Keywords
Bioinformatics, Data mining, Images, Scientific literature, Text, OCR, PDF, Biomedical
This article is included in the Bioinformatics gateway.
Bioinformatics, Data mining, Images, Scientific literature, Text, OCR, PDF, Biomedical
There has been an enormous increase in the amount of the scientific literature in the last decades1. The importance of information retrieval in the scientific community is well known; it plays a vital role in analyzing published data. Most published scientific literature is available in Portable Document Format (PDF), a very common way for exchanging printable documents. This makes it all-important to extract text and figures from the PDF files to implement an efficient Natural Language Processing (NLP) based search application. Unfortunately, PDF is only rich in displaying and printing but requires explicit efforts in the extraction of information, which significantly impacts the search and retrieval capabilities2. Due to this reason several document analysis based tools have been developed for physical and logical document structure analysis of this file type.
The recently, provided basic information retrieval (IR) system by PubMed is efficient in extracting literature based on published text (titles, authors, abstracts, introduction etc.), with the application of automatic term mapping and Boolean operators3. The normal outcome of a successful NLP query brings a maximum of 20 relevant results per page; however, user can improve the search by customizing the query using the provided advanced options. So far, the current PubMed system, as well many other related orthodox NLP approaches are unable to completely implement an efficient information retrieval system, capable of extracting both text and figures from published PDF files.
One of the major and technical challenges is the availability of structured text and figures. To our limited knowledge, there still is no single tool available which can efficiently perform both physical and logical structure analysis of all kinds of PDF files and can extract and classify all kinds of information (embedded text from all kinds of biological and scientific published figures). Different commercial and free downloadable software applications provide support in extracting the text and images from PDF files:
A-PDF (http://www.a-pdf.com/image-extractor/),
PDF Merge Split Extract (http://www.pdf-technologies.com/pdf-library-merge-split.aspx),
BePDF (http://haikuarchives.github.io/BePDF/), KPDF (https://kpdf.kde.org),
MuPDF (http://mupdf.com), Xpdf tool (http://www.foolabs.com/xpdf/),
Power PDF (http://www.nuance.com/for-business/imaging-solutions/document-conversion/power-pdf-converter/index.htm)
However, these software applications do not provide text and images in a form where they could be considered for further logical analysis e.g. mining text in reading order from double or multiple columns documents, searching marginal text using key-words, removing irrelevant graphics and extracting embedded text inside single and multi-panel complex biological images.
So far, the current PubMed system as well many other related orthodox NLP approaches e.g.4–13, are unable to completely implement an efficient information retrieval system, capable of extracting both text and figures from published PDF files.
To meet the technological objectives of this challenge, we took a step forward in the development of a new user friendly, modular and client based system (MSL) for the extraction of full and marginal text from PDF files based on the keywords and coordinates (Figure 1). Since MSL provides a module for the extraction of figures from PDF files and applies Optical Character Recognizer (OCR) to extract text from all kinds of biomedical and biological Images. MSL comprises three modules working in product-line architecture: Text, Image and OCR (Figure 2). Each module performs its task independently and its output is used as an input for the next module. It can be configured on Microsoft Windows platforms following a simple six-step installation process.
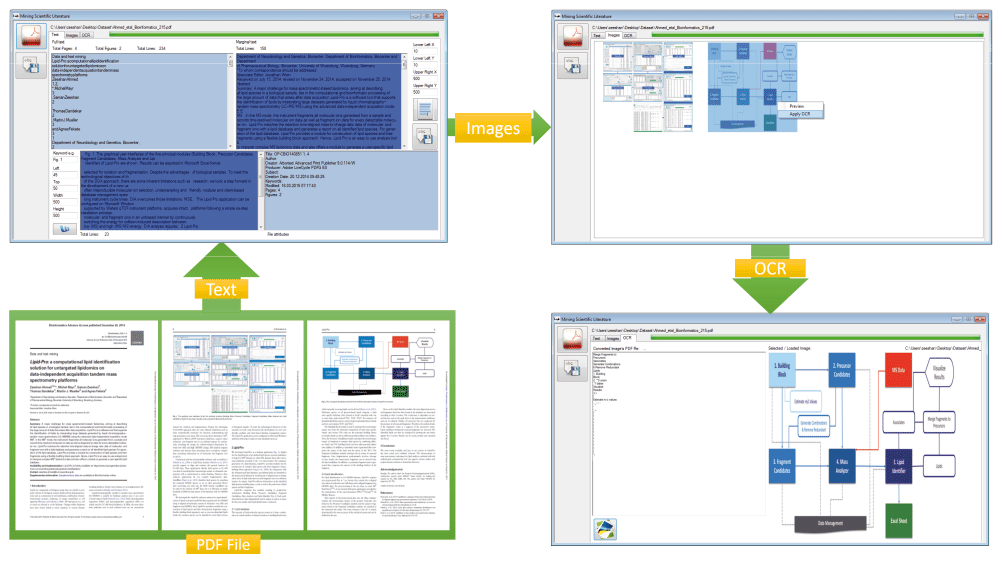
This figure shows the graphical user interface and modular workflow of three main components: Text, Image and OCR.
MSL extracts text and figures from the published scientific literature and helps in analyzing embedded text inside figures. The overall methodological implementation and workflow of the MSL is divided into two processes: (I) Text mining and (II) Image analysis. MSL is a desktop application, designed and developed following the scientific software engineering principles of three-layered Butterfly14 software development model.
Physical and logical document analysis is one of the living challenges. To the best of the authors’ knowledge, there is no solution available which can perform efficient physical and logical structural analysis of PDF files, implement completely correct rendering order and classify text in all possible categories e.g. Tile, Abstract, Headings, Figure Captions, Table Captions, Equations, References, Headers, Footers etc.
However, there are some tools available which are helping in this regard e.g. PDF2HTML towards contextual modeling of logical labelling15, PDF-Analyzer for object level document analysis16, XED for hidden structure analysis2, Dolores for the logical structure analysis and recovery17 automatic conversation from PDF to XML18 and PDF to HTML19 etc.
We developed MSL’s Text module, which is capable of processing PDF files with single, double or multiple columns. It divides the system’s text based output in four sub-modules: full text, marginal text, keyword based extracted text and file attributes. Full text gives the complete text from PDF file, marginal allows user to give the coordinates (Lower Left X, Lower Left Y, Upper Right X and Upper Right Y) and extract the desired portion of the text from the PDF file. The keyword based text allows user to extract the information from PDF file based on keywords and respective coordinates (Left, Top, Width, Height) e.g. if a user is only interested in getting the figure caption or references, this kind of search will be helpful. The last sub module, File attributes gives the information about input file including title, author, creator, producer, subject, creation date, keywords, modified, number of pages and number of figures.
While implementing Text module, we researched and tried different available commercial and freely downloadable libraries with a focus on full text extraction, marginal text extraction, keyword based text extraction and text extraction from embedded images from PDF files. We tried different implemented systems and libraries e.g. iTextSharp (http://sourceforge.net/projects/itextsharp/), Bytescout (https://bytescout.com), Spire PDF (http://www.e-iceblue.com/Introduce/pdf-for-net-introduce.html), Sautinsoft PDF Focus (http://www.sautinsoft.com/products/pdf-focus/), Dynamic PDF (https://www.dynamicpdf.com), PDFBox (https://pdfbox.apache.org), iText PDF (http://itextpdf.com), QPDF (http://qpdf.sourceforge.net), PoDoFo (http://podofo.sourceforge.net), Haru PDF Library (http://libharu.sourceforge.net), JPedal (https://www.idrsolutions.com/jpedal/), SVG Imprint (http://svgimprint-windows.software.informer.com), Glance PDF Tool Kit (http://www.planetpdf.com/forumarchive/53545.asp), BCL (http://www.pdfonline.com/corporate/) SharpPDF (http://sharppdf.sourceforge.net) etc.
One of the common problems in almost all libraries is merging and mixing of text, using double or multiple columns. Our developed system is the combination of different libraries, useful for different purposes. We have used Spire PDF to remove the Book-marks, iTextSharp for the extraction of full and marginal text, Bytescoute for the keyword based marginalized text search and producing output in the form of XML file (Figure 2). The generated XML file contains structured (tagged) text along with the information about its coordinates (placement in the file), font (Bold, Italic etc.) and size, which can be used for mapping and pattern recognition tasks.
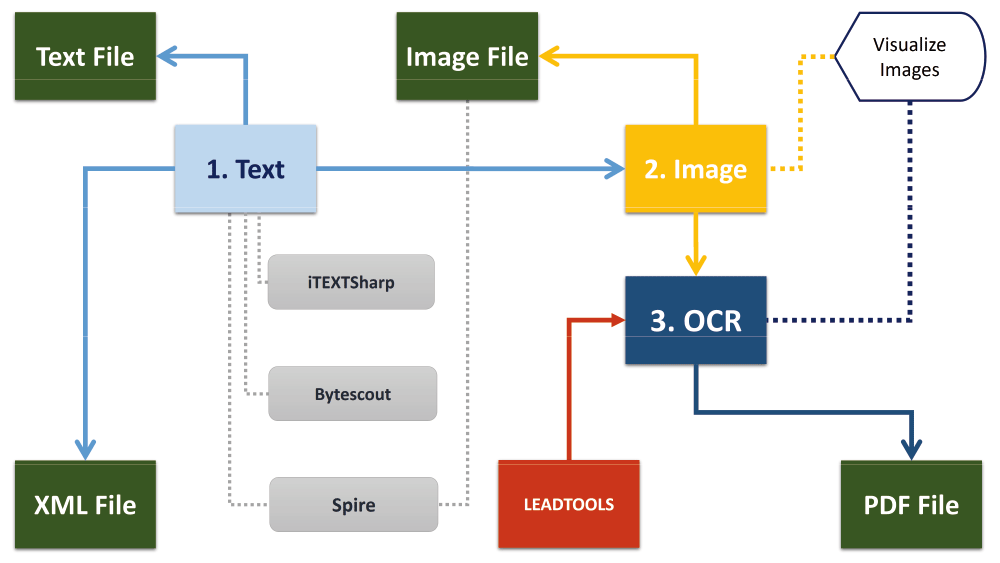
This figure shows the conceptual architecture of the MSL application, which consists of three main components: Text, Image and OCR.
Image-based analysis is a versatile and inherently multiplexed approach as it can quantitatively measure biological images to detect those features, which are not easily detectable by a human eye. Millions of figures have been published in scientific literature that includes information about results obtained from different biological and medicinal experiments. Several data and image mining solutions have been already implemented, published and are in use in the last 15 years20. Some of the mainstream approaches are towards the analysis of all kinds of images (flow charts, experimental images, models, geometrical shapes, graphs, images of thing or objects, mixed etc.). There are not many approaches proposed for specific kinds of image-analysis e.g. towards the identification and quantification of cell phenotypes21, prediction of subcellular localization of proteins in various organism22, analysis of gel diagrams23, mining and integration of pathway diagrams24.
While implementing a new data-mining tool, one of our goals was to extract images from published scientific literature and try to extract embedded text as well. We analyzed different freely available and commercial OCR systems and libraries including Aspose, PUMA, Microsoft OCR, Tesseract, LEADTOOLS, Nicomsoft OCR, MeOCR OCR, OmniPage, ABBYY, Bytescout claiming to be able to extract embedded text from figures. During our research we found LEADTOOLS (Figure 2) as one of the best available solutions for this purpose. MSL is capable of automatically extracting images from the PDF files and allowing the user to apply OCR to any extracted image by clicking and enlarging it for a better view (using Windows default image viewer).
We tested MSL with similar parameters on randomly selected scientific manuscripts (ten PDF files) from different open access (F1000Research, Frontiers, PLOS, Hindawi, PeerJ, BMC) and restricted access (Oxford University Press, Springers, Emerald, Bentham Science, ACM) publishers, including some of the authors’ published papers, details are given in Table 1. While testing MSL on the selected manuscripts, we observed best overall performance for the manuscripts26,38–42, with satisfactory results from almost all publishers (including Oxford University Press, BMC, Frontiers, PeerJ, Bentham Science, ACM) in terms of both extracting text in reading order and extracting images. An observed poor performance involved manuscripts from PLOS35, Hindawi36, F1000Research34 and IEEE37 publishers. Here, in the case of text extraction we observed that the text was in reading order when using manuscripts from F1000Research and IEEE but text was without spaces in the manuscript from PLOS and with additional lines and extra spaces in the manuscript from Hindawi. In the case of figure extraction we observed one common problem among the four manuscripts from these publishers; along with the manuscript images (Figures), embedded journal or publishers’ logos and images were also extracted. Additionally, while analyzing the manuscript from F1000Research, we observed that the images were broken into many pieces and it was not possible to find one single complete image. As we did not test all manuscripts from the mentioned publishers, we cannot claim that the results will be the same for all papers from a publisher, as the output may vary in different papers. Our observed results using MSL are given in attached supplementary material (Supplementary Table S1 and Dataset 1).
The table gives the list of 10 of those manuscripts from different publishers, which have been used for testing and validating the MSL application.
| Publishers | Manuscript |
|---|---|
| F1000-Research | Ant-App-DB: a smart solution for monitoring arthropods activities, experimental data management and solar calculations without GPS in behavioral field studies34. |
| PLOS | The Genomic Aftermath of Hybridization in the Opportunistic Pathogen Candida metapsilosis35. |
| Hindawi | Mathematical Properties of the Hyperbolicity of Circulant Networks36. |
| IEEE | Design implementation of I-SOAS IPM for advanced product data management37. |
| BMC | Software LS-MIDA for efficient mass isotopomer distribution analysis in metabolic modeling38. |
| PeerJ | Anvi’o: an advanced analysis and visualization platform for ‘omics data39. |
| Frontiers | Ontology-based approach for in vivo human connectomics: the medial Brodmann area 6 case study40. |
| ACM | Intelligent semantic oriented agent based search (I-SOAS)41. |
| Bentham Science | DroLIGHT-2: Real Time Embedded and Data Management System for Synchronizing Circadian Clock to the Light-Dark Cycles42. |
| Oxford University Press | Bioimaging-based detection of mislocalized proteins in human cancers by semi-supervised learning26. |
To apply MSL, published scientific literature has first to be downloaded in the form of a PDF file, from any published source. The validation process using MSL consists of three major steps: 1) Text mining, 2) Image extraction, and 3) Application of OCR to extract text from selected images as shown in Figure 1, following the implemented workflow as shown in Figure 2. Example results and graphics are shown in Figure 1, Figure 3 and Figure 4. Representation includes the extraction of text and images from one of the randomly selected papers25, and application of OCR to one of the extracted images from another randomly picked publication26.
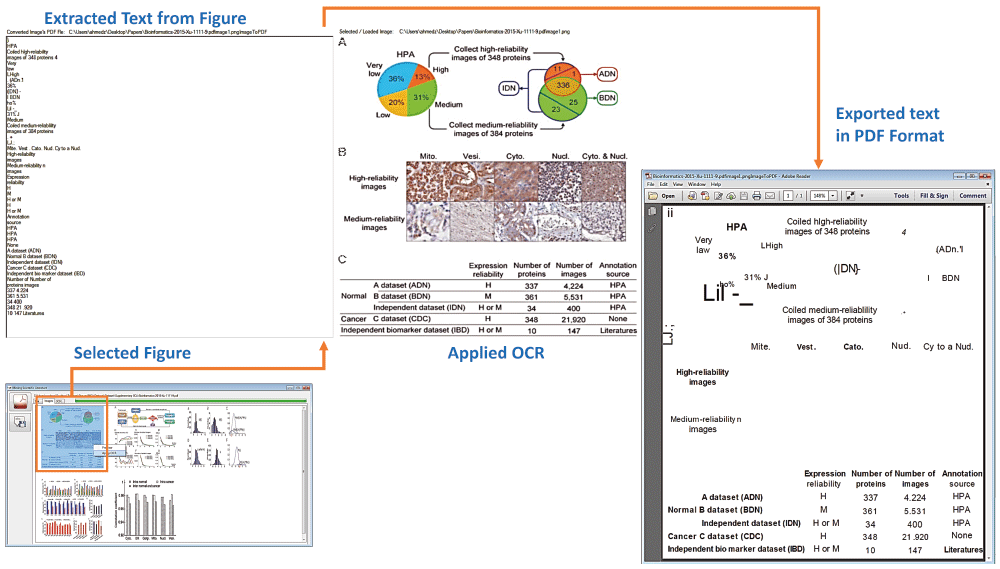
This figure shows document image analysis, text extraction and PDF conversion.

This figure shows document image analysis, text extraction and PDF conversion.
Figure 1 shows that one randomly selected published article’s PDF file25 is inputted to the MSL’s text, the extracted text is divided into three categories (i) complete text in excellent rendering order (ii) marginalized text and (iii) keyword based searched text. Two figures (Figure 1 and Figure 2) are extracted and displayed in the image section, and one of those is selected to apply OCR. The applied OCR extracts textual information, which is displayed in and can be exported in a PDF file.
To further validate the application of OCR and discuss different results, Figure 3 show another example of embedded text extraction from a complex figure27, which includes three panels of images (i) colorful pie and circle charts, (ii) biological images and (iii) tabular information. Similar to our prior application of OCR, results are displayed in textual form as well as generated PDF file of extracted text. A noticeable difference between both outputs is that the textual information is presented in line-by-line order whereas in the PDF file the information is displayed in margins with respect to the original image.
The last resultant example is based on the validation of MSL by extracting the textual information from image based PDF files. We produced an image form of one of the randomly selected article26 and then processed one of pages. As Figure 4 shows, the obtained results were comprehensive in both textual as well as the PDF form. This kind of textual extraction can be very helpful, especially when the literature is available in only images e.g. in the case of old published literature in print only format but electronically available in scanned form. MSL produces several files as system output in the parent folder of the files. These files are: XML files (which include structured or tagged information), an Images File (extracted from the PDF file) and PDF files for all analyzed images using OCR.
We mentioned earlier that we have tried and implemented different libraries for text and image extraction and analysis. The best text based outcome was observed using iTextSharp, better image extraction was observed using Spire and OCR from LEADTOOLS was the most promising. While validating the implemented solution, other than the expected results (text and images), we observed some limitations in the used libraries: unexpected and irrelevant images were also extracted e.g. journal, publisher’s logos and header-footer images, text was not always in good rendering order, especially when there were text-based mathematical equations with super and subscripts; and in case of double or multicolumn PDF files, most of the libraries’ rendering order is not correct. During extracting text, we found that some important symbols were missed and spaces were generated for some paragraphs. We found that it was not possible to extract particular images that are created as a combination of different sub-images and text objects in the manuscript. In these cases, text is found in extracted text area and all extracted sub-images are image sections, with the possibility of missing some sub-images as well. Moreover, when we applied OCR to different images (extracted or loaded), we found that its performance does vary with respect to the complexity of inputted images. In case of special characters (e.g. Greek delta, alpha, beta etc.), it does not perform well unless these are hard wired in the software.
To enhance the functionality of the MSL program (e.g. our standard version available here for download), we give a table of the most often used special symbols in biomedical literature (Table 2). Depending on your application in mind, you thus simply extend the MSL parser by considering also these special characters occurring often in your texts.
| Number | Special Symbols | Name |
|---|---|---|
| 1 | Δ | Delta |
| 2 | α | Alpha |
| 3 | β | Beta |
| 4 | ϕ | Phi |
MSL architecture is based on the Product Line Architecture (PLA) and Multi-Document Interface (MDI) developmental principles, and it is designed and developed (using C-Sharp programming language, Microsoft Dot NET Framework) following the key principles of Butterfly paradigm14,27. The work-flow of MSL is divided into two processes: (I) extraction and marginalization of text with respect to the division and placement of text in PDF file and keyword based search by using the iTextSharp, Bytescoute, Spire PDF libraries, and (II) extraction and analysis of figures by using the Spire PDF library and LEADTOOLS OCR.
It takes Portable Document Format (PDF) based literature files as input, performs partial physical structure analysis, and exports output in different formats e.g. text, images and XML files. It allows user to extract keywords and marginal (X and Y coordinates) information based text, have PDF file’s metadata information (title, author, creator, producer, subject, creation date, keywords, modified, number of pages and number of figures) and save extracted full and marginal text in text files.
Biomedical image extraction and analysis is one of the most complex tasks from the field of computer sciences and image analysis. Some of the mainstream approaches28–33 have been proposed towards the analysis of all kinds of images (e.g. flow charts, experimental images, models, geometrical shapes, graphs, image-of-thing, mix etc.). MSL allows user to automatically extracting images from the PDF files, let any selected image viewed via Windows default image viewer and apply implemented OCR. Other than extract images from PDF file, MSL allow user to load any image, apply OCR and export output in readable PDF file.
MSL produces several out files in the parent folder including XML files (which include structured or tagged information), Images File (extracted from PDF file) and PDF files for all analyzed images using OCR (Figure 5).

MSL application is very simple to install and use. It was tested and can be well configured on a Microsoft Windows platform (preferred OS version: 7). MSL follows a simple six steps installation process (Figure 6). After installation, it can be run by either clicking on the installed application’s icon at the desktop or execute application following sequence of steps: Start → All Programs → MSL 1.0.0 → MSL.
Regarding using the MSL application, one important point to remember is that it is based on different PDF text extraction, marginalization and figure extraction libraries, which are automatically configured during installation but used OCR by the LEADTOOLS is not a freely available library, which we have used upon academic research (free) license. The OCR library is also automatically configured during installation but its performance at different (non-licensed) machines is not confirmed. Moreover, the recommended display screen resolution size is 1680×1050 with landscape orientation.
The latest available and easy to use version of MSL has been tested and validated in-house. The advancements in information retrieval techniques for text and figure analysis combined with this sophisticated computational tool can support various studies. As future work, we are looking forward to further implement machine learning and pattern recognition methods for the extracted text classification.
F1000Research: Dataset 1. Extracted Images and Text from Papers tested using MSL, 10.5256/f1000research.7329.d10873943
The software executable is freely available at the following web link: https://zenodo.org/record/30941#.Vi0PtmC5LHM
The software download section provides one executable: MSL, setup to be installed on the Microsoft Windows platform.
MSL has been NOT been developed for any commercial purposes but as a non-commercial prototype application for academic research, analysis and development purposes.
Mining Scientific Literature (MSL) Ver 1.0.0 (DOI: 10.5281/zenodo.30941).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Click here to access the data.
Spreadsheet data files may not format correctly if your computer is using different default delimiters (symbols used to separate values into separate cells) - a spreadsheet created in one region is sometimes misinterpreted by computers in other regions. You can change the regional settings on your computer so that the spreadsheet can be interpreted correctly.
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)