Keywords
Bernoulli model, fingerprints, p-value, similarity value distributions, Tanimoto coefficient.
This article is included in the Cheminformatics gateway.
This article is included in the Mathematical, Physical, and Computational Sciences collection.
This article is included in the Python collection.
Bernoulli model, fingerprints, p-value, similarity value distributions, Tanimoto coefficient.
The quantitative assessment of molecular similarity is a central concept in chemoinformatics1–4. It forms the basis of similarity searching and ligand-based virtual screening to identify novel molecules in large databases with biological properties similar to given reference compounds5–7. Assessment of molecular similarity plays a central role in chemical space analysis and the study of activity landscapes where chemical space projections onto low-dimensional representations are based on quantified similarities8,9.
The use of fingerprints and the Tanimoto coefficient10 (Tc), also known as the Jaccard index11, represents one of the most popular methods for quantifying molecular similarity1–4. Fingerprints encode structural features of a molecule in a binary vector format and the Tc quantifies the overlap of features of two molecules as the ratio of the number of common features to the total number of features in each fingerprint. The Tc has the value range 0 to 1 and can be interpreted as the percentage of features shared by two molecules. However, whether a given percentage of overlap should be considered a significant similarity of two molecules depends on the fingerprint design and the global frequency of encoded features. Fingerprint designs might be categorized as dense or sparse. Dense fingerprints have a relatively small dimensionality of at most a few thousand features, but a significant fraction of these might be present in any given molecule. On the other hand, sparse fingerprints can have a theoretically infinite set of features (typical integer encodings allow up to 4 billion features). However, only tens or hundreds of these features might be found in a single molecule. Consequently, sparse fingerprint representations generally lead to smaller Tc values than dense fingerprints.
While it is not meaningful to compare Tc values of different fingerprint designs directly, statistical approaches can be applied to assess the significance of Tc values with respect to a reference data set. By using the distribution of Tc values obtained from comparing random compounds as a reference, Tc value significance can be determined by calculating the probability of obtaining a given Tc or higher value by chance. In statistical terms, the reference distribution corresponds to a null hypothesis and the significance measure is known as p-value or p-score. This score has the range 0 to 1 and indicates the probability that a given Tc would be obtained by chance. Thus, smaller p-values indicate higher significance. Here, we will use the measure 1 – (p-value) to assess significance. Although it is in principle possible to obtain Tc distributions by random sampling, this process is time consuming. Instead, the ccbmlib package presented here provides methods for the generation of Tc distribution models that are based on the statistical analysis of feature frequencies and feature correlations between fingerprints for a reference data set. Some mathematical models of Tc-value distributions12–14 have been introduced in the past. The ccbmlib implementation makes use of the conditional correlated Bernoulli model (CCBM) that has been shown to accurately model Tc distributions for a variety of fingerprint designs13,14. An unconditional distribution model accounts for Tc distributions of fingerprints of randomly selected compounds. However, it is of particular interest to model distributions where one compound fingerprint is used as a reference, which forms the basis of similarity searching. P-values obtained from such conditional distribution models efficiently estimate how high a test compound would be ranked in a similarity search with respect to a given reference compound. Hence, conditional models can be used to predict similarity search performance13,14.
The implementation presented here is based on RDKit15 and provides methods for statistically analyzing fingerprint feature distributions and building models for fingerprints implemented in RDKit. Methods are provided for calculating significance from Tc values, which enable a meaningful comparison of Tc values calculated using fingerprints of different design. The CCBM requires knowledge of the frequency of individual features as well as their pairwise covariances. This statistical analysis needs to be carried out once for each reference data set and fingerprint design. This step can be time consuming for large data sets. The ccbmlib implementation stores resulting statistics permanently to avoid redundant calculations. For our reference implementation and evaluation, compounds from ChEMBL (release 25)16 were selected as a representative sample of bioactive chemical space.
RDKit provides implementations for a variety of fingerprints. Available fingerprints are reported in Table 1. The atom pair fingerprint encodes typed pairs of atoms and their bond distance and is based on the description given by Carhart and Smith17, representing a sparse fingerprint. The Avalon fingerprint18 is a hashed fingerprint enumerating paths and feature classes. MACCS (Molecular ACCess System) keys record the presence or absence of a dictionary of 166 substructural features19. Morgan fingerprints are an RDKit implementation of extended connectivity fingerprints (ECFPs)20 and enumerate atom environments up to a selected radius. We calculated Morgan fingerprints for radius 1 and 2 corresponding to ECFP with diameter 2 and 4, respectively. The topological torsion fingerprints encode sequences of four bonded atoms in a sparse fingerprint21. The RDKit fingerprint is a hashed substructure/path fingerprint similar to the Daylight fingerprints22. Atom pairs, Morgan fingerprints, and the topological torsion fingerprint result in sparse vector representations whose dimensions are only limited by the underlying numerical representation. Hashing is often used to yield a dense fingerprint representation of constant length. We evaluated our models using the sparse and hashed versions with a default size of 2048 bits.
For the following mathematical description of the models, we will use lowercase bold letters to indicate bit vector representations and uppercase italic symbols to denote the corresponding feature set representations:
Here, d ∈ ℕ is the dimension of the fingerprint.
Similarity of fingerprints is most often assessed on the basis of the set of features common to two fingerprints. The Tanimoto coefficient10,11 is defined as the ratio of the number of features common to two fingerprints A and B to the total number of features present in either A or B:
where I(A, B) = |A ∩ B| and U(A, B) = |A ∪ B| are the cardinalities of the intersection and union of A and B, respectively.
The distribution of Tc values depends on the fingerprints of a reference compound data set. The resulting p-values must be interpreted with respect to the reference data set.
As indicated in Equation 1, fingerprints can be represented as sets of features and similarity metrics like the Tc depend on the cardinalities of the intersection and union of sets. Each of the d features Xi of a fingerprint can be modeled as a Bernoulli variable that occurs with a certain probability pi. Given a reference data set of N compounds and their fingerprints A = {ak|1 ≤ k ≤ N} where ak = (aj1, aj2, … ajd) the probabilities can be estimated from the relative frequencies:
The cardinality of a fingerprint itself, of the intersection, and of the union can then be modeled as a sum of non-identically distributed Bernoulli variables. In the case of independent variables, the sum follows a Poisson binomial distribution with mean
and variance
and can be approximated by a normal distribution. Because the cardinalities of the intersection and union of two sets are not independent, the Tc is then modeled as the ratio of two correlated normal distributions for which approximations exist23,24.
Fingerprint features are often correlated. Ignoring these correlations leads to a significant underestimation of the variance (Equation 5)13,14. While the equation for the mean μ remains valid for correlated random variables, the formula for the variance σ2 requires taking the pairwise covariances cij = cov(Xi,Xj) between the different features into account. These can also be estimated from the reference set:
Accordingly, the value cii = pi (1 – pi) denotes the variance of Xi.
Based on these estimates, the average cardinality of a fingerprint itself, of the intersection, and of the union of two unknown fingerprints can be determined:
For the respective variances, one obtains:
The covariance between the cardinality of union and intersection is given by:
Normal distributions are defined by their mean and standard deviation and can thus be calculated from the estimates of the averages and variances. However, given the fact that the underlying features are not independent, the suitability of using normal distributions as approximations cannot be guaranteed from a theoretical point of view. Nevertheless, as has been previously shown13,14, and as can be seen from our current evaluation (vide infra), practical applications of the model yield good performance for a variety of different fingerprint designs. Under the assumption of normality, the following models are obtained:
where N(μ,σ2) is the normal distribution with mean μ and standard deviation σ. The Tc distribution is then modeled as a ratio of these two correlated distributions. An analytical form of the probability distribution function exists23; however, for determining p-values and the significance, the following approximation of the cumulative distribution function (CDF) is used24:
Here, ρ = covIU / (σIσU) is the correlation between intersection and union and Φ is the CDF of the standard normal distribution:
The p-value can then be determined as:
For model evaluation, we use F(t) = Pr (Tc ≤ t) directly as an indication of significance.
For similarity searching, reference compounds are used and Tc values of database compounds are calculated relative to the references. As has been shown13, distributions of Tc values can vary greatly depending on the reference fingerprint. In this case, the significance of Tc values should to be considered for a given reference compound. Mathematically, this corresponds to determining the conditional distributions when one fingerprint is given. As in the unconditional case, the distributions are based on sums of correlated Bernoulli variables that are modeled as normal distributions based on the conditional means and variances:
The conditional model is obtained by applying these parameters in Equation 16.
A derivation of the formulas presented here for the CCBM can be found in the original publications13,14.
Sparse fingerprints like ECFPs or the Morgan fingerprint might result in hundreds of thousands of different features present in large data sets. Most of these will occur with very small probabilities pi and only have a small influence on the estimated means and variances. It is computationally unproblematic to handle these individual probability estimates; however, determining pairwise covariances of all possible features becomes infeasible for more than a few thousand features. To address this issue, the complete covariance matrix is only determined for the most frequent features of a sparse fingerprint (by default, the 2048 most frequent features are selected). Covariances involving rare fingerprints are not estimated. Given that feature probabilities of combinatorial fingerprints usually show pseudo-exponential drop-offs for rare features, contributions towards covariance estimates have negligible influence on the final estimates and are ignored in the current implementation.
As reference data set, ChEMBL compounds were selected. SMILES representations of 1,870,461 compounds were downloaded and standardized using a previously published protocol included in the ccbmlib package25. Additionally, stereochemical information was removed since most fingerprints implemented in RDKit do not account for stereochemistry, resulting in 1,691,786 unique compounds. Fingerprint statistics are reported in Table 1.
The software has been implemented as a module for Python 3.7. It requires the installation of RDKit and has been tested with version 2019.03.4 of RDKit. Any system (Linux, Windows, MacOS) capable of running Python 3.7 and RDKit is sufficient for running our software. A 64-bit operating system with at least 8GB RAM is recommended. After obtaining the code it can be installed using Python’s setup utility. The ccbmlib package contains three modules: preprocessing, statistics, and models.
Module preprocessing consists of routines for standardizing molecules and preparing compound data sets. Standardization of molecules is a generally recommended preprocessing step, especially when compound data sets are assembled from different sources.
Module statistics contains classes for feature statistics and distribution models. Its main classes are PairwiseStats and CorrelatedNormalDistributions for the fingerprint statistics and distribution models, respectively. Distribution models are obtained from PairwiseStats objects using the get_tc_distribution method, which are used to generate unconditional and conditional models.
The module models provides the main interface for the package. It offers wrapper functions for calculating RDKit fingerprints and contains the central method get_feature_statistics for generating or retrieving fingerprint statistics for a reference data set. Once calculated, statistics are saved and can be retrieved for later use. Exemplary applications of the module are provided in the readme file of the ccbmlib distribution.
Fingerprint statistics were calculated on the basis of the 1,691,786 unique ChEMBL compounds and distribution models were derived. To evaluate the quality of the general model, 1,000,000 Tc values were calculated from pairs of random compounds drawn from the ChEMBL data set and empirical CDFs were determined. Figure 1 compares the empirical CDFs to the modeled unconditional CDFs for the fingerprints in Table 1. Overall, the modeled CDFs match the different value ranges and shapes of the empirical CDFs very well. However, to assess the usefulness of the model as a quantitative and comparative tool, the quality of the model should be assessed with a focus on Tc values indicating high significance. The insets of the figures show an enlarged section with Tc values having a significance of 0.9 or higher. The models for the atom pair fingerprints are not able to accurately model the distribution in this region. However, most other Tc distributions can be modeled very well. For the MACCS, Morgan, and topological torsion fingerprint distributions, high-quality models are obtained with small differences between the theoretical and empirical model. The hashed variants of the Morgan and topological torsion fingerprints have distributions highly similar to their sparse counterparts. This can be expected because the average feature counts reported in Table 1 are also very similar, indicating that most of the sparse features are hashed to unique values and only few collisions occur between hashed values. The path-based Avalon and RDKit fingerprints still have usable, although less accurate models. These observations are consistent with previous observations13. CCBM models pharmacophore-based fingerprints only to a limited extent. This might be due to the specific nature of correlations between pharmacophore features.
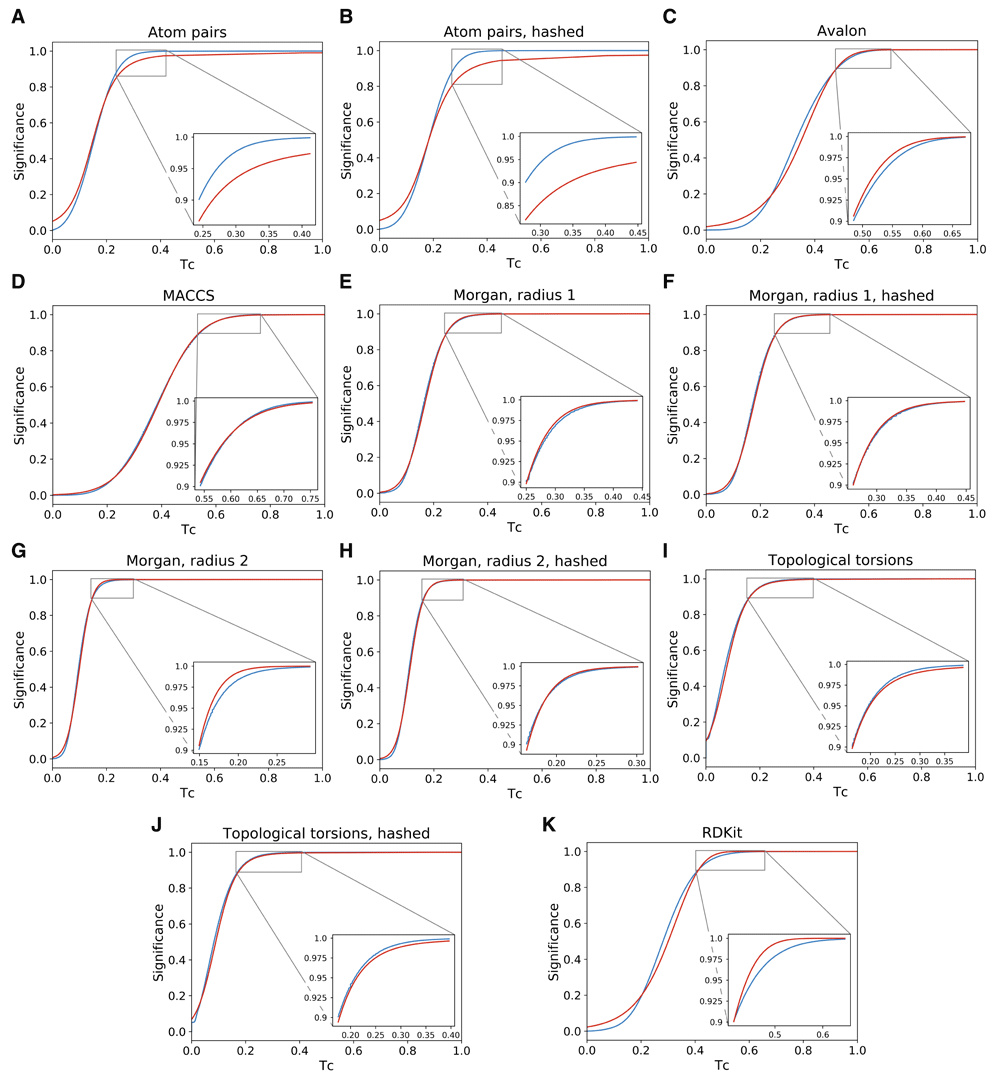
The empirical and modeled cumulative distribution functions for the fingerprints reported in Table 1 are shown in (a) – (k). Blue lines indicate empirical distributions obtained from randomly sampling 1,000,000 pairs of compounds from ChEMBL. Red lines show the corresponding modeled distributions according to Equation (16). The inserts highlight the correspondence between the curves for Tc values of high significance.
A quantitative summary of the observations is given in Table 2. It reports the Kolmogorov-Smirnov statistic (KS)26, which is defined as the maximum difference between empirical (Femp) and modeled (Fmodel) distributions:
In addition, the maximum difference for the significance range beyond 90% is reported (KS90):
The maximum difference for most models is observed for common Tc values, i.e., where the slope of the CDF is steepest. However, as can be seen from the KS90 values, the high significance range can be accurately assessed within 1% for MACCS, most Morgan, the torsion, and the Avalon fingerprints. The RDKit fingerprint still performs reasonably well with a KS90 of 1.70, whereas values of 4.22 and 8.80 for the atom pair fingerprint and its hashed variant indicate poor performance of the model in this region.
In addition to the unconditional model, conditional distributions were investigated when a reference fingerprint was given. As each reference fingerprint will yield a different model, 100 compounds were randomly chosen as a reference and conditional models were derived and compared to empirical Tc distributions by comparing the reference compound to 100,000 randomly chosen compounds. The ranges of correspondences between empirical and modeled significance values are shown in Figure 2. The MACCS and Morgan fingerprints again showed the best conditional models, all of which were close to the ideal diagonal. For most reference compounds, the topological torsion fingerprint also yielded very good models; however, few outliers with large deviations were observed. This might be expected when reference fingerprints only contain very few features and approximations by normal distributions fail to yield accurate models.
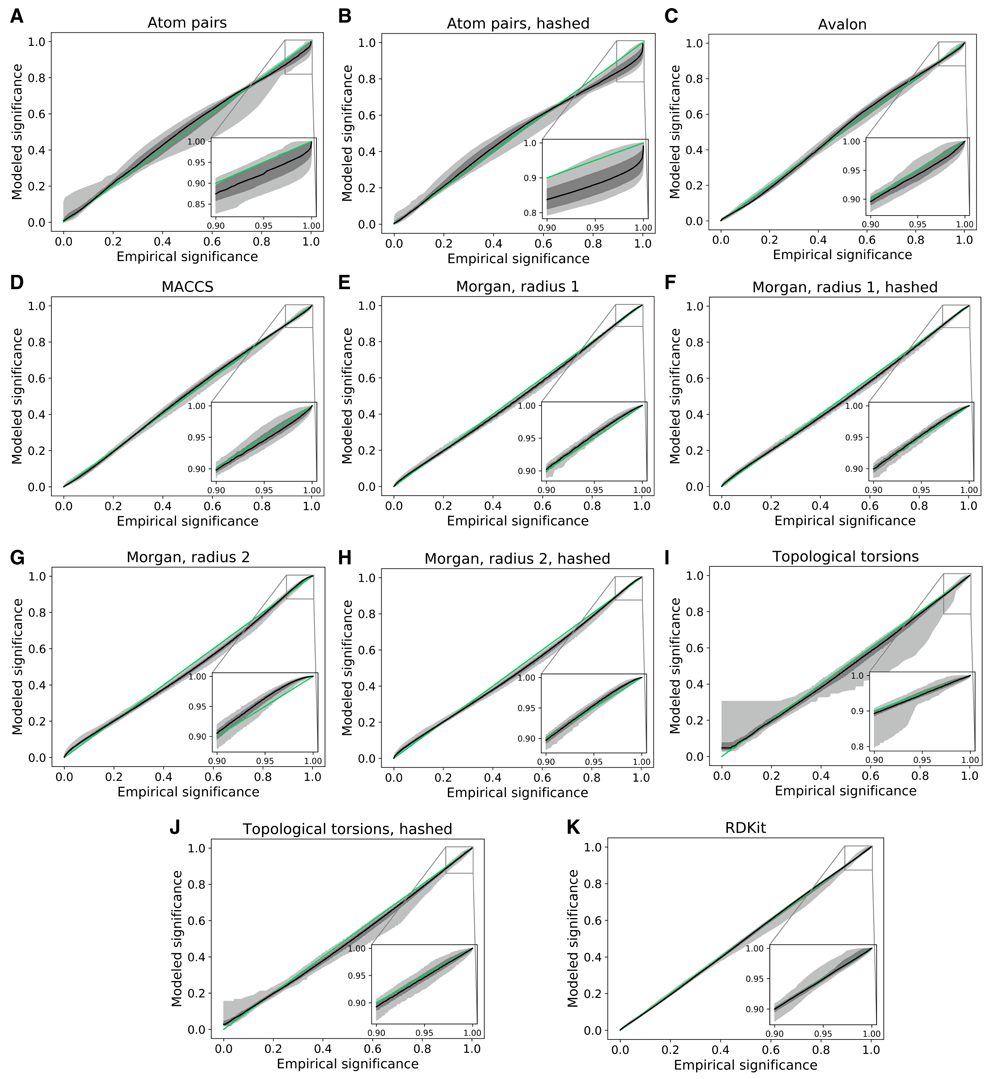
For the fingerprints in Table 1, each of the graphs (a) – (k) shows the variation of correspondences between empirical and modeled significance values of 100 conditional distributions obtained by selecting random reference compounds. Empirical distributions for each reference compound were determined from comparisons of 100,000 randomly chosen compounds. The black line indicates the median correspondence between empirical and modeled distribution. The dark gray area shows the interquartile range and the light gray area the range from the 5th to the 95th percentile. The green line is the diagonal corresponding to a perfectly matching model. The inserts highlight correspondences for significance values larger than 0.9.
The Python code used for data generation, data analysis, and generation of the figures is available in form of a Jupyter notebook in the github repository27.
The tools provided make it possible to evaluate the significance of Tc values for a variety of fingerprints from RDKit. Users can generate distribution models for different fingerprints with respect to reference data sets. Accurate models are obtained for most RDKIT fingerprints including the popular MACCS and Morgan fingerprints. Based on these models, it can be assessed to what extent molecular similarity is accounted for by fingerprints of different design and to what extent similarity between compounds sharing the same activity is reflected by similarity scores calculated on the basis of different fingerprint representations. Furthermore, the conditional models can be used to predict the suitability of fingerprints for similarity searching and ligand-based virtual screening.
The data sets used in this paper are freely available from ChEMBL: https://www.ebi.ac.uk/chembl/
Smiles structure representations were retrieved on 15 Jan 2020 from: ftp://ftp.ebi.ac.uk/pub/databases/chembl/ChEMBLdb/latest/chembl_25_chemreps.txt.gz
Source code is available from: https://github.com/vogt-m/ccbmlib
Archived source code at time of publication: https://doi.org/10.5281/zenodo.363495327
License: MIT
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)