Keywords
SummarizedExperiment, tree, microbiome, hierarchical structure
This article is included in the Bioconductor gateway.
This article is included in the Bioinformatics gateway.
This article is included in the RPackage gateway.
SummarizedExperiment, tree, microbiome, hierarchical structure
Biological data arranged into a hierarchy occurs in several fields. A notable example is in microbial survey studies, where the microbiome is profiled with amplicon sequencing or whole genome shotgun sequencing, and microbial taxa are organized as a tree according to their similarities in the genomic sequence or the evolutionary history. Also, a tree might be used in single cell cytometry or RNA-seq data, with nodes representing cell subpopulations at different granularities1. Currently, phyloseq2 and SingleCellExperiment3 are popular classes used in the analysis of microbial data and single cell data, respectively. The former supports the information pertaining to the hierarchical structure that is available as the phylo class (e.g., phylogenetic tree), and the latter is derived from the SummarizedExperiment class (defined in the SummarizedExperiment package4), which is widely used as a standardized container across many Bioconductor packages. Since the data structures in these fields share similarities, we were motivated to develop an S4 class5, TreeSummarizedExperiment, that not only leverages the facilities from the SummarizedExperiment class, but also bridges the functionality from the phylo class, which is available from the ape6 package and has been imported in more than 200 R packages.
We define TreeSummarizedExperiment by extending the SingleCellExperiment class, so that it is a member of the SummarizedExperiment family, and thus benefits from the comprehensive Bioconductor ecosystem (e.g., iSEE7, SEtools8, and ggbio9). At the same time, all slots of the phyloseq class have their corresponding slots in the TreeSummarizedExperiment class, which enables convenient conversion between these classes. Furthermore, we allow the link between profile data and nodes of the tree, including leaves and internal nodes, which is useful for algorithms in the downstream analysis that need to access internal nodes of the tree (e.g., treeclimbR1).
R version: R version 4.0.2 (2020-06-22)
Bioconductor version: 3.11
Package: 1.4.8
The structure of TreeSummarizedExperiment. The structure of the TreeSummarizedExperiment class is shown in Figure 1.
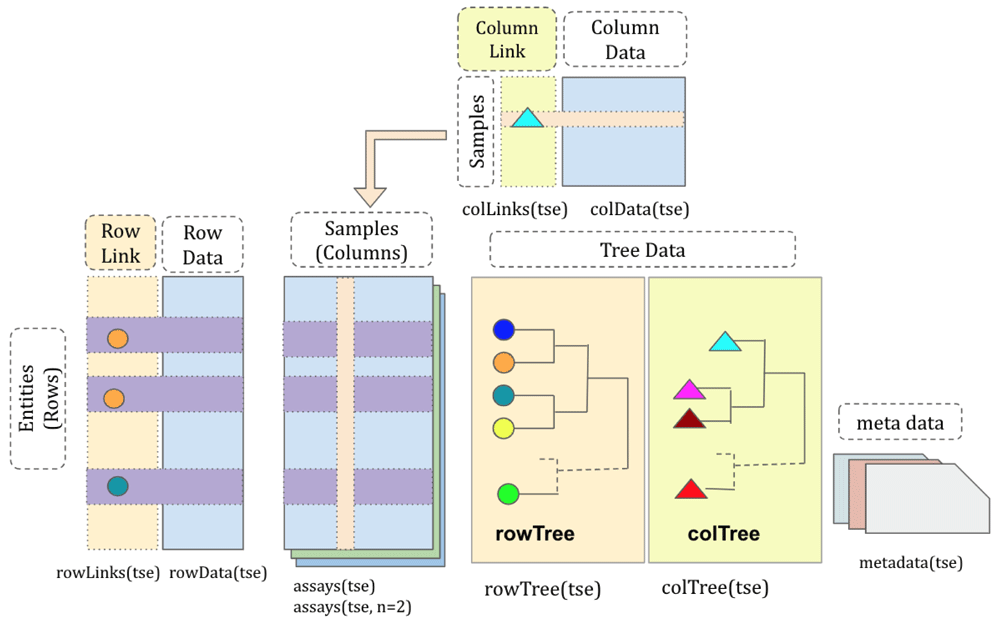
The rectangular data matrices are stored in assays. Each matrix usually has rows representing entities (e.g., genes or microbial taxa) and columns representing cells or samples. Information about rows and columns is stored in rowData and colData, respectively. The hierarchy structure on rows or columns is stored in rowTree or colTree respectively, and the link information between rows/columns and nodes of the row/column tree is in row/Links colLinks.
Compared to the SingleCellExperiment objects, TreeSummarizedExperiment has four additional slots:
rowTree: the hierarchical structure on the rows of the assays.
rowLinks: the link information between rows of the assays and the rowTree.
colTree: the hierarchical structure on the columns of the assays.
colLinks: the link information between columns of the assays and the colTree.
The rowTree and/or colTree can be left empty (NULL) if no trees are available; in this case, the rowLinks and/or colLinks are also set to NULL. All other TreeSummarizedExperiment slots are inherited from SingleCellExperiment.
The rowTree and colTree slots require the tree to be an object of the phylo class. If a tree is available in an alternative format, it can often be converted to a phylo object using dedicated R packages (e.g., treeio10).
Functions in the TreeSummarizedExperiment package fall in two main categories: operations on the TreeSummarizedExperiment object or operations on the tree (phylo) objects. The former includes constructors and accessors, and the latter serves as “components” to be assembled as accessors or functions that manipulate the TreeSummarizedExperiment object. Given that more than 200 R packages make use of the phylo class, there are many resources (e.g., ape) for users to manipulate the small “pieces” in addition to those provided in TreeSummarizedExperiment.
We generate a toy dataset that has observations of 6 entities collected from 4 samples as an example to show how to construct a TreeSummarizedExperiment object.
library(TreeSummarizedExperiment) # assays data (typically, representing observed data from an experiment) assay_data <- rbind(rep(0, 4), matrix(1:20, nrow = 5)) colnames(assay_data) <- paste0("sample", 1:4) rownames(assay_data) <- paste0("entity", seq_len(6)) assay_data
## sample1 sample2 sample3 sample4
## entity1 0 0 0 0
## entity2 1 6 11 16
## entity3 2 7 12 17
## entity4 3 8 13 18
## entity5 4 9 14 19
## entity6 5 10 15 20The information of entities and samples are given in the row_data and col_data, respectively.
# row data (feature annotations) row_data <- data.frame(Kingdom = "A", Phylum = rep(c("B1", "B2"), c(2, 4)), Class = rep(c("C1", "C2", "C3"), each = 2), OTU = paste0("D", 1:6), row.names = rownames(assay_data), stringsAsFactors = FALSE) row_data
## Kingdom Phylum Class OTU
## entity1 A B1 C1 D1
## entity2 A B1 C1 D2
## entity3 A B2 C2 D3
## entity4 A B2 C2 D4
## entity5 A B2 C3 D5
## entity6 A B2 C3 D6# column data (sample annotations) col_data <- data.frame(gg = c(1, 2, 3, 3), group = rep(LETTERS[1:2], each = 2), row.names = colnames(assay_data), stringsAsFactors = FALSE) col_data ## gg group ## sample1 1 A ## sample2 2 A ## sample3 3 B ## sample4 3 B
The hierarchical structure of the 6 entities and 4 samples are denoted as row_tree and col_tree, respectively. The two trees are phylo objects randomly created with rtree from the package ape. Note that the row tree has 5 rather than 6 leaves; this is used later to show that multiple rows in the assays are allowed to map to a single node in the tree.
library(ape) # The first toy tree set.seed(12) row_tree <- rtree(5) # The second toy tree set.seed(12) col_tree <- rtree(4) # change node labels col_tree$tip.label <- colnames(assay_data) col_tree$node.label <- c("All", "GroupA", "GroupB")
We visualize the tree using the package ggtree 2.2.411. Here, the internal nodes of the row_tree have no labels as shown in Figure 2.
library(ggtree) library(ggplot2) # Visualize the row tree ggtree(row_tree, size = 2, branch.length = "none") + geom_text2(aes(label = node), color = "darkblue", hjust = -0.5, vjust = 0.7, size = 4) + geom_text2(aes(label = label), color = "darkorange", hjust = -0.1, vjust = -0.7, size = 4)
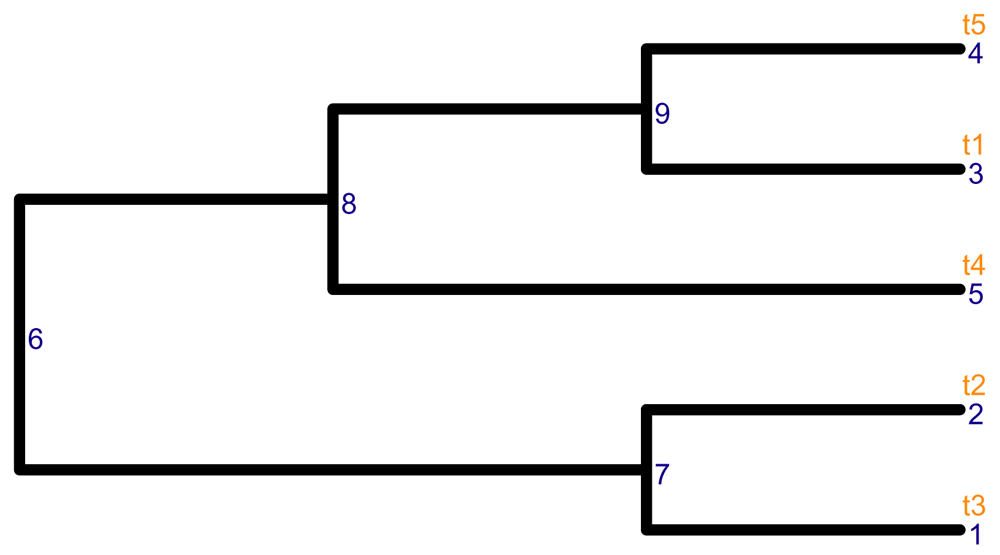
The node labels and the node numbers are in orange and blue text, respectively.
The col_tree has labels for internal nodes as shown in Figure 3.
# Visualize the column tree ggtree(col_tree, size = 2, branch.length = "none") + geom_text2(aes(label = node), color = "darkblue", hjust = -0.5, vjust = 0.7, size = 4) + geom_text2(aes(label = label), color = "darkorange", hjust = -0.1, vjust = -0.7, size = 4)+ ylim(c(0.8, 4.5)) + xlim(c(0, 2.2))
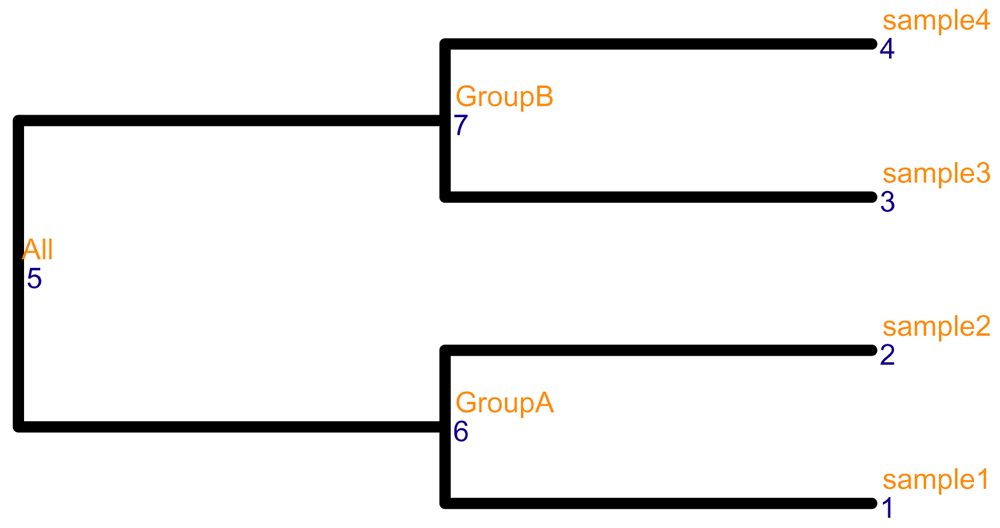
The node labels and the node numbers are in orange and blue text, respectively.
The TreeSummarizedExperiment class is used to store the toy data generated in the previous section: assay_data, row_data, col_data, col_tree and row_tree. To correctly store data, the link information between the rows (or columns) of ssay_data and the nodes of the row_tree (or col_tree) can be provided via a character vector rowNodeLab (or colNodeLab), with length equal to the number of rows (or columns) of the assays; otherwise the row (or column) names are used. Tree data takes precedence to determine entities included during the creation of the TreeSummarizedExperiment object; columns and rows with labels that are not present among the node labels of the tree are removed with warnings. The link data between the assays tables and the tree data is automatically generated during the construction.
The row and column trees can be included simultaneously during the construction of a TreeSummarized-Experiment object. Here, the column names of assay_data can be found in the node labels of the column tree, which enables the link to be created between the column dimension of assay_data and the column tree col_tree. If the row names of assay_data are not in the node labels of row_tree, we would need to provide their corresponding node labels (row_lab) to rowNodeLab in the construction of the object. It is possible to map multiple rows or columns to a node, for example, the same leaf label is used for the first two rows in row_lab.
# all column names could be found in the node labels of the column tree all(colnames(assay_data) %in% c(col_tree$tip.label, col_tree$node.label))
## [1] TRUE# provide the node labels in rowNodeLab tip_lab <- row_tree$tip.label row_lab <- tip_lab[c(1, 1:5)] row_lab
## [1] "t3" "t3" "t2" "t1" "t5" "t4"both_tse <- TreeSummarizedExperiment(assays = list(Count = assay_data), rowData = row_data, colData = col_data, rowTree = row_tree, rowNodeLab = row_lab, colTree = col_tree)
both_tse
## class: TreeSummarizedExperiment
## dim: 6 4
## metadata(0):
## assays(1): Count
## rownames(6): entity1 entity2 ... entity5 entity6
## rowData names(4): Kingdom Phylum Class OTU
## colnames(4): sample1 sample2 sample3 sample4
## colData names(2): gg group
## reducedDimNames(0):
## altExpNames(0):
## rowLinks: a LinkDataFrame (6 rows)
## rowTree: a phylo (5 leaves)
## colLinks: a LinkDataFrame (4 rows)
## colTree: a phylo (4 leaves)When printed on screen, TreeSummarizedExperiment objects display information as the parent SingleCell-Experiment class followed by four additional lines for rowLinks, rowTree, colLinks and colTree.
Slots inherited from the SummarizedExperiment class can be accessed in the traditional way (e.g., assays(), rowData(), colData() and metadata()). These functions are both getters and setters. To clarify, getters and setters are functions for users to retrieve and to overwrite data from the corresponding slots, respectively.
For new slots, we provide rowTree (and colTree) accessors to retrieve the row (column) trees, and rowLinks (and colLinks) to retrieve the link information between assays and nodes of the row (column) tree. Currently, these functions are getters but not setters. If the tree is not available, the corresponding link data is NULL.
# access trees rowTree(both_tse)
##
## Phylogenetic tree with 5 tips and 4 internal nodes.
##
## Tip labels:
## [1] "t3" "t2" "t1" "t5" "t4"
##
## Rooted; includes branch lengths.colTree(both_tse)
##
## Phylogenetic tree with 4 tips and 3 internal nodes.
##
## Tip labels:
## [1] "sample1" "sample2" "sample3" "sample4"
## Node labels:
## [1] "All" "GroupA" "GroupB"
##
## Rooted; includes branch lengths.# access the link data (r_link <- rowLinks(both_tse))
## LinkDataFrame with 6 rows and 4 columns
## nodeLab nodeLab_alias nodeNum isLeaf
## <character> <character> <integer> <logical>
## entity1 t3 alias_1 1 TRUE
## entity2 t3 alias_1 1 TRUE
## entity3 t2 alias_2 2 TRUE
## entity4 t1 alias_3 3 TRUE
## entity5 t5 alias_4 4 TRUE
## entity6 t4 alias_5 5 TRUE(c_link <- colLinks(both_tse))
## LinkDataFrame with 4 rows and 4 columns
## nodeLab nodeLab_alias nodeNum isLeaf
## <character> <character> <integer> <logical>
## sample1 sample1 alias_1 1 TRUE
## sample2 sample2 alias_2 2 TRUE
## sample3 sample3 alias_3 3 TRUE
## sample4 sample4 alias_4 4 TRUEThe link data objects are of the LinkDataFrame class, which extends the DataFrame class with the restriction that it has at least four columns:
nodeLab: the labels of nodes on the tree
nodeLab_alias: the alias labels of nodes on the tree
nodeNum: the numbers of nodes on the tree
isLeaf: whether the node is a leaf node
More details about the DataFrame class could be found in the S4Vectors R/Bioconductor package.
A TreeSummarizedExperiment object can be subset in two different ways: [ to subset by rows or columns, and subsetByNode to retrieve row and/or columns that correspond to nodes of a tree. To preserve the original clustering information, the rowTree and colTree are kept identical after subsetting, while rowLinks and rowData are updated accordingly.
sub_tse <- both_tse[1:2, 1] sub_tse ## class: TreeSummarizedExperiment ## dim: 2 1 ## metadata(0): ## assays(1): Count ## rownames(2): entity1 entity2 ## rowData names(4): Kingdom Phylum Class OTU ## colnames(1): sample1 ## colData names(2): gg group ## reducedDimNames(0): ## altExpNames(0): ## rowLinks: a LinkDataFrame (2 rows) ## rowTree: a phylo (5 leaves) ## colLinks: a LinkDataFrame (1 rows) ## colTree: a phylo (4 leaves)
# the row data rowData(sub_tse) ## DataFrame with 2 rows and 4 columns ## Kingdom Phylum Class OTU ## <character> <character> <character> <character> ## entity1 A B1 C1 D1 ## entity2 A B1 C1 D2
# the row link data rowLinks(sub_tse) ## LinkDataFrame with 2 rows and 4 columns ## nodeLab nodeLab_alias nodeNum isLeaf ## <character> <character> <integer> <logical> ## entity1 t3 alias_1 1 TRUE ## entity2 t3 alias_1 1 TRUE
# The first four columns are from colLinks data and the others from colData cbind(colLinks(sub_tse), colData(sub_tse)) ## DataFrame with 1 row and 6 columns ## nodeLab nodeLab_alias nodeNum isLeaf gg ## <character> <character> <integer> <logical> <numeric> ## sample1 sample1 alias_1 1 TRUE 1 ## group ## <character> ## sample1 A
To subset by nodes, we specify the node by its node label or node number. Here, entity1 and entity2 are both mapped to the same node t3, so both of them are retained
node_tse <- subsetByNode(x = both_tse, rowNode = "t3") rowLinks(node_tse) ## LinkDataFrame with 2 rows and 4 columns ## nodeLab nodeLab_alias nodeNum isLeaf ## <character> <character> <integer> <logical> ## entity1 t3 alias_1 1 TRUE ## entity2 t3 alias_1 1 TRUE
Subsetting simultaneously in both dimensions is also allowed.
node_tse <- subsetByNode(x = both_tse, rowNode = "t3", colNode = c("sample1", "sample2")) assays(node_tse)[[1]] ## sample1 sample2 ## entity1 0 0 ## entity2 1 6
The current tree can be replaced by a new one using changeTree. If the hierarchical information is available as a data.frame with each column representing a taxonomic level (e.g., row_data), we provide toTree to convert it into a phylo object that is further visualized in Figure 4.
# The toy taxonomic table (taxa <- rowData(both_tse)) ## DataFrame with 6 rows and 4 columns ## Kingdom Phylum Class OTU ## <character> <character> <character> <character> ## entity1 A B1 C1 D1 ## entity2 A B1 C1 D2 ## entity3 A B2 C2 D3 ## entity4 A B2 C2 D4 ## entity5 A B2 C3 D5 ## entity6 A B2 C3 D6
# convert it to a phylo tree taxa_tree <- toTree(data = taxa) # Viz the new tree ggtree(taxa_tree)+ geom_text2(aes(label = node), color = "darkblue", hjust = -0.5, vjust = 0.7, size = 4) + geom_text2(aes(label = label), color = "darkorange", hjust = -0.1, vjust = -0.7, size = 4) + geom_point2()
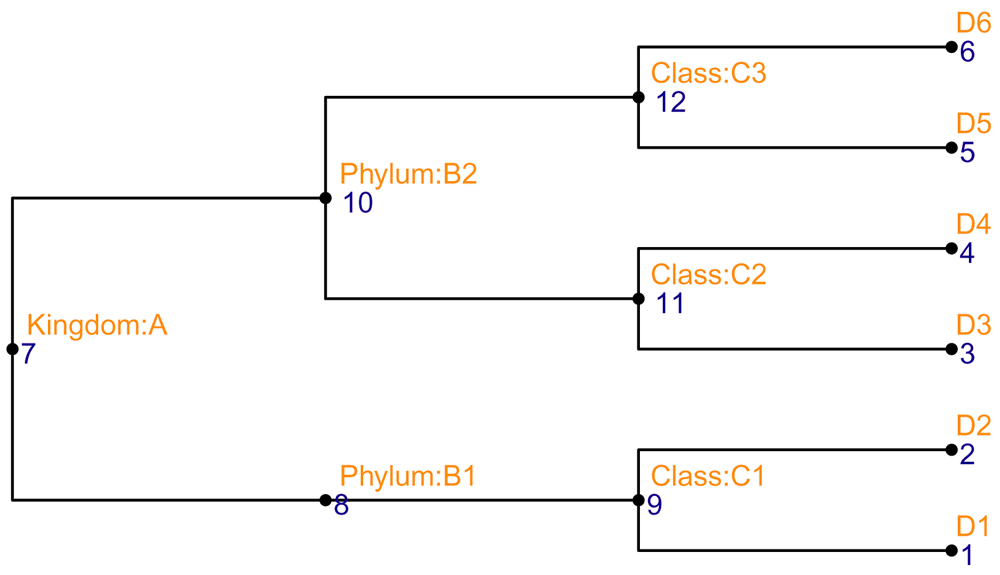
If the nodes of the two trees have a different set of labels, a vector mapping the nodes of the new tree must be provided in rowNodeLab.
taxa_tse <- changeTree(x = both_tse, rowTree = taxa_tree, rowNodeLab = taxa[["OTU"]]) taxa_tse
## class: TreeSummarizedExperiment
## dim: 6 4
## metadata(0):
## assays(1): Count
## rownames(6): entity1 entity2 ... entity5 entity6
## rowData names(4): Kingdom Phylum Class OTU
## colnames(4): sample1 sample2 sample3 sample4
## colData names(2): gg group
## reducedDimNames(0):
## altExpNames(0):
## rowLinks: a LinkDataFrame (6 rows)
## rowTree: a phylo (6 leaves)
## colLinks: a LinkDataFrame (4 rows)
## colTree: a phylo (4 leaves)rowLinks(taxa_tse) ## LinkDataFrame with 6 rows and 4 columns ## nodeLab nodeLab_alias nodeNum isLeaf ## <character> <character> <integer> <logical> ## entity1 D1 alias_1 1 TRUE ## entity2 D2 alias_2 2 TRUE ## entity3 D3 alias_3 3 TRUE ## entity4 D4 alias_4 4 TRUE ## entity5 D5 alias_5 5 TRUE ## entity6 D6 alias_6 6 TRUE
Since it may be of interest to report or analyze observed data at multiple resolutions based on the provided tree(s), the TreeSummarizedExperiment package offers functionality to flexibly aggregate data to arbitrary levels of a tree.
The column dimension. Here, we demonstrate the aggregation functionality along the column dimension. The desired aggregation level is given in the colLevel argument, which can be specified using node labels (orange texts in Figure 3) or node numbers (blue texts in Figure 3). Furthermore, the summarization method used to aggregate multiple values can be specified via the argument FUN.
# use node labels to specify colLevel agg_col <- aggValue(x = taxa_tse, colLevel = c("GroupA", "GroupB"), FUN = sum) # or use node numbers to specify colLevel agg_col <- aggValue(x = taxa_tse, colLevel = c(6, 7), FUN = sum) assays(agg_col)[[1]] ## alias_6 alias_7 ## entity1 0 0 ## entity2 7 27 ## entity3 9 29 ## entity4 11 31 ## entity5 13 33 ## entity6 15 35
The rowData does not change, but the colData is updated to reflect the metadata information that remains valid for the individual nodes after aggregation. For example, the column group has the A value for GroupA because the descendant nodes of GroupA all have the value A; whereas the column gg has the NA value for GroupA because the descendant nodes of GroupA have different values, (1 and 2).
# before aggregation colData(taxa_tse)
## DataFrame with 4 rows and 2 columns
## gg group
## <numeric> <character>
## sample1 1 A
## sample2 2 A
## sample3 3 B
## sample4 3 B# after aggregation colData(agg_col)
## DataFrame with 2 rows and 2 columns
## gg group
## <numeric> <character>
## alias_6 NA A
## alias_7 3 BThe colLinks is also updated to link the new rows of assays tables to the corresponding nodes of the column tree (Figure 3).
# the link data is updated colLinks(agg_col) ## LinkDataFrame with 2 rows and 4 columns ## nodeLab nodeLab_alias nodeNum isLeaf ## <character> <character> <integer> <logical> ## alias_6 GroupA alias_6 6 FALSE ## alias_7 GroupB alias_7 7 FALSE
The row dimension. Similarly, we can aggregate rows to phyla by providing the names of the internal nodes that represent the phylum level (see taxa_one below).
# the phylum level taxa <- c(taxa_tree$tip.label, taxa_tree$node.label) (taxa_one <- taxa[startsWith(taxa, "Phylum:")])
## [1] "Phylum:B1" "Phylum:B2"# aggregation agg_taxa <- aggValue(x = taxa_tse, rowLevel = taxa_one, FUN = sum) assays(agg_taxa)[[1]] ## sample1 sample2 sample3 sample4 ## alias_8 1 6 11 16 ## alias_10 14 34 54 74
Users are nonetheless free to choose nodes from different taxonomic ranks for each final aggregated row. Note that it is not necessary to use all original rows during the aggregation process. Similarly, it is entirely possible for a row to contribute to multiple aggregated rows.
# A mixed level taxa_mix <- c("Class:C3", "Phylum:B1") agg_any <- aggValue(x = taxa_tse, rowLevel = taxa_mix, FUN = sum) rowData(agg_any)
## DataFrame with 2 rows and 4 columns
## Kingdom Phylum Class OTU
## <character> <character> <character> <logical>
## alias_12 A B2 C3 NA
## alias_8 A B1 C1 NABoth dimensions. The aggregation on both dimensions could be performed in one step using the same function specified via FUN, in which case the aggValue function aggregates rows first, and columns second. If different functions are required for different dimensions, or if columns need to be aggregated before rows, users should perform the aggregation in two steps.
agg_both <- aggValue(x = both_tse, colLevel = c(6, 7), rowLevel = 7:9, FUN = sum)
As expected, we obtain a table with 3 rows representing the aggregated row nodes 7, 8 and 9 (rowLevel = 7:9) and 2 columns representing the aggregated column nodes 6 and 7 (colLevel = c(6, 7)).
assays(agg_both)[[1]] ## alias_6 alias_7 ## alias_7 16 56 ## alias_8 39 99 ## alias_9 24 64
Next, we highlight some functions to manipulate and/or to extract information from the phylo object. Further operations can be found in other packages, such as ape6, tidytree12. These functions are useful for users who wish to develop more functions for the TreeSummarizedExperiment class.
To show these functions, we use the tree shown in Figure 5.
data("tinyTree") ggtree(tinyTree, branch.length = "none") + geom_text2(aes(label = label), hjust = -0.1, size = 3) + geom_text2(aes(label = node), vjust = -0.8, hjust = -0.2, color = "blue", size = 3)
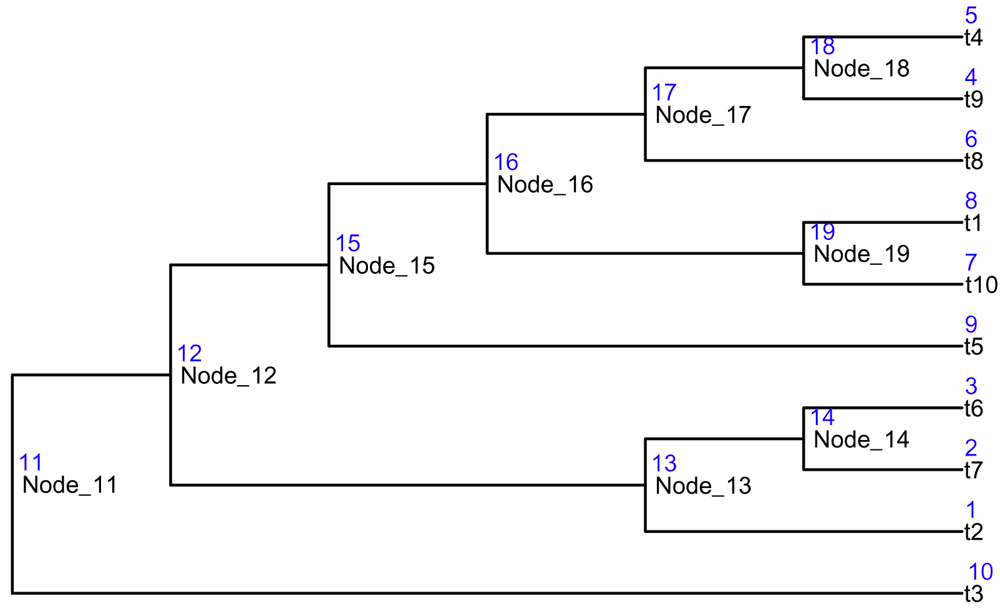
Conversion of the node label and the node number The translation between the node labels and node numbers can be achieved by the function convertNode.
convertNode(tree = tinyTree, node = c(12, 1, 4))
## [1] "Node_12" "t2" "t9"convertNode(tree = tinyTree, node = c("t4", "Node_18"))
## t4 Node_18
## 5 18Find the descendants To get descendants that are at the leaf level, we could set the argument only.leaf = TRUE for the function findDescendant.
# only the leaf nodes findDescendant(tree = tinyTree, node = 17, only.leaf = TRUE)
## $Node_17
## [1] 4 5 6When only.leaf = FALSE, all descendants are returned.
# all descendant nodes findDescendant(tree = tinyTree, node = 17, only.leaf = FALSE) ## $Node_17 ## [1] 4 5 6 18
More functions. We list some functions that might also be useful in Table 1. More functions are available in the package, and we encourage users to develop and contribute their own functions to the package.
Here, we show examples of how to write custom functions for TreeSummarizedExperiment objects. To extract data corresponding to specific leaves, we created a function subsetByLeaf by combining functions working on the phylo class (e.g., convertNode, keep.tip, trackNode) with the accessor function subsetByNode. Here, convertNode and trackNode are available in TreeSummarizedExperiment, and keep.tip is from the ape package. Since the numeric identifier of a node is changed after pruning a tree with keep.tip, trackNode is provided to track the node and further update links between the rectangular assay matrices and the new tree.
# tse: a TreeSummarizedExperiment object # rowLeaf: specific leaves subsetByLeaf <- function(tse, rowLeaf) { # if rowLeaf is provided as node labels, convert them to node numbers if (is.character(rowLeaf)) { rowLeaf <- convertNode(tree = rowTree(tse), node = rowLeaf) } # subset data by leaves sse <- subsetByNode(tse, rowNode = rowLeaf) # update the row tree ## -------------- new tree: drop leaves ---------- oldTree <- rowTree(sse) newTree <- ape::keep.tip(phy = oldTree, tip = rowLeaf) ## -------------- update the row tree ---------- # track the tree track <- trackNode(oldTree) track <- ape::keep.tip(phy = track, tip = rowLeaf) # update the row tree: # 1. get the old alias label and update it to the new alias label # 2. provide the new alias label as rowNodeLab to update the row tree oldAlias <- rowLinks(sse)$nodeLab_alias newNode <- convertNode(tree = track, node = oldAlias) newAlias <- convertNode(tree = track, node = newNode) changeTree(x = sse, rowTree = newTree, rowNodeLab = newAlias) }
The row tree is updated; after subsetting, it has only two leaves, t2 and t3.
(both_sse <- subsetByLeaf(tse = both_tse, rowLeaf = c("t2", "t3")))
## class: TreeSummarizedExperiment
## dim: 3 4
## metadata(0):
## assays(1): Count
## rownames(3): entity1 entity2 entity3
## rowData names(4): Kingdom Phylum Class OTU
## colnames(4): sample1 sample2 sample3 sample4
## colData names(2): gg group
## reducedDimNames(0):
## altExpNames(0):
## rowLinks: a LinkDataFrame (3 rows)
## rowTree: a phylo (2 leaves)
## colLinks: a LinkDataFrame (4 rows)
## colTree: a phylo (4 leaves)rowLinks(both_sse) ## LinkDataFrame with 3 rows and 4 columns ## nodeLab nodeLab_alias nodeNum isLeaf ## <character> <character> <integer> <logical> ## entity1 t3 alias_1 1 TRUE ## entity2 t3 alias_1 1 TRUE ## entity3 t2 alias_2 2 TRUE
The TreeSummarizedExperiment package can be installed by following the standard installation procedures of Bioconductor packages.
# install BiocManager if (!requireNamespace("BiocManager", quietly = TRUE)) install.packages("BiocManager") # install TreeSummarizedExperiment package BiocManager::install("TreeSummarizedExperiment")
Minimum system requirements is R version 3.6 (or later) on a Mac, Windows or Linux system. We highly recommend to use the latest versions of R (currently, 4.0.2) and Bioconductor (at time of writing, 3.11) to gain access to the latest version of this package.
To demonstrate the functionality of TreeSummarizedExperiment, we use it to store and manipulate a microbial dataset. We further show exploratory graphics using the available functions designed for SummarizedExperiment objects in other packages (e.g., scater), or customized functions from popular visualization packages (e.g., ggplot213).
# Packages providing dataset library(HMP16SData) # Packages to manipulate data extracted from TreeSummarizedExperiment library(tidyr) library(dplyr)
# Packages providing visualization library(ggplot2) library(scales) library(ggtree) library(scater) library(cowplot)
The Human Microbiome Project (HMP) 16S rRNA sequencing data, v35, is downloaded using the R package HMP16SData14, which contains survey data of samples collected at five major body sites in the variable regions 3–5.v35 is available as a SummarizedExperiment object via the ExperimentHub.
(v35 <- V35()) ## class: SummarizedExperiment ## dim: 45383 4743 ## metadata(2): experimentData phylogeneticTree ## assays(1): 16SrRNA ## rownames(45383): OTU_97.1 OTU_97.10 ... OTU_97.9998 OTU_97.9999 ## rowData names(7): CONSENSUS_LINEAGE SUPERKINGDOM ... FAMILY GENUS ## colnames(4743): 700013549 700014386 ... 700114717 700114750 ## colData names(7): RSID VISITNO ... HMP_BODY_SUBSITE SRS_SAMPLE_ID # name the assay names(assays(v35)) <- "Count"
We store the phylogenetic tree as the rowTree. Links between nodes of the tree and rows of assays are automatically generated in the construction of the TreeSummarizedExperiment object, and are stored as rowLinks. Rows of the assays matrices that do not have a match to nodes of the tree are removed with warnings.
(tse_phy <- TreeSummarizedExperiment(assays = assays(v35), rowData = rowData(v35), colData = colData(v35), rowTree = metadata(v35)$phylogeneticTree, metadata = metadata(v35)["experimentData"])) ## Warning in .linkFun(tree = rowTree, sce = sce, nodeLab = rowNodeLab, onRow = TRUE): 47 row(s) couldn’t be matched to the tree and are/is removed. ## class: TreeSummarizedExperiment ## dim: 45336 4743 ## metadata(1): experimentData ## assays(1): Count ## rownames(45336): OTU_97.1 OTU_97.10 ... OTU_97.9998 OTU_97.9999 ## rowData names(7): CONSENSUS_LINEAGE SUPERKINGDOM ... FAMILY GENUS ## colnames(4743): 700013549 700014386 ... 700114717 700114750 ## colData names(7): RSID VISITNO ... HMP_BODY_SUBSITE SRS_SAMPLE_ID ## reducedDimNames(0): ## altExpNames(0): ## rowLinks: a LinkDataFrame (45336 rows) ## rowTree: a phylo (45364 leaves) ## colLinks: NULL ## colTree: NULL cD <- colData(tse_phy) dim(table(cD$HMP_BODY_SITE, cD$RUN_CENTER)) ## [1] 5 12
Here, we show TreeSummarizedExperiment working seamlessly with SEtools (v. 1.2.0) to prepare data for the exploratory graphics. Since all operational taxonomic units (OTUs) in the sample belong to Bacteria in the SUPERKINGDOM level, we can calculate the sequencing depths by aggregating counts to the SUPERKINGDOM level. The resultant TreeSummarizedExperiment object agg_total is further converted into a data frame df_total with selected columns (HMP_BODY_SITE and RUN_CENTER) from the column data.
library(SEtools) agg_total <- aggSE(x = tse_phy, by = "SUPERKINGDOM", assayFun = sum) # The assays data and selected columns of the row/col data are merged into a # data frame df_total <- meltSE(agg_total, genes = rownames(agg_total), colDat.columns = c("HMP_BODY_SITE", "RUN_CENTER")) head(df_total) ## feature sample HMP_BODY_SITE RUN_CENTER Count ## 1 Bacteria 700013549 Gastrointestinal Tract BCM 5295 ## 2 Bacteria 700014386 Gastrointestinal Tract BCM,BI 10811 ## 3 Bacteria 700014403 Oral BCM,BI 12312 ## 4 Bacteria 700014409 Oral BCM,BI 20355 ## 5 Bacteria 700014412 Oral BCM,BI 14021 ## 6 Bacteria 700014415 Oral BCM,BI 17157
To make harmonized figures with ggplot2 (v. 3.3.2)13, we customized a theme to be applied to several plots in this section.
# Customized the plot theme prettify <- theme_bw(base_size = 10) + theme( panel.spacing = unit(0, "lines"), axis.text = element_text(color = "black"), axis.text.x = element_text(angle = 45, hjust = 1), legend.key.size= unit(6, "mm"), legend.spacing.x = unit(1, "mm"), plot.title = element_text(hjust = 0.5), legend.text = element_text(size = 9), legend.position="bottom", strip.background = element_rect(colour = "black", fill = "gray90"), strip.text.x = element_text(color = "black", size = 10), strip.text.y = element_text(color = "black", size = 10))
From Figure 6, we note that more samples were collected from the oral site than other body sites.
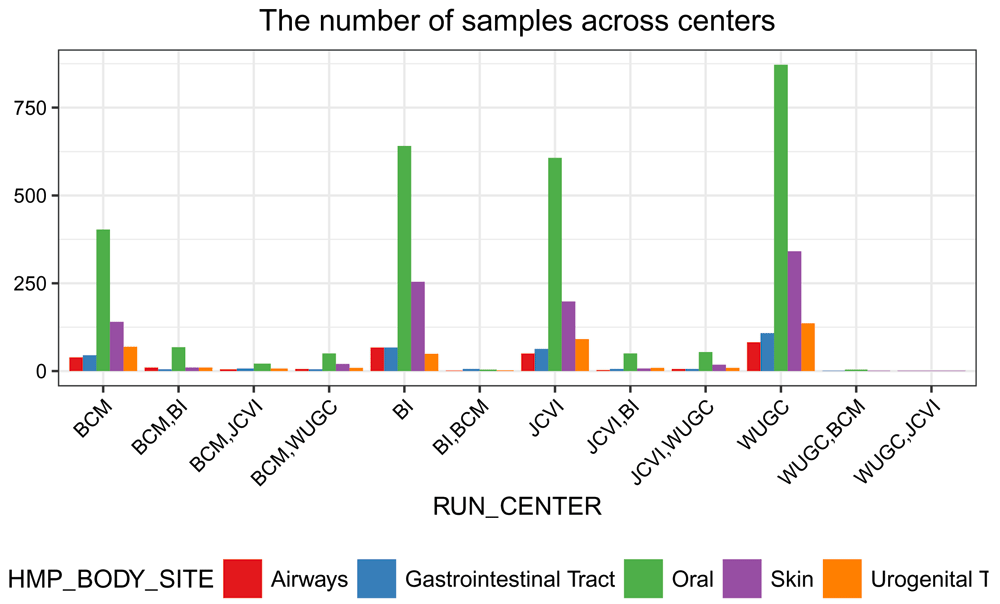
Samples collected at different body sites (HMP_BODY_SITE) are in different colors.
# Figure: (the number of samples) VS (centers) ggplot(df_total) + geom_bar(aes(RUN_CENTER, fill = HMP_BODY_SITE), position = position_dodge()) + labs(title = "The number of samples across centers", y = "") + scale_fill_brewer(palette = "Set1") + prettify
Figure 7 shows that the sequencing depth of each sample across different coordination centers are quite similar. Within the coordination center, samples collected from Skin are more variable in the sequencing depth than those from other body sites.
# Figure: (the sequencing depths) VS (centers) ggplot(df_total) + geom_boxplot(aes(x = RUN_CENTER, y = Count, fill = HMP_BODY_SITE), position = position_dodge()) + labs(title = "The sequencing depths of samples") + scale_y_continuous(trans = log10_trans()) + scale_fill_brewer(palette = "Set1") + labs(y = "Total counts") + prettify
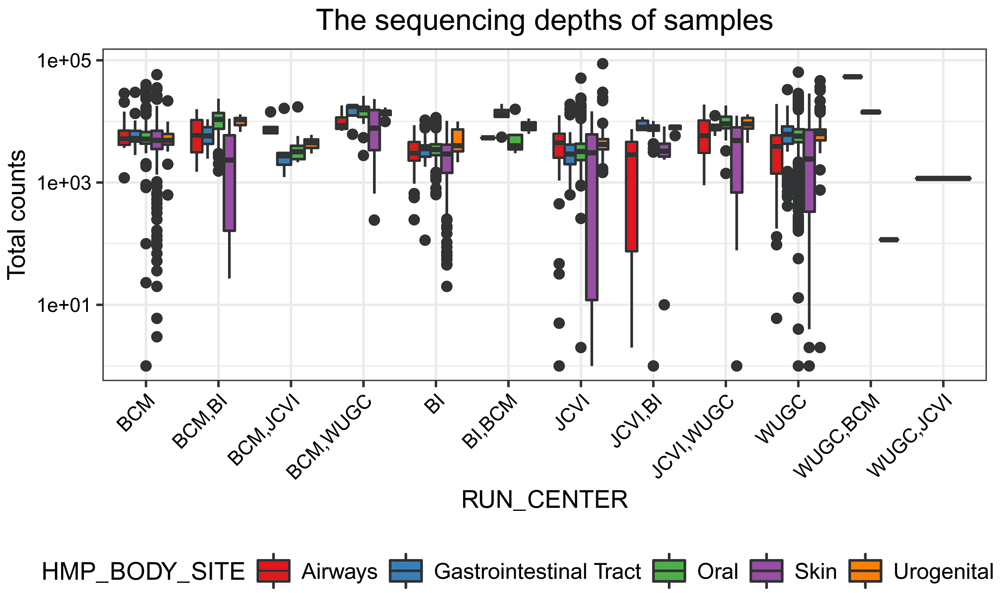
Samples collected at different body sites are in different colors.
We visualize samples in reduced dimensions to see whether those from the same body site are similar to each other. Three dimensionality reduction techniques are available in the package scater (v. 1.16.2), including principal component analysis (PCA)15, t-distributed Stochastic Neighbor Embedding (t-SNE)16, and uniform manifold approximation and projection (UMAP)17. Since TreeSummarizedExperiment extends the SingleCellExperiment class, functions from scater18 can be used directly. Here, we first apply PCA and t-SNE on data at the operational taxonomic unitl (OTU) evel, and select the one better clustering the samples to apply on data aggregated at coarser taxonomic levels to see whether the resolution affects the separation of samples.
The PCA is performed on the log-transformed counts that are stored in the assays matrix with the name logcounts. In practice, data normalization is usually applied prior to the downstream analysis, to address bias or noise introduced during the sampling or sequencing process (e.g., uneven sampling depth). Here, the library size is highly variable (Figure 7) and non-zero OTUs vary across body sites. It is difficult to say what is the optimal normalization strategy, and the use of an inappropriate normalization method might introduce new biases. The discussion of normalization is outside the scope of this work. To keep it simple, we will visualize data without further normalization.
In Figure 8, we see that the Oral samples are distinct from those of other body sites. Samples from Skin, Urogenital Tract, Airways and Gastrointestinal Tract are not separated very well in the first two principal components.
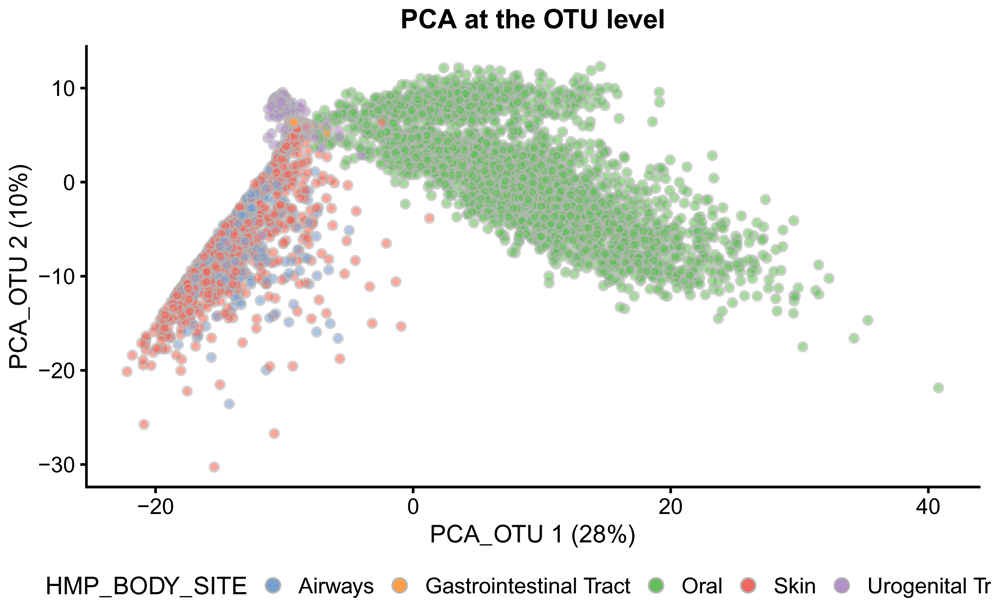
The first two principal components (PCs) are plotted. Each point represents a sample. Samples are coloured according to the body sites.
# log-transformed data assays(tse_phy)$logcounts <- log(assays(tse_phy)$Count + 1) # run PCA at the OTU level tse_phy <- runPCA(tse_phy, name="PCA_OTU", exprs_values = "logcounts") # plot samples in the reduced dimensions plotReducedDim(tse_phy, dimred = "PCA_OTU", colour_by = "HMP_BODY_SITE")+ labs(title = "PCA at the OTU level") + guides(fill = guide_legend(override.aes = list(size=2.5, alpha = 1))) + theme(plot.title = element_text(hjust = 0.5), legend.position = "bottom")
The separation is well improved with the use of t-SNE in Figure 9. Samples from Oral, Gastrointestinal Tract, and Urogenital Tract form distinct clusters. Skin samples and airways samples still overlap.
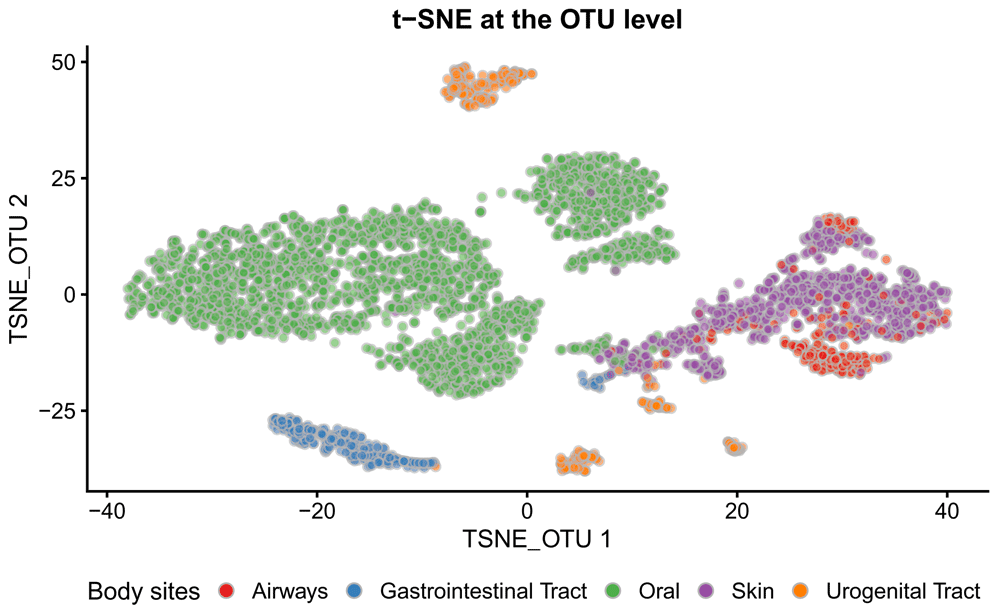
The first two t-SNE components are plotted. Each point represents a sample. Samples are coloured according to the body site.
# run t-SNE at the OTU level tse_phy <- runTSNE(tse_phy, name="TSNE_OTU", exprs_values = "logcounts") # plot samples in the reduced dimensions tsne_otu <- plotReducedDim(tse_phy, dimred = "TSNE_OTU", colour_by = "HMP_BODY_SITE") + labs(title = "t-SNE at the OTU level") + theme(plot.title = element_text(hjust = 0.5)) + scale_fill_brewer(palette = "Set1") + labs(fill = "Body sites") + guides(fill = guide_legend(override.aes = list(size=2.5, alpha = 1))) + theme(plot.title = element_text(hjust = 0.5), legend.position = "bottom") tsne_otu
Notably, there are two well-separated clusters labelled as oral samples. The smaller cluster includes samples from the Supragingival Plaque and Subgingival Plaque sites, while the larger cluster includes samples from other oral sub-sites (Figure 10).
is_oral <- colData(tse_phy)$HMP_BODY_SITE %in% "Oral" colData(tse_phy)$from_plaque <- grepl(pattern = "Plaque", colData(tse_phy)$HMP_BODY_SUBSITE) # Oral samples plotReducedDim(tse_phy[, is_oral], dimred = "TSNE_OTU", colour_by = "from_plaque") + guides(fill = guide_legend(override.aes = list(size=2.5, alpha = 1))) + theme(plot.title = element_text(hjust = 0.5), legend.position = "bottom")
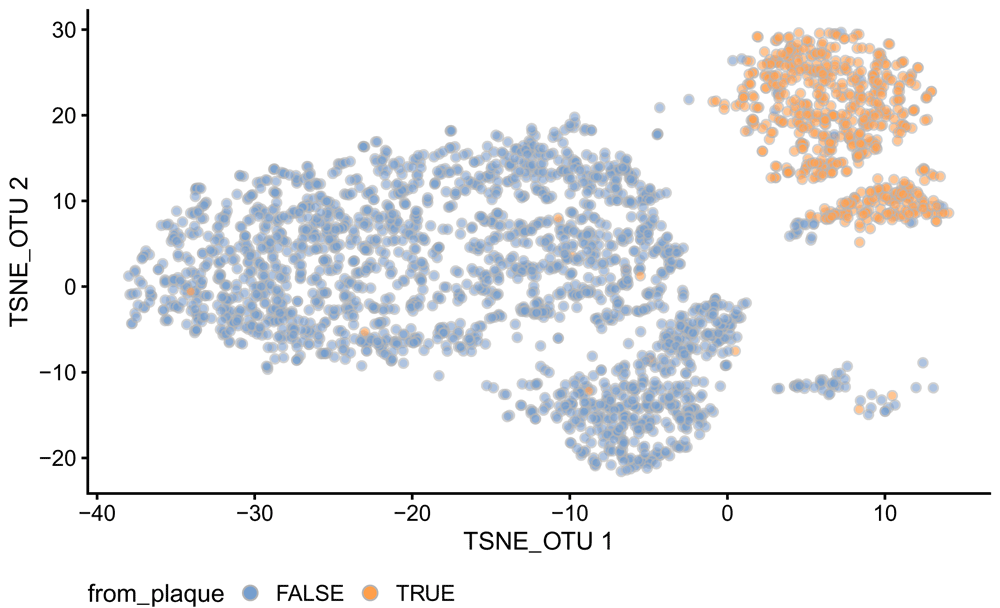
The two t-SNE components computed are plotted. Each point is a sample. Samples from the ‘supragingival or subgingival Plaque‘ are in orange, and those from other oral sub-sites are in blue.
To organize data at different taxonomic levels, we first replace the phylogenetic tree with the taxonomic tree that is generated from the taxonomic table. Due to the existence of polyphyletic groups, a tree structure cannot be generated. For example, the Alteromonadaceae family is from different orders: Alteromonadales and Oceanospirillales.
# taxonomic tree tax_order <- c("SUPERKINGDOM", "PHYLUM", "CLASS", "ORDER", "FAMILY", "GENUS", "CONSENSUS_LINEAGE") tax_0 <- data.frame(rowData(tse_phy)[, tax_order]) tax_loop <- detectLoop(tax_tab = tax_0) # show loops that are not caused by NA head(tax_loop[!is.na(tax_loop$child), ])
## parent child parent_column child_column
## 35 Alteromonadales Alteromonadaceae ORDER FAMILY
## 36 Oceanospirillales Alteromonadaceae ORDER FAMILY
## 37 Rhizobiales Rhodobacteraceae ORDER FAMILY
## 38 Rhodobacterales Rhodobacteraceae ORDER FAMILY
## 39 Chromatiales Sinobacteraceae ORDER FAMILY
## 40 Xanthomonadales Sinobacteraceae ORDER FAMILYTo resolve the loops, we add a suffix to the polyphyletic genus with resolveLoop. For example, Ruminococcus belonging to the Lachnospiraceae and the Ruminococcaceae families become Ruminococcus_1 and Ruminococcus_2, respectively. A phylo tree is created afterwards using toTree.
tax_1 <- resolveLoop(tax_tab = tax_0) tax_tree <- toTree(data = tax_1) # change the tree tse_tax <- changeTree(x = tse_phy, rowTree = tax_tree, rowNodeLab = rowData(tse_phy)$CONSENSUS_LINEAGE)
The separation of samples from different body sites appears to be worse when the data on broader resolution is used (Figure 11).
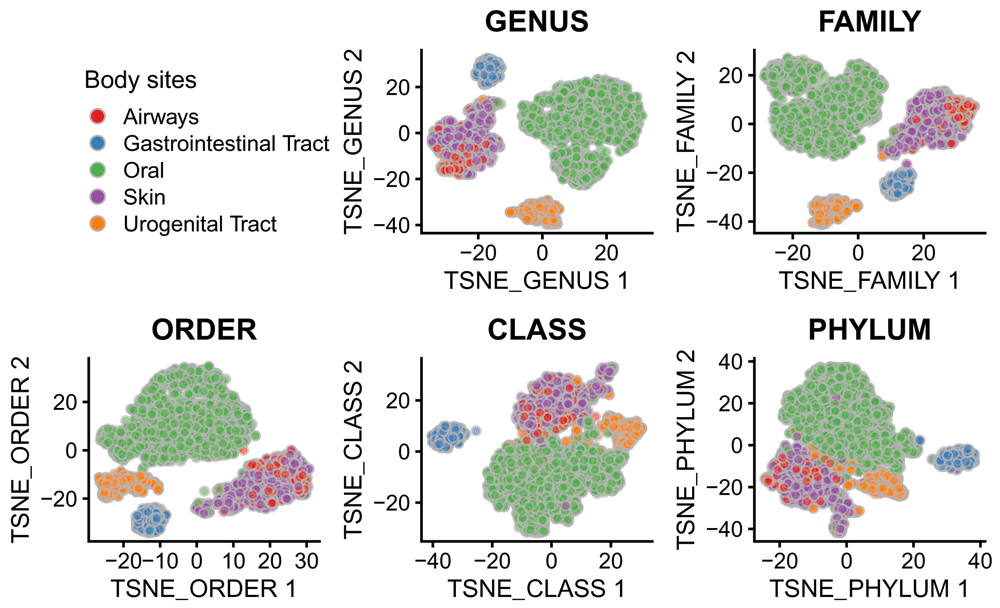
The two t-SNE components computed are plotted. Each point is a sample. Samples are colored according to the body sites.
# aggregation data to all internal nodes tse_agg <- aggValue(x = tse_tax, rowLevel = tax_tree$node.label, assay = "Count", message = FALSE) # log-transform count assays(tse_agg)$logcounts <- log(assays(tse_agg)[[1]] + 1)
Specifically, we loop over each taxonomic rank and generate a t-SNE representation using data aggregated at that taxonomic rank level.
tax_rank <- c("GENUS", "FAMILY", "ORDER", "CLASS", "PHYLUM") names(tax_rank) <- tax_rank fig_list <- lapply(tax_rank, FUN = function(x) { # nodes represent the specific taxonomic level xx <- startsWith(rowLinks(tse_agg)$nodeLab, x) # run t-SNE on the specific level xx_tse <- runTSNE(tse_agg, name = paste0("TSNE_", x), exprs_values = "logcounts", subset_row = rownames(tse_agg)[xx]) # plot samples in the reduced dimensions plotReducedDim(xx_tse, dimred = paste0("TSNE_", x), colour_by = "HMP_BODY_SITE") + labs(title = x) + theme(plot.title = element_text(hjust = 0.5, size = 12))+ scale_fill_brewer(palette = "Set1") + theme(legend.position = "none") + guides(fill = guide_legend(override.aes = list(size=2.5))) })
legend <- get_legend( # create some space to the left of the legend tsne_otu + theme(legend.box.margin = margin(0, 0, 0, 35), legend.position = "right") ) plot_grid(plotlist = fig_list, legend, nrow = 2)
TreeSummarizedExperiment is an S4 class in the family of SummarizedExperiment classes, which enables it to work seamlessly with many other packages in Bioconductor. It integrates the SummarizedExperiment and the phylo class, facilitating data access or manipulation at different resolutions of the hierarchical structure. By providing additional functions for the phylo class, we support users to customize functions for the TreeSummarizedExperiment class in their workflows.
Human Microbiome Project data (v35) was used for the presented use cases. The data can be downloaded using the R package HMP16SData14.
The TreeSummarizedExperiment package is available at:
https://doi.org/doi:10.18129/B9.bioc.TreeSummarizedExperiment
Source code of the development version of the package is available at:
https://github.com/fionarhuang/TreeSummarizedExperiment
Archived source code as at time of publication: http://doi.org/10.5281/zenodo.404609619
License: MIT
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)