Keywords
COVID-19, Epidemic outbreak, Probability forecast, Public health, Mathematical biology
This article is included in the Emerging Diseases and Outbreaks gateway.
This article is included in the Bioinformatics gateway.
COVID-19, Epidemic outbreak, Probability forecast, Public health, Mathematical biology
The authors have addressed language and formatting concerns. Equations have been improved, references extended.
See the authors' detailed response to the review by Adnan Khan
Statistical aspects of coronavirus disease 2019 (COVID-19) and other similar recent epidemics were receiving much attention in the modern research community.1–11 Generally, it is quite challenging to calculate realistic biological system reliability factors and outbreak probabilities under actual epidemic conditions by using conventional theoretical statistical methods.12–19 The latter is usually due to the fact that dynamic biological and environmental systems possess high number of degrees of freedom (in other words dimensional components), as well as system dependency on location – making bio-system of interest spatio-temporal. In principle, the reliability of a complex biological system may be accurately estimated straightforwardly by having enough measurements or by direct Monte Carlo simulations.20–23 For COVID-19, however, the only available observation numbers are limited as the observations are only available from the beginning of the year 2020 up to now.20 Motivated by the latter argument, the authors have introduced a novel reliability method for biological and health systems to predict and manage epidemic outbreaks more accurately; this study was focused on COVID-19 epidemics in northern China, with focus on cross-correlations between different provinces within same climatic zone. For other studies related to statistical variations per country see Ref. 24, 25, where spatial lags were addressed.26–29
Statistical modelling of lifetime data or extreme value theory (EVT) is widespread in medicine and engineering.32–40 For example, in Ref. 13, authors employed EVT theory to determine the fitness effect using a Beta-Burr distribution. While in Ref. 14, the author discusses using a bivariate logistic regression model, which was then used to access multiple sclerosis patients with walking disabilities and in a cognitive experiment for visual recognition. Finally, is a paper of relevance, which used EVT to estimate the probability of an influenza outbreak in China. The author demonstrated a forecasting prediction potential amid the epidemic in this paper. While in authors similarly used EVT to predict and detect anomalies of influenza epidemics.41–44 China was chosen to test the methodology proposed in this study, because of its COVID-19 origin and extensive health observations and related research available online.45–50
In this paper epidemic outbreak is viewed as unexpected incident that may occur at any province of a given country at any time, therefore spatial spread is accounted for. Moreover, a specific non-dimensional bio-system failure/hazard factor is introduced to unify various bio-system components having different failure/hazard limits.51–58
Biological systems are subjected to ergodic environmental influences. The other alternative is to view the process as being dependent on specific environmental parameters whose variation in time may be modelled as an ergodic process on its own.59–65 The incidence data of COVID-19 in all provinces of the People's Republic of China (PRC) from February 2020 until end of 2022 was retrieved from the official public PRC health website, for simplicity only northern provinces were selected for this study. As this dataset is organized by province (more than 30 provinces in China), the biological system under consideration can be regarded as a multi-degree of freedom (MDOF) dynamic system with highly inter-correlated regional components/dimensions. Some recent studies have already used statistical tools to predict COVID-19 development, for linear log model see Ref. 25, these studies however did not address fully dynamic space-time dynamic bio-system as this study does.66–72
Note that while this study aims at reducing risk of future epidemic outbreaks by predicting them, it is solely focused on daily registered patient numbers and not on symptoms themselves. For long-lasting COVID-19 symptoms, the so-called “long COVID”, and its risk factors and whether it is possible to predict a protracted course early in the disease, see Ref. 18, for mortality research see Ref. 1.
This section presents theoretical details of novel Gaidai bio-reliability method. For numerical part authors used commercial software MATLAB, (Mathworks, V 8.6), namely its optimization routines, otherwise authors have used extrapolation code available from modified Weibull. Only the code available from modified Weibull was used to complete all sections of the methods – both numerical part as well as final extrapolation.
Novel Gaidai bio-reliability method introduces MDOF (multi-degree of freedom) health bio-system vector process that was measured over a sufficiently long (representative) period of time. Unidimensional bio-system components global maxima over the entire time span denoted as , , .
Let be time local maxima of the process consequent in time, recorded at discrete time instants that are monotonously increasing in. A similar definition follows for other MDOF bio-system components with and so on. For simplicity, all bio-system components, and therefore its maxima are assumed to be non-negative.
The target is to estimate system failure probability, in other words the probability of exceedance
More specifically, the moment when either exceeds , or exceeds , or exceeds , and so on, the system is regarded as immediately failed. Fixed failure levels , , ,… are, of course, individual for each system one-dimensional component. , , , and so on.
Now, bio-system components local maxima time instants are sorted in monotonously non-decreasing order into one single merged time vector . Note that , . In this case represents local maxima of one of MDOF structural response components either or , or and so on. That means that having bio-system time record, one just needs continuously and simultaneously screen for unidimensional response component local maxima and record its exceedance of MDOF limit vector in any of its components In order to unify all three measured time series the following scaling was performed as follows
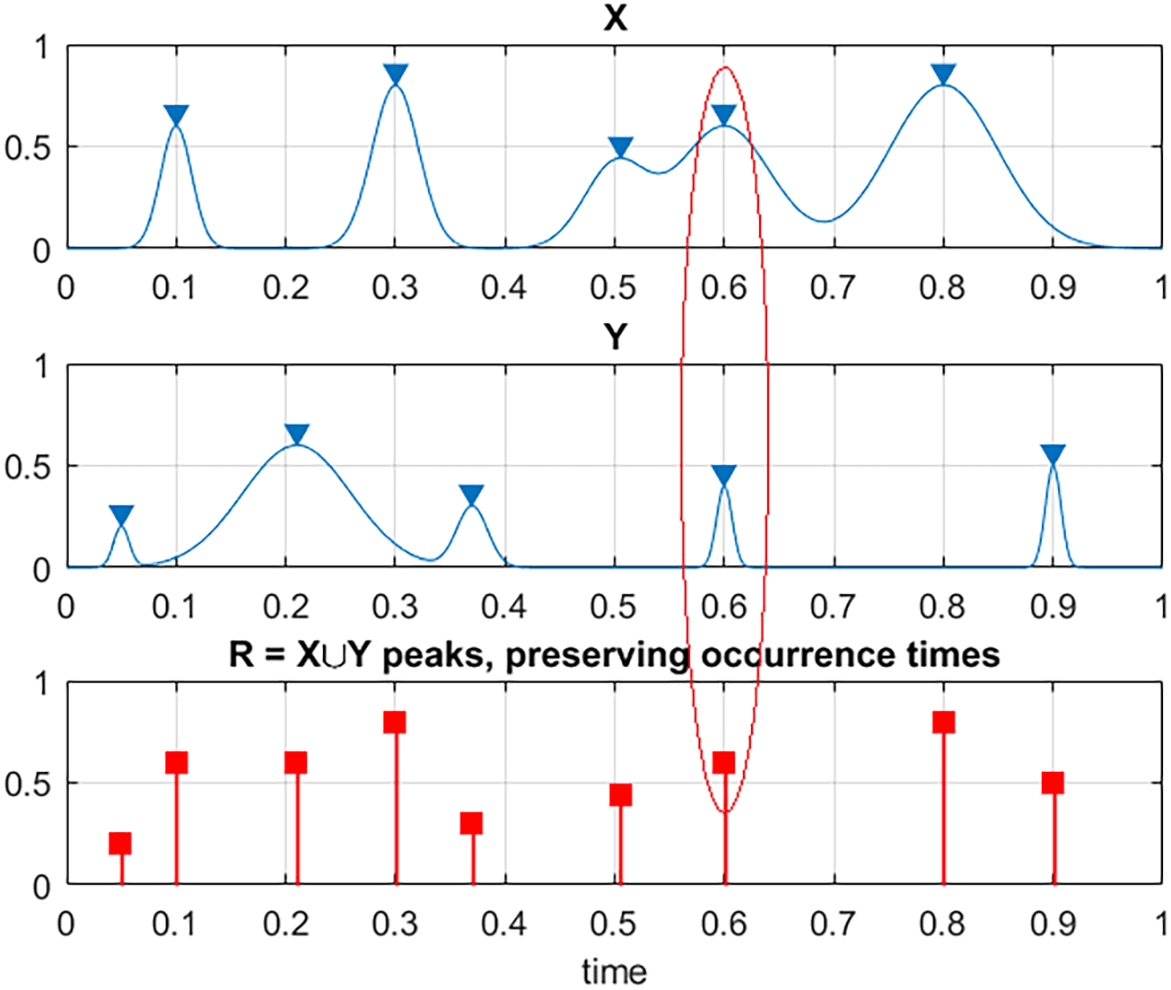
Red ellipse highlights case of simultaneous maxima for different components.
Now, the scaling parameter is introduced to, artificially, simultaneously decrease limit values for all bio-system components, namely the new MDOF limit vector with , , , … is introduced, see Ref. 28. The unified limit vector is introduced with each component is either , or and so on. The latter automatically defines probability as a function of , note that from Equation (1). Non-exceedance probability can be introduced as follows
Next, cascade of approximations which is based on conditioning is briefly outlined. In practice,32–36 the dependence between the neighboring is not negligible; thus, the following one-step (will be called conditioning level ) memory approximation is introduced
where (will be called conditioning level ), and so on. The idea is to monitor each independent failure that happened locally first in time, thus avoiding cascading local inter-correlated exceedances.
Equation (5) exhibits subsequent refinements with respect to the statistical independence assumption. These approximations increasingly accurately approximate statistical dependence between neighboring maxima. Since the original MDOF process has been assumed ergodic and thus stationary, the probability for is independent of , however dependent on the conditioning level . Thus, non-exceedance probability may be approximated as in the average conditional exceedance rate method, see Ref. 28 for more details on exceedance probability
Note that Equation (5) follows from Equation (1) if neglecting, as design failure probability must be epsilon order o(1), with . Equation (5) is analogous to the well-known mean up-crossing rate equation for the stochastic process probability of exceedance.28 There is convergence with respect to , called here conditioning level
Note that Equation (6) for is equivalent to a well-known non-exceedance probability relationship with the mean up-crossing rate function
where denotes the mean up-crossing rate of the bio-system non-dimensional level for the above assembled non-dimensional vector assembled from scaled MDOF bio-system scaled components . The mean up-crossing rate is given by the Rice's formula, given in Equation (7) with being joint PDF for with being time derivative. Equation (7) relies on the Poisson assumption that is up-crossing events of high levels (in this paper, it is ) can be assumed to be independent. The latter may not be the case for narrowband bio-system components and higher-level dynamical systems that exhibit cascading failures in different dimensions, subsequent in time, caused by intrinsic inter-dependency between extreme events, manifesting itself in the appearance of highly correlated local maxima clusters within the assembled vector .
In the above, the stationarity assumption has been used. However, the proposed methodology can also treat the nonstationary case. For nonstationary case, the scattered diagram of seasonal epidemic conditions, each short-term seasonal state has the probability, so that. Next, let one introduce the long-term equation
with being the same function as in Equation (6) but corresponding to a specific short-term seasonal epidemic state with the number .
Note that the accuracy of the suggested approach for a large variety of one-dimensional dynamic systems was successfully verified by authors in previous years.28,29
Introduced by Equation (5) functions are regular in the tail, specifically for values of approaching and exceeding.17 More precisely, for , the distribution tail behaves similar to with being suitably fitted constants for suitable tail cut-on value. Therefore, one can write
Next, by plotting versus , often nearly perfectly linear tail behavior is observed. Optimal values of the parameters may also be determined applying sequential quadratic programming (SQP) methods, incorporated in NAG Numerical Library.30 Methods described above have been applied as described in methods section. Authors used MATLAB (Mathworks, V 8.6) (RRID:SCR_001622) commercial tool as a basis for their numerical purposes. For more specific author developed code routines, related to the extrapolation method by Equation (9), see modified Weibull. Note that modified Weibull is a repository, containing not only the code, but user manual, examples and references. In this study only extrapolation part of modified Weibull was used. In other words, current study presents novel theoretical methodology, but using modified Weibull software previously developed by some of the authors.31
Methods described in this paper are novel and state of art. Prediction of influenza type epidemics has long been the focus of attention in mathematical biology and epidemiology. It is known that public health dynamics is a seasonally and spatially varying dynamic system that is always challenging to analyse. This section illustrates the efficiency of the above-described methodology using the new method applied to the real-life COVID-19 data sets, presented as a new daily recorded infected patient time series, spread over different regions.
COVID-19 and influenza are contagious diseases with high transmissibility and ability to spread. Seasonal influenza epidemics caused by influenza A and B viruses typically occur annually during winter, presenting a burden on worldwide public health, resulting in around 3–5 million cases of severe illness and 250,000–500,000 deaths worldwide each year, according to the World Health Organization (WHO).20
This section presents a real-life application of the above-described method. The statistical data in the present section are taken from the official website of the National Health Commission of the people's Republic of China. The website provides the number of newly diagnosed cases every day in 13 administrative regions in northern China from 22 January 2020 to the end of 2022. Patient numbers from thirteen different Chinese administrative regions were chosen as components thus constituting an example of a thirteen dimensional (13D) dynamic biological system, according to Equation (2).39–41
Failure limits , or in other words, epidemic thresholds, are not set values and must be decided. The simplest choice would be for different countries to set failure limits equal to the percentage per corresponding country population, making equal to percentage of daily infected per country. In this study, however, twice maxima of daily infected per country have been chosen as failure limits. Note that failure limits may be chosen differently for different dynamic bio-systems. Although the latter choice obviously introduces bias (accumulation point) at if the number of countrys is large, in this study the number of regions is not that large (below 20 national regions) and proper extrapolation technique may easily circumvent the above-mentioned accumulation point bias.
Next, all local maxima from three measured time series were merged into one single time series by keeping them in time non-decreasing order: with the whole vector being sorted according to non-decreasing times of occurrence of these local maxima.
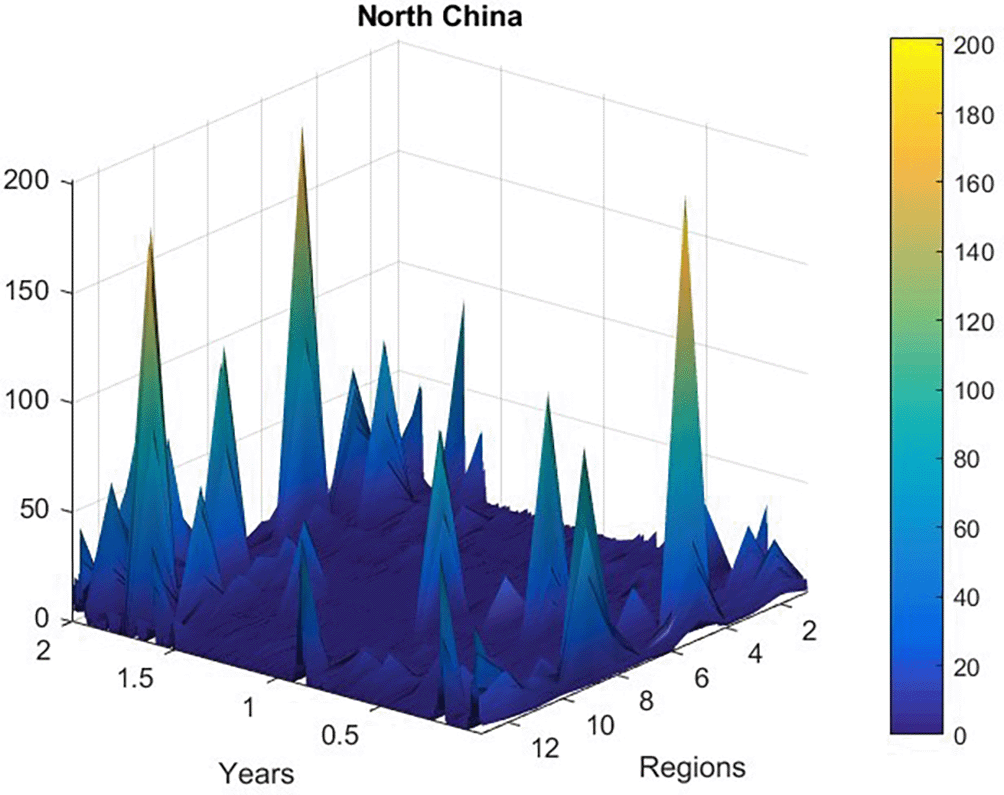
Figure 2 presents new daily recorded patients number plotted as a time-space 2D surface using MATLAB. Figure 3 presents the number of new daily recorded patients as a 13D vector , consisting of assembled regional new daily patient numbers. Note that vector does not have physical meaning on its own, as it is assembled of different regional components with different epidemic backgrounds. Index is just a running index of local maxima encountered in a non-decreasing time sequence.
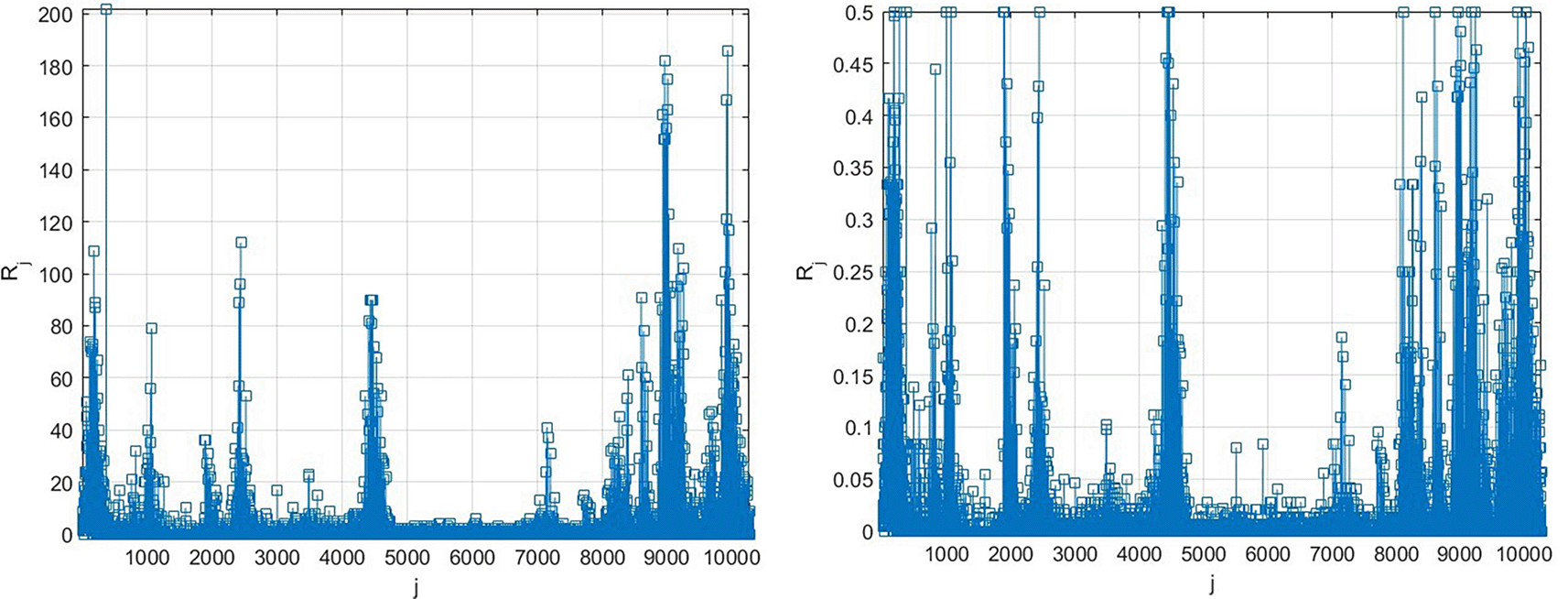
Left: as it is, Right: scaled by Equation (10).
Figure 4 presents 100 years return level extrapolation according to Equation (9) towards epidemic outbreak with 100-year return period, indicated by the horizontal dotted line, and somewhat beyond, cut-on value was used. Dotted lines indicate extrapolated 95% confidence interval according to Equation (10). According to Equation (5) is directly related to the target failure probability from Equation (1). Therefore, in agreement with Equation (5), system failure probability can be estimated. Note that in Equation (5), corresponds to the total number of local maxima in the unified bio-system vector. Conditioning parameter was found to be sufficient due to occurrence of convergence with respect to , see Equation (6). Figure 4 exhibits reasonably narrow 95% CI. The latter is an advantage of the proposed method.
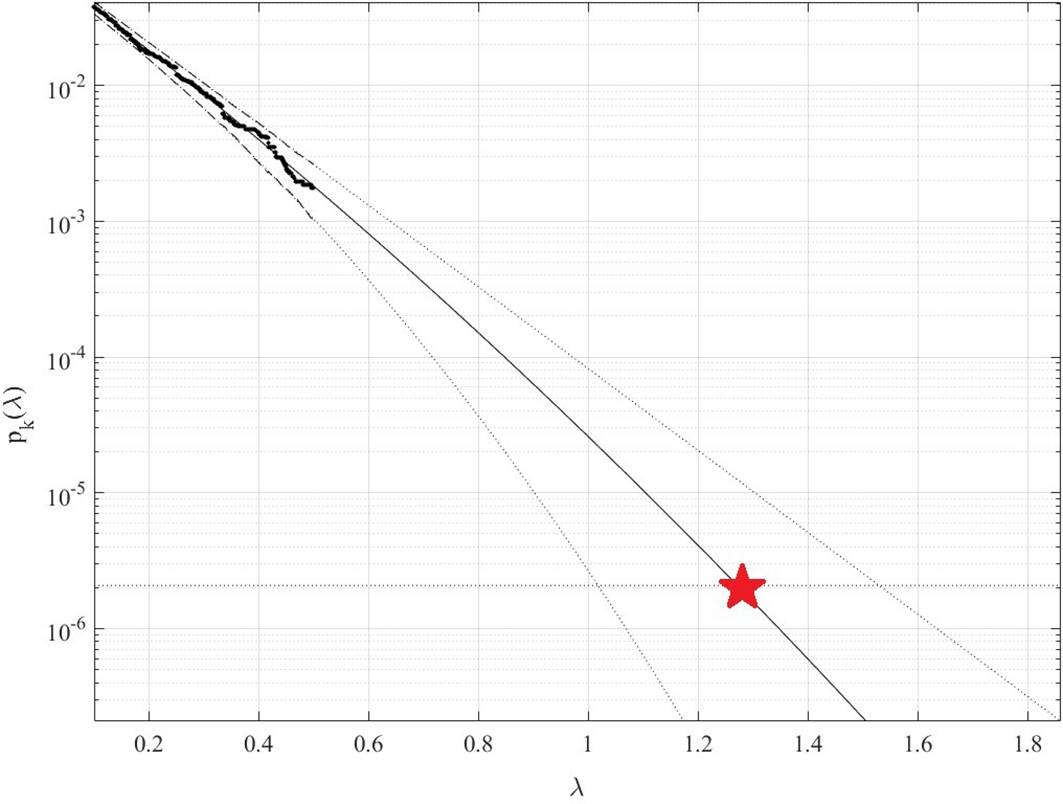
Extrapolated 95% CI indicated by dotted lines, using modified Weibull extrapolation technique.
Note that while being novel, the above-described methodology has a clear advantage of utilizing available measured data set quite efficiently due to its ability to treat health system multi-dimensionality and perform accurate extrapolation based on quite limited data set. Note that, predicted non-dimensional level, indicated by star in Figure 4, represents probability of epidemic outbreak at any northern province in China in the years to come.
Traditional health bio-systems reliability methods dealing with observed/measured time series do not have the ability to efficiently deal with high dimensionality and cross-correlation between different bio-system components. The main advantage of the introduced methodology is its ability to study high dimensional non-linear dynamic systems reliability.
Despite the simplicity, the present study successfully offers a novel multidimensional modelling strategy and a methodological avenue to implement the forecasting of an epidemic during its course, if it is assumed to be stationary in time. Proper setting of epidemiological alarm limits (failure limits) per province has been discussed, see Section Use case.
This paper studied recorded COVID-19 patient numbers from thirteen different Chinese northern provinces, constituting an example of a thirteen dimensional (13D) and ten-dimensional (10D) dynamic biological system respectively observed in 2020-2022. The novel reliability method was applied to new daily patient numbers as a multidimensional system in real-time.
The main conclusion is that if the public health system under local environmental and epidemiologic conditions in northern China is well managed. Predicted 100-year return period risk level of epidemic outbreak is reasonably low. However, there is an ultra-low risk of a future epidemic outbreak in chosen country of interest, at least in 100 years horizon.
This study outlines a general-purpose, robust and straightforward multidimensional bio-system reliability method. The method introduced in this study has been previously successfully validated by application to a wide range of engineering models,11,12 but only for one and two-dimensional bio-system components and, in general, very accurate predictions were obtained. Both measured and simulated bio-system components time series can be analysed using the proposed method. It is shown that the method produced an acceptable 95% confidence interval, see Figure 4. Thus, the suggested methodology may be used as a tool in various non-linear dynamic biological systems reliability studies. The presented COVID-19 example does not limit potential areas of new method applicability by any means.
The datasets analyzed during the current study are publicly available from the daily recorded patient’s dataset in China during 2020-2022 years, are available at http://www.nhc.gov.cn/. Daily recorded patients data was structured per province and per calendar day, namely it was straightforward to extract and systematize joint statistical distribution as a function of both space and time.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
 ’, similarly equation 5 needs to be explained further.
’, similarly equation 5 needs to be explained further.
Comments on this article Comments (0)