Keywords
disease surveillance, outbreaks, epidemics, infectious, R, RECON
This article is included in the RPackage gateway.
This article is included in the Emerging Diseases and Outbreaks gateway.
disease surveillance, outbreaks, epidemics, infectious, R, RECON
Infectious disease outbreaks cause significant suffering and mortality in the affected populations, and damage the health, social and economic well-being of the families affected by diseases as well as producing significant economic costs for local and national governments. As we have seen with Ebola and SARS, disease outbreaks can spread beyond national borders1. Travelers can acquire a disease while staying in a foreign country, and then seed new outbreaks in their home country after their return. As international travel increases worldwide, new surveillance tools are needed to help identify locations where diseases are most likely to be spread and prevention measures need to be implemented. This is essential to limit the global spread of local outbreaks.
Recently, Dorigatti et al.2 developed a method to assess the risk of travel-related international spread of disease by integrating epidemiological and travel (by air, land and water) volume. The model developed by Dorigatti et al.2 estimates the expected number of infections introduced elsewhere by taking into account population flows, lengths of stay, as well as the variability of the disease incubation and infectious periods. The method was applied to quantify the risk of spread of a recent outbreak of yellow fever in Southeast Brazil in December 2016 to May 2017, and was able to identify the countries that could have received travel-related disease cases capable of seeding local transmission.
In this paper we present epiflows, an R package that implements the method presented by Dorigatti et al.2 for risk assessment of travel-related spread of disease. Using data on population movement between the location that is source of the infection and other locations, lengths of stay, as well as information about the disease incubation and infectious period distributions, the package allows the estimation of the number of (symptomatic and/or asymptomatic) infections that could be spread to other locations together with uncertainty measures. The package also provides tools for geocoding and visualization of population flows.
The remainder of the paper is organized as follows. First, we briefly describe the modelling framework that is implemented in the epiflows package. Second, we introduce the main components of epiflows including instructions for installation and main functions. Third, we illustrate the use of the package via the assessment of the risk of travel-related spread of yellow fever cases due to population flows between Southeast Brazil and other countries in December 2016 to May 2017. Specifically, we discuss the data required and show how to perform the statistical analyses, how to interpret the results, and the visualization options. Finally, the conclusions are presented.
In this Section we explain the modelling framework presented in 2 for estimating the expected number of infections departing from one infectious location during the incubation or infectious periods. These cases comprise exportations and importations. Exportations refer to the infected residents of the infectious location (i.e. location with sustained disease transmission) that travel to other locations. Importations (also referred to as returning travelers) are people that are infected during a temporary stay in the infectious location and then return to their home location. The following Sections describe how to model exportations and importations to produce the total number of expected cases that could be spread to other locations together with uncertainty measures.
Let CS,W denote the cumulative number of infections in location S in time window W. Here, W denotes the temporal window between the first and the last disease case in location S. Note that Dorigatti et al.2 calculated CS,W by multiplying the number of confirmed and reported yellow fever cases by 10 to account for underreporting of asymptomatic and mild yellow fever cases.
Let popS be the resident population of the infectious location S, and the number of residents of location S travelling to location D in time window W. The per capita probability that a resident from the infectious location travelled to other location D during the time window W is given by
The method assumes that the incubation period TE and the infectious period TI follow specific probability distributions. Using these, we can calculate the probability pi that an infection incubated or is infectious in time window W as
Finally, the number of residents of the infectious location S that are infected and travel abroad during their incubation or infectious period during the time window W can be calculated as
ES,D = CS,W × pD × pi.
That is, ES,D is a product of the cumulative number of infections in location S in time window W, the per capita probability that a resident of S travels to location D, and the probability that an infection incubated or is infectious in time window W.
Note here that if travel data are expressed annually instead of in the time window W, travel data in the time window can be obtained as = ( × W)/365.
Let be the number of travelers visiting location S from location O in time window W, and let LO denote the average length of stay. The per capita risk of infection of travelers visiting location S during their stay can be calculated as
The probability of returning to the home location while incubating or infectious is given by
Finally, the expected number of travelers infected during their stay in the infectious location and returning to their home location before the end of the infectious period can be calculated as the product of the number of travelers, the per capita risk of infection and the probability of returning home while incubating or infectious,
Note that, similarly to exportations, if travel data are expressed annually () instead of in the time window W, travel data in the time window can be obtained as = ( × W)/365.
Finally, the expected number of infections departing from the infectious location S to location O during the incubation or infectious periods can be computed as the sum of the number of infected residents of S travelling during their incubation or infectious periods, and the travelers from abroad that are infected during their stay in S and return to their origin location before the end of the infectious period. That is,
Average estimates and the relative uncertainty are calculated by taking into account the variability of the incubation and infectious periods. Specifically, the method samples a large number of times from the incubation and infectious distributions, which produces a full distribution for pi (the probability that a disease case is incubated or infectious in the time window considered) and pl (the probability of returning to the home location while incubating or infectious). This, in turn, creates variability in exportations ES,O and importations IS,O, and finally in the total number of infections introduced in location O, TS,O.
The R package epiflows [17] is hosted in the Comprehensive R Archive Network (CRAN) which is the main repository for R packages: http://CRAN.R-project.org/package=epiflows. Users can install epiflows in R by executing the following code:
install.packages("epiflows")
There is also a development version from GitHub which can be accessed at https://github.com/reconhub/epiflows. This version of the package may contain new features which are not incorporated in the version on CRAN yet but may be useful for some users. GitHub also includes issue tracking where users can note problems or suggestions for improvements. This development version from GitHub can be installed by using the install_github() function from the R package devtools3:
install.packages("devtools") library("devtools") install_github("reconhub/epiflows")
When installing epiflows, other R packages which epiflows depends on are also automatically installed. These packages include sp4 for manipulating spatial objects; geosphere5 for calculating distances between locations; and leaflet6 for visualization.
The main function of the package is estimate_risk_spread() which calculates the mean and 95% confidence intervals of the number of cases spread to different locations from an infectious location. It is also possible to use this function to produce a data frame with all simulations (not just the mean and 95% confidence intervals that is computed from the simulations). This permits the user to aggregate the estimates and calculate confidence intervals with different levels using single simulations. To execute this function the following information is needed:
population of the infectious location,
number of infections in the infectious location, and the first and last dates of reported cases,
number of travelers between the infectious location and other locations,
average length of stay of travelers from other locations visiting the infectious location,
distributions of the incubation and infectious periods,
number of simulations to be drawn from the incubation and infectious period distributions,
logical value indicating whether the returned object should be a data frame with all simulations, or a data frame with the mean and lower and upper limits of a 95% confidence interval of the number of infections spread to each location.
Other useful functions are plot() which produces visualizations of population flows between locations, and add_coordinates() which finds the coordinates of the locations.
In this Section we provide an example on how to use epiflows to calculate the number of yellow fever cases spreading from south-east Brazil to other countries due to human movement. We show how to define the arguments of the estimate_risk_spread() function, interpret the results, and make visualizations with the population flows.
We use the data YF_Brazil which is contained in the epiflows package as data(YF_Brazil). YF_Brazil is a list containing the population size, the assumed number of yellow fever infections, dates of first and last case reporting, number of travelers and length of stay for the states of Espirito Santo, Minas Gerais, Rio de Janeiro, Sao Paulo, and for the whole region of Southeast Brazil (which comprises the four states of Espirito Santo, Minas Gerais, Rio de Janeiro and Sao Paulo) in the period December 2016 to May 2017 [15], [16].
Following Dorigatti et al.2, the total number of yellow fever infections in each of the Brazilian states was calculated by multiplying the cumulative number of confirmed yellow fever cases reported in 7 by 10 to account for underreporting of asymptomatic and mild yellow fever cases. The dates of first and last case reported in each state were derived as described by Dorigatti et al.2. Population data were obtained from the Brazilian Institute of Geography and Statistics website8. YF_Brazil also contains the number of travelers in the specified time window between the states of Espirito Santo, Minas Gerais, Rio de Janeiro, Sao Paulo (and the whole Southeast Brazilian region) and other countries. These estimates were obtained from World Tourism Organization data on the volume of air, land and water border crossings for Brazil for the year 20159, having assumed that travelers were distributed across the Brazilian states according to the relative population density and having accounted for information on the monthly distribution of tourism and on the average duration of stay of international visitors to Brazil10, as detailed in 2.
YF_Brazil$states is a data frame that contains, for each Brazilian state considered in our example, the code (location_code), the population (location_population), the number of assumed infections in the time window (num_cases_time_window), and the dates of the first and last case reported (first_date_cases and last_date_cases, respectively).
library("epiflows")
## epiflows is loaded with the following global variables in `global_vars()`: ## coordinates, pop_size, duration_stay, first_date, last_date, num_cases
data("YF_Brazil") YF_Brazil$states ## location_code location_population ## Espirito Santo Espirito Santo 3973697 ## Minas Gerais Minas Gerais 20997560 ## Rio de Janeiro Rio de Janeiro 16635996 ## Sao Paulo Sao Paulo 44749699 ## Southeast Brazil Southeast Brazil 86356952 ## num_cases_time_window first_date_cases last_date_cases ## Espirito Santo 2600 2017-01-04 2017-04-30 ## Minas Gerais 4870 2016-12-19 2017-04-20 ## Rio de Janeiro 170 2017-02-19 2017-05-10 ## Sao Paulo 200 2016-12-17 2017-04-20 ## Southeast Brazil 7840 2016-12-17 2017-05-10
YF_Brazil$T_D represents and contains the number of travelers from each of the Brazilian states to other countries. YF_Brazil$T_O represents and contains the number of travelers from other countries to each of the Brazilian states.
YF_Brazil$T_D ## Italy Spain Portugal Germany United Kingdom ## Espirito Santo 2827.572 3270.500 3264.182 1897.668 1985.482 ## Minas Gerais 15714.103 18175.655 18140.543 10546.202 11034.228 ## Rio de Janeiro 8163.938 9442.787 9424.545 5479.062 5732.606 ## Sao Paulo 34038.681 39370.707 39294.650 22844.371 23901.496 ## Southeast Brazil 76281.763 88231.000 88060.554 51194.959 53564.010 ## United States of America Argentina Chile Uruguay ## Espirito Santo 13597.39 5898.905 2794.168 2629.526 ## Minas Gerais 75566.85 32782.895 15528.462 14613.472 ## Rio de Janeiro 39259.20 17031.678 8067.493 7592.129 ## Sao Paulo 163687.11 71011.787 33636.561 31654.581 ## Southeast Brazil 366828.00 159139.665 75380.598 70938.918 ## Paraguay ## Espirito Santo 1164.344 ## Minas Gerais 6470.791 ## Rio de Janeiro 3361.766 ## Sao Paulo 14016.531 ## Southeast Brazil 31411.489
YF_Brazil$T_O ## Italy Spain Portugal Germany United Kingdom ## Espirito Santo 1566.257 1170.954 1258.379 1740.967 1467.435 ## Minas Gerais 9196.588 6875.487 7388.819 10222.433 8616.336 ## Rio de Janeiro 4812.885 3598.175 3866.818 5349.744 4509.219 ## Sao Paulo 19950.571 14915.302 16028.896 22175.981 18691.803 ## Southeast Brazil 41998.783 31398.827 33743.100 46683.586 39348.898 ## United States of America Argentina Chile Uruguay ## Espirito Santo 4464.246 16125.23 2375.037 2072.586 ## Minas Gerais 26212.701 94682.45 13945.500 12169.597 ## Rio de Janeiro 13717.991 49550.52 7298.151 6368.761 ## Sao Paulo 56864.386 205398.89 30252.597 26400.052 ## Southeast Brazil 119707.601 432393.80 63686.009 55575.856 ## Paraguay ## Espirito Santo 2340.148 ## Minas Gerais 13740.640 ## Rio de Janeiro 7190.941 ## Sao Paulo 29808.186 ## Southeast Brazil 62750.462
Finally, YF_Brazil$length_of_stay is a vector with the lengths of stay (in days) of the travelers visiting Brazil from other countries.
YF_Brazil$length_of_stay ## Italy Spain Portugal ## 30.1 27.2 27.2 ## Germany United Kingdom United States of America ## 22.3 19.5 18.5 ## Argentina Chile Uruguay ## 10.9 10.3 8.0 ## Paraguay ## 7.3
To aid in data organization between flows and metadata, we have implemented the “epiflows” object. This inherits the “epicontacts” object from the epicontacts package11, storing three elements:
1. flows — a data frame defining the number of cases flowing from one location to another
2. locations — a data frame listing the locations present in flows and relevant metadata.
3. vars — a dictionary mapping column names in locations to known global variables defined in global_vars(). These global variables are used as default values in estimate_risk_spread().
An epiflows object can be created with the make_epiflows() function by providing a data frame flows with the number of travelers between locations, a data frame locations with information about the locations, and the names of the columns of data frame locations indicating the name of each variable.
In the data frame flows each row represents the number of travelers from one location to the next. flows has at least three columns: columns from and to indicating where the flow starts and ends, respectively, and column n indicating the number of travelers that are in the flow. We can create a data frame YF_flows with the population flows of the Brazil data as follows.
from <- as.data.frame.table(YF_Brazil$T_D, stringsAsFactors = FALSE) to <- as.data.frame.table(t(YF_Brazil$T_O), stringsAsFactors = FALSE) YF_flows <- rbind(from, to) colnames(YF_flows) <- c("from", "to", "n") head(YF_flows)
## from to n
## 1 Espirito Santo Italy 2827.572
## 2 Minas Gerais Italy 15714.103
## 3 Rio de Janeiro Italy 8163.938
## 4 Sao Paulo Italy 34038.681
## 5 Southeast Brazil Italy 76281.763
## 6 Espirito Santo Spain 3270.500In data frame locations each row represents a location, and columns specify useful information about the locations such as ID, population, number of cases, dates and length of stay. locations must contain at least one column specifying the location ID used in the flows data frame. We can create the data frame YF_locations by combining the data frame YF_Brazil$states containing the Brazil states information, and the vector YF_Brazil$length_of_stay containing the lengths of stay.
YF_locations <- YF_Brazil$states los <- data.frame(location_code = names(YF_Brazil$length_of_stay), length_of_stay = YF_Brazil$length_of_stay) YF_locations <- merge(YF_locations, los, by = "location_code", all = TRUE) head(YF_locations)
## location_code location_population num_cases_time_window
## 1 Espirito Santo 3973697 2600
## 2 Minas Gerais 20997560 4870
## 3 Rio de Janeiro 16635996 170
## 4 Sao Paulo 44749699 200
## 5 Southeast Brazil 86356952 7840
## 6 Argentina NA NA
## first_date_cases last_date_cases length_of_stay
## 1 2017-01-04 2017-04-30 NA
## 2 2016-12-19 2017-04-20 NA
## 3 2017-02-19 2017-05-10 NA
## 4 2016-12-17 2017-04-20 NA
## 5 2016-12-17 2017-05-10 NA
## 6 <NA> <NA> 10.9Then, we can create an epiflows object called Brazil_epiflows as follows.
Brazil_epiflows <- make_epiflows(flows = YF_flows, locations = YF_locations, pop_size = "location_population", duration_stay = "length_of_stay", num_cases = "num_cases_time_window", first_date = "first_date_cases", last_date = "last_date_cases" )
The arguments that need to be specified in estimate_risk_spread() to calculate the cases or infections introduced in other countries are as follows. The first argument is an epiflows object containing the number of travelers between locations, the population size, the number of cases, and the first and last dates of reporting in the infectious location, and the average length of stay in days of travelers from other locations visiting the infectious location.
The second argument of estimate_risk_spread() is location_code which is a character string denoting the infectious location code. We also need to specify the incubation and infectious period distributions. Specifically, we need to provide functions with a single argument n that generate n random incubation and infectious periods. In this example, we assume that the incubation period TE is log-normally distributed with mean 4.6 days and variance 2.7 days, and that the infectious period TI is normally distributed with mean 4.5 days and variance 0.6 days. We can define functions incubation() and infectious() as
incubation <- function(n) { rlnorm(n, 1.46, 0.35) } infectious <- function(n) { rnorm(n, 4.5, 1.5/1.96) }
Argument num_sim is the number of simulations to be drawn from the incubation and infectious period distributions. It is recommended to use at least 1,000 simulations. The last argument of estimate_risk_spread() is return_all_simulations. This is a logical value indicating whether the returned object should be a data frame with all simulations (return_all_simulations = TRUE), or a data frame with the mean and lower and upper limits of a 95% confidence interval of the number of infections spread to each location (return_all_simulations = FALSE).
Once we have constructed the objects needed to call estimate_risk_spread() we can execute the function and obtain the estimated mean number of cases spread to each country and the 95% confidence intervals. The code to calculate the cases spread from Espirito Santo is the following:
set.seed(2018-07-25) res <- estimate_risk_spread(Brazil_epiflows, location_code = "Espirito Santo", r_incubation = incubation, r_infectious = infectious, n_sim = 1e5 )
The results returned by estimate_risk_spread() are stored in the res object. This is a data frame with the columns mean_cases indicating the mean number of cases spread to each location, and lower_limit_95CI and upper_limit_95CI indicating the lower and upper limits of 95% confidence intervals. The result object is shown below.
res## mean_cases lower_limit_95CI upper_limit_95CI
## Italy 0.2233656 0.1520966 0.3078136
## Spain 0.2255171 0.1537452 0.3126801
## Portugal 0.2317019 0.1565528 0.3383112
## Germany 0.1864162 0.1259548 0.2721890
## United Kingdom 0.1613418 0.1195261 0.2089475
## United States of America 0.9253419 0.6252207 1.3511047
## Argentina 1.1283506 0.7623865 1.6475205
## Chile 0.2648277 0.1789370 0.3866836
## Uruguay 0.2408942 0.1627681 0.3517426
## Paraguay 0.1619724 0.1213114 0.1926966We can plot the results with ggplot() as follows (Figure 1).
library("ggplot2") res$location <- rownames(res) ggplot(res, aes(x = mean_cases, y = location)) + geom_point(size = 2) + geom_errorbarh(aes(xmin = lower_limit_95CI, xmax = upper_limit_95CI), height = .25) + theme_bw(base_size = 12, base_family = "Helvetica") + ggtitle("Yellow Fever Spread from Espirito Santo, Brazil") + xlab("Number of cases") + xlim(c(0, NA))
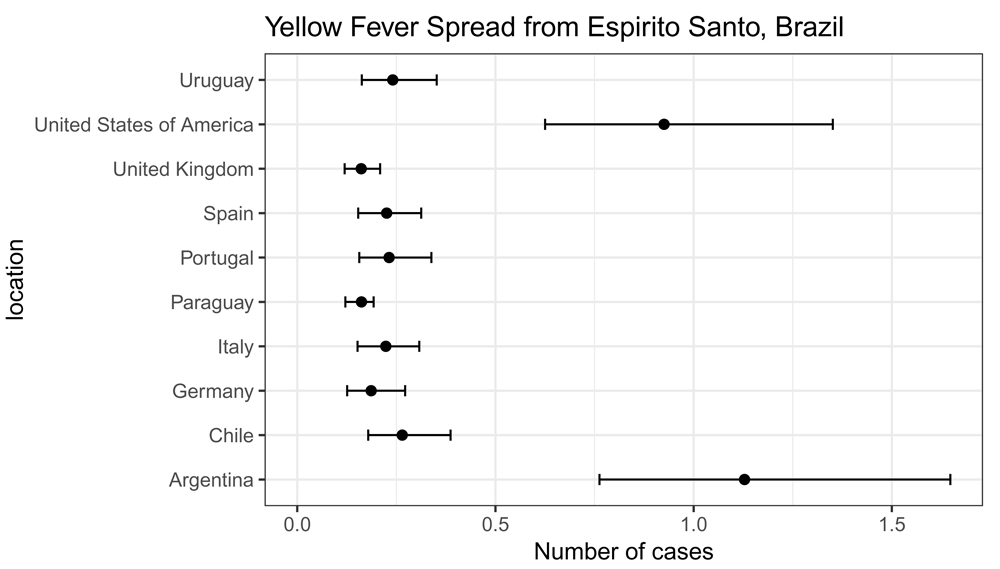
Note that if we set return_all_simulations equal to TRUE, the result object res will be a data frame with all simulations.
res <- estimate_risk_spread(Brazil_epiflows, location_code = "Espirito Santo", r_incubation = incubation, r_infectious = infectious, n_sim = 1e5, return_all_simulations = TRUE )
head(res)
## Italy Spain Portugal Germany United Kingdom
## [1,] 0.1946102 0.1967196 0.2003120 0.1611614 0.1483634
## [2,] 0.2861083 0.2875748 0.3035947 0.2442577 0.1937063
## [3,] 0.1883587 0.1904003 0.1938773 0.1559844 0.1455385
## [4,] 0.2128377 0.2151446 0.2190734 0.1762560 0.1566001
## [5,] 0.2087285 0.2109909 0.2148439 0.1728531 0.1547432
## [6,] 0.2747205 0.2744030 0.2853804 0.2296033 0.1857099
## United States of America Argentina Chile Uruguay Paraguay
## [1,] 0.7999806 0.9754866 0.2289530 0.2082646 0.1552200
## [2,] 1.2124582 1.4784567 0.3470033 0.3156478 0.1837588
## [3,] 0.7742827 0.9441508 0.2215983 0.2015745 0.1502338
## [4,] 0.8749078 1.0668519 0.2503970 0.2277709 0.1619986
## [5,] 0.8580163 1.0462546 0.2455627 0.2233735 0.1609097
## [6,] 1.1397160 1.3897558 0.3261846 0.2967103 0.1790695Using res, we can calculate the mean and 95% confidence intervals as follows.
meancases <- colMeans(res, na.rm = TRUE) quant <- t(apply(res, 2, stats::quantile, c(.025, .975), na.rm = TRUE)) data.frame(mean_cases = meancases, lower_limit_95CI = quant[, 1], upper_limit_95CI = quant[, 2] )
## mean_cases lower_limit_95CI upper_limit_95CI
## Italy 0.2233975 0.1522848 0.3081296
## Spain 0.2255621 0.1539354 0.3130456
## Portugal 0.2317602 0.1567465 0.3388166
## Germany 0.1864633 0.1261107 0.2725956
## United Kingdom 0.1613646 0.1196739 0.2091694
## United States of America 0.9255753 0.6259942 1.3531231
## Argentina 1.1286353 0.7633297 1.6499817
## Chile 0.2648933 0.1791584 0.3872613
## Uruguay 0.2409532 0.1629695 0.3522681
## Paraguay 0.1619776 0.1214615 0.1928268We can visualize flows of people travelling between locations using plot() and passing as first parameter an epiflows object containing the population flows, and as second parameter the type of plot we wish to produce. Population flows can be displayed on an interactive map, as a network or as a grid between origins and destinations as described in the following sections.
We can visualize population flows on an interactive map using plot() with the parameter type = "map". For this option to work, the epiflows object needs to include the longitude and latitude of the locations in decimal degree format. If coordinates are known, they can be added to the epiflows object using the add_coordinates() function from the epiflows package. In our example, the longitude and latitude data are in the data frame YF_coordinates.
data("YF_coordinates") head(YF_coordinates) ## id lon lat ## 1 Espirito Santo -40.30886 -19.18342 ## 2 Minas Gerais -44.55503 -18.51218 ## 3 Rio de Janeiro -43.17290 -22.90685 ## 4 Sao Paulo -46.63331 -23.55052 ## 5 Southeast Brazil -46.20915 -20.33318 ## 6 Argentina -63.61667 -38.41610
They can be added as follows.
Brazil_epiflows <- add_coordinates(Brazil_epiflows, coordinates = YF_coordinates[, -1])
If coordinates are unknown, we may resort to one of the freely available tools for geocoding. For example, we can use the geocode() function from the ggmap package12. This function finds the latitude and longitude of a given location using either the Data Science Toolkit or Google Maps. We can also use add_coordinates() which uses geocode() to find the coordinates and directly add them to the epiflows object as follows.
Brazil_epiflows <- add_coordinates(Brazil_epiflows, overwrite = TRUE)
Once we have assigned coordinates to the epiflows object, we can use plot() with type = "map" to visualize the population flows between locations in an interactive map (Figure 2).
plot(Brazil_epiflows, type = "map")
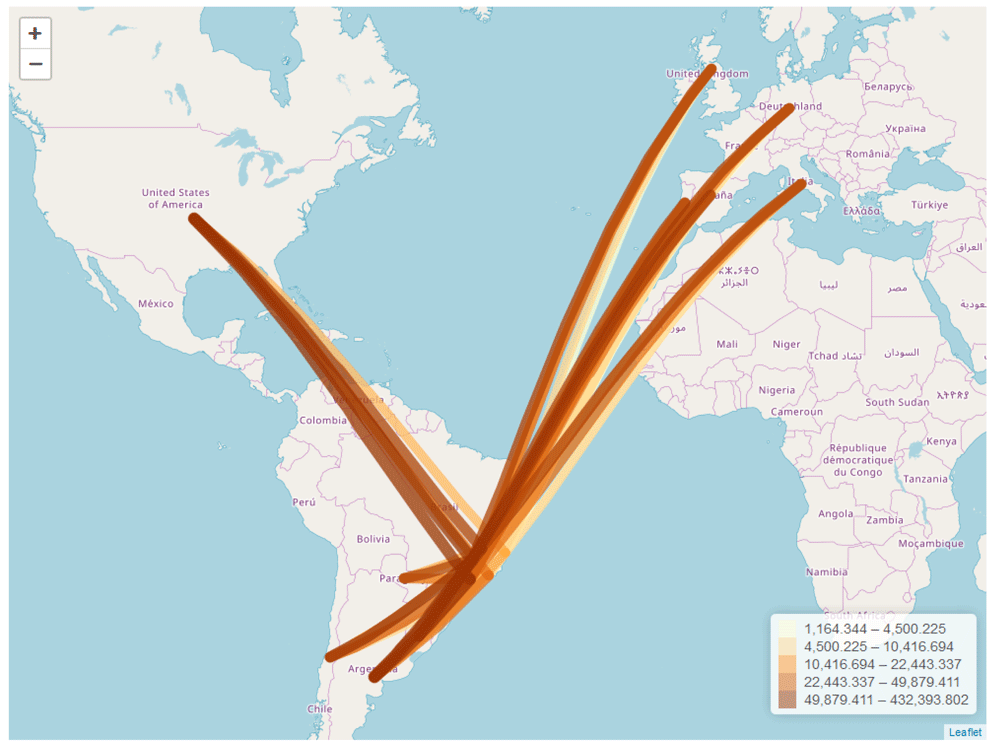
The produced map can be zoomed and permits an easy examination of flows. plot() uses the gcIntermediate() function from the geosphere package5 to obtain the great circle arcs between locations, and then uses the leaflet package6 to create an interactive map with the connection lines. The connection lines are coloured according to flow volume, and as the mouse passes over the lines, lines highlight and information about connections is shown. We can also include parameters to specify a title, the center of the map or a color palette. An interactive version of this visualization is shown here: https://www.repidemicsconsortium.org/epiflows/articles/introduction.html#introduction-epiflows-map.
Population flows can also be displayed as a dynamic network using plot() with type = "network" (Figure 3).
plot(Brazil_epiflows, type = "network")
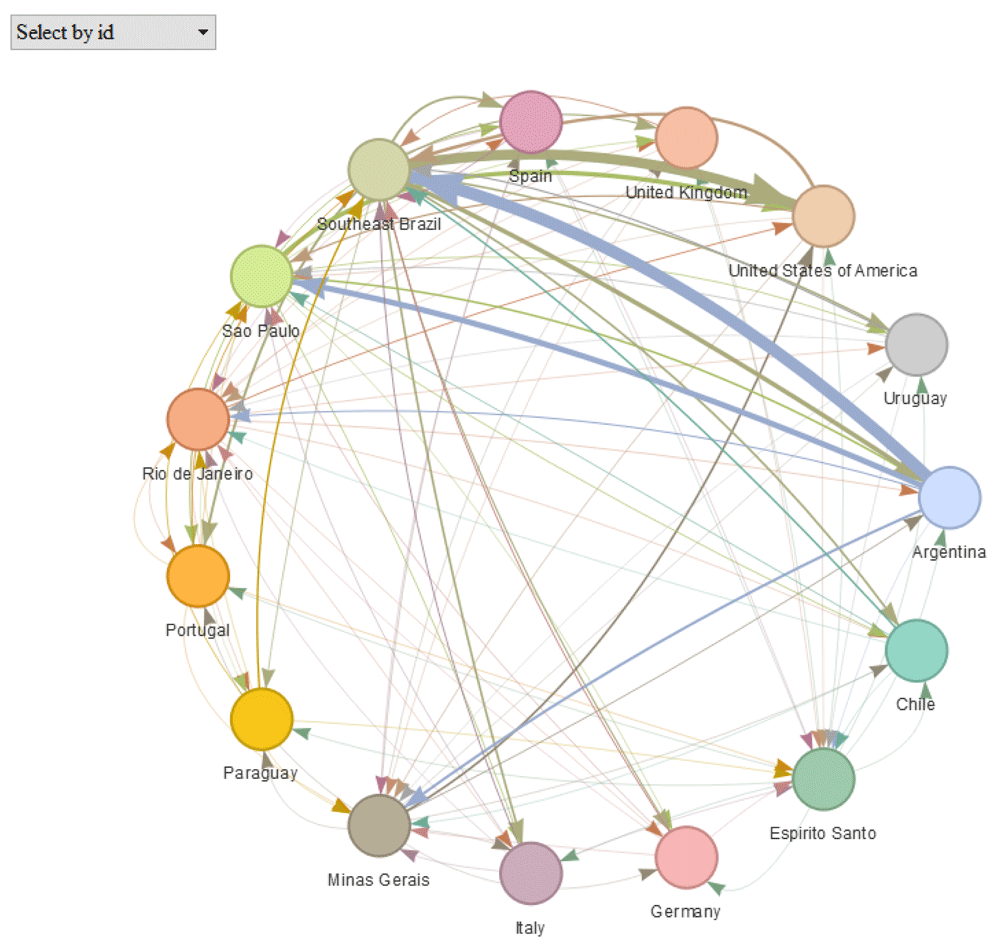
This option uses the package visNetwork13 to show the locations as nodes of a network and connections between them representing population flows. This plot is interactive and it is possible to highlight a given location and examine its population flows, as well as its population, number of cases, dates and length of stay. This type of plot can be used when coordinates of locations are missing. An interactive version of this plot can be viewed here: https://www.repidemicsconsortium.org/epiflows/articles/introduction.html#introduction-epiflows-vis.
Finally, population flows can also be shown as a grid between locations with the option type = "grid" (Figure 4).
plot(Brazil_epiflows, type = "grid")
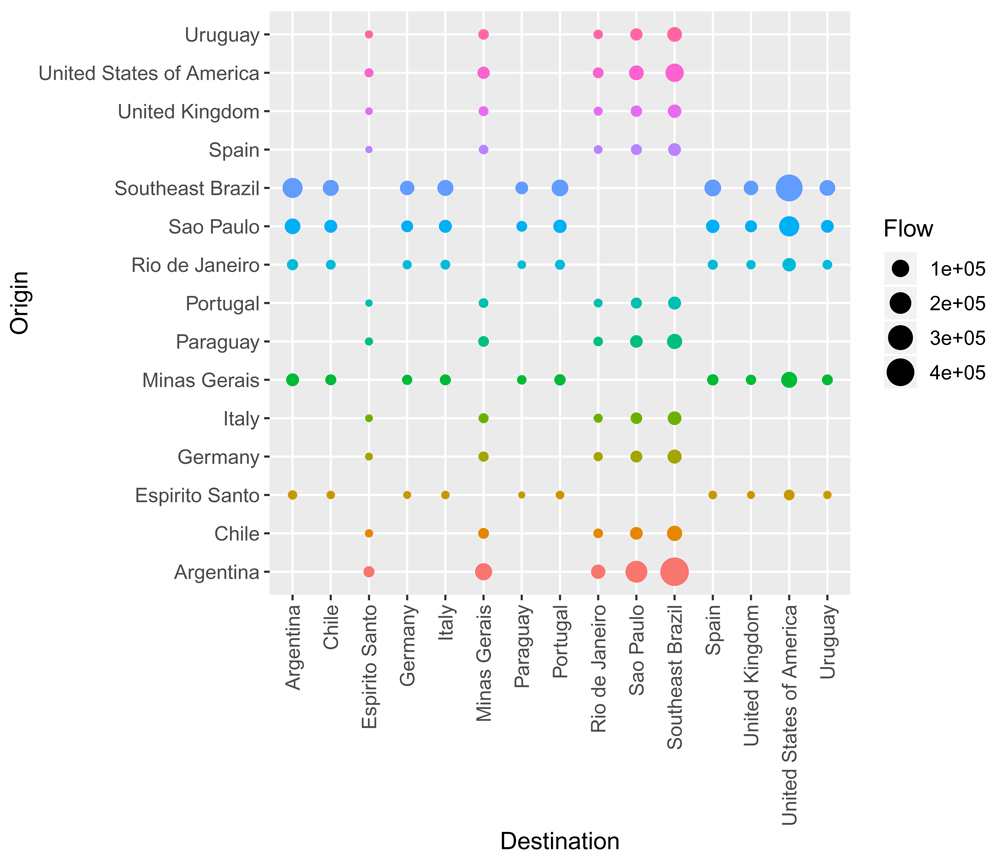
This plot shows flows between locations as points by positioning origins and destination in y and x axes, respectively. When using this option, additional arguments can be passed to set the size, color or shape of the points as in function geom_point() of package ggplot214. As the network plot, the grid plot can be used when coordinates of locations are missing.
In this article we have presented the epiflows package for risk assessment of travel-related spread of disease. This package allows the estimation of the expected number of infections that could be introduced to other locations from the source of infection by integrating data on the number of cases reported, population movement, length of stay and information on the distributions of the incubation and infectious periods of the disease. The package also provides tools for geocoding and visualization which facilitate the interpretation of the results.
First, we presented how to estimate exportations, importations and total number of infections using the modelling framework introduced by Dorigatti et al.2. Then, we demonstrated the use of the package by assessing the risk of travel-related spread of yellow fever cases in Southeast Brazil in December 2016 to May 2017. Specifically, we have shown how to construct an epiflows object containing population flows and information about locations, and how to use the function estimate_risk_spread() to obtain the average and confidence intervals of the estimated number of infections introduced elsewhere. Finally, we have shown how to visualize the results and produce maps of the population flows.
International travel has an important role in the spread of infectious diseases across national borders. We think the epiflows package represents a useful tool for disease surveillance that can help public health officials identify locations where diseases are most likely to spread and prevention measures are most needed.
Dataset 1. Arrivals of non-resident tourists at Brazilian national borders by country of residence. Annual volumes of air, land and water border crossings for Brazil relative to inbound tourism from years 2011 to 2015 obtained from the World Tourism Organisation. https://doi.org/10.5256/f1000research.16032.d21576315.
Dataset 2. Trips abroad by Brazilian resident visitors to countries of destination. Annual volumes of air, land and water border crossings for Brazil relative to outbound tourism from years 2011 to 2015 obtained from the World Tourism Organisation. https://doi.org/10.5256/f1000research.16032.d21576516.
1. Dedicated website for epiflows, including installation guidelines and documentation: https://www.repidemicsconsortium.org/epiflows
2. Software available from: https://cran.r-project.org/package=epiflows
3. Source code available from: https://github.com/reconhub/epiflows
4. Archived source code at time of publication: http://doi.org/10.5281/zenodo.140180617.
5. Software license: MIT License
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Click here to access the data.
Spreadsheet data files may not format correctly if your computer is using different default delimiters (symbols used to separate values into separate cells) - a spreadsheet created in one region is sometimes misinterpreted by computers in other regions. You can change the regional settings on your computer so that the spreadsheet can be interpreted correctly.
Click here to access the data.
Spreadsheet data files may not format correctly if your computer is using different default delimiters (symbols used to separate values into separate cells) - a spreadsheet created in one region is sometimes misinterpreted by computers in other regions. You can change the regional settings on your computer so that the spreadsheet can be interpreted correctly.
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)