Keywords
Hackathon, RNA-seq, Sequence Read Archive, MetaSRA, Metadata, Ontology, Jupyter
This article is included in the Hackathons collection.
Hackathon, RNA-seq, Sequence Read Archive, MetaSRA, Metadata, Ontology, Jupyter
The Sequence Read Archive (SRA; Leinonen et al., 2011) is a large public repository that stores next-generation sequencing data from thousands of diverse scientific investigations. Despite its promise, reuse and re-analysis of SRA data has been challenged by the heterogeneity and poor quality of the metadata that describe its biological samples (Gonçalves & Musen, 2019). Recently, the MetaSRA project (Bernstein et al., 2017) standardized these metadata by annotating each sample with terms from biomedical ontologies including Cell Ontology (Bard et al., 2005), Uberon (Mungall et al., 2012), Disease Ontology (Schriml et al., 2019), Cellosaurus (Bairoch, 2018), and the Experimental Factors Ontology (Malone et al., 2010). The MetaSRA also features an interface (http://metasra.biostat.wisc.edu) for querying human RNA-seq samples using these ontology term annotations. However, the MetaSRA web interface is not capable of producing structured datasets such as those that match case samples associated with a target condition or disease with healthy control samples. Similarly, the MetaSRA is also not capable of searching for samples associated with a particular condition and/or tissue-type that are ordered according to a numeric property (e.g., age).
Construction of such datasets is non-trivial and requires further processing of the results provided by the MetaSRA website. For example, finding case and control samples for a given disease likely requires matching case samples to control samples according to their tissue or cell type. Furthermore, given these search results, users may wish to further filter samples according to whether they are poorly annotated (i.e., are missing cell type or tissue information), whether they are derived from a cell line, or whether they were experimentally treated. Moreover, given these results, the user may wish to explore other ontology terms associated with the search results within either the case or control samples to check for any variables that may confound downstream analyses. Finding longitudinal or time-series data presents similar challenges. To the best of our knowledge, no existing tool addresses these tasks.
To address these two tasks, we produced two Jupyter notebook-based tools. The first tool, called the Case-Control Finder, searches the SRA via the MetaSRA terms to produce matched-case and control samples for a given disease or condition where the cases and controls are matched by tissue and cell type. The second tool, called the Series Finder, finds ordered sets of samples for the purpose of answering biological questions pertaining to changes over a numerical property (e.g., time). More specifically, the Series Finder produces ordered sets of samples, where the order is determined based on a temporal property in the metadata such as age, as standardized by the MetaSRA’s real-valued properties. These tools promise to facilitate the construction of suitable public datasets for secondary analyses.
The tools presented in this work were written in Python (v3.6) and make use of Python packages pandas (McKinney, 2011), Matplotlib (Hunter, 2007), and seaborn (https://seaborn.pydata.org). These notebooks are available ready-to-run in a Docker container.
The Case-Control Finder implements the following steps to produce a dataset of matched-case control samples for a given disease (Figure 1A):
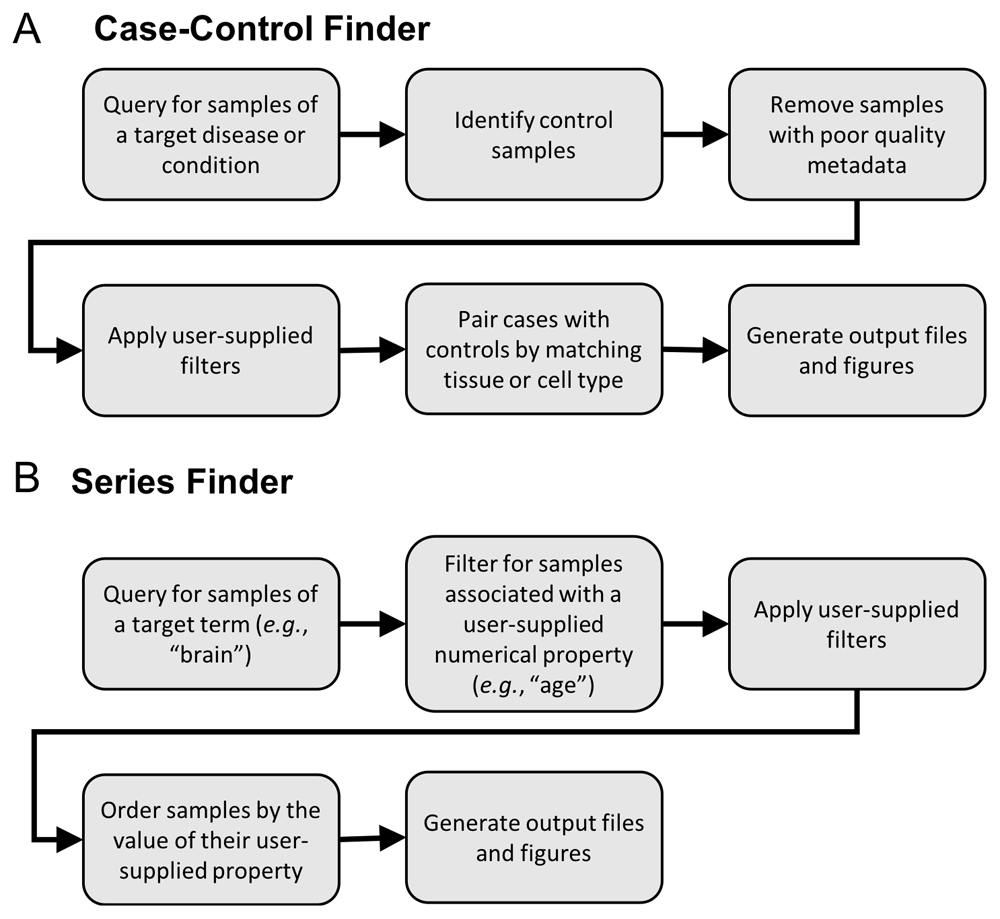
An overview of the backend processing functions called from the Jupyter notebooks.
1. Generate candidate case and control samples. Generate the set of candidate case samples by querying for all samples associated with a user-specified condition or disease using the MetaSRA-mapped ontology terms. Also, find all candidate control samples that are not associated with the target condition/disease.
2. Filter poorly annotated samples. Filter samples based on a metadata completeness threshold, which requires that all samples be associated with either a tissue term or a cell type term. The tissue/cell type information is required for downstream matching of case samples to control samples.
3. Apply user-specified filters. Further filter samples according to user-specified filtering parameters. The user can filter out cell line samples, treated samples, and in vitro differentiated samples. The user can also remove all diseased samples from the candidate control samples for the purpose of generating a healthy control-set.
4. Match by tissue and cell type. The candidate case samples are then matched with the candidate control samples by their tissue and cell type terms. Specifically, given that each sample can be associated with multiple ontology terms in the MetaSRA, a set of case samples is matched with a set of control samples when both sets of samples are labelled with the same set of tissue and cell type terms. For example, a set of case samples annotated with the set of terms “liver” and “epithelial cell” will be matched only to control samples also labeled strictly with these terms (Figure 2A). This ensures that case samples are matched with maximally similar control samples and mitigates matching samples from different tissue-types. For example, a set of case samples labelled with both the terms “liver” and “epithelial cell” will not be matched with a set of samples labelled only as “epithelial cell,” as there is no guarantee that the latter set of samples originate in the liver.
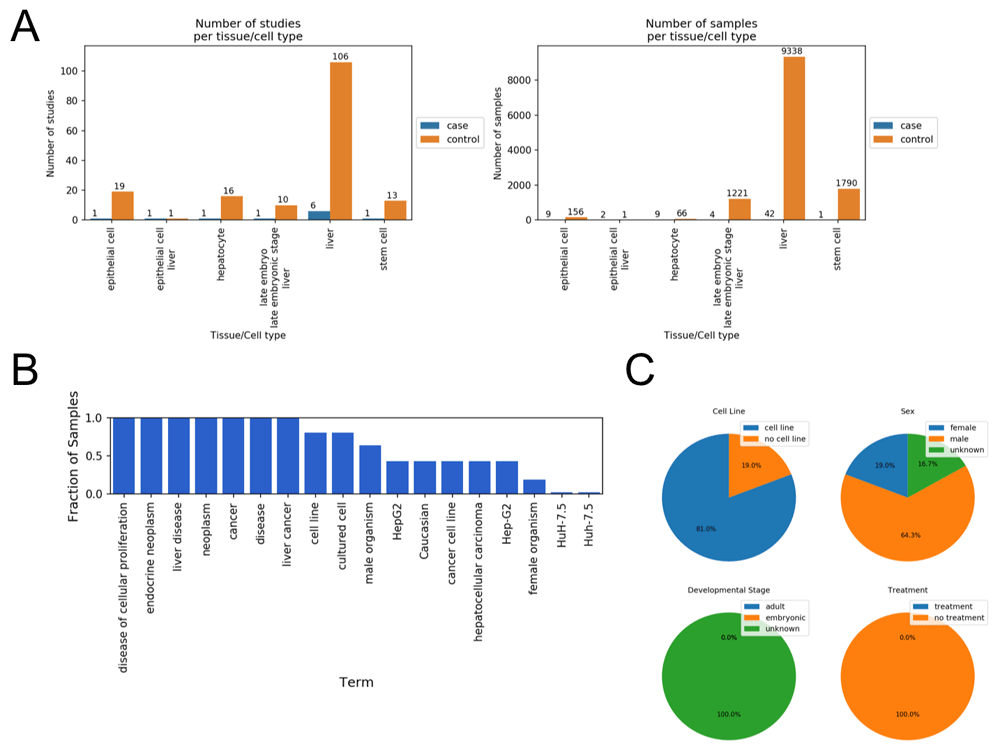
Results from running the Case-Control Finder for the query “liver cancer.” (A) The Case-Control Finder displays the number of case/control studies (left) and case/control samples (right) matched by each tissue and cell type. (B) The user can select either the case samples or control samples for a given tissue or cell type and display the most common ontology terms associated with those selected samples. Displayed here are the most common terms associated with the case samples labeled as “liver.” (C) The notebook also displays four pie charts for viewing the fraction of samples belonging to a cell line (top left), each sex (top right), each developmental stage (bottom left), and whether they were given an experimental treatment (bottom right).
Once the dataset is constructed, the notebook enables the user to explore the samples for other MetaSRA mapped ontology terms within the data (Figure 2B and C). By presenting other common ontology terms in the data, the user may be able to identify variables that either confound analysis.
The Series Finder finds RNA-seq data samples that are associated with a numerical property (e.g., age or time point) for a given tissue or cell type. To do so, the Series Finder utilizes the real-value property annotations provided by the MetaSRA where each real-value property in the MetaSRA is structured as a tuple consisting of a property name (e.g., age), numerical value, and unit (e.g., year).
To perform a query, the user provides an ontology term, such as a tissue or cell type, as well as a property name and unit. The Series Finder then finds all samples that are associated with the target ontology term and real-value property. The user can also provide a set of blacklist terms that can be used to filter the samples. Given a list of blacklist terms, the Series Finder will remove all samples annotated with any blacklist term. The Series Finder will then return all remaining samples ordered by their associated numerical values (Figure 1B).
We used the Case-Control Finder to query for samples of liver cancer RNA-seq samples matched with healthy control samples. This query resulted in six sets of samples representing different tissues or cell types including epithelial cells, hepatocytes, stem cells, and liver tissue (Figure 2A). The Case-Control Finder identified common terms associated with the case “liver cancer” samples (Figure 2B), and categorized these samples by cell line status, sex, developmental stage, and treatment status (Figure 2C).
We used the Series Finder to find all brain samples in the SRA ordered by the age of the sample donor. This query resulted in samples spanning many ages (Figure 3A). This dataset could prove useful for exploring gene expression-based signatures of aging. The Series Finder also identified common terms at each age (Figure 3B) and for each age’s sample-set, categorized those samples by cell line status, sex, developmental stage, and treatment status (Figure 3C).
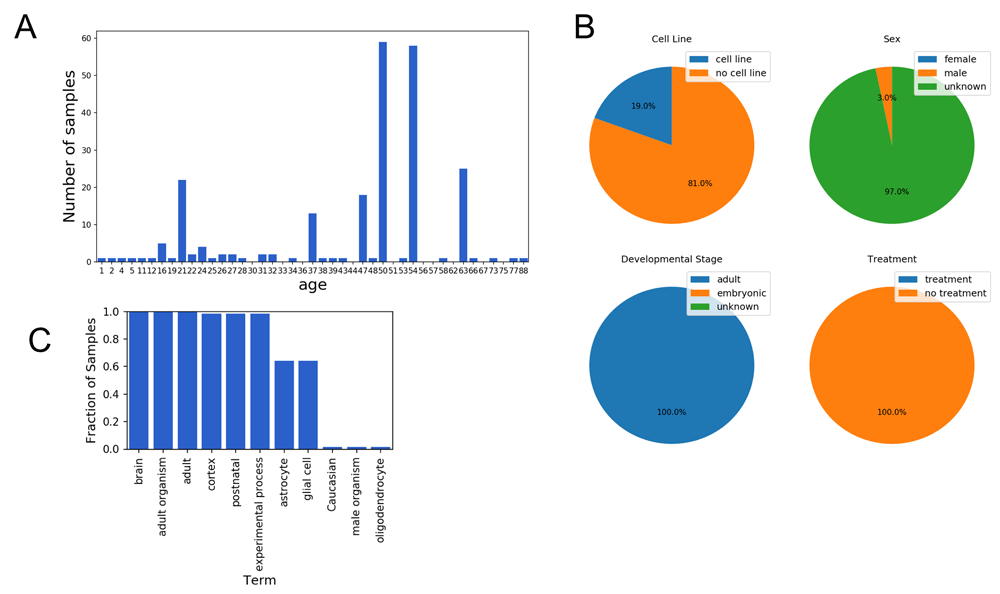
Results from running the Series Finder for the query “brain” sorted by “age,” where unit is specified as “year.” (A) The Series Finder displays the number of samples sorted by age. (B) The user can select samples associated with a given time point for further exploration. Here the samples annotated as “year = 63” are selected. The notebook then displays four pie charts for viewing the fraction of samples belonging to a cell line (top left), each sex (top right), each developmental stage (bottom left), and whether they were given an experimental treatment (bottom right). (C) Given the selected samples from (B), the notebook displays the most frequent terms associated with those selected samples. Displayed here are the most frequent terms associated with the case samples labeled as “liver.”
We implemented two Jupyter notebooks for performing hypothesis-driven queries of public RNA-seq samples in the SRA. These tools are built upon the standardized metadata provided by the MetaSRA project and enable querying of the metadata beyond what is natively possible via the MetaSRA website interface. Future work will entail either integrating these tools into a standard web-interface, such as the interface of the MetaSRA website, or by implementing a stand-alone web application for these tools using a platform such as R Shiny.
The figures and datasets produced in the analyses can be found on GitHub: https://github.com/mbernste/hypothesis-driven-SRA-queries/tree/master/results
All code is maintained on GitHub: https://github.com/mbernste/hypothesis-driven-SRA-queries
Archived code as at time of publication: https://doi.org/10.5281/zenodo.3807512 (Bernstein, 2020)
License: CC0
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)