Keywords
Gene-gene network, gene regulation, penalized regression, log penalty, partial correlation, R package, algorithm
This article is included in the Cell & Molecular Biology gateway.
This article is included in the Bioinformatics gateway.
This article is included in the RPackage gateway.
Gene-gene network, gene regulation, penalized regression, log penalty, partial correlation, R package, algorithm
The objective of this paper is to introduce a novel method that constructs gene-gene network (GGN) based on high dimensional gene expression data. Popular methods for GGN include neighborhood selection1, graphical Lasso2, and space (Sparse PArtial Correlation Estimation)3. Neighborhood selection consistently estimates the non-zero entries of the partial correlation matrix, and provide an approximation of the maximum likelihood estimate of partial correlation matrix. Graphical Lasso improves on neighborhood selection by providing a maximum likelihood estimate of the partial correlation matrix. The space method exploits the symmetry of partial correlation matrix to improve the estimation accuracy. It also avoids potential conflicts in neighborhood selection, that is, Yi is selected as a neighbor of Yj but Yj is not selected as a neighbor of Yi, and one has to make a post-hoc decision for whether Yi and Yj are connected. Furthermore, those available methods employ L1, L2 or elastic net penalty. However, penalties in the range of L0 to L1 is often needed to improve the accuracy of variable selection for high-dimensional gene expression data4. In this paper, we propose a new statistical method to estimate GGN by implementing the log penalty for the space approach, and we refer to our method as space-log.
Suppose that we have data on n independent individuals and m genes. Assume the expression of m genes, after appropriate normalization, follow a multivariate Gaussian distribution N(0, ∑).
The neighborhood selection (NS) approach considers each gene separately. Let Yi be the gene expression value for the ith gene and Y−i = (Y1, ..., Yi−1, Yi+1, Ym)T . For the NS approach, Yi is regressed on Yi by a penalized regression:
with penalty function We will compare NS-lasso with lasso penalty 5 and NS-log with log penalty 6,7. Source codes of NS-lasso and NS-log are available at https://github.com/Sun-lab/penalized_estimation/.
The joint modeling approach space3 is to estimate GGN, without the need to fit many (m) single gene regression models separately, but directly estimate partial correlation among all the genes. Denote the partial correlation between Yi and Yj by ρi,j. If we know the concentration matrix ∑−1 = (σij)m×m, then So we can easily get that Thus, the problem is translated into partial correlation matrix estimation. Specifically3, proposed to minimize a penalized loss function
where wi ≥ 0 is the weight, e.g., uniform weights wi = 1 for space-no, residual variance based weights wi = σjj for space-res, and degree based weights wi = number of genes that {j : ρi,j ≠ 0, j ≠ i} for space-df. In 3, p(|ρ|; λ) = λ|ρ| and we call it as space-lasso.
Inspired by 6 and 7, we extended the space approach with log penalty as space-log p(|ρ|; λ, τ) = λlog(|ρ| + τ) and used the active shooting algorithm3 to update the coefficient estimates iteratively in space-log (Extended data). We determined the tuning parameters by using extended BIC (extBIC)8.
Denote the target loss function as
The goal is to estimate = argminρf(ρ) for a given λ and τ. We implement the penalized estimation using space and Log penalties by Local Linear Approximation (LLA)9.
Where is the estimate of regression coefficient ρi,j at the k-th iteration. After applying LLA for the penalty part, we can minimize loss function at the (k + 1)-th step, while solving for ρi,j by
By letting we can find the solution for ρi,j as follows:
where and
In this section, we present Monte Carlo simulation to evaluate the performance of the space-log, space-lasso, NS-log, and NS-lasso. Following7, we studied two types of graphs: the traditional random graphs (ER model) where all the genes have the same expected number of neighbors10,11, and hubs graphs where a few genes may have a large number of neighbors (BA model), and BA model is more frequently observed in gene networks12.
We simulated GGN of m genes under both the BA and ER models, respectively. The initial graph had one gene and no edge. In the (k+1)th step, we added e edges between a new gene and e old genes. Under the BA model, there is a greater probability for the new gene to connect to an existing hub gene that has larger number of edges with the probability where number of edges connected with the ith gene at the tth step. For the ER model, each edge of any gene pair (Gi,Gj) was added randomly in the GGN with probability pE independent from all other edges. After constructing the bone of GGN, we simulated gene expression based on multivariate Gaussian. Without loss of generality, we simulated data sets with n = 400 individuals. As shown in Table 1, we considered different number of genes m = 100, 200, 300 with various sparsity level determined by pE = 1=m or 2=m for the ER model and e = 1 or e = 2 for the BA model.
We evaluated the performance of the methods by the following metrics: number of false positives (FP), false negatives (FN), FP+FN, F1 score, FDR, true positive rate (power). Note that there are three different weights used in joint modeling setting (space-log, space-lasso): (1) uniform weights; (2) residual variance based weights; and (3) degree freedom based weights. The corresponding methods are referred to as sp_no, sp_res, and sp_df with/without log respectively.
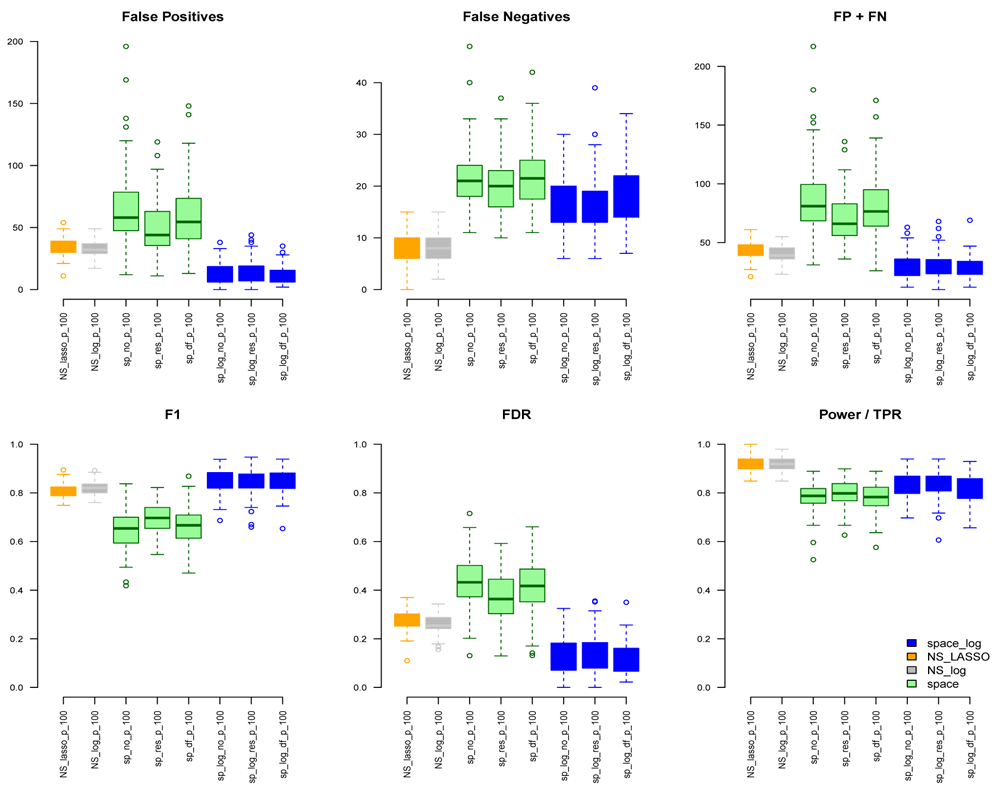
Under the BA model with m=100 and e=1 (Figure 1), we can see that space-log has smallest Errors (FP+FN), smallest FDR, and highest F1 score than other approaches, indicating that space-log controls overall false positive and false negative rates well. Under the ER model (Figure 2) with m=100 and e=1, space-log is slightly better than space, and NS-log shows lower Errors and higher F1 score than other approaches including space-log. Under both models, the log penalty has less false positives but slightly more false negatives compared to lasso penalty. We note that although log penalty performs well for both the ER and BA models, space-log is particularly powerful in identifying hub networks (such as BA models).
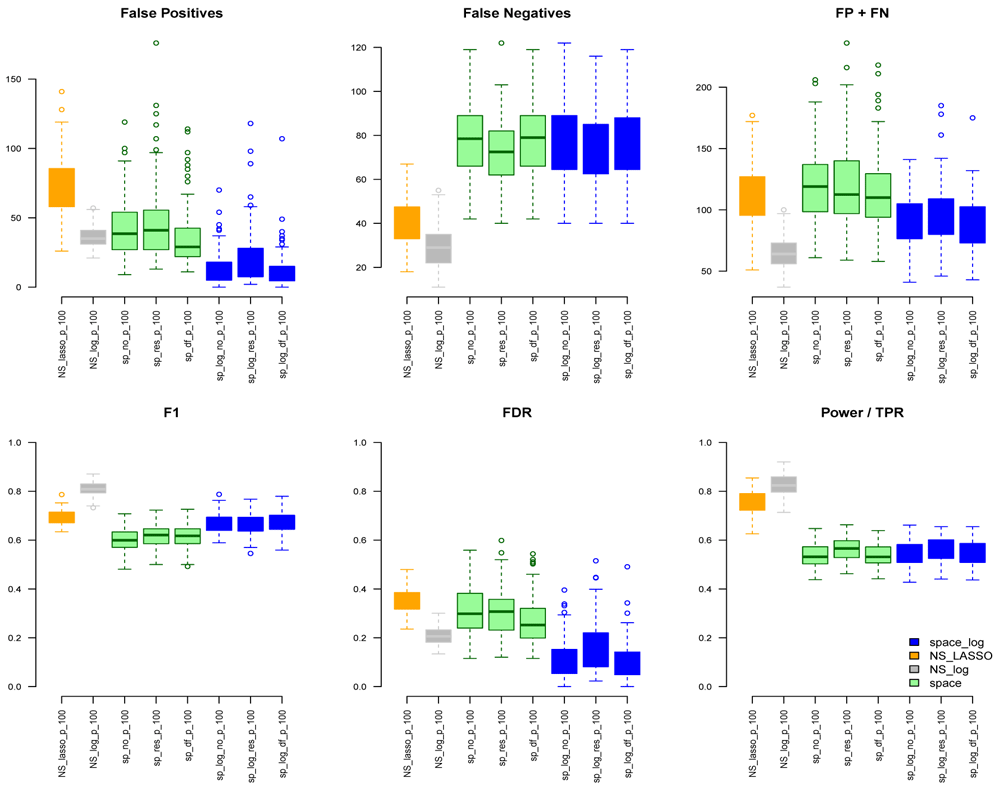
In the Extended data, Figures S3 and S4 show the results under the BA model for m=100,200,300 with low number of connections (e=1) and high number of connections (e=2), respectively. Figures S5 and S6 show the results under the ER model with low and high numbers of connections, respectively. Comparing with Figure 1, a similar pattern was noted with the increase of number of genes (m increases from 100, 200, to 300). In BA with low connections (Figure S3), space-log showed smallest FP+FN error and largest F1 score, which outperform all other methods. In BA with high connections (Figure S4), NS-log showed smallest FP+FN error and largest F1 score. For ER model with low and high connections, NS-log outperforms other methods in terms of FP+FN and F1 scores. It’s in line with our understanding that space-log is powerful at identifying hubs network, and NS-log is powerful at dealing with complex network with high number of gene-gene interactions and random networks.
We showed a simulated graph for the BA model with 400 subjects, 100 genes and each gene has only 1 connection (Figure 3). The GGN was estimated by 8 different approaches. In Figure 3, the true edges were indicated by black color, false positive (FP) edges by red color, and false negative (FN) edges by grey color. It’s clear that space-log identified far fewer false positive edges (red line) comparing with space-lasso and NS approaches, while clearly indicating the hub structures. We observed that the FP edges by two NS approaches were quite randomly identified, and the FP edges by two space approaches were mostly within a hub and not between hubs. In summary, the log penalty generally has better performance than the lasso penalty, and both space-log and NS-log control false positive and false negative rate well. For random networks, i.e., no hub, NS-log performs better than other methods. space-log performs best for hub-like gene networks (Figure 1 and Figure 3) with higher F1 score and less false positive edges. Identifying hub networks is generally considered of great interest in the GGN analysis, because a few of hubs connecting with a large proportion of genes, and those hub genes are thought to be master regulators and play a critical role in a biological system13.
| m | n | pE (ER) | e (BA) |
|---|---|---|---|
| 400 | 100 | 1/100, 2/100 | 1,2 |
| 400 | 200 | 1/200, 2/200 | 1,2 |
| 400 | 300 | 1/300, 2/300 | 1,2 |

A total of 400 subjects were generated. The GGN was estimated by 8 different approaches. Black is true edges, red is false positive edges, and grey is false negative edges.
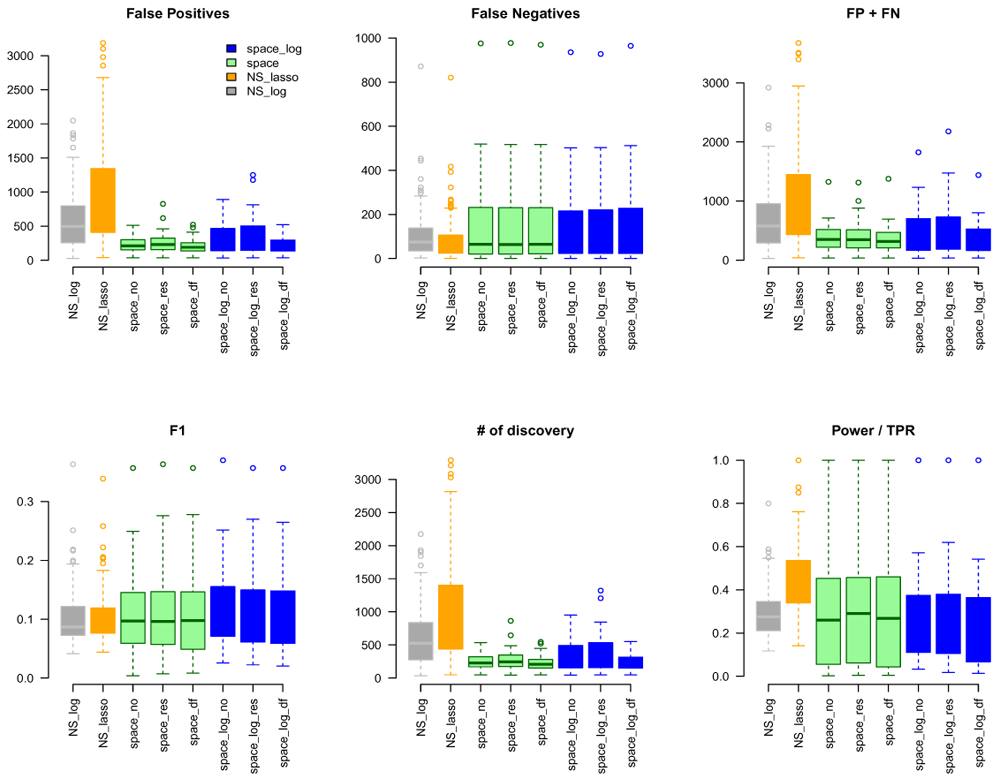
We applied both proposed space-log and existing methods (space-lasso, NS-log, and NS-lasso) to identify GGN using RNA-seq data from tumor tissue of 550 TCGA (The Cancer Genome Atlas) Colon Adenocarcinoma (TCGA-COAD) cancer patients14. The preprocessing steps of RNA-seq data included: (1) transforming the expression of each gene by log(total read count) = logTReC (2) removing the confounding effects by taking residuals of logTReC from a linear regression with the following covariates: 75% of logTReC per sample (which captures read depth), plate, institution, age, and six PCs from the corresponding germline genotype data. After removing genes with low expression across most samples, we had 18,238 genes and 450 samples.
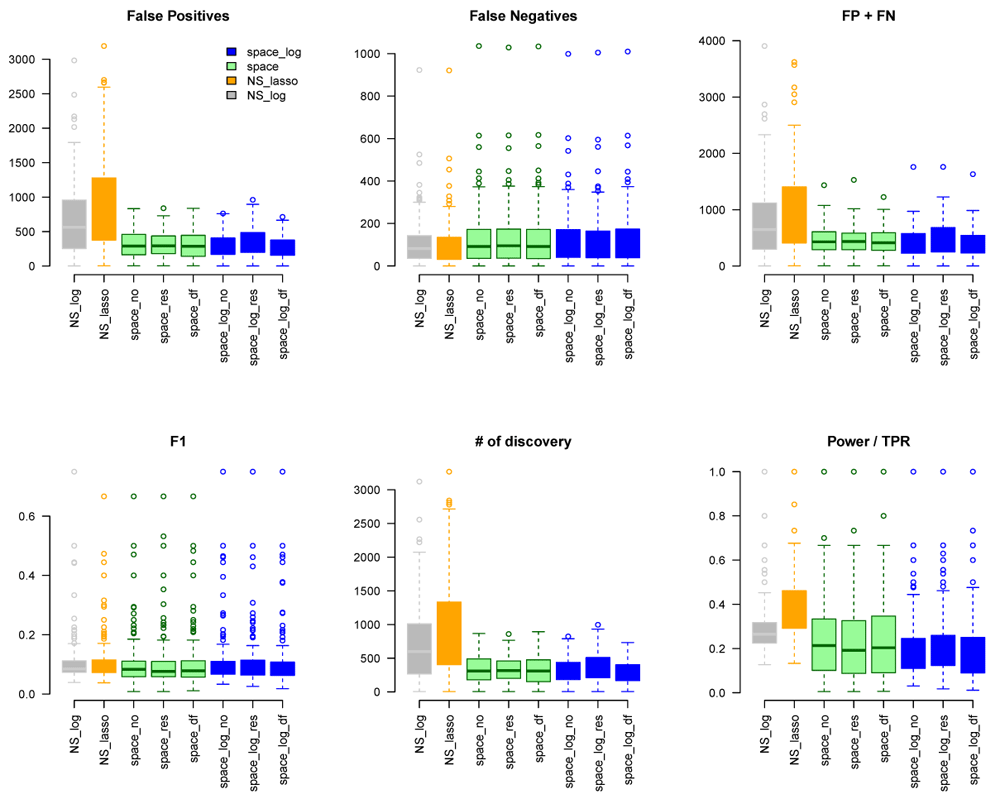
We considered gene sets C6 curated oncogenic pathways by MSigDB from the Broad Institute and inferred the GGN within each gene set. There were 189 gene pathways with a total of 8,737 unique genes for which TCGA have expression data. The sizes of gene sets ranged from 9 to 338 genes. Since we don’t know the true GGN, we downloaded the common pathway version 10 from www.pathwaycommons.org to provide a partial "gold standard". The observed GGN by different methods were compared with the known edges from common pathway and calculated FP, FN, FP+FN, number of total discovery, F1 score, and true positive rate (Extended data: Figure S10). The NS-based approach with both LASSO and log penalty discovered much more edges than space-based approach and space-log had fewer false positive (fewer FN+FP too) than space-lasso. There is almost no difference on number of false negative between different methods, as well as F1 score (Figure 4). Furthermore, in order to show the performance of these methods on the hub networks, we identified 17 pathways with hub-like genes (each hub gene set has < 50 genes and variance of the number of identified edges for each gene in the gene set > the first quartile of all 189 gene sets) and re-calculated the summary metrics in Figure 5. We noted that space-log approach has smallest Errors and slightly higher F1 than other approaches, which is in line with our finding in simulation that space-log is powerful in identifying hub networks, (such as BA models).
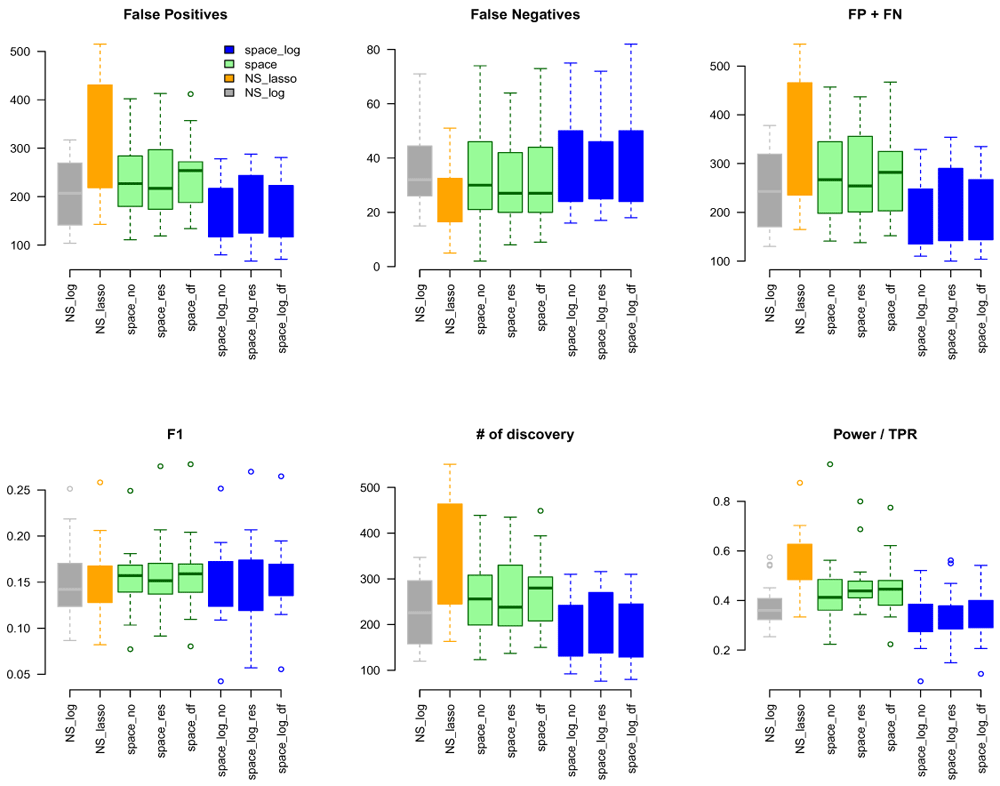
The Genotype Tissue Expression (GTEx) project15 aims to study tissue-specific gene expression and regulation in normal individuals. In this paper, we used gene expression data (RNA-seq) from blood tissue of 451 patients to identify GGN. We pre-processed gene expression data using the same procedure as for TCGA data. We mapped genes to gene pathways by MSigDB (https://www.gsea-msigdb.org/gsea/msigdb/index.jsp). A total of 189 gene pathways were represented with a total of 8097 unique genes. The size of gene sets ranged from 8 to 306 genes.
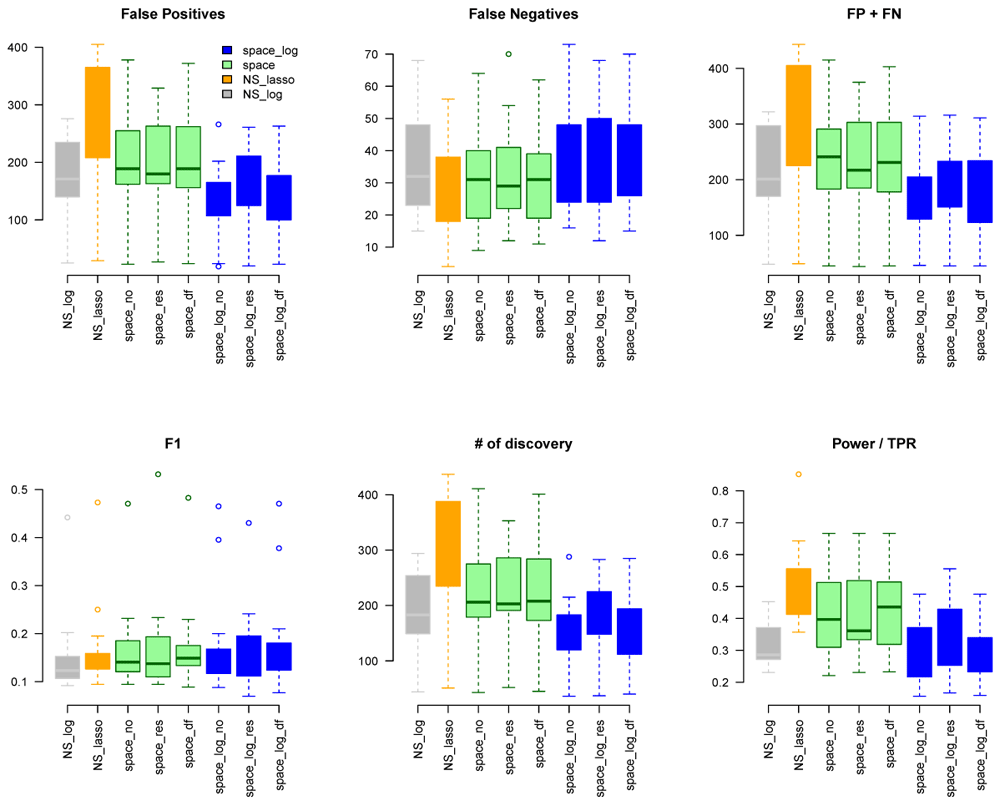
Again, we applied space-log, space-lasso, NS-log, and NS-lasso approaches to identify GGN. Using the same common pathway file used for the TCGA analysis as gold standard, we calculated FP, FN, FP+FN, # of discovery, F1, TPR (Figure 6). We obtained very similar results to the TCGA data. The NS-based approach with both LASSO and log penalty discovered much more edges than the space-based approach and space-log has fewer false positive (fewer FN+FP too) than space-lasso. There is almost no difference in the number of false negative between different methods, as well as F1 score. A similar sensitivity analysis was conducted to a subset of hub-type genes (Figure 7), where 30 pathways were selected to be in the first quartile of the variance of the number of identified genes with < 50. It also showed the space-log approach has smallest Errors (F1 is similar to other approaches).
In this paper, we proposed a new joint modeling method with log penalty, space-log, to identify gene-gene network. An assumption of the GGN analysis is that most of gene pairs do not directly interact with each other, and there are a few of master genes (hubs) for network that connect with many other genes, which are thought to play a critical role in a biological system13,16. Both simulation and real data analyses showed that space-log is particularly powerful in identifying hub networks and master genes, which is considered of great interest in gene-gene network analysis. In the Extended data, we compared several tuning parameter selection approaches, such as BIC Zou et al.17, extBIC8,18, and oracle4, and showed that extBIC outperforms other methods in simulation. The R package "SpaceLog" on GitHub includes algorithms, simulation, and real data examples: https://github.com/wuqian77/SpaceLog.
Simulation data. We used barabasi.game function from igraph R package to generate the skeleton of a BA model.
Source code, simulated data, and plots: https://github.com/wuqian77/SpaceLog/tree/master/Simulation.
TCGA data. The RNA-seq dataset from tumor tissue of 550 TCGA (The Cancer Genome Atlas) colon adenocarcinoma (TCGA-COAD) cancer patients14 can be downloaded from dbGap phs000178.v1.p1.: https://www.cancer.gov/about-nci/organization/ccg/research/structural-genomics/tcga.
Pre-processing and data analysis source code: https://github.com/wuqian77/SpaceLog/tree/ master/Analysis/TCGA.
GTex data. The RNA-seq dataset of blood tissue from the Genotype Tissue Expression (GTEx) project15 can be downloaded from dbGap Genotype-Tissue Expression Project and the study accession is phs000424.v7.p2.: https://www.gtexportal.org/home/datasets.
Pre-processing and data analysis source code: https://github.com/wuqian77/SpaceLog/tree/master/Analysis/GTex.
Zenodo: SpaceLog: First release of spacelog, http://doi.org/10.5281/zenodo.400293119.
This project contains the following extended data:
the detailed algorithm for active shooting;
simulation and figures on comparing methods to choose tuning parameters;
simulation and figures on comparing different GGN methods under various scenarios.
License: GPL-3
Source code for space-log available from: https://github.com/wuqian77/SpaceLog
Archived source code as at time of publication: http://doi.org/10.5281/zenodo.400293119.
License: GPL-3
Source code for NS-log and NS-lasso available from: https://github.com/Sun-lab/penalized_estimation
License: GPL-3
Existing methods space-lasso is available on R CRAN: https://cran.r-project.org/web/packages/space/index.html.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)