Keywords
Molecular biodiversity DNA barcoding Environmental DNA (eDNA) Whole-genome sequencing FAIR data principles Metadata standardisation Biobanks and specimen collections Biodiversity monitoring in Norway
This article is included in the Genomics and Genetics gateway.
This article is included in the ELIXIR gateway.
This article is included in the Data: Use and Reuse collection.
Molecular biodiversity DNA barcoding Environmental DNA (eDNA) Whole-genome sequencing FAIR data principles Metadata standardisation Biobanks and specimen collections Biodiversity monitoring in Norway
Biodiversity can be broadly defined as the variability of life on Earth displayed at the levels of populations, species, communities, higher taxa and ecosystems. It is widely recognised that biodiversity is currently being lost at an unprecedented rate due to human activity and that we are currently in the sixth mass extinction.1–3 This biodiversity crisis is a grave threat to the health of our planet, and is severely disrupting ecosystem services. Sustainable conservation of biodiversity is therefore key to facing future challenges related to food security, diseases, climate change and human health. Conservation of biodiversity is also important from an ecocentric perspective as species and ecosystems have inherent values irrespective of serving human needs.4 The UN Convention on Biological Diversity has highlighted five direct drivers of biodiversity change: anthropogenic land use, over-harvesting, climate change, invasive alien species, and pollution.3 The relative contributions of these global challenges must also be identified and dealt with at a national level in Norway.
Norway encompasses a wide range of marine and terrestrial ecosystems including deep-sea coral reefs, alpine and arctic tundra, coastal heath, and boreal rainforests.5–7 These ecosystems provide vital services to the Norwegian economy through supporting fisheries, forestry, aquaculture, agriculture and tourism.5 Seafood alone represents 9.2% of Norway’s total export value in 2023.8,9 However, it is important to stress that we do not know which species holds the key to tomorrow’s entrepreneurial endeavours. A good example of this is the discovery of cyclosporine, used to facilitate organ transplants, in a fungus (Ophiocordyceps sessilis) growing on the Norwegian tundra.10 What we do know is that the conservation of biodiversity is key to ensuring robust ecosystems and mitigating the effects of global change.
Effective biodiversity conservation begins with a clear understanding of the species present. According to the Norwegian Biodiversity Information Centre (NBIC, Artsdatabanken), a total of 53,284 valid species names have been recorded across Norway by 2024, including Svalbard, Jan Mayen, and adjacent marine areas (Nortaxa - Norwegian taxonomic register - 2024-08-31). This represents 73.8% of the estimated 72,190 species in Norway, a figure that is likely conservative.11–15 Thus, there still is a considerable knowledge gap about present species diversity in the country. Evaluating the distribution and ecological status of species is naturally challenging as high-quality data points are lacking for many groups. Consequently, less than half (23,405) of the recorded species have been evaluated according to the International Union for Conservation of Nature (IUCN.org) criteria with 4,957 being listed on the national red list of species.13,16 Terrestrial ecosystems are more surveyed than marine ecosystems, and there are more severe knowledge gaps in certain taxonomic groups, such as fungi. This bias is mainly due to how easily we can find and identify them, which depends on available methods and our access to data and knowledge.
Molecular tools have revolutionised how we study biodiversity at all levels and are a fundamental part of modern biodiversity research. Different types of data and methodologies give different levels of resolution in terms of biodiversity (population, species or community) and in terms of genetic resolution (from simple assays to sequencing of entire genomes). An overview of these levels in a Norwegian context is shown in Figure 1. The method of choice is not only dependent on the question, but also cost and feasibility. DNA barcoding involves sequencing of a short, standardised genetic region from individual specimens that can be used to identify and separate species.17 It became a widespread practice in the early 2000s and is now routinely used in taxonomy, ecology, phylogeography, biogeography, conservation, forensics and other nature management applications.18 This technique alleviates challenging morphological identification of cryptic species, undescribed life stages or incomplete specimens,19 provides independent lines of evidence in species delimitation analyses,20 and enables large-scale, cost-efficient biogeographic analyses.21 Advances in DNA sequencing technologies and bioinformatic tools over the past decade have enabled whole genome sequencing and assembly at a relatively low cost, which allows researchers to characterise not only individual species but also look at functional diversity and intra-species variation at a greater genetic resolution than ever before.22 Specimens from museum collections, as well as live or freshly collected individuals, may be sequenced. Sequencing may also be done on microorganisms in clonal cultures, or on single cells of eukaryotic microorganisms such as phytoplankton, giving unparalleled insight into biodiversity previously difficult, if not impossible, to observe.
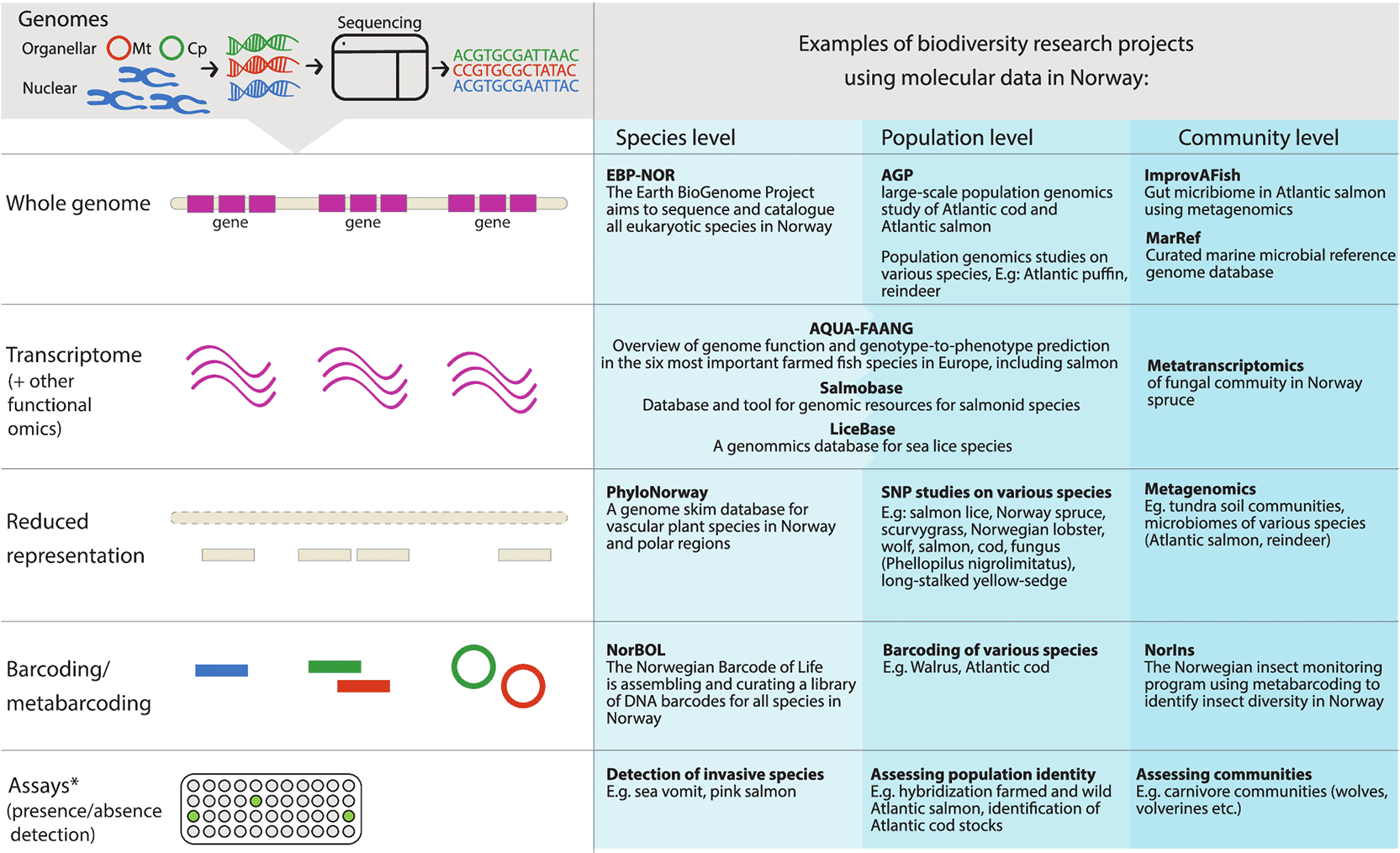
Projects are divided into different levels of genomic resolution, from whole genome sequencing to assays, and different levels of sampling, from single individuals to populations to communities of multiple species. For a more detailed overview see the Extended Data file Institutes, Networks, Projects, Services.docx.
With the increasing genetic characterisation of described and undescribed organisms, the use of environmental DNA (eDNA) to monitor biodiversity is rapidly evolving. eDNA is the genetic material shed by organisms into the environment in the form of free DNA, skin cells, mucous, gametes, or, in the case of microorganisms, the entire individual.23 Sampling of eDNA is normally non-invasive with minor or no impact on the ecosystem and includes a wide range of materials, such as water, soil, air and sediment.24 A single eDNA sample can be used for multiple analyses, for example targeting different taxonomic groups. Metabarcoding, akin to barcoding, refers to the amplification and sequencing of a marker region that can identify up to thousands of species for taxonomic inventory. Furthermore, genetic material from target species may be detected by quantitative or digital PCR. Metagenomics, i.e., sequencing of non-specific DNA in a sample, was originally developed to assemble genomes of un-isolated microorganisms, but is now also included among eDNA tools to provide information on functional diversity in addition to species diversity. Although eDNA dynamics is influenced by a multitude of environmental factors, eDNA methods are considered a promising suite of tools for studying biodiversity.25 However, analysis of eDNA relies on well-curated reference databases containing barcodes or other genetic characterisations of described specimens. Biobanks which facilitate long-term storage of all types of DNA samples, either from single specimens or environmental DNA, are essential for preserving our catalogued genetic biodiversity heritage for the future.26
Norway is at the forefront of implementing molecular tools and data in research and monitoring. For instance, the Norwegian Barcode of Life Network (NorBOL, NorBOL.org) has existed since 2007 and has been a national research infrastructure for DNA barcoding since 2014. Another example is the well-established, real-time genetic monitoring program for estimating cod populations established by the Institute of Marine Research (IMR) for regulation purposes by the Norwegian Directorate of Fisheries.27 Prior reports by the Norwegian Environment Agency have shown broad and interdisciplinary involvements with molecular methods including collaboration between universities, research institutes, administrative agencies and business (Norwegian Environment Agency reports M-2115, M-2062, M-2523). However, these reports focus on monitoring by means of eDNA, with less focus on cross-disciplinary initiatives, particularly whole genome sequencing and best practices in related domains. This makes it difficult to harvest and strengthen the potential of this rapidly evolving technology. Building good research infrastructures to support molecular biodiversity it is paramount to connect tools, data, and people, which entails the identification of significant gaps and needs among these research communities.28,29
In this whitepaper, we present the work and results of ELIXIR’s Norwegian Molecular Biodiversity Working Group – a network of scientists within the field of biodiversity genomics in Norway. Collaboratively we have mapped the community of molecular biodiversity initiatives that use molecular data and methodology in biodiversity research, nature management, education and innovation in Norway. We have also surveyed biodiversity researchers from various domains to reveal current challenges in integrating and utilising molecular biodiversity knowledge, data and resources on a national level. Finally, we present specific recommendations on how to coordinate and shape the future molecular biodiversity research landscape in Norway. Our approach is aligned with ELIXIR’s 2024–28 Priority Area strategies—Biodiversity, Food Security and Pathogens (BFSP) and Cellular & Molecular Research (CMR)—by focusing on federation across communities, FAIR data and standards, and multi-modal/multi-omics integration to enable interoperable analyses.30,31
The group takes the role as a communication hub to address challenges in the actor landscape and their infrastructures related to molecular biodiversity in Norway. ELIXIR’s Norwegian Molecular Biodiversity Working Group was established in November 2022 under the Norwegian ELIXIR3 project. It arose from the need to connect members from the molecular biodiversity research environments across Norway and has representatives from the institutes UiO, UiB, NTNU, NMBU, UiT, NINA, NIVA, and IMR, which also represent the organisations GBIF, NorBOL, ELIXIR, DiSSCo, LTER, LivingNorway, and EBP-Nor. As an open group, it welcomes those who have an interest in or are involved in molecular biodiversity-related work. Our goal is to promote the use of bioinformatics in biodiversity research by promoting the FAIR principles (28) for open, transparent, and consistent data sharing. To achieve this, we need to build and connect strong national infrastructures that support key areas such as biobanks, ecological data, imaging, marker sequences, and genomic resources. These infrastructures are essential for advancing collections, monitoring biodiversity, and generating new knowledge. As a first step, we have mapped the institutions and networks that make up Norway’s molecular biodiversity research landscape, providing a foundation for future development and collaboration.
To obtain insight into the landscape of actors in Norwegian biodiversity we have mapped institutions with an interest in molecular biodiversity and network connections. We have focused on large, broad biodiversity initiatives processing or linking molecular data. Websites of organisations and institutes have been visited during 2024 and early 2025 to collect and verify information about their own stated connections. Additionally, the members of the Norwegian Biodiversity working group have used their knowledge and expertise to verify and update these connections. Based on the collected data we have registered 19 Norwegian institutes expressing involvement in molecular biodiversity and 28 biodiversity networks with the most frequent connections shown in Table 1 (see full list in the Extended Data file Institutes, Networks, Projects, Services.docx, Sheet S1 and S2). Eleven of these have more than three institutes involved as consortium members or with a curator role. We would like to stress that it is beyond the scope and capacity of this paper to exhaustively mention all initiatives and research groups in Norway, but we acknowledge the vital collective contribution from all national biodiversity-related projects.
This index is not exhaustive as smaller teams and contributors are not listed.
National and international networks are hugely important collaborative frameworks that bring together institutions, people and data sources across national borders and fields of expertise. Relative to the research landscape, networks provide the backbone for avoiding duplication. The biodiversity topic constitutes numerous networks at stratified levels on national, European and international scopes. Most of these networks and initiatives do not have continuous funding.
The largest networks mentioned in this work represent international and European origins and operate at a decentralised national level with Norwegian nodes. These include DiSSCo (DiSSCo.eu), GBIF (GBIF.org), LTER (eLTER-RI.eu), IBOL (IBOL.org)/NorBOL (NorBOL.org), EBP (earthbiogenome.org), ELIXIR (ELIXIR-Europe.org), and EMBRC (EMBRC.eu) having centralised hubs representing their core organisations. Infrastructure development and standardisation of data are important drivers in several of these infrastructures for different types of biodiversity data, like digitisation of specimens (DiSSCo), species observations (GBIF), ecological monitoring (LTER), and molecular sequencing data (NorBOL, EBP, EMBRC, ELIXIR, ERGA). Norway is involved in a broad number of biodiversity organisations and thus has influence in the development and direction of global efforts.
Organisations and networks play important roles in driving communities to endorse state-of-the-art standards, protocols and data management. Additionally, networks contribute towards the development and maintenance of robust infrastructures. An example of this is NorBOL, which represents the Norwegian node of iBOL and the national research infrastructure for DNA barcoding. The network is coordinated by the NTNU University Museum in Trondheim and consists of 17 Norwegian biodiversity institutions under a formal agreement to work towards the goal of building a DNA barcode reference library for the Norwegian biota and to further develop molecular tools for species identification. Currently, more than 25,000 species from Norway have sequence data in the barcode reference library BOLD,42 slightly more than one-third of the estimated species in Norway. Another example is EBP-Nor, the Norwegian initiative aligned with EBP.36 EBP-Nor is a collaboration between major universities in Norway (UiO, NMBU, UiB, NTNU, Uni Nord, and UiT), the research institutes SINTEF and NINA, and the non-academic institutions REV Ocean, The Life Science Cluster, and ArcticZymes Technologies. The goal of this initiative is to catalogue the entire genome of all eukaryotic species in Norway, estimated at 45,000 species. In the current pilot phase, ~150 species have been completed. Further examples include the Nansen Legacy (arvenetternansen.com), LivingNorway (livingnorway.no) and Norway’s contribution to the Nordic Microalgae (nordicmicroalgae.org) initiative led by the Swedish Meteorological and Hydrological Institute. The Nansen Legacy was a 6-year, large-scale, holistic Arctic research project covering a wide range of biodiversity operations in the polar and arctic regions, but the contribution of molecular data was limited. Also national and hosted by NINA, LivingNorway is a network focused on the FAIRification and sharing of ecological data through its portal and collaboration with GBIF. Collectively, LivingNorway and GBIF provide several entry points for tools and training in the ecology and taxonomy part of biodiversity research. GBIF provides global coordination across regional and national infrastructures, including recent prioritised development for metabarcoding and other molecular biodiversity data.
The use of molecular data and tools has transformed biodiversity research and monitoring in Norway, enabling new insights into the genetic composition and ecological dynamics of species and ecosystems. However, several challenges hinder the effective utilisation of these resources. To evaluate the scope and nature of these challenges, we conducted a survey for biodiversity-related researchers across Norway.
The survey design process was initiated in 2023 based on feedback and suggestions from the ELIXIR Molecular Biodiversity Working Group and targeted the topic of data management. Some of the questionnaire concepts were inspired by the BioMedData gap analysis.43,44 Fifty-eight questions (Q) were designed to cover 8 categories: 1.) Administrative details, 2.) Pre-existing data, 3.) Data collection, 4.) Processing data, 5.) Preserving data, 6.) Taxonomy, 7.) Privacy of the data, and 8.) Final reflections. Items for the questionnaire were added by members of the biodiversity working group and went through several rounds of review. Where appropriate, controlled vocabularies based on DataCite45 were used to limit the number of free-text questions. The questionnaire was finally implemented in the Norwegian form system Nettskjema (Nettskjema.no) in January 2024 and opened for responses the following February 18th. Notifications were sent out via working group members to national biodiversity networks and included, among others, NorBOL, NHMO, The Norwegian Veterinary Institute, The Arctic University Museum of Norway, GBIF Norway, NINA, NIVA, NTNU and EBP-Nor. The form was open for responses for 3 weeks until March 8th, receiving in total 58 responses (Appendix 2 and 3). The form did not collect any personal information, allowing any respondent with the form link to answer and submit.
Norway’s national strategy for biodiversity data management prioritises adherence to the FAIR principles, emphasising the need for open, standardised, and reusable data. Key stakeholders, including the Research Council of Norway and the Norwegian Environment Agency, have embraced these principles, embedding them into funding policies and guidelines.46,47
In our survey, 60% of the respondents were familiar with the FAIR principlesQ6, while only 29% consistently made their data fully open or FAIR-compliant upon publicationQ49,50. This can originate from a lack of organisational focus or legal constraints, often due to resource limitations and highlights a gap between awareness and implementation of the FAIR principles. To FAIRify data, raw data must be linked to the correct metadata, and – if possible – to a physical specimen. Many researchers aim to publish their data and metadata in repositories such as GBIF or BOLDQ40. However, researchers often find inconsistencies and a lack of links between contextual metadata and physical specimens to be a significant challenge. Markedly, 38% of respondents to the survey do not link datasets with physical specimensQ38. This issue coupled with legal concerns or privacy restrictions, can delay data sharing and compromise data qualityQ49,50. Taxonomic assignment of database entries additionally poses a recurring challenge, with nearly 40% of respondents reporting frequent difficulties in assigning correct labelsQ45 ( Figure 2). This likely illustrates that identification of biota in many cases is far from trivial and also that there are inconsistencies in name use across major databases such as BOLD, GBIF, WoRMS (marinespecies.org) and ENA/NCBI (ebi.ac.uk/ena, ncbi.nlm.nih.gov). Discrepancies like these undermine the reliability of taxonomic species data, which is fundamental to biodiversity assessments.48
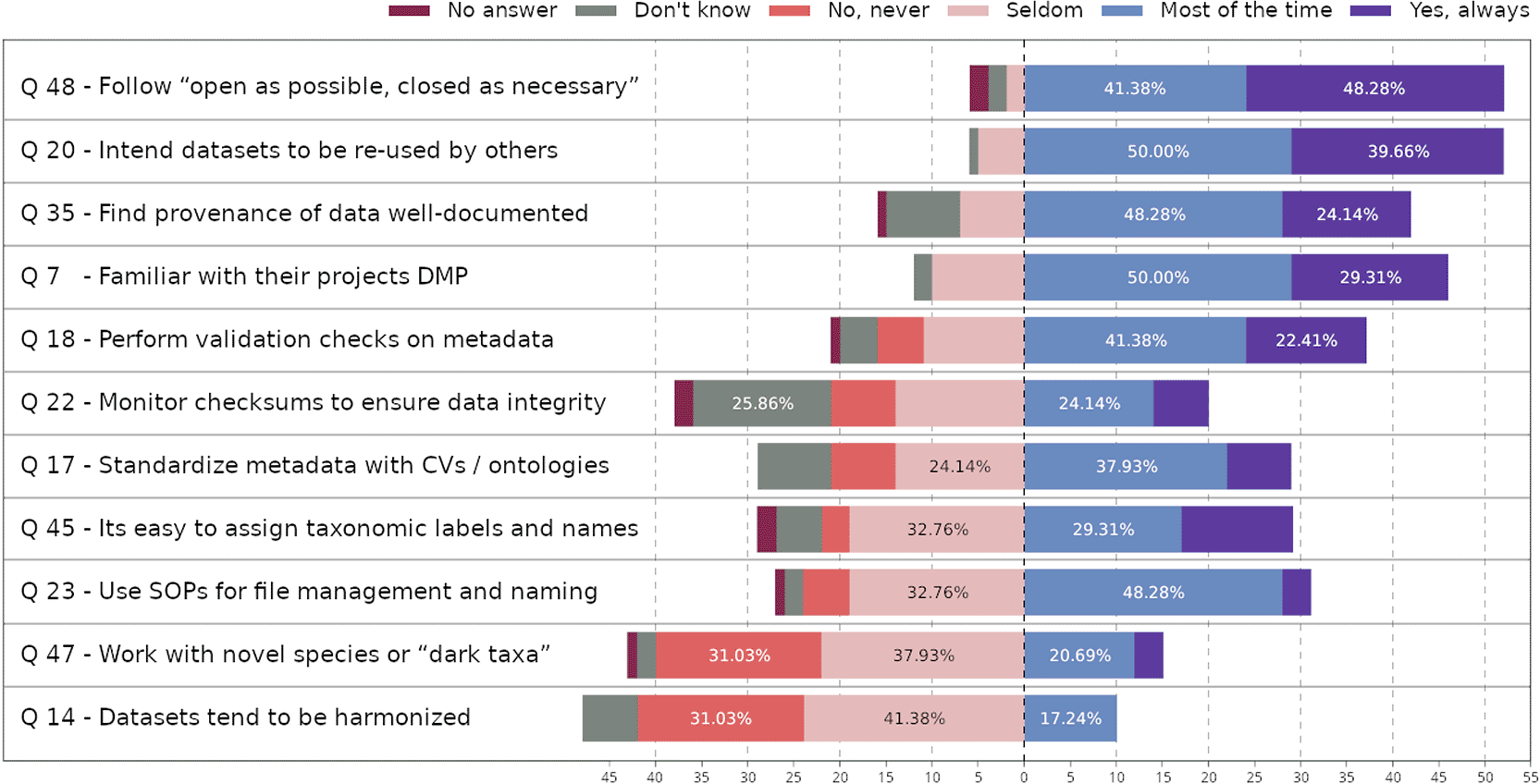
Note that the questions have been shortened to fit the figure. For all details see the Extended Data file Survey report - Nettskjema.pdf.
Despite the large volumes of sequencing data generated annually, roughly half of the respondents reported using standard operating procedures (SOPs)Q23 and monitor checksums for file and data managementQ22 ( Figure 2). This gap can limit the efficiency and reproducibility of research, representing a missed opportunity to optimise data workflows. Although many projects generate substantial dataQ29, only 22% of respondents consistently validate metadataQ18. FAIR metadata curation is also a specialised skill, requiring institutions to employ data stewards with the required know-how.49 The lack of rigour in ensuring metadata accuracy creates a significant disconnect between data collection efforts and their potential utility, diminishing the value of large datasets for future research and applications.
The results point to the urgency to improve multiple facets of general data management such as adherence to FAIR principles, standardised workflows, and robust and easy-to-use metadata validation processes. Some challenges can be addressed by using third-party brokers to improve the consistency of published datasets, however, only 4% of respondents reported to have used any form of brokering serviceQ42,43. Still, the FAIR principles should not only apply to the downstream data resulting from molecular analyses but also to the samples and specimens which these analyses originate from. It is therefore crucial to improve the practice of researchers and institutions for depositing research samples in publicly accessible biobanks. Such samples are reference material for completed research, ensure reproducibility, and have the potential for new usage in future research if they are made available.50 A related shortcoming is the lack of connections between the original samples and the downstream molecular data. This can be rectified by the consistent use of unique identifiers for the material samples.
The survey aimed to get an understanding of how scientists work with data and datasets already existing in Norwegian institutions as well as in published records of various online databases. Information and datasets in sources like GBIF, ENA, BOLD, Artsdatabanken/NBIC, and biobanks are essential for conducting comparison, classification, and other downstream data analysis. How scientists perceive the application, ease of use, and interoperability are of great interest.
A majority (90%) of the respondents reported using pre-existing published datasets for taxonomic classification and the annotation of features, such as genesQ10. However, only 41% of respondents found it easy to locate relevant molecular biodiversity data for their projects ( Figure 3)Q8a. This illustrates a challenge since researchers rely heavily on pre-existing data for reference and comparison. The difficulty may arise from a combination of factors like missing data for specific taxonomic groups, fragmented or discontinued online resources, or inefficiencies in data discovery tools. For example, 32% of the respondents struggled to locate appropriate sequence databases for their research, pointing to limitations in database coverage or search functionalitiesQ13.
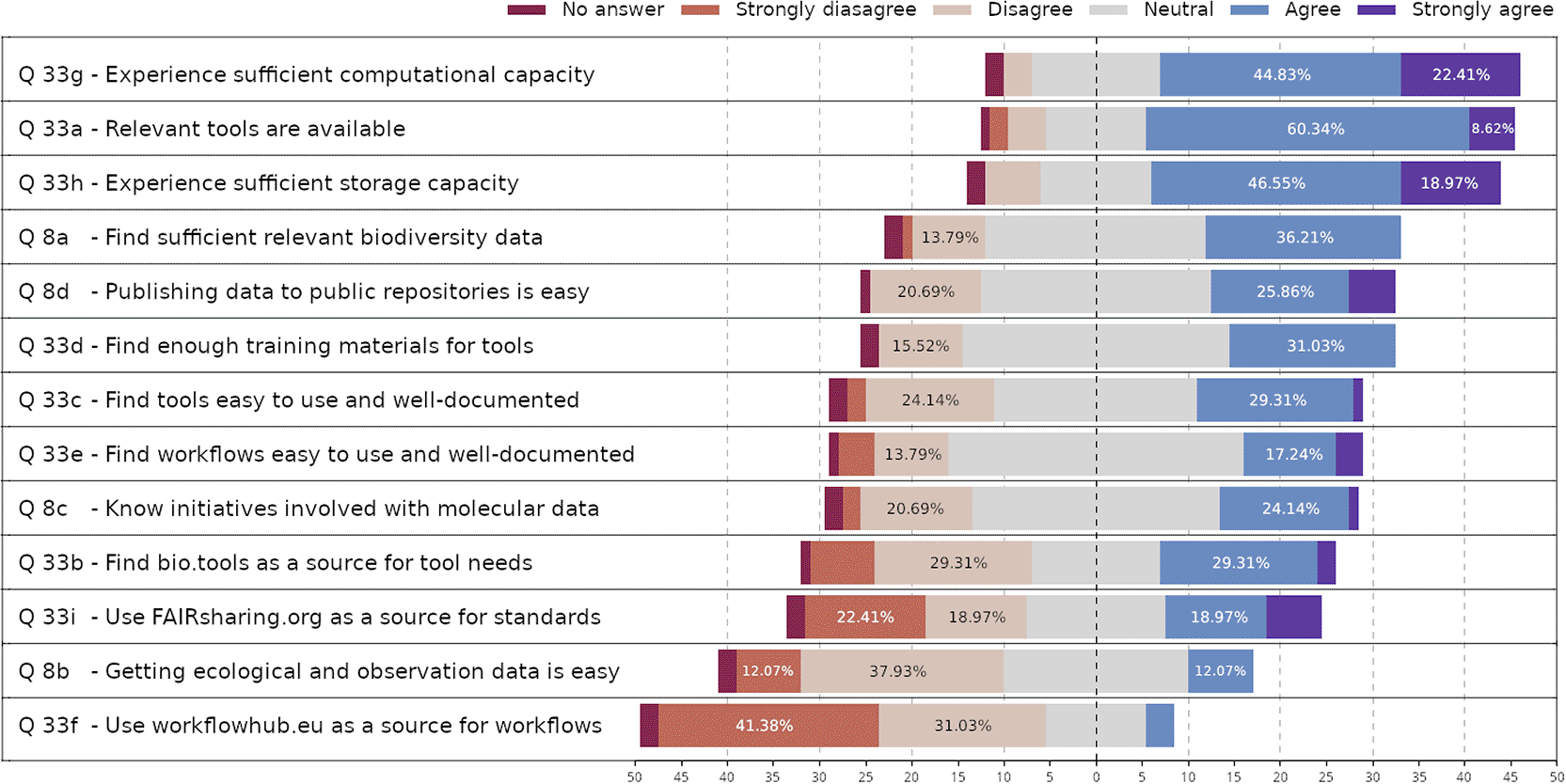
Note that the questions have been shortened to fit the figure. For more details see the Extended Data file Survey report - Nettskjema.pdf.
A notable 54% of the respondents considered insufficient metadata in published databases a challengeQ13. This poses a barrier when reusing molecular data. Challenges in navigating inconsistent annotations and formats further complicate efforts as 72% of the respondents most often need to perform harmonisation on combined datasetsQ14. The lack of harmonized data standards, especially when combining molecular and ecological datasets, amplifies these issues. Consequently, the EBP seeks to enforce that the GBIF Darwin Core standards are applied for its samples.51 Providing harmonised data has significant economic and time-saving benefits to the research community as exemplified by the Deloitte report on GBIF return on investment.52 Almost 40% of the respondents reported they only include the minimum required metadata when publishing their datasets, and only 35% find publishing their data easyQ41,8d. Consistently providing minimal metadata is a way to perpetuate a growing information gap of unpublished or paper-locked vital metadata. This practice undermines data reusability, often forcing researchers to spend additional time seeking further details from publications or directly contacting authors.
Despite the challenges, most respondents rely on existing datasets, underscoring their critical importance for molecular biodiversity research. However, fewer than 30% of the respondents had a good overview of initiatives using molecular data in NorwayQ8c. This suggests a lack of cohesion within the research community, limiting opportunities for collaboration and cross-disciplinary integration. In addition, the disconnect between molecular datasets and associated ecological or observational data was a recurring concern as several respondents noted difficulties in obtaining ecological datasets relevant to their molecular studiesQ8b. This gap highlights the need for improved interconnectivity between molecular data and broader ecological contexts, enabling more comprehensive and holistic analyses.
Only 34% of the respondents found it easy to publish their data in public repositories like ENA, BOLD, or GBIFQ8d. ENA is often perceived as particularly cumbersome for dataset deposition. The fact that most researchers do not find data publication straightforward suggests persistent barriers to data deposition, including the complexity of submission processes, technical constraints, or a lack of institutional support. These obstacles discourage the provision of complete and well-curated datasets, perpetuating challenges in data accessibility and reuse, and highlight (again) that FAIR data curation and publication is a specialised skill that often requires dedicated data steward roles to be delivered.49
On the topic of pre-existing data, the survey results indicate a necessity of addressing key bottlenecks in data availability across hosting institutions and services. Improving metadata standards, enhancing the discoverability of taxonomic and ecological datasets, as well as seeking collaboration across research domains are key points to breaking the negative cycle towards the issue of insufficient metadata.
Effective data analysis and robust technical infrastructure are critical to advancing molecular biodiversity research in Norway. The survey addresses the current status of scientists’ access to tools, computation, and storage.
While 70% of the respondents report having a good overview of tools in their field, and with 74% generating molecular dataQ15, only a small fraction is familiar with platforms such as bio.tools (32%) or workflowhub.eu (5%), which are designed to facilitate the discovery of relevant tools and workflowsQ33. There is a clear distinction between basic biodiversity research, which often requires the latest or custom-developed tools, and applied research, which prioritises standardised methods to ensure consistency and enable long-term comparisons.53 Notably, only 17% of the respondents are involved in tool development, while applied research increasingly relies on the availability of well-documented tools and workflowsQ34. Only 32% of the respondents agree that tools are well-documented and user-friendlyQ33. Despite many respondents being neutral, indicating confusion, or lack of interest or care for the topic,54 this gap is a barrier, limiting the adoption of suitable methods and potentially reducing the impact and reproducibility of research.55–57
A majority of the respondents (69%) report using computing clusters for data analyses, but a substantial portion (65%) also rely on local machinesQ30. While local machines provide conveniences such as local backups, they carry risks such as potential data loss, lack of scalability, and difficulties in sharing data among collaborators.58 On the other hand, 77% of the respondents’ store data in shared environments accessible to relevant users, indicating progress in adopting collaborative data stewardship practicesQ32. Despite this, there is a noticeable reliance on local infrastructures (60%) for high-performance computing and data storage while national infrastructures, such as Sigma2 (48%) and NeLS (26%) are less commonly usedQ31. National infrastructures provide a significant boost in ensuring consistency, scalability, and secure collaboration across institutions. We believe that encouraging the adoption of national infrastructures could address gaps in standardising practices for computation and data stewardship.
Most of the respondents (43%) require more than 1 TB of annual data storage, with 12% needing over 10 TBQ29. In the latter case, infrastructures like Sigma2 and NeLS/StoreBioinfo provide free storage up to 7 TB and 10 TB per project, respectively, with additional storage available for an additional fee. Only 11% of respondents reported insufficient temporary storage during their projects, suggesting that current storage provisions meet most researchers’ needsQ33. However, projects with exceptionally high data demands (exceeding 10 TB) may struggle due to funding constraints or lack of awareness of available storage options.
Highlighted in these points are awareness gaps related to tool documentation, infrastructure adoption, and national data-sharing frameworks. These challenges indicate the need for improved training and awareness of these infrastructures supporting FAIR-aligned data practices. There are also uncertainties to how data can be effectively shared between private and academic institutions and with international non-Norwegian project partners.
In order to keep up with the latest technology, methodology and requirements in an interconnected field like molecular biodiversity, it is crucial to have access to knowledge at all levels. Sometimes technical development is so fast that we are bound to use tools and methods with poor documentation.53,59 The flipside of this is that tools are published in a more transparent and easy-to-use way (through eg. GitHub, Nextflow/nf-core, WorkflowHub, Bio.tool etc.) than previously, often as workflows making FAIR analyses much easier to conduct. This might alleviate the need for extensive documentation. Through these established platforms we can enhance sharing experiences and provide training to ensure that scientists do not have to reinvent best practices and provide higher quality and speed of analyses. However, only 32% of the respondents reported sufficient availability of training material for new tools they want to learn, indicating training materials tend to lack convenient access or that researchers are not yet aware of many of the resources out thereQ33. Better knowledge of data management and stewardship would have a positive impact on the usage of current storage and computational resources, emphasising the need for training in data handling.60
Course material is not always accessible outside events and may not be free of charge. The interest in open training programs and the need for local and national expertise, particularly towards taxonomic knowledge, is frequently commented on in our survey ( Figure 4)Q57. Training material across the molecular biodiversity field tends to be scattered and not easily accessible through a common hub. Some established networks manage protocols and maintain updated training material relative to their scope. At the international level, this includes the EBP Best Practice Guidance,61 ERGA Knowledge Hub,62 ELIXIR TeSS,63 GBIF Training courses64 and iBOL Europe’s Resources65 online. At the national level training material is to a larger degree separate and distributed as course or workshop material. Notable contributions are given by EBP-NOR66 and ELIXIR Norway.67 The availability and accessibility of training materials play a crucial role in enhancing the quality of analyses and research, yet significant gaps remain. Continued efforts to centralise and share resources, both locally and internationally, could lead to more effective and efficient scientific progress.
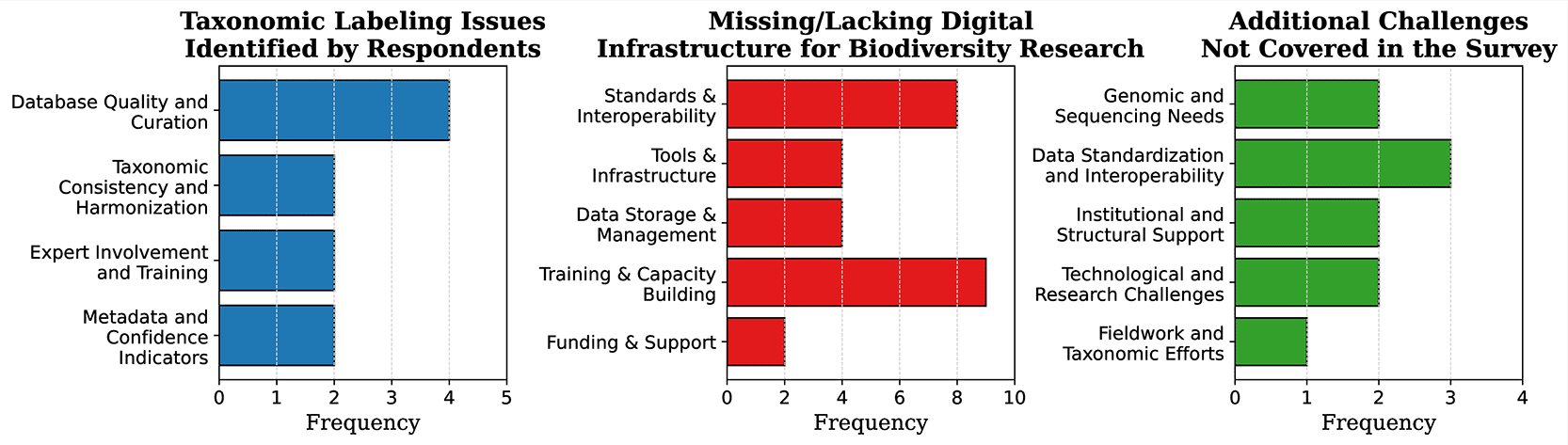
A full list of answers and with coding and content analysis can be found in the Extended Data file Survey report - Text answers.xlsx.
Working with biological samples and genetic data presents several legal challenges, both at the national and international level. These were not addressed in our survey but are discussed here as they certainly are relevant to Norwegian molecular biodiversity research and monitoring. In Norway, the use of genetic resources from other countries is regulated by the Nature Diversity Act/Naturmangfoldloven which ensures compliance with international treaties such as the UN Convention on Biological Diversity (CBD) and its Nagoya Protocol on Access and Benefit-sharing (ABS). The use of genetic resources obtained in Norway is not regulated by the Nature Diversity Act directly, but can be governed by other laws depending on the protective status of the species, habitat or geographic area, and takes genetic resources that are coupled to traditional knowledge in native or local communities into account.68 At the sixteenth CBD Conference of the Parties (Nov 2024), it was decided to operationalise a multilateral mechanism to ensure fair and equitable sharing of benefits from the use of Digital Sequence Information (DSI). DSI refers to digital data derived from the sequencing of genetic resources, such as nucleic acid sequences (DNA, RNA), amino acid sequences (proteins), and possibly related information like gene expression data or epigenetic markers. Although details in the mechanism are still to be worked out, it is clear that fair and equitable sharing of DSI originating from organisms obtained across borders will be even more important in the future. The discussion around access and benefit sharing of DSI has raised questions about ownership of genetic sequence data and the definition of genetic resources, as data can be easily shared and used globally.69 The CARE principles—Collective benefit, Authority to control, Responsibility, and Ethics extend the FAIR principles to strengthen Indigenous data governance, ensuring that genetic data management respects local communities’ rights.70 The Norwegian Environment Agency is the Norwegian Focal Point for guidance on the ABS regulations, registration of the use of genetic resources on material collected abroad, and contact point for information on the use of genetic resources from biological materials collected in Norway.71,72 Many researchers find it difficult and time-consuming to navigate these regulations and know where to seek relevant information, but the Norwegian Environment Agency has informative web pages on this topic and are readily available for questions.
To secure long-term funding and supportive policies that ensure continuity, innovation, and impact in the molecular biodiversity sector in Norway, we propose the following recommendations as four pillars. These are based on the group’s expert insights across multiple biodiversity domains, the mapping efforts, and survey results carried out by the group. These pillars directly map to BFSP objectives (Federation, FAIR Data, Analysis, Standards, Training) and support CMR goals to capture analytical workflows, strengthen data stewardship and interoperability, and promote trustworthy, FAIR AI/ML services.
Objective: Build seamless links between molecular data, ecological data, specimen collections, and biobanks to unlock the full potential of national biodiversity resources.
Actions:
• The Norwegian government should provide funds to develop nation-wide biodiversity biobanks with government-mandated responsibility to maintain these collections with unimpeded access for science.
• The Research Council of Norway (RCN) should demand that all samples collected in projects funded by them:
Objective: Ensure Norwegian biodiversity data is high-quality, interoperable, and aligned with international standards.
Actions:
• The Research Council of Norway (RCN) should enforce standardised data and metadata protocols across all national platforms (e.g., using Darwin Core (DwC), Minimum Information about any (X) Sequence (MIxS) and protocols.io) and require all publicly funded projects to include data-sharing and interoperability plans in their grant applications.
• Incentivise and reward data sharing and curation work, following NOR-CAM73 and DORA recommendations.74
• Fund data steward positions at biodiversity research institutions to ensure quality and accountability.
Objective: Foster collaboration across research groups, infrastructures, and disciplines to break silos and build a unified national network.
Actions:
Norway is at a critical moment in its efforts to address the biodiversity crisis by integrating molecular tools and data. In this work, Elixir’s Norwegian Molecular Biodiversity Working Group has provided insights into the current landscape situation, identifying strengths, gaps, and opportunities within the national molecular biodiversity research. While Norway has made significant contributions to methodologies such as DNA barcoding, environmental DNA (eDNA), and genome sequencing, challenges remain in data accessibility, standardisation, and broader integration of molecular datasets with other data types like genomic, ecological, collections and biobanks. To fully leverage these advancements, coordinated efforts are required to build and strengthen national infrastructures, bring together collaboration across institutions and networks, and adhere to FAIR principles for data sharing. By addressing these challenges and implementing the recommendations outlined in this whitepaper, Norway can position itself as a global leader in biodiversity research and conservation, ensuring robust interdisciplinary ecosystems.
Our study is based on an anonymous, voluntary survey of researchers working with biodiversity in Norway. The survey was conducted using Nettskjema (University of Oslo), a secure platform designed for data collection that does not store directly identifiable personal data. No sensitive personal data were collected, and participants could not be identified from their responses.
In accordance with Norwegian regulations and institutional guidelines, studies involving fully anonymous survey data that do not process personal or sensitive information do not require prior approval from a Regional Committee for Medical and Health Research Ethics (REK) or equivalent IRB. Therefore, formal ethical approval was not required for this study.
Participation in the survey was entirely voluntary, and informed consent was obtained from all participants prior to participation. Specifically, participants were provided with information about the purpose of the study, the anonymous nature of the data collection, and their right to withdraw at any time before submission. Consent was indicated by voluntary completion and submission of the survey (i.e., implied consent).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)