Keywords
high-throughput sequencing, metagenome, metagenomics, next generation sequencing, alpha diversity, complex matrices
high-throughput sequencing, metagenome, metagenomics, next generation sequencing, alpha diversity, complex matrices
In this version we incorporated all the suggestions of the reviewers.
Reviewer Alejandro Sanchez-Flores:
See the authors' detailed response to the review by Alejandro Sanchez-Flores
See the authors' detailed response to the review by Marcus Claesson and Shriram Patel
See the authors' detailed response to the review by José F. Cobo Diaz
See the authors' detailed response to the review by Francesco Dal Grande
Shotgun metagenomics offers the possibility to assess the complete taxonomic composition of biological matrices and to estimate the relative abundances of each species in an unbiased way1,2. It allows to agnostically characterize complex communities containing eukaryotes, fungi, bacteria and also viruses.
Metagenome shotgun high-throughput sequencing has progressively gained popularity in parallel with the advancing of next-generation sequencing (NGS) technologies3,4, which provide more data in less time at a lower cost than previous sequencing techniques. This allows the extensive application to study the most various biological mixtures such as environmental samples5,6, gut samples7–9, skin samples10, clinical samples for diagnostics and surveillance purposes11–14 and food ecosystems15,16. Another, more traditional approach currently used to assign taxonomy to DNA sequences is based on the sequencing of target conserved regions. Metabarcoding method relies on conserved sequences to characterize communities of complex matrices. These include the highly variable region of 16S rRNA gene in bacteria17, the nuclear ribosomal internal transcribed spacer (ITS) region for fungi18, 18S rRNA gene in eukaryotes19, cytochrome c oxidase sub-unit I (COI or cox1) for taxonomical identification of animals20, rbcL, matK and ITS2 as the plant barcode21. Metabarcoding has the advantage of reducing sequencing needs, since it does not require sequencing of the full genome, but just a marker region. On the other hand, given the commonly used approaches, characterization of microbial and eukaryotic communities requires different primers and library preparations22. In addition, several studies suggested that whole shotgun metagenome sequencing is more effective in the characterization of metagenomics samples compared to target amplicon approaches, with the additional capability of providing functional information regarding the studied approaches23.
Current whole shotgun metagenome experiments are performed obtaining several million reads5,8. However, obtaining a broad characterization of the relative abundance of different species, might easily be achieved with lower number of reads.
To test this hypothesis, we analzyed ten samples (eight sequenced in the framework of this study and two retrieved from the literature) derived from different complex matrices using whole metagenomics approach and tested accuracy of several summary statistics as a function of the reduction of the number of reads used for analysis. The selection of samples belonging to different matrices with distinct characteristics enabled to understand if the results are generally applicable and, if this is not the case, which are the features with the greatest impact on results.
In summary, the aim of the present work is to test the effect of the reduction of sequencing depth on 1) estimates of diversity and species richness in complex matrices; 2) estimates of abundance of the species present in the complex matrix, and 3) completeness of de novo reconstruction of the genome of the species present in the samples. To assess the consistency of our approach, we selected samples characterized by different levels of species richness and by different relative abundance of prokaryotic and eukaryotic organisms and viruses. In addition, publicly available viral particle enriched sequencing data was used to extend our analysis to viruses. Finally, we included in the study a mock community sample with known species composition.
Some of the samples were predominantly composed by eukaryotic organisms, while others were composed by prokaryotes or viruses; some were represented by very few dominant species while others had greater diversity. Results that were observed across such dissimilar samples are likely to be of general validity.
The following samples were used in the present work: the mock community DNA sample “20 Strain Staggered Mix Genomic Material” ATCC® MSA-1003TM (short name: A1), two biological medicines (B1 and B2), two horse fecal samples (F1 and F2), three food samples (M1, M2, and M3), and two human faecal samples (V1 and V2).
Biological medicines were two different lots of live attenuated MPRV vaccine, widely used for immunisation against measles, mumps, rubella and chickenpox in infants. Lyophilised vaccines were resuspended in 500 μl sterile water for injection and DNA extracted from 250 μl using Maxwell® 16 Instrument and the Maxwell® 16 Tissue DNA Purification Kit (Promega, Madison, WI, USA) according to the manufacturer's instructions. The vaccine composition declared by the producer is the following: live attenuated viruses: 1) Measles (ssRNA) Swartz strain, cultured in embryo chicken cell cultures; Mumps (ssRNA) strain RIT 4385, derived from the Jeryl Linn strain, cultured in embryo chicken cell cultures; Rubella (ssRNA) Wistar RA 27/3 strain, grown in human diploid cells (MRC-5); Varicella (dsDNA) OKA strain grown in human diploid cells (MRC-5).
Horse feces from two individuals were processed as follows: 100 mg of starting material stored in 70% ethanol were used for DNA extraction using the QIAamp PowerFecal DNA Kit (QIAGEN GmbH, Hilden, Germany), according to the manufacturer's instructions.
Food samples were raw materials of animal and plant origin, used to industrially prepare bouillon cubes. DNA extractions from those three samples were performed starting from 2 grams of material each, using the DNeasy mericon Food Kit (QIAGEN GmbH, Hilden, Germany), according to the manufacturer's instructions. The declared sample composition was Agaricus bisporus for M1, spice (Piper nigrum) for M2 and mix of animal extracts for M3.
The mock community declared components are: 0.18% Acinetobacter baumannii (ATCC 17978), 0.02% Actinomyces odontolyticus (ATCC 17982), 1.80% Bacillus cereus (ATCC 10987), 0.02% Bacteroides vulgatus (ATCC 8482), 0.02% Bifidobacterium adolescentis (ATCC 15703), 1.80% Clostridium beijerinckii (ATCC 35702), 0.18% Cutibacterium acnes (ATCC 11828), 0.02% Deinococcus radiodurans (ATCC BAA-816), 0.02% Enterococcus faecalis (ATCC 47077), 18.0% Escherichia coli (ATCC 700926), 0.18% Helicobacter pylori (ATCC 700392), 0.18% Lactobacillus gasseri (ATCC 33323), 0.18% Neisseria meningitidis (ATCC BAA-335), 18.0% Porphyromonas gingivalis (ATCC 33277), 1.80% Pseudomonas aeruginosa (ATCC 9027), 18.0% Rhodobacter sphaeroides (ATCC 17029), 1.80% Staphylococcus aureus (ATCC BAA-1556), 18.0% Staphylococcus epidermidis (ATCC 12228), 1.80% Streptococcus agalactiae (ATCC BAA-611), 18.0% Streptococcus mutans (ATCC 700610).
DNA purity and concentration were estimated using a NanoDrop Spectrophotometer (NanoDrop Technologies Inc., Wilmington, DE, USA) and Qubit 2.0 fluorometer (Invitrogen, Carlsbad, CA, USA).
Human fecal samples V1 and V2 derive from a study investigating the virome composition of feces of Amerindians24. The two samples with the highest sequencing depth were choosen. Sequences were retrieved from SRA (SRR6287060 and SRR6287079, respectively).
DNA library preparations were performed according to manufacturer’s protocol, using the kit Ovation® Ultralow System V4 1–96 (Nugen, San Carlos, CA). Library prep monitoring and validation were performed both by Qubit 2.0 fluorometer (Invitrogen, Carlsbad, CA, USA) and Agilent 2100 Bioanalyzer DNA High Sensitivity Analysis kit (Agilent Technologies, Santa Clara, CA). Obtained DNA concentrations were as follows: A1 8 ng/µl (total amount = 640 ng), B1 10.7 ng/µl (total amount = 535 ng), B2 9.41 ng/µl (total amount = 470.5 ng), F1 42.3 ng/µl (total amount = 4,230 ng), F2 22.6 ng/µl (total amount = 2,260 ng), M1 16.6 ng/µl (total amount = 1,494 ng), M2 1.87 ng/µl (total amount = 168.3 ng), M3 16 ng/µl (total amount = 640 ng).
Cluster generation was then performed on Illumina cBot and flowcell HiSeq SBS V4 (250 cycle), and sequenced on HiSeq2500 Illumina sequencer producing 125bp paired-end reads.
Samples F1 and F2 were loaded on flowcell HiSeq Rapid SBS Kit v2 (500 cycles) producing 250bp paired-end reads. The estimated library insert sizes were: 539 bp (A1), 531 bp (B1), 536 bp (B2), 620 bp (F1), 620 bp (F2), 342 bp (M1), 178 bp (M2), 496 bp (M3). Samples were sequenced in different runs and pooled with other libraries of similar insert sizes.
The CASAVA Illumina Pipeline version 1.8.2 was used for base-calling and de-multiplexing. Adapters were masked using cutadapt25. Masked and low quality bases were filtered using erne-filter version 1.4.6.26. Bioinformatics analysis.
The bioinformatics analysis performed in the present work are summarized in Figure 1; a standard pipeline for reproducing the main steps of analysis is available on GitHub27.
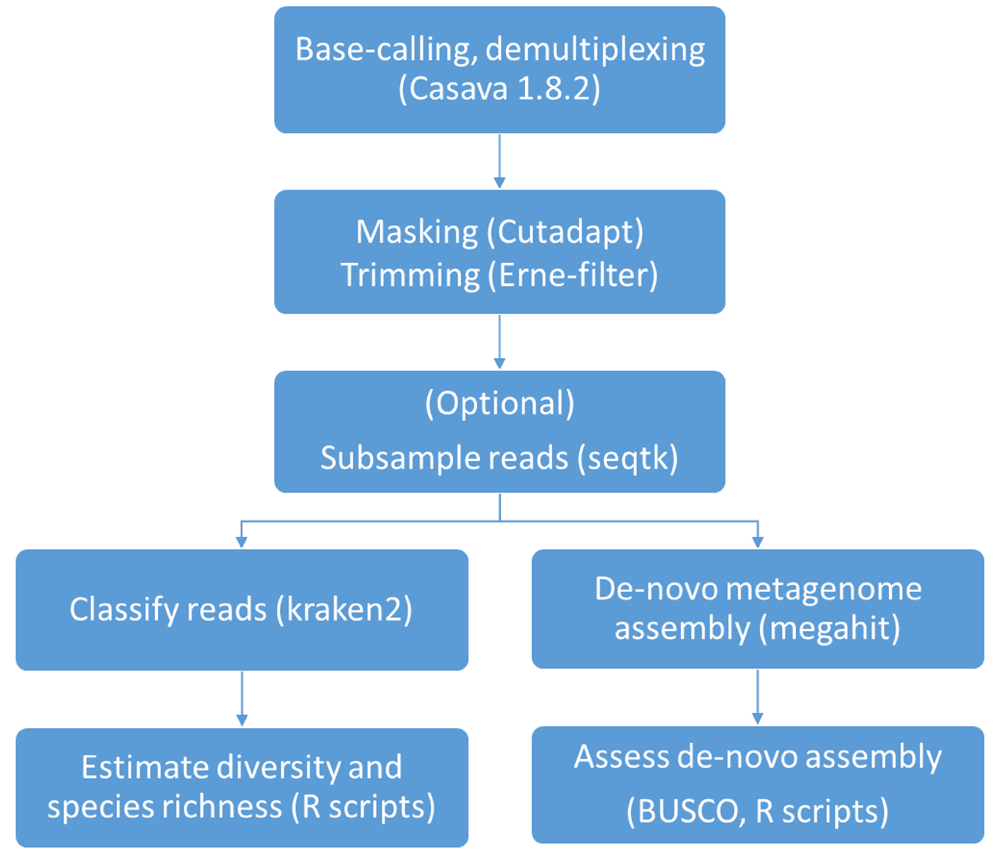
Since different read lengths among samples may constitute an additional confounder in analysis, 250 bp long reads belonging to F1, F2, V1 and V2 were trimmed to a length of 125bp using fastx-toolkit version 0.0.13 (http://hannonlab.cshl.edu/fastx_toolkit/) before subsequent analysis.
Reduction in coverage was simulated by randomly sampling a fixed number of reads from the full set of reads. Subsamples of 10,000, 25,000, 50,000, 100,000, 250,000, 500,000 and 1,000,000 reads were extracted from the raw reads using seqtk version 1.3. To estimate the variability due to random effects, subsampling was replicated five times for each simulated depth and 99% confidence limits were estimated and plotted.
To classify the largest possible number of prokaryotes, eukaryotes and viruses, reads were classified against the complete NCBI nt database using kraken2, version 2.0.628. The nt database was converted to kraken2 format using the built-in kraken2-build script with default parameters. Among the most significant parameters, kmer size for the database is by default set to 35 and the minimizer length to 31. A simplified representation of species composition was obtained using Krona29.
Observed number of taxa, Chao1 species richness30, Good’s coverage31, Shannon’s diversity index32 and Pielou’s index33 were estimated using the R package vegan version 2.4.234 or base R functions. The number of observed taxa was computed as the number of species to which at least one read was assigned. The number of singletons is defined as the number of species identified by only one read. The number of core species is the number of species with frequency equal or greater than 1‰. We then define the measure S90, obtained as follow: a) sort species in decreasing abundance, b) perform cumulative sum of the species abundance, and c) report how many of the ordered species are needed to reach an abundance equal or greater to 90% of the total number of reads.
Assembly of the metagenome was performed using megahit version 1.1.235 with default parameters, with kmer sizes varying as follows: 21, 29, 39, 59, 79, 99, 119, 141. Reconstructed contigs were classified at the species level using kraken2. Completeness of the assemblies of each species was assessed using BUSCO36. For each species, the proportion of the reconstructed genes was measured as the proportion of genes that were fully reconstructed, plus the proportion of genes that were partially reconstructed. For each sample, results were then averaged over species to provide the average proportion of reconstructed genes. BUSCO analysis was performed on prokaryotic database for all the samples with the exception of M1 (predominanty composed by fungi) for which the fungal database was used.
Unless otherwise specified, all the analysis were performed using R 3.3.337.
Summary statistics for the full samples included in the study are shown in Table 1.
Core: number of species with frequency greater than 1‰. N species: number of species identified in the sample; include species identified by one or more reads. Singletons: number of species identified in the sample by only one read. % Top 20: percentage of reads assigned to the 20 most abundant species. % Top 100: percentage of reads assigned to the 100 most abundant species. S90: Number of species accounting for 90% of the reads.
The number of reads obtained in the samples selected for the present study ranged from slightly more than 1 million (sample V1) to more than 12 millions (sample F1). The number of species identified in each sample was very high, ranging from 2,508 in sample B1 to 29,661 in sample F1. However, the 20 most abundant species accounted for a large proportion of the reads in each sample, from 74.62% in M2 to 99.75% in B1, and the 100 most abundant species accounted for 84.7% in M2 and 99.8% in B1. In sample A1 98.8% of the reads were assigned to the 20 declared species, and only 1.2% of reads were either unassigned or uncorrectly attributed to other species. To ensure that our conclusions have a general validity, we selected samples originating from very different sources with different compositions, and sequenced them at different depths. Figure 2 summarizes the composition of each sample at the Phylum level. Viruses are aggregated at the division level. Only phyla more abundant than 1% were plotted. Reads that were either unclassified or assigned to rare phyla were aggregated under the name “Unknown/Other”. Samples B1, B2 and M3 where mainly composed of Chordata, sample M1 was mostly composed by Basidiomycota, and sample V2 was mainly composed of Viruses. Samples F1, F2 and, to a lesser extent, M2 were characterized by a large proportion of reads unclassified or assigned to rare phyla. For a more detailed view of raw taxonomy composition, interactive html Chrona are available for download on Open Science Framework (https://osf.io/y7c39/), under the project “Do you cov me”, DOI: 10.17605/OSF.IO/Y7C39.
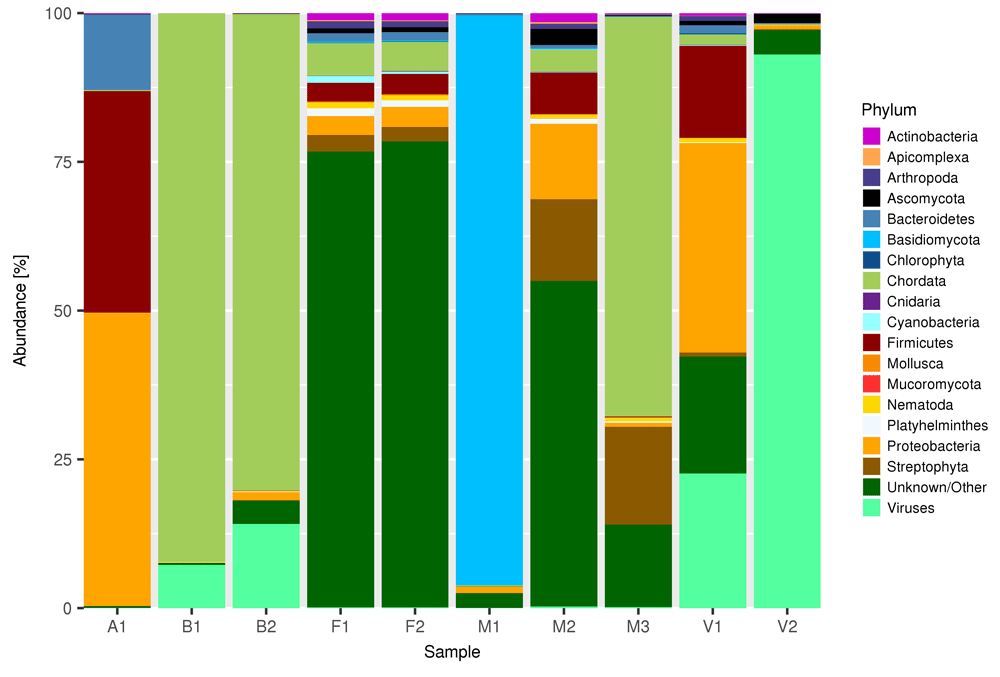
Only phyla represented by at least 1% of the reads are shown. Viruses are presented at division level. Unclassified reads and reads assigned to rare phyla are aggregated under the name “Unknown/Other”.
The mock community sample “20 Strain Staggered Mix Genomic Material” (ATCC® MSA-1003TM) was used as a reference to control performance of sequencing and classification procedures at various depth. The community includes a total of 20 bacterial species, of which 5 have a frequency of 0.02%, 5 a frequency of 0.18%, 5 a frequency of 1.8% and 5 a frequency of 18%.
Figure 3 shows the scatterplot (in logarithm scale) of the observed and expected abundance of organisms of the mock community at different taxonomic levels, from Sepcies to Phylum when using the full-dataset (4.9 M of reads). The correlation between the two measures is high even at the species level (r=0.87), and increases for higher taxonomic levels reaching 0.95 at Class and Phylum level.
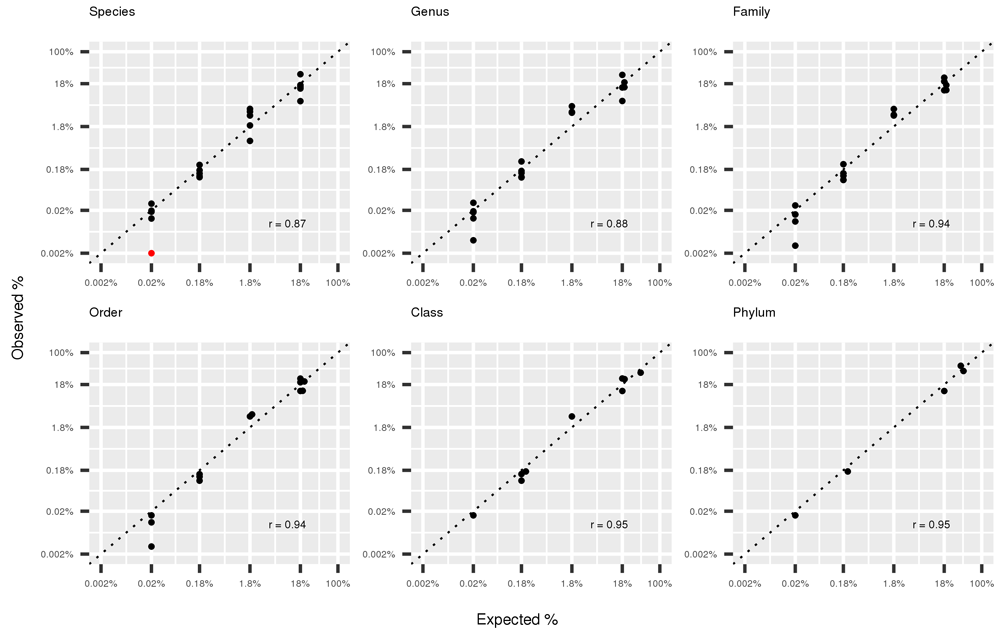
In red Actinomyces odontolyticus identified at frequency <0.002%, arbitrarily plotted at 0.002%.
The correlation between expected and observed abundancies of the 20 mock species remained high when decreasing sequencing depth, and Pearson’s correlation coefficient remains stable at 0.87 at all the investigated sequencing depths. Results for the hwole depth, 1,000,000 reads, 25,000 reads and 10,000 reads, together with 95% intervals are shown in Figure 4.
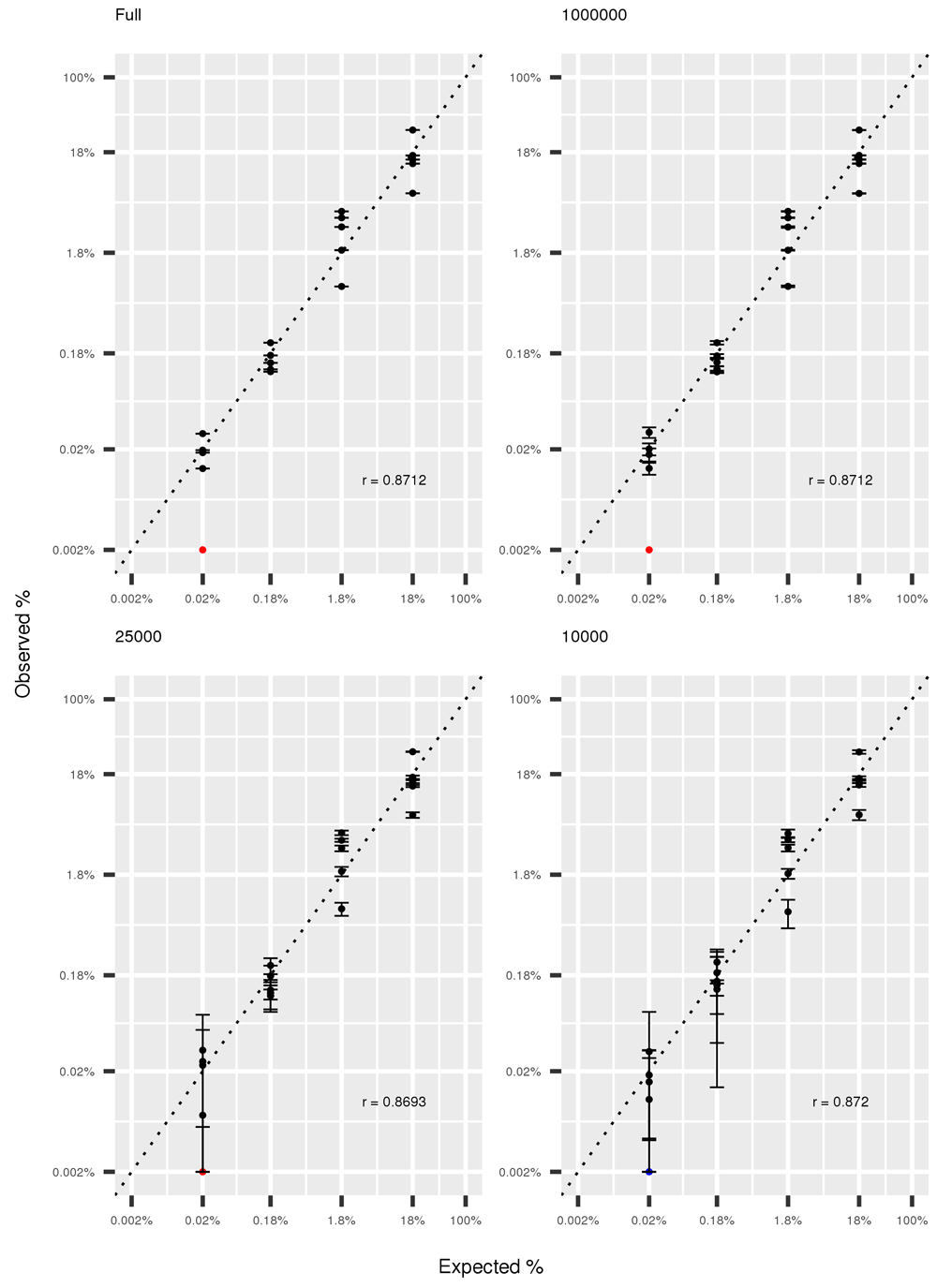
In red Actinomyces odontolyticus identified at frequency <0.002%, arbitrarily plotted at 0.002%. Error bars represent 95% confidence intervals obtained from five resampling experiments.
Figure 5 shows the variation of several summary statistics as a function of the number of reads used for the analysis, from the smallest (10,000 reads) on the left, to the full dataset on the right. Panels A and B show the observed number of taxa and the value of Chao1 (expected number of taxa) respectively. The two measures have very similar trend, with a swift decrease in horse feces (F1 and F2) when going from full set to 1,000,000 reads, and a relatively slow decrease in all other samples and subsets.
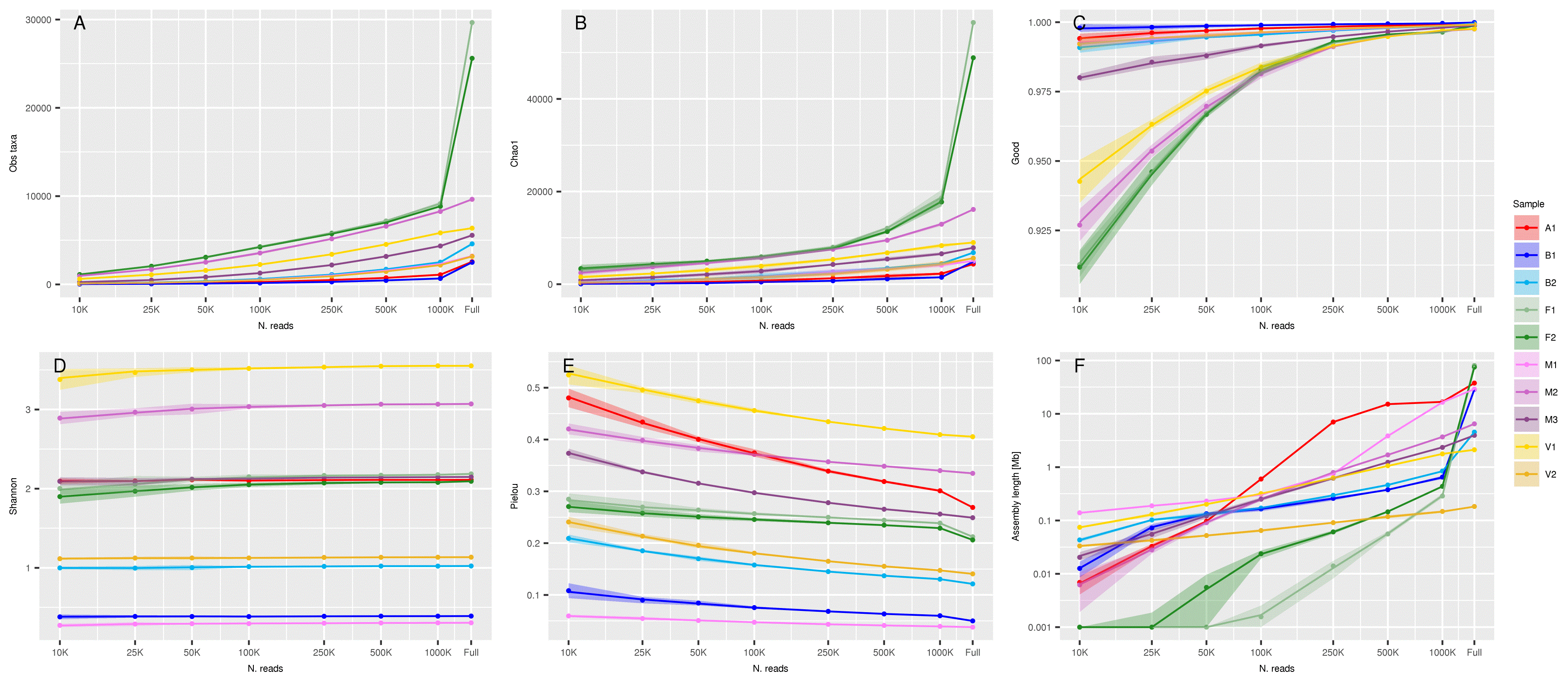
Effect of reduction of sequencing depth on: A) Observed number of taxa, B) Chao1 estimated number of taxa, C) Good’s Coverage, D) Shannon’s diversity index, E) Pielou’s diversity index, and F) Total length of de novo assembly. In all panels X axis is in log scale and Y axis is in linear scale with the exception of panel F, in which both axes are in log scale. Shaded areas represent the confidence limits of resampling experiments. “Full” represents the values obtained with the full set of reads.
Downsampling has different effects on the observed and estimated number of species in different samples. For most samples, even a robust downsampling led to only a slight reduction in the estimated species richness. However, for samples F1 and F2, characterized by a high number of species including rare ones, the downsampling led to a significant reduction (panels A and B). Good’s coverage (panel C) remained nearly constant when more than 100K reads were sequenced. Lower sequencing depth determined a decrease in Good’s coverage, especially for samples F1, F2, M2 and V1.
Shannon’s diversity index (panel D) is a widely used method to assess biological diversity of ecological and microbiological communities. The effect of sequencing depth on Shannon’s diversity index is negligible for all samples.
Pielou’s index (panel E) is a measure of the species’ distribution evenness. Values close to 1 denote equifrequent species, and lower values denote uneven distribution of species relative abundance. The effect of the number of reads on Pielou’s index is moderate.
Figure 6 shows the correlation in species abundance estimation between the full dataset and a reduced dataset of 100,000 reads. The linear correlation coefficient between the two datasets was >0.99 in all five subsampling replicates. The plot is in log-log scale to emphasize differences in low abundance species. Only the relative abundance estimation of species with frequencies lower than 0.01% (i.e . species represented by 1 read out of 10,000) was affected by subsampling. The same pattern was observed in all examined samples.
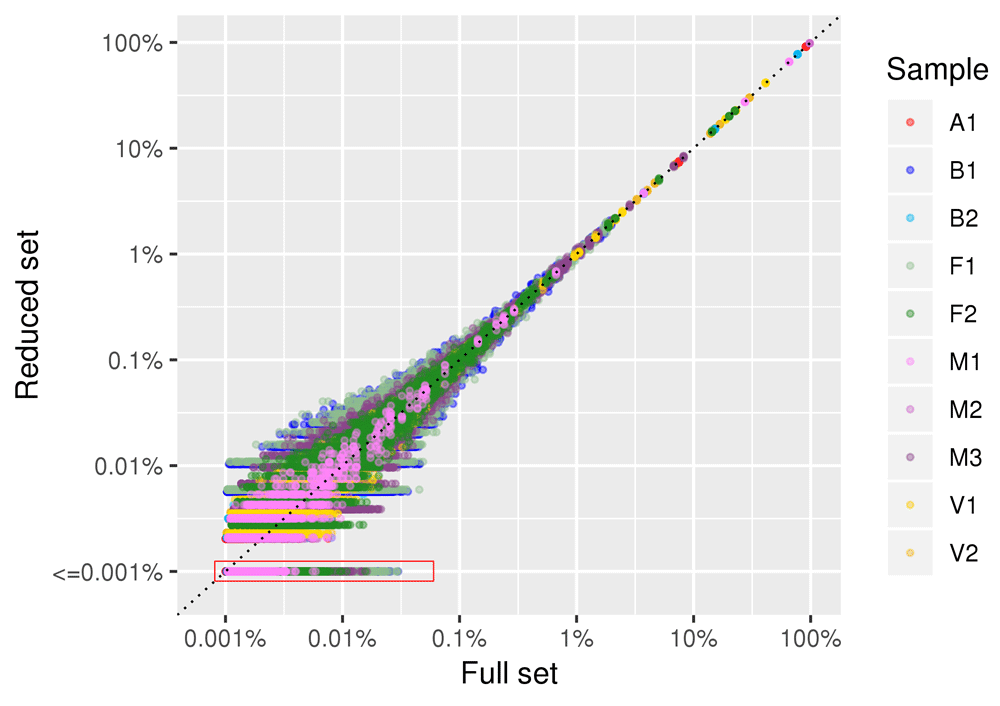
Data for all the five subsampled replicates are plotted. Each point (colored by sample of origin) represents a given species. Both axis are plotted in log scale to facilitate visualization of low abundance species. A red box encompasses datapoints of species that were present in the full set and absent in the reduced set, for which the frequency in the reduced set was set at “<=0.001%”.
In Figure 7 we show the results obtained by reducing the number of sampled reads to 10,000 reads per sample. Similarly to what we observed for 100,000 reads depth, the linear correlation coefficient between species abundance estimate in the full and the reduced dataset was high (r>0.95) for all the samples and in all five subsampling replicates. Only rare species with frequencies lower than 1/1000 (0.1%) in full dataset showed some deviation.
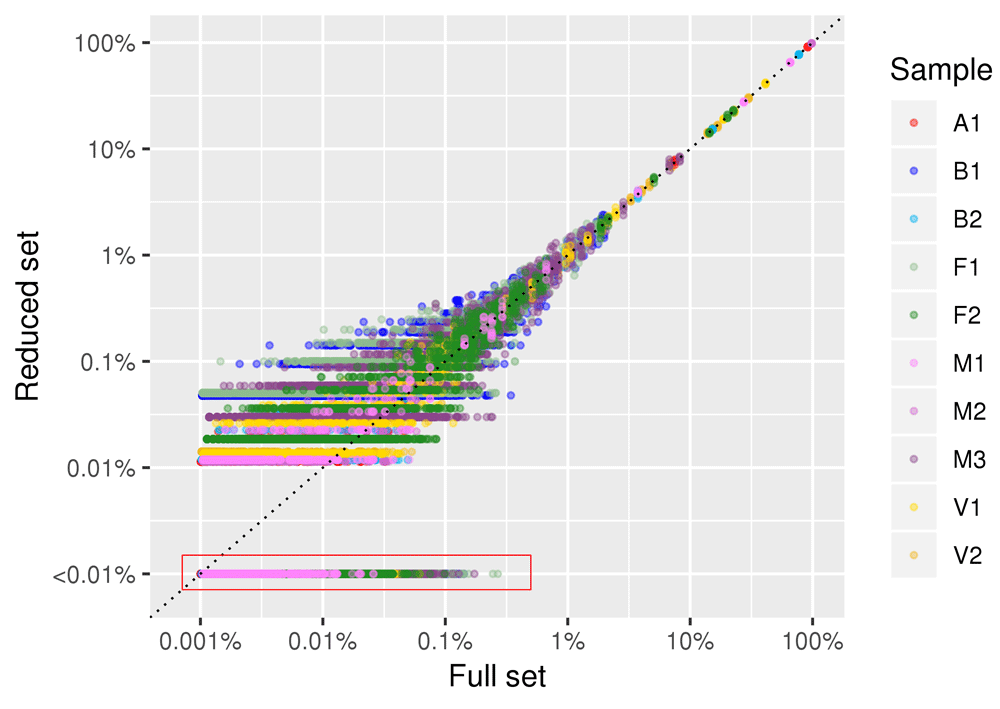
Data for all the five subsampled replicates are plotted. Each point (colored by sample of origin) represents a given species. Both axis are plotted in log scale to facilitate visualization of low abundance species. A red box encompasses datapoints of species that were present in the full set and absent in the reduced set, for which the frequency in the reduced set was set at “<0.01%”.
Since the reduction of the sequencing depth inevitably affects the ability of detecting rare species, we determined the minimum frequency required for a species to be identified at each sequencing depth. This detection threshold at any given sequencing depth was defined as follows: a) for each sample, identify all the species that are present in all five subsampling replicates; b) among the species identified, for each sample select the one with the lowest frequency in the full dataset; c) average the lowest frequencies across all samples. Table 2 shows the average and standard deviation of the detection threshold across the ten samples at any sequencing depth. At 10,000 reads depth, the detection threshold was 0.0124%. This means that species with frequencies higher than 0.0124% in full dataset were consistently identified also in the reduced datasets, while species with lower frequencies may be lost. At 1,000,000 reads depth the detection threshold was 0.00006% (i.e. 60 reads per million).
N. reads: Number of reads. Detection threshold (%): Detection threshold averaged across the ten samples, SD(%): Standard deviation of the detection threshold.
| N. reads | Detection threshold (%) | SD (%) |
|---|---|---|
| 10,000 | 0.01242 | 0.006312 |
| 25,000 | 0.00348 | 0.001719 |
| 50,000 | 0.00189 | 0.001078 |
| 100,000 | 0.00069 | 0.000536 |
| 250,000 | 0.0001 | 6.53E-05 |
| 500,000 | 0.00007 | 4.77E-05 |
| 1,000,000 | 0.00006 | 4.9E-05 |
We investigated the effect of coverage reduction on the completeness of de novo assembly. We reconstructed the metagenome of the full and reduced datasets and compared the completeness of the reconstructed genomes. Results are summarized in Figure 5 (panel F). As expected, the size of the assembly was strongly influenced by the sequencing depth. Assembly size for the full dataset ranged from less than 1 Mb (V2) to nearly 100 Mb (F1 and F2). A decrease in the sequencing depth led to a steady decrease in assembly size in all samples. At 1,000,000 reads the size ranged from slightly more than 100 kb (V2) to slightly more than 10Mb (A1 and M1).
BUSCO analysis36 was used as an additional measure to assess the completeness of the reconstructed metagenome. The proportion of reconstructed genes in full (X axis) and reduced (Y axis) datasets obtained by randomly sampling 1,000,000 reads is shown in Figure 8. In samples A1 and M1, on average 80% of the BUSCO genes were reconstructed in the full dataset. Reducing sequencing depth to 1,000,000 reads lowered the porportion of reconstructed genes in the two samples to 50% or less. In the remaining samples the proportion of reconstructed genes was very low even in the full dataset and the reduction of sequencing depth did not significantly alter the proportion.
We set out to test the effect of the reduction of sequencing depth on 1) estimates of diversity and species richness; 2) estimates of abundance of the species present, and 3) completeness of de novo reconstruction of the genome of the species present in complex matrices. We selected ten heterogeneous samples that underwent whole genome DNA-sequencing. This was also true for vaccine samples B1 and B2, several components of which are ssRNA viruses, and could not be detected using this approach. Indeed, the determination of the ssRNA components in vaccines was not the aim of the present study.
We started by determining the general characteristics of our samples. All the samples resulted as a mixture of a large number of species, nearly half of which were singletons (i.e. represented by one read). A control sample A1 comprised 2,572 species, while it should contain only 20 of them. However, A1 core set (species with a frequency of at least 0.1%) was made up by 16 species. Based on product specifications, 15 species in the mock community had a frequency greater than 0.1% and we observed all of them. In addition, we erroneously identified Staphylococcus lugdunensis (with a frequency of 0.11%), probably due to misclassification of other Staphylococcus reads. We devised the S90 measure which reports the number of the species (sorted by decreasing abundance) accounting for 90% of the reads. For several samples the S90 is less than 10, while for highly complex matrices as F1 and F2, is 2,795 and 2,947 respectively. The abundance of rare species might be factual for samples with very high complexity such as feces. Still, species represented by only one read are unlikely to be real. A proportion of singleton species is probably originated from sequencing errors and/or from errors in the classification against the database. In addition, especially for low input samples, it is possible that contaminants in laboratory reagents artificially increase the number of observed species38,39. Nevertheless, determining the relative and absolute contribution of these biases to metagenomics studies is out of the scope of the present paper.
The choice of the database against which sequences are matched can affect results. In the present study, we matched our sequences against the full NCBI nt database, because this allows to classify reads belonging to any given organism. However, this might cause some drawback in accuracy. As an example, in the vaccine sample B1, we identified 61 reads attributed to Elaeophora elaphi, a nematode, only found as a parasite of the liver of deers40. It is therefore highly unlikely that such organism might really be present in the vaccine sample. Repeating the analysis on the standard database, only consisting of Homo sapiens, bacteria and viruses, 57 out of 61 reads were assigned to Homo sapiens and the remaining 4 were unassigned (data not shown). Possible explanations are that a) some contamination from Homo sapiens is present in the deposited sequence of Elaeophora elaphi, or b) some reads belonging to Homo sapiens are attributed by mistake to genuine Elaeophora elaphi sequences.
Such marginal missclassification problems do not affect the results of our study, but clearly indicates that researchers should be very cautious when reporting contaminants or unexpected results from metagenomics studies.
In our study we kept the read length constant at 125 bp across experiments. Previous studies (although limited to targeted approaches) showed the effect of read length on the evaluation of the composition of complex matrices41. Even though an extensive assessment of the effect of read length on the ability to characterize complex matrices was beyond the scope of the present work, we compared the results obtained for horse fecal samples (F1 and F2) when using 250 bp long reads. The use of shorter sequences led to a strong increase in the proportion of unclassified reads, from 56% to 74% in F1 and from 58% to 75% in F2.
We performed a benchmark of the entire workflow with the help of a mock community with known composition. By comparing the expected and observed relative abundance of the 20 bacterial species included in the mock community we concluded that the workflow is accurate at all taxonomic levels (Figure 3). One species, Actynomices odontolyticus, with expected frequency of 0.02%, was observed with a much lower frequency (<0.002%, represented as a red dot in Figure 3 and Figure 4). Other species showed only slight deviations from expected frequencies in our experiment. To the best of our knowledge, this is the first published work reporting the observed frequencies of a mock community using WGS. However, previous works performed very extensive studies on target 16s sequencing of mock communities, and reported large deviations from expectation, depending on sequencing primers, extraction method and sequencing platform42. We tested the effect of decrease in sequencing depth on deviations from expected frequency (Figure 4) and observed that even when sampling 10,000 reads the average correlation between expected and observed abundances remained high (r=0.87), although the variance among resampling experiments was high.
To assess the requirements in sequencing depth for characterizing complex matrices, we measured the variation of several diversity indexes while reducing the sequencing depths. We measured the number of observed taxa, Chao1 (or number of expected taxa), Good’s coverage, Shannon’s diversity index and Pielou’s evenness index.
Chao1 estimator is obtained as
Where Sobs is the number of observed species in the sample, f1 is the number of species observed once, and f2 is the number of species observed twice.
Under our experimental conditions, the number of observed and estimated taxa followed similar trends. Both of them were heavily affected by the small proportion of reads attributed to unique or rare taxa.
Good’s coverage (G) is defined as
where f1 is the number of singletons and N is the total number of reads. G is heavily affected by the sequencing depth. Significant variation in G is observed when using 100,000 reads or less.
Shannon diversity index is estimated as
Where N is the total number of species and pi is the frequency of the species i. Thus Shannon diversity index is affected more by variation in the frequencies of highly abundant species than by the loss of rare species. In our study, Shannon’s index was very stable across sample sizes.
Pielou’s evenness index is estimated as
Where H is Shannon’s diversity index and S is the total number of observed species. The value ln S corresponds to the maximum possible value of H, observed when all species have the same frequency, thus Pielou’s index approaches 1 when all the species are evenly distributed. In our study, Pielou’s index showed a slight increase as the number of sampled reads decreased.
Horse fecal samples F1 and F2 are characterized by a very large number of observed species (29,660 and 25,607, respectively), while all the other samples have lower number of species, ranging from 2507 in B1 to 9637 in M2. Chao1 captures this differences, showing that F1 and F2 have greater diversity estimates Measures such as the number of observed taxa and Chao1 capture this differences, showing that F1 and F2 have greater diversity estimates. Shannon’s and Pielou’s indices, on the contrary, rely on the frequency distribution of the species. Therefore, samples that have a relatively high number of common species with comparable frequencies tend to have high Shannon’s diversity indices. Samples (such as M1) dominated by a single species, have very low Shannon and Pielou indices. The effect of sequencing depth on nearly all indices is moderate; we thus conclude that biological matrices with different levels of complexities, composed by different admixture of prokaryotes, eukaroytes and viruses can be satisfactorily characterized via WGS even at sequencing depth lower than 1,000,000 reads.
We then set out to assess the changes in the estimated relative frequency of each individual species when reducing the number of sequenced reads. Accurate estimate of the relative abundance of each species is an important task when the aim is a) to detect species with a relative abundance above any given threshold, b) to differentiate two samples based on different abundance of any given species composition, or c) to cluster samples based on their species composition. Our results show that even in case of substantial reduction of the number of sequenced reads, species abundances as low as 0.1% can be reliably estimated (Figure 6 and Figure 7).
In addition, we aimed to determine the threshold of detection for rare species at low sequencing depth. This statistics is of interest when researchers are interested in detecting the presence of a species that might be rare in the sample. Our results show that even very rare species can be accurately detected at low sequencing depth. When subsampling 1,000,000 reads, the frequency threshold for a species to be detected in the reduced sample was measured as 60 reads out of 1,000,000 (0.00006%). Even when the number of reads was unrealistically low (10,000), rare species could still be detected, with a detection threshold estimated to be 0.012%. While the detection threshold can vary according to sample characteristics, we can assume that for most samples rare species can be accurately detected even at low sequencing depth.
Finally, we assessed the effect of a reduction in the sequencing coverage on the accuracy of de novo assembly of the metagenome. Our results show that downsampling had a strongly negative effect on the total length of the reconstructed metagenome and on the propoprtion of reconstructed genes (Figure 5F and Figure 8).
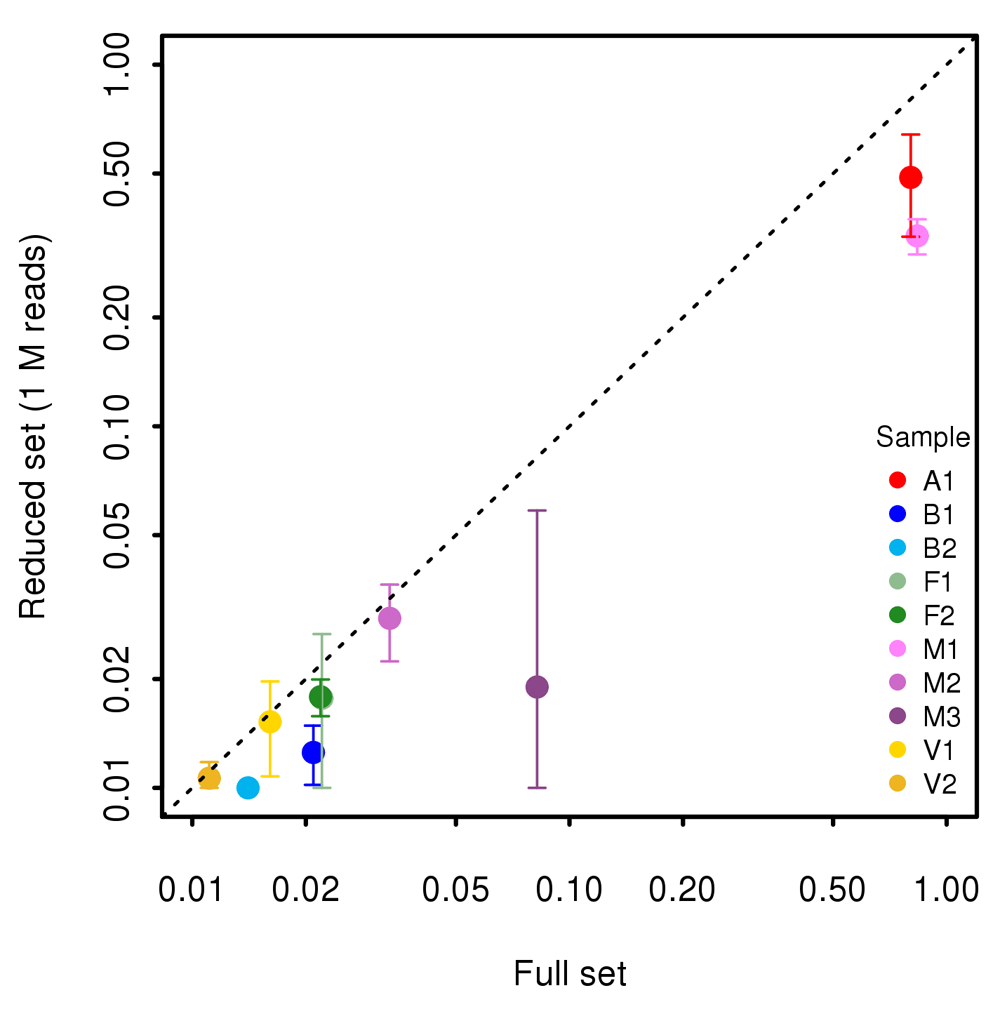
The plot is in log-log scale.
BUSCO is widely used for assessing the completeness of genome and transcriptome assemblies for individual organisms, and has benchmark datasets for several lineages. Our results clearly indicate that even 1,000,000 reads is a suboptimal depth in terms of fully sampling the genes present in the complex matrices. This observation needs to be taken into account in the phase of experimental design. Our conclusions are also important for research interested at reconstruction of an interesting part of the meta-genome, such as genes involved in antibiotic resistance43. The decrease in performance observed in the genes’ recostruction will be likely observed for any gene category. Researchers aiming at a de novo reconstruction of the metagenome (although partial) must keep in mind that several millions of reads are needed to attain reliable results. In addition, the proportion of genes reconstructed with BUSCO in the full dataset was very low for all samples, with the exception of the two samples M1, predominanty composed by one fungal species, and A1, composed by a limited number of small genomes. These results indicate that a complete reconstruction of the metagenome of a complex matrix requires at least several millions reads. In the present work we tested the feasibility of using metagenome shotgun shallow high-throughput sequencing to analyze complex samples for the presence of eukaryotes, prokaryotes and virus nucleic acids for monitoring, surveillance, quality control and traceability purposes. We show that, if the aim of the experiment is a taxonomical characterization of the sample or the identification and quantification of species, a low-coverage WGS is a good choice. On the other hand, if one of the aims of the study relies on de novo assembly, substantial sequencing efforts are required. The number of reads required for the reconstruction of the meta-genome, depends on several factors such as number of species in the sample, their genome size and abundance and length of the sequencing reads. An estimation needs to be performed for each experiment based on specific goals and sample characteristics.
Raw reads generated in the present study are available at NCBI Sequence Read Archive.
Sample A1 is available under accession number SRP174028: https://identifiers.org/insdc.sra/SRP174028.
Samples F1 and F2 are available under accession number SRP163102: https://identifiers.org/insdc.sra/SRP163102.
Samples B1 and B2 are available under accession number SRP163096: https://identifiers.org/insdc.sra/SRP163096;
and samples M1, M2 and M3 are available under accession number SRP163007: https://identifiers.org/insdc.sra/SRP163007.
Open Science Framework: Do you cov me. https://doi.org/10.17605/OSF.IO/Y7C3944.
This project contains the raw html graphs, produced using Krona.
Pipeline for performing the standard analysis included in this work available from: https://github.com/fabiomarroni/doyoucovme.
Archived code at time of publication: https://doi.org/10.5281/zenodo.259379827.
License: GNU GPL-3.0.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)