Keywords
Open Science, Heliophysics, Models, Numerical Simulation Software, FAIR
This article is included in the Research on Research, Policy & Culture gateway.
This article is included in the Bioinformatics gateway.
Open Science, Heliophysics, Models, Numerical Simulation Software, FAIR
The computational modeling community in Heliophysics is at the beginning of a cultural shift towards Open Science, following in the footsteps of other larger science modeling communities. Signs of this shift include a small but increasing number of codes becoming open source, select groups now offering educational workshops where using computational models and their outputs are featured, and an increasing concern for the lack of reproducibility of relevant models attempting to transition from use in applied research to implementation into forecasting operations and other decision-making processes. However, not every model can be funded to completely satisfy the principles of Open Science. Models of multiple software components and those requiring input data with pre-processing steps, whether for training AI models or otherwise, face more complex challenges in their shift to Open Science due to the additional documentation needed to explain the typical process. At the simpler end, even opening up code to be openly available to the community requires effort such as code clean-up and licensing. The challenges faced could be addressed by increased support from infrastructure, such as file format and metadata standardization complemented by increased collaboration with commercial technologies to simplify reusability, but these changes alone are not sufficient. The infrastructure supporting these efforts has critical gaps that confound the best efforts to improve model evaluation, research transparency, and funding stability. Analyzing these gaps from the perspective of Open Science with some consideration of what is realistically achievable will shed light on what a new prioritization system and its supporting infrastructure could look like. Now is the time to prepare for a full shift towards Open Science in modeling, and we must understand what that requires.
Although this study focuses on computational models in the text, the same tiering system can be used for AI models. Standardized documentation, metadata supporting tracking and citation, open collaboration, and other open science practices referenced below are also important characteristics of models developed using machine learning or artificial intelligence tools. The specifics of the standards in each case, particularly the structure of the standardized documentation (e.g., Edmunds et al. 2026) and related assessment methods (e.g., Sherpa et al. 2024), likely differ, but the high level needs are the same. The higher the intended impact of the given AI model, the more open, FAIR (Huerta et al. 2023), and standardized the model should become to support those goals.
This study builds on the growing international conversation of Open Science (e.g., UNESCO’s Recommendation on Open Science, recent changes to US agencies’ policies regarding Open Science, and various ongoing discussions and outputs in the Research Data Alliance and the Research Software Alliance) (UNESCO 2021). We incorporated inputs from the modeling community sourced from the 2024 Software for the NASA SMD Workshop Report, the 2024 Solar and Space Physics Decadal Survey, The Developing Heliophysics Standards and Cross-science Collaborations Workshop Report, attendees of the 2024 Jack Eddy Symposium, the Open Modeling Foundation, and other modeling community members both in Heliophysics and in closely related sciences. Consequently, this work holds firmly to a few guiding principles:
• Resources supporting scientific results or capabilities must be fully reviewable by the community without gatekeepers, including the software and processes used, to be considered as minimally open.
• Transitioning to Open Science practices must be a funded effort.
• Open Science is not a binary status, it is a spectrum of characteristics.
• Improving a resource’s location on this spectrum should always be desired but is not always useful.
• New types of infrastructure support and collaborations are needed to make open science easy.
The new tiering structure presented here was developed based on aspects of model evaluation, execution, and openness, prioritizing the feedback from modelers, operations staff, and scientists involved with computational models (Ringuette 2026).
One main activity of the science model user community with lacking infrastructure support is model evaluation. Model evaluation differs from model validation in that it allows for the community to determine a model’s usefulness for a given application, or fitness for purpose, such as predicting trends in an event’s intensity without accurately predicting the intensity, whereas model validation presents a much higher and typically unsurmountable barrier, requiring a model to correctly predict a given event with a given accuracy. The processes associated with both methods are similar historically, typically consisting of a series of peer-reviewed publications, each describing what models were compared, why they were chosen, a high-level description of how they were run, what observational data the outputs were compared to, and ideally the calculation of several metrics, including process-oriented metrics, and quantifying those comparisons (e.g., Bennett et al. 2013 and Maloney et al. 2019). In some cases, the predictions are compared with the later observed events and the relevant metrics calculated. However, the critical details needed to check the results are typically missing, such as version-specific software citations, open sharing of the code, all ingested and produced data with pre-processing steps described, standardized model documentation, and analysis details remain missing from these publications and comparison interfaces (e.g., Community Coordinated Modeling Center’s Space Weather Database Of Notifications, Knowledge, Information (CCMC’s DONKI)2), preventing proper tracking of model performance over time and the replicability needed to build community trust. As a result, it is rarely possible to distinguish between the performance of the full model run on fully capable machinery as compared to other configurations, which in turn negatively affects the reputation of the model and potentially the funding prospects of the associated model developers. Performance tracking and replicability are especially necessary for models working towards implementation in forecasting operations, but even publications including the simplest models in their analyses suffer when the basic trackable details of the modeling workflow are neglected.
By excluding the components necessary for others to fully understand or ideally replicate the published results, the research and forecasting communities could potentially (unintentionally) confuse the performance history of the model software with unexplainable performance metrics, particularly when the creation process is not ideal. With these critical details missing, the model research community cannot understand how the performance variations observed between different code versions of models and analysis software are related across multiple publications. Additionally, the practice of citing only the modeling software’s reference publication and not the specific version fails to give proper credit to the research software engineers (RSEs) who contributed to the software and were not included as authors on the model’s reference publication.3 Funders - the most critical piece of infrastructure - determine which model software should receive funding and at what level, but are faced with a convoluted landscape of information on model software capabilities, widely varying evaluation metrics across unspecified versions and implementation variations, and lacking information on the software and hardware infrastructure the available model softwares critically depend on. Without this information, funders lack the clarity needed to guide their decisions, which can result in funders preferring new and more exciting model software proposals rather than existing models that may be more capable. This confounds well-intentioned efforts and recommendations to improve modeling software and prediction capabilities, stabilize the recruitment and retention of RSEs in Heliophysics modeling, and improve the model evaluation process and the related research-to-operations-to-research feedback cycle (NASEM 2024). Determining clear paths forward in these challenges are difficult everywhere, but are expected to gain clarity through incorporating open science practices and existing international standards in a tiered approach.
Models created by the computational modeling community range widely in complexity. On one end of the spectrum, empirical models can be easily and quickly executed on a personal computer or laptop, often through a Python program wrapping the original code (e.g., pyIRI2016, Ronald 2017; and those available through SpacePy, Morley et al. 2024). Other models require the structure of a specific high performance computer such as Derecho at NCAR4, with many models existing between these two extremes. As a model increases in complexity, it becomes more difficult for users outside of the modeling group to use or execute the model, thus increasing the likelihood for the misapplication of the software to a given research or forecasting question or even more simply a misinformed execution of the code (Meier et al. 2025). Containerization technologies have eased the difficulties for models of lower complexity, but not for computations critically dependent on machine structure or design. Laudable efforts exist to create documentation directed towards this challenge (e.g., the documentations for the Space Weather Modeling Framework5 and Kaiju6 models), but gaps remain. A standardized documentation structure adaptable to the complexity of the model is needed alongside access to the computational infrastructure required. Some infrastructure is publicly available for model users to obtain permission to execute the more complex software for themselves (e.g., NSF ACCESS7 and NASA’s NCCS8) but is often oversubscribed.
The currently implemented solution in Heliophysics is for a small team of scientists to execute a large number of models for the research community. However, based on the community comments in the appendix, this solution imposes significant negative impacts on the modeling community (Ringuette 2026). These negative impacts include incorrectly citing the full model version in model evaluation and performance analysis efforts when a less capable version was used, insufficient communication between modelers and model users, limited flexibility and understanding of model execution, and difficulty in discovering relevant models. Although this approach has been needed in previous decades when the majority of modeling codes were closed, we now stand on the cusp of a new era of open modeling, which is in line with the global traction of the FAIR principles in data science. It is time to transition from this outdated practice to a richer, healthier community that works together to understand and execute the models themselves, increasing the distribution of knowledge, closing the currently broken feedback loop between the model users and developers, and improving the recruitment and retention of RSEs (see Figure 1).
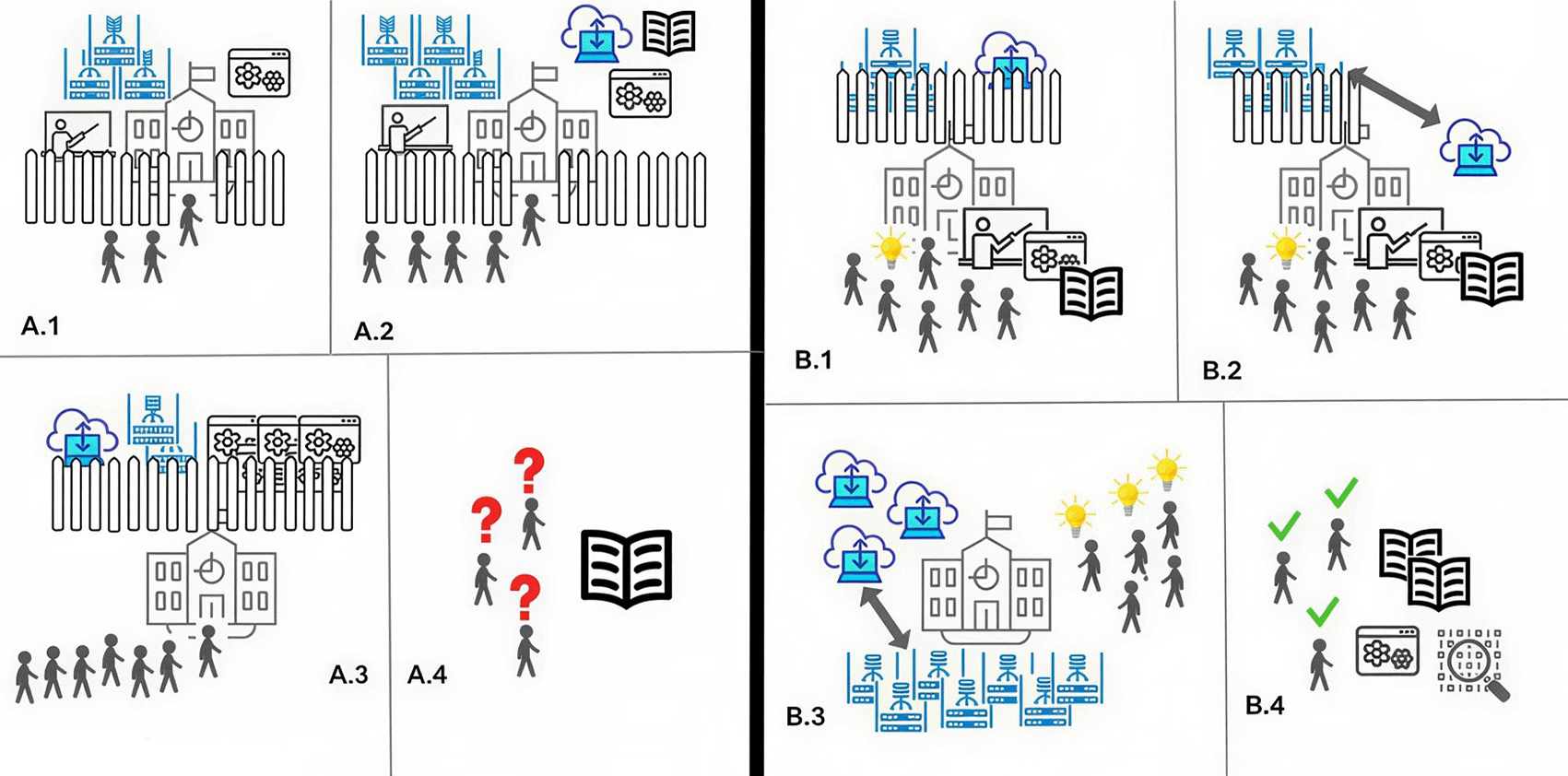
In the current structure, modeling institutions typically have their code and computing closed to the community as shown in A.1 and A.2, teaching only those in their groups how to use them. Those with more resourcing may also have documentation and cloud computing infrastructure, but these are also typically closed to the community (A.2). To compensate, the current approach is to collect all closed modeling codes at an institution with access to cloud and some computing capabilities and run those codes for the community (A.3). As a result, the community has little or no knowledge of the codes used to produce scientific results or how to run them properly, and so can only review related peer-reviewed publications in an incomplete manner (A.4). The proposed next phase is a much more open approach, shown at right, where modeling institutions have their code and standardized documentation in the open and teach the community how to use their modeling codes and interpret the result properly (B.1 and B.2). Computing capabilities at these institutions may necessarily still be closed, but a transition to hybrid (e.g., cloud platforms built on HPC systems) computing approaches can open this up further (B.2). In this structure, the community then applies their knowledge to run the modeling codes for themselves at computing centers with community access (e.g., NSF’s facilities) with support from the communities of practice formed around those models (not pictured) (B.3). This more educated and connected community then has the knowledge to properly review not only the published result, but also the modeling code, standardized documentation, and produced data in support of those scientific conclusions.
At the root of these and related challenges lies the need for model openness, which is relevant for models of all intended impact levels and scopes. The modeling community finds itself at a pivotal point in its history, a shift from openness on the concepts in a model communicated in scientific papers to the openness on the technical implementation of that model in open source software. This also comes at a time of increased technical specialization of modeling groups in the form of RSEs and an emancipation of RSEs from the depths of the community. On the other hand, partially opening up by sharing example datasets, less capable versions of the models, or limited documentation or training opportunities results in increased miscommunication and misuse of the models. A full transition towards model openness is needed to promote proper and expanded use of these valuable resources.
The various efforts cited in this work communicate the critical need for funders to incentivize the transition from closed modeling codes to open-source software and their continued improvement and maintenance, with recent examples of models that would not be open-source today without the associated incentive from funders (e.g., Caplan et al. 2025 and Wiltberger et al. 2025). Although the modeling community is making progress in making their code openly available for others to view, this step is not enough to fully participate in the rich discourse of research and innovation. First, offering access to view the modeling code is an important part of understanding the model (Peng 2011), but is only part of the workflow needed by other researchers to understand the result. For more complex models, the workflow needed to be shared includes the input data, scripts used to process that data, the modeling code, the created data, the scripts used to analyze that data, the final data result, and the documentation and explanation needed for a researcher to understand the process and its implications on the final result (e.g., Meier et al. 2025). Simpler workflows may have fewer components, but similar documentation and explanations are needed for others to understand the result.
Still, limiting model openness to where others can only view the code reduces the impact of the model, particularly its use in research led by those outside of the modeling group. Intentional support for the growth of a model’s impact requires major versions of the modeling and analysis codes must be citable, typically with DOIs, discoverable software, quality documentation for all software in the workflow, and the licenses for each to be open without restrictions on downstream usage. Once these basic components are in place, other researchers can begin to understand and incorporate the advances embodied in these softwares into their research. Open communication in dedicated communities of practice can help researchers, forecasters, and publication reviewers accurately understand how these software should be used in various scenarios, reducing the occurrence of software misuse in operations and publications (Ringuette et al. 2025, Ringuette et al. 2024).
Tiering model openness means making the effort that goes into it proportional to the expected impact of the model (HM Treasury 2015). Previous efforts for tiering exist. The Model Openness Framework for AI (White et al. 2024) prioritizes completeness and openness for the code, data and documentation, requiring release under certain licenses as a prerequisite for consideration in the tiering assignment. Higher tiers incorporate additional workflow components, increased documentation, and more details for user understanding and reproducibility. Although it is definitely important for the components of a workflow supporting a modeling result to have licenses without limitations on usage, disproportionately prioritizing licensing over other important components does not provide a balanced tiering system.
The Level of Service model for NASA’s Earth Science Data Systems also provides a tiering system for Earth Science data based on funding sources, data processing levels, and provided services9. The lowest tier requires rich metadata and long-term funded support for the archives, with higher tiers requiring increased metadata richness and alignment with an increasingly complex set of requirements to support user services for data access and visualization in exchange for user support and advertising services. Such a demanding structure is not sustainable without significantly large long-term funding, which is not likely for model and model output archiving. The desired tiering structure must have a more reasonable entry point with lower archival staff requirements so that more of the funding can be directed to the model developers.
A preprint of an article in Heliophysics attempted to categorize current practices in Heliophysics modeling into four areas called “Open Use”, “Open Validation”, “Open Development”, and “Open Collaboration”, while making the case that modeling software can align with open science principles while closed, unviewable to those outside of the modeling group without asking for permission (Corti et al. 2026). In cases where the code must remain closed (e.g., for security reasons or compliance with Federal law, see Appendix B of NASA’s SPD-41a10), this is the unfortunate reality; every effort should still be made to adopt Open Science practices. However, the vast majority of existing computational models have no such restriction, including many listed in that work, only in need of prompting and funding to open source the software. Promoting this closed approach for models that can be open hampers the adoption of Open Science in modeling software at a critical time in Heliophysics. Instead, the basic characteristics of Open Science must be advocated for, including openly available and citable modeling codes (e.g., on public GitHub repositories with versioned DOIs), licenses without restriction on downstream usage, schools to educate the community on how to execute and understand models for themselves, and multiple open communities of practice specific to modeling.
The application of Open Science to these challenges holds promise. The basic principles of Open Science - collaboration, availability (including FAIR: Findable, Accessible, Interoperable, and Reusable1), reproducibility, and transparency - provide a framework to understand the changes that are needed and how to positively progress. Substantial research into applying these concepts to complex software in other fields and across science already exists and should be applied with minor adaptations where needed for our field (especially Lamprecht et al. 2019). However, care must be taken to consider the difficulty and scope of each task and balance these with realism. Additional work cannot be reasonably required where no additional funding is granted (Micheletti et al. 2024); infrastructure can only support the data, computation, and software it has funding for; and funding is a limited resource that should be applied where the most impact is expected. Thus, a tiering system connecting funding, impact, and Open Science practices is outlined below for the benefit of model developers, infrastructure scientists, and funders with the added benefit of accelerated research and discovery promised by Open Science. This system also incorporates feedback from the modeling community included in the appendix and the desired infrastructure (Ringuette 2026). A period of transition to the new infrastructure required will be necessary for the success of the relevant communities, but should be kept short.
There are many definitions of Open Science, such as “transparent and accessible knowledge that is shared and developed through collaborative networks” in a European business paper (Vincente-Saez & Martinez-Fuentes 2018), “a set of principles and practices that aim to make scientific research from all fields accessible to everyone for the benefits of scientists and society as a whole” from UNESCO (2021), “The principle and practice of making research products and processes available to all, while respecting diverse cultures, maintaining security and privacy, and fostering collaborations, reproducibility, and equity” from the 2023 US White House,11 and the incorporation of similar ideas into the definition of Gold Standard science from the 2025 US White House.12 Each definition carries with it a varying set of principles, generally including Collaboration, Reproducibility, Availability (including FAIR), and Transparency - or CRAFT. These principles are used below as the framework of the needed tiering system connecting Open Science, impact, and funding, partially addressing the existing gap between Open Science activities and recognition of the significant efforts required (Chue Hong et al. 2022; Grattarola et al. 2024).
One signature idea of this work is the worthiness of funding and maintaining software to enhance or sustain its capabilities, community interaction, and alignment with Open Science as a critical priority alongside needed improvements in its science capability rather than the current sole focus on science capability. For example, three Heliophysics NASA DRIVE centers received significant funding over a few years to focus on answering science questions with modeling. This focus resulted in only one of those DRIVE centers including any major model development in the work, unfortunately only as an auxiliary objective. In contrast, the modeling community is calling for more substantive funding focused on developing the capabilities and openness of modeling software based on “usage, impact, and citation metrics; software standards compliance; model and execution complexity; alignment with FAIR; community involvement; and other indicators of transparency, quality, and openness” (Ringuette et al. 2025). The tiering system described in this section combined with the infrastructure improvements and levels of service described in the next section provide a prioritization system for models where limited resources are a reality.
The tiering system sketched out below is built upon these basic components - alignment with Open Science, impact, and funding ( Figure 2). Balance and realism are incorporated by connecting impact with effort along the scale, delegating harder tasks to higher tiers where the expected or intended impact is also higher (Jakeman et al. 2024, Micheletti et al. 2024). In this context, impact can be in the areas of science research, education, operations, or connected areas, typically measured quantitatively by tracking citations, number of contributors, software downloads, number of views of the item’s landing page, and engagement with the user community (Ringuette 2025). Care must be taken when assessing impact to avoid conflicts of interest, particularly on aspects of impact that are qualitative.
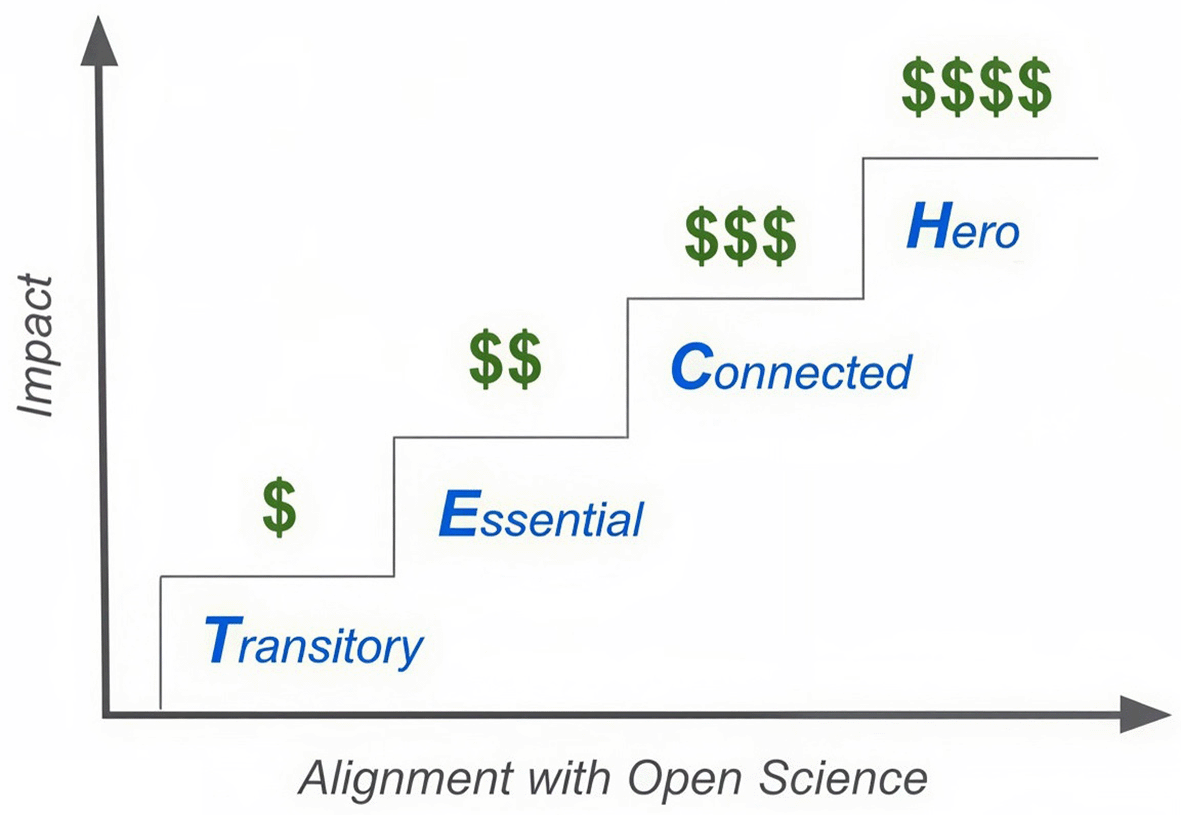
TECH stands for the names of the four tiers in increasing order: Transitory, Essential, Connected, and Hero. Model complexity is an independent axis (not shown).
A system with four tiers - Transitory, Essential, Connected, and Hero (TECH) - is selected to provide an entry level that is easily achievable, a top level that is designed for maximum impact, and two middle levels to give due credit where significant progression above the entry level is achieved. All characteristics of a given level must be met for a model to obtain that level. The requirements of higher levels are in addition to those of the lower levels. Finally, models of higher complexity will require more investment to advance to higher tiers due to the inherent technical challenges. Even so, advancing to higher tiers should be a funded effort and justified by the intended and observed impact of the model, regardless of the model’s complexity.
The lowest tier is designed for models that are intended to be transitory in their impact, and so have minimal or no support for Open Science practices ( Table 1). This tier is intended for “toy” models, simple models developed to aid in the developer’s understanding of a physical phenomenon or trend, beginning versions of modeling code in support of research publications, and similar modeling or model analysis software not yet ready for a wider impact. These models often focus on demonstrating concepts and ideas or on understanding the consequences of certain model assumptions, including theories (e.g., the demonstration category, see Grimm et al. 2020). The trademark of models in this tier is the lack of a version-specific persistent identifier and no license. Models or related software in this tier that are used in support of peer reviewed publications are necessarily open in their entirety for the sake of scientific review, usually in the supporting materials of the publication they support (Janssen et al. 2020), but typically as “view only”. At this tier, the code “does not have to be clean or beautiful, it just needs to be available” (Peng 2011). Due to legal restrictions, some models in this tier may only be allowed to share portions of the code. Archival support for transitory models is limited to that supplied by journal publishers.
The second tier provides a launching point for models and their associated workflow components where the essentials needed for increasing impact and the adoption of Open Science principles are incorporated ( Table 2). Models and their related components in this tier are required to have:
• A version specific persistent identifier, usually a DataCite DOI;
• The metadata required to obtain that identifier, plus a basic description and at least one keyword and author’s ORCiD per workflow component;
• Open access to all portions of the code, typically the main branch of the code repository;
• A license without restriction on downstream usage or collaboration (e.g., BSD-3-Clause, MIT, or Apache 2.0); and
• Version-specific citations to the most important artifacts the work depends on, especially including other components of the model workflow.
These items provide support for increased impact by enabling citation of the software version used through the persistent identifier, trackable attribution for those who contributed to that software, legal permission for usage and collaboration, and minimal dependency tracking of the data, software, and other resources deemed critical for the work. Archival support for models in the Essential tier is limited to generalist repositories such as Zenodo, Dryad, and similar. Submission of the model workflow components to a specialized community or instance of one of these services may be required by the funding agency or institution and may carry additional requirements. Products from models in this tier should not be considered for risk predictions or model intercomparison projects due to the significant lack of transparency.
The third tier is reserved for models and their associated workflow components that have made significant progress in increasing their impact, alignment with Open Science principles, and the model’s scientific or forecasting performance, but have not yet reached the requirements of the highest tier ( Table 3). The emphasis for this tier is an increase in metadata quality and richness in simple ways that increase the connectedness of the model with other resources in the community, lowers usage barriers for users external to the modeling group, and aids funders’ understanding of the software needed to support impactful models. This increases the likelihood for users to discover the model, understand the model, and be interested in working with the model developers to use the model, which is critical for the community to become involved in and supportive of models.
Recent work in related fields has demonstrated the advantages of standardized documentation for modeling, resulting in widespread adoption indicated by nearly 4000 citations as of 2020 of a format called “Overview, Design concepts, and Details” or ODD (Grimm et al. 2020). Requiring these non-technical descriptions in the Connected tier provides users a solid starting point to understanding models, with differences between models ameliorated by the standardized format. More detailed and technical documentation is reserved for the Hero tier. In addition to the requirements of the lower levels, all model workflow components in this tier have:
• At least half of all living authors and contributors indicated with the appropriate persistent identifiers (e.g., ORCiDs) with affiliations also indicated with the appropriate persistent identifiers where possible (e.g., RORs);
• All input products, including data, and at least half of all top level software dependencies indicated in metadata (e.g., using the Zenodo submission form), ideally using version-specific persistent identifiers (e.g., DOIs);
• Improved description and documentation, including an Overview, Design Concepts and Details (ODD) protocol document for the model and basic usage instructions for all components; and
• Increased richness of keywords, including science-specific terms (e.g. relevant phenomena), and names of all output variables produced by the model software.
Proper archival support of model workflow components in this tier does not yet exist in Heliophysics, including technologies to streamline the creation of increasingly detailed metadata. Operational usage of models at this tier is strongly discouraged due to the lacking support for reproducibility which is crucial for establishing community and public trust.
The highest tier is designed for models that aim to gain the full trust of the community, potentially for incorporation into risk prediction, forecasting operations, or other uses with high impact and broad reach ( Table 4). Models and their associated workflow components in this tier provide ample resources to their user communities to support external use of the full model even beyond the intended science area, such as detailed TRACE documentation, user workshops, model-specific communities of practice, and significant advances in the model’s reusability (Ringuette et al. 2025, Ringuette et al. 2024). TRACE documentation provides a standardized documentation structure for models to demonstrate and document good modeling practices, including parameterization, development, analysis, evaluation, and validation (Grimm et al. 2014, Focks et al. 2014, Ayllón et al. 2021). Complex models in this tier often have simplified versions of the model available for new users or exploratory analyses and custom analysis software as a workflow component, while simpler models are typically installable by a single command and wrapped by Python code or incorporated into existing community software for streamlined usage. Positive contributions to the model code are welcomed from exceptionally skilled users, with wider acceptance of similar contributions to any relevant model user software.
Alignment with standards from the wider software, metadata, data, and modeling communities is reserved for this tier. Investing into alignment with standards significantly increases interoperability for the model workflow components, reduces friction for collaboration both within and outside of heliophysics, and can attract and retain RSEs who are used to a certain standard of development. The standards to align each model workflow’s component must be relevant to the component and internationally adopted, ideally across multiple sciences. Specifically, any final produced data (e.g., produced by the model analysis software) and their associated metadata must align with the same requirements as the observational data they are to be compared to, such as the FITS file format and VSO metadata for solar physics data and CDF or netCDF file format and ISTP metadata for space physics data, with potential modifications useful for modeled data. Model user software must align with open source software standards (e.g., the Journal of Open Source Software13 or the Journal of Research Software14 for software in general, or pyOpenSci15 and the Python in Heliophysics Community16 for software written in or wrapped by Python) with its metadata aligned with CodeMeta17. The model software must similarly align with the standards and best practices promoted by the Open Modeling Foundation (e.g., Kherroubi et al. 2025). Ideally, the model software would also align with the same software standards as the model user software, applying the same concepts across programming languages where possible.
The significant work needed to achieve the requirements of this tier vastly improves the capability and openness of the model for users external to the developer group, including early career scientists, research software engineers, and experienced scientists in related fields. However, such work must be funded, and proper archival support of model workflow components in this tier does not yet exist in Heliophysics. The high impact of modeling software in this tier requires the implementation of good modeling practices and the necessary infrastructure, which does not happen for free (Micheletti et al. 2024). In summary, components of a model workflow in this tier have:
• Detailed software documentation with model software fully described by a TRACE document, ideally with an example script or digital notebook demonstrating how to use the model;
• Significant user support and software advances to support external reusability;
• Demonstrated significant community usage; and
• Model software, relevant model user software, produced data and each component’s metadata fully aligned with relevant standards, specifically including all necessary information needed to reasonably reproduce the result.
Full alignment with Open Science practices is an asymptotic pursuit where significant improvements often become increasingly difficult with decreasing return on investment, especially for improvements beyond the Hero tier. For example, it might be considered worthwhile to restructure the code of a complex model in the Hero tier to improve alignment with software best practices; but the investment required would be quite high with little community benefit. However, if that restructuring created new interoperability with other models in the hero tier, thus significantly increasing the depth of science questions that could be addressed or the forecasting capability or speed of the model, then the investment may be justified. Another example improvement likely worth additional investment is alignment of a selected model in the Hero tier with standards required by operational use for transitions into operations (e.g., Henley and Milan 2025), where the model has demonstrated high community trust and usage, high forecasting performance as measured by standard community metrics, and sustained community interaction. Funders must remove support for the advancement or use of unnecessarily closed modeling software, but must instead incentivize their transition to open-source code and their advancement to an appropriate tier, as long as the expected impact of the model justifies the effort.
Considering the GraphCast model as an example (Lam et al. 2023), we can determine the relevant characteristics of the model, determine what tier it aligns with, and what improvements are needed to advance the model to the next tier ( Table 5). In this case, the caveat is that selection is an AI model, but the general ideas also apply.
Due to the lack of a DOI for the software, the GraphCast model is classified as Transitory. Adding a DOI for the software for each major version produced, including a description and a few useful keywords in the DOI metadata, and updating the license on the associated materials to be less restrictive would quickly place this model in the Essential tier. Advancing to the Connected tier would take more effort, including generating standardized documentation, metadata improvements, indicating version ranges for dependencies, and adding a simple data output function with the file format aligned with community standards. Since the model software presents itself as a new skillful option for weather forecasting, some consideration should be given for work needed to advance to the Hero tier, but only after interaction with and use by the community has been demonstrated.
The infrastructure supporting research software is overall robust for softwares where curation or higher level supporting services are not desired, assuming the right incentives are applied to convert currently closed models to open-source software. There are a number of websites where software can be shared and developed in the open, such as GitHub, GitLab, BitBucket, pypi and several others. Additionally, Software Heritage automatically crawls these and many other similar websites to permanently save a copy of the software hosted on those websites.18 These softwares are each assigned a Software Hash Identifier, which is now an ISO/IEC international standard with support for citation. This service, combined with the interlinking capabilities available in DataCite’s metadata structure (e.g., through Zenodo), provide ample support for the requirements of the Transitory and Essential tiers. Funding agencies and institutions may have a small number of additional requirements, such as including funding information, but such items are typically already supported in current infrastructure.
Although the current infrastructure is sufficient for models in the Transitory and Essential tiers, there are significant gaps in the support needed for models in higher tiers. Models in the Connected tier face the challenge of creating richer metadata, standardized documentation, aligning with standards, and increasing user support for their software, but there are no services or support yet available to streamline these processes. This is where the infrastructure needs improvement. The creation of richer metadata for the software and any data generated can be streamlined through the application of technology, such as converting a list of software dependencies into a citation list or using AI to suggest the proper variable types from a controlled vocabulary. Model developers also need examples in the relevant science area of the desired documentation. Some general standards exist for software components, but implemented examples for modeling software are missing along with funding to support alignment (e.g., CodeMeta19 and Croissant20 for research software metadata). Finally, the increased demand for user support in higher tiers must be distributed broadly among an increasingly experienced developer and user community in order to be sustainable, such as through a community of practice with modeler-led user workshops, but there must be a small amount of funding for a few forerunners to work out how this should operate in practice (see Ringuette et al. 2025 for details). The associated increased demand for computational resources must advise the planning of added high end and high performance computing machinery that is open for public use. In many cases, a discounted price for in-house workstations (e.g., with multiple GPUs) would allow for less demanding model executions without the need for public supercomputers.
Advances in the current infrastructure are critical for the success of impactful models, for understanding the software and technologies they depend on, and the recruitment and retention of the RSEs those models rely on. Advances focused on metadata, standards alignment and creation, or impact measurement should be led by science data repositories and the international standards community, given their significant expertise in these areas, and with the involvement of model software developers. Development focused on communities of practice, user support, and RSEs should be led by the model developers with the support of the RSE associations (e.g., US-RSE21). Adding a comparatively small amount of funding now to improve support for impactful existing models is expected to greatly increase the return on investment rather than funding repeated efforts with slightly updated technologies, especially when those technologies can take decades to develop (Micheletti et al. 2024; e.g., Gombosi et al. 2021).
Modeling and simulation code is generally of much smaller size than the outputs they produce, making the complete archival of those codes an easily attainable task (e.g., Software Heritage22). However, the data produced by models can be problematically large for science quality results. The proper archival and preservation needed for the generated data heavily depends on its purpose, whether simply in support of a research publication or more data intensive scenarios such as model intercomparison projects. Schuster et al. (2023) provides a rubric to determine the most impactful portions of these outputs to archive when in support of research publications, taking into consideration the difficulty of re-executing the model, the size of the output, the availability of machinery required to execute the model, and other relevant considerations. This decreases the total size of the data submissions, but often not below the no-cost limits on generalist repositories. Infrastructure support is needed for these research data with support from personnel trained with this rubric to provide the needed guidance for researchers working with modeled data and the expertise offered by existing science data repositories. Streamlining technologies for the semi-automatic creation of metadata for these data are also needed, regardless of the intended use (e.g., SAMMI for CDF metadata, Robbertz et al. 2025).
In contrast to research data, the sizable outputs often produced in support of risk predictions, training of AI emulators, model intercomparison projects (e.g., Schmidt 2025), or other data-focused applications cannot be reduced without crippling the intended use. The large file sizes of those outputs also demand the installation of required model analysis software next to the data to avoid barriers caused by attempting to download large data for processing. A critical difference here between data in support of publications and these data is the short timeframe data preservation is needed - several months or a few years compared to many decades - which provides more flexibility in constructing a solution than current systems support. The solution would likely involve an open-source science cloud platform for medium-sized efforts (e.g., low PB-scale) or a similar science platform installed on high performance computing infrastructure for larger sized efforts. A typical preservation duration policy would be needed, ideally based on the expected impact of the effort, the duration required for the proposed project and desired impact, the size of the data to be produced, and the tier level of the model workflow used to generate the data.
As in the existing science data repository community, the level of support assigned for components of a modeling workflow should be aligned with the tier the model has achieved and the impact of the model. The concept of this structure, typically called “levels of service”, is to use a classification system to prioritize which archived models receive what services and funding. Given the TECH classification system presented, a sketch of the services associated with each level can be easily made, including curation, preservation, search and discovery, advertising, and support for large data. Not every model can or should pursue the Hero tier. Rather, the progression to a higher tier should be a funded activity, where that funding is awarded based on satisfactorily completing the required items of the previous tier, the current impact and community use of the model, the relevance of the model’s science questions and capabilities to current funding objectives, and the funding required for the supporting services of the next tier.
Considering most of the support of model development is currently through scientific research proposals, one possible scenario that might work in the short term is:
• The funding agencies and institutions reserve a certain amount of funding for each science proposal solicitation.
• After the selection has been made, the selected proposal team could request additional funding for advancing their models in the relevant tiering system, with the amount of funding increasing to higher levels.
• At the end of the period of performance, the model will be evaluated under the same tiering system.
The tiering system, such as the TECH tiering system described in this work, must be developed by the community, align with Open Science, and result in demonstrable increases in usage of the model by the community.
Transitory
The archival and preservation services for model workflow components, including models, are generally provided by journals. No further support is warranted given the transitory nature of these artifacts.
Essential
Models and their workflow components in this category are sufficiently serviced by the existing archival and preservation infrastructure, including Software Heritage, GitHub, Zenodo, and similar. Large data produced by these models should follow the rubric generated by Schuster et al. (2023) to preserve the science while decreasing the size to take advantage of the free or low-cost preservation services offered by generalist repositories. Data-focused applications of data from these models should not be supported due to the low openness of the model.
Connected
The additional requirements of models in this tier warrant a low level of specialized support in addition to the services associated with the previous tier. In addition to the streamlining technologies discussed before, the software and data metadata and documentation required in this tier would benefit from curation services. Given these metadata, a fitting service for these models and associated components is enhanced search, discovery, and tracking services, supplemented by minimal advertising (e.g., EMAC search services, Renaud et al. 2022; e.g., badges, Kidwell et al. 2016). These services support the potential advance of the model to the next tier by increasing the likelihood that new users will be able to discover and use the software, and by providing the model developers with the usage and citation statistics needed to justify the additional funding needed to fulfill the requirements of the next tier. The preservation needs of model workflow components in this tier can be sufficiently supplied by existing infrastructure, but may need a small specialized layer to provide the additional services, such as an institution-specific implementation of DataVerse or an agency-specific community on Zenodo with the streamlining technologies added. Data produced by these models for data-focused applications could be preserved if resources are available, but with a lower priority and possibly a shorter duration than for models in the Hero tier.
Hero
Models in this tier represent a significant amount of investment which warrants a more substantial level of supporting services for increased community benefit compared to lower tiers. The time-intensive process of aligning these model workflow components with the relevant standards and increased reproducibility requirements must be supported through streamlining technologies and more detailed curation support. The increased reproducibility also justifies enhanced advertising and support, such as highlights in conference presentations and on a dedicated website, providing logistical support for user-focused workshops and hackathons led by the model developers, similar support for model-specific communities of practice where requested, and short-term cloud or HPC support for analysis of model outputs. Users of complex models in this tier would also benefit from links on the model’s landing page to the specific machines the model has been successfully executed on, ideally also with the relevant documentation. These enhanced services likely require a specialized system beyond what is currently available, but similar to the science data repository systems. The size limit for permanent archival requests in support of peer-reviewed publications should also be raised compared to the lower tiers. Data produced by these models for data-focused applications should be preserved if resources are available with a duration appropriate for the intended use (e.g., several months to ~5 years), which could be extended if community use of those data is sustained.
Maintaining and sunsetting models
Improving and maintaining model software is a critical activity to fund for the long-term advancement of our modeling capabilities. Software maintenance is not an exciting proposal to review or fund compared to enhancing functionality of widely-used software, but without such funding the capabilities offered by that software diminish and eventually become useless to the community. However, a delicate balance is needed to properly advance the capabilities of current software without neglecting new exploratory work and the development of new functionalities for widely-used software.
Not every model can be sustained long term and must eventually be “sunsetted”, or retired from active use and maintenance by the community. Complex mission software faces a similar challenge that we can learn from. In that case, mission-specific capabilities are increasingly incorporated into more permanent software packages (e.g., MMS analysis software incorporated into pySPEDAS) rather than being lost once the mission funding ends. This benefits not only the community in retaining the analysis capability due to the maintenance performed by the more general software package maintainers, but also benefits the mission scientists by encouraging use (and citation) of the software long after they have moved on to other work. Similarly for model software, the advances achieved in a given effort should be incorporated into larger modeling software efforts or at minimum thoroughly explained in a fully transparent way in peer-reviewed publications for others to benefit.
The vision presented in this work outlines a new prioritization system based on impact, Open Science practices, consequences of limited funding, and the long-term health of the modeling community, including the recruitment and retention of RSEs. This system incorporates input from the modeling community sourced from the 2024 Software for the NASA SMD Workshop Report, the 2024 Solar and Space Physics Decadal Survey, The Developing Heliophysics Standards and Cross-science Collaborations Workshop Report, attendees of the 2024 Jack Eddy Symposium, the Open Modeling Foundation, and other modeling community members at large both in Heliophysics and in closely related sciences (Ringuette et al. 2024; NASEM 2024; Ringuette et al. 2025). The topics gathered from these inputs include software-focused communities of practice, Open Science practices applied to the entire modeling workflow, funding opportunities designed for software, and the recruitment and retention of RSEs alongside the discovered challenges and existing capabilities of the current infrastructure (e.g., archival support, services, computational resources, funding, etc). These inputs and concepts have been carefully combined into the tiering system presented.
Shifting from the current system designed to support closed models to this new system designed to promote and reward the adoption of Open Science practices has several benefits.
1. Strong incentives for transitioning closed models to open-source software;
2. Purposeful support for increased collaboration between model developers, RSEs, and the research community, which is expected to result in accelerated research and scientific discovery;
3. Increased stabilization and funding efficiency for the model development community;
4. Improved clarity in model performance trends in risk prediction, evaluation studies, and model intercomparison projects;
5. Stable funded pipelines for the attraction and retention of the next generation of modelers and RSEs through dedicated communities of practice, including educational opportunities;
6. Standardized expectations for metadata aligned with international standards and best practices, which will power more capable search and discovery services with increased user understanding of models;
7. Support for proper citation of model workflow components, enabling research culture to increase their research transparency through version-specific data and software citations in their model-oriented publications;
8. Clearer expectations of requirements, typical supporting services, and funding prospects for models and their associated workflow components based on the desired impact;
9. Development of currently missing archival infrastructure, including streamlining technologies and prioritized archival support for modeled data; and
10. New short-duration archival support for data-focused modeling efforts.
The call for Open Science in modeling is one that demands change. However, change does not happen in a day. There must be a transition period, ideally a short one, to allow the incentivized shift from closed modeling to the adoption of Open Science practices. During and after this transition, it is and will be valuable to remember the mantra of “something is better than nothing”, or in other words considering incomplete progress as still valuable progress (e.g., Kherroubi et al. 2025, rule 10). Using a prioritization system such as the one described in this work allows the various modeling groups in the community to select what tier is the most relevant for their work while simultaneously guiding them in what Open Science practices are the most useful for the desired impact of that tier. While the authors consider the high level structure presented as well constructed and balanced, the finer details should be developed in partnership with the model developer community in each science area, including in Heliophysics, and are expected to change over time as technology advances.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)