Keywords
ImageJ, Fiji, KNIME, image annotation, image classification, ground-truth labelling, qualitative analysis, bioimage analysis
This article is included in the Bioinformatics gateway.
This article is included in the Software and Hardware Engineering gateway.
This article is included in the NEUBIAS - the Bioimage Analysts Network gateway.
ImageJ, Fiji, KNIME, image annotation, image classification, ground-truth labelling, qualitative analysis, bioimage analysis
A common requirement of most imaging projects is to qualitatively describe images, either by assigning them to defined categories or by selecting a set of descriptive keywords. This routine task is shared by various scientific fields, for instance in biomedical research for the categorization of samples, in clinical imaging for image-based diagnostics, or in manufacturing for the description of object-properties.
Qualitative descriptors, or keywords, can correspond to the presence or discrete count of features, the evaluation of quality criteria, or the assignment of images to specific categories. While automated methods for such qualitative description may exist, they usually require substantial effort for their implementation and validation. Therefore, for simple tasks like routine image data analysis and inspection, the qualitative description is usually performed manually.
For small datasets of a few dozen images, manual description of images can be performed by reporting the image and qualitative descriptors in a simple spreadsheet. However, for larger datasets or large number of descriptors, this becomes quickly overwhelming and error prone as one needs to inspect a multitude of images while appending information to increasingly complex tables. Although solutions for qualitative annotations of large datasets exist (Westhoff et al., 2020), there is surprisingly no widespread solution available in common user-oriented image analysis software, for the assignment of multiple descriptive keywords to images. Therefore, we developed a set of plugins for Fiji (Schindelin et al., 2012), to facilitate and standardize routine qualitative image annotations. We also illustrate possible applications of the resulting standardized qualitative description for the exploration of data-distribution, or the training of supervised image classification algorithms.
We developed a set of Fiji plugins for the assignment of multiple pre-defined keywords to images. This set of keywords is entered by the user at the beginning of the annotation session. The image annotation is then carried out using an intuitive graphical user interface consisting of either buttons, checkboxes, or dropdown menus, which are automatically generated from the user-defined keywords (Figure 1–Figure 3). In addition to the pre-defined set of keywords, arbitrary image-specific comments can also be entered via a text input field. Furthermore, if run Measure is selected in the graphical interface, quantitative measurements as defined in Fiji’s menu Analyze>Set Measurements are reported in addition to the selected keywords. By default, the annotations and measurements are assigned to the entire image but can also describe image-regions outlined by regions of interest (ROI). The latter is simply achieved by drawing a new ROI on the image or selecting existing ROIs in the ROI Manager before assigning the keywords (Figure 3). Newly drawn ROIs are automatically added to the ROI Manager upon annotation with the plugins.
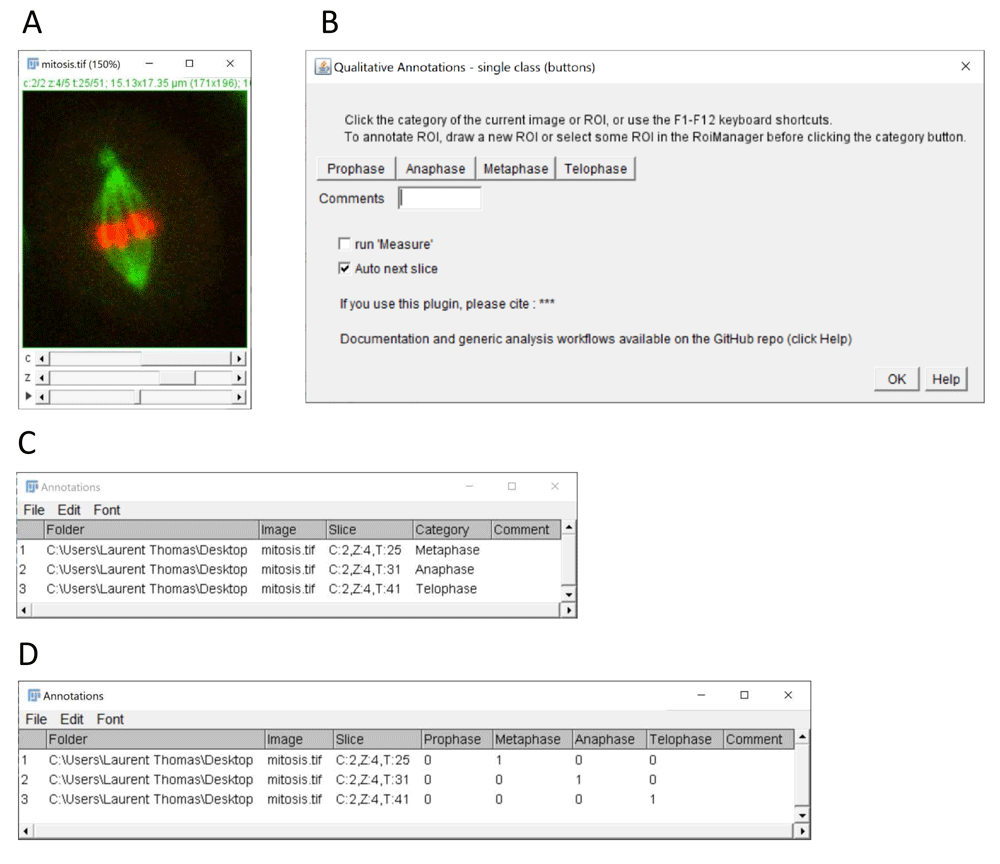
(A) Example of multi-dimensional image stack used to annotate mitotic stages in time-lapse data (source: ImageJ example image “Mitosis” – image credit NIH). (B) Graphical interface of the single class (buttons) plugin configured for annotation of 4 mitotic stages. (C) Results table with annotated categories (column category) generated by the plugin after selecting the single category column option in the plugin configuration window (not shown). (D) Alternative results table output using 1-hot encoding after selecting the option 1 column per category. The resulting 1-hot encoding of categories can be used for the training of classification algorithms.
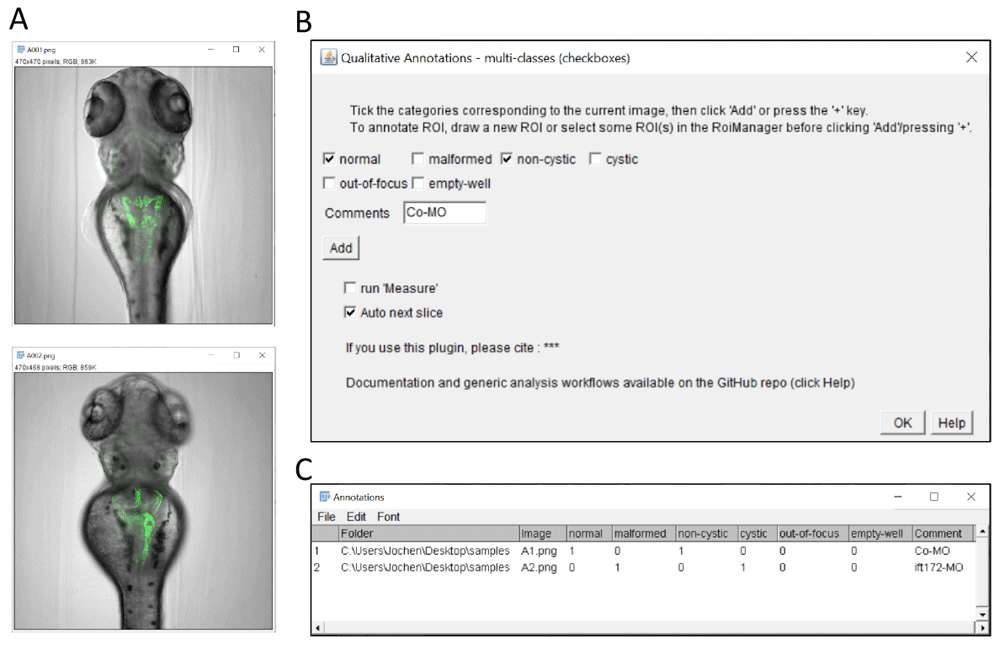
(A) Example images of transgenic zebrafish larvae of the Tg(wt1b:egfp) transgenic line after injection with control morpholino (upper panel) or with ift172 morpholino (lower panel) inducing pronephric cysts. In this illustration, the plugin is used to score overall morphology and cyst formation. It could also be used to mark erroneous images (such as out-of-focus or empty wells). Images are from (Pandey et al., 2019). (B) Graphical interface of the checkbox annotation plugin configured with 2 checkboxes for overall morphology, 2 checkboxes for presence of pronephric cysts, and checkboxes to report out-of-focus and empty wells. Contrary to the single class (button) plugin, multiple categories can be assigned to a given image. (C) Resulting multi-category classification table with binary encoding of the annotations (True/False).

(A) ImageJ’s sample image “embryos” after conversion to grayscale using the command Image > Type > 32-bit (image credit: NIH). The embryos outlined with yellow regions of interest were annotated using the “multi-class (dropdown)” plugin. The insets at the top shows the annotation of overlapping ROIs, here corresponding to embryos with phenotype granular texture, dark pigmentation and elliptic shape. The inset at the bottom shows other embryos with different phenotypes (10: smooth/clear/circular, 12: granular/clear/elliptic, 14: smooth/dark/circular). (B) Graphical interface of the multi-class (dropdown) plugin. Three exemplary features are scored for each embryo: texture (granular, smooth), shape (circle, ellipse) and pigmentation (dark, clear). Quantitative measurements as selected in the Analyze > set Measurements menu (here Mean, Min and Max grey level) are also reported for each embryo, when the run Measure option is ticked. (C) ROI Manager with ROIs corresponding to annotated regions. (D) Resulting classification table with the selected features, qualitative measurement and associated ROI identifier for the outlined embryos.
The selected keywords, comments, measurements, and the image filename and directory are reported in a Fiji result table window with one row per annotation event (Figure 1C, D). An annotation event is triggered when a button is clicked, or a keyboard shortcut is pressed. With ROIs, the identifiers of the ROIs are also reported in the table, and the descriptors are saved as properties of the ROI objects. The information can then be retrieved from the ROIs using the Fiji scripting functions. The result table is updated row by row, as the user progresses with the annotations and can be saved as a csv file at any time. The csv file can be edited in any spreadsheet software or text editor, for instance to update the image directory column when images have been transferred to a different location or workstation.
Three plugins are provided to accommodate for different annotation modalities. The single-class (buttons) plugin (Figure 1) allows the assignment of a single keyword per image by clicking the corresponding button. With this plugin, the user can decide if the result table should contain a single category column containing the clicked category keyword for each image (Figure 1C), or one column per category with a binary code (0/1) depicting the assignment (Figure 1D). The latter option is particularly suitable for the training of supervised classification algorithms, which typically expect for their training an array of probabilities with 1 for the actual image-category and 0 for all other categories (also called 1-hot encoding, see (Müller & Guido, 2016)).
The multi-class (checkboxes) plugin (Figure 2) allows multiple keywords per image, which are selected via associated checkboxes (Figure 2B). This yields a result table with one column per keyword, and a 0/1 code if the keywords apply or not (Figure 2C). In this case, the table structure is similar to Figure 1D except that multiple keywords might be selected for a given image (i.e. multiple 1 for a given table row, as in row 1).
The multi-class (dropdown) plugin (Figure 3) allows to choose keywords from several lists of choices using dropdown menus (Figure 3B). The labels and choices for the dropdown menus are defined by the user in a simple csv file (Extended data, Supplementary Figure 1) (Thomas, 2020). This is convenient if multiple image features should be reported in separate columns (content, quality, etc.) with several options for each feature.
The plugins run on any system capable of executing Fiji. Executing one of the plugins will first display a configuration window requesting the user-defined keywords. Upon validation of the configuration, the actual annotation interface as in Figure 1–Figure 3 is displayed and ready to use for annotation. For the single-class (buttons) plugin, annotations can be recorded by clicking the corresponding category button, or by pressing one of the F1-F12 keyboard shortcuts. The shortcuts are automatically mapped to the categories in the order of their respective buttons, e.g. pressing F1 is equivalent to clicking the leftmost button. For the multi-class plugins, the annotations can be recorded by clicking the Add button or pressing one of the + keys of the keyboard.
For every plugin, an annotation event updates the results table as described in the implementation section, stores any newly drawn ROI into Fiji’s ROI Manager, and if the corresponding option is selected in the graphical user interface, the next image slice is displayed when a stack is annotated. The annotation table can be saved to a csv file at any time like a regular Fiji table. Moreover, the annotations can be appended to an existing result table in Fiji, provided the associated window is entitled “Annotations” or “Annotations.csv”.
The described plugins allow the rapid and systematic description of images or image regions with custom keywords. Additionally, by activating the measurement option, the qualitative description can be complemented by any of ImageJ’s quantitative measurements. The annotation tools can be used for routine image evaluation e.g. for the assignment of predefined categories, to identify outliers or low-quality images, or to assess the presence of a particular object or structure. Examples annotations are illustrated in Figure 1 (single-cell mitotic stage), Figure 2 (pronephric morphological alterations in transgenic zebrafish larvae (Pandey et al., 2019) and Figure 3 (phenotypic description of multi-cellular embryos). Images and annotations are available as Underlying data (Pandey et al., 2020).
For the annotation of ROIs, the presented plugins can be used in combination with our previously published ROI 1-click tools (Thomas & Gehrig, 2020), which facilitate the creation of ROIs of predefined shapes, and the automated execution of custom commands for these ROIs. The generated ROIs can then be described with qualitative features using the hereby presented plugins, either for one ROI at a time, or by simultaneously selecting multiple ROIs. Besides facilitating qualitative annotations, the plugins have the advantage to generate tables with standardized structures that can potentially facilitate the visualization and analysis of the annotations by automated workflows.
To illustrate and expand on the potential of such annotations, we provide a set of generic KNIME workflows which directly operate on tables generated by one of the presented plugins. The workflows do not require advance knowledge of KNIME and can be readily used without major adaptation. KNIME (Berthold et al., 2009) is particularly suitable for the analysis of data involving both images and tabular data, in an intuitive graphical environment. Especially it allows users to design complex analysis workflows with no or little coding skills. The example workflows demonstrate classical scenarios for the exploitation of qualitative descriptors: (i) the visualization of data-distribution using interactive sunburst chart (Extended data, Supplementary Figure 2) (Thomas, 2020), and (ii) the training of a deep learning model for image classification (Figure 4). By providing those examples, we also wish to facilitate and spread those advanced data-processing tools, by drastically reducing the need for custom development. We also provide detailed documentation about the workflows and other software dependencies on the GitHub repository (https://github.com/LauLauThom/Fiji-QualiAnnotations).
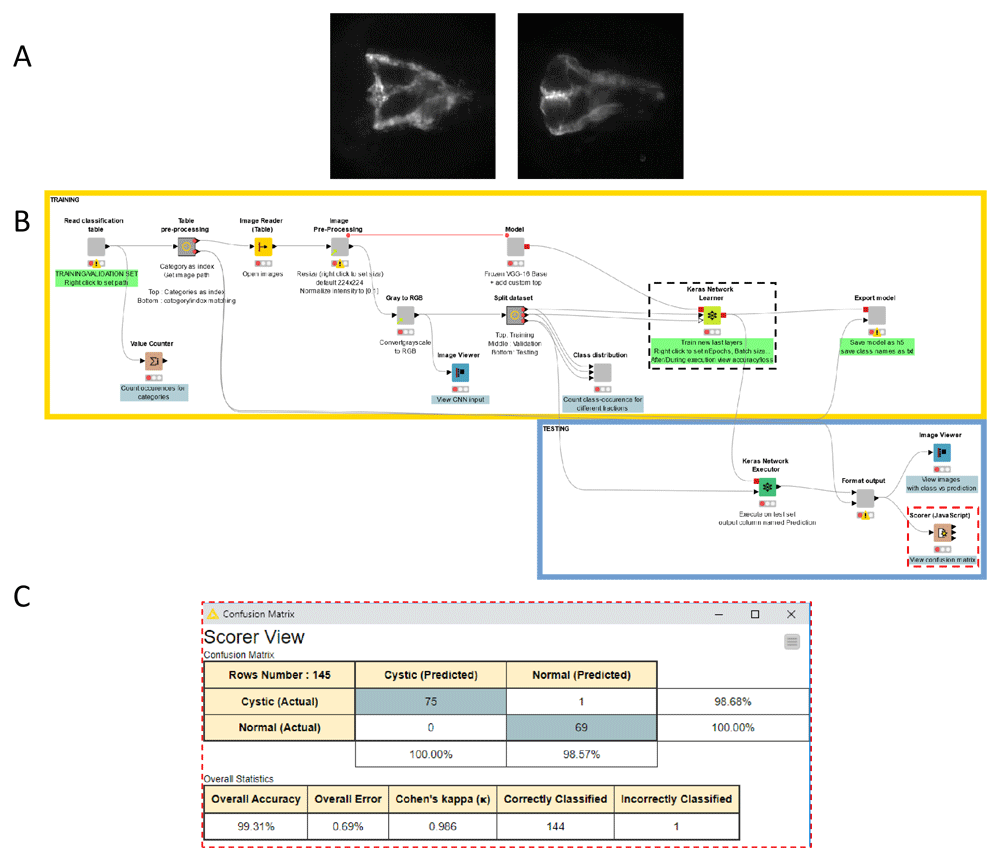
(A) Example images representing the two classes the deep-learning model was trained to recognize. The images show fluorescently-labelled pronephroi in larvae of the Tg(wt1b:EGFP) transgenic zebrafish line showing 2 common morphologies (Left: Normal, Right: Cystic), observed in a previously published chemical screen (Pandey et al., 2019). (B) Screenshot of the KNIME workflow for the training of the model. A subset of the annotated data (training and validation set) is used for the model training (upper part of the workflow outlined in yellow). The remainder of the annotated data (test set) is used for the evaluation of the model performance after training (lower part of the workflow, outlined in blue). The parameters for the training can be adjusted via the settings panel of the Keras network learner node (outlined with dashed black line - See Extended data, Supplementary Figure 3). (C) Confusion matrix as shown by the Scorer node (rightmost side of the workflow, highlighted with red dashed line) depicting the accuracy of the classification by the trained model for the test set. After training for only 5 epochs with 116 training images as explained in the main text, the model achieved already a very good classification accuracy with only 1 image misclassified, out of 145 test images.
Sunburst charts offer an intuitive option for the visualization of the distribution of multiple qualitative features in a dataset. In these charts, the distributions of distinct features are represented as concentric “pies”, which help to identify relations between features. Supplementary Figure 2B (see extend data, Thomas, 2020) shows an example of such a sunburst chart generated with the provided workflow (Sunburst-chart-workflow) for the visualization of three qualitative features (texture, shape, and pigmentation) describing samples annotated in Figure 3. To generate such visualization, the workflow takes as input a table as in Figure 3 and counts the occurrence for each unique combination of qualitative features appearing in the table. The resulting occurrence-table (Extended data, Supplementary Figure 2A) (Thomas, 2020) is then represented as a sunburst chart. The order of the concentric circles is defined by the order of the columns in the annotation table, which can be configured in the workflow. In KNIME, the visualization is rendered as an interactive figure, allowing high-lighting specific sections of the plot, or reducing the number of displayed levels to inspect the distribution of a sub-population (e.g. samples with a smooth texture only). Finally, the provided workflow can be adapted for custom analysis and visualization, using any functionality available in KNIME.
The plugins can also be used to generate the ground-truth annotation for the training of supervised image classification algorithms, such as deep learning models. For this purpose, we adapted an existing KNIME example workflow designed for the training of a convolutional neural network (CNN) by transfer learning, to directly use as input the annotation table provided by the single-class (buttons) plugin (Figure 4). The workflow generates a hybrid model architecture made of a pre-trained VGG16 base (Simonyan & Zisserman, 2015) used for feature-extraction from the images, completed by newly initialized fully-connected layers for the classification with custom classes. The workflow reads the image-locations and image-categories from the annotation table generated by the plugin, and performs classical data pre-processing for the training of CNNs: splitting the annotated dataset between training, validation and test sets, loading and pre-processing of the images and finally training and evaluation of the model. The trained model can be exported as a h5 file, suitable for the prediction of classes for new images. A second workflow is provided for this purpose. As an example of application, the workflow was used to train a model for the identification of two distinct morphological phenotypes of fluorescently-labelled pronephroi (normal and cystic) in transgenic zebrafish larvae as observed in a drug discovery screen (Pandey et al., 2019) (Figure 2A and Figure 4A). For this particular dataset and classification problem, the trained model readily achieved high classification accuracy (>99%, see confusion matrix Figure 4C) on a test set of 145 images (69 normal, 76 cystic) after training for only 5 epochs with a distinct training set of 116 images (57 normal, 59 cystic).
Usually training a custom deep learning model requires substantial programming skills, and a good comprehension of deep learning architecture and parameters. Recent efforts have aimed at facilitating the access of deep learning solutions to non-expert users (Gómez-de-Mariscal et al., 2019; Kräter et al., 2020; von Chamier et al., 2020); however, they usually do not cover the full pipeline from ground-truth annotation to model training, evaluation and application. Here we propose a complete pipeline for image classification that does not require major coding skills and is pre-configured with widely applicable default parameters. The workflow is expected to yield a model with satisfactory classification performance with the default parameters, such that non-expert users can directly get familiar with the method. For better performance, parameters for data pre-processing and model training (e.g. number of epochs, batch-size, learning rate) can be adapted in the configuration window of the Keras network learner node (Extended data, Supplementary Figure 3A). Importantly, using transfer-learning and only training the newly initialized fully-connected layers, the size of the training set and the time to train the network until it reaches a decent accuracy can be dramatically reduced compared to a training from scratch. For the classification of zebrafish pronephroi described above, the training by transfer learning took about 1 minute on a workstation with a Nvidia GTX760 GPU with 2 GB dedicated memory. In contrast, reaching a similar accuracy with the same model trained from scratch would likely require a few hours even on more modern and high-end hardware. Regarding hardware requirement, a CUDA-capable GPU is advised to achieve rapid model training, but the training can also be carried out with CPU only, on any machine supporting KNIME and python. Readers can refer to the GitHub repository (see section Software availability) for detailed descriptions of installation and requirements.
Here, we propose a set of plugins for the qualitative annotations of images or image regions, designed for the popular image analysis software Fiji. The annotations comprise user-defined keywords, as well as optional quantitative measurements as available in Fiji. The keywords can describe categorical classification, the evaluation of quality metrics or the presence of particular objects or structures. The plugins are easy to install and to use via an intuitive graphical user interface. In particular, the tools facilitate tedious qualitative annotation tasks, especially for large-datasets, or for the evaluation of multiple features. The annotations are recorded as standardized result tables, to facilitate automated analysis by generic workflows. To this extent, example workflows for data-visualization and supervised data classification are provided, which can be directly executed with the resulting annotation table without further customization effort. Finally, video tutorials about the plugins and analysis workflows are available on YouTube.
Zenodo: Fluorescently-labelled zebrafish pronephroi + ground truth classes (normal/cystic) + trained CNN model. https://doi.org/10.5281/zenodo.3997728 (Pandey et al., 2020).
This project contains the following underlying data:
Annotations-multiColumn.csv. (Ground-truth category annotations.)
Annotations-singleColumn.csv. (Ground-truth category annotations.)
images.zip. (Images of fluorescently labelled pronephroi in transgenic Tg(wt1b:EGFP) zebrafish larvae used for the training and validation of the deep learning model for classification.)
trainedModel.zip (Pretrained model.)
Zenodo: Qualitative image annotation plugins for Fiji - https://doi.org/10.5281/zenodo.4064118 (Thomas, 2020).
This project contains the following extended data:
Suppl.Fig.1: Detail of the input for the multi-class (dropdown) plugin.
Suppl.Fig.2: Supplementary Figure 2: Visualizing data-distribution using sunburst charts in KNIME.
Supplementary Figure 3: Detail of the Keras network learner node.
Data are available under the terms of the Creative Commons Attribution 4.0 International license (CC-BY 4.0).
Source codes, documentation and example workflows are available at: https://github.com/LauLauThom/Fiji-QualiAnnotations.
Archived source code at time of publication: https://doi.org/10.5281/zenodo.4064118 (Thomas, 2020).
License: GNU General Public License v3.
The plugins can be installed in Fiji by simply activating the Qualitative Annotations update site. Then the plugins are listed under the menu Plugins > Qualitative Annotations.
A pre-configured Fiji installation bundle for windows is also archived in the release section of the repository.
The following KNIME workflows and associated documentation README files are available in the subdirectory KNIMEworkflows under a Creative Commons Attribution 4.0 International License (CC-BY):
- View-Images-And-Annotations workflow
- Sunburst-chart-workflow (with csv of annotations for multi-cellular embryos)
- Deep-Learning – binary classifier – training workflow
- Deep-Learning – binary classifier – prediction workflow
- Deep-Learning – multi-class classifier – training workflow
- Deep-Learning – multi-class classifier – prediction workflow
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)