Keywords
Constant Effect, Precision medicine, Homoscedasticity, Clinical Trial, Variability, Standard deviation, Review
Constant Effect, Precision medicine, Homoscedasticity, Clinical Trial, Variability, Standard deviation, Review
The following major changes have been introduced in the manuscript:
See the authors' detailed response to the review by Dennis W. Lendrem
See the authors' detailed response to the review by Vance W. Berger
See the authors' detailed response to the review by Erica E.M. Moodie
See the authors' detailed response to the review by Saskia le Cessie
See the authors' detailed response to the review by Ian White
See the authors' detailed response to the review by Richard Stevens and David Nunan
The idea behind precision medicine is to develop prevention and treatment strategies that take into account individual characteristics. With this strong endorsement “The prospect of applying this concept broadly has been dramatically improved by recent developments in large-scale biologic databases (such as the human genome sequence), powerful methods for characterizing patients (such as proteomics, metabolomics, genomics, diverse cellular assays, and mobile health technology), and computational tools for analyzing large sets of data.”, US President Obama launched the Precision Medicine initiative in 2015 to capitalize on these developments1,2. However, we aim to quantify the proportion of interventions that may benefit from this idea.
The variability of a clinical trial outcome measure should interest researchers because it conveys important information about whether or not there is a need for precision medicine. Does variance come only from unpredictable and ineluctable sources of patient variability? Or should it also be attributed to a different treatment effect that requires more precise prescription rules3–5? Researchers assess treatment effect modifications (“interactions”) among subgroups based on relevant variables. The main problem with that methodology is that, by the usual standards of a classical phase III trial, the stratification factors must be known in advance and be measurable. This in turn implies that when new variables are discovered and introduced into the causal path, new clinical trials are needed. Fortunately, one observable consequence of a constant effect is that the treatment will not affect variability, and therefore the outcome variances in both arms should be equal (“homoscedasticity”). If this homoscedasticity holds, there is no evidence that the clinical trial should be repeated once a new possible effect modifier becomes measurable.
Nevertheless, the fundamental problem of causal inference is that for each patient in a parallel group trial, we can know the response for only one of the interventions. That is, we observe their response to either the new Treatment or to the Control, but not both. By experimentally controlling unknown confounders through randomization, a clinical trial may estimate the averaged causal effect. In order to translate this population estimate into effects for individual patients, additional assumptions are needed. The simplest one is that the effect is constant. Panels A and B in Figure 16–15 represent two scenarios with a common effect in all patients, although the effect is null in the first case. Following Holland16, this assumption has the advantage of making the average causal effect relevant to each patient. All other scenarios (Figure 1, Panels C to F) require additional parameters to fully specify the treatment effect.
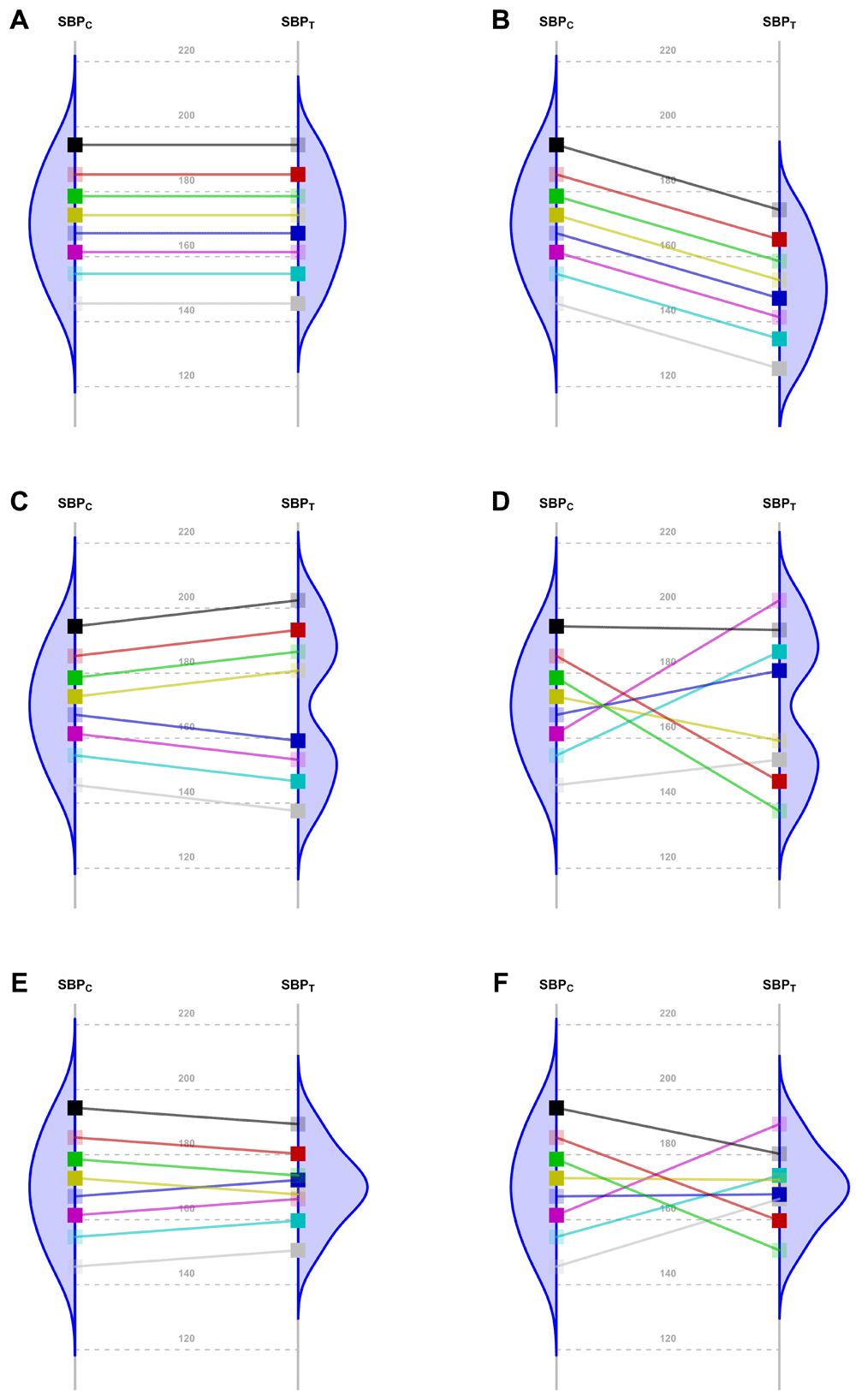
Because of the random allocation to one of two treatment arms, we will observe only one of the two potential outcomes for each patient: either under T or under C. Fully saturated colors represent observed Systolic Blood Pressure (SBP) values, and transparent squares represent missing potential values. The line slope indicates the individual non-observable effect for each patient. Densities are the potential distributions of the outcome in each group: As both random samples come from the same target population, the average causal effect is estimable without bias. Panel A shows the potential outcome values that we could obtain if there were not any treatment effect; as the intervention has no effect at all, both groups have the same distribution (i.e., mean and variance). Panel B shows the scenario of a constant effect, meaning that the intervention lowers the SBP by a single value in every patient and thus implying the same variability in both arms. For instance, the study from Duran-Cantolla et al.6 compared the 24-hour systolic blood pressure among 340 patients randomized to either Continuous Positive Airway Pressure (CPAP) or sham–CPAP, and it showed a greater decrease of 2.1 mmHg (95% CI from 0.4 to 3.7) in the intervention group compared to the control group. Furthermore, baseline standard deviations (SDs) were 12 and 11; and final SDs were 13 for both groups. Therefore, their results fully agree with the trial design’s assumption of a constant effect (scenario B) and nothing contradicts the inference that each patient exhibits a constant reduction of 2.1mmHg, although the uncertainty of random allocation makes the results compatible with a constant effect that lies anywhere between 0.4 and 3.7. Panel C represents a situation with 2 different effects in 2 subpopulations (“treatment by subgroup interaction”). Although the effects are identical within them, the observable distribution in the treated arm would have higher variability. Here, we need to find finer eligibility criteria for classifying patients in those subpopulations so that a constant effect could be assumed again. In Panel D, the treatment has a variable effect in each patient, resulting also in greater variability within the treated arm but without any subgroup sharing a common effect. The results are poorly predictive about the effects on future patients. In the study by Kojima et al.7, the primary outcome measure was the 3-hour postprandial area under the curve of apolipoprotein B48, with outcome SDs being 0.78 and 0.16 in the treated and reference arms, respectively, and thus showing an outcome variance ratio of 23.77. This is compatible with different treatment effects that could need additional refinements through precision medicine, since a greater variance in the treated arm indicates that “the interpretation of the main treatment effect is controversial”8. In that case, guidelines for treating new patients should be based either on additional eligibility criteria (“precision medicine”, panel C) or on n-of-1 trials (“individualized medicine”, panel D)9–13. This “treatment by patient interaction” was already highlighted by W. S. Gosset in the data of his 1908 paper proposing the Student t-distribution14. Alternatively, interactions can result in smaller variances in the treated arm. Panel E shows a different effect in 2 subgroups; but the variability is now reduced indicating that the best solution would be to identify the subpopulations in order to refine the selection criteria. In Panel F, the treatment again has a variable effect on each patient; but unlike Panel D, in this case the result is less variability within the treated arm. In the study from Kim et al.15, the primary endpoint was the PTSD Checklist–Civilian version (PCL-C). This scale is based on the sum of 17 Likert symptoms, ranging from 17 (perfect health) to 85 (worst clinical situation). At the end of the trial, the respective outcome SDs were 16 and 3 for the control and treated arms, meaning that variance was reduced around 28 times. This situation can correspond to scenarios E or F, and it merits much more statistical consideration, which is beyond the scope of this paper.
As an example, the 10 clinical trials published in the journal Trials in October 2017 (Supplementary File 1: Table S1) were designed without explicitly mentioning that the effect was not constant within the study population. Furthermore, all their analyses were designed to estimate just an average effect with no mention of any possible interaction with baseline variables (Figure 1, Panels C and E), nor did they discuss any random variability for the treatment effect (Figure 1, Panels D and F). In those scenarios, the authors should take these factors into account when designing their trials. For example, Kim et al.17 designed their trial to test the intervention for non-inferiority in the overall population and for superiority in the subgroup of patients with high epidermal growth factor receptor. So, without further specifications, it seems that they were hoping for the treatment effect to be the same for all patients.
Below, we will elucidate whether the comparison of observed variances may shed some light on the non-observable individual treatment effect.
Our objectives were, first, to compare the variability of the main outcome between arms in clinical trials published in medical journals; and, second, to provide a rough estimate of the proportion of studies that could potentially benefit from precision medicine. To assess the consistency of results, we explore the changes in the variability of the experimental arm over time (from baseline to the end of the study).
Our target population was parallel randomized clinical trials with quantitative outcomes (not including time-to-event studies). The trials needed to provide enough information to assess two homoscedasticity assumptions in the primary endpoint: between arms at trial end; and baseline to outcome over time in the treated arm. Therefore, baseline and final SDs for the main outcome were necessary or, failing that, we needed at least one measure that would allow us to calculate them (variances, standard errors or mean confidence intervals).
Articles on parallel clinical trials from the years 2004, 2007, 2010 and 2013 were selected from the Medline database with the following criteria: “AB (clinical trial* AND random*) AND AB (change OR evolution OR (difference AND baseline)” [The word “difference” was paired with “baseline” because the initial purpose of the data collection, subsequently modified, was to estimate the correlation between baseline and final measurements]. The rationale behind the selection of these years was to have a global view of the behavior of the studies over a whole decade. For the years 2004 and 2007, we selected all papers that met the inclusion criteria; however, we retrieved a greater number of articles from our search for the years 2010 and 2013 (478 and 653, respectively) and therefore chose a random sample of 300 papers (Section II in Supplementary File 1).
Data were collected by two different researchers (NM, MkV) in two phases: 2004/2007 and 2010/2013. Later, two statisticians (JC, MtV) verified the data and made them accessible to readers through a shiny application and through the Figshare repository18.
Collected variables were: baseline and outcome SDs; experimental and reference interventions; sample size in each group; medical field according to Web of Science (WOS) classification; main outcome; patient’s disease; kind of disease (chronic or acute); outcome type (measured or scored); intervention type (pharmacological or not); improvement direction (upwards or downwards) and whether or not the main effect was statistically significant.
For studies with more than one quantitative outcome, the primary endpoint was determined according to the following hierarchical criteria: (1) objective or hypothesis; (2) sample size determination; (3) main statistical method; (4) first quantitative variable reported in results.
In the same way, the choice of the "experimental" arm was determined depending on the role in the following sections of the article: (1) objective or hypothesis; (2) sample size determination; (3) rationale in the introduction; (4) first comparison reported in results (in the case of more than two arms).
We assessed homoscedasticity between treatments and over time. For the former, our main analysis compared, the outcome variability between Treated (T) and Control (C) arms at the trial end. For the latter, we compared the variability between Outcome (O) and its Baseline (B) value for the treated arm.
Three different methods were used to compare the variances: 1) a random-effects model; 2) a heuristic procedure based on the heterogeneity of the previous random-effects model; and 3) a classical variance comparison test.
To distinguish between the random sampling variability and heterogeneity, we fitted a random-effects model. The response was the logarithm of the outcome variance ratio at the end of the trial. The covariates were the study as a random effect and the logarithm of the variance ratio at baseline served as a fixed effect19.
The main fitted model for between-arm comparison was:
where VXX represent the variances of the outcome in each arm (VXT, VXC) at the end of the study (VOT, VOC) and at baseline (VBT, VBC). The parameter μ is the logarithm of the average variance ratio across all the studies; si represents the heterogeneity between-study effect associated with study i with variance τ2; β is the coefficient for the linear association with the baseline variance ratio; and ei represents the intra-study random error with variance .
The parameter μ represents a measure of the imbalance between the variances at the end of the study, which we call heteroscedasticity.
The estimated value of τ2 provides a measure of heterogeneity, that is, to what extent the value of μ is applicable to all studies. The larger τ2 is, the less the homogeneity.
The percentage of variance explained by the differences among studies in respect to the overall variance is measured by the I2 statistic20. That is:
v2 is the mean of the error variances .
An analogous model was employed to assess the homoscedasticity over time. As there is only one available measure for each study, it is not possible to differentiate both sources of variability: (i) within-study or random variability; and (ii) heterogeneity. To isolate the second, the first was estimated theoretically using either the Delta method in the case of comparison between arms or some approximation in the case of comparison over time (see details in Sections VI and VII of Supplementary File 1). Thus, the within-study variance was estimated using the following formulas:
Centered at zero, funnel plots for the measurement of interest as a function of its standard error are reported in order to help investigate asymmetries. The first and main analysis considers the points outside the triangle (which is defined as ± 2 times the standard error) to be those studies that have different variability. Everything far from the two standard errors represents a possible mismatch that is either between the groups (comparison between arms) or between baseline and final variability (comparison over time).
The second analysis was heuristic. In order to obtain a reference in the absence of treatment effect, we first modeled the baseline variance ratio as a response that is expected to have heterogeneity equal to 0 due to randomization – so long as no methodological impurities are present (e.g., considering the outcomes obtained 1 month after the start of treatment to be the baseline values). This reference model allows us to know the proportion of studies in the previous models that could have additional heterogeneity and which cannot be explained by the variability among studies (Section III in Supplementary File 1). Specifically, studies with larger discrepancies in variances were removed one by one until the estimated value of τ was as close as possible to that of the reference model. These deleted studies were considered to be those that had significantly different variances, perhaps because the experimental treatment either increased or decreased the variance. From now on, the complete dataset and the resulting dataset after removing the abovementioned studies will be called Full Data (FD) and Reduced Data (RD), respectively.
Thirdly, as an additional sensitivity analysis, we also assessed homoscedasticity in each single study using pre-specified tests: (a) between outcomes in both arms with an F-test for independent samples; and (b) between baseline and outcome in the treated arm with a specific test for paired samples21 when the variance of the paired difference was available. All tests were two-sided (α=5%).
Several subgroup analyses were carried out according to the statistical significance of the main effect of the study and to the different types of outcomes and interventions.
All analyses were performed with the R statistical package version 3.2.5. (The R code for the main analysis is available from https://doi.org/10.5281/zenodo.123953922)
A total of 1214 articles were retrieved from the search. Of those papers, 542 belong to the target population and 208 (38.4%) contained enough information to conduct the analysis (Figure 2).
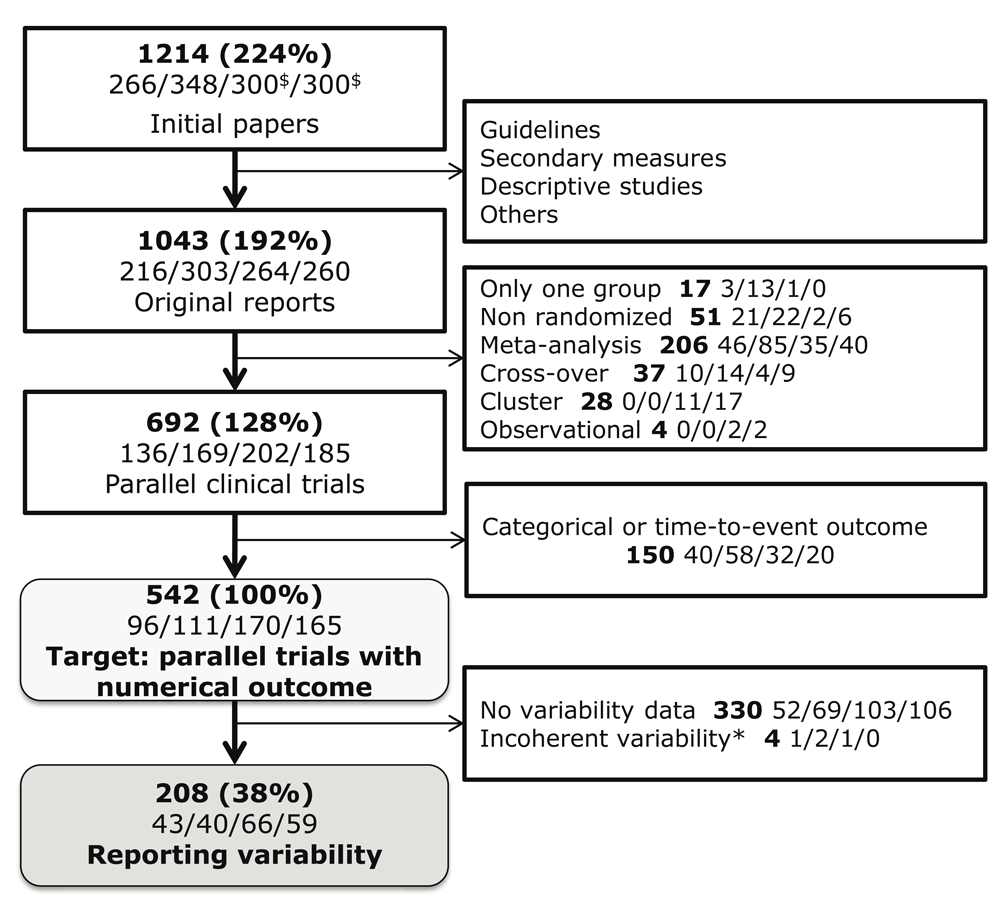
Percentages represent the quantity of papers in the target population. The number of articles for each year (2004/2007/2010/2013) is specified in the second line of each box (separated by slashes). $300 papers were randomly selected for years 2010 and 2013. *Four papers were excluded because the variance of the change over time was inconsistent with both the baseline and final variances, which would lead to impossible absolute correlation estimates greater than 1.
Overall, the selected studies were non-pharmacological (122, 58.6%), referred to chronic conditions (101, 57.4%), had an outcome measure with units (132, 63.8%) instead of a constructed scale, had an outcome that was measured (125, 60.1%) rather than assessed; and had better responses corresponding to lower values (141, 67.8%). Regarding the primary objective of each trial, the authors found statistically significant differences between arms (all of which favoring the experimental group) in 83 (39.9%) studies. Following the WOS criteria, 203 articles (97.6%) belonged to at least one medical field. The main areas of study were: General & Internal Medicine (n=31, 14.9%), Nutrition & Dietetics (21, 10.1%), Endocrinology & Metabolism (19, 9.1%), and Cardiovascular System & Cardiology (16, 7.7%).
On average, the outcome variance ratio is close to one, with evidence of smaller variability in the treated arm. At the end of the study, 113/208 (54%, 95% CI, 47 to 61%) papers showed less variability in the treated arms (Supplementary File 1 : Figure S1 and Figure S2). Among the treated arms, 111/208 (53%, 95% CI, 46 to 60%) had less or equal variability at the end of follow-up than at the beginning (Supplementary File 1 : Figure S3 and Figure S4).
Regarding the comparison between arms, the main analysis is based on the random-effects model (Supplementary File 1: Table S4, model 3 with FD), in which the adjusted point estimate of the mean outcome variance ratio (Treated to Control group) is 0.89 (95% CI 0.81 to 0.97). This indicates that treatments tend to reduce the variability of the patient's response by about 11% on average. As for the comparison over time (Supplementary File 1 : Table S4, model 6 with FD), the average variability at the end of the study is 14% lower than that at the beginning.
The estimated baseline heterogeneity (τ2) was 0.31 (Supplementary File 1 : Table S4, model 1 with FD), which is a very high value that could be explained by methodological flaws similar to those presented by Carlisle23. Fortunately, the exclusion of the four most extreme papers reduced it to 0.07 (Supplementary File 1 : Table S4, model 1 with RD); one of these was the study by Hsieh et al.24 whose “baseline” values were obtained 1 month after the treatment started. When we modeled the outcome instead of the baseline variances as the response, estimated heterogeneity () was almost doubled (Supplementary File 1 : Table S4, model 6 with FD). We found 30 studies that compromised homoscedasticity: 11 (5.3%) with higher variance in the treated arm and 19 (9.1%), with lower variance. These figures were slightly higher in the analysis based on the classical variance comparison tests: In 41 studies (19.7%) we found statistically significant differences between outcome variances, 15 (7.2%) were in favor of greater variance in the treated arm; and 26 (12.5%) were in the opposite direction. Larger proportions were obtained from the comparisons over time of 95 treated arms: 16.8% had significantly greater variability at the end of the study and 23.2% at the beginning. Table 1 summarizes those numbers and Figure 3 shows the funnel plots for both between-arm and over-time comparisons.
Alternative possible methods to estimate the number and percentage of studies with different variances on comparisons between arms and over-time. Limits for declaring different variances come from different statistical methods: (1) the analysis relying on random-effects model and funnel plots; (2) the heuristic analysis based on number of studies that have to be deleted from the random-effects model in order to achieve a negligible heterogeneity (studies with larger discrepancies in variances were removed one by one until the estimated value of τ was as close as possible to that of the reference model – the one that compares the variances of the response at baseline. See Methods for details); (3) classic statistical tests for comparing variances (F for independent outcomes or Sachs’ test21 for related samples).¥ This comparison was performed in studies reporting enough information to obtain the variability of the change from baseline to outcome, for example because they provide the correlation between outcome and baseline values.
| Comparing variances | N | Method | After treatment, variability is… | ||
|---|---|---|---|---|---|
| Increased n (%) | Decreased n (%) | Not changed n (%) | |||
| Outcome between treatment arms | 208 | Random-effects model | 14(6.7%) | 26 (12.5%) | 168(80.8%) |
| Heuristic | 11 (5.3%) | 19 (9.1%) | 178 (85.6%) | ||
| F-test | 15 (7.2%) | 26 (12.5%) | 167 (80.3%) | ||
| Outcome versus baseline in treated arm | 95¥ | Random-effects model | 16 (16.8%) | 22(23.2%) | 57(60.0%) |
| Heuristic | 13 (13.7%) | 19 (20.0%) | 63 (66.3%) | ||
| Paired test | 16 (16.8%) | 22 (23.2%) | 57 (60.0%) | ||
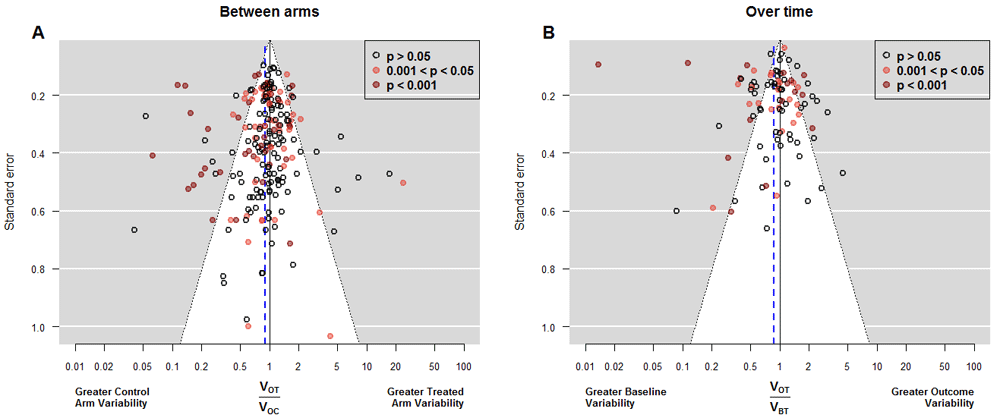
Funnel plots of outcome variance ratio between arms (Panel A) and of outcome variance ratio over time (Panel B). The first shows all 208 studies while the second shows the only 95 studies in which the variance of the difference between the baseline and final response was available. Vertical axis indicates precision for the comparison of variances; with points outside the triangle being statistically significant. Additionally, red points mark significant differences between the means, which correspond each study’s objective to assess main treatment effects. In Panel A, points on the right indicate higher outcome variability for the treated individuals, as expected if there is patient-by-treatment interaction; similarly, points on the left correspond to lower variability, although this is compatible with traditional Evidence-Based Medicine. Eleven (5.2%) out of 208 studies reported exactly the same outcome variability in both arms. We observe more red points on the left, indicating that changes in the average come with reductions in the variance. In Panel B, points on the right indicate higher variability in the experimental arm at the end of the study, as expected in a scenario of heterogeneous treatment effect; points on the left correspond to lower variability at the end, which implies a more homogenous response after treatment. The largest number of points on the left side indicates a majority of experimental interventions that reduce variability. In addition, several of these interventions yielded significant results in the main endpoint. VOT: Variance of the Outcome in the Treated arm. VOC: Variance of the Outcome in the Control arm. VBT: Variance of the Outcome at baseline in the Treated arm.
Subgroup analyses suggest that significant interventions had an effect on reducing variability (Supplementary File 1 : Figures S5–S7), which has already been observed in other studies25,26. Even more important, lower variances in experimental arm occur only in outcomes that require low values for a better response; this is in line with other works that have found a positive correlation between the effect size and its heteroscedasticity27,28: The fact is that difficult to find heteroscedasticity when there is no overall treatment effect. The remaining subgroup analyses did not raise concerns (section V in Supplementary File 1).
Our main objective was to show that comparing variances can provide some evidence about how much precision medicine is needed. We found that variability seems to decrease for treatments that perform significantly better than the reference; otherwise, it remains similar. Therefore, the treatment seems to be doing what medicine should do –having larger effects in the most ill patients. Two considerations may be highlighted here: (1) as the outcome range becomes reduced, we may interpret that, following the intervention, this population is under additional control; but also, (2) as subjects are responding differently to treatment, this opens the way for not treating some (e.g. those subjects who are not very ill, and thus lack the scope to respond very much), which subsequently incurs savings in side effects and costs.
This reduced variability could also be due to methodological reasons. One is that some measurements may have a “ceiling” or “floor” effect (e.g., in the extreme case, if a treatment heals someone, no further improvement is possible). In fact, according to the subgroup analysis of the studies with outcomes that indicate the degree of disease (high values imply greater severity; e.g., pain), a greater variance (25%) is obtained in the experimental arm (see Figure S5). However, in the studies with outcomes that measure the degree of healthiness (high values imply better condition; e.g., mobility), the average variances match between arms and this does not suggest a ceiling effect. Another reason might be that the treatment effect is not additive, suggesting that it would be suitable to explore other metrics and transformations. For example, if the treatment acts proportionally rather than linearly, the logarithm of the outcome would be a better scale.
When both arms have equal variances, then the simplest interpretation is that the treatment effect is constant, thus rendering futile any search for predictors of differential response. This means that the average treatment effect can be seen as an individual treatment effect (not directly observable), which supports the use of a unique protocol for all patients within the eligibility criteria, thus in turn also supporting evidence-based medicine.
Our second objective was to provide a rough estimate of the proportion of interventions with different variability that would require more precise medicine: Considering the most extreme result from Table 1 for comparison between arms, 1 out of 14 interventions (7.2%) had greater variance in the experimental arm while 1 out of 8 interventions (12.5%) had lower variance. Even if there are no differences in means, lower variance implies a larger proportion of patients within the reference range. However, the non-constant effect indicates that trials with n=1 are needed to estimate different treatment effects on those individuals.
Our sensitivity analysis of the change over time in the experimental arm agreed with the findings in the comparison between arms, although this comparison is not protected by randomization. For example, the existence of eligibility criteria at baseline may have limited the initial variance (a hypertension trial might recruit patients with baseline SBP between 140 and 159 mm Hg), leading to the variance naturally increasing over time.
There are three reasons why these findings do not invalidate precision medicine in all settings. First, there are studies where the variability in the response is glaringly different, indicating the presence of a non-constant effect. Second, the outcomes of some type of interventions such as surgeries, for example, are greatly influenced by the skills and training of those administering the intervention; and these situations could have some effect on increasing variability. And third, we focus on quantitative outcomes, which are neither time-to-event nor binary, meaning that the effect in these cases could take a different form, such as all-or-nothing.
The results rely on published articles, which raises some relevant issues. First, some of our analyses are based on Normality assumptions for the outcomes that are unverifiable without access to raw data. Second, a high number of manuscripts (61.6%, Figure 2) act contrary to CONSORT29 advice in that they do not report variability. Thus, the trials of this study may not be representative of trials in general. Third, trials are usually powered to test constant effects and thus the presence of greater variability would lead to underpowered trials, non-significant results and unpublished papers. Fourth, the heterogeneity observed in the random-effects model may be the result of methodological inaccuracies23 arising from typographical errors in data translation, inadequate follow-up, insufficient reporting, or even data fabrication. On the other hand, this heterogeneity could also be the result of relevant undetected factors interacting with the treatment, which would indeed justify the need for precision medicine. A fifth limitation is that many clinical trials are not completely randomized. For example, multicenter trials often use a permuted blocks method. This means that if variances are calculated as if the trial were completely randomized (which is standard practice), the standard simple theory covering the random variation of variances from arm to arm is at best approximately true25
The main limitation of our study arises from the fact that, although a constant effect always implies homoscedasticity on the chosen scale, the reverse is not true; i.e., homoscedasticity does not necessarily imply a constant effect. Nevertheless, a constant effect is the simplest explanation for homoscedasticity. For example, the highly specific and non-parsimonious situation reflected in Figure 4 indicates homoscedasticity but without a constant effect (Section VIII of Supplementary File 1: Conditions for homoscedasticity to hold without a constant effect under an additive model).
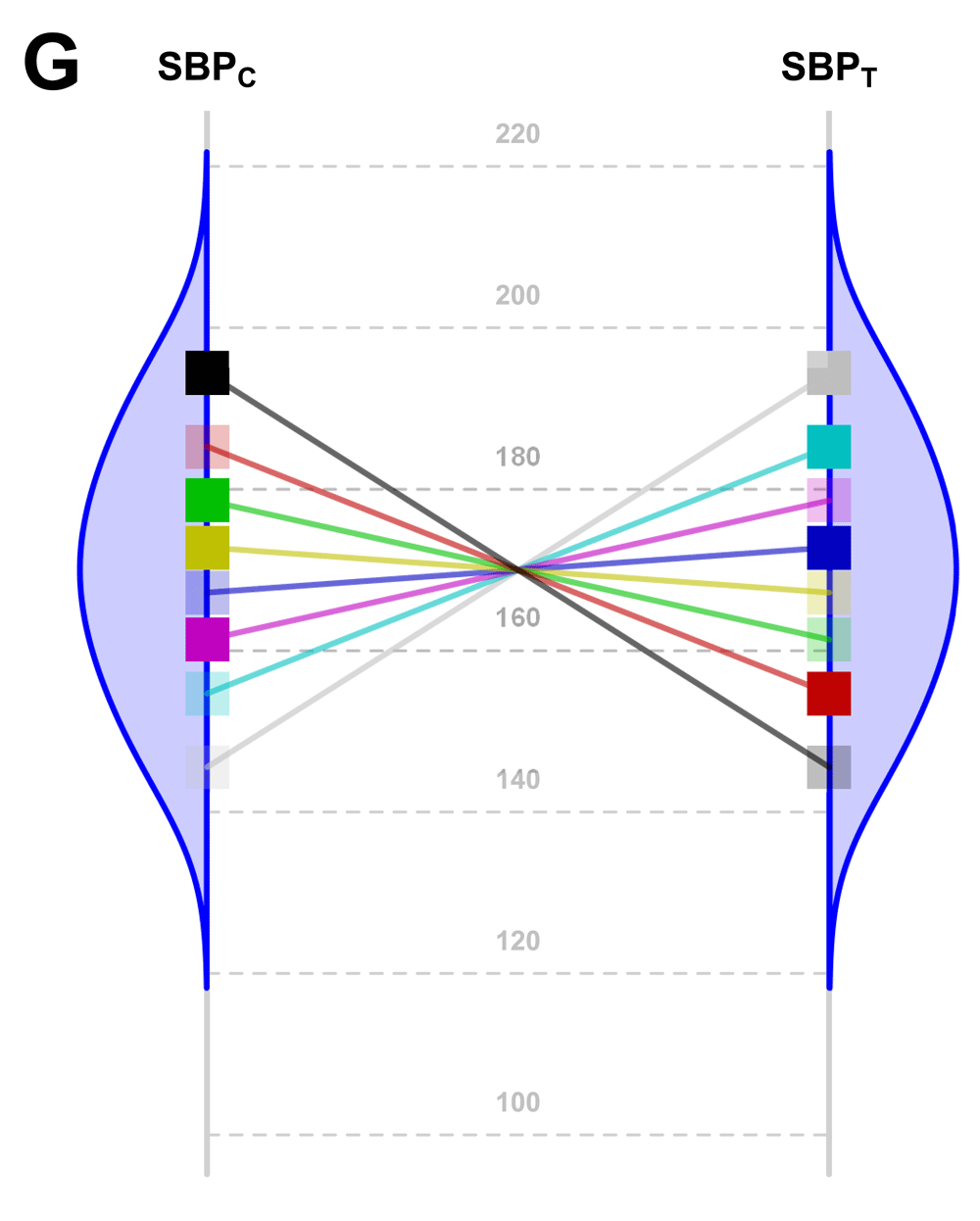
SBP potential values of each patient in both groups (C: Control; T: Treated) under a highly hypothetical scenario: the treatment effect has no value if systematically applied to the whole population; but if n-of-1 trials could be performed in this situation, the best treatment strategy would be chosen for each patient and the overall health of the population would be improved.
Heteroscedasticity may suggest the need for further refinements of the eligibility criteria or for finding an additive scale25,30. Because interaction analyses cannot include unknown variables, all trials would potentially need to be repeated once any new potential interaction variable emerges (e.g., a new biomarker) as a candidate for a new subgroup analysis. Nevertheless, we have shown how homoscedasticity can be assessed when reporting trials with numerical outcomes, regardless of whether every potential effect modifier is known.
For most trials, the variability of the response to treatment changes scarcely or even decreases, which suggests that precision medicine’s scope may be less than what is commonly assumed – while always taking into account the limitation previously explained in Figure 4. Evidence-Based Medicine operates under the paradigm of a constant effect assumption, by which we learn from previous patients in order to develop practical clinical guides for treating future ones. Here, we have provided empirical insights for the rationale behind Evidence-Based Medicine. However, even where one common effect applies to all patients fulfilling the eligibility criteria, this does not imply that the same decision is optimal for all patients, specifically because different patients and stakeholders may vary in their weighting not only of efficacy outcomes, but also of the harm and cost of the interventions – thus bridging the gap between common evidence and personalized decisions.
Nevertheless, when considering the main analysis we find evidence of effect variation in around 1 out of 5 trials (40/208), suggesting a limited role for tailored interventions: either with finer selection criteria (common effect within specific subgroups), or with n-of-1 trials (no subgroups of patients with a common effect). By identifying indications where the scope for precision medicine is limited, studies such as ours may free up resources for situations with a greater scope.
Our results uphold the assertion by Horwitz et al. that there is a “need to measure a greater range of features to determine [...] the response to treatment”31. One of these features is an old friend of statisticians, the variance. Looking only at averages can cause us to miss out on important information.
Data is available through two sources:
A shiny app that allows the user to interact with the data without any need to download it: http://shiny-eio.upc.edu/pubs/F1000_precision_medicine/
The Figshare repository: https://doi.org/10.6084/m9.figshare.555265618
In both sources, the data can be downloaded under a Creative Commons License v. 4.0.
The code for the main analysis is available in the following link: https://doi.org/10.5281/zenodo.123953922
Supplementary File 1: The supplementary material contains the following sections:
- Section I: Constant effect assumption in sample size rationale
- Section II: Bibliographic review
- Section III: Descriptive measures
- Section IV: Random-effects models
- Section V: Subgroup analyses
- Section VI: Standard error of log(VOT/VOC) in independent samples
- Section VII: Standard error of log(VOT/VBT) in paired samples
- Section VIII: Conditions for homoscedasticity to hold without a constant effect under an additive model
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
We're definitely right to question the unproven assumption that patients differ meaningfully in their responses to treatments. But I'm doubtful about how strongly the evidence in this paper speaks against that idea.
We're definitely right to question the unproven assumption that patients differ meaningfully in their responses to treatments. But I'm doubtful about how strongly the evidence in this paper speaks against that idea.