuracy of deep-learning models in real-world testing.18 Deep learning has been widely used for various artificial intelligence (AI) tasks such as speech and image recognition and natural language processing.19 However, the generalization performance of deep learning reduces drastically when tested in noisy real-world data.20 One of the strategies to circumvent this pitfall is to train the neural networks using data augmented with some random noise to increase the robustness and generalization power.21
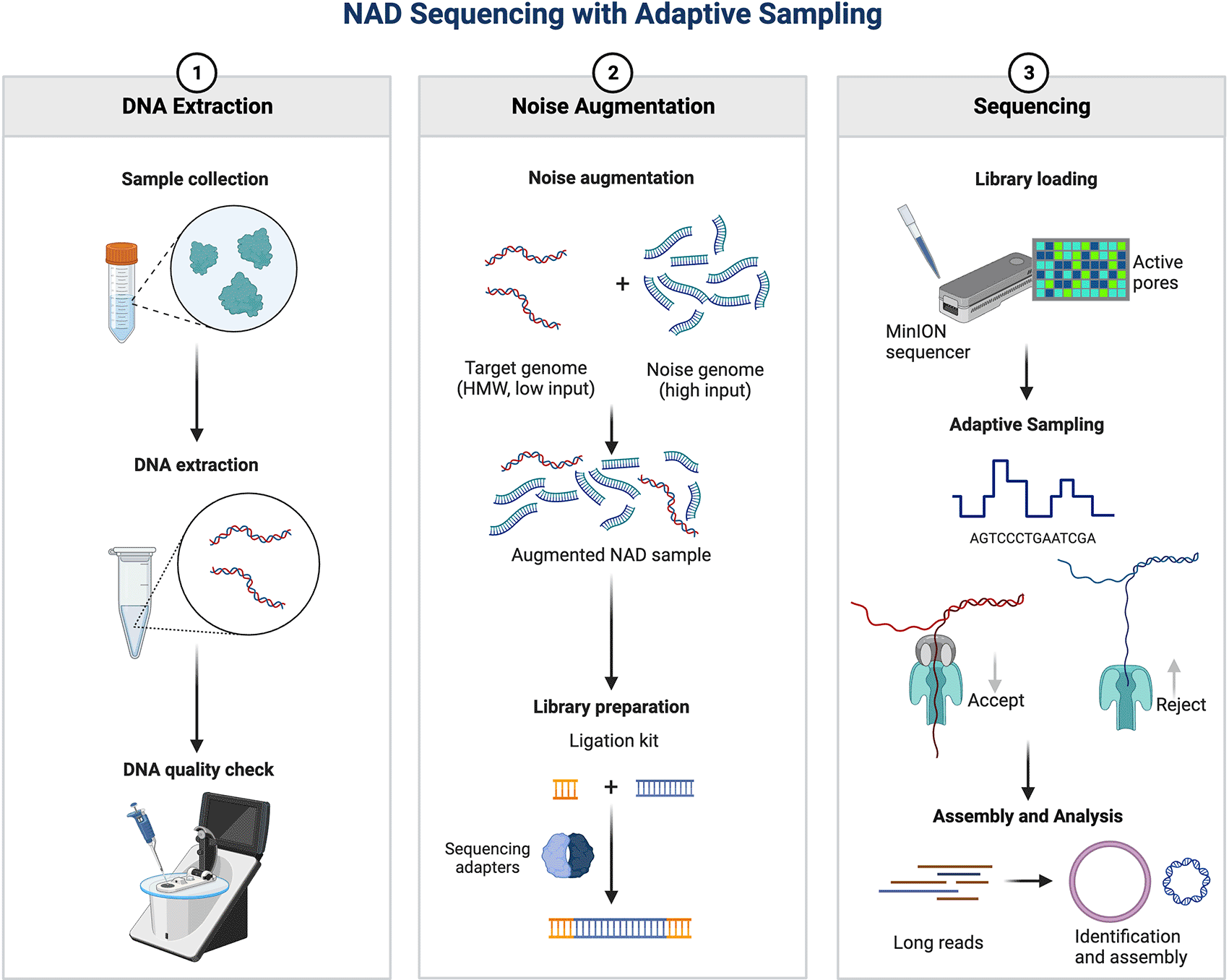
The target DNA/RNA is extracted from a sample of interest (e.g. human nasal swab) and augmented with the noise DNA/RNA. The sequencing library of the target and noise DNA/RNA is directly sequenced in real-time using adaptive sampling by depleting the noise DNA/RNA. This allows direct sequencing of the target DNA/RNA in a native form, without the need to amplify the target DNA/RNA that is below the minimum quantity and concentration of long-read sequencing requirements.
In this study, we adopt a similar line of reasoning to increase the generalization performance of nanopore sequencing in real-world datasets by adding a controlled amount of ‘noise’ DNA to a biological sample and exploiting the ability of adaptive sampling to enrich the target DNA by selectively depleting the noise DNA. In the context of sequencing experiments, the noise DNA is a preselected sequence that is randomly sequenced by nanopores. It should be a sequence long enough (a minimum of 450 base pairs) to allow adaptive sampling to make a decision, but not so long that it significantly increases mapping time. Here, we use the lambda phage genome as the noise DNA and two bacterial genomes (Pseudomonas aeruginosa and Salmonella enterica) as the target DNA. We demonstrate that NAD sequencing can detect the target DNA with an input quantity as low as 1 ng in cost-effective Flongle flow cells. Furthermore, NAD sequencing can efficiently assemble parts of the bacterial genome, with a target DNA quantity as low as 3 ng (30% complete with an accuracy of 97.58%) in cost-effective Flongle flow cells, and a target DNA quantity of 300 ng (99.9% complete with an accuracy of 99.97%) in high-throughput MinION flow cells. This result demonstrates the potential of NAD sequencing as a practical method for detecting and assembling target DNA of limited quantity. This proof-of-concept study underscores the effectiveness of injecting noise DNA to augment target DNA to expand the applicability of long-read sequencing to real-world settings where biological samples often contain limited nucleic acids. We further discuss the necessity of enhancing the integration of computational processing power to handle the vast datasets generated by NAD sequencing, particularly when incorporating adaptive sampling in real time.
Microbial DNA standards serve as a benchmark to evaluate the performance along the workflow of genomics analyses and as a tool to increase reproducibility. Before noise augmentation, the quality and quantity of the DNA standards were checked using a DNA Spectrophotometer (DS-11 Series from DeNovix). The results show that the DNA standard of the noise genome (Lambda phage) was as stated by the manufacturers at the concentration of ~600 ng/μL, meeting the quality criteria of A260/280 and A260/230 at ~1.8 and ~2.0, respectively (Extended Data: Figure S1 and Table S1). However, the target DNA samples were below the minimum concentration range of the DNA Spectrophotometer. For example, the target DNA sample of P. aeruginosa was measured to be 15.322 ng/μL before augmenting with the noise DNA (Extended Data: Table S1), which was close to the concentration stated by the manufacturers of 10 ng/μL. Due to the minimum concentration threshold, the quality control values of 260/280 and 260/230 were not relevant for these initial target DNA samples.
The target DNA samples that were below the minimum concentration were augmented with the noise DNA to meet the input DNA criteria for nanopore sequencing (Extended Data: Tables S2 and S3). The augmented DNA samples of Pseudomonas aeruginosa and Salmonella enterica were ligated and sequenced in MinION flow cells and Flongle flow cells (Oxford Nanopore Technologies), respectively.
The noise-augmented sample of P. aeruginosa had two technical replicates, where the first replicate was only run for 13 hours due to an error in flow cells ( Table 1). The second replicate was run for 96 hours to completely exploit the capacity of the MinION flow cell. However, the quality score of real-time basecalling declined significantly after ~72 hours despite replenishing with the flush buffer, which is a typical runtime of MinION flow cells (data not shown). The second replicate has a better experimental output with twice more bases sequenced (4.79 Gb) as compared to the first replicate (2.14 Gb). This data output was below the theoretical output of MinION flow cells at 50 Gb, but achieving 10% of the theoretical capacity was typical data sizes generated with nanopore sequencing in the previous experiments.15 The second replicate also has a better N50 estimate (40,320 b) which was around 5 times longer than that of the first replicate (Extended Data: Figure S2). The estimated N50 from the reads shows a satisfactory performance of high-molecular-weight DNA sequencing.
The noise-augmented sample of S. enterica had three experimental runs with a range of target DNA concentrations (1 ng, 3 ng, and 5 ng). All the experiments were run for 72 hours to completely exploit the capacity of the Flongle flow cells. However, the quality score of real-time basecalling declined significantly after ~24 hours, which is a typical runtime of Flongle flow cells (data not shown). All the runs generated around 5% to 10% of the theoretical capacity of Flongle flow cells at 2.8 Gb ( Table 1). The N50 estimates of all the sequencing runs showed much lower read lengths than expected of high-molecular-weight DNAs (Extended Data: Figure S2). The sequencing run with the largest amount of target DNA at 5 ng shows the largest estimated N50 at 11,440 b. The estimated N50 correlates with the concentration of the target DNA, indicating that the low estimated N50 may arise as an artifact of sequencing the noise DNA of the Lambda phage genome.
In NAD sequencing of the noise-augmented samples, the adaptive sampling feature of nanopore sequencers was used to enrich the target DNA by depleting the noise DNA. The read length graphs from the nanopore report show there are two peaks in all the NAD sequencing experiments (Extended Data: Figure S2). The first peaks are at the read length of 500 b, while the second peaks are at the read length of ~45 kb. The bimodal distribution of these read length graphs indicates successful adaptive sampling in these experiments, with the first peak representing the noise DNA that was rejected within a few seconds after being sequenced with a nanopore. The second peak likely represents the noise DNA of Lambda phage genomes with the length of 48,502 base pairs. The accepted reads of each experiment that were classified as the target DNA had lengths greater than 4,000 b in both the Pseudomonas and Salmonella samples (Extended Data: Figure S3). Furthermore, the N50 values calculated for these accepted reads classified as the target DNA were over 17 kb for the Salmonella samples (Extended Data: Figure S3A), and over 29 kb for the Pseudomonas sample (Extended Data: Figure S3B).
During adaptive sampling, each read passing the nanopore was mapped against the reference genome of the Lambda phage while sequencing (Extended Data: Table S4). There are three types of decisions in adaptive sampling of nanopore sequencing: “no_decision,” “stop_receiving,” and “unblock.” A “stop_receiving” is a decision made when the read is accepted and fully sequenced, based on the real-time basecalling and mapping. On the other hand, “no_decision” occurs when the read continues through the nanopore with no decision to either accept or reject the read and becomes fully sequenced. An “unblock” is a decision made when the read is stopped and rejected by reversing of the voltage, based on the real-time basecalling and mapping.
To evaluate the decision-making process of adaptive sampling, the proportion of these three types of decisions was plotted for each NAD sample, in nominal value ( Figure 2A) and relative value ( Figure 2B). For all the samples, a majority of the reads were “unblocked” while being sequenced, indicating that more than 50% of reads were rejected as adaptive sampling is set to deplete the noise DNA. For the Salmonella samples, there is a decreasing trend of unblocked reads as the concentration of the target DNA increases. This trend indicates that adaptive sampling was functioning as expected, as the nanopores rejected a fewer number of reads when there were fewer noise DNAs present in the sample. Conversely, the proportion of acceptance (“stop_receiving”) in sequencing increases as the concentration of the target DNA increases in the Salmonella samples. For NAD sequencing, it is notable that the proportion of unblocked reads is much larger than the proportion of accepted reads, as adaptive sampling is set to deplete rather than enrich.
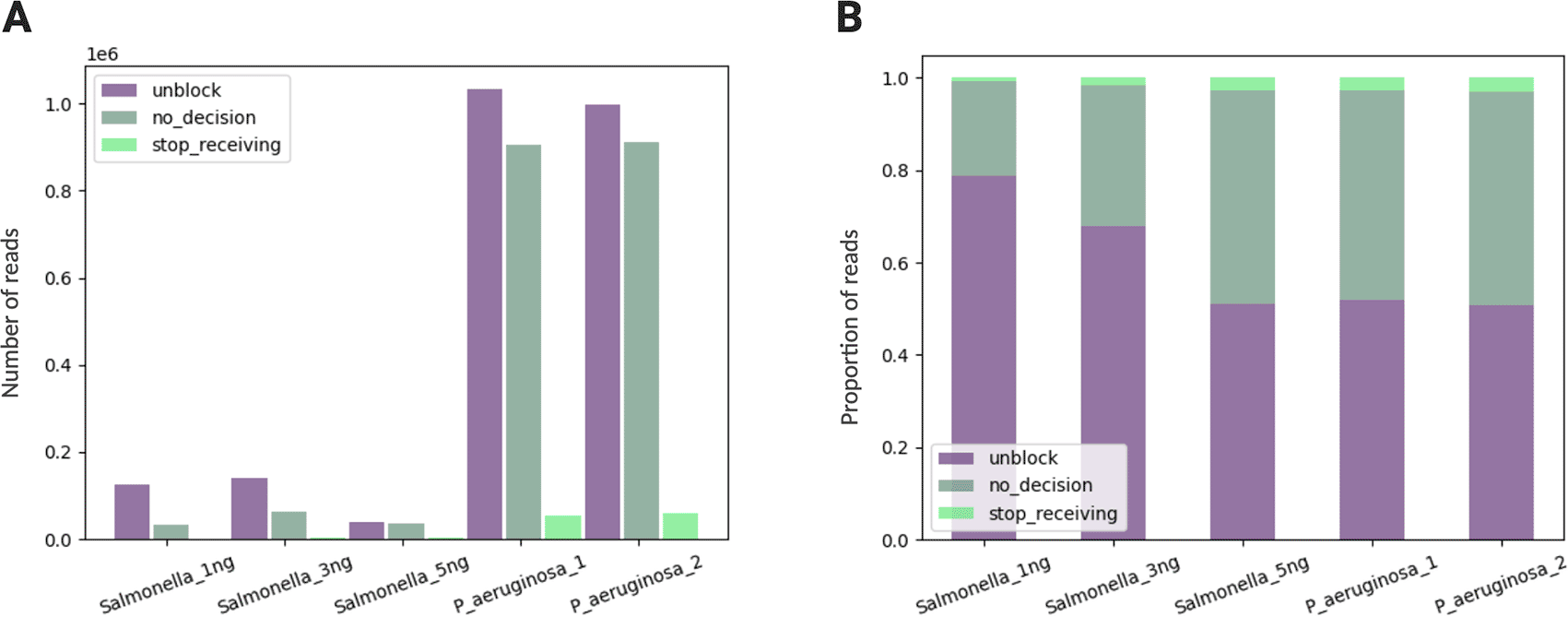
(A) Comparison in nominal value; (B) Comparison in relative value.
“no_decision” when the read has been continued without decision; “stop_receiving” when the read was accepted and fully sequenced (read acceptance occurs at ~4000 bp for depletion protocols); “unblock” when the read was stopped and rejected by the nanopore (read rejection occurs at ~400 bp).
To evaluate the performance of NAD sequencing, the sequence length of the reads was compared by the sample type ( Figure 3A) and by the classification type ( Figure 3B). In all the samples, the average sequence length of the reads that were unblocked and rejected was much shorter at 500 b than those of the other reads ( Figure 3A). The nanopore sequencer was preset to deplete the noise DNA by rejecting the Lambda phage genome of ~48 kb using adaptive sampling. As it takes around 1 second for nanopores to decide on whether to accept or reject a read using the real-time basecalling and mapping process of adaptive sampling, this result verifies the implementation of adaptive sampling given the translocation speed of 450 bases per second.22 Furthermore, the average sequence length of the reads that were accepted and fully sequenced (“stop_receiving”) was much higher at 4,000 b than that of the reads that were continued (“no_decision”) at 1,000 b.
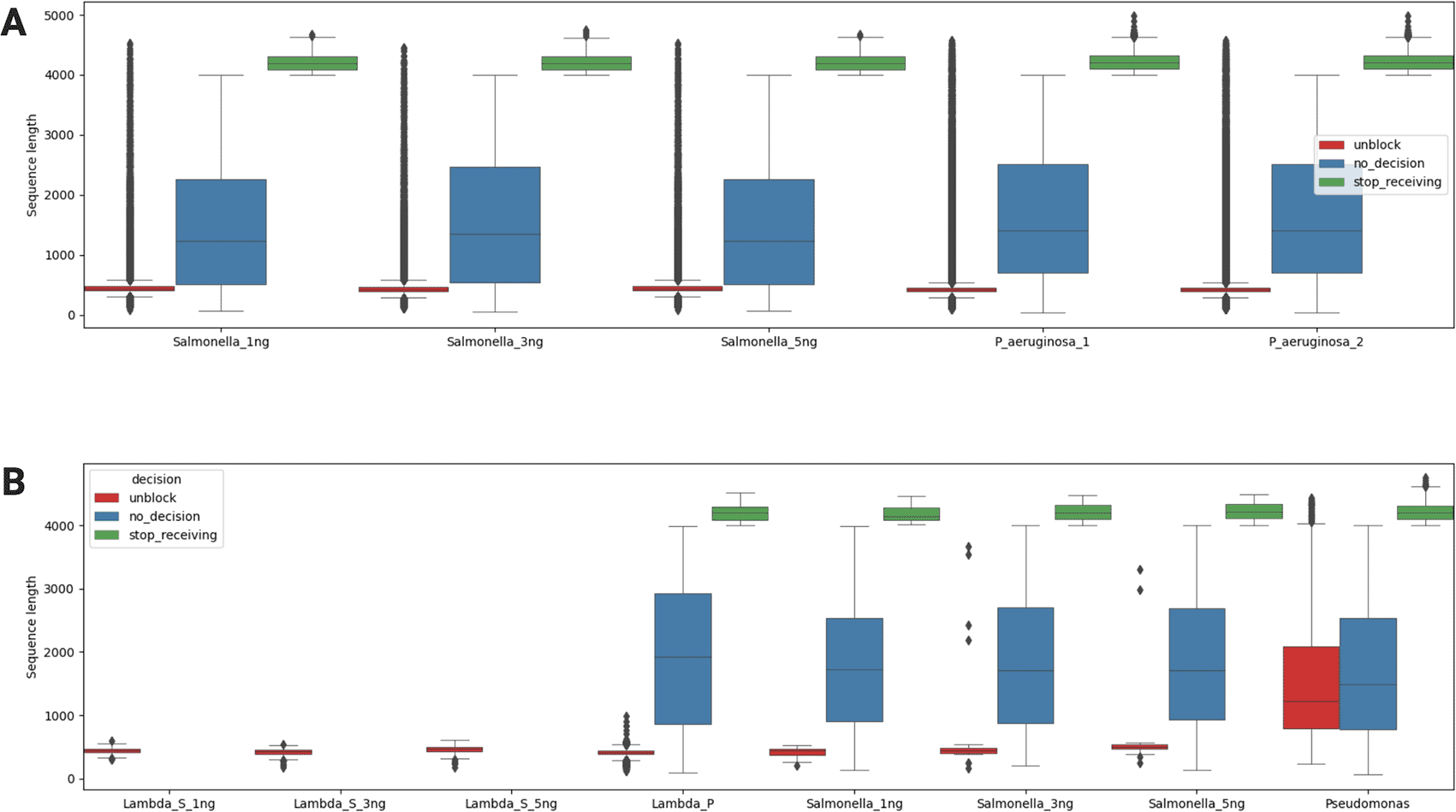
(A) Comparison by the sample for all reads; (B) Comparison by the noise DNA (Lambda phage) versus the target DNA (S. enterica or P. aeruginosa).
Lambda_S indicates the noise DNA from the samples of S. enterica and Lambda_P indicates the noise DNA from the sample of P. aeruginosa. From the NAD experiments, only reads that had a quality score above 10 were classified using the WIMP workflow (Extended Data: Figure S2). For the noise DNA and the target DNA, Lambda_S_1ng: unblock=161; Lambda_S_3ng: unblock=131; Lambda_S_5ng: unblock=175; Lambda_P: unblock=11574, no_decision=790, stop_receiving=75; Salmonella_1ng: unblock=23, no_decision=380, stop_receiving=30; Salmonella_3ng: unblock=28, no_decision=1862, stop_receiving=123; Salmonella_5ng: unblock=19, no_decision=5394, stop_receiving=391; Pseudomonas: unblock=1766, no_decision=975621, stop_receiving=55543.
To confirm the decision-making process of adaptive sampling, each read was classified by a cloud-based analysis platform called the WIMP workflow (Extended Data: Figures S4 and S5). The species identification was downloaded from the WIMP workflow, and the reads identified as the noise DNA or the target DNA were saved separately. Subsequently, each identified read was subcategorized into its adaptive sampling decision type ( Figure 3B). The results show that the noise DNA from the Salmonella samples was all rejected (“unblocked”) by adaptive sampling. Interestingly, there were some noise DNA reads from the Pseudomonas sample that were either continued (“no_decision”) or even accepted (“stop_receiving”). This result is unexpected as MinION flow cells are expected to have more stable nanopores and generate higher outputs. However, the current setting of GPU-accelerated adaptive sampling may be a limiting factor in depleting the noise DNA with a larger number of nanopores generating big data output in NAD sequencing experiments with real-time processing.
For the target DNA, the NAD experiments successfully continued (“no_decision”) or accepted (“stop_receiving”) a larger number of reads in both the Salmonella samples and the Pseudomonas sample (Extended Data: Table S5). In the Pseudomonas sample, it is notable that more target DNA reads with longer sequence lengths were rejected wrongly (“unblocked”) than those of the Salmonella samples ( Figure 3B), as the decision-making process of adaptive sampling takes potentially has a bottleneck from basecalling for read mapping longer in higher throughput flow cells due to the limitation of parallel computing power in this study.
In the Salmonella samples, the output ratio of target DNA to noise DNA increases from 2.69 to 33.17 as the concentration of the target DNA increases from 1 ng to 5 ng ( Table 2). Furthermore, the ratio of acceptance to rejection of the target DNA increases from 1.30 to 20.58 with the increasing concentration of the bacterial DNA content. This result indicates that adaptive sampling functions with predictable outcomes, and NAD experiments perform effectively in sequencing low concentrations of target DNAs. Additionally, the output ratio of target DNA length and noise DNA length remain constant at around 4 ( Table 2), indicating this correlation in the performance and the concentration of the target DNA is independent of other factors in NAD experiments.
However, the Pseudomonas sample has a much lower output ratio of target DNA to noise DNA at 18.83 despite a higher input ratio of target DNA to noise DNA. This result is due to the noise DNA being accepted or fully sequenced, as shown by the higher ratio of acceptance to rejection in the noise DNA ( Table 2 and Extended Data: Table S5). These summary statistics emphasize the importance of increasing parallel computing power to process higher throughput in MinION flow cells for NAD experiments.
The species identification of each read using the WIMP workflow shows that while a large number of reads was correctly classified as the target DNA or the noise DNA at the family level, a higher proportion of reads was wrongly classified as other organisms at the genus level (Extended Data: Figures S4 and S5). For example, a majority of the reads were identified as Escherichia coli in the Salmonella samples. This misclassification may arise from the fact the genomes of Escherichia coli and Salmonella enterica share similar gene content,23,24 making it difficult for the Centrifuge classification engine to accurately identify the genus or species based on a single long read.
After the rapid species classification, the potential of genome assembly using NAD sequencing experiments with such low DNA inputs was investigated. The reads from the NAD datasets were assembled with a de novo assembler for single-molecule sequencing reads called Flye using a metagenomic option. The assembled fragments had an N50 of around 50 kb in the Salmonella samples and an N50 of around 1 Mb in the Pseudomonas sample (Extended Data: Table S6). This shows that MinION flow cells are much more effective in assembling bacterial genomes with a higher data output, in spite of the lower efficiency in adaptive sampling ( Table 2).
After metagenomic genome assembly, the assembled fragments were aligned against the reference target genome or the reference noise genome ( Table 3 and Extended Data: Tables S7-S8). We evaluated the extent and accuracy of the noise genome assemblies from each sample against the reference genome of Lambda phage. The purpose of this assembly and comparison was to verify the accuracy of long-read sequencing using an independent dataset, different from the target genomes. Additionally, this approach allowed us to quantify the amount of noise reads identified as artifacts. The fewer the noise DNA read, the more sequencing capacity could be allocated to assembling the target genomes. The results show that the Salmonella samples assembled only a small percentage of the target genome of S. enterica. For example, the assembled fragments from the Salmonella_1ng sample only covered 0.36% of the reference target genome, while it covered 100% of the reference noise genome ( Figure 4). The coverage of the target genome increases with the increasing target DNA concentrations, as shown by the Salmonella_3ng sample and the Salmonella_5ng sample covering almost 30% and 20% of the reference target genome, respectively. They both covered the reference noise genome fully as an artifact of NAD sequencing experiments. Notably, the Pseudomonas sample covered 99.9% of the reference target genome ( Figure 5).
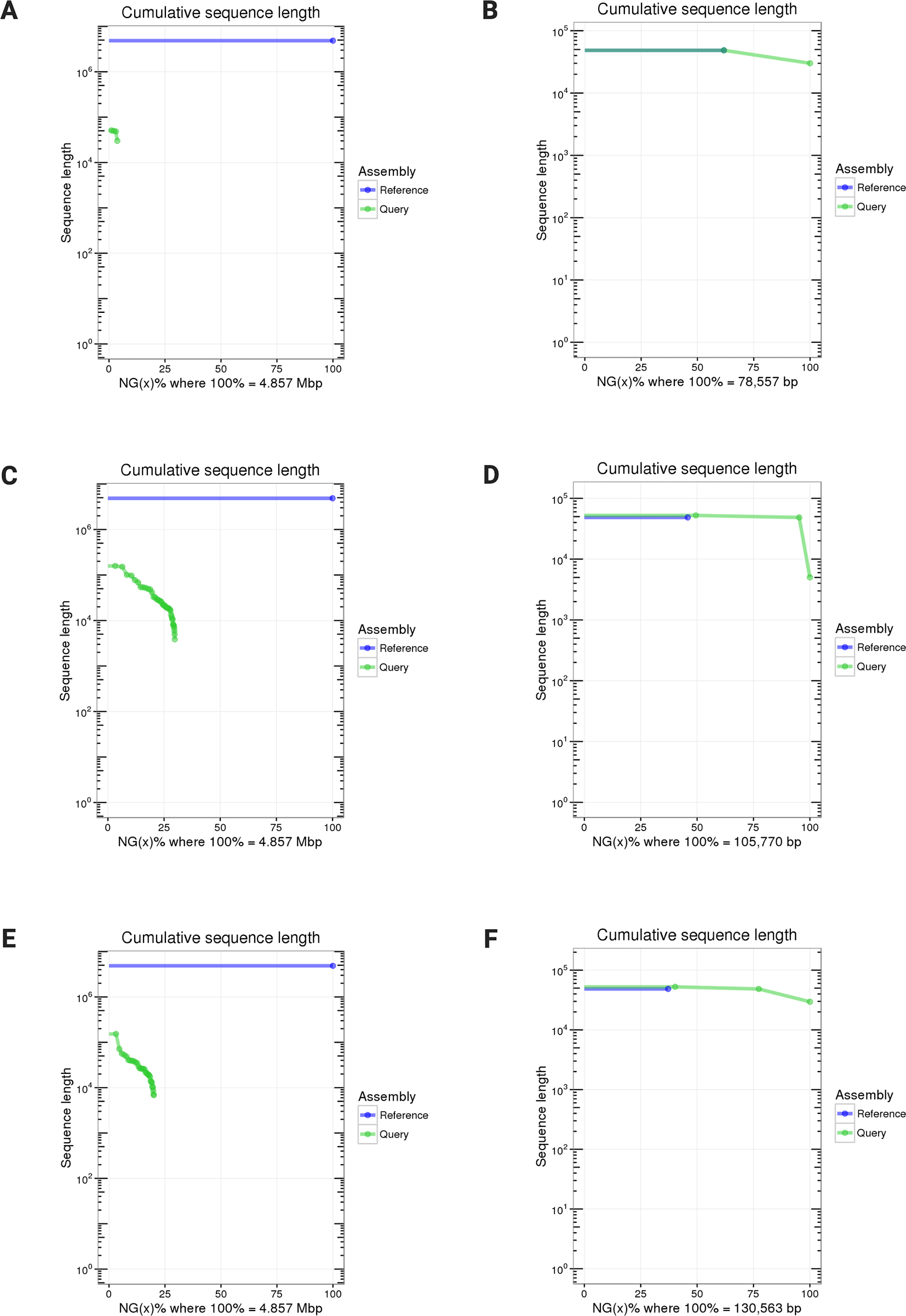
(A) Salmonella_1ng against the target reference; (B) Salmonella_1ng against the noise reference; (C) Salmonella_3ng against the target reference; (D) Salmonella_3ng against the noise reference; (E) Salmonella_5ng against the target reference; (F) Salmonella_5ng against the noise reference.
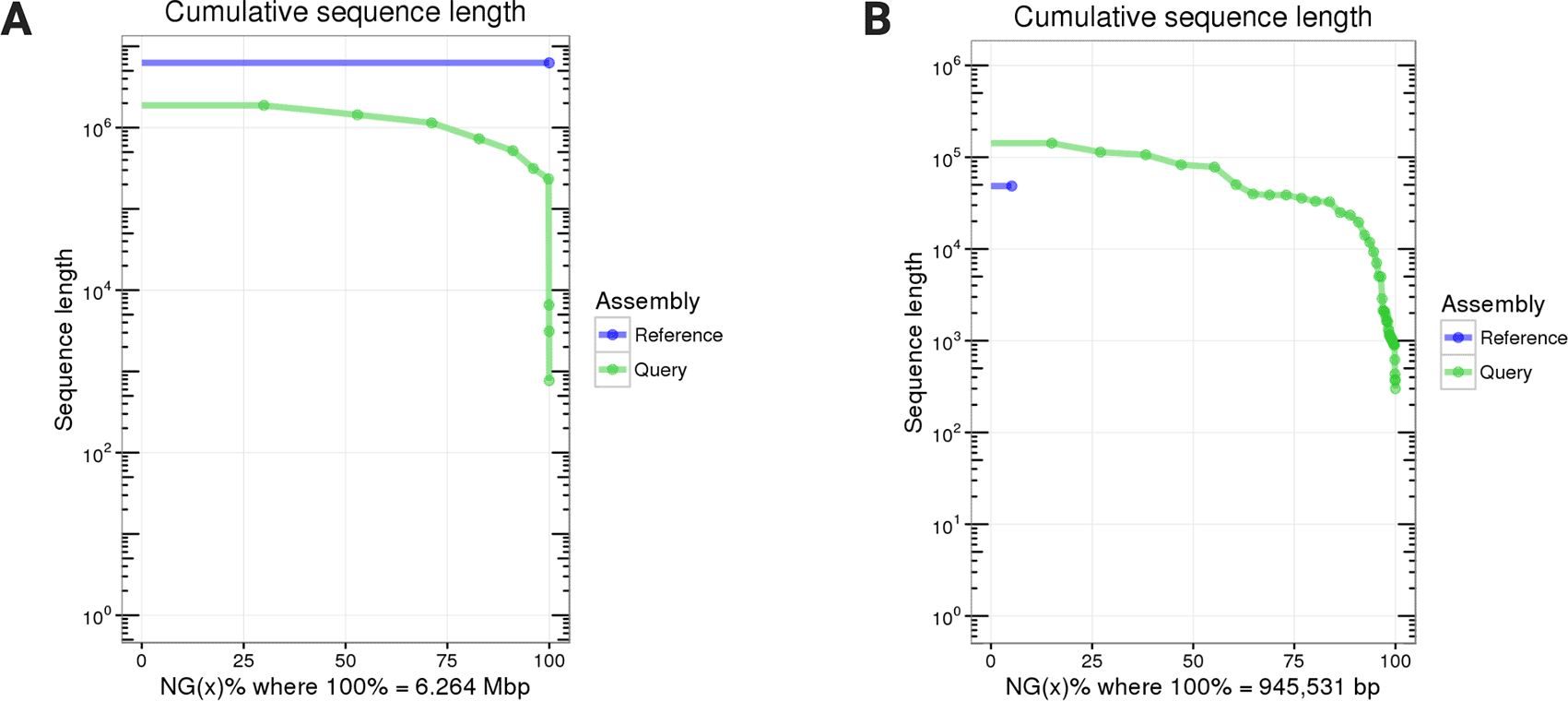
(A) Pseudomonas_300 ng against the target reference; (B) Pseudomonas_300ng against the noise reference.
The assembled genome had a variable average identity depending on the sample type. The Pseudomonas sample had the highest accuracy of 99.97% in genome assembly when aligned to the reference target genome ( Table 3). The assembled genome of the noise DNA also had the highest accuracy of 99.93% when mapped to the reference noise genome (Extended Data: Table S7). The Salmonella_1ng of the lowest target concentration had the lowest accuracy of 82.53% in genome assembly when aligned to the reference target genome ( Table 3). In this NAD sample, several mutations were detected, including breakpoints, insertions, and single nucleotide polymorphisms (SNPs) (Extended Data: Figure S6). However, the assembled genome of the noise DNA had a high accuracy of 99.89% when mapped to the reference noise genome (Extended Data: Table S8). The Salmonella_3ng and the Salmonella_5ng samples had an average identity of 97.58% and 97.77% when aligned to the reference target genome, respectively ( Table 3). These results show that NAD sequencing experiments accurately assemble full bacterial genomes at lower input DNAs (300 ng) than recommended (1,000 ng) using MinION flow cells. Furthermore, NAD sequencing experiments assemble a fraction of bacterial genomes (~30%) accurately at a much lower input DNAs of 3ng than recommended (500 ng) using Flongle flow cells. Lower input DNAs at 1 ng may still be used for species identification with NAD sequencing, potentially overcoming the current limitation of long-read sequencing of high input DNA requirements.
NAD sequencing explores the potential of sequencing low-input target DNA/RNA in its native state by augmenting biological samples with a controlled quantity and quality of noise DNA/RNA. This concept is inspired by the data augmentation technique of machine learning and enabled by the technological advances in long-read sequencing and parallel computing. This study has the specific aim of lowering the minimum input DNA/RNA to a fraction of the recommended input amount of 500 ng and 1,000 ng in cost-effective and high-throughput nanopore sequencing, respectively. This input quantity requirement of DNA/RNA is not realistic in many biological samples without amplification. Conventionally, these biological samples with scarce DNA/RNA have been amplified with the Polymerase Chain Reaction (PCR) technique to meet the minimum criteria of input DNA/RNA before sequencing.
Using PCR, very small amounts of DNA sequences are exponentially amplified to millions to billions of copies with a DNA polymerase in a series of cycles of temperature changes.25,26 However, there are several PCR-induced biases and artifacts, such as DNA polymerase errors and the loss of epigenetic signatures.27–29 These PCR-induced issues have been a limiting factor in understanding some biological processes, such as DNA methylation which plays a key role in development and gene expression.30 Recently, there has been an increasing interest in studying the genomes of various species and individuals at the epigenetic level, of how DNA and RNA sequences undergo epigenetic modifications to inherit information without changing the genetic sequences.31 Such epigenetic information is relevant in medical fields such as cancer genomics,32,33 but recent findings also suggest that various organisms utilize base modifications to escape host immunity.34,35 The development of the ground-breaking mRNA vaccine also arises from the differentially modified nucleotides as a method to transport mRNA without triggering the immune system.36,37 Thus, expanding the capacity to sequence native DNA/RNA from diverse biological samples will enable the scientific community to further explore novel territories of epigenetics.
The study aims to develop a method that broadens the possibility of direct sequencing for various biological samples so that more DNA/RNA can be sequenced in their native states. In this study, the novel method of NAD sequencing tested the minimum input ranges of target DNA from 1 ng to 5 ng for cost-effective nanopore sequencing and 300 ng for high-throughput nanopore sequencing. We demonstrate that NAD sequencing can detect the target DNA with a quantity as low as 1 ng with the cost-effective Flongle flow cells. Furthermore, NAD sequencing can efficiently assemble parts of a bacterial genome, with the target DNA quantity as small as 3 ng (30% complete with an accuracy of 97.58%) in the cost-effective Flongle flow cell, and the target DNA quantity of 300 ng (99.9% complete with an accuracy of 99.97%) in the high-throughput MinION flow cell.
The initial concentration and quantity of the microbial DNA standards of Salmonella enterica and Pseudomonas aeruginosa, approximately at ~10 ng/μl, fell below the minimum concentration measurable within the confidence level of a DNA spectrophotometer. Without NAD sequencing, the target DNA in these samples was not sufficient to be sequenced effectively in their native form with nanopore sequencing. The primary challenge with low input samples in Oxford Nanopore Technologies' sequencing lies in the ligation step, which typically recommends starting with 1 μg of gDNA or 100-200 fmol of amplicons or cDNA. The rapid ligation kit that is optimized for speed and simplicity also recommends an input requirement of 100 ng of gDNA. Using lower amounts of input material or impure samples can compromise library preparation efficiency and significantly reduce sequencing throughput. The smallest quantity of the target DNA examined in this study was 1 ng of Salmonella enterica genome, constrained by the limitations of the laboratory equipment, but NAD sequencing exhibits the potential to detect smaller input amounts of target DNAs than those employed in this study.
The broad aim of this study is to increase the robustness of long-read sequencing to real-world biological samples of small input amounts and noisy backgrounds. Because of the high input requirement, the option of direct sequencing using long-read technologies is frequently supplanted by PCR and short-read sequencing. Conversely, NAD sequencing capitalizes on noise combined with adaptive sampling to mitigate the challenges associated with high DNA inputs required in long-read sequencing, without the need for amplification or any supplementary processing. The only additional step is to determine the type and amount of noise DNA necessary to attain noise-augmented samples requisite for adaptive sampling. Augmenting biological samples with a controlled noise DNA is inspired by the data augmentation technique of white noise injection in machine learning to improve the robustness and generalization power of deep learning models with noisy real-world data.38
In future developments, the proof-of-concept of NAD sequencing experiments will be broadened to establish standardized protocols for augmenting biological samples with the noise DNA. These protocols are designed to eliminate the need for input DNA/RNA quantification in experimental conditions where such equipment is not available, such as in cost-constraint settings or during remote sampling campaigns. Nanopore sequencing has been optimized to perform in remote and cost-constraint situations where rapid and on-site sequencing of biological samples is desirable. Such scenarios may entail the urgency of swiftly detecting infectious agents in remote areas. In such cases, the simple addition of noise DNA such as the Lambda phage genome will suffice in detecting scarce target DNA/RNAs or even in assembling the target genome. This noise augmentation ensures increasing the robustness of direct sequencing in real-world biological data, as well as eliminating the bottleneck of DNA/RNA quantification.
Microbial DNA standards from Pseudomonas aeruginosa and Salmonella enterica (Sigma-Aldrich) were obtained at the concentration of 10 ng/μL. For both the microbial DNA standards, the UV absorbance ratio (OD260/OD280) and the bacteria identity from the manufacturers are given as 1.8 and 95%, respectively. DNA concentration and purity were confirmed (Extended Data: Table S1, Figure S1) using a DNA spectrophotometer. Given the total volume of 30 μl, the total amount of DNA from these microbial standards was 300 ng. The input DNA requirements for MinION flow cells (R9.4.1) and Flongle flow cells (R9.4.1) are 1,000 ng and 500 ng, respectively.
Lambda DNA standards from Escherichia coli bacteriophage (Thermo Fisher) were obtained at the concentration of 0.3 μg/μL. To meet the input DNA requirements of nanopore sequencing, the microbial DNA standards were augmented with the lambda DNA standard. For nanopore sequencing of P. aeruginosa, 30 μl of the microbial DNA standard was augmented with 17 μl of the lambda DNA standard to obtain 5.4 μg of input DNA (Extended Data: Table S2). The final concentration of the noise-augmented sample far exceeds the minimum DNA input requirement for MinION flow cells (R9.4.1). For nanopore sequencing of S. enterica, a small amount of the microbial DNA standard (0.1 μl, 0.3 μl, 0.5 μl) was augmented with 2 μl of the lambda DNA standard to obtain approximately 600 ng of input DNA (Extended Data: Table S3). The final concentrations of these noise-augmented samples meet the minimum DNA input requirement for Flongle flow cells (R9.4.1).
A ligation-based sequencing kit was chosen for processing singleplex samples of the noise-augmented target DNA. Library preparation was carried out using the ligation sequencing kits (SQK-LSK109; Oxford Nanopore Technologies) according to the manufacturer’s instructions. For Flongle flow cells (R9.4.1), the Flongle Sequencing Expansion (EXP-FSE001; Oxford Nanopore Technologies) was used in combination for optimal results. These ligation sequencing kits are optimized for preparing sequencing libraries from dsDNA such as gDNA, cDNA, or amplicons. The library preparation method involves repairing and dA-tailing DNA ends using the NEBNext End Repair/dA-tailing module, and then ligating sequencing adapters onto the prepared ends. For the highest data yields, these ligation kits recommend starting with 1 μg of gDNA or 100-200 fmol of shorter-fragment input such as amplicons or cDNA. Starting with lower amounts of input material, or impure samples, may affect library preparation efficiency and reduce sequencing throughput.
The NAD samples of the microbial DNA standards augmented with the noise DNA were sequenced with a MinION Mk1B (Oxford Nanopore Technologies). For each sequencing run, adaptive sampling implemented in the MinKNOW software (v.21.11.8) was preset to deplete the Lambda phage genome. The complete genome of Escherichia coli bacteriophage (NC_001416.1) was uploaded as a FASTA file as the reference sequence to deplete while sampling. Adaptive sampling requires high computational power due to the need to conduct real-time basecalling to process whether to reject or accept reads for further sequencing. GPU-accelerated adaptive sampling was performed using an NVIDIA GPU on Windows (NVIDIA Quadro P3000). For better performance, we recommend using GPUs with clock speeds of 1320 MHz base clock and 1777 MHz boost clock for NAD sequencing and super-accuracy basecalling.
After the NAD sequencing of the samples was completed, the raw signal data in FAST5 files were basecalled with Guppy (v6.5.7). The GPU version of Guppy was used to improve the performance of super-accuracy basecalling, which achieves the highest raw read accuracy out of the other available neural network models in Guppy, such as fast analysis and high-accuracy analysis.39 An external GPU enclosure (eGPU) paired with an Nvidia Ampere card (RTX3060) was connected to a Dell Latitude laptop to perform high-accuracy basecalling, saving the basecalled long reads in FASTQ files.
For the rapid classification of reads, a cloud-based platform providing analysis workflows called EPI2ME was used. Using the EPI2ME platform (v.3.5.7), the WIMP workflow (v.2021.11.26) rapidly classifies long reads from nanopore sequencing based on the Centrifuge classification engine.40 The NAD datasets basecalled with the super-accuracy models were classified at the Family, Genus, and Species level using the WIMP workflow.
The classification of each long read was saved to assess the performance of NAD sequencing in accuracy and efficiency. For accuracy, the decision of adaptive sampling to accept or reject further sequencing of each read was analyzed by the reads classified as the target (bacterial DNA) versus the noise (Lambda phage DNA). For efficiency, the mean DNA length sequenced for the reads classified as the target (bacterial DNA) versus the noise (Lambda phage DNA) was calculated.
For the downstream analysis, the NAD datasets from each sample were assembled using Flye (v2.9.2).41,42 For the assembly, the FASTQ files generated from each experiment were combined into one file, and the metagenomic option was used to assemble the long reads into contigs.43
After metagenomic genome assembly, the resulting contigs were aligned to the reference noise genome (NC_001416) and the reference target genome (GCF_000006945 or GCF_000006765) using MUMmer (v4.0+).44–46 The alignment quality of NAD datasets to the reference genomes was analyzed and visualized using Assemblytics.47
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)