Keywords
Linear Model, Experimental Design, Design Matrix, Shiny, R, Interactivity
This article is included in the Bioinformatics gateway.
This article is included in the RPackage gateway.
This article is included in the Bioconductor gateway.
Linear Model, Experimental Design, Design Matrix, Shiny, R, Interactivity
Linear and generalized linear models are ubiquitous tools in a wide variety of scientific disciplines, and encompass well-known special cases such as linear and logistic regression, ANOVA and Student’s t-test. Of particular interest to us, they are also the basis for many of the most widely used tools for analysis of high-throughput biological data. This includes limma1,2 for linear modeling of gene expression microarray and similar data, as well as edgeR3,4 and DESeq25 for differential expression analysis of RNA-seq and other count data, missMethyl6, DMRcate7 and minfi8 for differential methylation analysis, DiffBind9 for differential binding analysis, msmsTests10 for mass spectrometry, and many others. Since the linear model is a special case of the generalized linear model, and particularly as the aspects of defining the design matrix are shared between the two, we will generally refer to generalized linear models in the rest of this manuscript.
Fitting a generalized linear model requires observations of a response variable y (e.g., inferred abundance levels of a gene) as well as a set of continuous or categorical predictor variables or sample annotations (e.g. the sample genotype, age, or treatment condition). In addition, in the R statistical programming environment, the user provides a design formula, specifying which, and how, provided predictor variables should be used to model the expected value of the response. The design formula in R is a version of a syntax for model specification originally proposed in 1973 by Wilkinson and Rogers11. This design formula and a specification of a type of contrast coding define a numeric N × J design matrix X, where N is the number of observations and J the number of model coefficients. The expected response values are then modeled by
where β = (β1, . . . , βJ) are the regression coefficients for the respective columns of the design matrix, and g is a link function12,13. X β is typically referred to as the linear predictor. After fitting the model, statistical tests can be performed to test the null hypothesis that a given combination of coefficients (referred to as a linear contrast) is zero. In this manuscript, we will focus on reference cell coding, or “treatment” coding for contrasts, though in general other schemes may also be considered. For more details on how R’s design formula functionality is implemented, we refer to the reference for statistical modeling in S14.
The way that the model is specified, that is, the definition of the design matrix, naturally determines how the model coefficients should be interpreted. As an example, consider a situation with a linear model and a single categorical predictor with two levels. Defining a model including an intercept (a column of the design matrix with the value 1 for all observations) implies that the second regression coefficient represents the difference between the average response values for the two levels of the predictor, while without the intercept, the two regression coefficients directly represent the average response values for the two factor levels. Given the versatility of generalized linear models, determining the proper contrast to use for testing a specific biological hypothesis of interest requires an understanding of the interpretation of the individual regression coefficients, and can be challenging for users of generalized linear model-based tools.
Here, we present ExploreModelMatrix15, an R package for interactive exploration of generalized linear model designs, coefficients, and contrasts. Given a table of predictor variables, the user can specify the desired design formula and explore the value of the linear predictor for each combination of predictor values, expressed in terms of the model coefficients. From this type of visualization, it is often straightforward to determine the contrast corresponding to a given comparison of interest. We envision that ExploreModelMatrix can be useful for both research and teaching purposes. Specifically for the latter, the application contains several built-in example data sets, corresponding to some of the most commonly used experimental design setups. The underlying function in ExploreModelMatrix that processes the input data and generates visualizations can also be directly called by the user, enabling the generation of static plots for inclusion in reports and educational material.
ExploreModelMatrix15 is implemented as an R package16, using the Shiny framework17. The package is available via Bioconductor18, with the current development version accessible via GitHub. The package has been tested with R version 3.6 and later.
An instance of the interactive application is launched by calling the ExploreModelMatrix() function. This function accepts two optional arguments; a data.frame with one row per observation and each column corresponding to a measured predictor variable (below referred to as the sample information table), and a design formula. If the ExploreModelMatrix() function is called without any arguments, the user can either explore one of the built-in designs, or load a sample information table from a tab-separated text file. The design formula can always be specified or modified interactively in the application. If the user wishes to generate the visualizations independently of the interactive interface, this can be achieved via the VisualizeDesign() function, which is also called internally by ExploreModelMatrix().
The user interface of ExploreModelMatrix consists of a side bar with control widgets and a main window containing a set of fixed, but collapsible, panels, each illustrating a different aspect of the design matrix or the associated standard linear model (Figure 1). A more detailed explanation of each panel is accessible via the guided tour of the interface, implemented via the rintrojs package19 and accessible by clicking on the question mark icon in the top right corner (represented by the letter P in Figure 1).
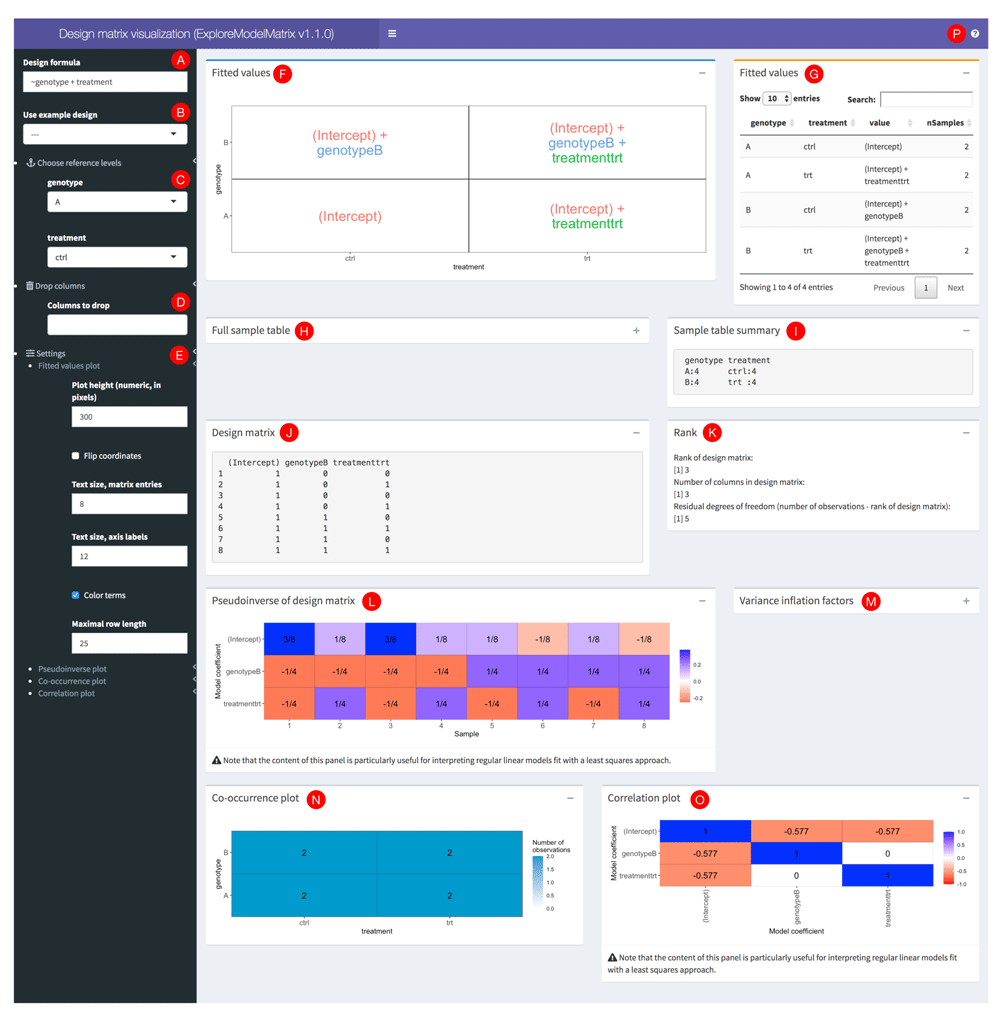
This example shows a model with two predictors (genotype and treatment), each with two levels, and with the assumption that their effects are additive. Red circles with letters were added to be able to refer to specific parts of the interface in the text.
Given a sample information table and a design formula, either provided by the user or obtained via one of the built-in designs, ExploreModelMatrix will first check that the two objects are compatible, i.e., that the terms in the design formula use only variables that are present in the sample information table, and that the design formula is supported by the package. If no problems are detected, ExploreModelMatrix will create a design matrix using the model.matrix() R function. The full sample table, a summary of its columns, and the resulting design matrix are all displayed in the application interface for convenience (see H-J in Figure 1). In addition, the rank of the design matrix is calculated (K). If the design matrix is not full rank, ExploreModelMatrix will display a warning, together with an indication of the coefficients that are not estimable (using the nonEstimable() function from the limma R package1,2). In addition, ExploreModelMatrix will inform the user if the number of rows (observations) in the design matrix is the same as its rank, in which case there are no residual degrees of freedom, and the variance or dispersion cannot be estimated.
Expressed in terms of the model coefficients, the panels in the first row of the application (F-G) illustrate, in graphical and tabular form, the value of the linear predictor in a generalized linear model, for each combination of levels for the predictors used in the design formula. This provides an intuitive understanding of the interpretation of each of the model coefficients, and can be helpful for specifying appropriate contrasts.
The panels in the lower part of the interface (L, M, O) should largely be interpreted in the context of standard linear models, where coefficient estimates are obtained using least squares fitting. The pseudoinverse (XT X)−1 XT20–22 represents the way each observed response value would contribute to the coefficient estimates. More precisely, in such a linear model represented by
the estimated regression coefficients are given by
ExploreModelMatrix also estimates variance inflation factors and correlations among the coefficient estimates. Finally, the co-occurrence plot in the bottom left panel (N) shows the number of observations in the data set for each combination of levels of the predictor variables.
The controls in the left-hand sidebar can be used to interactively modify the studied design as well as the display parameters of the panels. The text box in the top (A) allows the user to type in a design formula (starting with the ~, or “tilde” character), and the displayed figures will be updated accordingly. The dropdown menu immediately below (B) contains the built-in example designs. To use the sample information table provided either as an argument to ExploreModelMatrix() or uploaded into the app at run time, select -- here. The next section of controls (C) lets the user control which level should be considered the “baseline” or reference level for each categorical or factor variable in the model. ExploreModelMatrix will convert each character variable to a factor when a sample information table is loaded; by default the baseline level will be the first in alphabetical order.
In cases where the design matrix is not of full rank, it may be desirable to exclude a subset of the columns in the design matrix (for example, columns with all zero values or columns that are linear combinations of other columns). This can be done in the "Drop columns" section (D). As mentioned above, in the case of a non-full rank design matrix, ExploreModelMatrix will indicate which coefficients are not estimable and thus candidates for being dropped. The final group of controls (E) provide the ability to change the way the panels are displayed, e.g. by setting the height of the plot panels and changing the size and display mode of the text.
To illustrate how ExploreModelMatrix15 can be used to interpret the coefficients in a complex experimental design, we consider the example of differential allele-specific expression analysis with RNA-seq data. Generalized linear models for count data often use the log link function, and we assume this to be the case in some of the interpretations below. This type of experiment contains different groups of subjects (e.g., from different experimental conditions), where each subject contributes two columns in the read count matrix: one representing the read counts for the reference allele, and one representing those for the alternative allele, for each considered gene. Typical scientific questions of interest are whether there are differences between the expression of the two alleles within each condition, and whether there are differences in the allele-specific expression patterns between the conditions. Similar setups can be observed, for example, in differential methylation experiments (where the two columns for each sample would correspond to methylated and unmethylated read counts for a feature), or in situations where individuals from different groups are each given the same set of treatments.
The sample annotation table considered here is provided in Table 1. In addition to the columns containing the subject identifier, the condition and the count type (reference or alternative allele), we include a column corresponding to a within-condition relabeling, or dummy encoding, of the subject identifier. Note that this dummy subject identifier has only three levels, compared to six for the original subject identifier. This design setup is available among the example designs provided within ExploreModelMatrix, denoted “Two crossed, one nested factor (manuscript example)”. We will illustrate two equivalent ways of setting up the design formula, and show how ExploreModelMatrix can help in the interpretation of the model coefficients.
First, we specify the design formula
including an overall condition effect, a term to account for sample-specific effects, and an interaction between the condition and count type columns to capture allele-specific expression within each condition. In R’s design formula syntax, a “:” between two variable names indicates the addition of an interaction term between these two variables, which may have a different effect on columns of X depending on whether these are numeric or factor variables, and what other terms are in the design. Given this design formula together with the sample annotation table from Table 1 as the input arguments, the ExploreModelMatrix functions determine the composition of the linear predictor for each combination of predictor variables shown in Figure 2A (corresponds to panel (F) in Figure 1, shown here separately for increased readability). The Rank panel in the application further indicates that the design matrix is of full rank and that the residual degrees of freedom is non-zero, allowing also estimation of variances or dispersions for use in statistical hypothesis tests involving the estimated coefficients. The illustration in Figure 2A can be used to extract appropriate contrasts for statistical testing. For example, comparing the values of the linear predictor for each sample in the control group, we can see that the conditioncontrol:countalt coefficient represents the allele-specific expression effect (alt/ref expression log-ratio) in this group. Similarly, the conditiontreated:countalt coefficient represents the allele-specific expression in the treated group. As a consequence, the condition-dependent allele-specific expression effect is obtained as the difference between the allele-specific effects within the respective conditions, that is, by conditiontreated:countalt - conditioncontrol:countalt.
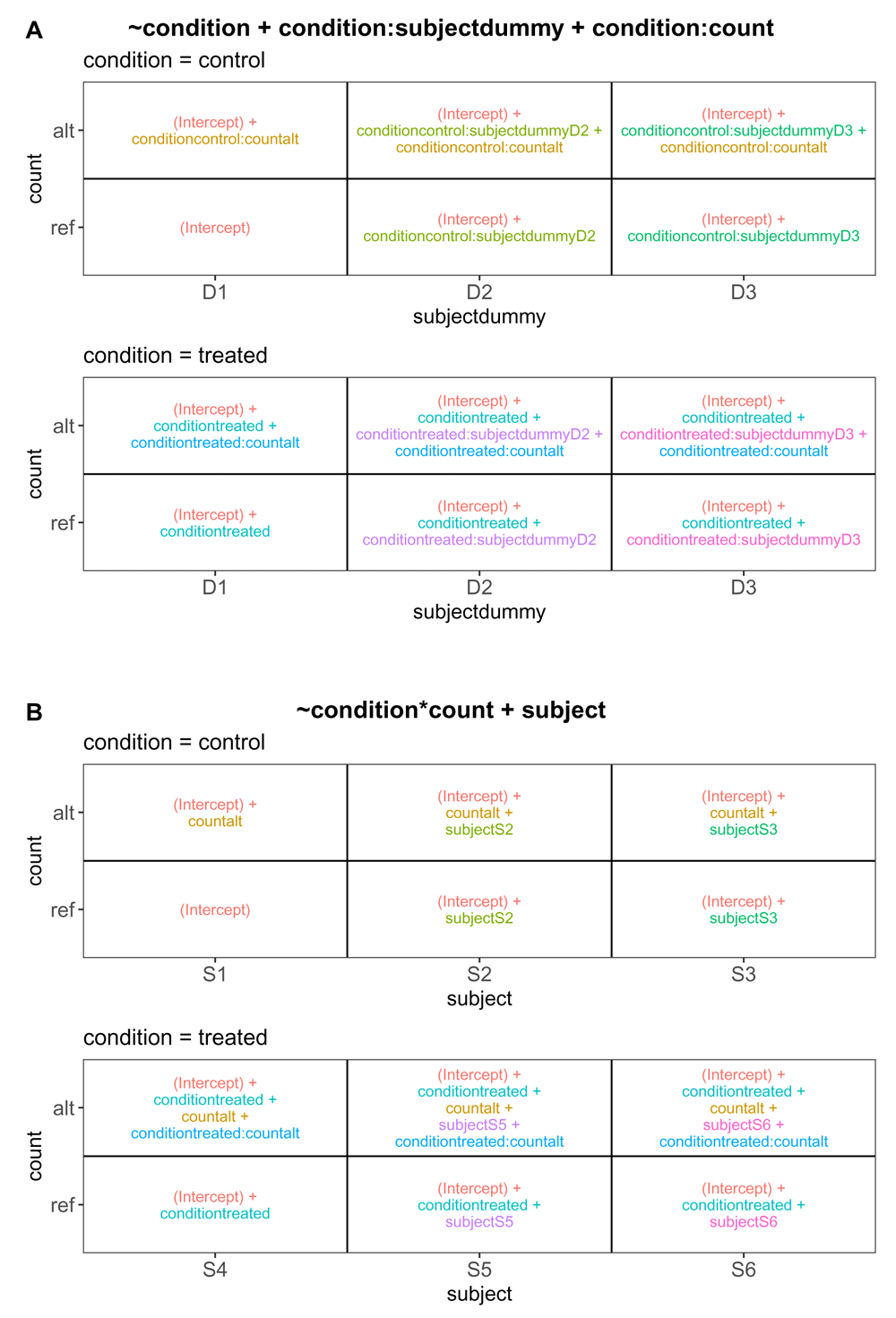
A. Using the design formula ~ condition + condition:subjectdummy + condition:count. B. Using the design formula ~ condition*count + subject.
Next, we illustrate an alternative way of setting up the design matrix, by specifying the design formula as
Here, we use the original subject ID (not the dummy encoded), and include main effects for condition and count type as well as an interaction between the condition and the count type. In R’s design formula syntax, a “*” between two variable names indicates the addition of both main effects and an interaction term between these two variables. Upon changing the design formula in ExploreModelMatrix, we are notified that the design matrix is no longer full rank, as a consequence of having different subjects in the different conditions. Dropping the subjectS4 column results in a full-rank design matrix, and the composition of the linear predictor is shown in Figure 2B. The rank of the design matrix, as well as the residual degrees of freedom, are the same as with the previous formulation. However, the composition of the linear predictor for each combination of input variables is different. Comparing the alternative and reference allele groups for the control condition shows that with this formulation, the allele specificity in the control group is encoded by the countalt coefficient. Similarly, the allele specificity in the treated group is represented by the sum of the countalt and conditiontreated:countalt coefficients. Consequently, the difference in allele specificity between the treated and control group is now directly encoded in the conditiontreated:countalt coefficient.
This example stresses that knowing how to interpret a given coefficient in a generalized linear model is critical, that identically labelled coefficients can have different meanings depending on the chosen design formula, and that ExploreModelMatrix can help the user interpret the resulting coefficients for a given choice of design formula and set up an appropriate contrast.
We have described the ExploreModelMatrix R/Bioconductor package15, which enables interactive exploration for increased understanding of model coefficients in linear and generalized linear models. To the best of our knowledge, this is the first package of its kind, and we envision applications for both research and educational purposes. The application requires minimal input and can be launched from a local R session, as well as be deployed on a Shiny server. An example instance of the latter is available at http://shiny.imbei.uni-mainz.de:3838/ExploreModelMatrix/, and the process for deploying an instance of the application on a Shiny server is documented in one of the vignettes accompanying the software.
All data underlying the results are available as part of the article and no additional source data are required.
ExploreModelMatrix is available at: http://www.bioconductor.org/packages/ExploreModelMatrix/
Source code available at: https://github.com/csoneson/ExploreModelMatrix.
Source code at time of publication: https://doi.org/10.5281/zenodo.383740215.
License: MIT License.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)