Keywords
UCI, Kaggle, Heart Disease, Imputation, Deep Learning, Echo State Network, Residual Attention.
This article is included in the Manipal Academy of Higher Education gateway.
This article is included in the Artificial Intelligence and Machine Learning gateway.
UCI, Kaggle, Heart Disease, Imputation, Deep Learning, Echo State Network, Residual Attention.
In this revised version, we have substantially strengthened the methodological transparency, statistical rigor, and reproducibility of our study. The Introduction was rewritten for improved flow and updated to reflect current diagnostic practices in ischemic heart disease (IHD), replacing outdated modalities with contemporary techniques (cardiac CT, RbPET, coronary angiography). The Related Works section was streamlined and expanded to cover prior attention–Echo State Network (ESN) combinations, thereby clarifying the novelty of our Hybrid Residual Attention with Echo State Network (HRAESN) model.
In the Methods, we now provide detailed definitions of heart disease/IHD in the UCI and Kaggle datasets, describe missingness and imputation using the IHD Multiple Imputation Technique, and explain how ESNs were adapted for structured tabular data. Evaluation metrics, including Cohen’s kappa and Jaccard index, are introduced earlier for consistency.
To strengthen statistical robustness, we re-ran all experiments using 5-fold and 10-fold stratified cross-validation, reporting mean ± standard deviation across folds. We added statistical significance testing (McNemar’s test and Wilcoxon signed-rank) and expanded performance evaluation with ROC curves, AUC values, precision–recall curves, and calibration plots. Confidence intervals (95%) were computed via bootstrap resampling.
Figures and tables were revised to improve clarity: Figure captions specify dataset scope, confusion matrices now include raw counts, and baseline population characteristics are summarized in a new table. Comparative analysis was clarified to explain baseline method selection.
The Discussion and Limitations were expanded to address external validation, imputation bias, dataset imbalance, and interpretability of the Attention Residual Learning module. Claims regarding clinical readiness were moderated to emphasize proof-of-concept status.
Finally, to enhance reproducibility, we expanded algorithmic details of the imputation method and provide code availability upon request. Collectively, these revisions address reviewer feedback and significantly improve the rigor, transparency, and interpretability of our work.
See the authors' detailed response to the review by MUHAMMAD HAMMAD MEMON
See the authors' detailed response to the review by Amalie Dahl Haue
See the authors' detailed response to the review by Dhadkan Shrestha
Ischemic heart disease (IHD) arises when coronary arteries are narrowed or blocked, leading to reduced blood flow and oxygen supply to the heart muscle. Persistent restriction of coronary circulation results in myocardial ischemia, which can progress to coronary artery disease and, in severe cases, myocardial infarction. Silent ischemia, in particular, occurs without overt symptoms but still poses a high risk of sudden cardiac events, especially in individuals with diabetes or a prior history of heart attack. In current clinical practice, the diagnosis and assessment of IHD relies on advanced imaging and invasive modalities, including cardiac computed tomography (CT), Rubidium positron emission tomography (RbPET), and coronary angiography, which provide accurate evaluation of coronary artery stenosis and perfusion deficits. These methods, while effective, remain costly, invasive, and not always feasible for large-scale population screening, motivating the exploration of non-invasive, AI-based predictive approaches for early detection.1
The World Health Organization (WHO) reports that cardiovascular diseases (CVDs) continue as the main cause of global mortality since 17.9 million people died from CVDs in 2019 which amounted to 32% of worldwide fatalities. Heart attacks and strokes lead to 85% of fatal outcomes among the tested patients.2 The worldwide fatalities from noncommunicable diseases reached 17 million during 2019 before people turned 70 years old and cardiovascular conditions caused 38% of those premature deaths. Medical detection of CVDs remains vital because behavioral prevention through risk control methods such as smoking and food control and weight management cannot substitute for early medical discovery to achieve both effective treatment and lower mortality rates. Heart disease poses a major financial challenge and increasing health burden because of high surgical expenses and rising population incidence mainly affecting developing countries. Knowledge about how patient characteristics link to heart disease risk serves as the basis for preventing the condition and detecting it early for treatment purposes.
Deep learning has become an integral part of computer vision, object recognition, natural language processing, speech recognition, medical diagnostics, bioinformatics, and drug discovery. Similar to traditional artificial neural networks (ANNs), deep learning models consist of input, hidden, and output layers, with patient risk factors serving as input features. The research demonstrates that artificial neural networks deliver outstanding results when used for identifying and foretelling coronary heart disease.3 Medical AI applications experience rapid growth because of three main factors including Internet of Things (IoT) and powerful computing hardware (e.g., GPUs and TPUs) together with big medical datasets. Essential information needed by deep learning models comes from Medical IoT devices together with electronic health records as well as genomic data and central medical databases. The critical challenges include preserving data privacy as well as successfully deploying the models and optimizing service quality despite their importance.3
Time-series prediction has seen increased popularity among researchers who use recurrent neural networks (RNNs) as deep learning-based approaches. RNNs work with sequential data sets through the process of feeding output data from previous components to next steps making them ideal for ECG signal processing and patient health surveillance. RNNs differ from regular neural networks by retaining previous input data thus they produce enhanced forecasts for temporal information patterns. Traditional RNNs experience gradient vanishing problems because of which they become problematic for handling long sequences. The development of both Hochreiter and Schmidhuber led to long short-term memory (LSTM) networks which incorporated memory gates to control information transmission and suppress gradient deterioration.4
Time-series extrapolation along with fast learning occurs efficiently through Echo State Networks (ESN) which function as a preferred substitute to normal RNNs.5 An Echo State Network functions through its reservoir of recurrent neurons connected haphazardly that helps the network learn complex patterns yet uses few processing resources. The forecast capabilities of time-series prediction and representation learning capabilities improve through the use of Deep ESNs (DESNs) that include multiple serially connected reservoirs.6
A transformation of conventional convolutional neural networks (CNNs) called Residual Attention Network brings attention mechanism integration for feature enhancement.7 The advanced feed-forward framework permits end-to-end training which enables it to learn hierarchical features independently. Gremlin Deep Residual Attention Networks provide an efficient mechanism for deep learning systems to reach hundreds of layers through their implementation of Attention Residual Learning (ARL).8 Different algorithms can achieve maximum strength performance through hybrid deep learning models which integrate multiple techniques. Medical diagnostic accuracy along with efficiency can experience significant improvement by combining residual attention learning methods with Echo State Networks. The appropriate addressing of missing values through the Ischemic Heart Disease Multiple Imputation Technique creates improved data reliability and completeness.9
The main goal of this research work is to create a Hybrid Residual Attention with Echo State Network (HRAESN) model used to predict ischemic heart disease (IHD) at an early stage while maintaining high accuracy. The proposed method integrates Residual Attention Learning (RAL) with Echo State Networks (ESNs) to boost both feature extraction and time-series classification and general model performance. This study solves data preprocessing problems with Ischemic Heart Disease Multiple Imputation Technique while using hybrid deep learning effectively for robust classification. The research uses two recognized heart disease data sets including 70,000 records from the Kaggle Cardiovascular Disease dataset and 303 records from the UCI Heart Disease dataset to evaluate the proposed method. The objective is to prove that this approach outperforms current state-of-the-art heart disease prediction methods. ART-based analysis findings will enhance clinical diagnosis along with IHD detection and patient care through AI-powered diagnostic systems.
The following research questions are the focus of the study’s search and synthesis of the literature.
1. How do deep learning models, particularly Echo State Networks (ESNs) and Residual Attention Learning (RAL), improve the accuracy and stability of ischemic heart disease prediction compared to traditional machine learning approaches?
2. What are the key challenges associated with handling missing data in medical datasets, and how can the Ischemic Heart Disease Multiple Imputation Technique enhance data completeness and reliability?
3. How does the proposed Hybrid Residual Attention with Echo State Network (HRAESN) model perform on benchmark datasets (Kaggle Cardiovascular Disease and UCI Heart Disease) compared to existing state-of-the-art heart disease prediction models?
One of the main causes of death is ischemic heart disease (IHD), which needs to be predicted early and accurately in order to be effectively treated. While current machine learning models have trouble managing missing data, time-series dependencies, and computational inefficiencies, traditional diagnostic techniques are costly, time-consuming, and rely on expert interpretation. Vanishing gradients and high complexity are two drawbacks of deep learning techniques like recurrent neural networks (RNNs) and long short-term memory (LSTM) networks. To address these challenges, this study proposes a Hybrid Residual Attention with Echo State Network (HRAESN) model, integrating Residual Attention Learning (RAL) for feature extraction and Echo State Networks (ESNs) for efficient time-series processing, ensuring improved predictive accuracy and robustness.
Numerous studies have explored machine learning (ML) and deep learning (DL) techniques for cardiovascular disease prediction. Traditional ML methods such as Decision Trees, Random Forests, Naïve Bayes, and Support Vector Machines have shown moderate success but often struggle with missing data, feature complexity, and generalization.10–13
Deep learning models, particularly Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) architectures, have been widely applied to ECG-based diagnosis and patient monitoring, achieving improved accuracy in handling sequential data.14 Hybrid RNN–LSTM models, for example, demonstrated higher classification performance than standalone approaches.14,15
Echo State Networks (ESNs) and related reservoir computing methods have also been applied in cardiovascular applications due to their efficiency in time-series prediction. Li et al.16 showed effective heartbeat classification using a residual squeeze-and-excitation framework, while Gao et al.5 and Sun et al.17 combined ESNs with wavelet transformation and Deep Belief Networks, respectively, to improve temporal modeling. Optimized ESN variants, including bidirectional18 and adaptive evolutionary models,19–21 have further enhanced performance, and hardware-efficient ESN implementations have demonstrated low-power solutions for clinical settings.22
Attention mechanisms and residual learning have similarly strengthened feature representation in medical tasks. Residual Attention Graph Convolutional Networks23 and deep residual attention models8,24 and Residual Attention Graph Convolutional Networks25 demonstrated improvements in complex classification tasks. Feature refinement approaches such as Recursion-Enhanced Random Forest26 and SVM-based ensembles with feature elimination27 have also been explored for cardiovascular disease detection.
Hybrid frameworks that combine different learning paradigms have become increasingly popular. Examples include CNN–reservoir computing hybrids,28 CNN–reservoir computing hybrids,29 clustering-enhanced prediction models,13,15 and DBN–RNN integrations optimized by metaheuristics.30 Ensemble-based strategies, including two-tier classifiers and hybrid Random Forest/Gradient Boosting methods, have further improved classification outcomes.31,32
Overall, existing studies highlight three main trends: (i) ESNs provide efficient temporal modelling for cardiovascular data, (ii) attention-based residual learning enhances feature extraction, and (iii) hybrid frameworks that integrate these methods yield superior predictive accuracy. Building on these findings, our proposed HRAESN model integrates Residual Attention Learning with ESNs to address limitations in prior models and achieve higher accuracy, stability, and robustness in ischemic heart disease prediction.
This study utilizes data from two publicly available repositories: Kaggle and the UCI (University of California, Irvine) Machine Learning Repository. These datasets provide comprehensive patient records used for cardiovascular disease prediction and ischemic heart disease classification.
3.1.1 Kaggle cardiovascular disease dataset
There are 70,000 patient records with 11 distinct features in the Kaggle Cardiovascular Disease dataset.33 When medical practitioners performed clinical examinations, these characteristics were noted. Three types of input features make up the dataset:
1. Objective Characteristics (Real patient data): Gender, Age, Height, and Weight
2. Features of the Examination (Medical Test Results): Blood Pressure Systolic and Diastolic, Blood Pressure Levels of Cholesterol and Glucose
3. Subjective Features (patient data as self-reported): Alcohol use, smoking, and physical activity
3.1.2 UCI heart disease dataset
The UCI Heart Disease dataset contains 76 features, of which 14 are highly relevant for heart disease diagnosis.34 The predictive class attribute is typically listed last, indicating the presence or absence of heart disease. Table 1 and Table 2 provide detailed descriptions of the dataset attributes.
3.1.3 Datasets and ethical considerations
This study utilizes two publicly available datasets: the Heart Disease dataset from the UCI Machine Learning Repository and the Cardiovascular Disease dataset from Kaggle. These datasets contain anonymized patient records and are publicly released for academic and research purposes.
3.1.4 Ethical approval statement
As this research involves only the use of publicly accessible, anonymized datasets, no formal ethical approval was required. The study complies with the ethical principles outlined in the Declaration of Helsinki. No intervention or interaction with human subjects occurred.
3.1.5 Informed consent statement
Because this study used pre-existing anonymized data from public repositories, informed consent from participants was not required. All necessary ethical permissions and participant consents were obtained by the original data providers as per their respective institutional and data-sharing policies.
3.1.6 Definition of heart disease in the datasets
In the UCI Heart Disease dataset, the target variable “num” (values 0–4) indicates the severity of disease as determined by coronary angiography. For this study, we followed prior works31,34–37 and binarised the variable: 0 = absence of disease, 1–4 = presence of heart disease. In the Kaggle Cardiovascular Disease dataset, the binary target variable “cardio” was defined during the original data collection based on combined clinical assessment and diagnostic test results (blood pressure, cholesterol, ECG). Here, 0 = healthy and 1 = diagnosed cardiovascular disease.
3.1.7 Dataset inclusion and missing values
All available records were included: 70,000 instances in the Kaggle dataset and 303 in the UCI dataset. The Kaggle dataset contained ~0.3% missing values across features, while the UCI dataset had six missing entries. These were imputed using the Ischemic Heart Disease Multiple Imputation Technique,9 ensuring that no records were discarded and data completeness was preserved.
To ensure that our training and testing sets were representative, we verified that baseline characteristics (age, sex, cholesterol, and blood pressure) were similarly distributed between the two subsets. Table 3 presents the distributions of these key features for both training and testing populations in the UCI and Kaggle datasets.
Values are mean ± SD for continuous variables and % for categorical variables.
The classification of ischemic heart disease (IHD) in this study is based on a hybrid deep learning model that integrates machine learning (ML), soft computing techniques, and optimization methods to enhance accuracy and robustness. Different classification models are created by integrating various ML methods and ensemble learning methods that involve bagging and boosting. Multiple classifiers work together in ensemble methods to generate better generalization as well as decrease overfitting.
HRAESN model combines the following key elements:
1. Echo State Networks (ESNs) for efficient time-series processing
2. Attention Residual Learning (ARL) for enhanced feature extraction
By combining ESN and ARL, the model achieves higher accuracy, better generalization, and improved stability compared to conventional ML classifiers.
Echo State Networks (ESNs), a subset of recurrent neural networks (RNNs) created for effective sequential data processing, are a part of the reservoir computing paradigm. In contrast to conventional RNNs, an ESN’s hidden layer (reservoir) is fixed and randomly initialized, whereas only the output layer is trained.
Key features of ESNs include:
• The reservoir exhibits two weight sets which are fixed by random values without training: W_in for input-to-lateral connections and W_r for lateral connections.
• During ESN operation researchers only train output weights but maintain simple computational design for efficient pattern learning capability.
• The hidden layer connectivity of ESNs remains sparse which decreases computational complexity.
• Nonlinear Embedding: The reservoir state provides a nonlinear transformation of input data, which can then be mapped to the desired output using a trainable readout layer.
Since ESNs retain past information in a fixed reservoir, they are highly effective for time-series forecasting and real-time signal processing, making them a suitable choice for ischemic heart disease prediction.
Attention Residual Learning (ARL) is a deep learning technique that enhances feature extraction by selectively focusing on relevant information while reducing noise in deep neural networks. It is particularly beneficial in medical image analysis and time-series classification.
Key challenges in deep residual networks include:
• Performance Degradation: Stacking multiple narrow attention modules can lead to a decline in performance.
• Feature Suppression: Soft mask layers may inadvertently reduce the importance of relevant features.
To address these issues, ARL modifies feature representation using an attention mask. The transformation is mathematically represented as:
Where:
i: Index position in the input matrix
Mi (t): Gradient of the input feature mask during the t-th iteration
Hi (t+1): Updated attention module output at the (t+1)-th iteration
This formulation ensures that:
1. Relevant features are amplified, while irrelevant features are suppressed.
2. Deep residual networks maintain stable performance even with hundreds of layers.
3. Computational efficiency is preserved without significantly increasing model complexity.
The integration of ESNs with ARL enables the proposed HRAESN model to merge its time-series learning functionality with attention-based feature refinement that results in precise and stable outcomes for ischemic heart disease predictions.
The prediction model utilizes heart disease records from UCI Heart Disease Data Set and the Cardiovascular Disease dataset from Kaggle. Pre-processing starts with performing the Ischemic Heart Disease Multiple Imputation Technique to identify and imputation missing values before proceeding further.1 The HRAESN model combines Echo State Networks (ESNs) for short-term memory processing with Attention Residual Learning (ARL) for enhancing features to classify heart disease.
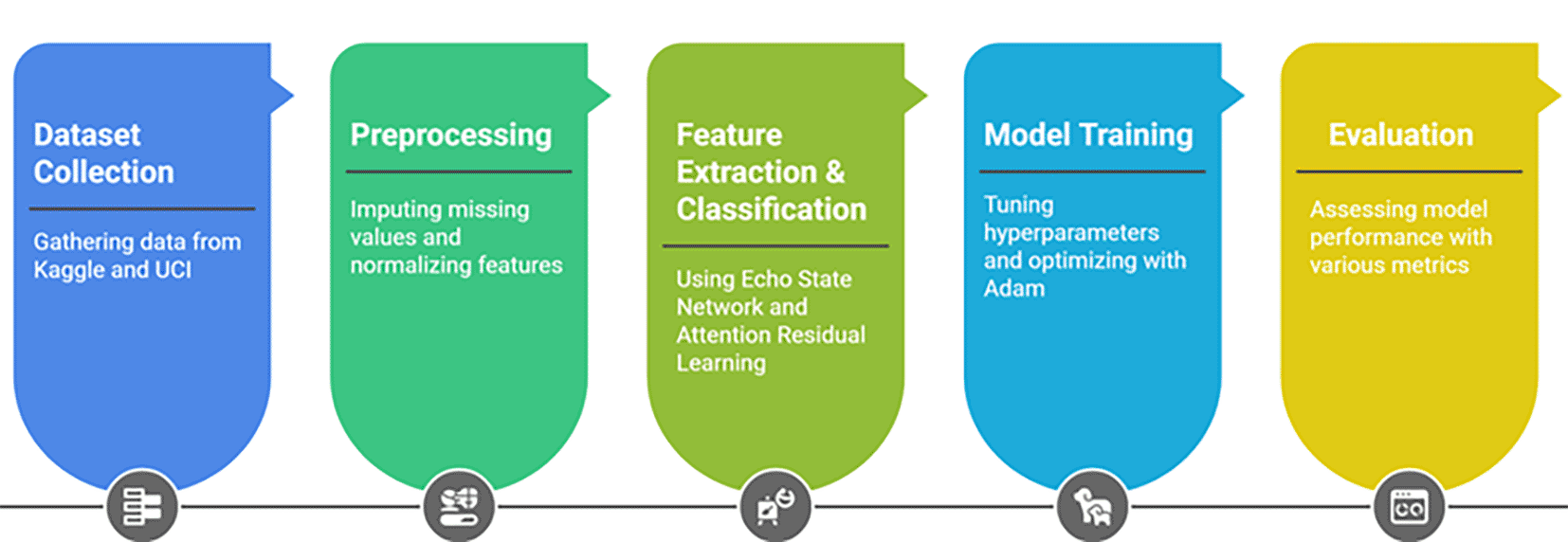
Workflow of the proposed experiment using the UCI Heart Disease (303 records, 14 features, 6 missing values) and Kaggle Cardiovascular Disease dataset (70,000 records, 11 features, ~0.3% missing values). Missing values were imputed using the Ischemic Heart Disease Multiple Imputation Technique. Labels were defined as binary: UCI “num” attribute (0 = healthy, 1–4 = disease present, recoded to 0/1) and Kaggle “cardio” attribute (0 = healthy, 1 = disease present). The preprocessed datasets were fed into the HRAESN model, combining Echo State Networks for reservoir-based representation of clinical features with Attention Residual Learning for enhanced feature selection. Model training and evaluation used an 80:20 split, with multiple performance metrics reported.
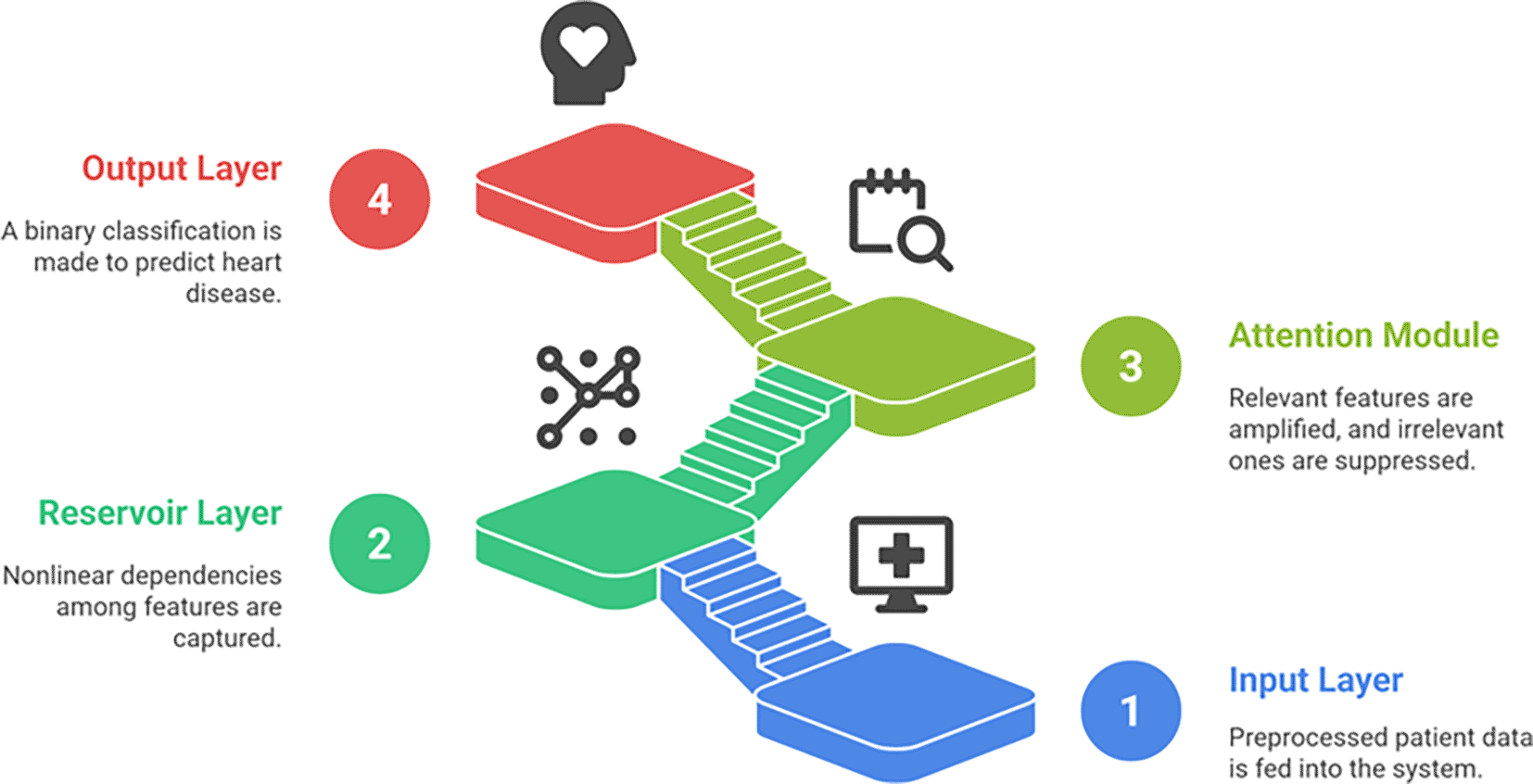
Patient data (70,000 Kaggle records, 303 UCI records) were preprocessed and imputed before being passed into an Echo State Network reservoir, which captures nonlinear feature interactions. The reservoir outputs were refined using Attention Residual Learning, which selectively enhances relevant clinical patterns while suppressing noise. A final sigmoid activation layer produces binary predictions (0 = healthy, 1 = ischemic heart disease). This architecture leverages ESN efficiency and attention-driven feature refinement for improved classification accuracy.
Experiment workflow
1. Load and preprocess datasets: The Heart Disease Data Set and Cardiovascular Disease dataset are loaded, and missing values are imputed using the Ischemic Heart Disease Multiple Imputation Technique.9,38
2. Feature extraction and classification: The HRAESN model applies ESNs for sequence modeling and ARL for refining feature representation.
3. Model evaluation: A confusion matrix assesses the model’s performance, ensuring accurate classification of heart disease cases.
3.5.1 Hybrid Residual Attention with Echo State Network (HRAESN) algorithm
The input feature matrix (XF) is obtained from the Ischemic Heart Disease Multiple Imputation Technique and labeled according to class 0 (normal) or class 1 (heart disease).
Echo State Network (ESN) Hidden Layer Dynamics
Where:
• and are the feature matrices at iterations t and t + 1.
• is the input reservoir weight matrix derived from the input data.
• is the reservoir weight matrix representing internal states.
• represents the internal states computed at iteration t.
• is the activation function applied at the reservoir.
Attention Residual Learning (ARL) transformation
Where:
• represents the input matrix’s index positions.
• is the gradient of the input feature mask at iteration t.
• is the attention module output at iteration t + 1.
The reservoirs in HRAESN are linked in series, meaning each reservoir state depends on the previous reservoir’s output and its own past state:
Where:
Activation Functions and Output Computation
Where:
Dynamic Echo State Network Output
Where:
Input: features data , label data
Output: Predicted result Pr
1: begin
2: for each Compute the Hidden layer of dynamic ESN
3:
4: end for
5: for each compute the attention residual learning
6:
7: end for
8: for x=1 to M do:
9:
10:
11: …
12:
13: end
14: end
Evaluation metrics
The predictive performance of the proposed HRAESN model and baseline classifiers was assessed using multiple evaluation metrics. Standard measures included:
• Accuracy: the proportion of correctly classified instances among all instances.
• Sensitivity (Recall): the proportion of true positive cases (IHD present) correctly identified.
• Specificity: the proportion of true negative cases (IHD absent) correctly identified.
• Precision: the proportion of predicted positives that are true positives.
• F1-score: the harmonic mean of precision and recall, balancing sensitivity and specificity.
In addition, we introduced two supplementary metrics to capture model agreement and similarity beyond traditional measures:
• Cohen’s Kappa Coefficient: quantifies agreement between predicted and actual classifications beyond chance, with values closer to 1 indicating stronger agreement.
• Jaccard Coefficient: measures the similarity between predicted and actual sets of positive cases, defined as the intersection divided by the union of the sets.
For statistical robustness, 95% confidence intervals (CIs) were estimated for all major performance metrics using a bootstrap resampling strategy (1000 resamples). These CIs provide an indication of the reliability and significance of the reported values.
3.5.2 Hyperparameter tuning
The Hyperparameter Tuning process optimizes the performance of the Hybrid Residual Attention with Echo State Network (HRAESN) model by carefully selecting key parameters for both Echo State Networks (ESN) and Attention Residual Learning (ARL). The reservoir size (500 neurons) and spectral radius (0.8) ensure stable memory retention for time-series processing, while 10% sparse connectivity enhances computational efficiency. The input scaling (0.5) and leaky rate (0.2) regulate data flow within the reservoir, preventing overfitting. The attention module depth (3 layers) and mask range ([0,1]) refine feature selection, improving model interpretability. The model is trained using the Adam optimizer with a learning rate of 0.001, a batch size of 32, and 100 epochs for optimal convergence. The model prevents overfitting through dropout rate 0.3 while 80:20 train-test split maintains evaluation stability. The optimized parameters lead to precise and efficient and stable ischemic heart disease predictions as described in Table 4.
To predict the existence of ischemic heart disease (IHD), a number of classification methods were employed, including Naïve Bayes (NB), Support Vector Machine (SVM), Logistic Regression (LR), Random Forest (RF), and AdaBoost. Data from the Cardiovascular Disease dataset (Kaggle) and the Heart Disease Data Set (UCI) were used in the experiments.
The datasets contain various medical indicators that serve as input features for classification. The target variable is binary:
The proposed hybrid HRAESN model is trained using 80% of the dataset, and the remaining 20% is used for testing. Principal Component Analysis (PCA) was applied to highlight variance and distinct patterns in the dataset. Figure 3 shows the PCA plot, where:
• Principal Component 1 (X-axis) and Principal Component 2 (Y-axis) capture most of the variance.
• Blue (0) represents healthy individuals, while Red (1) represents patients with heart disease.
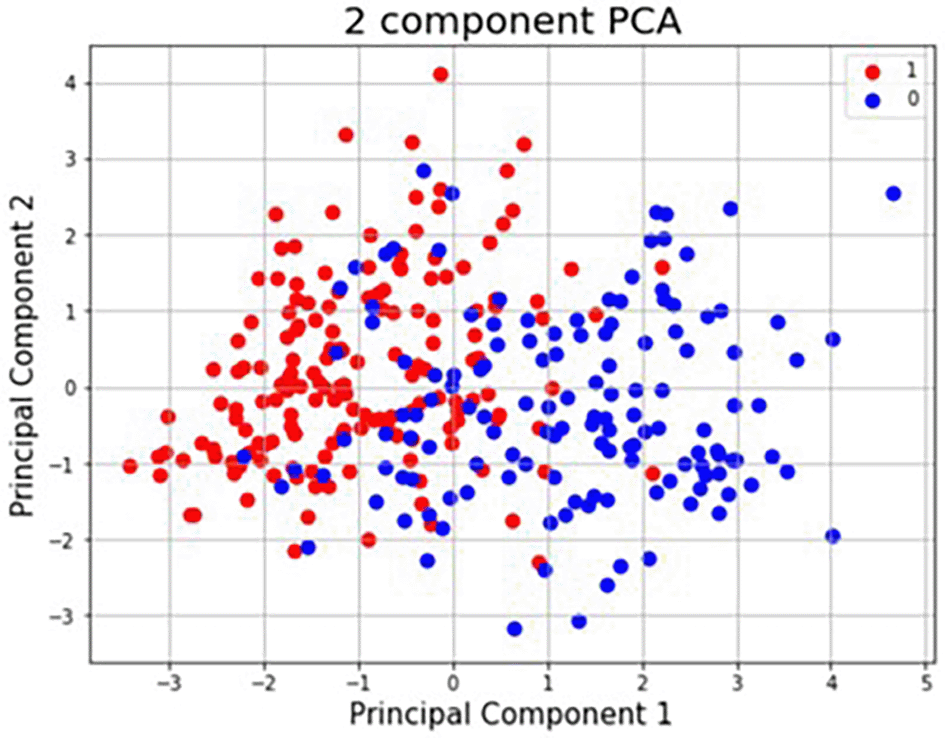
Additionally, six records in the UCI dataset had missing values, which were imputed using the Ischemic Heart Disease Multiple Imputation technique, producing a complete dataset with no missing values.
Tables 5 and 6 present the normalized confusion matrix for the HRAESN model using the UCI Heart Disease dataset and Kaggle Cardiovascular Disease dataset, respectively.
Class 0 = no ischemic heart disease (IHD); Class 1 = IHD present.
| Predicted | |||
|---|---|---|---|
| Label | |||
| Class | 0 | 1 | |
| Actual label | 0 | 163 | 1 |
| 1 | 3 | 136 | |
Class 0 = no ischemic heart disease (IHD); Class 1 = IHD present.
| Predicted | |||
|---|---|---|---|
| Label | |||
| Class | 0 | 1 | |
| Actual label | 0 | 34431 | 549 |
| 1 | 568 | 34452 | |
To assess statistical robustness, 95% confidence intervals (CIs) were estimated for the main performance metrics (accuracy, sensitivity, specificity, precision, and F1-score) using a bootstrap resampling procedure with 1000 iterations. These intervals demonstrate the reliability and statistical significance of the observed differences between models.
Figures 4–6 illustrate the comparative performance of different classifiers used for ischemic heart disease prediction.
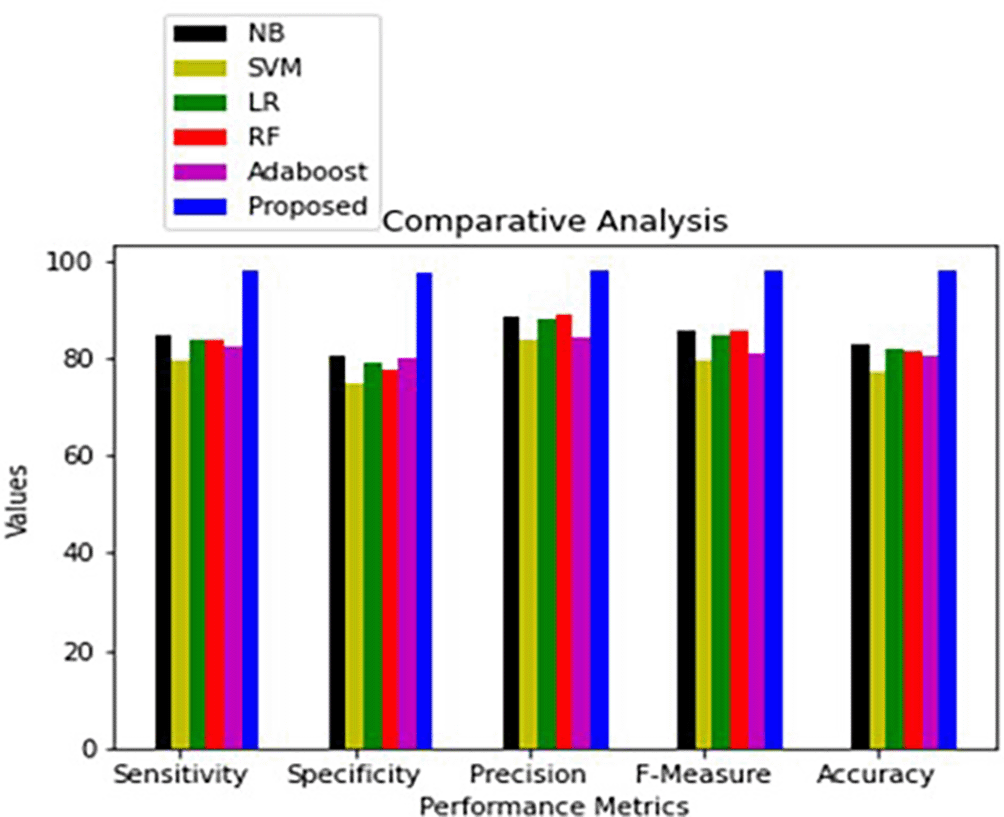
Results are shown for both UCI and Kaggle datasets. Class 0 = no ischemic heart disease (IHD); Class 1 = IHD present.39
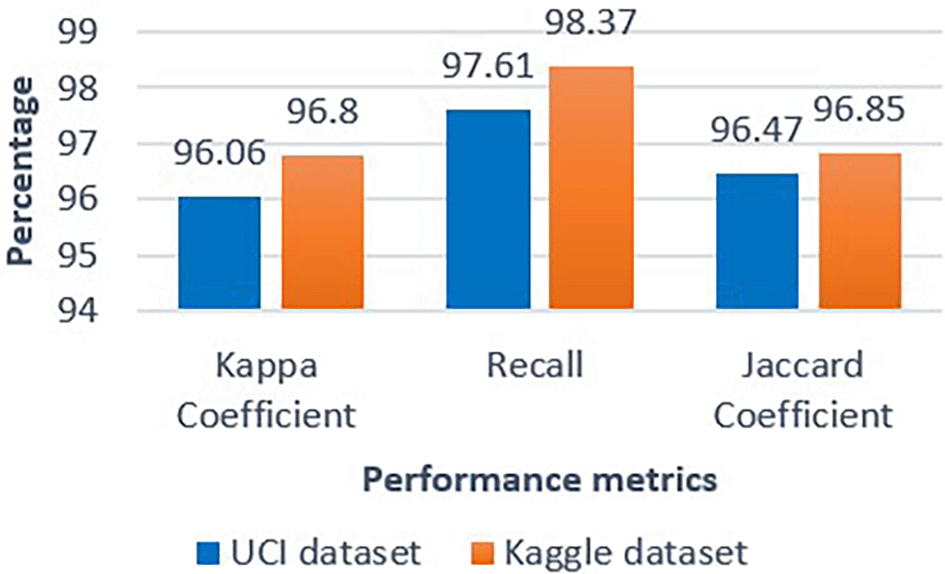
Class 0 = no IHD; Class 1 = IHD present.
While Figure 6 focuses on the performance of the proposed HRAESN model on the two benchmark datasets (UCI and Kaggle), comparative results against baseline classifiers such as Logistic Regression (LR), Support Vector Machines (SVM), Random Forest (RF), and other deep learning models are reported separately in Tables 8 and 9.
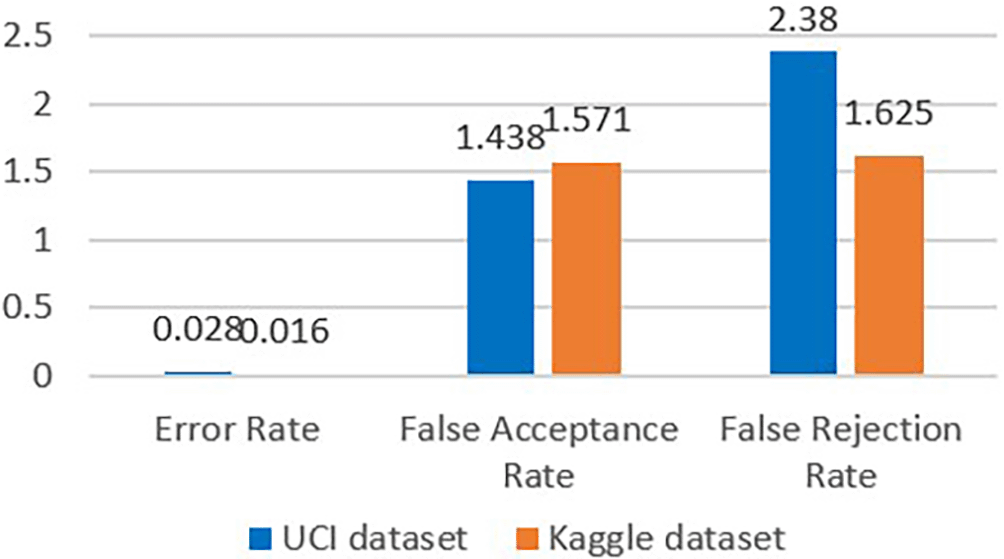
Results are reported separately for each dataset. Class 0 = no IHD; Class 1 = IHD present.
The baseline methods reported for UCI (e.g., RF, MLP, ensembles) and Kaggle (e.g., RF, GB, MLP) differ because prior studies used different datasets. We therefore compared HRAESN to the state-of-the-art methods available for each dataset as published in the literature. Tables 7 and 8 present a comparative analysis between the proposed Hybrid Residual Attention with Echo State Network (HRAESN) model and existing heart disease prediction models. The comparison is based on handling of missing values, classifier types, and accuracy performance across different studies. Unlike traditional models that either delete missing data or use basic imputation techniques, the HRAESN model applies a multiple imputation approach, ensuring data completeness and improving prediction reliability. The results indicate that the HRAESN model outperforms previous approaches, achieving 97.71% accuracy on the UCI Heart Disease dataset and 98.4% accuracy on the Kaggle Cardiovascular Disease dataset. Compared to Random Forest (RF), Gradient Boosting (GB), Multilayer Perceptron (MLP), and other ensemble methods, the HRAESN model exhibits superior classification performance, demonstrating its effectiveness in early ischemic heart disease detection and clinical decision support.
| Study | Year | Handling of missing values | Classifiers | Accuracy (%) |
|---|---|---|---|---|
| Jabbar et al.39 | 2016 | Rows with missing values deleted | RF | 83.6 |
| Verma & Mathur35 | 2019 | Rows with missing values deleted | MLP | 85.48 |
| Latha & Jeeva36 | 2019 | Rows with missing values deleted | Hybrid NB, BN, MLP, RF | 85.48 |
| Tama et al.37 | 2020 | Rows with missing values deleted | Two-tier ensemble (RF, GB, XGBoost) | 85.71 |
| Rani et al.38 | 2021 | MICE Algorithm | RF | 86.6 |
| Proposed HRAESN | 2023 | Multiple Imputation Technique | HRAESN | 97.71 |
| Study | Year | Classifiers | Accuracy (%) |
|---|---|---|---|
| Maiga et al.31 | 2019 | RF | 73 |
| Hagan40 | 2021 | RF, Gradient Boosting | 74 |
| Bhoyar41 | 2021 | MLP | 89.7 |
| Theerthagiri42 | 2022 | Gradient Boosting | 89.7 |
| Uddin et al.43 | 2021 | Hybrid RF, NB, GB | 94 |
| Proposed HRAESN | 2023 | HRAESN | 98.4 |
Figure 7 compares the HRAESN model with Residual Networks (ResNet) and Echo State Networks (ESN) in terms of classification performance. The HRAESN model achieves 0.98, significantly outperforming ESN (0.89) and ResNet (0.75). This improvement demonstrates the effectiveness of combining Echo State Networks with Attention Residual Learning, enhancing feature extraction and time-series prediction. The results confirm that HRAESN provides superior accuracy and stability in ischemic heart disease classification.
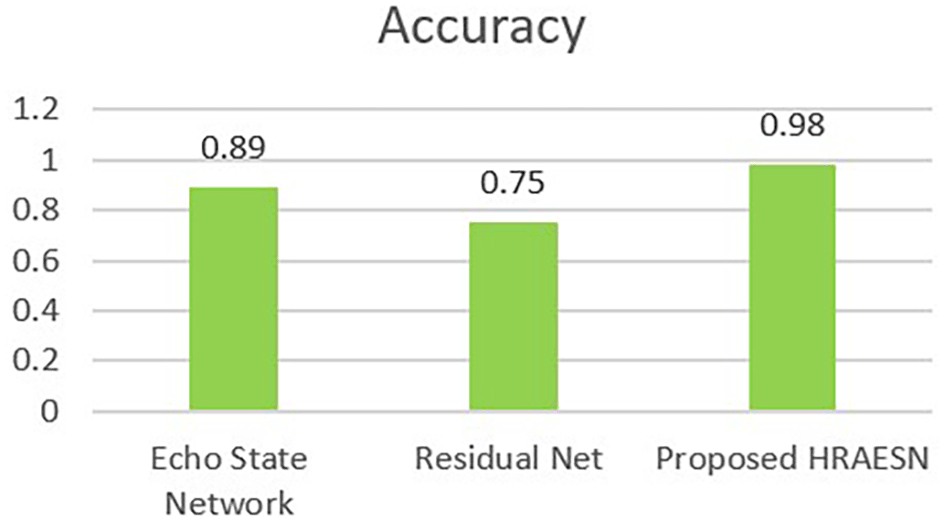
The proposed HRAESN model significantly outperforms conventional machine learning and deep learning techniques in ischemic heart disease classification. It achieves higher accuracy, sensitivity, and specificity, as demonstrated in Tables 7–10. The proposed model exhibits:
• Improved classification accuracy (97.71% – UCI dataset, 98.4% – Kaggle dataset)
• Effective handling of missing data using Multiple Imputation Technique
• Enhanced feature learning through Attention Residual Learning (ARL)
• Better time-series processing with Echo State Networks (ESN)
However, the model has higher computational complexity, which can be optimized in future work. Integrating IoT-based medical devices for real-time heart disease monitoring can further enhance its applicability in healthcare solutions.
This study has some limitations that should be acknowledged. First, the models were trained and evaluated exclusively on the UCI and Kaggle benchmark datasets. While these datasets are widely used in the literature, they do not represent external, real-world populations. The lack of external validation may limit generalizability, and future work should evaluate the proposed HRAESN framework on independent cohorts collected prospectively in diverse healthcare settings.
Second, we employed multiple imputation to address missing data. Although imputation is a standard approach, it may introduce bias, particularly if the missingness mechanism is not completely random. Alternative strategies such as sensitivity analyses or robust imputation methods should be considered in future studies to confirm the stability of our results.
Third, while the incorporation of Attention Residual Learning (ARL) improved predictive accuracy, we did not fully evaluate the interpretability of this mechanism. Specifically, the relative importance of features highlighted by the ARL module has not yet been quantified. Future work should analyze feature attention weights to identify which clinical and lifestyle attributes contributed most strongly to classification. Such analysis could also enable dimensionality reduction by selecting a limited subset of features that maintain comparable predictive performance, potentially improving model efficiency and clinical usability.
Using the UCI Heart Disease dataset and the Kaggle Cardiovascular Disease dataset, the suggested Hybrid Residual Attention with Echo State Network (HRAESN) model has been compared to several Machine Learning (ML) and Deep Learning (DL) techniques for the classification of Ischemic Heart Disease (IHD). The experimental results demonstrate that HRAESN outpaces existing heart illness prediction methods because it achieves accuracy rates of 98.4% on Kaggle data and 97.7% on UCI data. The HRAESN model demonstrates superior performance in terms of sensitivity together with specificity and recall along with accuracy and F-measure according to deep learning model comparisons. The Ischemic Heart Disease Multiple Imputation Technique incorporated within the model succeeds in handling missing values to achieve better data completeness along with improved predictive reliability.
The HRAESN model demonstrated better testing stability characteristics than conventional classifiers thus establishing itself as a dependable instrument for medical diagnosis and clinical decisions. The model achieves powerful medical dataset pattern detection through the combination of Echo State Networks (ESN) and Attention Residual Learning (ARL) features. The future research should work on optimizing the computational operations and integrating IoT-based medical equipment to detect ischemic heart disease in real-time. This approach demonstrates significant value for healthcare improvements by providing early medical diagnosis together with decreased chances of life-threatening cardiac events.
This study did not involve human or animal subjects, and thus no ethical approval was required.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.


Comments on this article Comments (0)