Keywords
Dendrites, computation, linearly separable, implementation
This article is included in the INCF gateway.
Dendrites, computation, linearly separable, implementation
We corrected all the points raised by the reviewers. You canread in details how we addressed them in our response to their comments.
We changed the title from dendritic neurons to neurons with dendrtites following a suggestion from the third reviewer.
The equations contained some small mistakes introduced during the editorial process which we have corrected in the new revisions.
We changed the first three figures to more clearly show which architectures computed the D-AND and the D-OR. We have also reorganizedFigure 4: the new panel B compares the effect of different synaptic weights and shows what would happen with linear dendrites. An additional panel summarizes the effect of changing the weights.
Multiple references were added to the introduction and discussion to make them stronger and clearer.
Finally, We rewrote the discussion to make it flow better and added a paragraph about learning.
See the authors' detailed response to the review by Sacha van Albada
See the authors' detailed response to the review by Alexandra Tzilivaki and Panayiota Poirazi
See the authors' detailed response to the review by Fleur Zeldenrust
In theoretical studies, scientists typically represent neurons as linear threshold units (LTU; summing up the weighted inputs and comparing the sum to a threshold)1. Multiple decades ago, theoreticians exactly delimited the computational capacities of LTUs, also known as perceptrons2. LTUs cannot implement computations like the exclusive or (XOR), but they can implement all possible linearly separable computations and a sufficiently large network of LTUs can approximate all possible computations3.
Research in computer science investigated the synaptic weight resolution required to implement linearly separable computations4,5. Hastad et al. studied a computation implementable by an LTU only if its synaptic weight resolution grows exponentially with the number of inputs. We consider, similarly to these studies, the needed resources as the minimal size of integer-valued weights necessary to implement a set of linearly separable computations.
Requiring a high synaptic resolution has important consequences. In the nervous system, neurons would need to maintain a large number of synapses or synapses with a large number of stable states. For the same reason, neuromorphic chips based on LTUs have to dedicate a large amount of resources to synapses6. We demonstrate here that dendrites might be a way to cope with this challenge.
Dendrites are the receptive elements of neurons where most of the synapses lay. They turn neurons into a multilayer network7,8 because of their non-linear properties9,10. These non-linearities enable neurons to perform linearly inseparable computations like the XOR or the feature binding problem11,12. The non-linear integration also appears to be tuned for efficient integration of in vivo presynaptic activity13.
In this study, we investigate whether dendrites can also decrease the synaptic resolution necessary to implement linearly separable computations. We address this question by looking at all the computations of three input variables implementable by an LTU with positive synaptic weights. We then extend the definition of one of these computations to an arbitrarily high number of inputs. Finally, we implement this computation in a biophysical neuron model with two passive dendrites using fewer synapses than an LTU.
This work proposes a new role for dendrites in the nervous system, but also paves the way for a new generation of more cost-efficient artificial neural networks and neuromorphic chips composed of neurons with dendrites.
We performed simulations in a spatially extended neuron model, consisting of a spherical soma (diameter 10 µm) and two cylindrical dendrites (length 400 µm and diameter 0.4 µm). The two dendrites are each divided into four compartments and connect to the soma at one extremity.
In contrast to a point-neuron model, each compartment has a distinct membrane potential.
The membrane potential dynamics of the somatic compartment follows the Hodgkin-Huxley formalism with:
The dendritic compartments only contain passive currents:
Here, Vsoma and Vdend are the respective membrane potentials, Cm = 1µFcm−2 is the membrane capacitance, gL, K, and Na stand for the leak, the maximum potassium and sodium conductances respectively, and EL, EK, and ENa stand for the corresponding reversal potentials. The currents Ia represent the axial currents due to the membrane potential difference between connected compartments. The synaptic current Is arises from a synapse placed at the respective compartment. It is described by
with Es being the synaptic reversal potential and gs the synaptic conductance. This conductance jumps up instantaneously for each incoming spike and decays exponentially with time constant τs = 1 ms otherwise:
The dynamics of the gating variables n, m, and h are identical to 14, except for shifting the membrane potential relative to VT = –50 mV instead of the cell’s resting potential. The equations are omitted here for brevity. The parameter values are summarized in Table 1. Note that due to the absence of sodium and potassium channels in the dendrites, the dendrites are passive and cannot generate action potentials.
| Equilibrium potentials (in mV) | Conductances (in mS/cm2) | ||
|---|---|---|---|
| EL | −65 | gL | 10 |
| ENa | 50 | Na | 100 |
| EK | −90 | K | 30 |
| Es | 0 | ||
All simulations were performed with Brian 215. The code is available at http://doi.org/10.5281/zenodo.431501116. It allows for reproducing the results presented in Figure 4, Figure 5 and Figure 6. To demonstrate that the details of the neuron model do not matter for the results presented here, the provided code can also be run with a simpler leaky integrate-and-fire model.
As a reminder, we first define Boolean functions:
Definition 1. A Boolean function of n variables is a function on {0, 1}n into {0, 1}, where n is a positive integer.
Note that we use the terms function and computation interchangeably.
A special class of Boolean functions, which are of particular relevance for neurons, are linearly separable computations:
Definition 2. f is a linearly separable computation of n variables if and only if there exists at least one vector w ∈ ℝn and a threshold Θ ∈ ℝ such that:
where X ∈ {0, 1}n is the vector notation for the Boolean input variables.
Binary neurons are one of the simplest possible neuron models and closely related to the functions described above: their inputs are binary variables, representing the activity of their input pathways, and their output is a single binary variable, representing whether the neuron is active or not. The standard model is a linear threshold unit (LTU), defined as follows:
Definition 3. An LTU has a set of m weights wi ∈ 𝒲 and a threshold Θ ∈ 𝒯so that:
where X = (X1, . . . , Xm) are the binary inputs to the neuron, and 𝒲 and 𝒯 are the possible values for synaptic weights and the threshold, respectively.
This definition is virtually identical to Definition 2, however, wi and Θ are no longer arbitrary real values, but chosen from a finite set of numbers depending on the specific implementation and noise at which these value can be stabilised. It follows that a neuron may not be able to implement all linearly separable functions. For instance, a neuron with non-negative weights can only perform positive linearly separable computations:
Definition 4. A threshold function f is positive if and only if f (X) ≥ f (Z) ∀(X , Z) ∈ {0, 1}n such that X ≥ Z (meaning that ∀i: xi ≥ zi).
To account for saturation occurring in dendrites, we introduce the sub-linear threshold unit (SLTU):
Definition 5. An SLTU with d dendrites and n inputs has a set of d × n weights wi,j ∈ {0, 1} with n wi such that and a threshold Θ ∈ 𝒯, such that:
with
The function E accounts for dendritic saturation; because we work with binary weights its value is either 0 or 1.
Such a neuron model can implement all positive Boolean computations (see Definition 4) given a sufficient number of dendrites and synapses11.
We used integer-valued and non-negative parameters both for the LTU and the SLTU without loss of generality. It allows us to exactly determine the minimal resources necessary to implement a given computation.
We begin by listing all computations of n = 3 inputs that are implementable by an LTU (i.e., positive threshold functions; Table 2). These computations can be divided in five classes, and one can obtain all computations from a class by swapping the input labels. The OR, AND/OR, and AND can be implemented with equal synaptic weights. In contrast, the remaining classes require heterogeneous synaptic weights. We call these classes the Dominant AND (D-AND) and the Dominant OR (D-OR): to implement these computations, an LTU needs to have one synaptic weight that is twice as big as the others (see Figure 1).
We have assigned a name to each class for easier reference.
| Inputs | OR | AND/OR | AND | D-OR | D-AND |
|---|---|---|---|---|---|
| 000 | 0 | 0 | 0 | 0 | 0 |
| 001 | 1 | 0 | 0 | 0 | 0 |
| 010 | 1 | 0 | 0 | 0 | 0 |
| 011 | 1 | 1 | 0 | 1 | 0 |
| 100 | 1 | 0 | 0 | 1 | 0 |
| 101 | 1 | 1 | 0 | 1 | 1 |
| 110 | 1 | 1 | 0 | 1 | 1 |
| 111 | 1 | 1 | 1 | 1 | 1 |
The D-AND computation gets its name from the fact that it requires the activation of a dominant (D) input AND the activation of another input. The D-OR is the Boolean dual of the D-AND, i.e. obtained by replacing AND operations by OR, and vice versa. In this computation, activation of the dominant input OR of the two other inputs together triggers an output. Both computations have a “dominant input” – an input that is sufficient to make the output true (D-OR), respectively necessary to make the output true (D-AND). There is nothing comparable in the other three computations, which treat all inputs identically. In the present paper, we always chose X1 as the dominant input, but we could have picked X2 or X3.
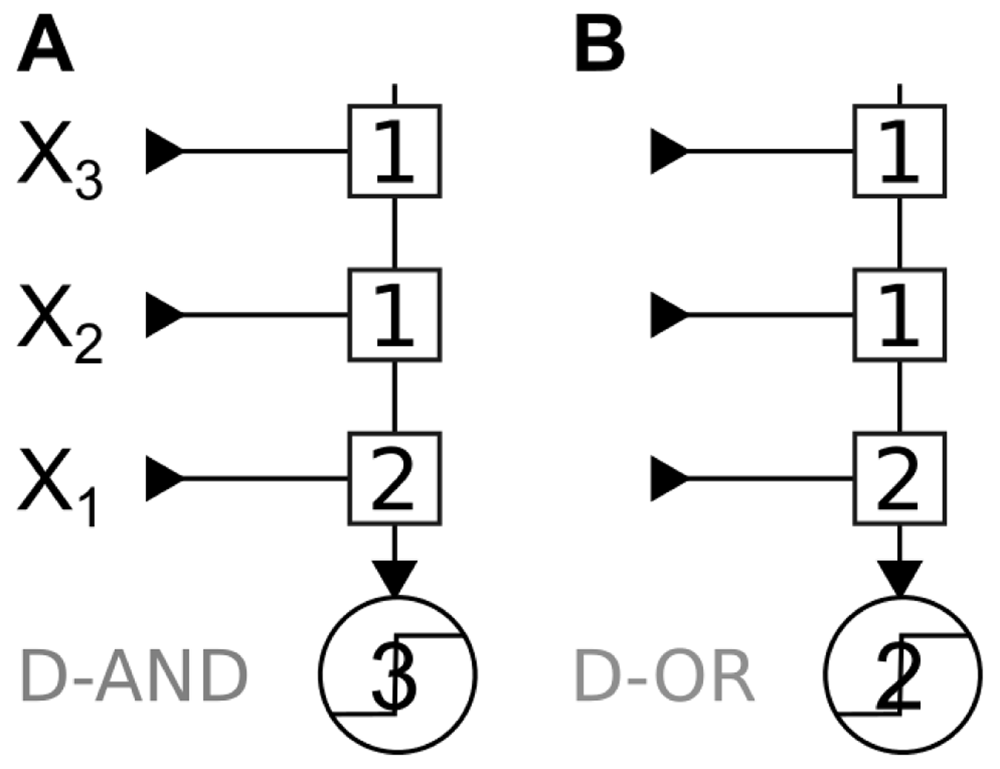
Implementations of the D-AND where X1 is the dominant input. Squares represent synapses with their synaptic weight, and circles stand for transfer functions. Here, the transfer functions are threshold functions with the given value as their threshold. A: Implementation of the D-AND, note that X1 has twice the synaptic weight compared to the others. B: Implementation of the D-OR, note that we keep the same synaptic architecture and we only change the threshold of the transfer function.
An LTU (Figure 1) implements D-AND and D-OR by making use of synaptic strength to distinguish between the dominant and non-dominant inputs. We employed synaptic weights with integer values to reflect their finite precision. Even if synaptic weights can take real values, a finite precision means a finite number of values, which again can be represented by an integer value. The weight and threshold values to implement a function are obviously not unique. For example, we could multiply all the weights by 2 and set the threshold to 6 (D-AND), or 4 (D-OR) and obtain the same results. Here, we always use the lowest possible integer values for synaptic weights, and the corresponding lowest possible threshold.
Next, we wanted to implement the D-AND and D-OR computation in threshold units with non-linear dendritic sub-units, as an abstraction of neurons with dendrites7.
We consider two types of non-linearities: a threshold function to model supra-linear summation; and a saturating function to model sub-linear summation (SLTU; see Methods). Both types of summation have been observed in dendrites. Dendritic spikes are a well-known example of supra-linear summation12, while sub-linear summation can be observed in completely passive dendrites due to a reduced driving force9.
On the one hand, Figure 2 (top) shows that a neuron with supra-linear dendrites implements the D-OR using space whereas the sub-linear implementation uses strength. On the other hand, Figure 2 (bottom) shows that a neuron with supra-linear dendrites implements the D-AND using strength whereas the sub-linear implementation uses space.
In both cases, all synapses are of identical strength. However, note that in the supra-linear implementation of the D-AND in Figure 2C the X1 input connects to both dendrites. Therefore, if we define an input’s synaptic weight as the total effect it has in the final summation stage (analogous to depolarisation measured in the soma of a neuron), we have to consider the weight of X1 as twice as high as the other inputs. This makes this implementation “as bad as” the implementation in an LTU (Figure 1A): the dominance of X1 is expressed by a stronger weight.
This starkly contrasts with the sub-linear implementation of the D-AND (Figure 2D), where all synaptic weights are identical. The placement of X1’s synapse causes its dominance: while X2 and X3 share a dendrite, X1’s synapse lays alone on a dendrite. This implementation uses space. We focus on sub-linear summation and the D-AND for the rest of the study.
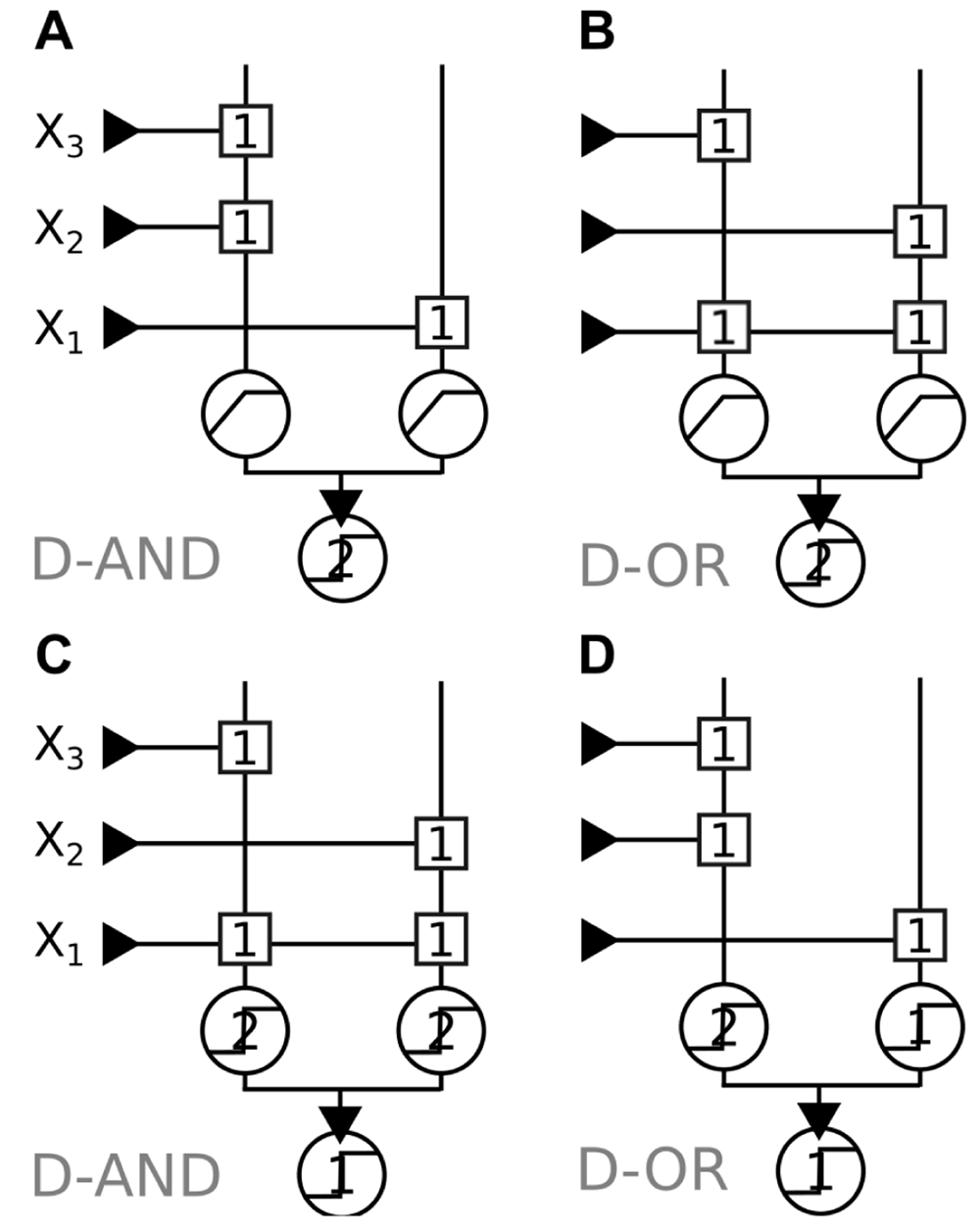
Squares represent synapses and circles represent transfer functions with their respective threshold/saturation values. Note that the final transfer functions (“somatic integration”) are always threshold units, whereas the transfer functions of the sub-units (“dendrites”) are threshold functions for supra-linear summation, and saturating functions (corresponding to the E function defined in Definition 5) for strictly sub-linear summation. A: D-AND implementation using sub-linear summation where X1 targets only one dendrite. B: D-OR implementation, in this case X1 targets two sub-linear dendrites. C: D-AND implementation using supra-linear summation, where X1 targets two dendrites. D: D-OR implementation, X1 in this case targets only one dendrite.
In the previous section, we have limited our analysis to computations with three input variables. We will now extend the definition of the D-AND to an arbitrary number of input variables. As in the three-variables case, we will consider one input to be the dominant input (assumed to be X1, without loss of generality). This input has to be activated together with at least one of the non-dominant inputs. Formally, we therefore define fn(X) as follows:
where X is the n-dimensional input vector with elements X1... Xn.
We can implement this computation in an LTU (Figure 3A), as well as in an SLTU (Figure 3B)
In the LTU implementation (Figure 3A), the D-AND of n variables requires that an input has a synaptic weight at least n − 1 times bigger than the other inputs, and the threshold has to grow accordingly.
We can summarise these observations in a proposition.
Proposition 1. To implement the D-AND, an LTU requires that an input has a synaptic weight n − 1 times bigger than the smallest synaptic weight.
Proof. The LTU must stay silent when X1 is not active, even if X2, X3, . . . , Xn are active. Therefore w2 + w3 + ... + wn < Θ, thus Θ must be at least n × wmin with wmin the smallest synaptic weight.
Conversely, the output should be active as soon as X1 is co-active with any other input Xj (for j > 1). So w1 + wmin ≥ Θ, this means w1 + wmin ≥ n × wmin, thus w1 ≥ wmin(n − 1).
In contrast, Figure 3B provides a constructive proof that an SLTU can implement the D-AND with equal synaptic weights. In this implementation, the distinguishing feature of the dominant input is that it targets the second dendrite; synaptic weights and the threshold do not have to change with the number of inputs. If one only measured the response to single inputs at the “soma” (last stage of summation), the dominant input would be indistinguishable from the other inputs, despite its dramatically different importance.
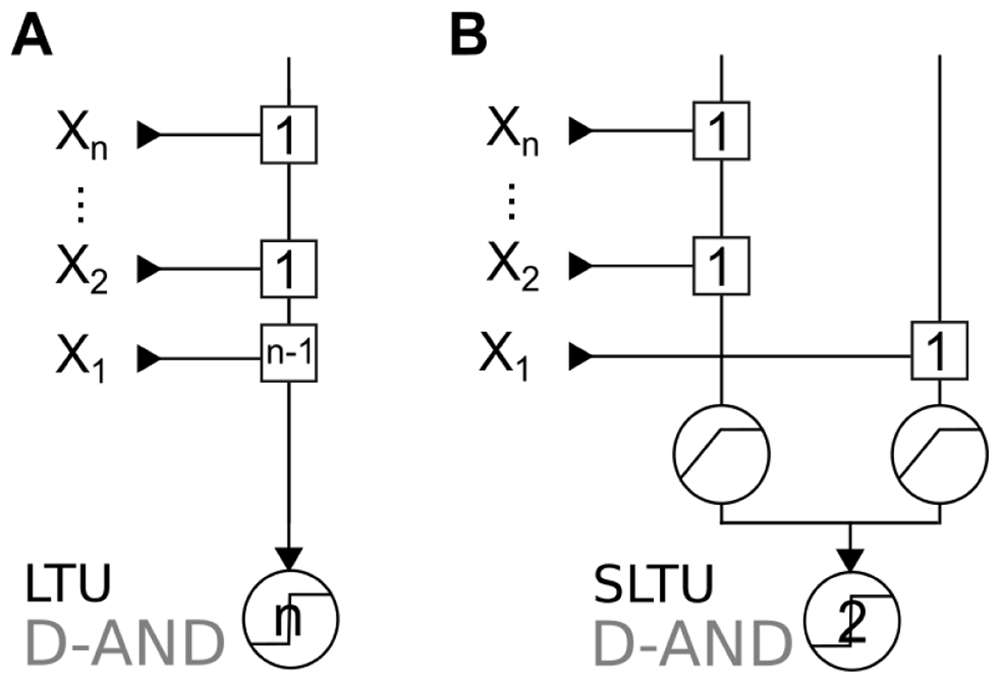
Synaptic weights are in squares, and transfer functions are in circles. A: Minimal D-AND implementation in an LTU. Note that this implementation requires a synaptic weight that is n − 1 times bigger than the smallest weight. B: Implementation in an SLTU with sub-linear summation (see Definition 5).
We will see next how these insights transfer to a more realistic biophysical model.
Figure 4A presents a biophysical model of a single neuron implementing the D-AND computation with three groups of synapses. All the synapses, taken individually, produce the exact same depolarisation at the soma because we place them at the same distance (350 µm) and give them the same maximal conductance (20 nS).
We first look at the sub-threshold behaviour by disabling the sodium channels in the soma ( = 0). Figure 4B plots the somatic voltage response at distinct locations in response to either clustered (black) or dispersed (aquamarine) synaptic activation. Despite activating the same number of synapses in both cases, and despite them all having the same strength, the depolarisation is markedly different. When we disperse active synapses, EPSPs sum linearly (same as dotted gray line) whereas when we cluster active synapses summation becomes sub-linear. This difference is robust with respect to the specific values of the synaptic weights. As shown in Figure 4C, the dispersed activation always exceeds the clustered activation, for the same total synaptic weight. This difference remains even for a total weight bigger for the clustered than the dispersed case. For example, a clustered activation with a total weight of 100 nS leads to a maximum membrane potential of only −54mV in the soma, whereas a dispersed activation with a mere total weight of 10 nS leads to a maximal membrane potential of −52.5mV.
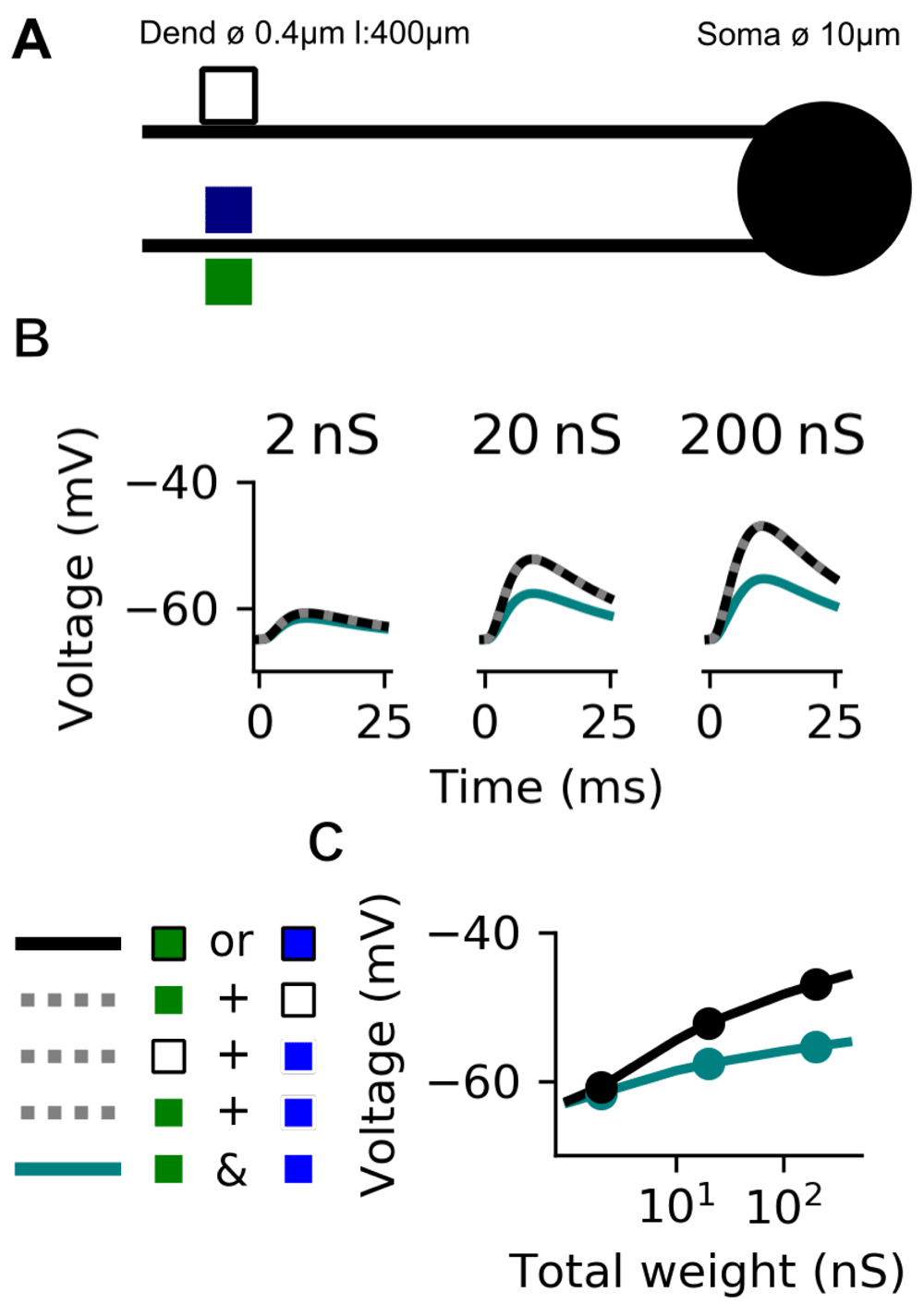
A: A biophysical model with two dendrites and a soma (lines: dendrites, circle: soma). Coloured squares depict synapses. The model has three equivalent groups of synapses (black/blue/green). B: Somatic membrane voltage traces in response to synaptic inputs which are either clustered (synapses activate on the same dendrite; aquamarine) or dispersed (synapses activate on distinct dendrites; black). In a linear neuron, all active groups of synapses (black + blue or black + green or blue + green) produce the same somatic EPSP (gray dotted line). C: Maximal membrane voltage at the soma depending on the total synaptic weight for either clustered (aquamarine) or dispersed (black) stimulation.
We can explain this observation by considering the synaptic driving force17. The synaptic current induced by the activation of the synapse depends on the distance between the membrane potential and the synapses’ reversal potential; when several inputs drive the membrane potential closer to the reversal potential (here 0mV), this driving force diminishes. The combined effect of multiple synaptic inputs is therefore smaller than what is expected from summing the individual effects. In other words, the dendrite performs sub-linear summation.
This means that even if we have a complete synaptic democracy18 (all synapses have the same impact on the soma when taken individually), the relative placement of the synapses strongly influences the somatic response.
Based on the sub-threshold behaviour presented above, we will now show that we can implement the D-AND in a spiking neuron model. It is crucial to look at the supra-threshold behaviour as it is how the neuron communicates with the rest of the network. Moreover, backpropagated action potentials might undermine the dendritic non-linearity disrupting the implementation19.
We can interpret Boolean inputs and outputs in different ways when we apply them to a biophysical spiking neuron model. Here, we will consider two interpretations. Firstly, we can think of an active input as corresponding to a continuous stimulation where the individual spikes arrive at random times, and of an active output as some spiking activity of the neuron (“rate interpretation”). Alternatively, we can think of active inputs as coincidentally arriving spikes within a certain time window, and accordingly of an active output as a single spike emitted in response (“spike interpretation”). We present the model implementing the rate interpretation in Figure 5. We introduced this model earlier (Figure 4), except that it now has active sodium channels in the soma ( = 650mScm–2). Each of its inputs (colours corresponding to the colours in Figure 4) activates in 25 randomly chosen time-bins of 1 ms to simulate a 100 Hz spike train over 250 ms.
The Figure 5 displays, from top to bottom, the model’s responses in five different situations:
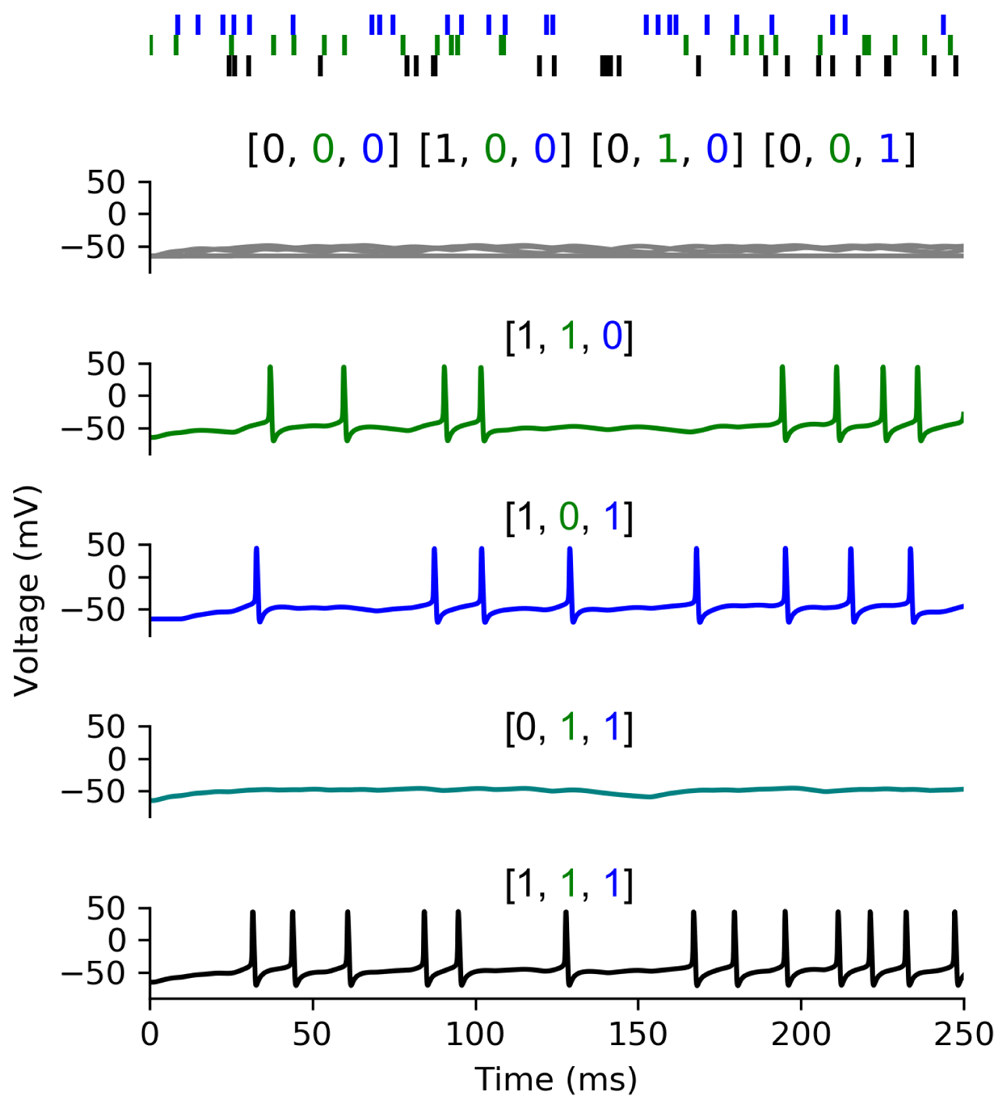
In this interpretation Xi =1 corresponds to a presynaptic neuron firing at 100Hz. Top: activity of the three input synapses, the two first synapses impinge on the same dendrite while the black one impinges on another. Bottom: Eight somatic membrane responses depending on the active inputs. (gray: no synapse/only black/green/blue, green: black + green, blue: black + blue, aquamarine: green + blue, black: all inputs active). Note that this activity reproduces the truth table from Table 2. The difference between the aquamarine line (green and blue inputs) and the green and blue lines (black input and either green or blue input) is due to the sub-linear summation in the dendrite. With linear summation these three input patterns would evoke identical responses.
A single input activates, in this case the neuron remains silent. We obtain the same outcome whatever the chosen input.
Two groups of dispersed inputs activate (black + green or black + blue), in these two scenarios the neuron fires.
The two groups of clustered inputs (green + blue) activate, in this case the neuron remains silent as expected from our observation in Figure 4B.
All inputs activate, in this last case the neuron firing rate remains moderate because of the refractory period.
This figure thus presents the response of the neuron model to all non-trivial cases, we have only omitted the case without any input activation (and therefore without any output activity).
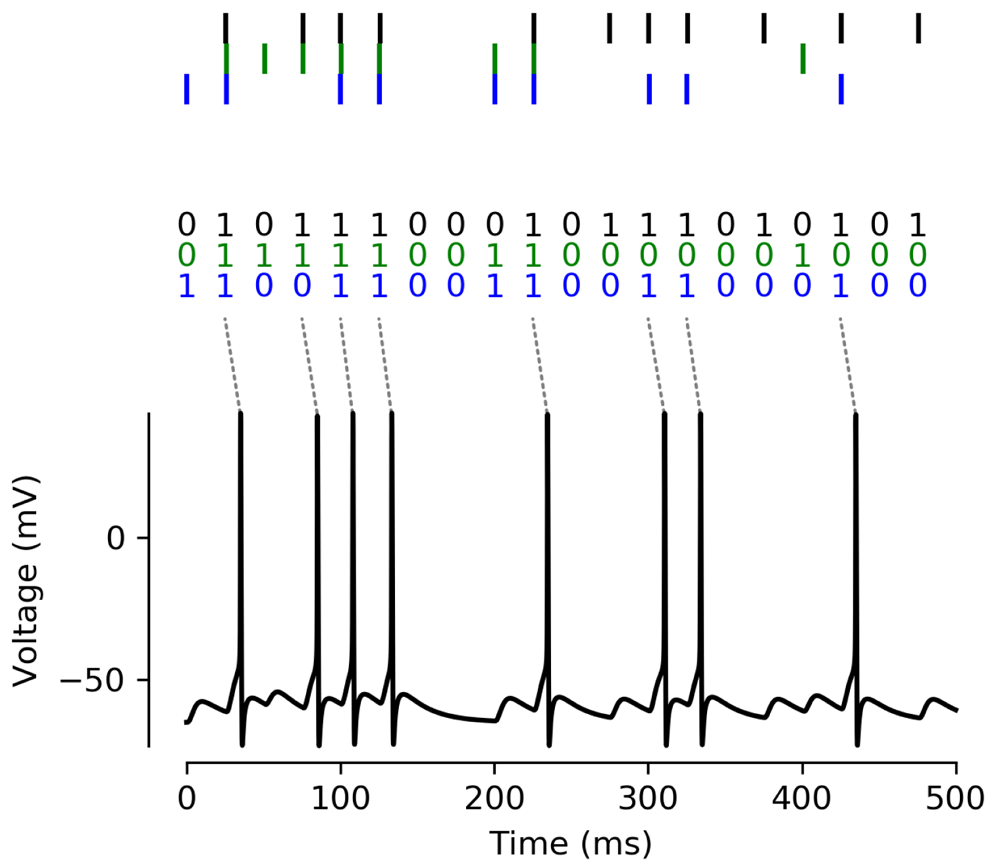
Top: The biophysical model receives input from three sources, where activation happens at regular intervals of 25 ms, with a random jitter of ±1ms for each spike. We translate this activity into a binary pattern for each time bin of 25 ms. Bottom: The model’s membrane potential as measured in the soma. The response spikes implement the output of the D-AND computation as described in Table 2.
Finally, we show an implementation of the spike interpretation in Figure 6. This model is identical to the model shown previously (Figure 5), except for a slightly lower activation threshold of the sodium channels (VT = −55 mV instead of VT = −50 mV) to make it spike more easily. We discretize time into bins of 25 ms and decide randomly for each input whether it is active in each bin. If it is active, it activates at the beginning of the bin with a small temporal jitter (1 ms); inputs activating in the same bin therefore spike coincidentally. We can directly link these activations to Boolean variables that are either 0 (no spike) or 1 (spike). As Figure 6 shows, the neuron implements the D-AND and only spikes whenever the black synapses activate together with at least one of the blue or green synapses.
We have shown that a biophysical model can implement the D-AND computation using a different strategy than the LTU. Each input has the same synaptic weight producing the same depolarisation at the soma. To distinguish between the inputs, the biophysical model uses location instead of strength: the dominant input (black) targets its own dendrite, while the two other inputs cluster on the same dendrite. With this strategy, the model can implement the D-AND. This implementation also works for two interpretations of the Boolean inputs and outputs – as elevated rates of spiking without temporal alignment, or as precisely timed coincident spikes.
In the present work, we oppose the linear threshold unit (LTU) to the sub-linear threshold unit (SLTU), a more realistic neuron model that includes the non-linear processing in dendrites. We compare these two models on the implementation of a simple computation, the D-AND. We define it for three inputs and then extend it to n inputs by keeping its two defining features: a single dominant input that needs to be activated together with at least one of the remaining inputs. In this extension, the synaptic heterogeneity grows linearly with n in the case of an LTU implementation while all synaptic weights remain equal for an SLTU with two dendrites.
Our denomination of one input as “dominant” and the others as “non-dominant” in the definition of the D-AND relates to the distinction between “driver” and “modulator” inputs20. This concept, where driver inputs are necessary to activate a neuron, but this activity can be modulated by other inputs, is ubiquitous in the sensory system. For example, neurons in the primary visual cortex require a stimulus in their classical receptive field. Stimuli in the so-called extra-classical receptive field cannot activate the neuron by themselves, but strongly modulate the response if presented together with a stimulus in the classical receptive field21. This distinction is not entirely applicable for the D-AND, since the dominant input X1 is not sufficient to activate the neuron by itself. Nevertheless, both computations rely on making a distinction between synaptic inputs, which can be implemented by placing inputs on different dendrites as we have shown in this study.
Our findings are in line with a previous study that demonstrated that SLTUs enable to robustly implement a computation22. In that study, an SLTU with eight dendrites implements direction selectivity while being resilient to massive synaptic failure. As in the present work, findings were reproduced in a biophysical model.
Several properties of our biophysical model used here fit with experimental observations. Firstly, synapses at different positions tend to create the same depolarisation at the soma18. Secondly, while the depolarisation generated at a dendritic tip could be large (>50mV) the depolarisation recorded at the soma never exceeds 10mV. Finally, many experimental studies show examples of sub-linear summation in dendrites8,9, notably in interneurons.
How could neurons learn to implement the D-AND in an STLU? Multiple studies have shown that synaptic rewiring can happen at the sub-cellular level in a short time period23 and that such a reorganisation could be used for learning24. This markedly differs from classic Hebbian learning which uses changes in the total synaptic weight to implement computations.
Our findings also have implications beyond neuroscience, in particular for engineering applications. Studies in computer science assert that even problems solvable by an LTU might not have a solution when weights have a limited precision25. Being able to implement computations with an SLTU is therefore advantageous for hardware with limited resources.
In conclusion, dendrites unlock computations inaccessible without them and allow to more efficiently implement the accessible ones. Dendrites enables us to do more with less.
R.C. wrote the initial draft, initiated the project, and made the initial simulations and figures. M.S. added additional simulations and improved part of the simulation code. Both authors discussed the results and wrote the final manuscript.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)